注:本文为 "Linux 内核源码学习" 相关合辑。
略作重排,未整理去重。
如有内容异常,请看原文。
需要多久才能看完 linux 内核源码?
原创 土豆居士 一口 Linux 2021 年 12 月 29 日 11:50
Linux 内核代码到底有多少行?
我们需要多久能读完呢?
一、内核行数
Linux 内核分为 CPU 调度、内存管理、网络和存储四大子系统,针对硬件的驱动成百上千。代码的数量更是大的惊人。
先说说最早的内核 linux 0.11,下面这本书可以说很多驱动工程师都学习过,我花了大概 1 个半月,勉强看了一遍。

再来看看内核代码量的统计。
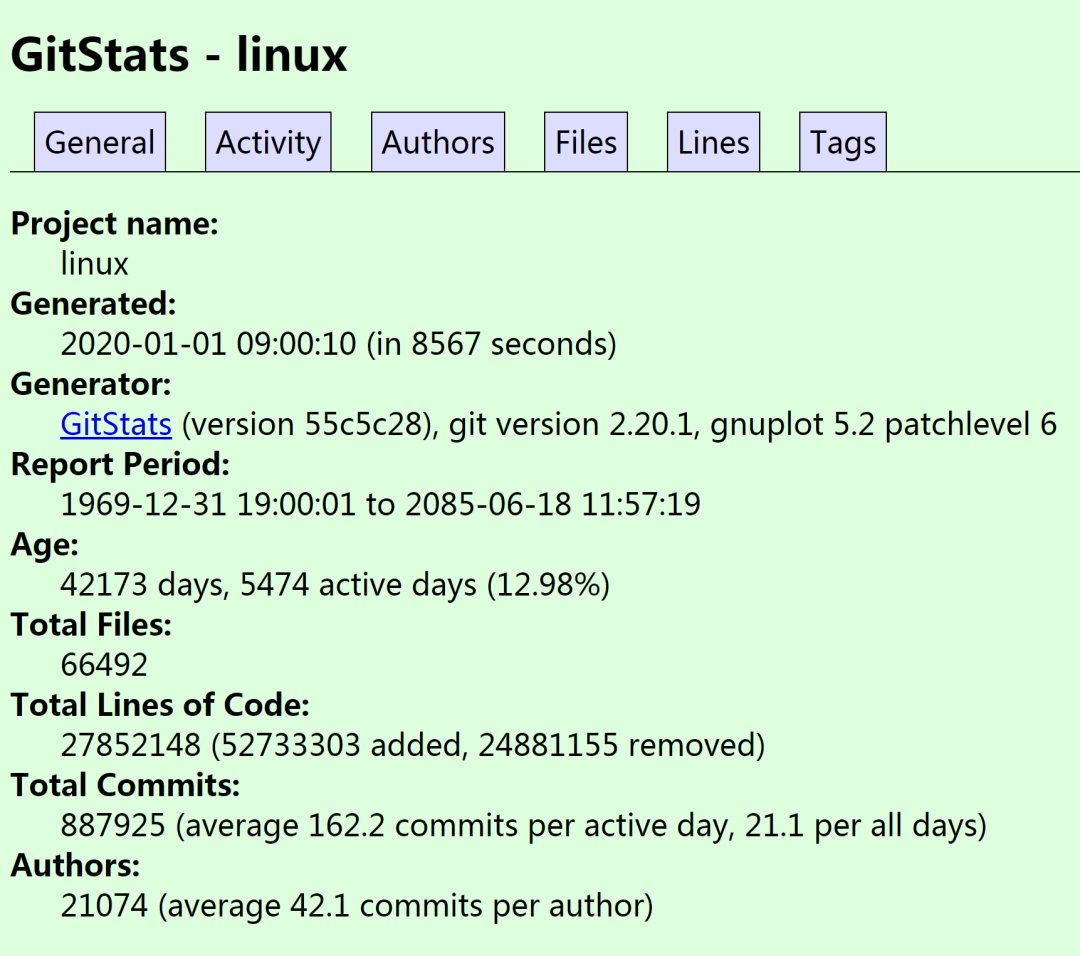
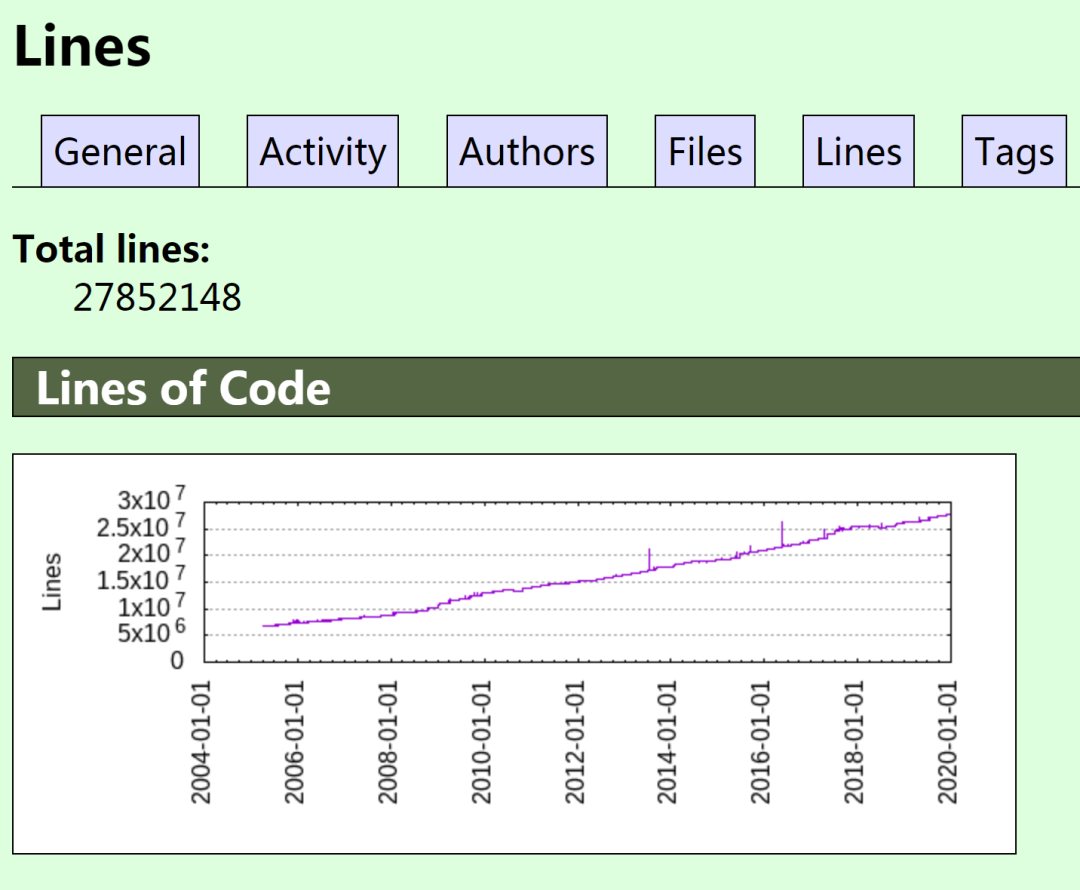
2020 年 1 月 1 日,Linux 内核 Git 源码树中的代码达到了 2780 万行。
phoronix 网站统计了 Linux 内核在进入 2020 年时的一些源码数据并作了总结。
从统计数据来看,Linux 内核源码树共有:
27852148 行 (包括文档、Kconfig 文件、树中的用户空间实用程序等)、
887925 次 commit
21074 位不同的作者
2780 万行代码分布在 66492 个文件中。
Linux 内核从最初的 10000 行代码到现在的 2780 万行代码就是全球精英共同贡献的结果。
按照一天一万行的速度,也需要 2700 天,也需要 7 年多。
这还是建立在所有单次都认识,所有代码逻辑看了的都懂,而且都不忘记的基础上。
实际上即使我们真的看完了,几年后内核又会有非常大的变化,可以说一辈子都看不完 Linux 内核的代码。
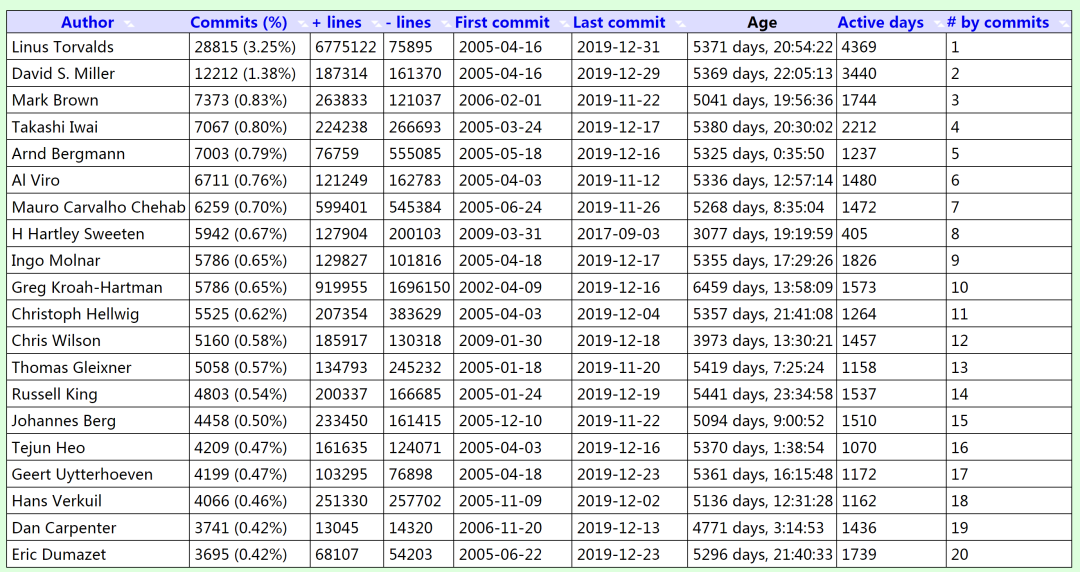
Linux 内核 Git 源码树中的代码达到了 2780 万行,核心代码只有 2%是由李纳斯•托瓦兹自己编写的,其他均是其他个人和组织贡献的,李纳斯•托瓦兹公开了 Linux 但保留了选择新代码和需要合并的新方法的最终裁定权。
除了 Linus Torvalds,对内核贡献最多的是 David S.Miller、 Mark Brown、Takashi Iwai、Arnd Bergmann、Al Viro 和 Mauro Carvalho Chehab。
而参与贡献的公司,从域名统计来看,谷歌、Intel 与 Red Hat 排在了最前列。
二、内核目录文件大小
然而,现在的内核已经膨胀的不成样子了,以还不算最新的 linux-4.1.15 为例:
整个内核源码一共约 793M:

驱动代码占了大概一半,大约 380M:

体系相关的代码大约 134M:
网路子系统相关的代码 26M:

文件系统相关的代码 37M:

linux 内核核心代码大约 6.8M:

这些目录任意一个目录想完全看明白都非常不容易。
三、内核子系统
什么是内核:
在计算机科学中是一个用来管理软件发出的数据 I/O(输入与输出)要求的计算机程序,将这些要求转译为数据处理的指令并交由中央处理器(CPU)及计算机中其他电子组件进行处理,是现代操作系统中最基本的部分。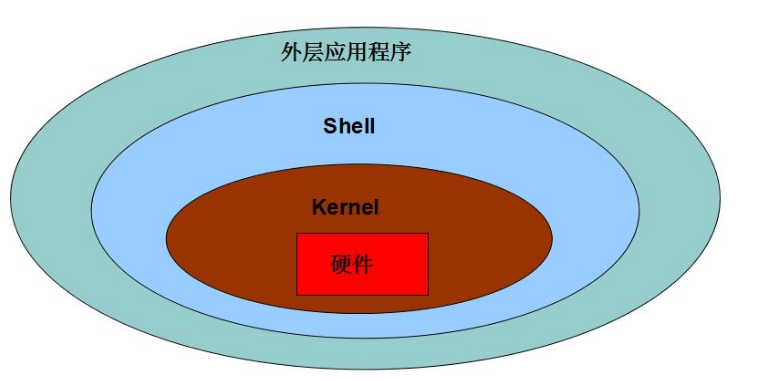
它是为众多应用程序提供对计算机硬件的安全访问的一部分软件,这种访问是有限的,并由内核决定一个程序在什么时候对某部分硬件操作多长时间。
linux 内核代码涉及知识点包括汇编指令、c 语言、硬件组成原理、操作系统、数据结构和算法、各种外设总线、驱动、网络协议栈。
直接对硬件操作是非常复杂的。所以内核通常提供一种硬件抽象的方法,来完成这些操作。
通过进程间通信机制及系统调用,应用进程可间接控制所需的硬件资源(特别是处理器及 IO 设备)。
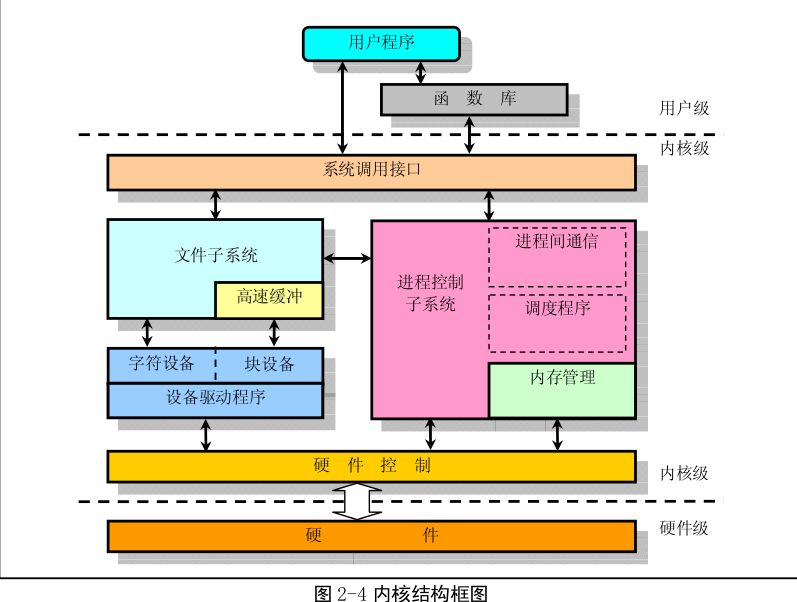
最上面是用户(或应用程序)空间。这是用户应用程序执行的地方。用户空间之下是内核空间,Linux 内核正是位于这里。
GNU C Library (glibc)也在这里。它提供了连接内核的系统调用接口,还提供了在用户空间应用程序和内核之间进行转换的机制。
内核和用户空间的应用程序使用的是不同的保护地址空间。
每个用户空间的进程都使用自己的虚拟地址空间,而内核则占用单独的地址空间。
Linux 内核可以进一步划分成 3 层。最上面是系统调用接口,它实现了一些基本的功能,例如 read 和 write。
系统调用接口之下是内核代码,可以更精确地定义为独立于体系结构的内核代码。这些代码是 Linux 所支持的所有处理器体系结构所通用的。
在这些代码之下是依赖于体系结构的代码,构成了通常称为 BSP(Board Support Package)的部分。这些代码用作给定体系结构的处理器和特定于平台的代码。
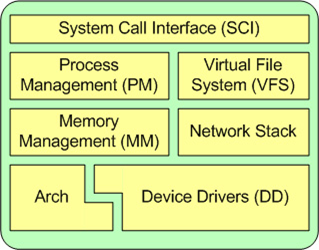
内核主要系统包括:SCI:系统调用接口 PM:进程管理 VFS:虚拟文件系统 MM:内存管理 Network Stack:内核协议栈 Arch:体系架构 DD:设备驱动
1 系统调用接口
SCI 层提供了某些机制执行从用户空间到内核的函数调用。这个接口依赖于体系结构,甚至在相同的处理器家族内也是如此。
SCI 实际上是一个非常有用的函数调用多路复用和多路分解服务。
在 ./linux/kernel 中您可以找到 SCI 的实现,并在 ./linux/arch 中找到依赖于体系结构的部分。
2 进程管理
进程管理的重点是进程的执行。
在内核中,这些进程称为线程,代表了单独的处理器虚拟化(线程代码、数据、堆栈和 CPU 寄存器)。
在用户空间,通常使用进程 这个术语,不过 Linux 实现并没有区分这两个概念(进程和线程)。
内核通过 SCI 提供了一个应用程序编程接口(API)来创建一个新进程(fork、exec 或 Portable Operating System Interface POSIX 函数),停止进程(kill、exit),并在它们之间进行通信和同步(signal 或者 POSIX 机制)。
3 内存管理
内核所管理的另外一个重要资源是内存。为了提高效率,如果由硬件管理虚拟内存,内存是按照所谓的内存页方式进行管理的(对于大部分体系结构来说都是 4KB)。
Linux 包括了管理可用内存的方式,以及物理和虚拟映射所使用的硬件机制。
4 虚拟文件系统
虚拟文件系统(VFS)是 Linux 内核中非常有用的一个方面,因为它为文件系统提供了一个通用的接口抽象。VFS 在 SCI 和内核所支持的文件系统之间提供了一个交换层。
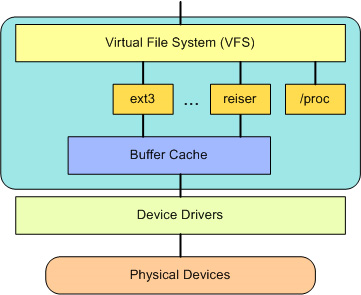
在 VFS 上面,是对诸如 open、close、read 和 write 之类的函数的一个通用 API 抽象。在 VFS 下面是文件系统抽象,它定义了上层函数的实现方式。
它们是给定文件系统(超过 50 个)的插件。文件系统的源代码可以在 ./linux/fs 中找到。
文件系统层之下是缓冲区缓存,它为文件系统层提供了一个通用函数集(与具体文件系统无关)。
这个缓存层通过将数据保留一段时间(或者随即预先读取数据以便在需要是就可用)优化了对物理设备的访问。缓冲区缓存之下是设备驱动程序,它实现了特定物理设备的接口。
5 网络堆栈
网络堆栈在设计上遵循模拟协议本身的分层体系结构。
回想一下,Internet Protocol (IP) 是传输协议(通常称为传输控制协议或 TCP)下面的核心网络层协议。TCP 上面是 socket 层,它是通过 SCI 进行调用的。
socket 层是网络子系统的标准 API,它为各种网络协议提供了一个用户接口。
从原始帧访问到 IP 协议数据单元(PDU),再到 TCP 和 User Datagram Protocol (UDP),socket 层提供了一种标准化的方法来管理连接,并在各个终点之间移动数据。内核中网络源代码可以在 ./linux/net 中找到。
6 设备驱动程序
Linux 内核中有大量代码都在设备驱动程序中,它们能够运转特定的硬件设备。
Linux 源码树提供了一个驱动程序子目录,这个目录又进一步划分为各种支持设备,例如 Bluetooth、I2C、serial 等。设备驱动程序的代码可以在 ./linux/drivers 中找到。
下面这个图形象的讲解了 Linux 内核都有哪些东西!
四、如何学习内核?
1. 学习主线
linux 内核源码大而全,一个人,即使再聪明、再有精力,也不可能完全看完、看懂所有的 linux 内核源码。
一口君建议按照以下主线进行深入研究:
-
linux 驱动架构
-
linux 网络子系统
-
linux 内核启动过程
-
linux 内存管理机制
-
linux 调度器
-
linux 进程管理
-
linux 虚拟机制 (kvm)
-
linux 内核实时化技术
沿着某一个主线,深入进去,在研究清楚这个主线的同时,向其他的主线扩展、渗透和学习。
此处之所以将驱动列为学习内核的入口,是因为内核为很多外设驱动实现了架构, 比如 I2C、SPI、UART、PCIE、字符设备、网络设备、块设备, 我们可以从最基本的字符设备学起, 学习如何编写一个简单的模块 学习如何如何为一些简单的设备比如 LED、KEY、ADC 等编写驱动 可以说驱动是我们学习内核最简单的入口,
由点到线、由线到面、由面到体,层层深入、不断精进,是学习 linux 内核源码的一个有效的方法。
2. 代码阅读工具
对于代码阅读方法从两个角度来介绍,一个方面是需要选择一个比较有效阅读代码的工具。
一口君强烈推荐:source insight 这款阅读代码神器!
也可以使用 vscode 或者 vim+ctags 的组合。
不过一口君十几年的从业经验,
99%以上的开发人员都选择 SI 阅读内核代码。
代码并不是写给人看的,而是交给机器运行的。
所以我们去理解别人的代码时,并不能像看小说一样去通篇的阅读代码,而应该是像研究化石一样去调查它,解密它。
有时我们往往也需要把对方的一段代码亲手的实现一遍,然后自己举一反三看自己会怎么去实现它,才能真正的理解。
3. 学习的内核版本
有些人推荐先阅读一些低版本的内核,比如 0.01 版的,总代码量才 1 万行左右。
阅读这个代码大概一个月应该能比较清晰了。
但是,改代码与现在的代码差异巨大,阅读后可以理解基本思想,但对理解现有代码的帮助不是特别明显。
3.10 版本之后的内核都支持设备树!
所以一口君建议是尽量选择 3.10 版本之后的代码阅读学习。
最好选择一款开发板学习!
开发板的选择一定要选择资料比较全,
售后比较好的品牌!
否则学习中遇到的一个小问题都可能被卡个一两周。
无形中增加了学习的成本,
要知道时间就是金钱!
对于初学者来说,
强烈推荐正点原子的开发板!
4. 学习 Linux 最重要的是培养自己写代码的能力和对 Linux 框架结构的了解
Linux 内核中绝大部分代码都是由这个地球上顶尖的技术大牛所编写,
这些代码的高内聚低耦合,
其精准度,简洁度、质量都相当的高,
每每看到一段高质量的代码,
一口君都会被那一行行枯燥的代码背后隐藏的设计思想所震撼,所折服!
阅读内核的代码简直就是在欣赏艺术品!
很多粉丝问我如何提高自己的 C 语言编程水平, 一口君不厌其烦的 重复着同样一句话:看 Linux 内核!
代码中自由颜如玉!代码中自有黄金屋!
我们一定要像泡妞一样来泡内核!
时刻保持激情,任性和耐性!
耐住寂寞,天天读它,泡她!
从量变到质变!
水滴石穿!
愿各位都能够熟练掌握 Linux,实现从程序员涅槃成为真正的软件大师!
linux 内核源码破 4k 万行,读完是不可能了~
原创 bug 菌 最后一个 bug 2025 年 2 月 2 日 14:02 湖南
Linux6.13 于 2025 年 1 月初发布,共有 39,819,522 行,而随着 Linux6.14rc1 源代码的最新发布,这一数字已经膨胀到 40,063,856 行,这数字有点可怕了~
Linux 内核源代码将扩展到 4000 万行以上,已经是不可避免的了。这个 4000 万行里程碑是 2015 年 Linux 内核源代码行数的两倍。
如果还有伙计想一行一行的看完最新的 linux 内核源码,还是要三思呀。
Linux 内核代码膨胀这么快,肯定也是好掺半的,内核的规模增长,说明它的
功能是越来越丰富,支持的硬件体系架构、新技术也越来越多,生态也保持着强劲的活力。
对用户和企业来说也是好的,因为
能用到更多先进的功能,甚至能够简化很多系统性设计,兼容性也会更好。比如支持新的处理器、显卡或者物联网设备,这都是技术发展的必然结果。
不过,代码量大了之后,维护起来会更困难一些,内核开发者们需要管理这么庞大的代码库,也会增加出错的概率。大部分搞开发的朋友都知道,项目代码越多,潜在的 bug 和漏洞可能就越多。
同时对于一名想入门 linux 内核开发者来说,学习曲线也会更陡峭,因为要理解这么多代码的结构和逻辑,需要更多时间和精力,深入研究内部机制并应用确实不太友好。
另外,内核的复杂度提高可能导致性能问题。虽然硬件也在进步,但代码优化是否跟得上呢?比如启动时间会不会变长,资源占用会不会增加,这对嵌入式系统或实时性要求高的场景可能不太友好。还有,每次升级内核时,体积增大可能让一些存储空间有限的设备难以适应,比如物联网设备或旧硬件,当然你可以裁剪,不过深度裁剪还是需要一定功底的,裁剪不好稳定性就是很大问题。
代码增长可能反映出社区的活跃和贡献者的增加,这是积极的。但另一方面,代码管理、审核和合并的挑战也变大了。维护者需要处理更多的补丁和功能请求,可能导致审核时间延长,或者一些贡献被忽视,影响开发效率。
安全性方面,虽然更多的代码意味着更多潜在漏洞,但 Linux 社区一直以快速修复著称。不过,代码量增加确实会让全面审计变得更困难,可能存在未被发现的安全隐患。这对依赖 Linux 的关键系统来说是个风险。
还有,不同用户的需求差异挺大的。普通项目可能不需要那么多功能,像 RTOS 集成一些功能就能满足项目应用需求了,而企业大型项目则需要高度定制。内核能否保持灵活性,允许模块化加载或裁剪,这对它的适用性很重要。如果内核能保持模块化设计,用户可以根据需要启用或禁用功能,那代码量的增加也倒不是什么大问题,可以在"大而全"与"小而美"场景下灵活适配。
有了这张图,看谁还能阻拦我研究 linux 内核源码!
原创 ytcoode kernel.guide 2020 年 10 月 15 日 21:32
内核 bzImage 全景图
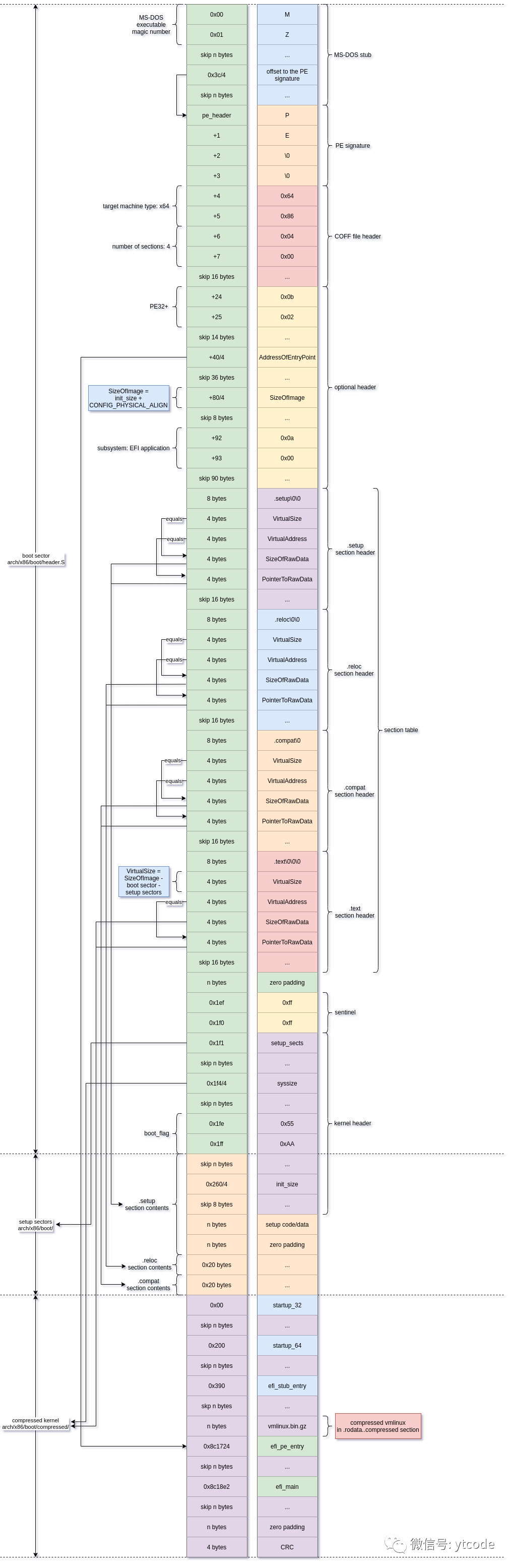
UEFI 环境下 bzImage 内核文件的加载机制
当打包生成的内核文件 bzImage 以 EFI 应用程序(EFI application)形式被 UEFI 硬件启动时,UEFI 固件将依据 PE(Portable Executable)文件格式对该内核文件进行解析,并完成内核代码的加载操作。
PE 文件格式的所有相关数据均存储于引导扇区(boot sector)中,该扇区的大小固定为 512 字节。
在 UEFI 启动 bzImage 文件的过程中,首先会根据 PE 文件头中 SizeOfImage 字段指定的数值,为内核分配对应的内存空间;随后,依据节表(section table)中记录的各项数据,将文件中各个节(section)的内容加载至预分配的指定内存地址。
由图示可知,除最后一个名为 .text 的节(该节对应压缩后的内核,即 compressed kernel)外,其余各个节加载至内存后的位置与大小,均与它们在 bzImage 文件中的原始位置和大小保持一致。
bzImage 文件被加载至内存后,其内存布局按顺序依次为引导扇区(boot sector)、.setup 节、.reloc 节、.compat 节及 .text 节。其中,.text 节除包含 bzImage 文件中对应的原始内容外,还预留有一块较大的空闲内存区域,该区域将用于后续压缩内核的解压过程。
当 bzImage 文件的解析与加载流程全部完成后,UEFI 固件将读取 PE 文件可选头(optional header)中 AddressOfEntryPoint 字段指定的入口地址(即 efi_pe_entry),并从该地址开始执行内核代码。
为什么要阅读 Linux 内核源码以及如何阅读 Linux 内核源码
原创 Jasonangel 嵌入式 Linux 系统开发 2021 年 1 月 5 日 12:14
阅读源码目的
为了更好地编写驱动程序;对自己写的程序有更深入的理解;并且自己的岗位定位在底层开发。
获取内核源码:
阅读 linux 内核,常用下面两种方法:
-
bochs+linux0.11+书(linux 内核完全注释、linux 内核完全剖析、linux 内核设计的艺术)
-
Source Insight+linux2.X+书(linux 内核情景分析)
-
另外:笨叔叔近两年出的两本书不错,《奔跑吧 Linux 内核 入门篇》和《奔跑吧 Linux 内核 》基于 Linux4.x,只是配套视频有点贵,但是书写的很不错,以实际问题出发,在实际工作中很有用。
阅读源码分为纵向阅读和横向阅读。
纵向就是跟着内核的执行流程来读,横向就是按照内核的各大功能模块来读。
第一种方法纵向或者横向来读都可以,因为代码量不是很大。《linux 内核完全剖析》《linux 内核完全注释》是引导你横向阅读的书,《linux 内核设计的艺术》是引导你纵向阅读的书。建议横向纵向结合着来,纵向跟着 bochs 调试工具来是必不可少的,当遇到问题时进入到相应的功能模块横向拓展一下。
《linux 内核情景分析》中的内核版本是 2.4.X,现代内核版本还是推荐横向阅读,纵向几乎不可能。(在 Linux 下搭建了 quem 虚拟机,然后用 GDB 调试内核也可以)总之阅读源码的方法也就上面两种,贵在坚持,但是别闭门 N 久学内核,没有意义。而且长时间只读代码,不敲代码是不行的。
如果想在简历中写上关于 Linux 内核的经验,先不要花大量时间看源码,先把《linux 内核设计与实现》读了,在找工作中更有用。
Linux5.8.14
通常 Linux 会有以下目录
arch 子目录包括所有和体系结构相关的核心代码。它还有更深的子目录,每一个代表一种支持的体系结构
include 子目录包括编译核心所需要的大部分 include 文件。它也有更深的子目录,每一个支持的体系结构一个。include/asm 是这个体系结构所需要的真实的 include 目录的软链接,例如 include/asm-i386 。为了改变体系结构,你需要编辑核心的 makefile ,重新运行 Linux 的核心配置程序
init 这个目录包含核心的初始化代码,这时研究核心如何工作的一个非常好的起点
mm 这个目录包括所有的内存管理代码。和体系结构相关的内存管理代码位于 arch/*/mm/
drivers 系统所有的设备驱动程序在这个目录。它们被划分成设备驱动程序类
ipc 这个目录包含核心的进程间通讯的代码
modules 这只是一个用来存放建立好的模块的目录
fs 所有的文件系统代码。被划分成子目录,每一个支持的文件系统一个
kernel 主要的核心代码。同样,和体系相关的核心代码放在 arch/*/kernel
net 核心的网络代码
lib 这个目录放置核心的库代码。和体系结构相关的库代码在 arch/*/lib/
scripts 这个目录包含脚本(例如 awk 和 tk 脚本),用于配置核心
按照以下顺序阅读源代码会轻松点
核心功能 (kernel)
内存管理 (mm)
文件系统 (fs)
进程通讯 (ipc)
网络 (net)
系统启动和初始化 (init/main 和 head.S)
其他等等
建议书籍说明(参考):
1, 《Linux 内核设计与实现》,英文名 Linux Kernel Development(所以有人叫它 LKD),机械工业出版社,美国 Robert Love 著,陈莉君译者。评说:
此书是当今首屈一指的入门最佳图书。作者是为 2.6 内核加入了抢占的人,对调度部分非常精通,而调度是整个系统的核心,因此本书是很权威的。这本书讲解浅显易懂,全书没有列举一条汇编语句,但是给出了整个 Linux 操作系统 2.6 内核的概观,使你能通过阅读迅速获得一个 overview。而且对内核中较为混乱的部分(如下半部),它的讲解是最透彻的。对没怎么深入内核的人来说,这是强烈推荐的一本书。
2, 《Linux 内核源代码情景分析》上、下。毛德操、胡希明著,浙江大学出版社,评说:
本书是基于 2.4.0 内核的。上册讲解内存管理、中断、异常与系统调用、进程控制、文件系统与传统 Unix IPC;下册讲解 socket、设备驱动、SMP 和引导。关于这套书的评价褒贬不一,我个人认为其深度是同类著作中最优秀的。本书基于 Intel IA32 体系,由于厚度大,很多体系上的知识都捎带讲解了,所以如果你想深入了解内核的工作机制而又不非常熟悉 Intel CPU 的体系构造,本书是最合适的。缺点是:版本较老,没有 TCP/IP 协议栈部分(它讲的 socket 只是 Unix 域协议的),图表太少,不适合初学者入门。还有就是对学生朋友来说,可能书价偏高,这样的话可以考虑先买上册,因为上册是核心部分,下册一大部分都在讲具体 PCI/ISA/USB 设备的驱动。
3, 《深入理解 Linux 内核》第二版。中国电力出版社。也是陈莉君译。此书是 Linux 内核黑客在推荐图书时的首选。评说:
此书图表很多,形象地给出了关键数据结构的定义,与《情景分析》相比,本书内容紧凑,不会一个问题讲解动辄上百页,有提纲挈领的功用,但是深度上要逊于《情景分析》。
4, 其它的几本书。市面上能见到的其它的 Linux 内核的图书,《Linux 设备驱动程序》、《Linux 内核源代码完全注释》以及新出的《Linux 内核分析及编程》等。
《Linux 设备驱动程序》第二版是基于 2.4 的,中文翻译不错,中国电力出版。这书强调动手实践,但它是讲解"设备驱动"的,不是最核心的东西,而且有些东西没硬件的话无法实践,可能更适合驱动开发的程序员吧,不太适合那些 For fun and profit 的人。此书有第三版英文版,东南大学出版社影印,讲解 2.6 的,行文流畅,讲解的面也比第二版更广泛,我读过其中关于同步与互斥、内存分配的部分,感觉很不错。
《Linux 内核源代码完全注释》(机械工业出版社)是同济大学的博士生赵炯的著作,讲解 0.1Linux 内核,我没买也没看,有看过的朋友说一说。
《Linux 内核分析及编程》(电子工业出版社)是刚刚出版的,国人写的,讲解 2.6.11 。很多人说好,但有人说不够系统,我没买,不敢评说。
还有一本清华出的《Linux 内核编程指南(第三版)》,原书应该是好书,但是翻译、排版十分糟烂,脱字跳行,根本没法看,我买了一本又扔掉了。
5, 其它资源。TLDP(The Linux Documentation Project)有大量文档,其中不少是关于内核的,有些是在国外出版过的,像《Linux Kernel Interls》《The Linux Kernel》《Linux Kernel Module Programming Guide》等,作者都是亲身参加开发的人,著作较为可信。
6, 一本不是讲解 Linux 的书:《现代体系结构上的 Unix 系统:内核程序员的 SMP 和 Caching 技术》,人民邮电出版社 2003 版, 本书虽然不是讲解 Linux,但是对所有 Unix 内核都是适用的,适合对 SMP 和 CPU 的 Cache 这些组成原理知识不是很熟的朋友,而且是很多国外牛人推荐的书。中文版翻译非常负责。
在线阅读 Linux 内核源码网站:
https://elixir.bootlin.com/linux/latest/source
初学者建议书籍(实拍):
个人建议内核和驱动一起学。

Linux 内核源码学习
一、Linux 内核源码规模与演进特征
1.1 代码行数的历史增长
Linux 内核的代码规模呈持续扩张态势,反映其功能生态的不断完善:
- 初始版本 Linux 0.11 仅包含约 10,000 行代码,结构简洁,是入门学习的经典素材;
- 2020 年 1 月,Linux 内核 Git 源码树累计代码量达 27,852,148 行(含文档、Kconfig 文件及用户空间工具),分布于 66,492 个文件中;
- 截至 2025 年,Linux 6.14 rc1 版本代码行数突破 40,063,856 行,较 2015 年实现翻倍增长,成为全球规模最大的开源项目之一。
这一增长背后是全球开发者社区的协作贡献:累计提交次数达 887,925 次,参与贡献的开发者超 21,074 位,其中 Linus Torvalds 编写的代码占比仅 2%,David S.Miller、Mark Brown 等开发者及 Google、Intel、Red Hat 等企业是主要贡献力量。
1.2 源码目录体积分布(以 Linux 4.1.15 为例)
Linux 内核源码目录按功能模块划分,体积分布呈现显著差异:
- 整体源码体积约 793 MB;
- 设备驱动目录(drivers)占比最高,约 380 MB,占总体积的近 50%;
- 体系结构相关代码(arch)约 134 MB,适配不同处理器架构;
- 文件系统模块(fs)约 37 MB,包含各类文件系统实现;
- 网络子系统(net)约 26 MB,实现分层网络协议栈;
- 内核基础代码(kernel)约 6.8 MB,包含进程调度、系统调用等关键逻辑。
1.3 代码规模扩张的双重影响
| 积极意义 | 潜在挑战 |
|---|---|
| 支持更多硬件架构与外设,兼容性大幅提升 | 代码维护复杂度增加,潜在漏洞风险上升 |
| 集成新技术与功能模块,生态活力强劲 | 入门学习曲线陡峭,需投入更多时间精力 |
| 简化企业级系统设计,降低开发成本 | 内核体积增大,对嵌入式设备存储造成压力 |
| 社区活跃性提升,问题修复与迭代效率高 | 代码审核与合并流程复杂,影响开发效率 |
二、Linux 内核关键子系统架构
2.1 内核的本质与功能定位
在计算机系统中,内核是介于硬件与应用程序之间的关键软件层,其主要职责包括:
- 管理硬件资源(CPU、内存、I/O 设备),将应用程序的 I/O 请求转换为硬件可执行的指令;
- 提供安全的资源访问机制,限定应用程序对硬件的操作权限与时间片;
- 通过系统调用接口(SCI)为用户空间程序提供硬件抽象与功能调用支持。
Linux 内核采用分层架构设计,从上至下分为用户空间、内核空间两层,其中内核空间进一步划分为系统调用接口、体系结构无关代码、体系结构相关代码(BSP)三个层级,依赖 GNU C 库(glibc)实现用户空间与内核空间的转换。
2.2 六大关键子系统详解
(1)系统调用接口(SCI)
- 功能:提供用户空间到内核空间的函数调用通道,实现功能的多路复用与分解;
- 特性:依赖具体体系结构,不同处理器家族可能存在差异;
- 源码位置:./linux/kernel(通用实现)、./linux/arch(体系结构相关实现)。
(2)进程管理(PM)
- 功能:实现进程(线程)的创建、调度、同步与终止,提供处理器虚拟化能力;
- 关键机制:通过 fork、exec、exit 等系统调用与 POSIX 标准接口,管理进程的虚拟地址空间、代码段、数据段与堆栈;
- 源码位置:./linux/kernel/sched/
(3)内存管理(MM)
- 功能:管理物理内存与虚拟内存,实现内存分页(多数体系结构默认页大小为 4 KB)、地址映射与缓存优化;
- 关键机制:通过虚拟内存技术隔离进程地址空间,提高内存利用率与系统稳定性;
- 源码位置:./linux/mm/(通用实现)、./linux/arch/*/mm/(体系结构相关实现)。
(4)虚拟文件系统(VFS)
- 功能:为各类文件系统提供统一的抽象接口,实现"打开-读取-写入-关闭"等标准化操作;
- 架构分层:上层为通用 API 抽象,中层为文件系统插件(支持超过 50 种文件系统),下层为缓冲区缓存与设备驱动;
- 源码位置:./linux/fs/
(5)网络堆栈(Network Stack)
- 功能:遵循分层体系结构,实现从链路层到应用层的网络协议支持,包括 IP、TCP、UDP 等关键协议;
- 关键接口:通过 Socket 层为用户空间提供网络通信 API,支持连接管理与数据传输;
- 源码位置:./linux/net/
(6)设备驱动程序(DD)
- 功能:为各类硬件设备提供驱动支持,实现内核与硬件的交互;
- 分类:按设备类型划分为 Bluetooth、I2C、Serial、PCIe 等子模块,是内核中规模最大的代码子集;
- 源码位置:./linux/drivers/
2.3 内核启动流程全景(基于 bzImage 启动)
Linux 内核以 bzImage 格式通过 UEFI 启动的流程如下:
- UEFI 固件按 PE 格式解析 bzImage,读取 boot sector(前 512 字节)中的 SizeOfImage 与 section table 信息;
- 根据解析结果分配内存空间,加载 boot sector、.setup、.reloc、.compat、.text 等区段至指定内存地址(.text 区段包含压缩内核与解压预留空间);
- 执行 optional header 中指定的入口地址(efi_pe_entry),启动内核解压与初始化流程。
三、源码阅读的客观挑战
3.1 规模带来的时间成本
按每日阅读 10,000 行代码的理想效率计算,通读 4000 万行源码需 4000 天(约 11 年),且需满足"代码完全理解、逻辑无遗漏、记忆不衰减"的前提。实际场景中,内核代码的复杂性(如汇编指令、硬件交互、算法优化)导致阅读效率远低于理想值,且内核版本的持续迭代(平均每 2-3 个月发布一个稳定版本)使得"读完所有代码"成为不可能完成的任务。
3.2 技术栈的综合性要求
阅读 Linux 内核源码需掌握多领域知识:
- 编程语言:C 语言(内核主要实现语言)、汇编语言(体系结构相关代码);
- 计算机基础:操作系统原理、计算机组成原理、数据结构与算法;
- 硬件相关:外设总线协议(I2C、SPI、PCIe 等)、设备驱动开发原理;
- 协议标准:TCP/IP 网络协议栈、POSIX 接口规范。
四、Linux 内核源码系统性学习路径
4.1 学习目标与主要原则
(1)明确学习目标
- 驱动开发方向:聚焦设备驱动架构与外设交互逻辑;
- 系统优化方向:深入内存管理、进程调度与性能调优;
- 底层开发方向:全面掌握内核子系统架构与设计思想。
(2)主要学习原则
- 模块化学习:避免全面通读,选择特定子系统作为切入点,再逐步拓展;
- 由浅入深:从简单版本(如 Linux 0.11)或基础模块入手,积累基础后再攻坚复杂模块;
- 理论与实践结合:通过编写内核模块、调试源码等方式深化理解,避免单纯阅读;
- 长期坚持:内核学习是渐进过程,需通过持续积累实现知识体系的构建。
4.2 推荐学习主线与模块
(1)主要学习主线
- 驱动架构:从字符设备、块设备驱动入手,掌握 I2C、SPI 等总线驱动框架;
- 内存管理:理解虚拟内存、分页机制、内存分配算法(buddy 系统、slab 分配器);
- 进程管理:研究进程创建、调度算法(CFS 调度器)、进程间通信(IPC)机制;
- 网络子系统:从 Socket 接口到 TCP/IP 协议栈,逐层剖析数据传输流程;
- 文件系统:学习 VFS 抽象层、ext4 等典型文件系统的实现逻辑;
- 内核启动流程:跟踪从 bootloader 到内核初始化的完整过程;
- 进阶方向:内核实时化技术、KVM 虚拟化等。
(2)学习顺序建议
纵向学习(按执行流程):内核启动 → 系统调用 → 进程调度 → 内存分配 → 设备驱动;
横向学习(按模块深度):基础模块(kernel)→ 内存管理(mm)→ 文件系统(fs)→ 网络(net)→ 设备驱动(drivers)。
4.3 工具选型与版本选择
(1)代码阅读工具
- 首选工具:Source Insight,支持代码跳转、符号查找、依赖分析,是内核开发领域应用最广泛的工具;
- 替代方案:VS Code(搭配内核源码插件)、Vim + ctags + cscope,适合习惯命令行操作的用户;
- 在线工具:Elixir Bootlin,支持多版本源码查询与跳转。
(2)内核版本选择
- 入门版本:Linux 0.11(代码量小、结构清晰,适合理解内核基本架构);
- 实践版本:Linux 3.10 及以上版本(支持设备树,与当前嵌入式开发场景贴合);
- 进阶版本:Linux 4.x 或 5.x 系列(功能完善,适合深入研究特定模块)。
(3)开发板选择
推荐选择资料齐全、售后完善的开发板(如正点原子系列),避免因硬件问题阻碍学习进度,降低调试成本。
4.4 推荐参考书籍与资源
(1)入门级书籍
- 《Linux 内核设计与实现》(Robert Love 著):以 2.6 内核为基础,讲解内核关键概念与设计思想,无汇编代码,适合构建整体认知;
- 《奔跑吧 Linux 内核(入门篇)》:基于 Linux 4.x 版本,以实际问题为导向,配套实践案例,适合入门实践。
(2)进阶级书籍
- 《深入理解 Linux 内核》(第三版):详细剖析内核数据结构与实现机制,图表丰富,适合深入研究;
- 《Linux 内核源代码情景分析》(毛德操、胡希明著):基于 2.4 内核,深度解析内存管理、中断等基础模块,适合提升技术深度;
- 《Linux 设备驱动程序》:专注设备驱动开发,讲解驱动框架与编写方法,是驱动开发方向的必备书籍。
(3)其他资源
- 官方文档:Linux 内核源码自带的 Documentation 目录,包含模块说明与设计文档;
- TLDP 项目:The Linux Documentation Project,提供大量内核相关教程与技术文档;
- 调试工具:Bochs(模拟 x86 架构)、QEMU + GDB(内核调试),辅助跟踪代码执行流程。
五、总结
Linux 内核源码的庞大规模与复杂架构决定了"全面通读"的不现实性,其学习关键在于构建模块化的知识体系与科学的学习方法。通过明确学习目标、选择合适的版本与工具、聚焦基础模块、坚持理论与实践结合,学习者可逐步深入内核的设计思想与实现细节。内核学习不仅是技术能力的提升过程,更是对计算机系统底层逻辑的深度探索,最终实现从"使用内核"到"理解内核"再到"优化内核"的能力跨越。
via:
- 需要多久才能看完 linux 内核源码?
https://mp.weixin.qq.com/s/K_Ix6C9d_03cb1Hfpz461g - linux 内核源码破 4k 万行,读完是不可能了~
https://mp.weixin.qq.com/s/6iXs_Qk5oHtq2d1EtIX2GA - 有了这张图,看谁还能阻拦我研究 linux 内核源码!
https://mp.weixin.qq.com/s/ffYBke1o_5AfzDOHxs7l9Q - 为什么要阅读 Linux 内核源码以及如何阅读 Linux 内核源码
https://mp.weixin.qq.com/s/Q6_aE39KTVTBGXJS6weOYQ - ......