前几天我发了一篇文章《从PDF中提取Excel,这个工具真的好用》,受到很多的关注和评论,方法是用Python的开源库pdfplumber来实现对PDF上表格和文本的提取,非常方便和快捷。
pdfplumber是专门用来处理PDF的第三方库,完全开源和免费,它最核心的功能是提取PDF的文本和表格,支持保留段落、换行、空格的原始格式,不会像某些库那样把不同区域的文本混在一起,是我体验下来最好用的PDF处理库。
pdfplumber可以对PDF进行基本查询和编辑。
- page_number:页码
- width/height:页面尺寸
- rotation:旋转角度
- bbox:页面边界框
- crop(bbox):裁剪指定区域
- rotate(angle):旋转页面
- to_image():生成可视化页面
同时支持提取PDF文本和表格,这是pdfplumber的强项。
- extract_text():保留布局的整页文本提取
- extract_text_simple():忽略布局的简单文本提取
- get_textbox(bbox):提取指定区域文本
- extract_table(table_settings={}):提取页面第一个表格
- extract_tables(table_settings={}):提取页面所有表格
- find_tables():查找表格边界框
- extract_images():提取页面所有图像
pdfplumber使用也很简单,比如说提取PDF页面。
import pdfplumber
with pdfplumber.open("path/to/file.pdf") as pdf:
first_page = pdf.pages[0]
print(first_page.chars[0])虽然在Python上使用pdfplumber提取PDF文本表格并不难,但这仅限于懂Python的同学,如果你不会Python,那也是没办法用pdfplumber操作PDF,只能求助于付费软件。
我突发奇想用pdfplumber搭建了个PDF文本表格提取应用,可以实现拖拉拽实现操作,不需要任何的代码。
这个应用是基于streamlit开发的,在浏览器上打开使用,它支持的PDF操作包括:
1、支持拖拽导入PDF,并查看PDF基本信息
2、支持提取PDF文本、表格
3、支持导出Markdown、Word、TxT、Json格式文件
4、支持拉取所有表格,并导出Excel格式文件
5、支持将PDF转换为Word文件,并保持样式
6、支持DeepSeek生成PDF文本摘要
下面以一份PDF行业报告为例,咱们用这个工具去提取文本和表格,速度非常快。

首先将PDF拖到打开栏里,点击处理PDF。
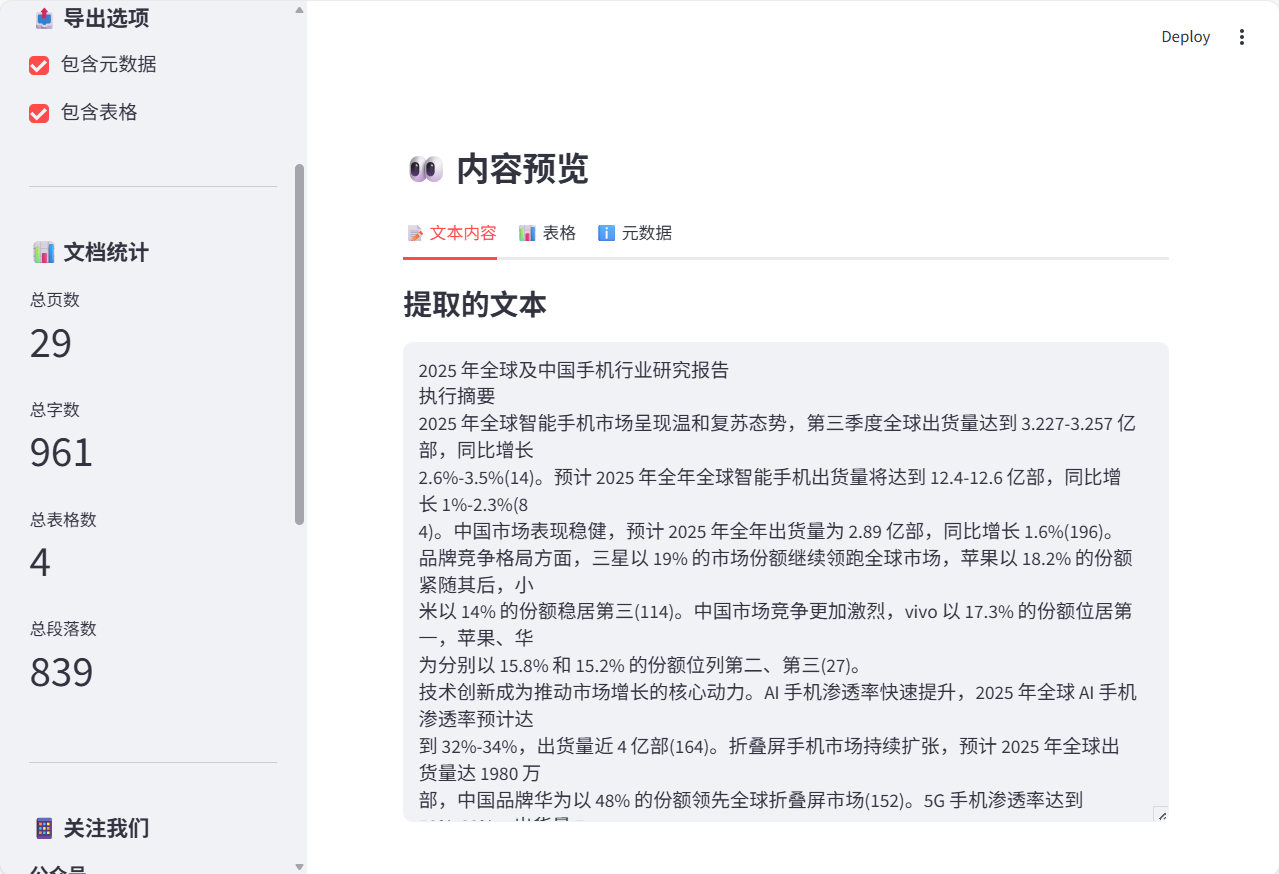
它就会将完整的文本提取出来,并显示PDF的基本信息。
点击表格功能,这个PDF所有的表格都会单独呈现出来,并可以下载Excel文件。
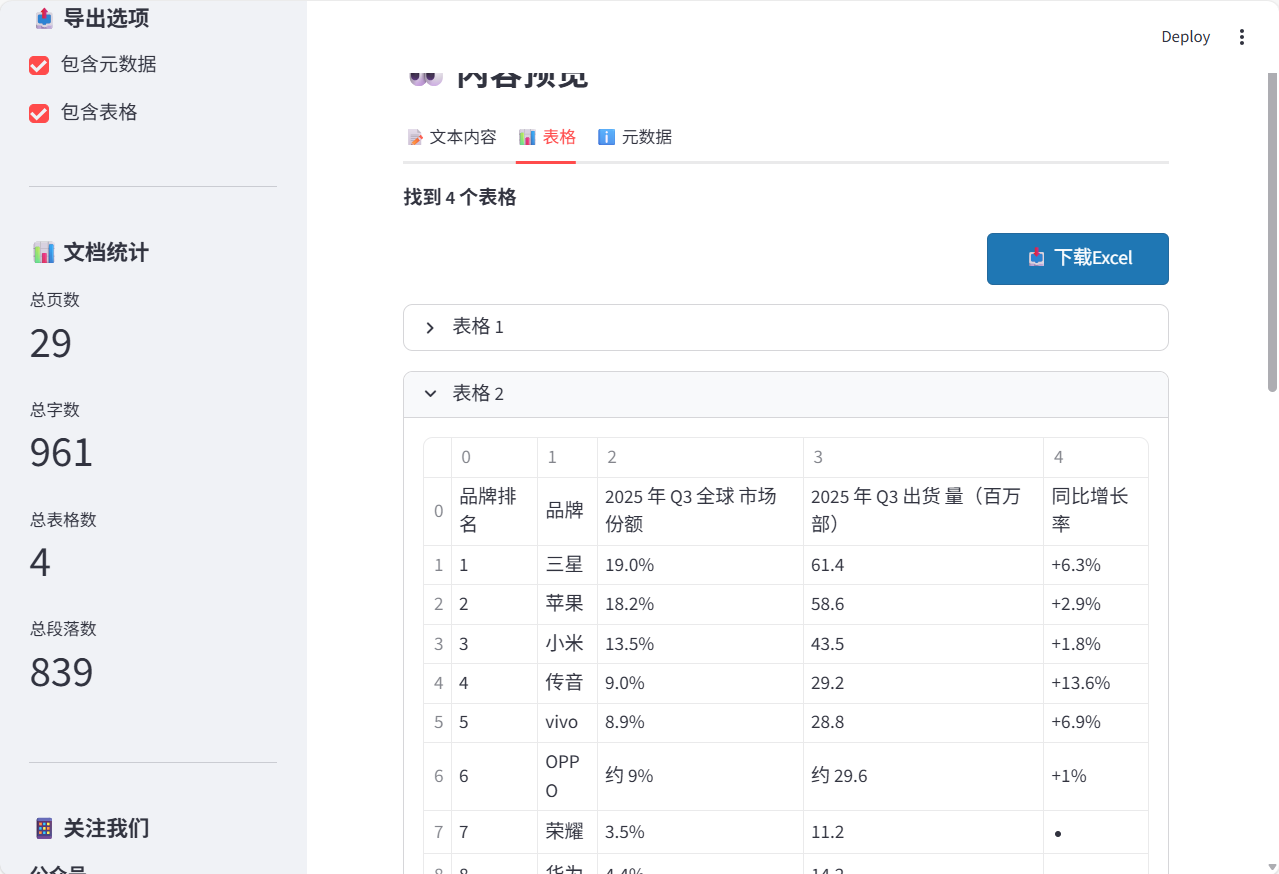
下载的Excel包含所有PDF表格,且高度还原格式。
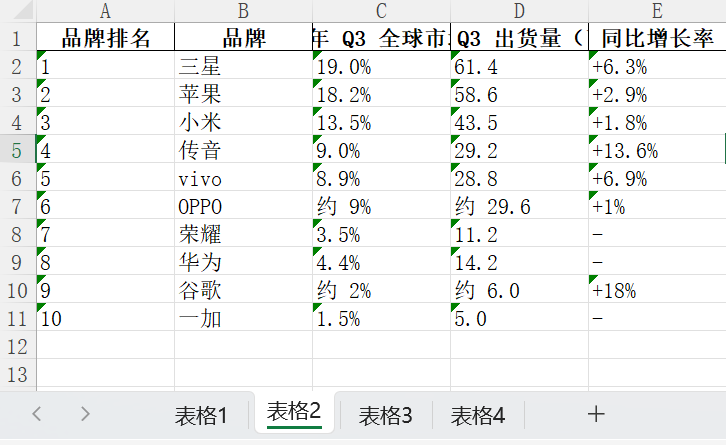
你可以将提取的文本导出为Word、Markdown、txt、Json格式文件。
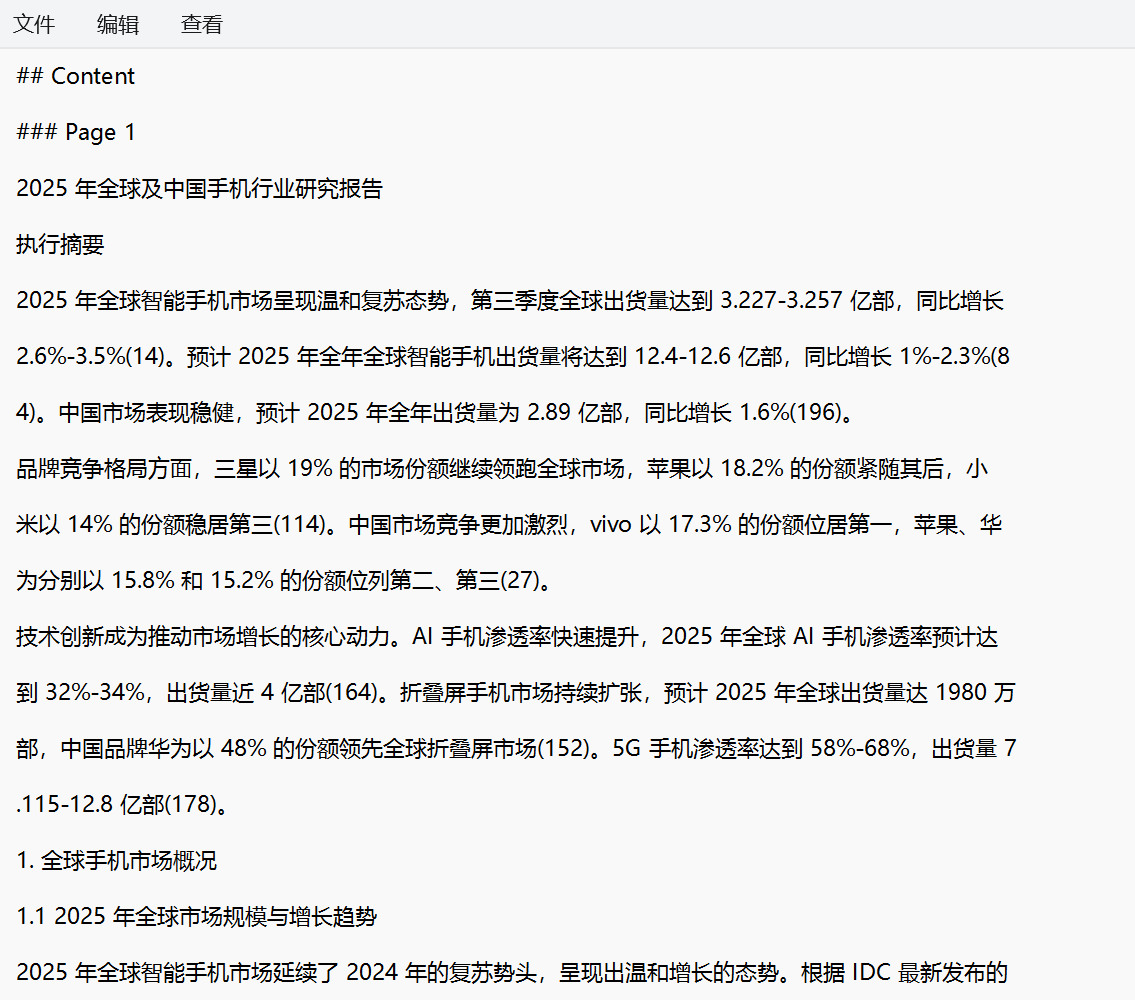
导出的Markdown文件如下:
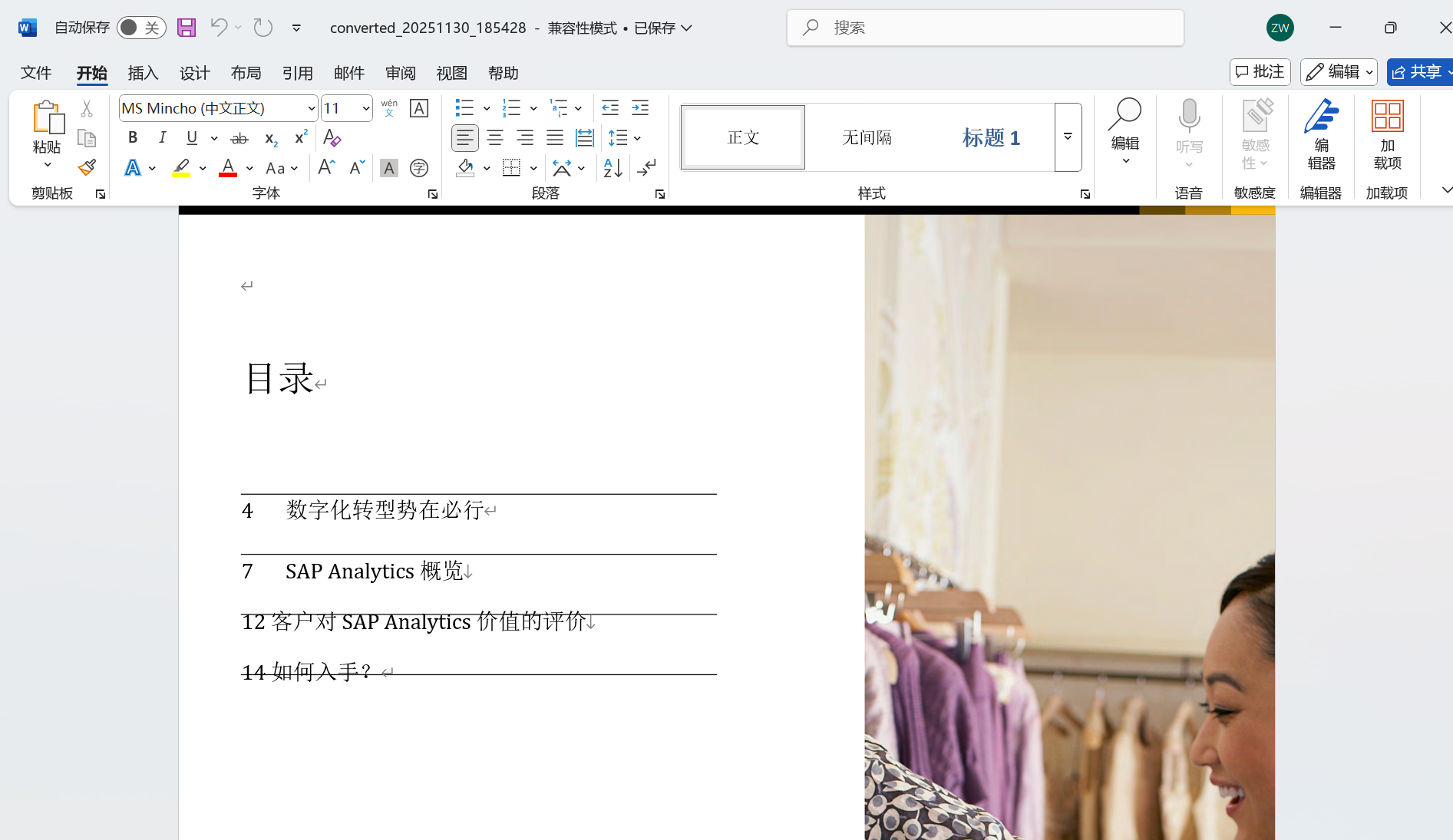
还可以直接将PDF原封不动转换为Word文件。
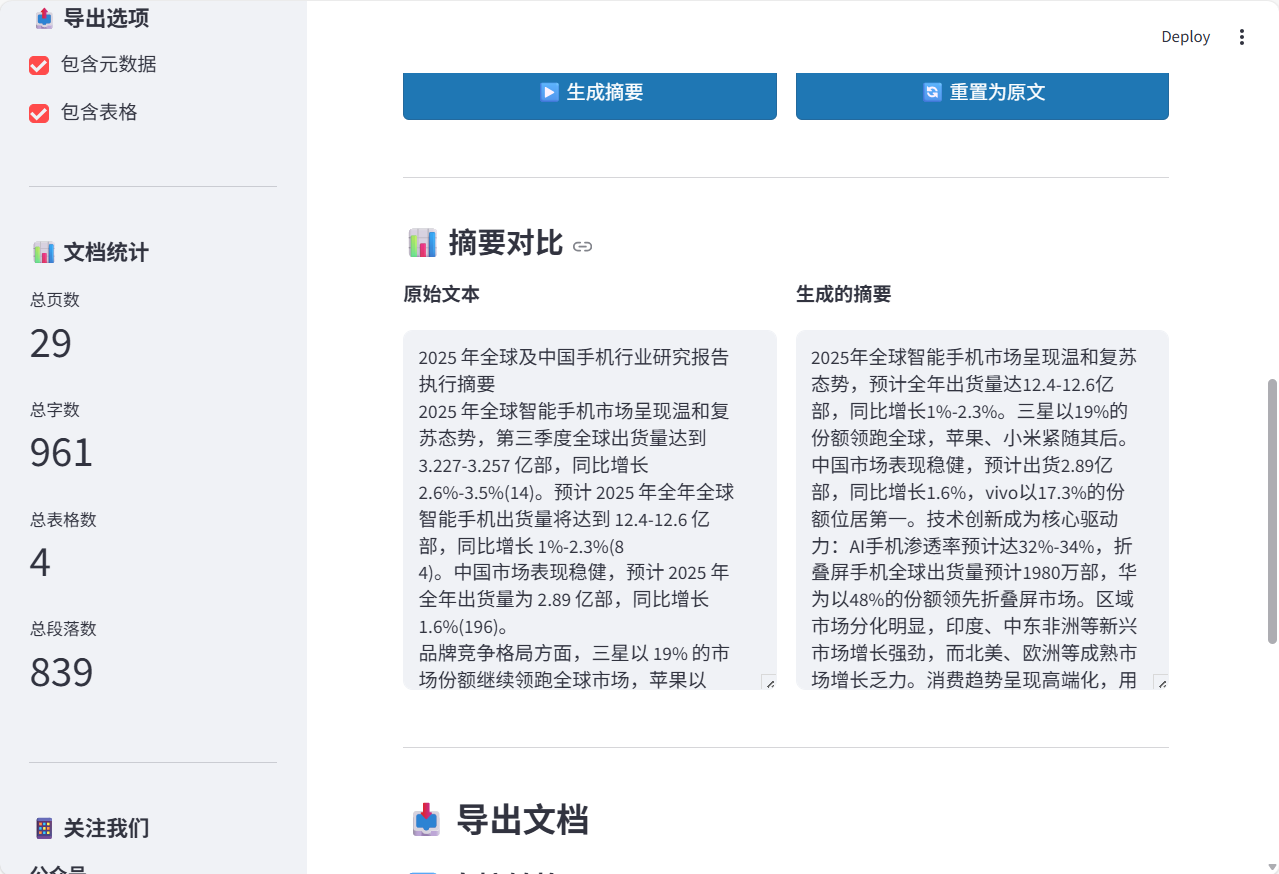
我还在这个应用里植入了DeepSeek总结功能可以提炼PDF摘要。
以上就是这个web应用的功能,应该是比较适合日常办公处理PDF。
如何安装这个应用呢?
因为它是基于Python streamlit开发的,所以会有一些依赖库,在使用前需要安装到本地电脑,包括:
# Core PDF processing
pdfplumber==0.11.0
PyPDF2==3.0.1
pdf2docx==0.5.8
# AI API integration
requests==2.31.0
openai==1.12.0
# Document generation
python-docx==1.1.0
markdown==3.5.2
# Web framework
streamlit==1.31.0
streamlit-extras==0.3.6
# Data processing
pandas==2.2.0
numpy==1.26.4
openpyxl==3.1.2
# Async processing
aiohttp==3.9.3
# Utilities
python-dotenv==1.0.1
Pillow==10.2.0
tqdm==4.66.1
# Logging
loguru==0.7.2当然这里默认你的电脑上已经安装好Python,并配置好以上依赖,然后你就可以通过以下命令进入该应用。
streamlit run app.py或者直接点击文件夹里的run批处理文件,就能直接启动应用。

我写了详细的readme,你可以根据指引来安装使用。
想要下载可以去我的Github仓库,地址如下: