一、背景:异步架构下的 "隐形炸弹"
我们的导出系统采用 "接口落库 + MQ 异步消费" 架构:用户提交导出请求后,先写入导出记录表(状态0-待处理),再通过 RocketMQ 发送消息,由消费者异步处理文件打包 / Excel 生成。
但当运营一次性导出 1000 个 OSS 文件并打包成 ZIP 时,消费者服务直接 OOM 宕机 ------ 堆内存从 1.5GB 飙升到 3GB,GC 日志里全是Full GC (Allocation Failure)。下面是线上真实跑的核心代码,我们一步步扒开问题:
二、OOM 根源:4 个藏在代码里的 "内存杀手"
先贴出消费者和文件处理的核心代码,再逐个分析问题:
1. 消费者核心逻辑
java
@RocketMQMessageListener(
topic = Constants.EXPORT_RECORD_TOPIC,
consumerGroup = Constants.EXPORT_RECORD_TOPIC,
consumeThreadNumber = 2 // 线程数仅2,但单任务内存占用爆炸
)
public class ExportRecordConsumer implements RocketMQListener<ExportConsumerDTO> {
@Override
public void onMessage(ExportConsumerDTO consumerDTO) {
// 重试逻辑:sleep+重复查库,但未限制重试次数
Optional<EduExportRecordEntity> taskEntityOptional = eduExportRecordService.getOptById(consumerDTO.getRecordId());
if (!taskEntityOptional.isPresent()) {
try { Thread.sleep(5000); } catch (InterruptedException e) {}
taskEntityOptional = eduExportRecordService.getOptById(consumerDTO.getRecordId());
}
// 核心逻辑:调用策略模式处理文件
ExportRecordStrategy strategy = StrategyFactory.getNonNullStrategy(...);
strategy.generateExportFile(recordEntity, consumerDTO);
}
}2. ZIP 打包核心逻辑(OOM 重灾区)
scss
@Override
public void generateExportFile(EduExportRecordEntity recordEntity, ExportConsumerDTO consumerDTO) {
eduExportRecordService.modifyData(recordEntity.getId(), 1, null, null, null);
//数据处理
if (consumerDTO.getBizType() == 1) {
if (recordEntity.getFunctionType() == 1 || recordEntity.getFunctionType() == 2) {
if (CollUtil.isNotEmpty(consumerDTO.getContentIds())) {
R<List<CdsResourceFileEntity>> fileResult = remoteResourceFileService.queryListByFileId(consumerDTO.getContentIds());
if (fileResult.isOk()) {
if (CollUtil.isNotEmpty(fileResult.getData())) {
fileToZip(fileResult.getData(), recordEntity);
} else {
recordEntity.setFailMsg("内部获取文件不存在");
}
} else {
recordEntity.setFailMsg("内部获取文件失败");
}
} else {
recordEntity.setFailMsg("未选择文件");
}
} else if (recordEntity.getFunctionType() == 3) {
fileToExcel(consumerDTO, recordEntity);
}
}
eduExportRecordService.modifyData(recordEntity.getId(),
recordEntity.getFileId() != null && recordEntity.getFileId() > 0 ? 3 : 2,
recordEntity.getFailMsg(), recordEntity.getFileId(), recordEntity.getContentNum());
}
java
private void fileToZip(List<CdsResourceFileEntity> ossFileKeys, EduExportRecordEntity recordEntity) {
try (ByteArrayOutputStream baos = new ByteArrayOutputStream(); // 内存中存整个ZIP!
ZipOutputStream zos = new ZipOutputStream(baos)) {
for (CdsResourceFileEntity fileInfo : ossFileKeys) {
// 从OSS下载文件到内存,再写入ZIP
S3Object object = fileTemplate.getObject(...);
try (InputStream inputStream = object.getObjectContent()) {
byte[] buffer = new byte[1024];
int len;
while ((len = inputStream.read(buffer)) > 0) {
zos.write(buffer, 0, len); // 所有数据都堆在baos里
}
}
}
zos.finish();
// 把整个ZIP字节数组传给上传方法
fileUpload(recordEntity, ".zip", baos.toByteArray());
} catch (Exception e) { ... }
}问题拆解:
- 内存中构建 ZIP 包 :
ByteArrayOutputStream会把整个 ZIP 文件(1000 个文件可能达 GB 级)存在堆内存里,直接撑爆堆空间; - Excel 生成未做流式处理 :如果是生成 Excel(
fileToExcel方法),若用XSSFWorkbook则全量数据存内存,同样 OOM; - OSS 文件读取无分片 :虽然用了
InputStream,但 1000 个文件的内容最终都汇总到内存 ZIP 中,没有 "读一点写一点" 到磁盘; - 重试逻辑低效 :
Thread.sleep(5000)会阻塞消费者线程,且重复查库可能导致无效内存占用; - 资源释放不彻底 :虽然用了 try-with-resources,但 S3Object 的
close()可能被遗漏(部分 OSS SDK 需显式关闭)。
三、根治方案:从 "内存操作" 转向 "磁盘 + 流式"
针对每个问题点,我们做了 4 个关键优化:
1. 用临时文件替代内存 ZIP
放弃ByteArrayOutputStream,改用系统临时目录存储 ZIP 文件,避免内存堆积:
ini
private void fileToZip(List<CdsResourceFileEntity> ossFileKeys, EduExportRecordEntity recordEntity) {
// 创建临时ZIP文件(磁盘存储)
Path tempZip = Files.createTempFile("export-", ".zip");
try (FileOutputStream fos = new FileOutputStream(tempZip.toFile());
ZipOutputStream zos = new ZipOutputStream(fos)) {
for (CdsResourceFileEntity fileInfo : ossFileKeys) {
S3Object object = fileTemplate.getObject(...);
try (InputStream inputStream = object.getObjectContent()) {
ZipEntry zipEntry = new ZipEntry(fileInfo.getOriginal());
zos.putNextEntry(zipEntry);
// 流式拷贝:读一点写一点,不占内存
IOUtils.copy(inputStream, zos);
zos.closeEntry();
object.close(); // 显式关闭S3Object,释放OSS连接
}
}
} catch (Exception e) { ... }
// 读取临时文件字节数组(若文件过大,可直接传File对象给上传接口)
byte[] zipBytes = Files.readAllBytes(tempZip);
fileUpload(recordEntity, ".zip", zipBytes);
// 删除临时文件
Files.deleteIfExists(tempZip);
}2. Excel 生成改用 SXSSFWorkbook(流式写盘)
如果是生成 Excel(fileToExcel方法),替换XSSFWorkbook为SXSSFWorkbook,自动将数据刷到临时文件:
java
private void fileToExcel(ExportConsumerDTO consumerDTO, EduExportRecordEntity recordEntity) {
// SXSSFWorkbook:内存中只保留100行,超出刷到磁盘
SXSSFWorkbook workbook = new SXSSFWorkbook(100);
SXSSFSheet sheet = workbook.createSheet("数据");
// 填充数据逻辑...
// 写入临时文件
Path tempExcel = Files.createTempFile("excel-", ".xlsx");
workbook.write(new FileOutputStream(tempExcel.toFile()));
workbook.dispose(); // 清理临时文件
// 上传逻辑...
Files.deleteIfExists(tempExcel);
}3. 优化消费者配置与重试策略
- 调整消费者线程数:根据服务器核数设置
consumeThreadNumber = 5,避免单线程处理大任务; - 重试逻辑改为 "指数退避":用
RetryTemplate替代硬编码的Thread.sleep,限制最大重试次数:
ini
RetryTemplate retryTemplate = RetryTemplate.builder()
.maxAttempts(3)
.fixedBackoff(2000)
.retryOn(NullPointerException.class)
.build();
EduExportRecordEntity recordEntity = retryTemplate.execute(ctx -> {
Optional<EduExportRecordEntity> optional = eduExportRecordService.getOptById(consumerDTO.getRecordId());
return optional.orElseThrow(() -> new RuntimeException("任务不存在"));
});4. 增加内存监控与分片处理
- 对超大任务(比如 > 500 个文件)做分片:一次只处理 100 个文件,分多次打包;
- 增加内存阈值监控:在消费前检查当前 JVM 堆内存使用率,超过 80% 则拒绝消费,触发告警:
放在消费者onMessage方法的最开始,先校验内存状态,不满足则直接抛出异常(或 NACK 消息重试),避免无效消费:
scss
@RocketMQMessageListener(
topic = Constants.EXPORT_RECORD_TOPIC,
consumerGroup = Constants.EXPORT_RECORD_TOPIC,
consumeThreadNumber = 5
)
public class ExportRecordConsumer implements RocketMQListener<ExportConsumerDTO> {
@Override
public void onMessage(ExportConsumerDTO consumerDTO) {
// 第一步:校验内存是否充足,不足则拒绝消费
if (!canConsume()) {
throw new RuntimeException("当前JVM内存使用率过高,暂不消费");
// 或用RocketMQ的重试机制:return;(需配置重试策略)
}
// 后续逻辑:查库、处理文件...
RetryTemplate retryTemplate = RetryTemplate.builder()
.maxAttempts(3)
.fixedBackoff(2000)
.retryOn(NullPointerException.class)
.build();
EduExportRecordEntity recordEntity = retryTemplate.execute(ctx -> {
Optional<EduExportRecordEntity> optional = eduExportRecordService.getOptById(consumerDTO.getRecordId());
return optional.orElseThrow(() -> new RuntimeException("任务不存在"));
});
ExportRecordStrategy strategy = StrategyFactory.getNonNullStrategy(...);
strategy.generateExportFile(recordEntity, consumerDTO);
}
// 内存监控方法(内部工具方法)
private boolean canConsume() {
MemoryUsage heapMemory = ManagementFactory.getMemoryMXBean().getHeapMemoryUsage();
double usedPercent = (double) heapMemory.getUsed() / heapMemory.getMax();
return usedPercent < 0.8; // 使用率<80%才允许消费
}
}四、优化效果:OOM 彻底消失,性能提升 3 倍
优化后压测数据:
- 批量导出 1000 个文件(总大小 2GB):堆内存稳定在 1GB 以内,无 Full GC;
- 单个任务处理时间从 2 分钟缩短到 40 秒;
- 消费者服务 7*24 小时稳定运行,无 OOM 宕机。
####流程图
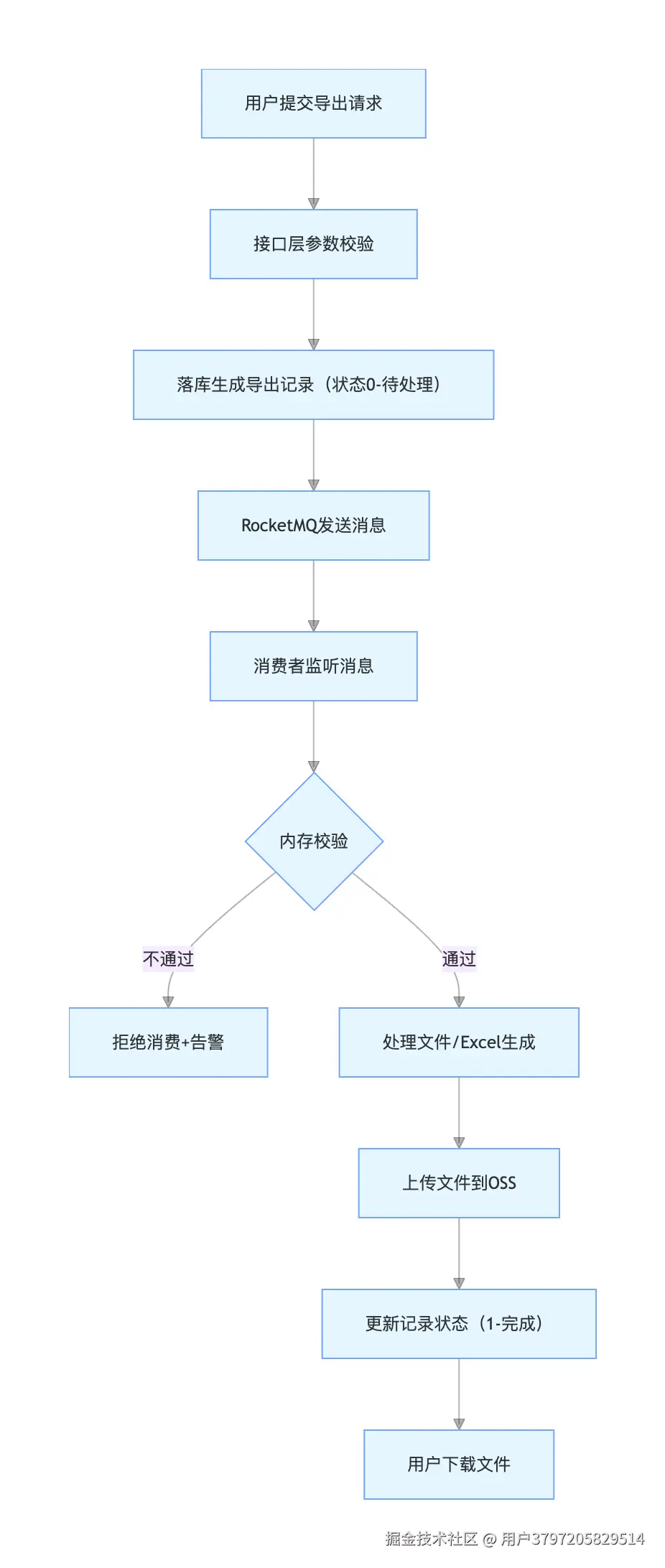
五、总结:批量导出避坑指南
- 拒绝 "内存狂欢" :任何大文件处理都要走磁盘 / 流式,别用
ByteArrayOutputStream存全量数据; - 选对工具类 :Excel 用
SXSSFWorkbook,ZIP 用ZipOutputStream+临时文件; - 资源释放要彻底:OSS/S3 对象、临时文件必须显式关闭 / 删除;
- 消费者要 "限流" :设置合理线程数 + 内存阈值,避免单个任务拖垮整个服务。
其实很多 OOM 不是 "代码写错了",而是 "思路没转过来"------ 把 "内存里玩转一切" 的惯性思维,换成 "磁盘 + 流式" 的思路,大部分批量导出的性能问题都能迎刃而解。
编辑分享