noitce:
学习从14到19章的时候发现都是MySQL的一些优化相关的学习,个人认为不是特别核心于是就先跳过到后面几章的内容开始学习了
第19章 事务简介
事务的起源
对于coder来说,主要任务就是将显示世界中的要做的事情映射到计算中对应的数据库中进行处理
个人思考:好像很久之前学习On Java的时候作者也这样说过,当时还是不是很明白,现在完全理解了!!
映射的关键就是抓住现实世界中的事情状态的转换规则,如果数据库实现了这些规则,那么这不就成功映射上了吗!
比如对银行账户中的钱进行修改,修改一次就需要更新一次状态,现实生活中是自动随着行动的发生更新的,但是数据库中就不一样了,必须满足规则更新状态才行
主要规则:
原子性
转账只有两种可能:转了或者没有转,不可能有中间的状态
这种要么全部实现要么干脆不做的规则叫做原子性,也就是一不做二不休嘛
这种映射到数据库中就会牵扯到很多相关的操作,比如缓存和磁盘刷新等等,如果中间任何一个环节出了问题,那么就会导致卡在中间的状态:破坏了原子性
于是需要设计一些机制来保证如果发生错误的恢复
隔离性
现实中的两次状态转换是不会相互影响的,可以理解为是独立的两个过程
但是在数据库中这些只是一些执行的语句而已,既然是语句的执行那么就有可能交替执行语句
比如狗哥给猫爷同时转账两次5元钱:
现实中理应是可以同时进行的,再次也是分两步相互不影响的转账,最终猫爷都是得到了10元钱
理想中的数据库操作:
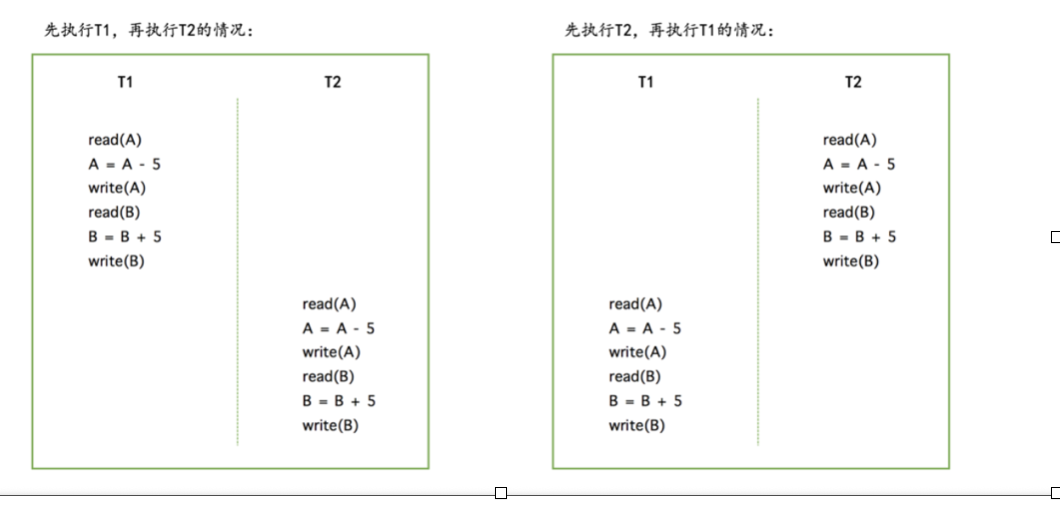
但是在数据库中可能会出现这样:(假设一开始狗哥有11元钱)

像这第二种情况就是不应该出现的错误情况,我们需要保证其他的状态转换不会影响到本次的状态转换。需要进行顺序性相关的操作来保证隔离性
一致性
数据不可以是随便的,当然如果你是随便插入什么数据当然可以。但是如果是正常的业务流程,对现实世界的映射的话,那么就需要数据库的数据符合现实生活中的约束
这种符合约束我们叫做符合一致性原则
数据库本身可以实现一致性操作,比如建立表的时候声明主键,拒绝NULL值的插入等等
但是更多的一致性需要自己手动保证才行,需要手动写一些表达式提前判断操作是否执行(防止破坏一致性原则)
原子性和隔离性都会对一致性产生影响。可以说原子性和隔离性都是保证一致性的两种手段,但是这两种都是在逻辑上的角度来的:比如狗哥本身没有钱,但是转了10元给猫爷,那么狗哥的账户不就是负数了嘛,这样也不行,因为不符合现实要求。
因此满足一致性出了需要满足原子性和隔离性,还需要符合现实的要求才行
持久性
状态转换的结果,如果没有再修改那么就是永久保留的,比如转账转成功了那么金额就一直是转账成功的那个状态的金额,除非你再次转账之类的
映射到数据库就是持久性:所有的操作都应该在磁盘上保留下里啊,后续的任何事故都不应该对本次的转换得到的状态产生影响
事务的概念
将现实生活中的操作映射到数据库中,需要满足4个原则:
原子性,隔离性,一致性,持久性
也就是ACID:酸的
MySQL设计师将满足这些条件的数据库操作称之为一个事务(transaction)
事务就是一个抽象的概念,简单来说就是做符合现实的数据库操作
执行事务可以分成几个阶段:
(1)活动的
正在执行的操作,称事务处在活动的状态
(2)部分提交
事务的最后一步完成的时候,即将从内存中将结果刷新到磁盘,这个时候称之为部分提交的状态
(3)失败的
处于活动的或者部分提交状态的事务,发生意外了导致事务不可以继续进行,就说事务处于失败状态
(4)中止的
事务执行了一半但是变成失败的了,这就是中止的。执行了一半产生的影响需要撤销,这个撤销的过程称之为回滚。回滚完毕,事务到了执行之前的状态。这个回到的状态称之为中止的状态
个人思考:就像是玩地平线5中的回溯,回到刚开始的状态吧哈哈哈💦回到之后叫做中止状态
(5)提交的
部分提交状态的事务将数据全部同步到磁盘上了以后,称之为提交了的状态
事务处于提交的或者中止状态的时候,一个事务的生命周期才算是结束了
对于已经提交的事务来说,修改将永久生效。对于中止状态的事务,所有修改将被撤回到执行事务之前的状态
MySQL中事物的语法
事务的本质只是一些数据库的操作,符合ACID罢了。MySQL中如何将这些操作放到一个事务中去执行呢
开启事务
BEGIN 【WORK】 ,这个语句后面可以跟着很多语句,这些语句组合在一起就是一个事务
START TRANSACTION, 也是一样的开启事务,后面可以加上语句。不过它可以跟几个修饰符READ ONLY 和 READ WRITE等等,表示只读,修改之类的修饰符
提交事务
直接COMMIT即可,保存之前BEGIN下所有的操作:
mysql> BEGIN;
Query OK, 0 rows affected (0.00 sec)
mysql> UPDATE account SET balance = balance - 10 WHERE id = 1;
Query OK, 1 row affected (0.02 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> UPDATE account SET balance = balance + 10 WHERE id = 2;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> COMMIT;
Query OK, 0 rows affected (0.00 sec)
手动中止事务
可以手动ROLLBACK来恢复数据库到执行操作之前的状态
注意:ROLLBACK语句时手动执行回滚才使用的,如果事务自己遇到了问题会自动回滚的
支持事务的存储引擎
目前MySQL中只有InnoDB和NDB引擎支持
自动提交
MySQL中的一个系统变量: autocommit
默认是自动开启的,也就是如果不手动声明一个BEGIN或者START,那么每一条语句就自动视为一个独立的事务
手动声明那么会自动关闭这个功能,或者你可以直接设置这个系统变量关闭:SET autocommit = OFF;
隐式提交
如果关闭了自动提交或者手动开启了事务,那么事务就不会自动提交。但是可以使用一些特殊语句将事务提交,这种情况称之为隐式提交:比如COMMIT语句
还有另外的一些隐式提交的语句:
(1)定义或者修改数据库对象的数据定义语言:DDL
个人感受:这个真的很熟悉是怎么回事?好像之前玩的学习版的游戏原文件里面一堆这种东西哈哈哈哈💦
数据库对象就是:数据库、表、视图、存储过程等等一些过程
使用CREATE、ALTER、DROP这些语句去修改这些数据库对象的时候,就会隐式提交之前的事务:
BEGIN;
SELECT ... # 事务中的一条语句
UPDATE ... # 事务中的一条语句
... # 事务中的其它语句
CREATE TABLE ... # 此语句会隐式的提交前面语句所属于的事务
(2)隐式使用或者修改表中的数据的时候
(3)事务控制或者关于锁定的语句
如果一个事务还没有提交或者回滚的话,又使用START或者BEGIN开启另一个事务,那么就会隐式提交上一个事务
(4)加载数据的语句
使用LOAD DATA来向数据库导入数据的时候,也会隐式提交事务
(5)MySQL中的一些复制语句
(6)其他语句
保存点
每次出错都需要回滚,那么整个流程又需要重写了。所以MySQL的设计师提出了一个保存点的概念,可以定位原来数据库语句中的几个位置,这样使用ROLLBACK就会回到指定的位置,而不是整个重新开始:
SAVEPOINT 保存点名称;
然后回滚的时候可以回到这个保存点了:
ROLLBACK TO 保存点名称;
RELEASE SAVEPOINT 保存点名称,可以删除一个保存点
总结:什么是事务?满足ACID(原子性,隔离性,持久性,一致性)的一系列的数据库操作,就是满足现实映射条件的数据库操作