在当前信创和国产化大背景下,Easysearch 作为 Elasticsearch 的优秀国产化替代方案,凭借其高兼容性和本土化服务,越来越受到企业青睐。

然而,在实际从 elasticsearch-py 迁移或接入时,我们经常会遇到连接、认证和索引创建的兼容性问题。
本文将基于一个已成功运行 的企业级实战案例,手把手教你如何使用 Python 客户端(elasticsearch 库)连接 Easysearch 集群,并实现数据的完整生命周期管理:检查连接
索引创建
批量写入
简单查询。

unsetunset一、技术选型与核心痛点分析unsetunset
1.1 为什么仍使用 elasticsearch 库?
Easysearch 目前没有专属 Python 客户端,但在兼容性版本上,使用 elasticsearch 官方库是行业内的主流做法。我们选择的版本为:
💡 python 库版本信息:
elasticsearch==7.13.1
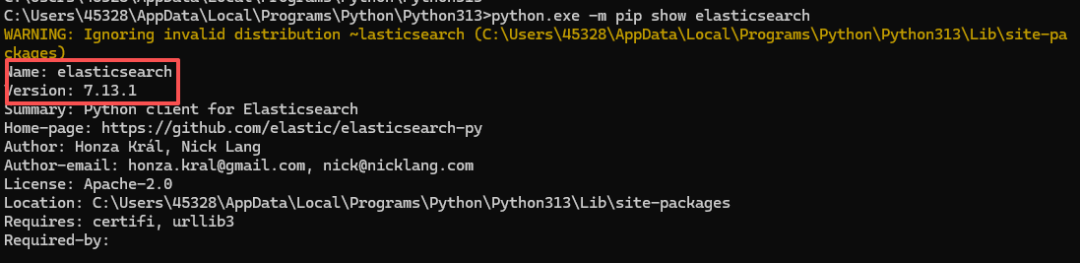
选择这个版本是为了确保对 Easysearch 7.x 版本(如 Easysearch 1.X 和 2.0 版本)的最大兼容性 和API一致性。
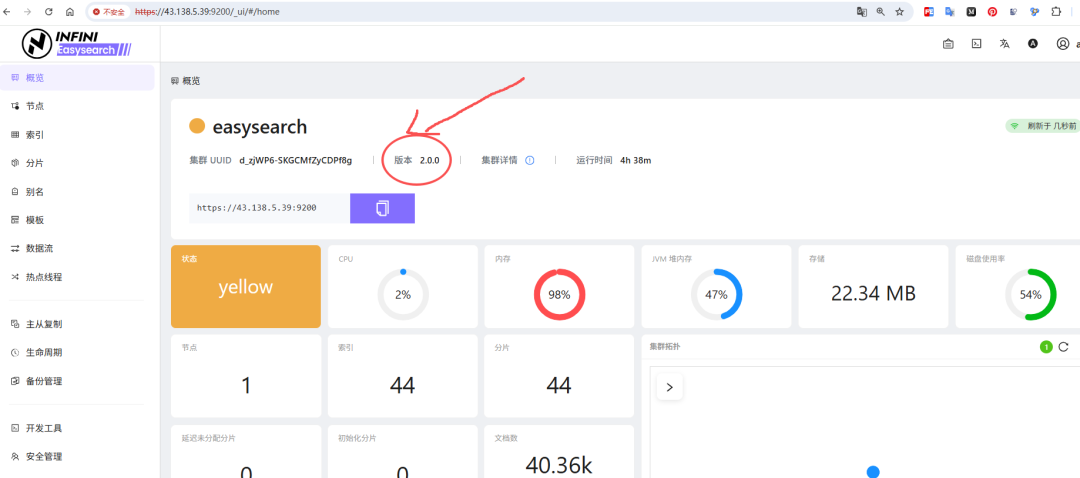
本文验证的是 Easysearch 2.0.0 版本。
1.2 企业级应用的核心痛点(及本案例的修复重点)
在企业级环境中,连接 Easysearch 常常涉及 HTTPS、用户名密码认证,以及老版本 API 兼容性问题。本实战案例的核心修复点在于:
-
HTTPS/SSL 连接与认证: 针对带证书验证的 Easysearch 服务,配置
use_ssl=True、verify_certs=False(禁用证书验证)并添加http_auth。 -
索引创建 API 兼容: 解决老版本
elasticsearch-py(如 7.13.1) 在创建索引时,indices.create()方法对参数兼容性问题。
unsetunset二、修复后的 Python 客户端核心实现unsetunset
我们将核心逻辑封装在 EasysearchDemoFixed 类(自己封装的代码)中,实现了连接、索引、写入和查询的闭环操作。
2.1 依赖安装与健壮连接初始化
首先,确保安装必要的依赖:
go
pip install elasticsearch python-dotenv在初始化阶段,我们通过环境变量加载配置,并设置了最健壮的连接参数:
go
from elasticsearch import Elasticsearch
# ... (其他导入和变量加载)
class EasysearchDemoFixed:
def __init__(self):
# ... (获取主机、端口、用户名、密码)
# 创建客户端实例 - 更健壮的连接配置
self.es_client = Elasticsearch(
[
{
'host': self.host,
'port': self.port,
'scheme': 'https',
'use_ssl': True# 启用 SSL
}
],
http_auth=(self.username, self.password) if self.username and self.password elseNone,
timeout=30,
max_retries=3,
retry_on_timeout=True,
verify_certs=False, # 禁用证书验证,解决SSL连接握手问题
ssl_show_warn=False
)
# ... (打印配置信息)
def check_connection(self):
"""检查 Easysearch 集群连接状态"""
# ... (ping, info, cluster.health 检查逻辑)
# 完整的错误诊断和建议,是企业级代码必不可少的
pass💡 铭毅天下点评:
在生产环境中,timeout、max_retries 和 retry_on_timeout 是保障代码健壮性的黄金三件套。
针对云上 Easysearch,scheme='https' 和 verify_certs=False 更是解决连接问题的关键钥匙。
2.2 索引创建与 API 兼容性
这是本次的重点 。在 python 客户端 7.13.1 版本中,indices.create() 并不接受分开的 mappings 和 settings 参数,而是要求它们合并到一个 body 参数中。
修复前(可能导致错误):
go
# 错误示范:老版本客户端不支持分开的 mappings 和 settings
# self.es_client.indices.create(index=self.index_name, mappings=mapping, settings=settings)修复后(兼容且正确):
go
def create_index(self):
"""创建索引 - 修复版本"""
# ... (删除旧索引逻辑)
# 索引映射和设置定义 (旧版本 API 格式)
index_body = {
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"mappings": {
"properties": {
"timestamp": {"type": "date"},
"user_id": {"type": "keyword"},
# ... (其他字段定义)
"ip_address": {"type": "ip"}
}
}
}
try:
# 创建新索引,将 settings 和 mappings 合并到 body 中
self.es_client.indices.create(
index=self.index_name,
body=index_body # 关键修改:使用 body 参数
)
print(f"✅ 新索引 {self.index_name} 创建成功")
# ... (等待和返回)
except Exception as e:
print(f"❌ 创建索引失败: {e}")
returnFalse⚙️ 核心实现说明:
我们将分开的 mappings 和 settings 参数合并到单个 body 参数中。
从:self.es_client.indices.create(index=self.index_name, mappings=mapping, settings=settings)
改为: self.es_client.indices.create(index=self.index_name, body=index_body)
这是确保在较旧的 elasticsearch-py 版本(如 7.13.1)中能够正常创建索引的关键修改,解决了 "IndicesClient.create() got an unexpected keyword argument 'mappings'" 错误,同时保持与 Easysearch 7.10.2 的兼容性。
2.3 批量数据写入与简单查询
批量写入使用 elasticsearch.helpers.streaming_bulk,这是企业级应用中最高效的写入方式 。查询则展示了标准的 search API 调用。
go
from elasticsearch.helpers import streaming_bulk
def ingest_sample_data(self):
"""批量写入模拟数据"""
# ... (准备 documents 数据)
try:
# 准备批量操作 actions 列表
actions = [
{
"_index": self.index_name,
"_source": doc
}
for doc in documents
]
# 使用 streaming_bulk 进行批量写入
for success, info in streaming_bulk(self.es_client, actions):
# ... (统计成功/失败数)
pass
# 刷新索引
self.es_client.indices.refresh(index=self.index_name)
print("✅ 索引刷新完成,数据已可查询。")
except Exception as e:
# ... (错误处理)
pass
def simple_search(self):
"""简单搜索演示"""
search_body = {
"query": {"match_all": {}},
"size": 10
}
res = self.es_client.search(index=self.index_name, body=search_body)
total_hits = res['hits']['total']['value']
print(f"📊 搜索结果: 共找到 {total_hits} 条记录")
# ... (打印结果详情)unsetunset三、完整运行流程与结果展示unsetunset
将上述步骤串联起来,形成完整的实战主流程。
go
def main():
"""主程序"""
demo = EasysearchDemoFixed()
# 步骤1: 检查连接
ifnot demo.check_connection():
# ... 退出
return
# 步骤2: 创建索引 (关键修复点)
ifnot demo.create_index():
# ... 退出
return
# 步骤3: 写入数据 (使用 streaming_bulk)
demo.ingest_sample_data()
# 步骤4: 搜索演示
demo.simple_search()
# 步骤5: 清理数据(可选)
# demo.cleanup()
print("\n✅ Easysearch Python 客户端从0到1实战案例演示完毕!")
if __name__ == '__main__':
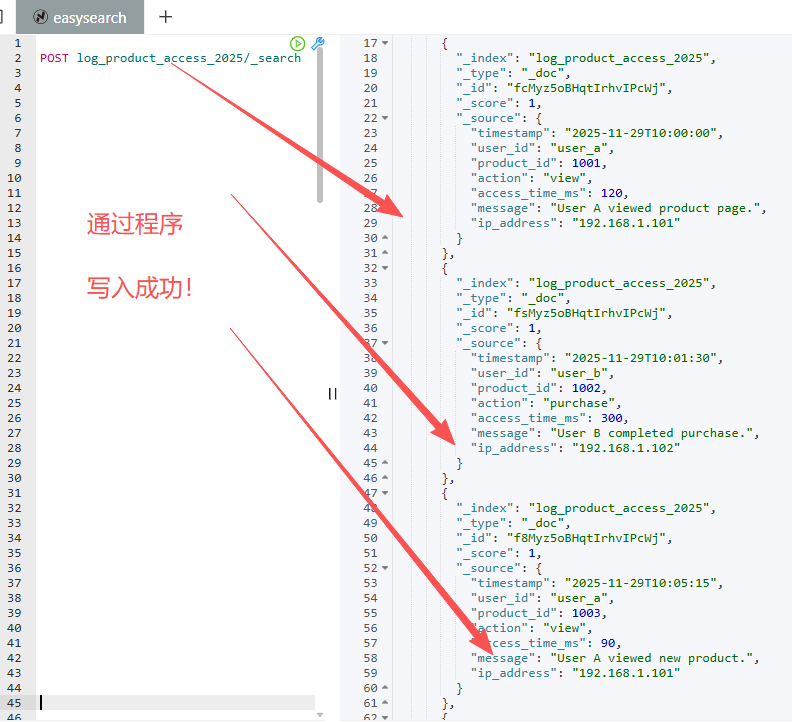
main()code buddy 编译器执行成功如下图所示:
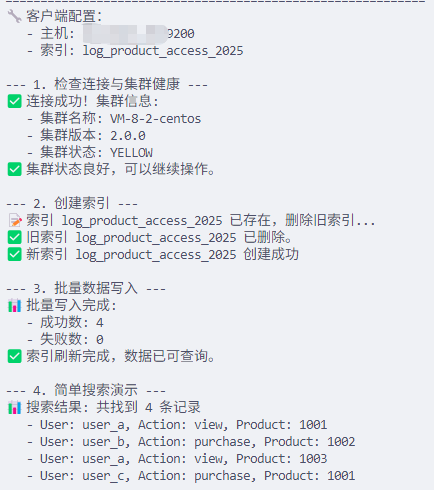
unsetunset四、铭毅天下总结与进阶建议unsetunset
通过本次"修复版"实战案例,我们可以得出以下核心结论:
-
高兼容性,但需注意版本差异
Easysearch 在 API 层面对 ES 7.x 版本兼容性极高,但在使用老版本的
elasticsearch-py客户端时,必须注意其 API 参数的变化,例如indices.create方法。 -
健壮性是企业级基石
在连接配置中,加入超时、重试和 SSL 证书的妥善处理,是保障服务稳定运行的 铁律。
-
高性能写入的唯一选择
生产环境数据导入,请 始终 使用
streaming_bulk或bulk助手函数,避免单条写入带来的性能瓶颈。
Easysearch 的国产化进程为我们带来了更多选择。只要掌握了兼容性处理的技巧,无论是从 ES 迁移,还是直接接入 Easysearch,Python 工程师都能快速上手,实现高性能的数据检索和分析能力!
elasticdumpWeb------Elasticsearch、Easysearch 跨集群索引迁移新Web工具