大家好,又是好久不见了,今天我们来继续Linux网络的学习。上一次我们学完了自定义协议,从现在开始我们来自顶向下具体地学习一下这些协议,今天我们先来学习HTTP协议。那么话不多说,我们开始今天的学习:
目录
[应用层协议 HTTP](#应用层协议 HTTP)
[1. HTTP 协议](#1. HTTP 协议)
[2. 认识 URL](#2. 认识 URL)
[3. urlencode 和 urldecode](#3. urlencode 和 urldecode)
[4. HTTP 协议请求与响应格式](#4. HTTP 协议请求与响应格式)
[5. HTTP 的方法](#5. HTTP 的方法)
[HTTP 常见方法](#HTTP 常见方法)
[1. GET 方法(重点)](#1. GET 方法(重点))
[2. POST 方法(重点)](#2. POST 方法(重点))
[3. PUT 方法(不常用)](#3. PUT 方法(不常用))
[4. HEAD 方法](#4. HEAD 方法)
[5. DELETE 方法(不常用)](#5. DELETE 方法(不常用))
[6. OPTIONS 方法](#6. OPTIONS 方法)
[6. HTTP 的状态码](#6. HTTP 的状态码)
[7. HTTP 常见 Header](#7. HTTP 常见 Header)
[关于 connection 报头](#关于 connection 报头)
[8. 简单的 HTTP 服务器](#8. 简单的 HTTP 服务器)
[9. HTTP 历史及版本核心技术与时代背景](#9. HTTP 历史及版本核心技术与时代背景)
应用层协议****HTTP
1. HTTP****协议
首先我们先来学习HTTP协议,这是一个应用层协议,HTTP协议可用来传输视频,图片,音频等文件资源。我们之前所实现的代码也都是应用层的代码。
虽然我们说 , 应用层协议是我们程序猿自己定的 . 但实际上 , 已经有大佬们定义了一些现成的, 又非常好用的应用层协议 , 供我们直接参考使用 . HTTP( 超文本传输协议 ) 就是其中之一。
在互联网世界中, HTTP ( H yper T ext T ransfer P rotocol ,超文本传输协议)是一个至关重要的协议。它定义了客户端(如浏览器)与服务器之间如何通信,以交换或传输超文本(如 HTML 文档)。
HTTP 协议是客户端与服务器之间通信的基础。客户端通过 HTTP 协议向服务器发送请求,服务器收到请求后处理并返回响应。HTTP 协议是一个 无连接、无状态 的协议,即每次请求都需要建立新的连接,且服务器不会保存客户端的状态信息。
2. 认识****URL

这里有一个网址,平时我们俗称的 "网址" 其实就是说的 URL。
- 协议方案名 :
http://表示使用 HTTP 协议进行通信(http是超文本传输协议,://是协议与地址的分隔符)。- 登录信息(认证) :
user:pass@(可选部分)包含用户名user和密码pass,用于访问服务器时的身份认证,@是登录信息与服务器地址的分隔符。- 服务器地址 :
www.example.jp服务器的域名(也可以是 IP 地址),用于定位目标服务器。- 服务器端口号 :
:80(可选部分)指定服务器的端口,HTTP 默认端口是 80,所以这里可省略;如果是其他端口(如 HTTPS 的 443)则需明确写出。- 带层次的文件路径 :
/dir/index.htm服务器上资源的路径,指向具体的文件(这里是dir目录下的index.htm页面)。- 查询字符串 :
?uid=1#ch1
?uid=1:通过?开头,传递给服务器的参数(这里是uid参数,值为 1)。#ch1:片段标识符(锚点),用于定位页面内的特定位置(如ch1对应的章节),不会发送给服务器,仅在浏览器端解析。
再比如我们拿一个腾讯新闻的网址来分析一下:
https://news.qq.com/rain/a/20251201A03Q0H00
- 协议方案名 :
https://表示使用 HTTPS(加密的超文本传输协议),比 HTTP 更安全,://是协议与地址的分隔符。- 服务器地址 :
news.qq.com服务器的域名,对应腾讯新闻的服务器。(这里没有登录信息、端口号,因为 HTTPS 默认端口 443,无需额外指定)- 带层次的文件路径 / 资源标识 :
/rain/a/20251201A03Q0H00是服务器上该新闻资源的唯一路径,用于定位这篇具体的新闻内容。(注:这个网址没有查询字符串 和片段标识符,属于结构更简洁的资源链接)
通常在http后直接写的就是服务器域名,用来指定服务器,服务器后面写的是要访问的资源的路径,而对于一些大型且成熟的协议,它们的端口号是默认的,无需再额外指定了,比如http的端口号是80,https的端口号是443。
3. urlencode 和 urldecode
像 / ? : 等这样的字符 , 已经被 url 当做特殊意义理解了 . 因此这些字符不能随意出现 .比如, 某个参数中需要带有这些特殊字符 , 就必须先对特殊字符进行转义 .转义的规则如下:
将需要转码的字符转为 16 进制,然后从右到左,取 4 位 ( 不足 4 位直接处理 ) ,每 2 位做一位,前面加上% ,编码成 %XY 格式
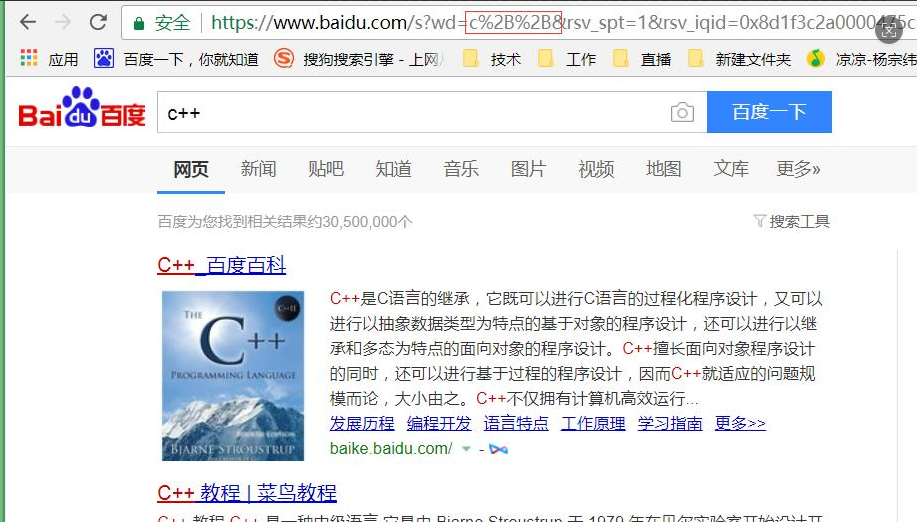
这些字符,就是具有特殊用途的字符,如果直接在 url 中出现,会导致 url 解析失败!
请求的时候,url 中如果有特殊字符,客户端(一般是浏览器)会自动给我们进行对特殊字符进行编码 encode,浏览器和服务器自己进行 urldecode
这里"+" 被转义成了 "%2B"
4. HTTP****协议请求与响应格式
HTTP 请求
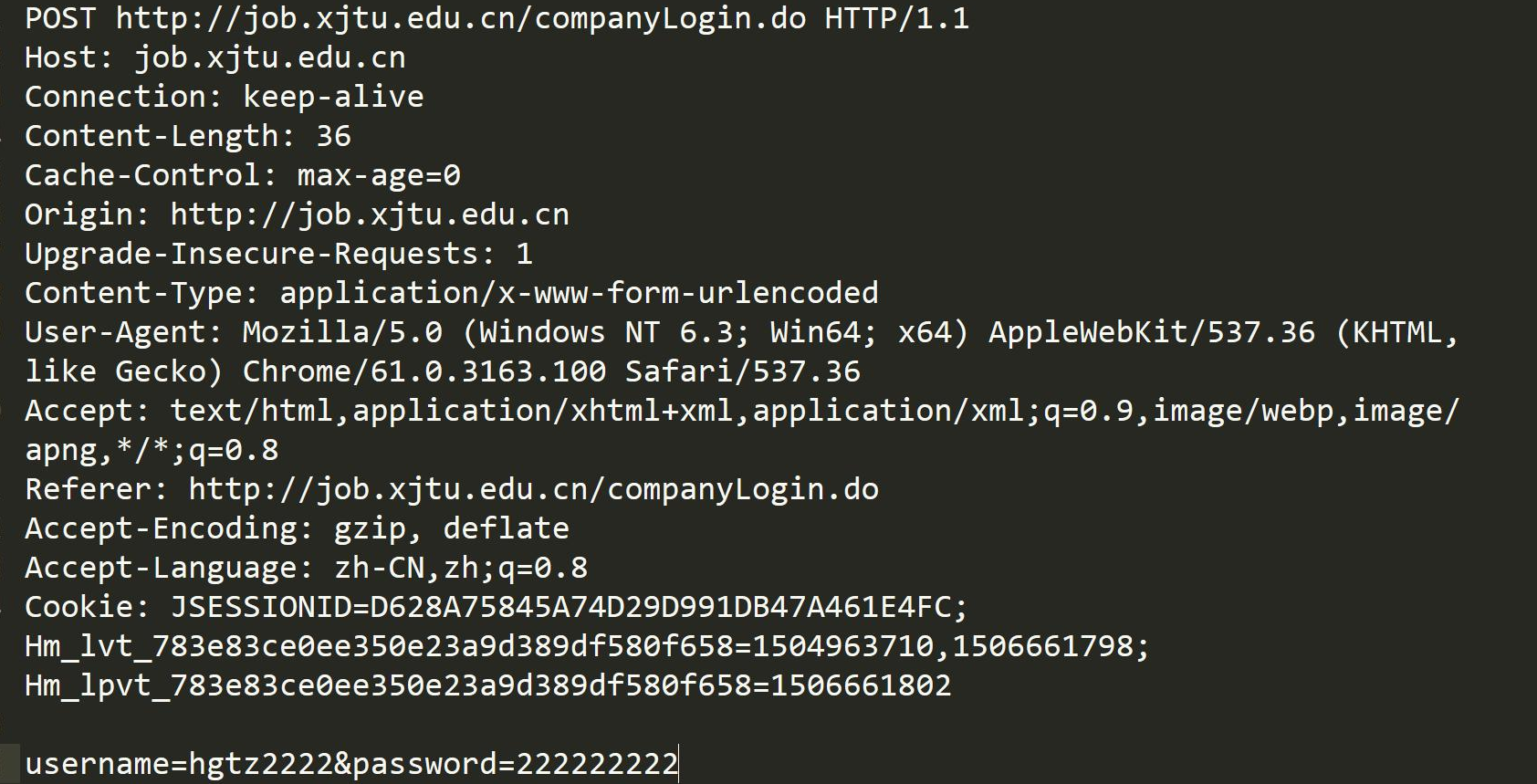
首行 : 方法 + url + 版本
- Header: 请求的属性 , 冒号分割的键值对 ; 每组属性之间使用 \r\n 分隔 ; 遇到空行表示 Header 部分结束
- Body: 空行后面的内容都是 Body. Body 允许为空字符串 . 如果 Body 存在 , 则在Header 中会有一个 Content-Length 属性来标识 Body 的长度 ;
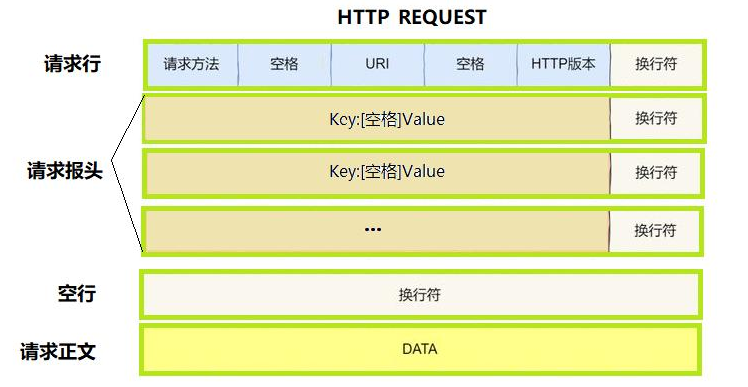
这是一个http request的报文
HTTP****响应
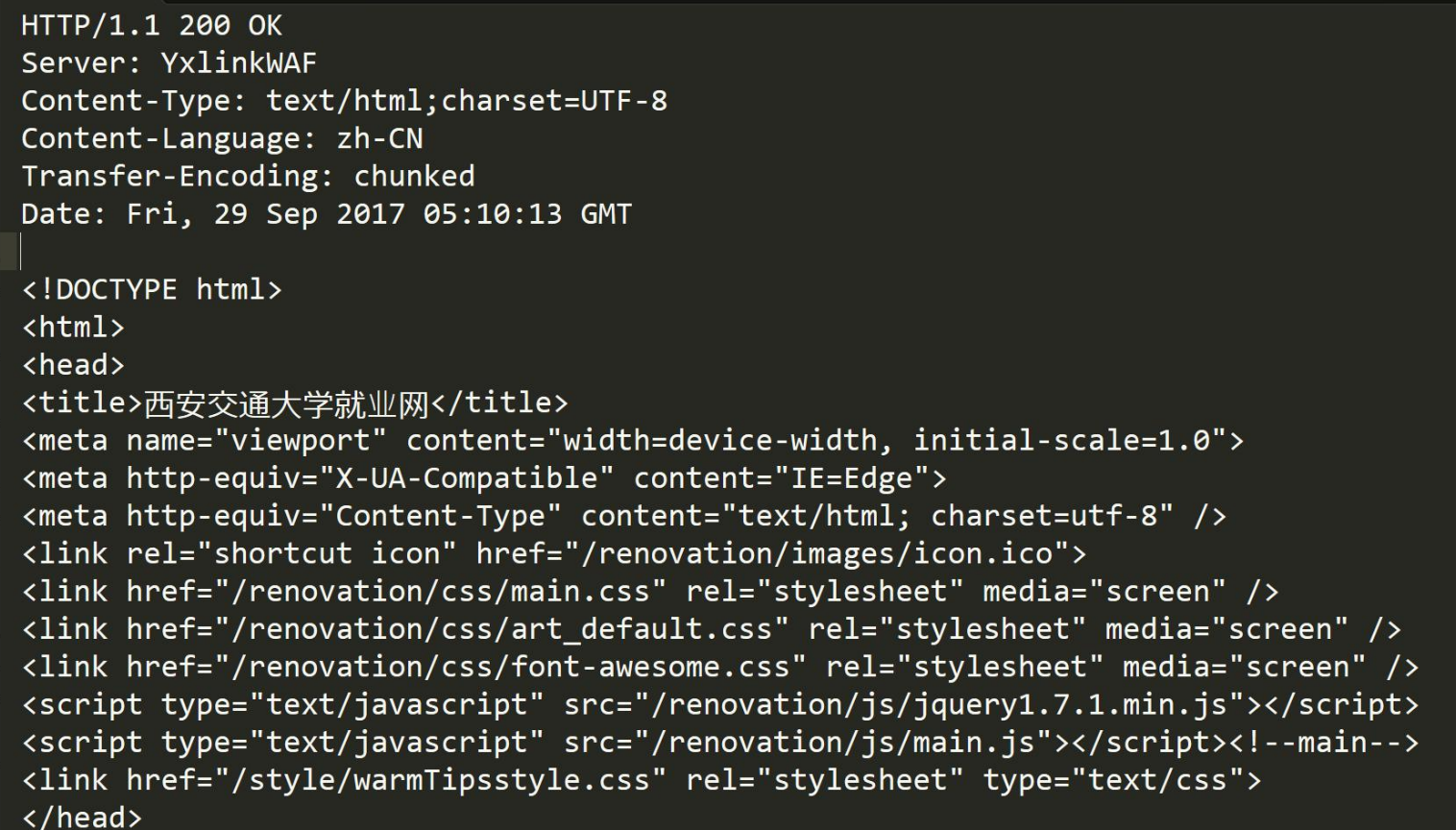
首行 : 版本号 + 状态码 + 状态码解释
- Header: 请求的属性 , 冒号分割的键值对 ; 每组属性之间使用 \r\n 分隔 ;遇到空行
表示 Header 部分结束- Body: 空行后面的内容都是 Body. Body 允许为空字符串 . 如果 Body 存在 , 则在Header 中会有一个 Content-Length 属性来标识 Body 的长度 ; 如果服务器返回了一个 html 页面 , 那么 html 页面内容就是在 body 中 .

1. HTTP 如何做到报头和有效载荷的分离?
通过 ** 空行(
\r\n\r\n)** 来分隔:
- HTTP 报文的结构是「报头 + 空行 + 有效载荷(Body)」;
- 客户端 / 服务器在解析报文时,读取到连续的换行符(
\r\n)后,就会判定 "空行已出现",空行之前的内容是报头,之后的内容是有效载荷。- 若有效载荷存在,报头中还会通过
Content-Length等字段标识其长度,辅助解析。2. HTTP 协议如何理解?
HTTP 是应用层的请求 - 响应协议,核心是 "客户端发请求、服务器回响应",可以从这几点理解:
- 结构:请求 / 响应都由「起始行 + 报头 + 空行 + 有效载荷」组成;
- 无状态:默认不记录请求的上下文,需用 Cookie/Session 维持状态;
- 灵活传输 :通过
Content-Type支持 HTML、JSON、图片等多种数据类型;- 版本演进:从 HTTP/0.9(仅 GET)到 HTTP/3(基于 QUIC),不断优化性能和安全。
3. HTTP 协议的序列化和反序列化,在哪里表现?
序列化(把数据转成 HTTP 报文格式)、反序列化(把 HTTP 报文解析为数据),体现在客户端 / 服务器的报文处理过程中:
- 序列化 :客户端构建请求时,将 "请求方法、URL、参数" 按 HTTP 格式拼接(例:把
GET /index.html HTTP/1.1+ 报头 + 空行 + Body 拼接成字符串);- 反序列化 :服务器接收请求后,按
\r\n拆分报文,解析出请求行、报头、Body(例:从报文中提取Host、Content-Length等字段)。- 这一过程依赖 HTTP 的文本格式和特殊分隔符(
\r\n、空格),无需额外库即可实现。
5. HTTP****的方法
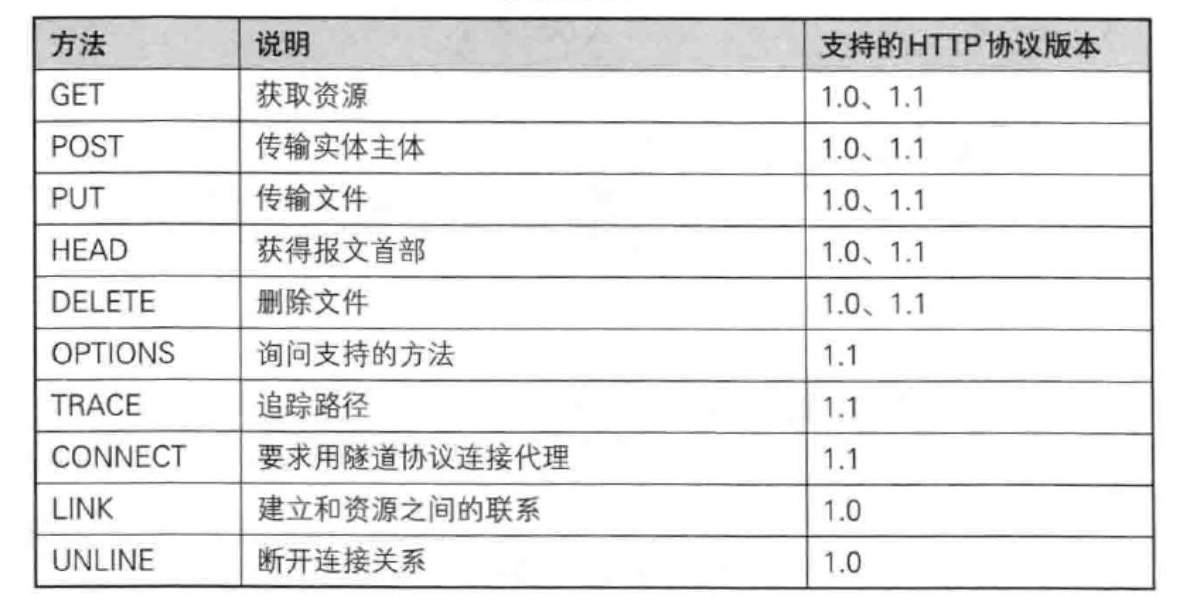
其中最常用的就是 GET 方法和 POST 方法
HTTP****常见方法
1. GET****方法(重点)
用途:用于请求 URL 指定的资源。
示例: GET /index.html HTTP/1.1
特性:指定资源经服务器端解析后返回响应内容。
form 表单: https://www.runoob.com/html/html-forms.html
std::string GetFileContentHelper(const std::string &path)
{
// 一份简单的读取二进制文件的代码
std::ifstream in(path, std::ios::binary);
//用std::ifstream(输入文件流)打开路径path对应的文件;
//std::ios::binary表示以二进制模式读取(避免文本模式下的换行符转换,保证文件内容准确)。
if (!in.is_open())
return "";
in.seekg(0, in.end); // 将文件指针移动到文件末尾
int filesize = in.tellg(); // 获取当前指针位置(即文件总大小)
in.seekg(0, in.beg); // 将文件指针移回文件开头
std::string content;
content.resize(filesize); // 预先分配足够的内存(避免多次扩容)
in.read((char *)content.c_str(), filesize); // 把文件内容读取到content中
// std::vector<char> content(filesize);
// in.read(content.data(), filesize);
in.close();
return content;
}这个函数可以用来读取 web 目录下的文件(比如 HTML、CSS、图片等),将文件内容作为 HTTP 响应的 Body 返回给客户端(比如处理 GET 请求时,返回网页文件的内容)。
form表单它是网页里用来收集用户输入并提交给服务器的工具,是用户和网站交互的核心组件之一。作用:让用户输入信息(比如登录的账号密码、搜索关键词、注册信息),然后把这些信息发送给服务器处理(比如登录验证、搜索结果查询)。
组成 :由
<form>标签包裹各种输入控件(文本框、密码框、按钮等),常见结构是:
<form action="服务器地址" method="提交方式(GET/POST)"> <!-- 输入框、按钮等控件 --> 用户名: <input type="text" name="username"> 密码: <input type="password" name="password"> <input type="submit" value="提交"> </form>和 HTTP 方法的关系 :表单可以用
GET或POST方式提交数据(对应你之前看到的 "GET 方法"),比如用GET提交时,数据会附加在 URL 后面(像图里的GET /index.html HTTP/1.1)。
2. POST****方法(重点)
用途:用于传输实体的主体,通常用于提交表单数据。
示例: POST /submit.cgi HTTP/1.1
特性:可以发送大量的数据给服务器,并且数据包含在请求体中。
form 表单: https://www.runoob.com/html/html-forms.htm
下面是GET和POST两种方法的比较:
| 特性 | POST 方法 | GET 方法 |
|---|---|---|
| 数据位置 | 请求体(Body) | URL 查询字符串(?key=val) |
| 数据大小 | 无限制(取决于服务器配置) | 有限制(通常几 KB) |
| 安全性 | 相对安全(不暴露在 URL) | 不安全(URL 可见) |
| 主要用途 | 提交数据(表单、上传) | 获取资源(查询、浏览) |
3. PUT****方法(不常用)
用途:用于传输文件,将请求报文主体中的文件保存到请求 URL 指定的位置。
示例: PUT /example.html HTTP/1.1
特性:不太常用,但在某些情况下,如 RESTful API 中,用于更新资源。
4. HEAD****方法
用途:与 GET 方法类似,但不返回报文主体部分,仅返回响应头。
示例: HEAD /index.html HTTP/1.1
特性:用于确认 URL 的有效性及资源更新的日期时间等。
5. DELETE****方法(不常用)
用途:用于删除文件,是 PUT 的相反方法。
示例: DELETE /example.html HTTP/1.1
特性:按请求 URL 删除指定的资源。
6. OPTIONS****方法
用途:用于查询针对请求 URL 指定的资源支持的方法。
示例: OPTIONS * HTTP/1.1
特性:返回允许的方法,如 GET 、 POST 等。
6. HTTP****的状态码
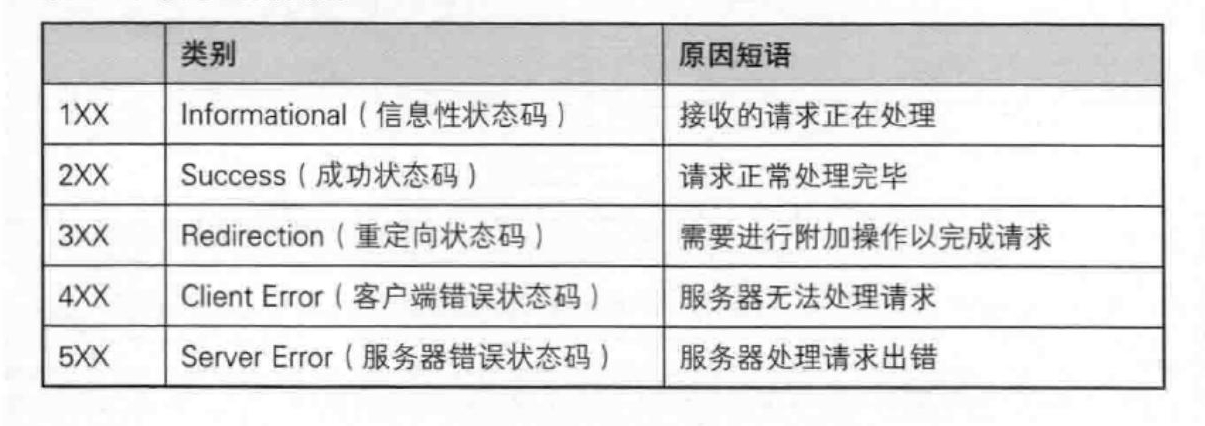
最常见的状态码 , 比如 200(OK), 404(Not Found), 403(Forbidden), 302(Redirect, 重定
向 ), 504(Bad Gateway)
| 状态码 | 含义 | 应用样例 | |
|---|---|---|---|
| 100 | Continue | 上传大文件时,服务器告诉客户端可以继续上传 | |
| 200 | OK | 访问网站首页,服务器返回网页内容 | |
| 201 | Created | 发布新文章,服务器返回文章创建成功的信息 | |
| 204 | No Content | 删除文章后,服务器返回 "无内容" 表示操作成功 | |
| 301 | Moved Permanently | 网站换域名后,自动跳转到新域名;搜索引擎更新网站链接时使用 | |
| 302 | Found 或 See Other | 用户登录成功后,重定向到用户首页 | |
| 304 | Not Modified | 浏览器缓存机制,对未修改的资源返回 304 状态码 | |
| 400 | Bad Request | 填写表单时,格式不正确导致提交失败 | |
| 401 | Unauthorized | 访问需要登录的页面时,未登录或认证失败 | |
| 403 | Forbidden | 尝试访问你没有权限查看的页面 | |
| 404 | Not Found | 访问不存在的网页链接 | |
| 500 | Internal Server Error | 服务器崩溃或数据库错误导致页面无法加载 | |
| 502 | Bad Gateway | 使用代理服务器时,代理服务器无法从上游服务器获取有效响应 | |
| 503 | Service Unavailable | 服务器维护或过载,暂时无法处理请求 | |
| 301 | Moved Permanently | 否(永久重定向) | 网站换域名后,自动跳转到新域名;搜索引擎更新网站链接时使用 |
| 302 | Found 或 See Other | 是(临时重定向) | 用户登录成功后,重定向到用户首页 |
| 307 | Temporary Redirect | 是(临时重定向) | 临时重定向资源到新的位置(较少使用) |
| 308 | Permanent Redirect | 否(永久重定向) | 永久重定向资源到新的位置(较少使用) |
HTTP 状态码 301 (永久重定向)和 302 (临时重定向)都依赖 Location 选项 。以下
是关于两者依赖 Location 选项的详细说明:
HTTP 状态码 301 (永久重定向) :
当服务器返回 HTTP 301 状态码时,表示请求的资源已经被永久移动到新的位置。
在这种情况下,服务器会在响应中添加一个 Location 头部,用于指定资源的新位置。这个 Location 头部包含了新的 URL 地址,浏览器会自动重定向到该地址。
例如,在 HTTP 响应中,可能会看到类似于以下的头部信息:
HTTP/1.1 301 Moved Permanently\r\n Location: https://www.new-url.com\r\n
HTTP 状态码 302 (临时重定向) :
当服务器返回 HTTP 302 状态码时,表示请求的资源临时被移动到新的位置。
同样地,服务器也会在响应中添加一个 Location 头部来指定资源的新位置。浏览器会暂时使用新的 URL 进行后续的请求,但不会缓存这个重定向。
例如,在 HTTP 响应中,可能会看到类似于以下的头部信息:
HTTP/1.1 302 Found\r\n Location: https://www.new-url.com\r\n
总结 :无论是 HTTP 301 还是 HTTP 302 重定向,都需要依赖 Location 选项来指定资源的新位置。这个 Location 选项是一个标准的 HTTP 响应头部,用于告诉浏览器应该将请求重定向到哪个新的 URL 地址。
7. HTTP常见Header
Content-Type: 数据类型 (text/html 等 )
Content-Length: Body 的长度
Host: 客户端告知服务器 , 所请求的资源是在哪个主机的哪个端口上 ;
User-Agent: 声明用户的操作系统和浏览器版本信息 ;
referer: 当前页面是从哪个页面跳转过来的 ;
Location: 搭配 3xx 状态码使用 , 告诉客户端接下来要去哪里访问 ;
Cookie: 用于在客户端存储少量信息 . 通常用于实现会话 (session) 的功能 ;
关于connection报头
HTTP 中的 Connection 字段是 HTTP 报文头的一部分,它主要用于控制和管理客户端与服务器之间的连接状态
核心作用
管理持久连接 : Connection 字段还用于管理持久连接(也称为长连接)。持久连接允许客户端和服务器在请求/ 响应完成后不立即关闭 TCP 连接,以便在同一个连接上发送多个请求和接收多个响应。
持久连接(长连接)
HTTP/1.1 :在 HTTP/1.1 协议中,默认使用持久连接。当客户端和服务器都不明确指定关闭连接时,连接将保持打开状态,以便后续的请求和响应可以复用同一个连接。
HTTP/1.0 :在 HTTP/1.0 协议中,默认连接是非持久的。如果希望在 HTTP/1.0上实现持久连接,需要在请求头中显式设置 Connection: keep-alive 。
语法格式
Connection: keep-alive:表示希望保持连接以复用 TCP 连接。 Connection: close:表示请求/响应完成后,应该关闭 TCP 连接。
下面附上一张关于 HTTP 常见 header 的表格:
| 字段名 | 含义说明 | 典型样例 |
|---|---|---|
| 请求头字段 | ||
| Accept | 客户端可接受的响应内容类型(用于协商返回格式) | Accept: text/html,application/xhtml+xml,image/webp,*/*;q=0.8 |
| Accept-Encoding | 客户端支持的数据压缩格式(减少传输体积) | Accept-Encoding: gzip, deflate, br |
| Accept-Language | 客户端偏好的语言类型(用于返回对应语言内容) | Accept-Language: zh-CN,zh;q=0.9,en;q=0.8 |
| Host | 请求的目标主机名 + 端口(HTTP/1.1 必填,用于服务器区分虚拟主机) | Host: www.example.com:8080 |
| User-Agent | 客户端的软件环境信息(服务器可据此适配内容) | User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/91.0.4472.124 |
| Cookie | 客户端向服务器传递的会话信息(维持登录状态等) | Cookie: session_id=abcdefg12345; user_id=123 |
| Referer | 请求的来源 URL(用于统计、防盗链) | Referer: http://www.example.com/previous_page.html |
| Content-Type | 请求体的媒体类型(说明提交数据的格式) | Content-Type: application/x-www-form-urlencoded(表单)/application/json(JSON) |
| Content-Length | 请求体的字节大小(帮助服务器确定数据边界) | Content-Length: 150 |
| Authorization | 客户端的认证信息(如账号密码的 Base64 编码) | Authorization: Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ== |
| Cache-Control | 缓存控制指令(控制请求 / 响应的缓存策略) | Cache-Control: no-cache(请求)/Cache-Control: public, max-age=3600(响应) |
| Connection | 控制连接的保持 / 关闭(HTTP/1.1 默认 keep-alive) | Connection: keep-alive/Connection: close |
| 响应头字段 | ||
| Date | 请求 / 响应的日期时间(用于时间同步、缓存判断) | Date: Wed, 21 Oct 2023 07:28:00 GMT |
| Location | 重定向的目标 URL(与 3xx 状态码配合使用) | Location: http://www.example.com/new_location.html(配合 302) |
| Server | 服务器的软件类型(标识服务器环境) | Server: Apache/2.4.41 (Unix) |
| Last-Modified | 资源的最后修改时间(用于缓存验证) | Last-Modified: Wed, 21 Oct 2023 07:28:00 GMT |
| ETag | 资源的唯一标识符(更精确的缓存验证,避免时间判断误差) | ETag: "3f80f-1b6-5f4e2512a4100" |
| Expires | 响应的过期时间(早期缓存策略,优先级低于 Cache-Control) | Expires: Wed, 21 Oct 2023 08:28:00 GMT |
以下是一个简单的http服务器封装代码:
8. 简单的HTTP服务器
Http.hpp:
#pragma once
#include "Socket.hpp"
#include "TcpServer.hpp"
#include "Util.hpp"
#include "Log.hpp"
#include <iostream>
#include <string>
#include <memory>
#include <sstream>
#include <functional>
#include <unordered_map>
using namespace SocketModule;
using namespace LogModule;
const std::string gspace = " ";
const std::string glinespace = "\r\n";
const std::string glinesep = ": ";
const std::string webroot = "./wwwroot";
const std::string homepage = "index.html";
const std::string page_404 = "/404.html";
class HttpRequest
{
public:
HttpRequest() : _is_interact(false)
{
}
std::string Serialize()
{
return std::string();
}
void ParseReqLine(std::string &reqline)
{
// GET / HTTP/1.1
std::stringstream ss(reqline);
ss >> _method >> _uri >> _version;
}
// 实现, 我们今天认为,reqstr是一个完整的http request string
bool Deserialize(std::string &reqstr)
{
// 1. 提取请求行
std::string reqline;
bool res = Util::ReadOneLine(reqstr, &reqline, glinespace);
LOG(LogLevel::DEBUG) << reqline;
// 2. 对请求行进行反序列化
ParseReqLine(reqline);
if (_uri == "/")
_uri = webroot + _uri + homepage; // ./wwwroot/index.html
else
_uri = webroot + _uri; // ./wwwroot/a/b/c.html
LOG(LogLevel::DEBUG) << "_method: " << _method;
LOG(LogLevel::DEBUG) << "_uri: " << _uri;
LOG(LogLevel::DEBUG) << "_version: " << _version;
const std::string temp = "?";
auto pos = _uri.find(temp);
if (pos == std::string::npos)
{
return true;
}
// _uri: ./wwwroot/login
// username=zhangsan&password=123456
_args = _uri.substr(pos + temp.size());
_uri = _uri.substr(0, pos);
_is_interact = true;
// ./wwwroot/XXX.YYY
return true;
}
std::string Uri()
{
return _uri;
}
bool isInteract()
{
return _is_interact;
}
std::string Args()
{
return _args;
}
~HttpRequest()
{
}
private:
std::string _method;
std::string _uri;
std::string _version;
std::unordered_map<std::string, std::string> _headers;
std::string _blankline;
std::string _text;
std::string _args;
bool _is_interact;
};
class HttpResponse
{
public:
HttpResponse() : _blankline(glinespace), _version("HTTP/1.0")
{
}
// 实现: 成熟的http,应答做序列化,不要依赖任何第三方库!
std::string Serialize()
{
std::string status_line = _version + gspace + std::to_string(_code) + gspace + _desc + glinespace;
std::string resp_header;
for (auto &header : _headers)
{
std::string line = header.first + glinesep + header.second + glinespace;
resp_header += line;
}
return status_line + resp_header + _blankline + _text;
}
void SetTargetFile(const std::string &target)
{
_targetfile = target;
}
void SetCode(int code)
{
_code = code;
switch (_code)
{
case 200:
_desc = "OK";
break;
case 404:
_desc = "Not Found";
break;
case 301:
_desc = "Moved Permanently";
break;
case 302:
_desc = "See Other";
break;
default:
break;
}
}
void SetHeader(const std::string &key, const std::string &value)
{
auto iter = _headers.find(key);
if (iter != _headers.end())
return;
_headers.insert(std::make_pair(key, value));
}
std::string Uri2Suffix(const std::string &targetfile)
{
// ./wwwroot/a/b/c.html
auto pos = targetfile.rfind(".");
if (pos == std::string::npos)
{
return "text/html";
}
std::string suffix = targetfile.substr(pos);
if (suffix == ".html" || suffix == ".htm")
return "text/html";
else if (suffix == ".jpg")
return "image/jpeg";
else if (suffix == "png")
return "image/png";
else
return "";
}
bool MakeResponse()
{
if (_targetfile == "./wwwroot/favicon.ico")
{
LOG(LogLevel::DEBUG) << "用户请求: " << _targetfile << "忽略它";
return false;
}
if (_targetfile == "./wwwroot/redir_test")
{
SetCode(301);
SetHeader("Location", "https://www.qq.com/");
return true;
}
int filesize = 0;
bool res = Util::ReadFileContent(_targetfile, &_text); // 浏览器请求的资源,一定会存在吗?出错呢?
if (!res)
{
_text = "";
LOG(LogLevel::WARNING) << "client want get : " << _targetfile << " but not found";
SetCode(404);
_targetfile = webroot + page_404;
filesize = Util::FileSize(_targetfile);
Util::ReadFileContent(_targetfile, &_text);
std::string suffix = Uri2Suffix(_targetfile);
SetHeader("Content-Type", suffix);
SetHeader("Content-Length", std::to_string(filesize));
// SetCode(302);
// SetHeader("Location", "http://8.137.19.140:8080/404.html");
// return true;
}
else
{
LOG(LogLevel::DEBUG) << "读取文件: " << _targetfile;
SetCode(200);
filesize = Util::FileSize(_targetfile);
std::string suffix = Uri2Suffix(_targetfile);
SetHeader("Conent-Type", suffix);
SetHeader("Content-Length", std::to_string(filesize));
SetHeader("Set-Cookie", "username=zhangsan;");
// SetHeader("Set-Cookie", "passwd=123456;");
}
return true;
}
void SetText(const std::string &t)
{
_text = t;
}
bool Deserialize(std::string &reqstr)
{
return true;
}
~HttpResponse() {}
// private:
public:
std::string _version;
int _code; // 404
std::string _desc; // "Not Found"
std::unordered_map<std::string, std::string> _headers;
std::vector<std::string> cookie;
std::string _blankline;
std::string _text;
// 其他属性
std::string _targetfile;
};
using http_func_t = std::function<void(HttpRequest &req, HttpResponse &resp)>;
// 1. 返回静态资源
// 2. 提供动态交互的能力
class Http
{
public:
Http(uint16_t port) : tsvrp(std::make_unique<TcpServer>(port))
{
}
void HandlerHttpRquest(std::shared_ptr<Socket> &sock, InetAddr &client)
{
// 收到请求
std::string httpreqstr;
// 假设:概率大,读到了完整的请求
// bug!
int n = sock->Recv(&httpreqstr); // 浏览器给我发过来的是一个大的http字符串, 其实我们的recv也是有问题的。tcp是面向字节流的.
if (n > 0)
{
std::cout << "##########################" << std::endl;
std::cout << httpreqstr;
std::cout << "##########################" << std::endl;
// 对报文完整性进行审核 -- 缺
// 所以,今天,我们就不在担心,用户访问一个服务器上不存在的资源了.
// 我们更加不担心,给用户返回任何网页资源(html, css, js, 图片,视频)..., 这种资源,静态资源!!
HttpRequest req;
HttpResponse resp;
req.Deserialize(httpreqstr);
if (req.isInteract())
{
// _uri: ./wwwroot/login
if (_route.find(req.Uri()) == _route.end())
{
// SetCode(302)
}
else
{
_route[req.Uri()](req, resp);
std::string response_str = resp.Serialize();
sock->Send(response_str);
}
}
else
{
resp.SetTargetFile(req.Uri());
if (resp.MakeResponse())
{
std::string response_str = resp.Serialize();
sock->Send(response_str);
}
}
// HttpResponse resp;
// resp._version = "HTTP/1.1";
// resp._code = 200; // success
// resp._desc = "OK";
// //./wwwroot/a/b/c.html
// LOG(LogLevel::DEBUG) << "用户请求: " << filename;
// bool res = Util::ReadFileContent(filename, &(resp._text)); // 浏览器请求的资源,一定会存在吗?出错呢?
// (void)res;
}
// #ifndef DEBUG
// #define DEBUG
#ifdef DEBUG
// 收到请求
std::string httpreqstr;
// 假设:概率大,读到了完整的请求
sock->Recv(&httpreqstr); // 浏览器给我发过来的是一个大的http字符串, 其实我们的recv也是有问题的。tcp是面向字节流的.
std::cout << httpreqstr;
// 直接构建http应答. 内存级别+固定
HttpResponse resp;
resp._version = "HTTP/1.1";
resp._code = 200; // success
resp._desc = "OK";
std::string filename = webroot + homepage; // "./wwwroot/index.html";
bool res = Util::ReadFileContent(filename, &(resp._text));
(void)res;
std::string response_str = resp.Serialize();
sock->Send(response_str);
#endif
// 对请求字符串,进行反序列化
}
void Start()
{
tsvrp->Start([this](std::shared_ptr<Socket> &sock, InetAddr &client)
{ this->HandlerHttpRquest(sock, client); });
}
void RegisterService(const std::string name, http_func_t h)
{
std::string key = webroot + name; // ./wwwroot/login
auto iter = _route.find(key);
if (iter == _route.end())
{
_route.insert(std::make_pair(key, h));
}
}
~Http()
{
}
private:
std::unique_ptr<TcpServer> tsvrp;
std::unordered_map<std::string, http_func_t> _route;
};Util.hpp:
#pragma once
#include <iostream>
#include <fstream>
#include <string>
// 工具类
class Util
{
public:
static bool ReadFileContent(const std::string &filename /*std::vector<char>*/, std::string *out)
{
// version1: 默认是以文本方式读取文件的. 图片是二进制的.
// std::ifstream in(filename);
// if (!in.is_open())
// {
// return false;
// }
// std::string line;
// while(std::getline(in, line))
// {
// *out += line;
// }
// in.close();
// version2 : 以二进制方式进行读取
int filesize = FileSize(filename);
if(filesize > 0)
{
std::ifstream in(filename);
if(!in.is_open())
return false;
out->resize(filesize);
in.read((char*)(out->c_str()), filesize);
in.close();
}
else
{
return false;
}
return true;
}
static bool ReadOneLine(std::string &bigstr, std::string *out, const std::string &sep/*\r\n*/)
{
auto pos = bigstr.find(sep);
if(pos == std::string::npos)
return false;
*out = bigstr.substr(0, pos);
bigstr.erase(0, pos + sep.size());
return true;
}
static int FileSize(const std::string &filename)
{
std::ifstream in(filename, std::ios::binary);
if(!in.is_open())
return -1;
in.seekg(0, in.end);
int filesize = in.tellg();
in.seekg(0, in.beg);
in.close();
return filesize;
}
};#include "Http.hpp"
void Login(HttpRequest &req, HttpResponse &resp)
{
// req.Args();
LOG(LogLevel::DEBUG) << req.Args() << ", 我们成功进入到了处理数据的逻辑";
std::string text = "hello: " + req.Args(); // username=zhangsan&passwd=123456
// 登录认证
resp.SetCode(200);
resp.SetHeader("Content-Type","text/plain");
resp.SetHeader("Content-Length", std::to_string(text.size()));
resp.SetText(text);
}
// void Register(HttpRequest &req, HttpResponse &resp)
// {
// LOG(LogLevel::DEBUG) << req.Args() << ", 我们成功进入到了处理数据的逻辑";
// std::string text = "hello: " + req.Args();
// resp.SetCode(200);
// resp.SetHeader("Content-Type","text/plain");
// resp.SetHeader("Content-Length", std::to_string(text.size()));
// resp.SetText(text);
// }
// void VipCheck(HttpRequest &req, HttpResponse &resp)
// {
// LOG(LogLevel::DEBUG) << req.Args() << ", 我们成功进入到了处理数据的逻辑";
// std::string text = "hello: " + req.Args();
// resp.SetCode(200);
// resp.SetHeader("Content-Type","text/plain");
// resp.SetHeader("Content-Length", std::to_string(text.size()));
// resp.SetText(text);
// }
// void Search(HttpRequest &req, HttpResponse &resp)
// {
// }
// http port
int main(int argc, char *argv[])
{
if(argc != 2)
{
std::cout << "Usage: " << argv[0] << " port" << std::endl;
exit(USAGE_ERR);
}
uint16_t port = std::stoi(argv[1]);
std::unique_ptr<Http> httpsvr = std::make_unique<Http>(port);
httpsvr->RegisterService("/login", Login); //
// httpsvr->RegisterService("/register", Register);
// httpsvr->RegisterService("/vip_check", VipCheck);
// httpsvr->RegisterService("/s", Search);
// httpsvr->RegisterService("/", Login);
httpsvr->Start();
return 0;
}其余代码都是以前做过的封装,就不再重复展示了。
9. HTTP****历史及版本核心技术与时代背景
HTTP ( Hypertext Transfer Protocol ,超文本传输协议)作为互联网中浏览器和服务器间通信的基石,经历了从简单到复杂、从单一到多样的发展过程。以下将按照时间顺序,介绍 HTTP 的主要版本、核心技术及其对应的时代背景。
HTTP/0.9
核心技术 :
仅支持 GET 请求方法。
仅支持纯文本传输,主要是 HTML 格式。
无请求和响应头信息。
时代背景 :
1991 年, HTTP/0.9 版本作为 HTTP 协议的最初版本,用于传输基本的超文本HTML 内容。
当时的互联网还处于起步阶段,网页内容相对简单,主要以文本为主。
HTTP/1.0
核心技术 :
引入 POST 和 HEAD 请求方法。
请求和响应头信息,支持多种数据格式( MIME )。
支持缓存( cache )。
状态码( status code )、多字符集支持等。
时代背景 :
1996 年,随着互联网的快速发展,网页内容逐渐丰富, HTTP/1.0 版本应运而生。
为了满足日益增长的网络应用需求, HTTP/1.0 增加了更多的功能和灵活性。
然而, HTTP/1.0 的工作方式是每次 TCP 连接只能发送一个请求,性能上存在一定局限。
HTTP/1.1
核心技术 :
引入持久连接( persistent connection ),支持管道化( pipelining )。
允许在单个 TCP 连接上进行多个请求和响应,提高了性能。
引入分块传输编码( chunked transfer encoding )。
支持 Host 头,允许在一个 IP 地址上部署多个 Web 站点。
时代背景 :
1999 年,随着网页加载的外部资源越来越多, HTTP/1.0 的性能问题愈发突出。
HTTP/1.1 通过引入持久连接和管道化等技术,有效提高了数据传输效率。
同时,互联网应用开始呈现出多元化、复杂化的趋势, HTTP/1.1 的出现满足了这些需求。
HTTP/2.0
核心技术 :
多路复用( multiplexing ),一个 TCP 连接允许多个 HTTP 请求。
二进制帧格式( binary framing ),优化数据传输。
头部压缩( header compression ),减少传输开销。
服务器推送( server push ),提前发送资源到客户端。
时代背景 :
2015 年,随着移动互联网的兴起和云计算技术的发展,网络应用对性能的要求越来越高。
HTTP/2.0 通过多路复用、二进制帧格式等技术,显著提高了数据传输效率和网络性能。
同时, HTTP/2.0 还支持加密传输( HTTPS ),提高了数据传输的安全性。
HTTP/3.0
核心技术 :
使用 QUIC 协议替代 TCP 协议,基于 UDP 构建的多路复用传输协议。
减少了 TCP 三次握手及 TLS 握手时间,提高了连接建立速度。
解决了 TCP 中的线头阻塞问题,提高了数据传输效率。
时代背景 :
2022 年,随着 5G 、物联网等技术的快速发展,网络应用对实时性、可靠性的要求越来越高。
HTTP/3.0 通过使用 QUIC 协议,提高了连接建立速度和数据传输效率,满足了这些需求。
同时, HTTP/3.0 还支持加密传输( HTTPS ),保证了数据传输的安全性。
好了,以上就是今天关于http的内容,觉得有收获的话还请多多点赞收藏,那么我们下次再见!