目录
[1. IO读写的基础原理](#1. IO读写的基础原理)
[1.1 内核空间与用户空间](#1.1 内核空间与用户空间)
[1.2 内核缓冲区与进程缓冲区](#1.2 内核缓冲区与进程缓冲区)
[1.3 典型IO系统调用sys_read&sys_write的流程](#1.3 典型IO系统调用sys_read&sys_write的流程)
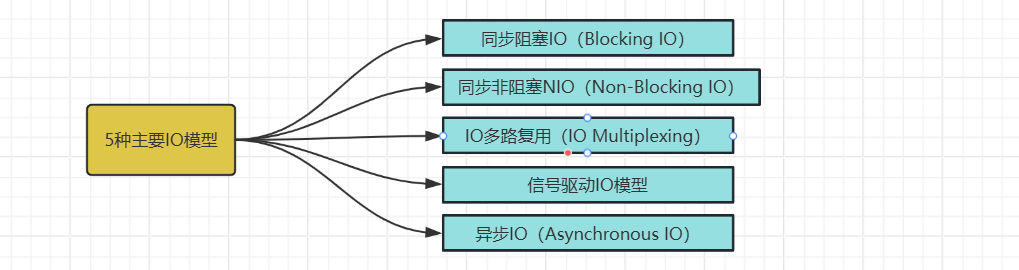
[2. 5种主要的IO模型](#2. 5种主要的IO模型)
[2.1 同步阻塞IO(Blocking IO)](#2.1 同步阻塞IO(Blocking IO))
[2.2 同步非阻塞NIO(Non-Blocking IO)](#2.2 同步非阻塞NIO(Non-Blocking IO))
[2.3 IO多路复用(IO Multiplexing)](#2.3 IO多路复用(IO Multiplexing))
[2.4 .信号驱动IO模型](#2.4 .信号驱动IO模型)
[2.5 异步IO(Asynchronous IO)](#2.5 异步IO(Asynchronous IO))
[2.6 同步异步、阻塞非阻塞区别联系](#2.6 同步异步、阻塞非阻塞区别联系)
1. IO读写的基础原理
1.1 内核空间与用户空间
-
为了避免用户进程直接操作内核,保证内核安全,操作系统将内存(虚拟内存)划分为 两部分,一部分是内核空间(Kernel-Space),一部分是用户空间(User-Space)。
-
在 Linux系统中,内核模块运行在内核空间,对应的进程处于内核态;而用户程序运行在用户空间,对应的进程处于用户态。
-
操作系统的核心是内核,独立于普通的应用程序,可以访问受保护的内核空间,也有访问底层硬件设备的权限。内核空间总是驻留在内存中,它是为操作系统的内核保留的。
-
应用程序是不允许直接在内核空间区域进行读写,也是不容许直接调用内核代码定义的函数的。 每个应用程序进程都有一个单独的用户空间,对应的进程处于用户态
-
用户态进程不能访问内核空间中的数据,也不能直接调用内核函数的,因此要进行系统调用的时候,就要将进程切换到内核态才能进行。
-
内核态进程可以执行任意命令,调用系统的一切资源,而用户态进程只能执行简单的运算,不能直接调用系统资源
用户态进程如何执行系统调用呢? 答案为:用 户态进程必须通过系统接口(System Call),才能向内核发出指令,完成调用系统资源之类 的操作
用户程序进行IO操作原理
-
用户程序进行IO的读写,依赖于底层的IO读写,基本上会用到底层的两大系统调用: sys_read & sys_write。
-
虽然在不同的操作系统中,sys_read&sys_write两大系统调用的名称和形式可能不完全一样,但是他们的基本功能是一样的。
1.2 内核缓冲区与进程缓冲区
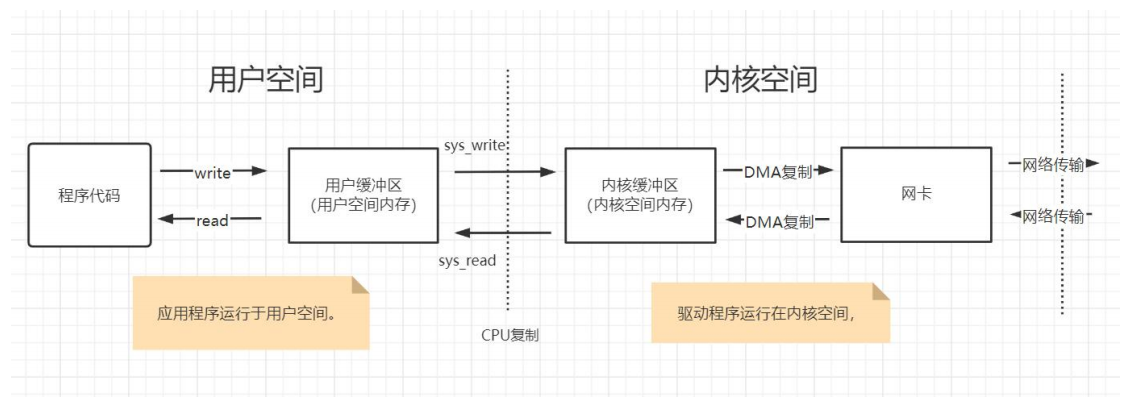
操作系统层面的sys_read系统调用,并不是直接从物理设备把数据读取到应用的内存中; sys_write系统调用,也不是直接把数据写入到物理设备。
上层应用无论是调用操作系统的sys_read,还是调用操作系统的sys_write,都会涉及缓冲区。
具体来说,上层应用通过操作 系统的sys_read系统调用,是把数据从内核缓冲区复制到应用程序的进程缓冲区;上层应用通过操作系统的sys_write系统调用,是把数据从应用程序的进程缓冲区复制到操作系统内核 缓冲区。
简单来说,应用程序的IO操作,实际上不是物理设备级别的读写,而是缓存的复制。 sys_read&sys_write两大系统调用,都不负责数据在内核缓冲区和物理设备(如磁盘、网卡等)之间的交换。这项底层的读写交换操作,是由操作系统内核(Kernel)来完成的。所以, 应用程序中的IO操作,无论是对Socket的IO操作,还是对文件的IO操作,都属于上层应用的开发,它们的在输入(Input)和输出(Output)维度上的执行流程,都是类似的,都是在内核缓冲区和进程缓冲区之间的进行数据交换。
为什么设置那么多的缓冲区,导致读写过程那么麻烦呢?
-
缓冲区的目的,是为了减少频繁地与设备之间的物理交换。
-
计算机的外部物理设备与内存与CPU相比,有着非常大的差距,外部设备的直接读写,涉及操作系统的中断。发生系统 中断时,需要保存之前的进程数据和状态等信息,而结束中断之后,还需要恢复之前的进程数据和状态等信息。为了减少底层系统的频繁中断所导致的时间损耗、性能损耗,于是出现了内核缓冲区。
-
有了内核缓冲区,操作系统会对内核缓冲区进行监控,等待缓冲区达到一定数量的时候,再进行IO设备的中断处理,集中执行物理设备的实际IO操作,通过这种机制来提升系统的性能。至于具体在什么时候执行系统中断(包括读中断、写中断),则由操作系统的内核来决定,应用程序不需要关心。
-
上层应用程序使用sys_read系统调用时,仅仅把数据从内核缓冲区复制到上层应用的缓冲区(进程缓冲区);上层应用使用sys_write系统调用时,仅仅把数据从应用的用户缓冲区复制到内核缓冲区中。
-
内核缓冲区与应用缓冲区在数量上也不同,在Linux系统中,操作系统内核只有一个内核缓冲区。而每个用户程序(进程)则有自己独立的缓冲区,叫做用户缓冲区或者进程缓冲区。Linux系统中的用户程序的IO读写程序,在大多数情况下,并没有进行实际的IO操作,而是在用户缓冲区和内核缓冲区之间直接进行数据的交换。
1.3 典型IO系统调用sys_read&sys_write的流程
系统调用sys_read&sys_write,并不是使数据在内核缓冲区和物理设备之间的交换。sys_read调用把数据从内核缓冲区复制到应用的用户缓冲区,sys_write调用把数据从应用的用户缓冲区复制到内核缓冲区
两个系统调用的大致的流程
以sys_read系统调用为例,完整输入流程如下:
应用程序等待数据准备好。
从内核缓冲区向用户缓冲区复制数据。
如果是sys_read一个socket(套接字),那么以上两个阶段的具体处理流程如下:
第一个阶段,应用程序等待数据通过网络中到达网卡,当所等待的分组到达时,数据被操作系统复制到内核缓冲区中。这个工作由操作系统自动完成,用户程序无感知。
第二个阶段,内核将数据从内核缓冲区复制到应用的用户缓冲区。
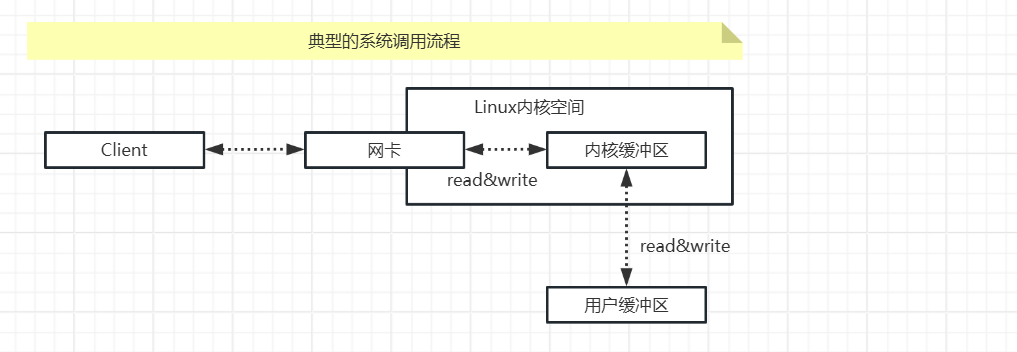
再具体一点,如果是在C程序客户端和服务器端之间完成一次socket请求和响应(包括sys_read和sys_write)的数据交换,其完整的流程如下:
客户端发送请求:C程序客户端程序通过sys_write系统调用,将数据复制到内核缓冲区,Linux将内核缓冲区的请求数据通过客户端器的网卡发送出去。
服务端系统接收数据:在服务端,这份请求数据会被服务端操作系统通过DMA硬件,从接收网卡中读取到服务端机器的内核缓冲区。
服务端C程序获取数据:服务端C程序通过sys_read系统调用,从Linux内核缓冲区复制数据,复制到C用户缓冲区。
服务器端业务处理:服务器在自己的用户空间中,完成客户端的请求所对应的业务处理。
服务器端返回数据:服务器C程序完成处理后,构建好的响应数据,将这些数据从用户缓冲区写入内核缓冲区,这里用到的是sys_write系统调用,操作系统会负责将内核缓冲区的数据发送出去。
服务端系统发送数据:服务端Linux系统将内核缓冲区中的数据写入网卡,网卡通过底层的通信协议,会将数据发送给目标客户端。
2. 5种主要的IO模型
**阻塞非阻塞:**阻塞IO,指的是需要内核IO操作彻底完成后,才返回到用户空间执行用户程序的操作指令,阻塞一词所指的是用户程序(发起IO请求的进程或者线程)的执行状态是阻塞的。可以说传统的IO模型都是阻塞IO模型,并且在Java中,默认创建的socket都属于阻塞IO模型。
同步与异步: 同步与异步可以看成是发起IO请求的两种方式。同步IO是指用户空间(进程或者线程)是主动发起IO请求的一方,系统内核是被动接受方。异步IO则反过来,系统内核主动发起IO请求的一方,用户空间是被动接受方。
2.1 同步阻塞IO(Blocking IO)
谓同步阻塞IO,指的是用户空间(或者线程)主动发起,需要等待内核IO操作彻底完成后,才返回到用户空间的IO操作,IO操作过程中,发起IO请求的用户进程(或者线程)处于阻塞状态。
默认情况下,在Java应用程序进程中,所有对socket连接的进行的IO操作都是同步阻塞IO(Blocking IO)。
在阻塞式IO模型中,Java应用程序从发起IO系统调用开始,一直到系统调用返回,在这段时间内,发起IO请求的Java进程(或者线程)是阻塞的。直到返回成功后,应用进程才能开始处理用户空间的缓存区数据。
同步阻塞IO的具体流程
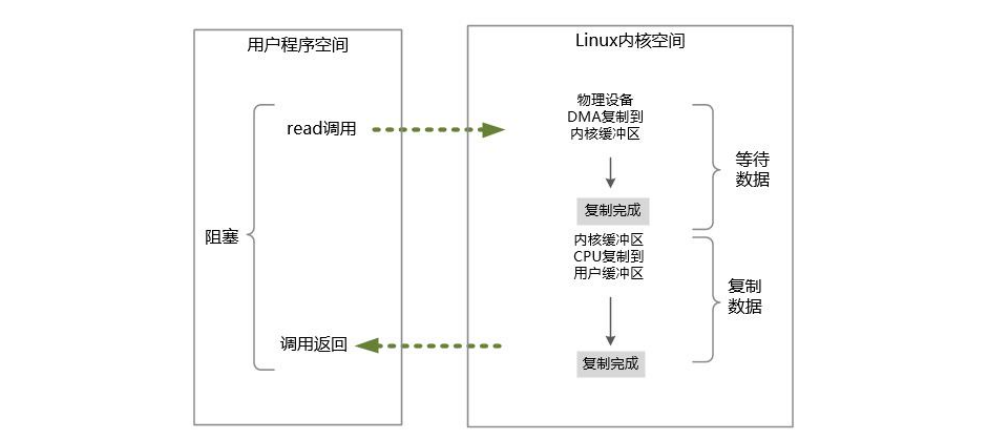
在Java中发起一个socket的sys_read读操作的系统调用,流程大致如下:
-
从Java进行IO读后发起sys_read系统调用开始,用户线程(或者线程)就进入阻塞状态。
-
当系统内核收到sys_read系统调用,就开始准备数据。一开始,数据可能还没有到达内核缓冲区(例如,还没有收到一个完整的socket数据包),这个时候内核就要等待。
-
内核一直等到完整的数据到达,就会将数据从内核缓冲区复制到用户缓冲区(用户空间的内存),然后内核返回结果(例如返回复制到用户缓冲区中的字节数)。
-
直到内核返回后,用户线程才会解除阻塞的状态,重新运行起来。
同步阻塞IO的特点:
- 在内核进行IO执行的两个阶段,发起IO请求的用户进程(或者线程)被阻塞了。
同步阻塞IO的优点:
- 应用的程序开发非常简单;在阻塞等待数据期间,用户线程挂起,用户线程基本不会占用CPU资源。
同步阻塞IO的缺点:
-
一般情况下,会为每个连接配备一个独立的线程,一个线程维护一个连接的IO操作。
-
在并发量小的情况下,这样做没有什么问题。但是,当在高并发的应用场景下,需要大量的线程来维护大量的网络连接,内存、线程切换开销会非常巨大。
-
在高并发应用场景中,阻塞IO模型是性能很低的,基本上是不可用的
2.2 同步非阻塞NIO(Non-Blocking IO)
非阻塞IO,指的是用户空间的程序不需要等待内核IO操作彻底完成,可以立即返回用户空间去执行后续的指令,即发起IO请求的用户进程(或者线程)处于非阻塞的状态,与此同时,内核会立即返回给用户一个IO的状态值。
阻塞和非阻塞的区别
阻塞是指用户进程(或者线程)一直在等待,而不能干别的事情;非阻塞是指用户进程(或者线程)拿到内核返回的状态值就返回自己的空间,可以去干别的事情。
在Java中,非阻塞IO的socket套接字,要求被设置为NONBLOCK模式。
同步非阻塞NIO,指的是用户进程主动发起,不需要等待内核IO操作彻底完成之后,就能立即返回到用户空间的IO操作,IO操作过程中,发起IO请求的用户进程(或者线程)处于非阻塞状态。
在Linux系统下,socket连接默认是阻塞模式,可以通过设置将socket变成为非阻塞的模式(Non-Blocking)。
在NIO模型中,应用程序一旦开始IO系统调用,会出现以下两种情况:
在内核缓冲区中没有数据的情况下,系统调用会立即返回,返回一个调用失败的信息。
在内核缓冲区中有数据的情况下,在数据的复制过程中系统调用是阻塞的,直到完成数据从内核缓冲复制到用户缓冲。复制完成后,系统调用返回成功,用户进程(或者线程)可以开始处理用户空间的缓存数据。
同步非阻塞IO的流程
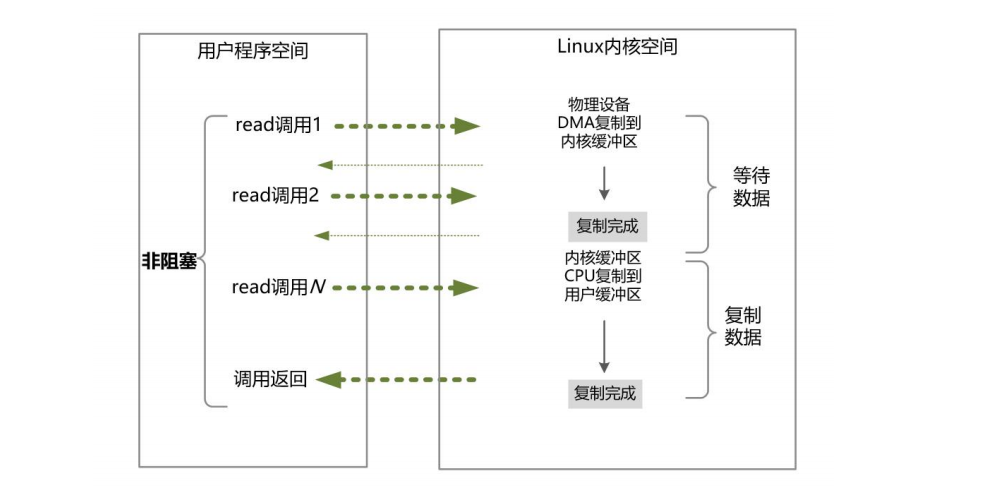
发起一个非阻塞socket的sys_read读操作的系统调用,流程如下
-
在内核数据没有准备好的阶段,用户线程发起IO请求时,立即返回。所以,为了读取到最终的数据,用户进程(或者线程)需要不断地发起IO系统调用。
-
内核数据到达后,用户进程(或者线程)发起系统调用,用户进程(或者线程)阻塞(大家一定要注意,此处用户进程的阻塞状态)。内核开始复制数据,它会将数据从内核缓冲区复制到用户缓冲区,然后内核返回结果(例如返回复制到的用户缓冲区的字节数)。
-
用户进程(或者线程)在读数据时,没有数据会立即返回而不阻塞,用户空间需要经过多次的尝试,才能保证最终真正读到数据,而后继续执行。
同步非阻塞IO的特点:
- 应用程序的线程需要不断地进行IO系统调用,轮询数据是否已经准备好,如果没有准备好,就继续轮询,直到完成IO系统调用为止。
同步非阻塞IO的优点:
- 每次发起的IO系统调用,在内核等待数据过程中可以立即返回。用户线程不会阻塞,实时性较好。
同步非阻塞IO的缺点:
- 不断地轮询内核,这将占用大量的CPU时间,效率低下。
总体来说,在高并发应用场景中,同步非阻塞IO是性能很低的,也是基本不可用的,一般Web服务器都不使用这种IO模型。在Java的实际开发中,也不会涉及这种IO模型。但是此模型还是有价值的,其作用在于,其他IO模型中可以使用非阻塞IO模型作为基础,以实现其高性能。
说明:
同步非阻塞 IO 也可以简称为 NIO,但是,它不是 Java 编程中的 NIO,虽然它们的英文缩写一样,但是不能混淆。Java 的 NIO(New IO)类库组件,所归属的不是基础 IO 模型中的 NIO(None Blocking IO)模型,而是另外的一种模型,叫做 IO 多路复用模型(IOMultiplexing)。
2.3 IO多路复用(IO Multiplexing)
为了提高性能,操作系统引入了一类新的系统调用,专门用于查询IO文件描述符的(含socket连接)的就绪状态。在Linux系统中,新的系统调用为select/epoll系统调用。通过该系统调用,一个用户进程(或者线程)可以监视多个文件描述符,一旦某个描述符就绪(一般是内核缓冲区可读/可写),内核能够将文件描述符的就绪状态返回给用户进程(或者线程),用户空间可以根据文件描述符的就绪状态,进行相应的IO系统调用。
**IO多路复用(IO Multiplexing)**是高性能Reactor线程模型的基础IO模型,此模型是建立在同步非阻塞的模型基础之上的升级版。
IO多路复用模型可以避免同步非阻塞IO中的轮询等待的问题
在IO多路复用模型中,引入了一种新的系统调用,查询IO的就绪状态。在Linux系统中,对应的系统调用为select/epoll系统调用。通过该系统调用,一个进程可以监视多个文件描述符(包括socket连接),一旦某个描述符就绪(一般是内核缓冲区可读/可写),内核能够将就绪的状态返回给应用程序。随后,应用程序根据就绪的状态,进行相应的IO系统调用。
在IO多路复用模型中通过select/epoll系统调用,单个应用程序的线程,可以不断地轮询成百上千的socket连接的就绪状态,当某个或者某些socket网络连接有IO就绪状态,就返回这些就绪的状态(或者说就绪事件)。
IO多路复用模型的sys_read系统调用流程如下:
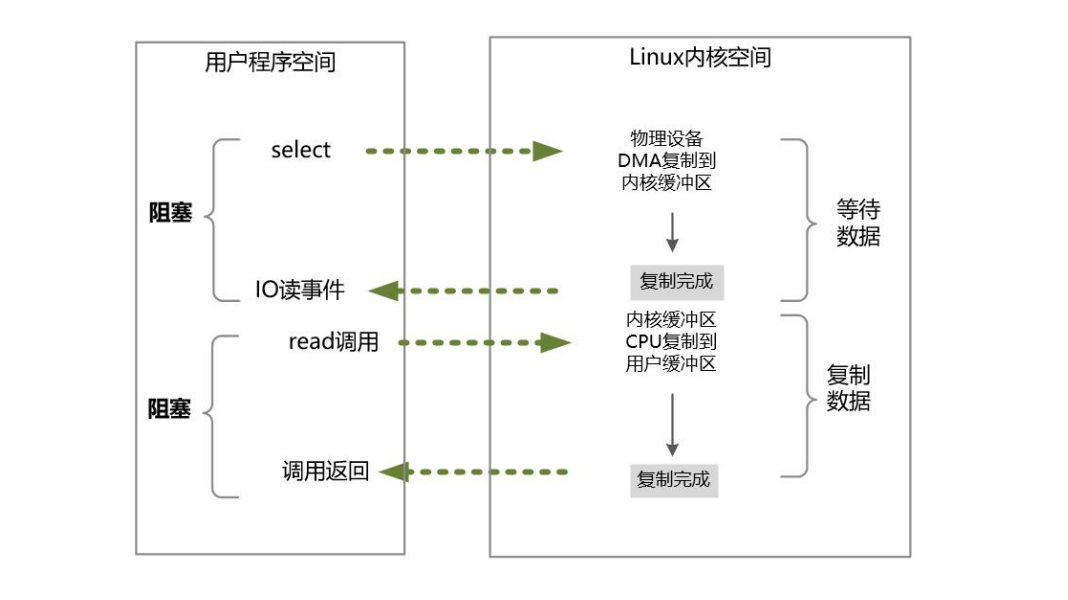
流程如下:
-
**选择器注册。**在这种模式中,首先,将需要sys_read操作的目标文件描述符(socket连接),提前注册到Linux的select/epoll选择器中,在Java中所对应的选择器类是Selector类。然后,才可以开启整个IO多路复用模型的轮询流程。
-
**就绪状态的轮询。**通过选择器的查询方法,查询所有的提前注册过的目标文件描述符(socket连接)的IO就绪状态。通过查询的系统调用,内核会返回一个就绪的socket列表。当任何一个注册过的socket中的数据准备好或者就绪了,就是内核缓冲区有数据了,内核就将该socket加入到就绪的列表中,并且返回就绪事件。
-
用户线程获得了就绪状态的列表后,根据其中的socket连接,发起sys_read系统调用,用户线程阻塞。内核开始复制数据,将数据从内核缓冲区复制到用户缓冲区。
-
复制完成后,内核返回结果,用户线程才会解除阻塞的状态,用户线程读取到了数据,继续执行。
IO多路复用模型的特点:
-
IO多路复用模型的IO涉及两种系统调用,一种是IO操作的系统调用,另一种是select/epoll就绪查询系统调用。
-
IO多路复用模型建立在操作系统的基础设施之上,即操作系统的内核必须能够提供多路分离的系统调用select/epoll。
-
和NIO模型相似,多路复用IO也需要轮询。负责select/epoll状态查询调用的线程,需要不断地进行select/epoll轮询,查找出达到IO操作就绪的socket连接。
-
IO多路复用模型与同步非阻塞IO模型是有密切关系的,具体来说,注册在选择器上的每一个可以查询的socket连接,一般都设置成为同步非阻塞模型。只是这一点对于用户程序而言,是无感知的。
IO多路复用模型的优点:
-
一个选择器查询线程,可以同时处理成千上万的网络连接,所以,用户程序不必创建大量的线程,也不必维护这些线程,从而大大减小了系统的开销。这是一个线程维护一个连接的阻塞IO模式相比,使用多路IO复用模型的最大优势。
-
通过JDK的源码可以看出,Java语言的NIO(New IO)组件,在Linux系统上,是使用的是select系统调用实现的。所以,Java语言的NIO(New IO)组件所使用的,就是IO多路复用模型。
IO多路复用模型的缺点:
-
本质上,select/epoll系统调用是阻塞式的,属于同步阻塞IO。都需要在读写事件就绪后,由系统调用本身负责进行读写,也就是说这个事件的查询过程是阻塞的。
-
如果彻底地解除线程的阻塞,就必须使用异步IO模型
2.4 .信号驱动IO模型
在信号驱动IO模型中,用户线程通过向核心注册IO事件的回调函数,来避免IO时间查询的阻塞。
具体来说,用户进程预先在内核中设置一个回调函数,当某个事件发生时,内核使用信号(SIGIO)通知进程运行回调函数。然后进入IO操作的第二个阶段------执行阶段:用户线程会继续执行,在信号回调函数中调用IO读写操作来进行实际的IO请求操作。
信号驱动IO可以看成是一种异步IO,可以简单理解为系统进行用户函数的回调。只是信号驱动IO的异步特性做的不彻底。为什么呢? 信号驱动IO仅仅在IO事件的通知阶段是异步的,而在第二阶段,也就是在将数据从内核缓冲区复制到用户缓冲区这个过程,用户进程是阻塞的、同步的。
在信号驱动IO模型中,用户线程通过向核心注册IO事件的回调函数,来避免IO时间查询的阻塞。
具体的做法是,用户进程预先在内核中设置一个回调函数,当某个事件发生时,内核使用信号(SIGIO)通知进程运行回调函数。 然后用户线程会继续执行,在信号回调函数中调用IO读写操作来进行实际的IO请求操作。
信号驱动IO的基本流程是:用户进程通过系统调用,向内核注册SIGIO信号的owner进程和以及进程内的回调函数。内核IO事件发生后(比如内核缓冲区数据就位)后,通知用户程序,用户进程通过sys_read系统调用,将数据复制到用户空间,然后执行业务逻辑。
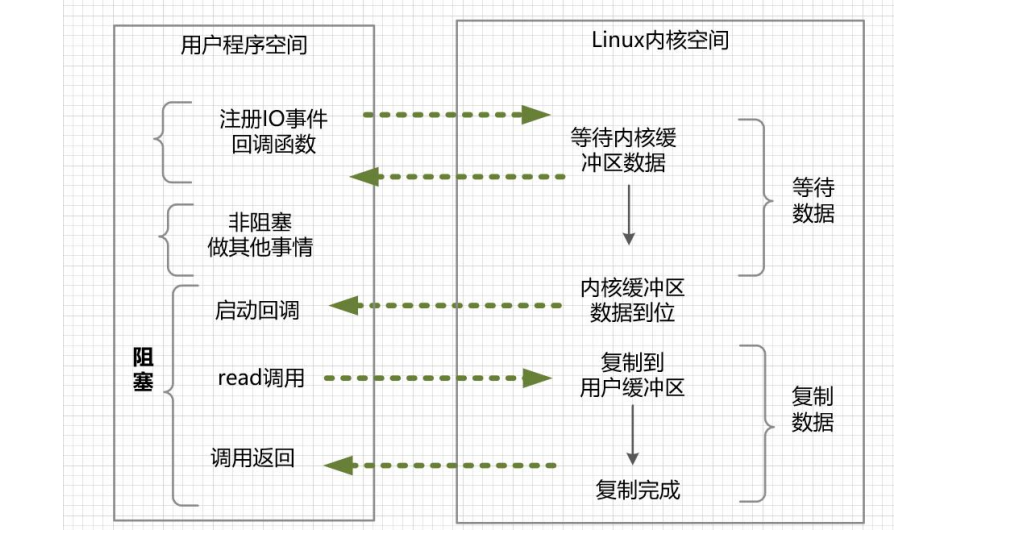
发起一个异步IO的sys_read读操作的系统调用流程如下:
-
设置SIGIO信号的信号处理回调函数。
-
设置该套接口的属主进程,使得套接字的IO事件发生时,系统能够将SIGIO信号传递给属主进程,也就是当前进程。
-
开启该套接口的信号驱动I/O机制,通常通过使用fcntl方法的F_SETFL操作命令,使能(enable)套接字的 O_NONBLOCK非阻塞标志和O_ASYNC异步标志完成。
完成以上三步,用户进程就完成了事件回调处理函数的设置。当文件描述符上有事件发生时,SIGIO 的信号处理函数将被触发,然后便可对目标文件描述符执行 I/O 操作。
信号驱动IO优势:
-
用户进程在等待数据时,不会被阻塞,能够提高用户进程的效率。
-
具体来说:在信号驱动式I/O模型中,应用程序使用套接口进行信号驱动I/O,并安装一个信号处理函数,进程继续运行并不阻塞。
信号驱动IO缺点:
-
在大量IO事件发生时,可能会由于处理不过来,而导致信号队列溢出。
-
对于处理UDP套接字来讲,对于信号驱动I/O是有用的。可是,对于TCP而言,由于致使SIGIO信号通知的条件为数众多,进行IO信号进一步区分的成本太高,信号驱动的I/O方式近乎无用。
-
信号驱动IO可以看成是一种异步IO,可以简单理解为系统进行用户函数的回调。只是,信号驱动IO的异步特性,又做的不彻底。为什么呢? 信号驱动IO仅仅在IO事件的通知阶段是异步的,而在第二阶段,也就是在将数据从内核缓冲区复制到用户缓冲区这个过程,用户进程是阻塞的、同步的。
如果要做彻底的异步IO,那就需要使用异步IO模式。
2.5 异步IO(Asynchronous IO)
异步IO,指的是用户空间与内核空间的调用方式大反转。用户空间的线程变成被动接受者,而内核空间成了主动调用者。在异步IO模型中,当用户线程收到通知时,数据已经被内核读取完毕,并放在了用户缓冲区内,内核在IO完成后通知用户线程直接使用即可。
异步IO类似于Java中典型的回调模式,用户进程(或者线程)向内核空间注册了各种IO事件的回调函数,由内核去主动调用。
异步IO包含两种:不完全异步的信号驱动IO模型和完全的异步IO模型。
异步IO模型(Asynchronous IO,简称为AIO)。AIO的基本流程是:用户线程通过系统调用,向内核注册某个IO操作。内核在整个IO操作(包括数据准备、数据复制)完成后,通知用户程序,用户执行后续的业务操作。
在异步IO模型中,在整个内核的数据处理过程中,包括内核将数据从网络物理设备(网卡)读取到内核缓冲区、将内核缓冲区的数据复制到用户缓冲区,用户程序都不需要阻塞。
异步IO模型的流程
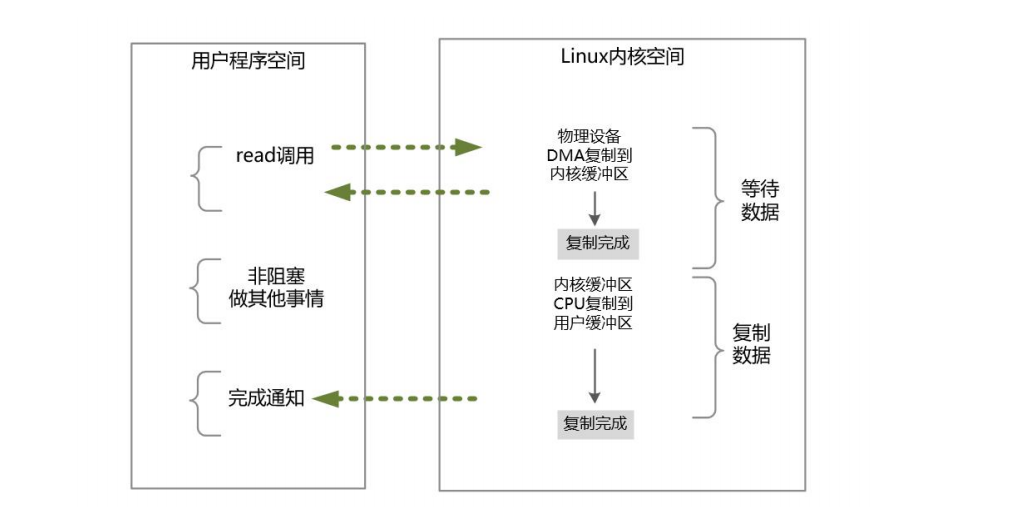
发起一个异步IO的sys_read读操作的系统调用,流程如下:
-
当用户线程发起了sys_read系统调用(可以理解为注册一个回调函数),立刻就可以开始去做其他的事,用户线程不阻塞。
-
内核就开始了IO的第一个阶段:准备数据。等到数据准备好了,内核就会将数据从内核缓冲区复制到用户缓冲区。
-
内核会给用户线程发送一个信号(Signal),或者回调用户线程注册的回调方法,告诉用户线程,sys_read系统调用已经完成了,数据已经读入到了用户缓冲区。
-
用户线程读取用户缓冲区的数据,完成后续的业务操作。
异步IO模型的特点:
-
在内核等待数据和复制数据的两个阶段,用户线程都不是阻塞的。
-
用户线程需要接收内核的IO操作完成的事件,或者用户线程需要注册一个IO操作完成的回调函数。
-
正因为如此,异步IO有的时候也被称为信号驱动IO。
异步IO异步模型的缺点:
- 应用程序仅需要进行事件的注册与接收,其余的工作都留给了操作系统,也就是说,需要底层内核提供支持。
2.6 同步异步、阻塞非阻塞区别联系
同步和异步:
-
同步和异步,是针对应用程序(如Java)与内核的交互过程的方向而言的
-
同步类型的IO操作,发起方是应用程序,接收方是内核。
-
同步IO由应用进程发起IO操作,并阻塞等待,或者轮询的IO操作是否完成。
-
异步IO操作,应用程序在提前注册完成回调函数之后去做自己的事情,IO交给内核来处理,在内核完成IO操作以后,启动进程的回调函数。
阻塞和非阻塞:
-
阻塞与非阻塞,关注的是用户进程在IO过程中的等待状态。
-
前者用户进程需要为IO操作去阻塞等待,而后者用户进程可以不用为IO操作去阻塞等待。
-
同步阻塞型IO、同步非阻塞IO、多路IO复用,都是同步IO,也是阻塞性IO。
-
异步IO必定是非阻塞的,所以不存在异步阻塞和异步非阻塞的说法。真正的异步IO需要内核的深度参与。异步IO中的用户进程时候根本不去考虑IO的执行,IO操作主要交给内核去完成,而自己只等待一个完成信号。
3.Linux系统配置使其支持百万级并发连接
在 Linux 环境中,任何事物都是用文件来表示,设备是文件,目录是文件,socket 也是文件。用来表示所处理对象的接口和唯一接口就是文件。应用程序在读/写一个文件时,首先需要打开这个文件,打开的过程其实质就是在进程与文件之间建立起连接,句柄的作用就是唯一标识此连接。此后对文件的读/写时,由这个句柄作为代表。最后关闭文件其实就是释放这个句柄的过程,也就是进程与文件之间的连接断开。
这里所涉及的配置,就是Linux操作系统中文件句柄数的限制。在生产环境Linux系统中,基本上都需要解除文件句柄数的限制。原因是,Linux的系统默认值为1024,也就是说,一个进程最多可以接受1024个socket连接。这是远远不够的。
文件句柄,也叫文件描述符。在Linux系统中,文件可分为:普通文件、目录文件、链接文件和设备文件。文件描述符(File Descriptor)是内核为了高效管理已被打开的文件所创建的索引,它是一个非负整数(通常是小整数),用于指代被打开的文件。所有的IO系统调用,包括socket的读写调用,都是通过文件描述符完成的。
bash
# 通过调用ulimit命令,可以看到一个进程能够打开的最大文件句柄数量
# ulimit 命令是用来显示和修改当前用户进程一些基础限制的命令,-n选项用于引用或设置当前的文件句柄数量的限制值,Linux的系统默认值为1024。
unlimit -n
# 文件句柄数不够,会导致什么后果呢?当单个进程打开的文件句柄数量超过了系统配置的上限值时,就会发出"Socket/File:Can't open so many files"的错误提示。
# 修改句柄数量命令如下
ulimit -n 1000000ulimit命令只能用于临时修改,如果想永久地把最大文件描述符数量值保存下来,可以编辑/etc/rc.local开机启动文件,在文件中添加如下内容:
bash
ulimit -SHn 1000000
# -S表示软性极限值,-H表示硬性极限值。硬性极限是实际的限制,就是最大可以是100万,不能再多了。
# 软性极限值则是系统发出警告(Warning)的极限值,超过这个极限值,内核会发出警告。
# 普通用户通过ulimit命令,可将软极限更改到硬极限的最大设置值。如果要更改硬极限,必须拥有root用户权限。终极解除Linux系统的最大文件打开数量的限制,可以通过编辑Linux的极限配置文件/etc/security/limits.conf来解决,修改此文件,加入如下内容:
bash
soft nofile 1000000
hard nofile 1000000
# soft nofile表示软性极限,hard nofile表示硬性极限。除了修改应用进程的文件句柄上限之外,还需要修改内核基本的全局文件句柄上限,通过修改 /etc/sysctl.conf 配置文件来更改,参考的配置如下:
bash
fs.file-max = 2048000
fs.nr_open = 1024000
# fs.file-max表示系统级别的能够打开的文件句柄的上限,可以理解为全局的句柄数上限。是对整个系统的限制,并不是针对用户的。
# fs.nr_open指定了单个进程可打开的文件句柄的数量限制,nofile受到这个参数的限制,nofile值不可用超过fs.nr_open值。参考:
《极致经典(卷1):Java高并发核心编程(卷1 加强版) 》-尼恩