一. 引言
大型语言模型已成为各行各业的核心基础设施。从客户服务到内容创作,从代码生成到科学研究,大模型正深度融入企业的核心业务流程。然而,随着模型规模的不断扩大和业务场景的日益复杂,模型运维管理面临着前所未有的挑战。传统的系统监控工具如Zabbix、Prometheus等虽然能监控基础硬件资源,但无法深入理解大模型服务的特殊行为模式,无法感知模型推理的内在质量,更无法预测服务性能的潜在风险。
我们需要一套能够深入理解模型行为、实时感知服务状态、智能预警潜在风险的全方位健康度监测体系。这种体系不仅要能回答系统是否在运行这样的基础问题,更要能回答模型服务是否健康、性能是否最优、用户体验是否良好等深层次问题。今天我们将以模型健康度监测系统为例,深度剖析现代大模型运维平台的设计理念、技术实现与创新亮点。通过详细的流程分析、架构解读和实践场景说明,为构建智能化的模型运维体系提供完整的实践参考和技术路线图。
二、系统设计理念
1. 设计理念
-
- 前后端分离:前端使用HTML/CSS/JavaScript构建用户界面,后端使用Flask提供RESTful API。
-
- 后端负责数据采集、处理、存储和提供API接口。
-
- 前端通过调用后端API获取数据,并动态更新界面。
-
- 采用异步数据加载,避免页面刷新,提升用户体验。
2. 数据交互
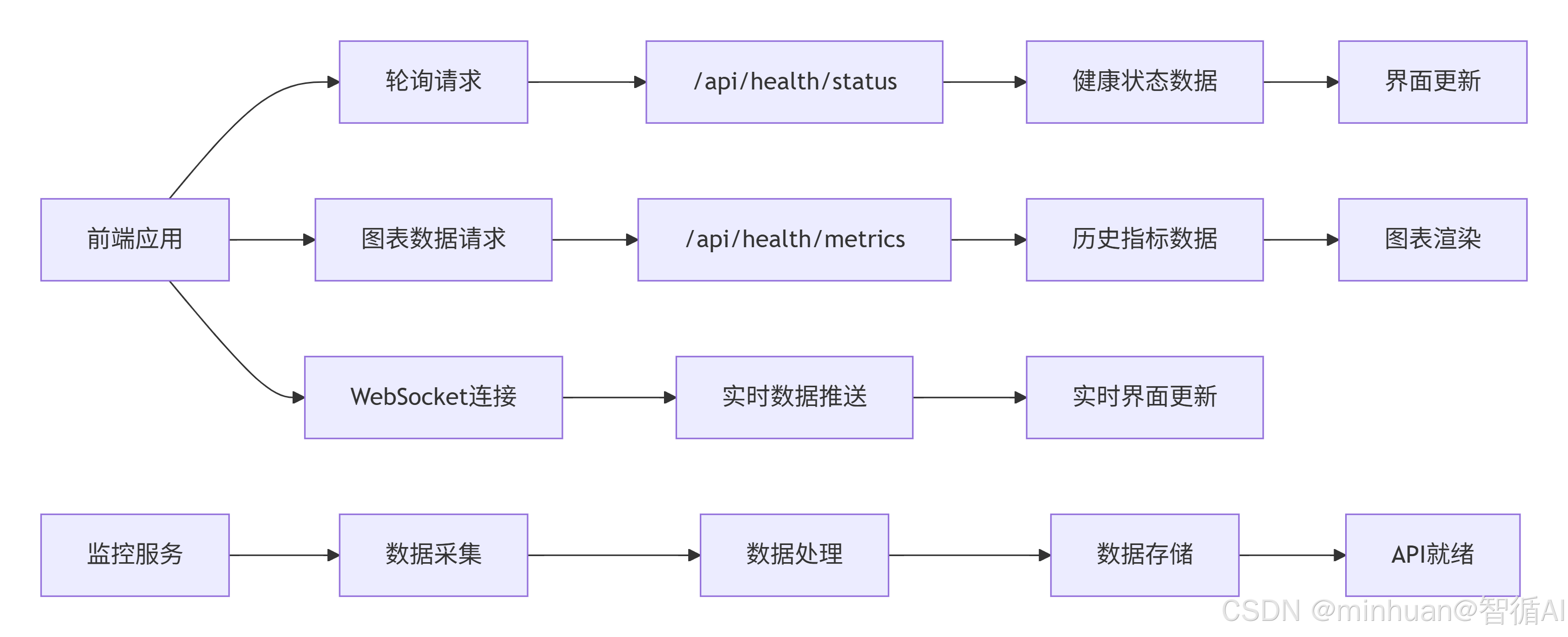
- 前端通过HTTP GET/POST请求与后端交互。
- 数据格式使用JSON。
3. API接口设计
- 健康状态:GET /api/health/status
- 指标历史数据:GET /api/health/metrics
- 启动监控:GET /api/health/start
- 停止监控:GET /api/health/stop
- 模型信息:GET /api/model/info
- 生成文本:POST /api/model/generate
- 重启监控:POST /api/system/restart
- 推理分析:GET /api/analysis/inference
- 吞吐量分析:GET /api/analysis/throughput
- 请求分析:GET /api/analysis/requests
- 生成分析:GET /api/analysis/generation
4. 前端设计
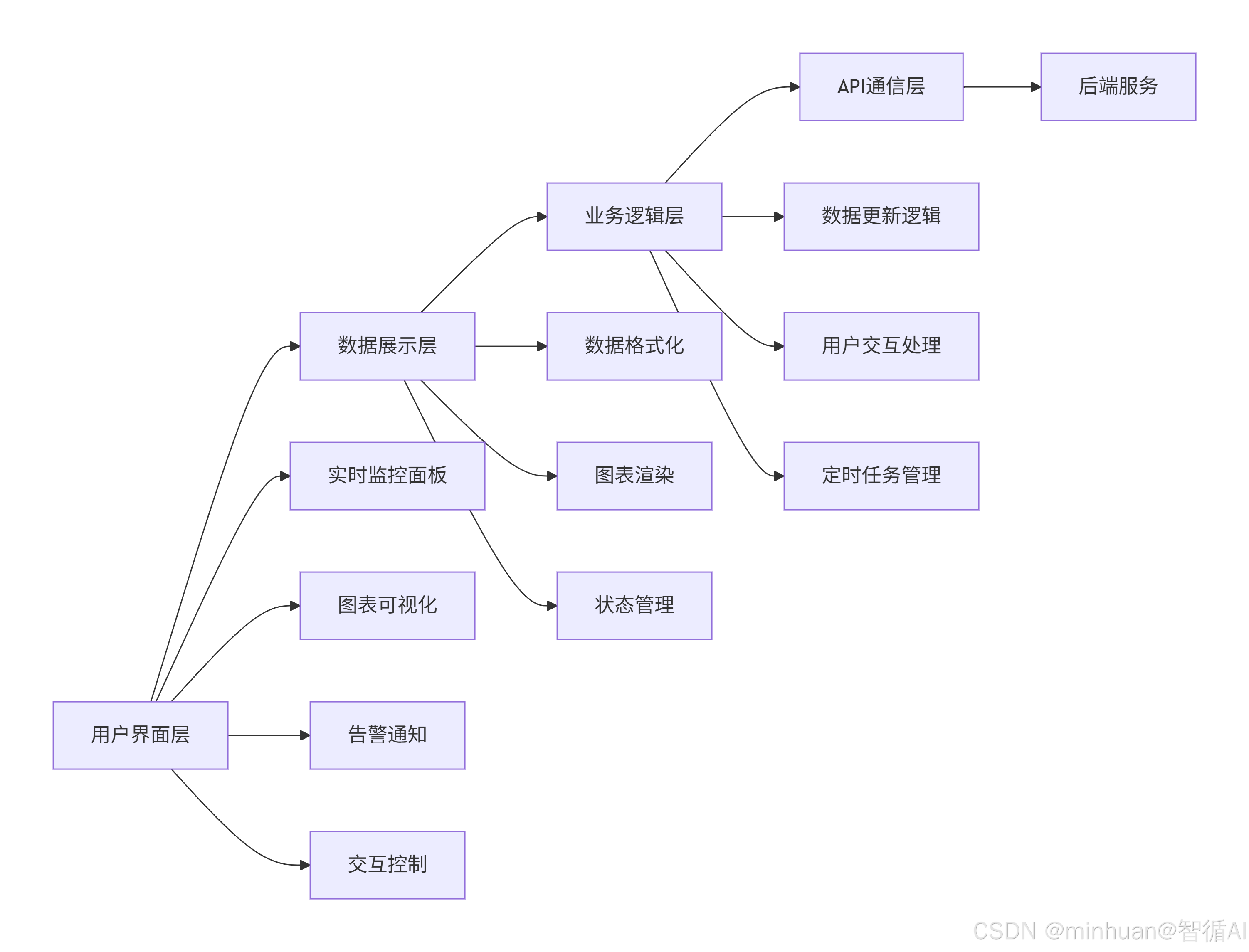
4.1 设计理念
- 单页面应用(SPA)或多页面应用,根据复杂度选择。这里我们可以设计一个单页面应用,通过不同的导航显示不同部分。
- 使用图表库(如Chart.js、ECharts等)来可视化数据。
- 实时更新:通过定时器定期调用API更新数据。
4.2 页面结构
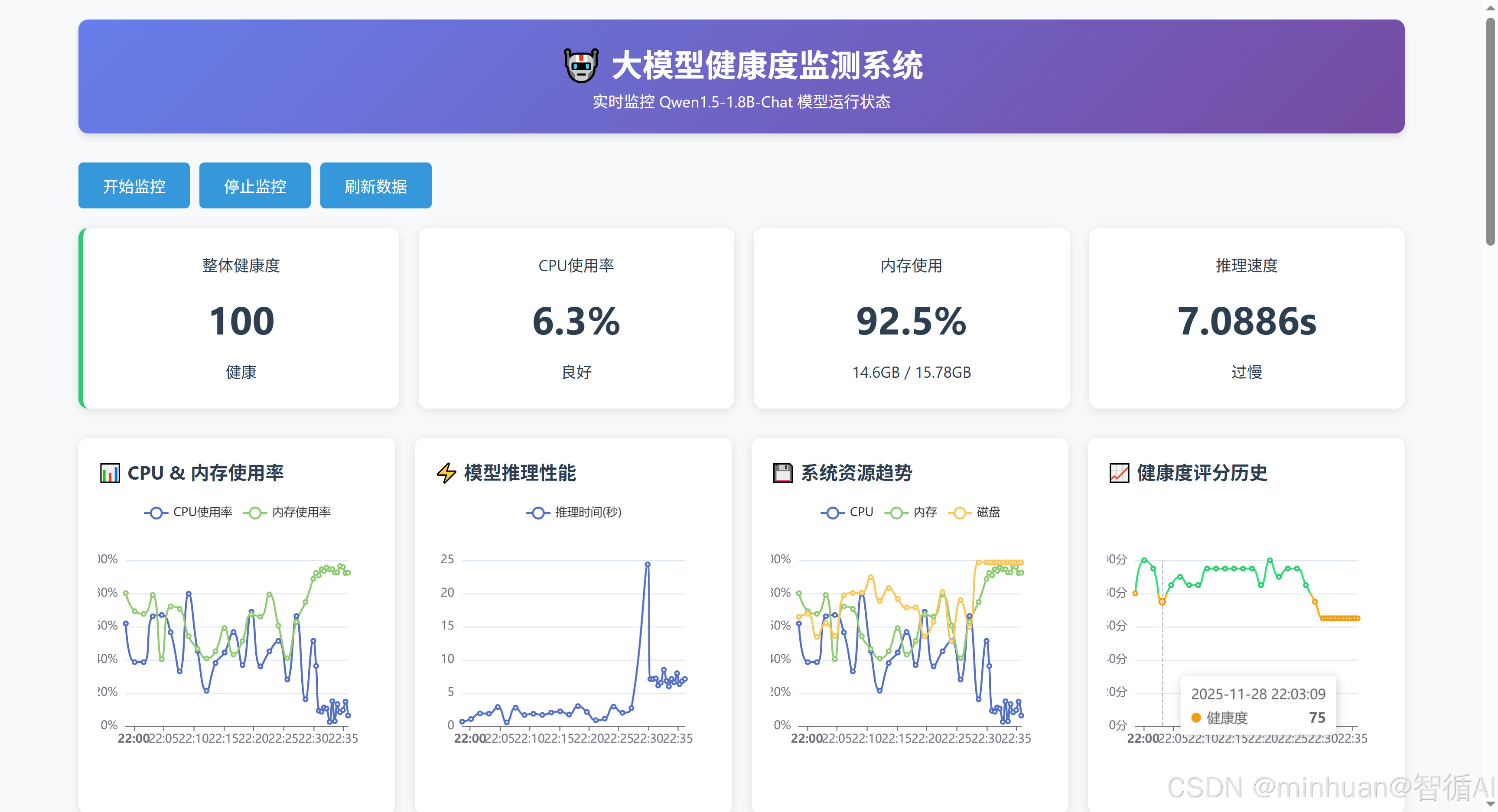
- 系统概览:显示当前健康状态、性能评分、服务运行时间、活跃告警等。
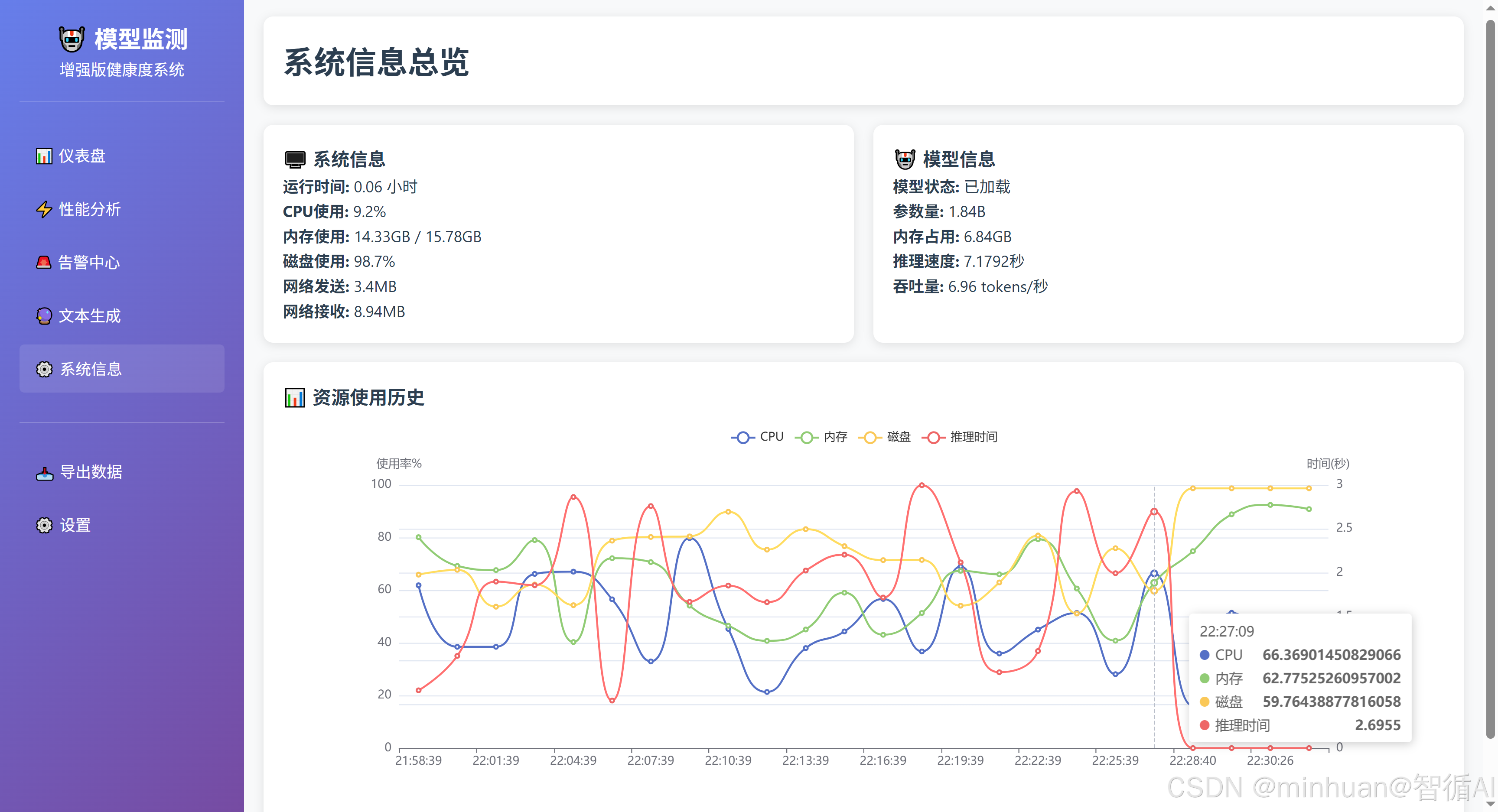
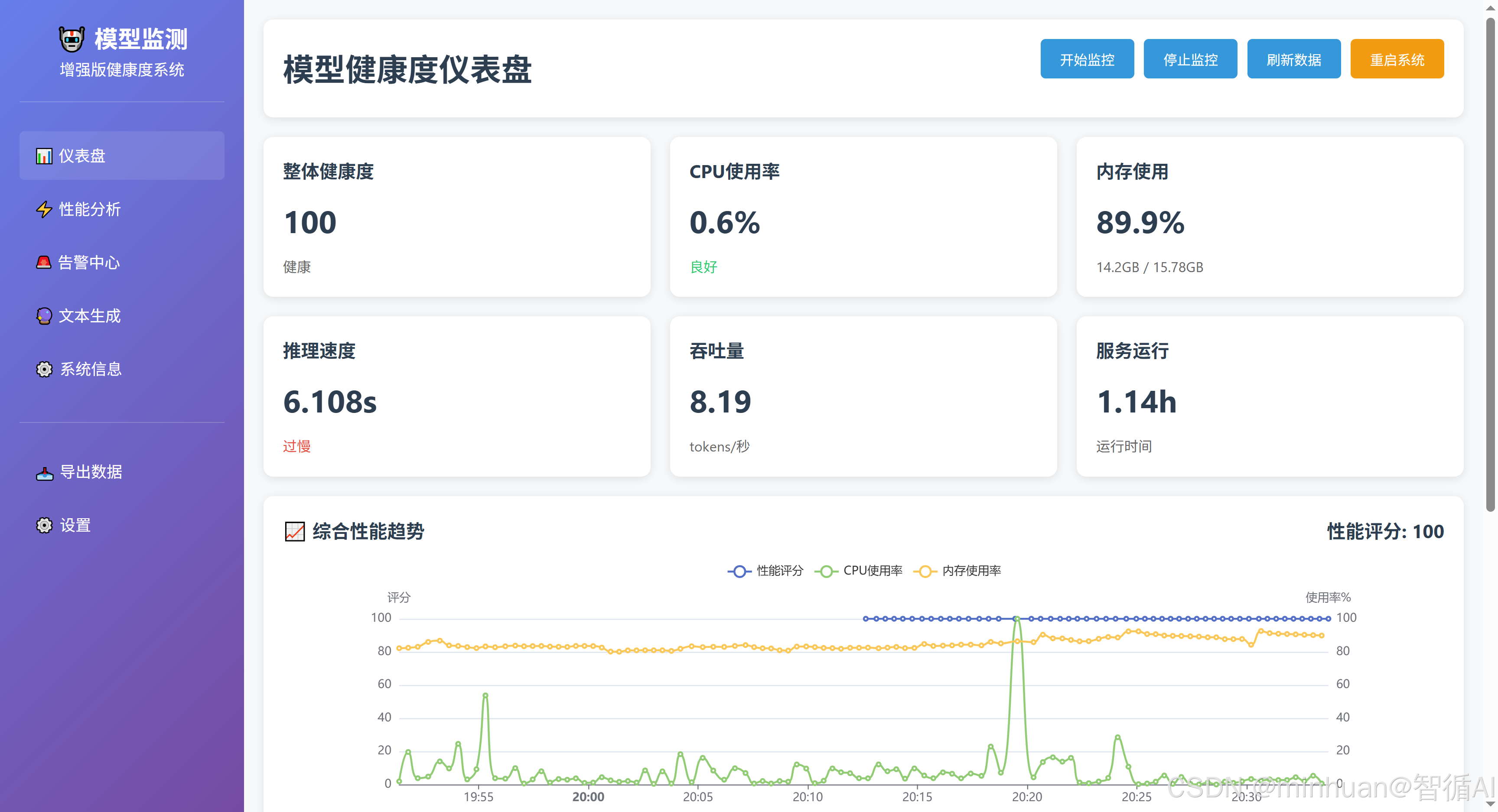
- 系统监控:显示CPU、内存、磁盘、网络等系统指标图表。
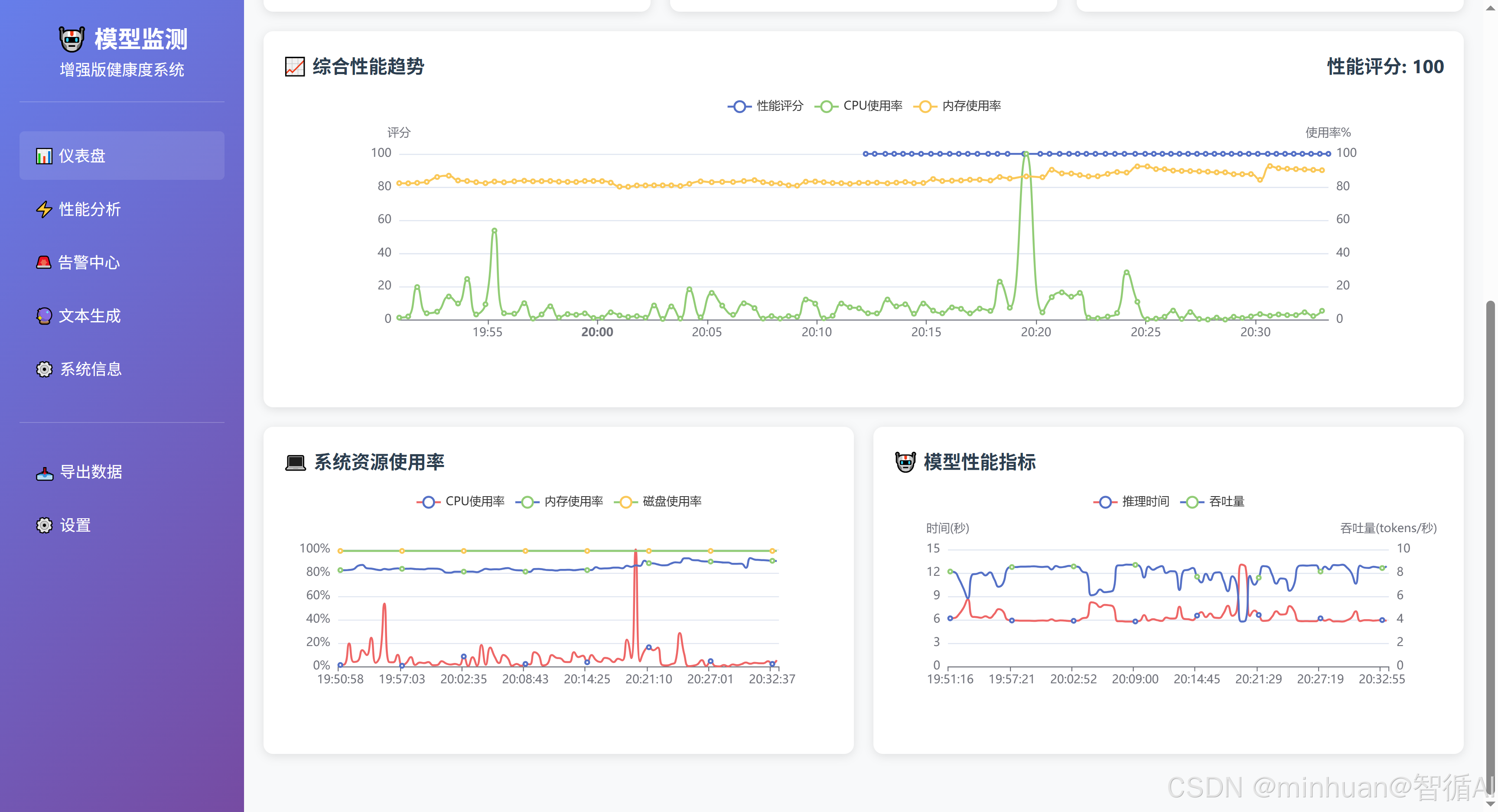
- 模型监控:显示模型推理速度、内存占用、吞吐量等图表。
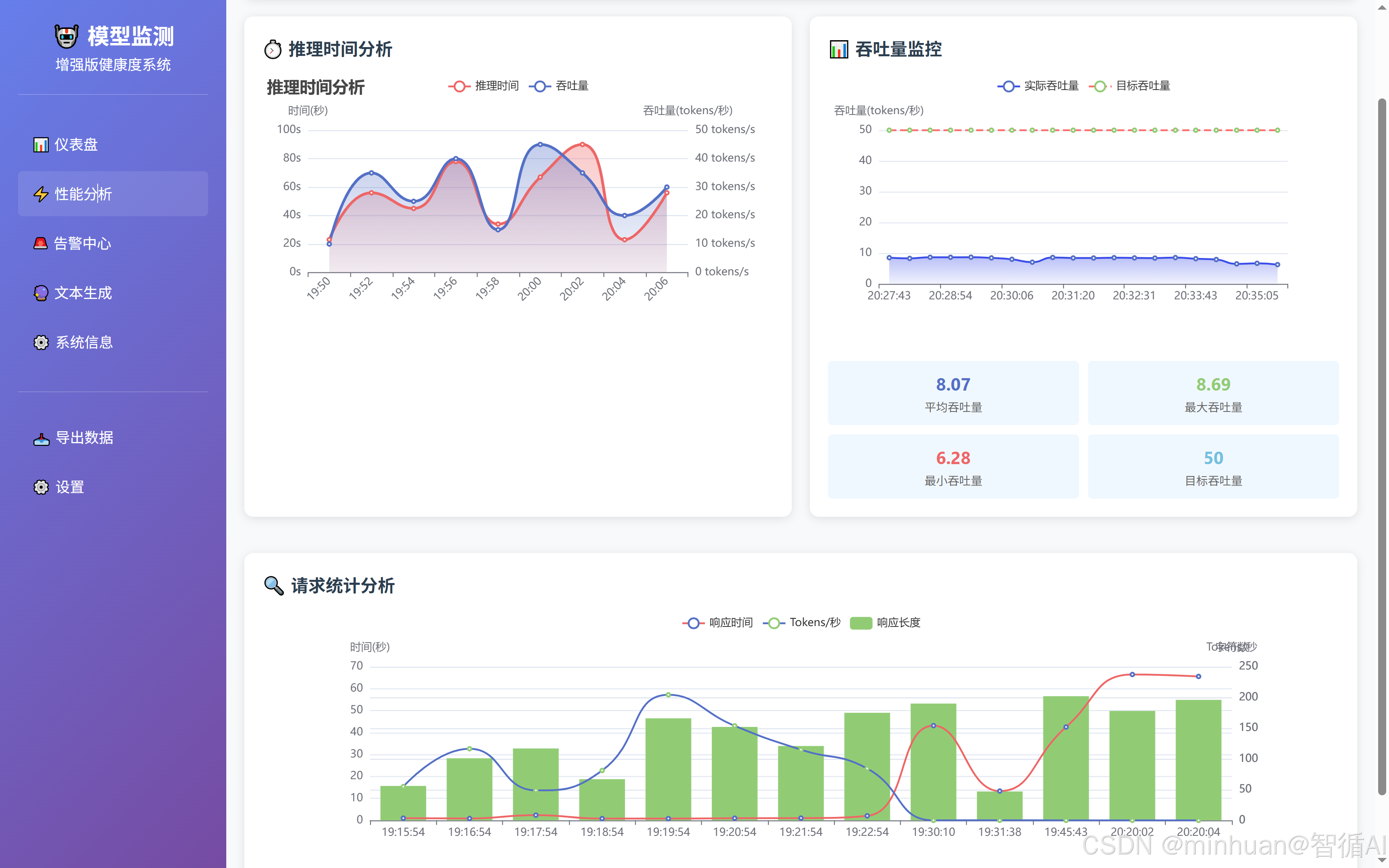
- 性能分析:显示性能评分趋势、请求统计、生成统计等。
- 告警信息:显示当前的告警列表。

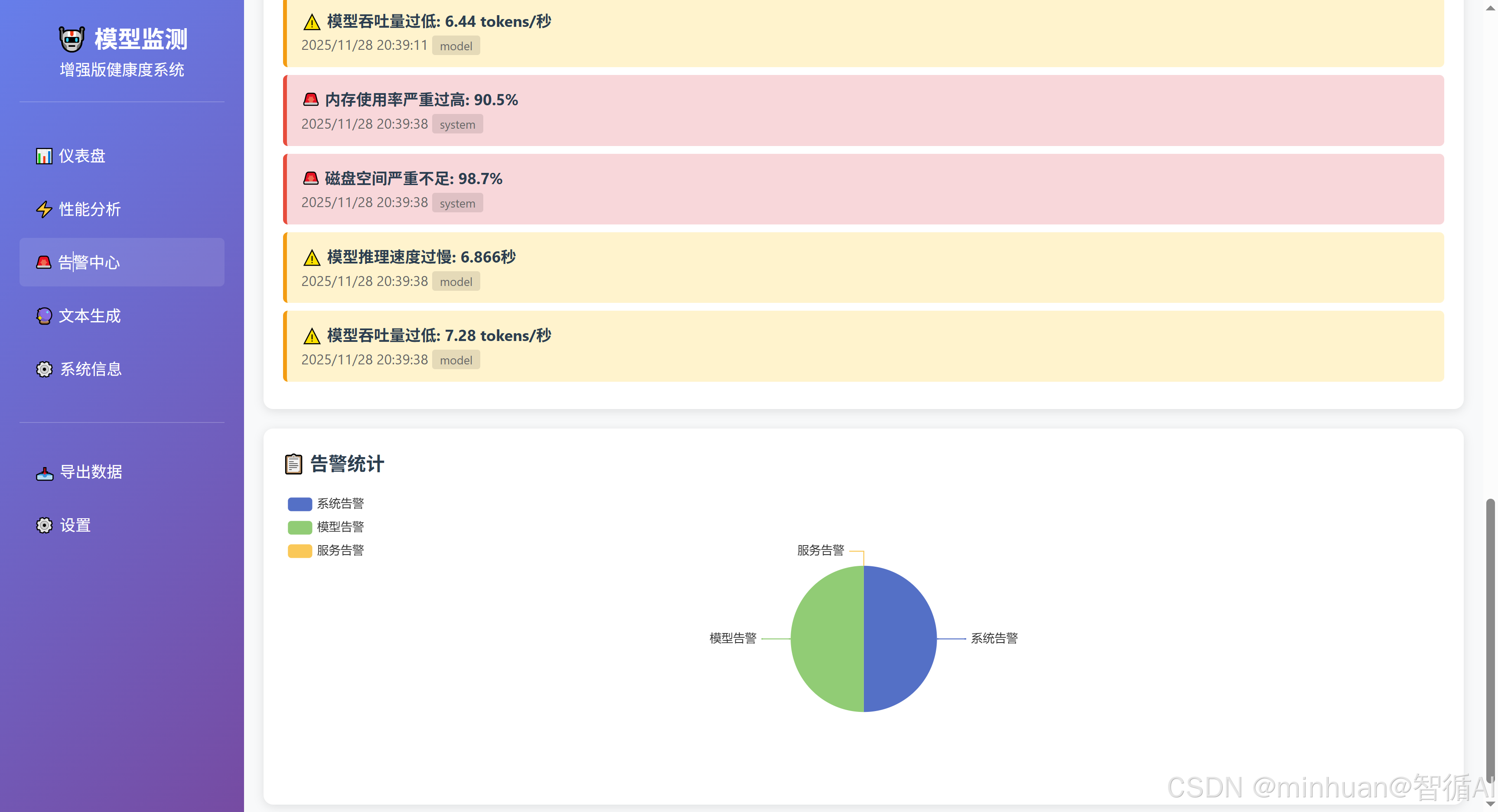
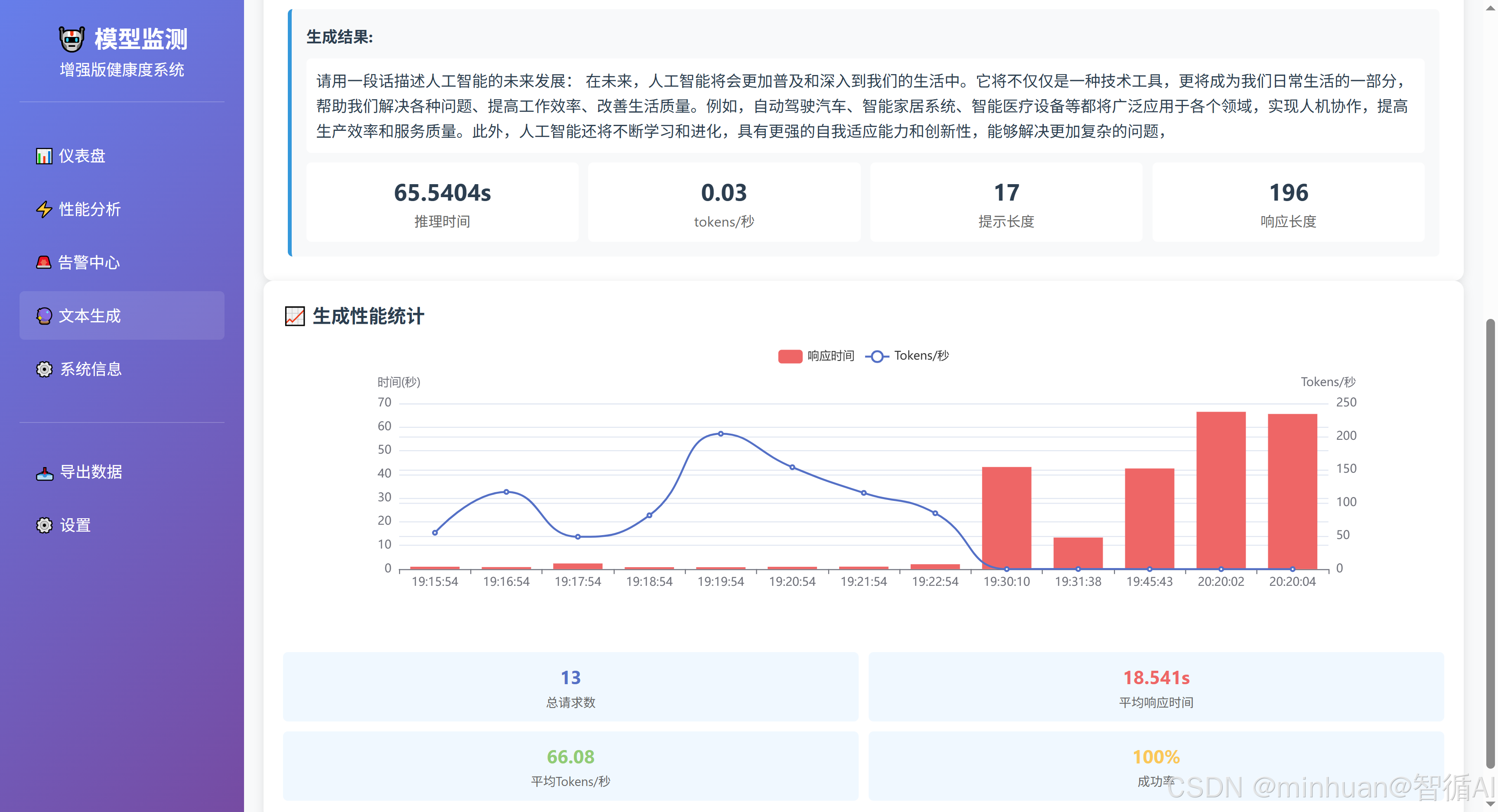
- 模型交互:提供文本生成界面。
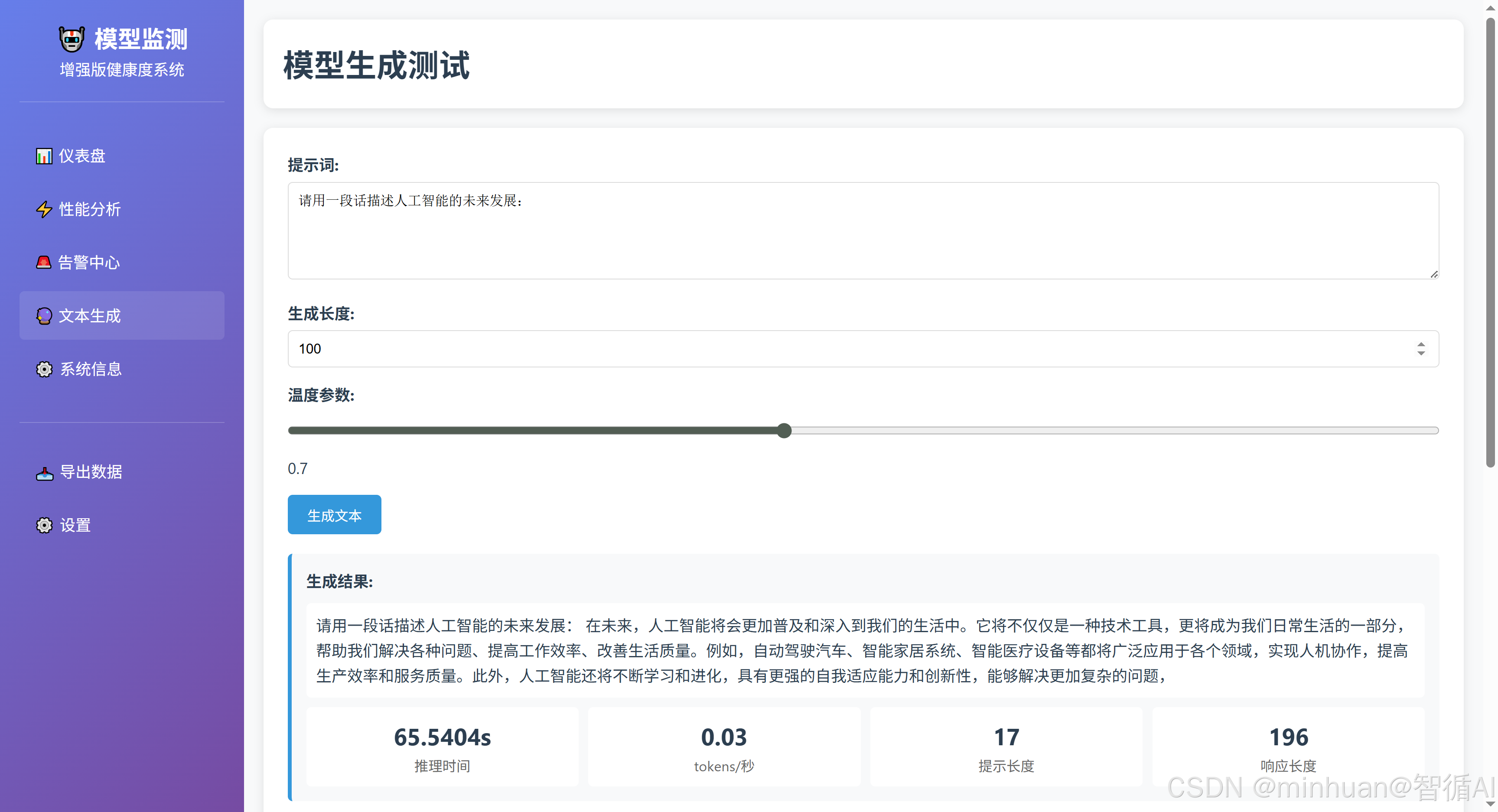
4.3 数据交互流程
-
- 页面加载时,前端调用健康状态接口和模型信息接口,显示基本状态。
-
- 然后,前端调用指标历史数据接口,绘制历史趋势图。
-
- 前端启动定时器,定期调用健康状态和指标接口更新数据。
-
- 当用户点击生成文本时,前端将提示文本和参数通过POST请求发送到后端,并显示生成结果。
5. 后端设计
5.1 设计理念
- 使用Flask提供RESTful API。
- 使用CORS支持跨域请求(因为前端可能运行在不同端口)。
- 使用多线程进行后台监控,确保监控不影响API响应。
- 使用内存存储监控数据(使用deque限制内存使用),在生产环境中可考虑持久化存储。
5.2 数据流
- 监控线程定期收集系统指标和模型指标,计算性能评分,检查告警,并更新deque。
- API端点从deque中获取最新数据或历史数据返回给前端。
5.3 安全性考虑
- 在实际生产环境中,需要增加身份验证和授权。
- 对输入进行验证,防止注入攻击。
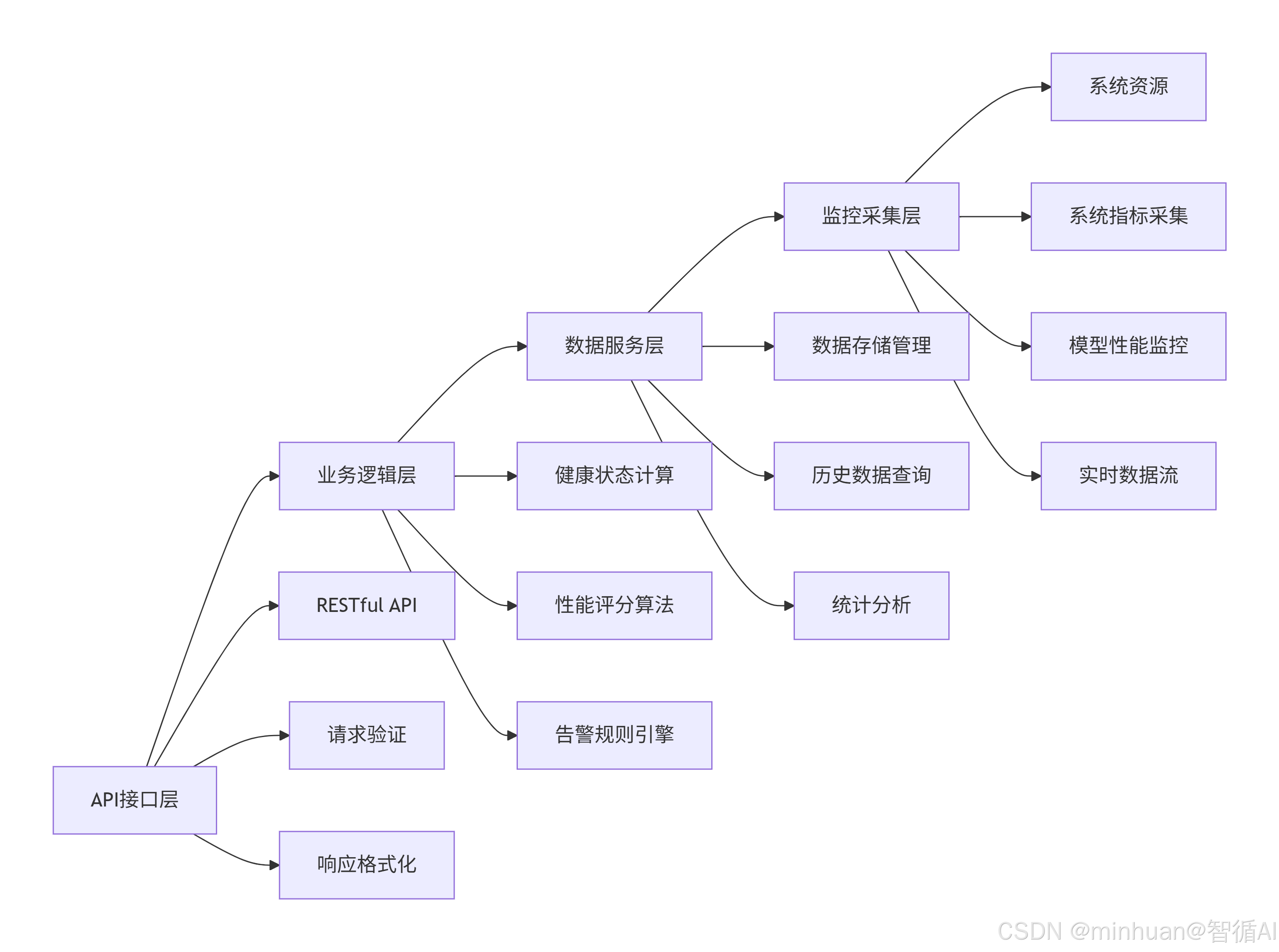
三、系统架构设计
1. 多层次监控体系
系统构建我们采用了四层级的立体化监控架构,每一层都针对大模型服务的特定维度进行深度监控:
- 系统资源层:基础硬件资源监控(CPU、内存、磁盘、网络),确保运行环境稳定
- 模型运行层:模型加载状态、推理性能、内存占用,保障模型服务能力
- 服务性能层:请求处理、响应时间、吞吐量统计,优化用户体验
- 业务质量层:生成质量、用户交互体验,提升服务价值
这种分层设计使得系统能够从不同维度全面把握服务状态,当出现问题时可以快速定位到具体层级,大大缩短故障诊断时间。
代码设计参考:
python
class EnhancedModelHealthMonitor:
"""增强版模型健康度监测器的核心架构"""
health_metrics = {
"system_metrics": deque(maxlen=100), # 系统指标 - 硬件资源状态
"model_metrics": deque(maxlen=100), # 模型指标 - 推理性能状态
"performance_metrics": deque(maxlen=50), # 性能指标 - 服务质量状态
"alerts": deque(maxlen=20), # 告警信息 - 风险预警状态
"generation_stats": deque(maxlen=50) # 生成统计 - 业务质量状态
}2. 数据流设计
系统采用生产者-消费者模式,监控线程作为生产者持续收集各类指标数据,API服务线程作为消费者提供实时查询接口,同时前端展示层作为最终用户界面呈现可视化数据。这种设计形成了完整的数据闭环:

3. 多维数据分析接口
系统提供丰富的分析端点,支持时间序列分析和性能对比分析,满足不同角色的监控需求:
- /api/analysis/inference - 推理时间趋势分析,帮助开发人员识别性能回归
- /api/analysis/throughput - 吞吐量统计分析,为运维团队提供容量规划依据
- /api/analysis/requests - 请求模式分析,帮助产品团队理解用户行为
- /api/analysis/generation - 生成质量分析,为算法团队优化模型提供反馈
四、系统流程设计
1. 启动与初始化流程
系统启动时执行分层初始化策略,确保各组件有序启动:
- 模型加载阶段:使用modelscope下载并初始化Qwen大模型,包括tokenizer和model的加载
- 数据预热阶段:生成样本数据确保系统立即可用,避免空数据状态
- 监控启动阶段:启动后台监控线程,开始持续数据采集
2. 实时监控循环
监控线程以5秒为间隔执行全量指标采集,确保数据的实时性和连续性:
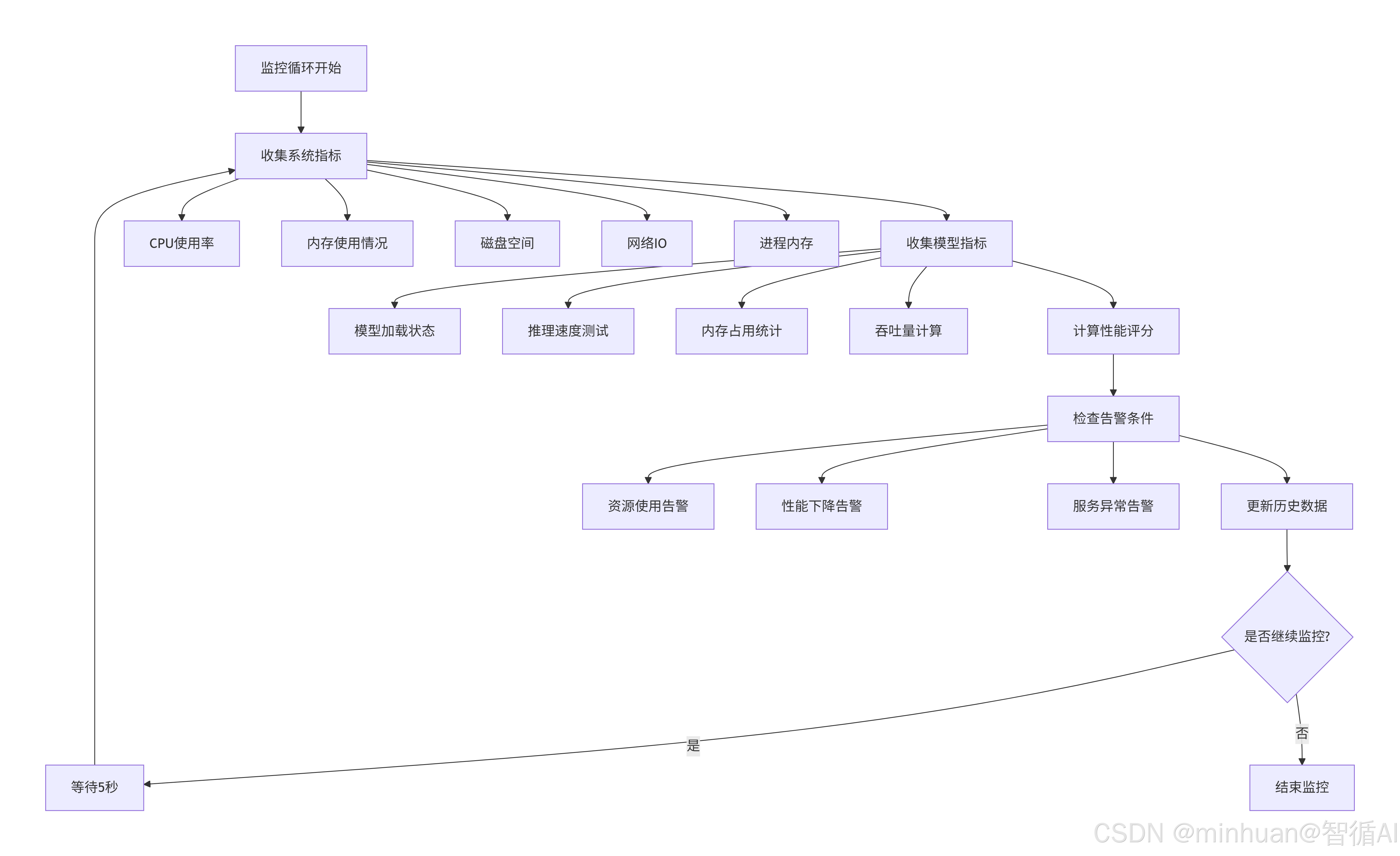
这个监控循环的设计体现了几个重要原则:
- 非阻塞设计:监控线程独立运行,不影响主服务性能
- 容错处理:单个指标采集失败不会影响其他指标
- 数据连续性:固定间隔采集确保时间序列数据的完整性
- 资源控制:历史数据长度限制防止内存无限增长
3. 请求处理流程
当收到生成请求时,系统执行原子化操作链,确保每个请求都被完整追踪:
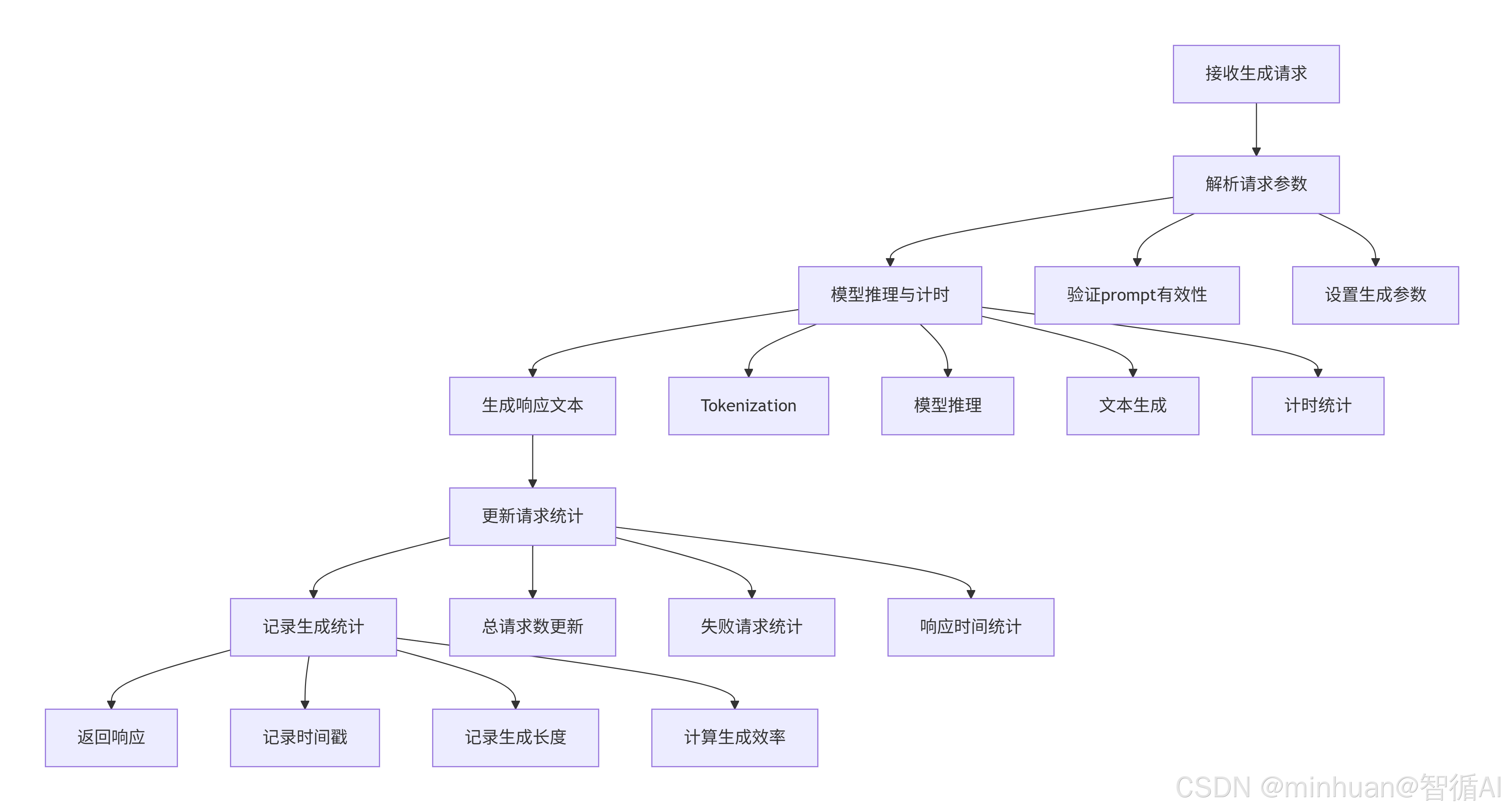
这个请求处理流程的核心在于:
- 全链路追踪:从请求接收到响应返回的每个环节都有数据记录
- 性能监控:精确测量推理时间,为性能优化提供依据
- 统计更新:实时更新服务指标,反映当前负载状态
- 错误隔离:单个请求失败不影响整体服务稳定性
五、核心技术点
1. 智能性能评分算法
系统创新性地引入了多维加权评分机制,将抽象复杂的服务状态量化为直观易懂的性能分数。这个评分算法不是简单的加权平均,而是基于大模型服务的实际运行特性精心设计的:
python
def calculate_performance_score(self, system_metrics, model_metrics):
"""智能性能评分算法 - 基于大模型服务特性的专业评分体系"""
score = 100 # 基准分数
# CPU性能 (权重: 25%) - 考虑到大模型推理对CPU计算资源的敏感度
cpu_score = max(0, 100 - system_metrics["cpu_usage"])
score += cpu_score * 0.25
# 内存性能 (权重: 25%) - 大模型对内存带宽和容量要求极高
memory_score = max(0, 100 - system_metrics["memory_usage"])
score += memory_score * 0.25
# 推理性能 (权重: 30%) - 核心业务指标,直接影响用户体验
if model_metrics["inference_speed"] > 0:
# 推理时间超过3秒将显著影响用户体验
inference_score = max(0, 100 - (model_metrics["inference_speed"] * 20))
score += inference_score * 0.30
else:
score += 30 # 默认分数,确保系统在模型未加载时仍有基本评分
# 吞吐量性能 (权重: 20%) - 反映系统整体处理能力
throughput = model_metrics.get("throughput_tokens_per_sec", 0)
throughput_score = min(100, throughput * 2) # 假设50 tokens/秒为满分
score += throughput_score * 0.20
return max(0, min(100, score)) # 确保分数在合理范围内这个评分算法的优势在于它不仅仅反映当前状态,还能够通过权重分配体现不同指标对用户体验的影响程度,为运维决策提供量化依据。
2. 动态基准线告警系统
不同于传统的静态阈值告警,该系统实现了基于历史数据的动态基准线机制。系统会持续学习服务的正常行为模式,建立个性化的性能基准:
- 推理速度基线:1.0秒(基于历史平均性能)
- 内存使用基线:70%(基于资源使用模式)
- CPU使用基线:60%(基于计算负载特征)
当指标持续偏离基准线时,系统会生成分级告警,包括warning和critical两个级别,实现预测性运维。这种动态基准线的优势在于能够适应不同硬件环境和服务负载,避免了一刀切的静态阈值带来的误报和漏报问题。
六、总结
系统初步实现了对模型健康监测的服务运维监控体系,基于Flask框架确保API服务的稳定性,多线程监控保证数据实时性,内存队列存储控制资源消耗,整体方案技术风险可控,部署维护成本合理。
为了提升系统的健壮性,还需引入时序数据库存储历史数据,支持更长周期分析,增加模型输出质量评估指标,如相关性、流畅度等,进一步优化前端数据可视化,提供更直观的监控看板
附录一:代码示例参考
python
# enhanced_model_health_monitor.py
from flask import Flask, jsonify, render_template, request
from flask_cors import CORS
import psutil
import time
import json
import threading
from datetime import datetime, timedelta
import numpy as np
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
import logging
from collections import deque
import os
import random
from modelscope import snapshot_download
# 配置日志
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
app = Flask(__name__)
CORS(app)
class EnhancedModelHealthMonitor:
"""增强版模型健康度监测器"""
def __init__(self, model_name="qwen/Qwen1.5-1.8B-Chat"):
self.model_name = model_name
self.health_metrics = {
"system_metrics": deque(maxlen=100),
"model_metrics": deque(maxlen=100),
"performance_metrics": deque(maxlen=50),
"alerts": deque(maxlen=20),
"generation_stats": deque(maxlen=50)
}
self.is_monitoring = False
self.monitor_thread = None
self.start_time = datetime.now()
# 请求统计
self.request_stats = {
"total_requests": 0,
"failed_requests": 0,
"avg_response_time": 0,
"requests_per_minute": 0
}
# 性能基准
self.performance_baseline = {
"inference_time": 1.0, # 秒
"memory_usage": 70, # %
"cpu_usage": 60 # %
}
# 加载模型
self.load_model()
# 生成样本数据(仅用于演示)
self.generate_sample_data()
def load_model(self):
"""加载模型"""
try:
logger.info(f"正在加载模型: {self.model_name}")
model_path = snapshot_download("qwen/Qwen1.5-1.8B-Chat", cache_dir="D:\\modelscope\\hub")
self.tokenizer = AutoTokenizer.from_pretrained(
model_path,
trust_remote_code=True
)
if self.tokenizer.pad_token is None:
self.tokenizer.pad_token = self.tokenizer.eos_token
self.model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.float32,
device_map="auto",
trust_remote_code=True,
low_cpu_mem_usage=True
)
self.model_loaded = True
logger.info("模型加载成功")
# 记录模型信息
self.model_info = {
"name": self.model_name,
"parameters": sum(p.numel() for p in self.model.parameters()),
"loaded_at": datetime.now().isoformat()
}
except Exception as e:
logger.error(f"模型加载失败: {e}")
self.model_loaded = False
self.model_info = {"error": str(e)}
def generate_sample_data(self):
"""生成样本数据用于测试"""
base_time = datetime.now() - timedelta(minutes=30)
# 生成系统指标样本数据
for i in range(20):
timestamp = (base_time + timedelta(minutes=i * 1.5)).isoformat()
self.health_metrics["system_metrics"].append({
"timestamp": timestamp,
"cpu_usage": random.uniform(20, 80),
"memory_usage": random.uniform(40, 85),
"memory_used_gb": round(random.uniform(2, 8), 2),
"memory_total_gb": 16,
"disk_usage": random.uniform(50, 90),
"network_sent_mb": round(random.uniform(10, 100), 2),
"network_recv_mb": round(random.uniform(50, 200), 2),
"process_memory_mb": round(random.uniform(500, 2000), 2),
"system_uptime_hours": round(random.uniform(1, 100), 2),
"gpu_info": {"gpu_available": False}
})
# 生成模型指标样本数据
for i in range(20):
timestamp = (base_time + timedelta(minutes=i * 1.5)).isoformat()
inference_time = random.uniform(0.5, 3.0)
self.health_metrics["model_metrics"].append({
"timestamp": timestamp,
"model_status": "loaded",
"inference_speed": round(inference_time, 4),
"memory_footprint_gb": round(random.uniform(2, 4), 2),
"throughput_tokens_per_sec": round(50 / inference_time, 2),
"model_parameters_billions": 1.8
})
# 生成性能指标样本数据
for i in range(20):
timestamp = (base_time + timedelta(minutes=i * 1.5)).isoformat()
self.health_metrics["performance_metrics"].append({
"timestamp": timestamp,
"performance_score": random.randint(60, 95),
"request_stats": {
"total_requests": random.randint(50, 200),
"failed_requests": random.randint(0, 5),
"avg_response_time": round(random.uniform(0.8, 2.5), 3),
"requests_per_minute": round(random.uniform(1, 10), 1)
}
})
# 生成生成统计样本数据
base_time = datetime.now() - timedelta(minutes=10)
for i in range(8):
timestamp = (base_time + timedelta(minutes=i)).isoformat()
inference_time = random.uniform(0.5, 2.5)
response_length = random.randint(50, 200)
self.health_metrics["generation_stats"].append({
"timestamp": timestamp,
"prompt_length": random.randint(10, 50),
"response_length": response_length,
"inference_time": round(inference_time, 4),
"tokens_per_second": round(response_length / inference_time, 2)
})
logger.info("样本数据生成完成")
def collect_enhanced_system_metrics(self):
"""收集增强的系统指标"""
# 基础系统指标
cpu_percent = psutil.cpu_percent(interval=1)
memory = psutil.virtual_memory()
disk = psutil.disk_usage('/')
# 网络指标
net_io = psutil.net_io_counters()
# 进程指标
process = psutil.Process()
process_memory = process.memory_info()
# 系统启动时间
boot_time = datetime.fromtimestamp(psutil.boot_time())
uptime = datetime.now() - boot_time
# GPU信息
gpu_info = self.get_gpu_info()
return {
"timestamp": datetime.now().isoformat(),
"cpu_usage": cpu_percent,
"memory_usage": memory.percent,
"memory_used_gb": round(memory.used / (1024 ** 3), 2),
"memory_total_gb": round(memory.total / (1024 ** 3), 2),
"disk_usage": disk.percent,
"network_sent_mb": round(net_io.bytes_sent / (1024 ** 2), 2),
"network_recv_mb": round(net_io.bytes_recv / (1024 ** 2), 2),
"process_memory_mb": round(process_memory.rss / (1024 ** 2), 2),
"system_uptime_hours": round(uptime.total_seconds() / 3600, 2),
"gpu_info": gpu_info
}
def get_gpu_info(self):
"""获取GPU信息"""
# try:
# gpus = GPUtil.getGPUs()
# if gpus:
# gpu = gpus[0]
# return {
# "gpu_available": True,
# "gpu_usage": gpu.load * 100,
# "gpu_memory_used": gpu.memoryUsed,
# "gpu_memory_total": gpu.memoryTotal,
# "gpu_memory_percent": (gpu.memoryUsed / gpu.memoryTotal) * 100,
# "gpu_temperature": gpu.temperature
# }
# except Exception as e:
# logger.warning(f"无法获取GPU信息: {e}")
return {"gpu_available": False}
def collect_enhanced_model_metrics(self):
"""收集增强的模型指标"""
if not self.model_loaded:
return {
"timestamp": datetime.now().isoformat(),
"model_status": "not_loaded",
"inference_speed": 0,
"memory_footprint": 0,
"throughput": 0
}
# 模型内存占用
try:
param_size = sum(p.numel() * p.element_size() for p in self.model.parameters())
buffer_size = sum(b.numel() * b.element_size() for b in self.model.buffers())
memory_footprint = param_size + buffer_size
except:
memory_footprint = 0
# 推理性能测试
inference_time = self.test_inference_speed()
# 计算吞吐量(tokens/秒)
throughput = 50 / inference_time if inference_time > 0 else 0
return {
"timestamp": datetime.now().isoformat(),
"model_status": "loaded",
"inference_speed": round(inference_time, 4),
"memory_footprint_gb": round(memory_footprint / (1024 ** 3), 2),
"throughput_tokens_per_sec": round(throughput, 2),
"model_parameters_billions": round(self.model_info.get("parameters", 0) / 1e9, 2)
}
def test_inference_speed(self):
"""测试推理速度"""
test_prompts = [
"人工智能的未来发展",
"机器学习的基本原理",
"深度学习在自然语言处理中的应用"
]
total_time = 0
successful_tests = 0
for prompt in test_prompts:
try:
start_time = time.time()
inputs = self.tokenizer.encode(prompt, return_tensors="pt")
with torch.no_grad():
_ = self.model.generate(
inputs,
max_length=30,
num_return_sequences=1,
do_sample=False
)
end_time = time.time()
total_time += (end_time - start_time)
successful_tests += 1
except Exception as e:
logger.warning(f"推理测试失败: {e}")
continue
return total_time / successful_tests if successful_tests > 0 else 0
def update_request_stats(self, response_time, success=True):
"""更新请求统计"""
self.request_stats["total_requests"] += 1
if not success:
self.request_stats["failed_requests"] += 1
# 更新平均响应时间(移动平均)
old_avg = self.request_stats["avg_response_time"]
count = self.request_stats["total_requests"]
self.request_stats["avg_response_time"] = (
old_avg * (count - 1) + response_time
) / count if count > 0 else response_time
def calculate_performance_score(self, system_metrics, model_metrics):
"""计算性能评分"""
score = 100
# CPU性能 (权重: 25%)
cpu_score = max(0, 100 - system_metrics["cpu_usage"])
score += cpu_score * 0.25
# 内存性能 (权重: 25%)
memory_score = max(0, 100 - system_metrics["memory_usage"])
score += memory_score * 0.25
# 推理性能 (权重: 30%)
if model_metrics["inference_speed"] > 0:
inference_score = max(0, 100 - (model_metrics["inference_speed"] * 20))
score += inference_score * 0.30
else:
score += 30 # 默认分数
# 吞吐量性能 (权重: 20%)
throughput = model_metrics.get("throughput_tokens_per_sec", 0)
throughput_score = min(100, throughput * 2) # 假设50 tokens/秒为满分
score += throughput_score * 0.20
return max(0, min(100, score))
def check_enhanced_alerts(self, system_metrics, model_metrics):
"""检查增强的告警"""
alerts = []
# 系统资源告警
if system_metrics["cpu_usage"] > 85:
alerts.append({
"level": "warning",
"type": "system",
"message": f"CPU使用率过高: {system_metrics['cpu_usage']}%",
"timestamp": datetime.now().isoformat()
})
if system_metrics["memory_usage"] > 90:
alerts.append({
"level": "critical",
"type": "system",
"message": f"内存使用率严重过高: {system_metrics['memory_usage']}%",
"timestamp": datetime.now().isoformat()
})
if system_metrics["disk_usage"] > 95:
alerts.append({
"level": "critical",
"type": "system",
"message": f"磁盘空间严重不足: {system_metrics['disk_usage']}%",
"timestamp": datetime.now().isoformat()
})
# 模型性能告警
if model_metrics["inference_speed"] > 3.0:
alerts.append({
"level": "warning",
"type": "model",
"message": f"模型推理速度过慢: {model_metrics['inference_speed']}秒",
"timestamp": datetime.now().isoformat()
})
if model_metrics.get("throughput_tokens_per_sec", 0) < 10:
alerts.append({
"level": "warning",
"type": "model",
"message": f"模型吞吐量过低: {model_metrics.get('throughput_tokens_per_sec', 0)} tokens/秒",
"timestamp": datetime.now().isoformat()
})
# 请求成功率告警
total_requests = self.request_stats["total_requests"]
if total_requests > 10:
failure_rate = (self.request_stats["failed_requests"] / total_requests) * 100
if failure_rate > 10:
alerts.append({
"level": "warning",
"type": "service",
"message": f"请求失败率过高: {failure_rate:.1f}%",
"timestamp": datetime.now().isoformat()
})
return alerts
def monitoring_loop(self):
"""监控循环"""
while self.is_monitoring:
try:
# 收集指标
system_metrics = self.collect_enhanced_system_metrics()
model_metrics = self.collect_enhanced_model_metrics()
# 计算性能评分
performance_score = self.calculate_performance_score(system_metrics, model_metrics)
performance_metrics = {
"timestamp": datetime.now().isoformat(),
"performance_score": performance_score,
"request_stats": self.request_stats.copy()
}
# 检查告警
alerts = self.check_enhanced_alerts(system_metrics, model_metrics)
# 更新指标历史
self.health_metrics["system_metrics"].append(system_metrics)
self.health_metrics["model_metrics"].append(model_metrics)
self.health_metrics["performance_metrics"].append(performance_metrics)
for alert in alerts:
self.health_metrics["alerts"].append(alert)
except Exception as e:
logger.error(f"监控收集错误: {e}")
time.sleep(5) # 5秒间隔
def start_monitoring(self):
"""开始监控"""
if not self.is_monitoring:
self.is_monitoring = True
self.monitor_thread = threading.Thread(target=self.monitoring_loop)
self.monitor_thread.daemon = True
self.monitor_thread.start()
logger.info("增强版模型健康度监控已启动")
def stop_monitoring(self):
"""停止监控"""
self.is_monitoring = False
if self.monitor_thread:
self.monitor_thread.join(timeout=10)
logger.info("增强版模型健康度监控已停止")
def get_enhanced_health_status(self):
"""获取增强的健康状态"""
if not self.health_metrics["system_metrics"]:
return {"status": "no_data"}
latest_system = self.health_metrics["system_metrics"][-1]
latest_model = self.health_metrics["model_metrics"][-1]
latest_performance = self.health_metrics["performance_metrics"][-1] if self.health_metrics["performance_metrics"] else {"performance_score": 0}
# 确定状态等级
performance_score = latest_performance["performance_score"]
if performance_score >= 80:
status = "healthy"
elif performance_score >= 60:
status = "warning"
else:
status = "critical"
# 计算服务运行时间
service_uptime = datetime.now() - self.start_time
uptime_hours = round(service_uptime.total_seconds() / 3600, 2)
return {
"status": status,
"performance_score": performance_score,
"service_uptime_hours": uptime_hours,
"model_loaded": self.model_loaded,
"model_info": self.model_info,
"latest_system": latest_system,
"latest_model": latest_model,
"request_stats": self.request_stats,
"active_alerts": len([a for a in list(self.health_metrics["alerts"])[-10:]
if a["level"] in ["warning", "critical"]])
}
# 新增的分析数据方法
def get_inference_analysis_data(self):
"""获取推理时间分析数据"""
if not self.health_metrics["model_metrics"]:
return {"timestamps": [], "inference_times": [], "throughputs": []}
model_metrics = list(self.health_metrics["model_metrics"])
timestamps = []
inference_times = []
throughputs = []
for metric in model_metrics[-20:]: # 取最近20个数据点
timestamps.append(metric["timestamp"])
inference_times.append(metric["inference_speed"])
throughputs.append(metric.get("throughput_tokens_per_sec", 0))
return {
"timestamps": timestamps,
"inference_times": inference_times,
"throughputs": throughputs
}
def get_throughput_analysis_data(self):
"""获取吞吐量分析数据"""
if not self.health_metrics["model_metrics"]:
return {"timestamps": [], "throughputs": [], "target_throughput": 50}
model_metrics = list(self.health_metrics["model_metrics"])
timestamps = []
throughputs = []
for metric in model_metrics[-20:]:
timestamps.append(metric["timestamp"])
throughputs.append(metric.get("throughput_tokens_per_sec", 0))
# 计算吞吐量统计
if throughputs:
avg_throughput = sum(throughputs) / len(throughputs)
max_throughput = max(throughputs)
min_throughput = min(throughputs)
else:
avg_throughput = max_throughput = min_throughput = 0
return {
"timestamps": timestamps,
"throughputs": throughputs,
"statistics": {
"average": round(avg_throughput, 2),
"maximum": round(max_throughput, 2),
"minimum": round(min_throughput, 2),
"target": 50 # 目标吞吐量
}
}
def get_request_analysis_data(self):
"""获取请求分析数据"""
# 从生成统计中获取请求数据
generation_stats = list(self.health_metrics["generation_stats"])
if not generation_stats:
return {
"timestamps": [],
"response_times": [],
"tokens_per_second": [],
"request_lengths": []
}
timestamps = []
response_times = []
tokens_per_second = []
request_lengths = []
for stat in generation_stats[-15:]: # 取最近15个生成请求
timestamps.append(stat["timestamp"])
response_times.append(stat["inference_time"])
tokens_per_second.append(stat["tokens_per_second"])
request_lengths.append(stat["response_length"])
return {
"timestamps": timestamps,
"response_times": response_times,
"tokens_per_second": tokens_per_second,
"request_lengths": request_lengths
}
def get_generation_stats_data(self):
"""获取生成统计数据分析"""
generation_stats = list(self.health_metrics["generation_stats"])
if not generation_stats:
return {
"timestamps": [],
"performance_data": [],
"statistics": {
"total_requests": 0,
"avg_response_time": 0,
"avg_tokens_per_sec": 0,
"success_rate": 100
}
}
timestamps = []
response_times = []
tokens_per_second = []
for stat in generation_stats:
timestamps.append(stat["timestamp"])
response_times.append(stat["inference_time"])
tokens_per_second.append(stat["tokens_per_second"])
# 计算统计信息
total_requests = len(generation_stats)
avg_response_time = sum(response_times) / len(response_times) if response_times else 0
avg_tokens_per_sec = sum(tokens_per_second) / len(tokens_per_second) if tokens_per_second else 0
return {
"timestamps": timestamps,
"performance_data": list(zip(timestamps, response_times, tokens_per_second)),
"statistics": {
"total_requests": total_requests,
"avg_response_time": round(avg_response_time, 3),
"avg_tokens_per_sec": round(avg_tokens_per_sec, 2),
"success_rate": 100 # 简化处理,假设都是成功的
}
}
# 创建监控实例
monitor = EnhancedModelHealthMonitor()
# API路由
@app.route('/')
def index():
return render_template('enhanced_index.html')
@app.route('/api/health/status')
def get_health_status():
"""获取当前健康状态"""
status = monitor.get_enhanced_health_status()
return jsonify(status)
@app.route('/api/health/metrics')
def get_health_metrics():
"""获取健康指标历史"""
# 转换为列表返回
recent_data = {
"system_metrics": list(monitor.health_metrics["system_metrics"]),
"model_metrics": list(monitor.health_metrics["model_metrics"]),
"performance_metrics": list(monitor.health_metrics["performance_metrics"]),
"alerts": list(monitor.health_metrics["alerts"]),
"generation_stats": list(monitor.health_metrics["generation_stats"])
}
return jsonify(recent_data)
@app.route('/api/health/start')
def start_health_monitor():
"""启动健康监控"""
monitor.start_monitoring()
return jsonify({"message": "健康监控已启动"})
@app.route('/api/health/stop')
def stop_health_monitor():
"""停止健康监控"""
monitor.stop_monitoring()
return jsonify({"message": "健康监控已停止"})
@app.route('/api/model/info')
def get_model_info():
"""获取模型信息"""
return jsonify({
"model_info": monitor.model_info,
"model_loaded": monitor.model_loaded
})
@app.route('/api/model/generate', methods=['POST'])
def generate_text():
"""模型生成文本API"""
data = request.json
prompt = data.get('prompt', '')
max_length = data.get('max_length', 100)
temperature = data.get('temperature', 0.7)
if not monitor.model_loaded:
return jsonify({"error": "模型未加载"}), 500
start_time = time.time()
try:
inputs = monitor.tokenizer.encode(prompt, return_tensors="pt")
with torch.no_grad():
outputs = monitor.model.generate(
inputs,
max_length=max_length,
temperature=temperature,
do_sample=True,
pad_token_id=monitor.tokenizer.eos_token_id,
num_return_sequences=1
)
generated_text = monitor.tokenizer.decode(outputs[0], skip_special_tokens=True)
inference_time = time.time() - start_time
# 更新请求统计
monitor.update_request_stats(inference_time, success=True)
# 记录生成统计
generation_stat = {
"timestamp": datetime.now().isoformat(),
"prompt_length": len(prompt),
"response_length": len(generated_text),
"inference_time": round(inference_time, 4),
"tokens_per_second": round(len(generated_text.split()) / inference_time, 2)
}
monitor.health_metrics["generation_stats"].append(generation_stat)
return jsonify({
"generated_text": generated_text,
"inference_time": round(inference_time, 4),
"prompt_length": len(prompt),
"response_length": len(generated_text),
"tokens_per_second": generation_stat["tokens_per_second"]
})
except Exception as e:
inference_time = time.time() - start_time
monitor.update_request_stats(inference_time, success=False)
logger.error(f"生成文本失败: {e}")
return jsonify({"error": str(e)}), 500
@app.route('/api/system/restart', methods=['POST'])
def restart_monitor():
"""重启监控系统"""
try:
monitor.stop_monitoring()
time.sleep(2)
monitor.start_monitoring()
return jsonify({"message": "监控系统重启成功"})
except Exception as e:
return jsonify({"error": str(e)}), 500
# 新增的分析API路由
@app.route('/api/analysis/inference')
def get_inference_analysis():
"""获取推理时间分析数据"""
data = monitor.get_inference_analysis_data()
return jsonify(data)
@app.route('/api/analysis/throughput')
def get_throughput_analysis():
"""获取吞吐量分析数据"""
data = monitor.get_throughput_analysis_data()
return jsonify(data)
@app.route('/api/analysis/requests')
def get_request_analysis():
"""获取请求分析数据"""
data = monitor.get_request_analysis_data()
return jsonify(data)
@app.route('/api/analysis/generation')
def get_generation_analysis():
"""获取生成统计分析数据"""
data = monitor.get_generation_stats_data()
return jsonify(data)
if __name__ == '__main__':
# 启动时开始监控
monitor.start_monitoring()
logger.info("增强版模型健康度监测系统启动完成")
app.run(debug=False, host='0.0.0.0', port=5000)