刚刚,DeepSeek 开源了最新的数学推理模型 DeepSeek-Math-V2 。
最近国外 Gemini、Claude 神仙打架,小鲸鱼又活过来了。
这不仅仅是一次普通的模型迭代,根据在国际数学奥林匹克和普特南数学竞赛上的表现来看,这可能是开源模型在数学推理领域的一个里程碑时刻。
数学推理新王登基了。

如果说上一代 DeepSeek-Math 让我们看到了开源模型在数学领域的潜力,那么这一次 V2 版本交出了一份令人咋舌的成绩单:IMO 2025 金牌水平。
让我们一起来深扒一下这个新发布的模型到底有多强。
01、项目简介
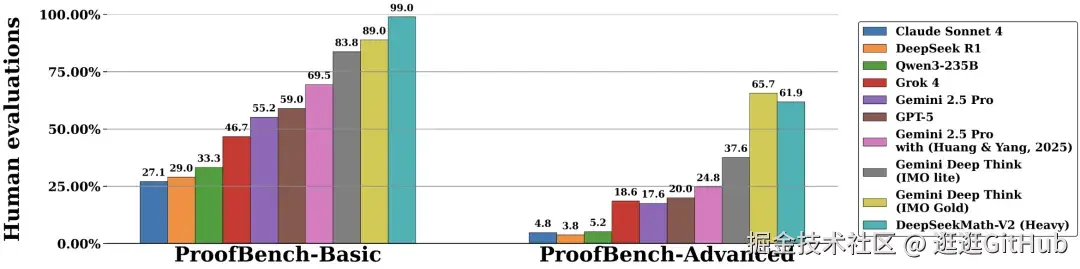
上面这个图就是 DeepSeek-Math-V2 甩出的成绩单。
🏆 IMO 2025(国际数学奥林匹克):金牌水平
DeepSeek-Math-V2 展现了极强的定理证明能力,达到了金牌选手的得分线。
在 IMO-ProofBench 基准测试上,超越了 Google DeepMind 引以为傲的 DeepThink 模型,它曾也是金牌得主。
而且超越 DeepThink 不是一个点,而是 10 个点。紧跟在它们后面的是 GPT-5、Grok4 等模型。
🎓 Putnam 2024(普特南数学竞赛):118/120 分
这几乎是一个满分成绩!要知道 Putnam 是全美顶尖大学生参加的超高难度数学竞赛,能拿满分意味着它不仅会做题,还能处理极高难度的逻辑陷阱。
02、为什么提升这么多?
为什么 DeepSeek-Math-V2 能取得如此巨大的突破?官方的技术文档透露了几个关键点,这不仅仅是堆参数的结果。

① 核心架构
这个模型是基于 DeepSeek 最新的 V3.2-Exp-Base 构建的。
它继承了 V3 系列强大的通用语言理解能力和 MoE(混合专家)架构的高效性。而且参数量达到了惊人的 685B(6850亿),这是一个真正的巨无霸模型。

② 验证者-生成器双核驱动

这是本次 V2 最大的技术亮点。
传统的数学模型往往只是预测下一个 Token,追求最终答案正确。但数学推理的核心在于过程的严谨性。
DeepSeek-Math-V2 引入了自我验证(Self-Verification)机制:
- Generator(生成器) :负责提出解题思路和证明步骤。
- Verifier(验证者):像人类数学家一样,一步步审查推理过程的严谨性。
这种机制解决了 AI 做数学题的一个顽疾:"答案对了,但过程全是胡扯"。
V2 版本不仅能给出答案,还能确保每一步推导都是逻辑闭环的。
③ Test-Time Compute Scaling
类似于 OpenAI 的 o1 系列思路,DeepSeek-Math-V2 支持在推理阶段通过增加计算量来换取更高的准确率。
它会在输出最终结果前,进行多轮的自我博弈和验证,直到找到最完美的证明路径。
03、开源地址
这个模型 Apache 2.0 协议全开源,DeepSeek 这次依然保持了侠客风范,不藏着掖着。
bash
HF地址:https://huggingface.co/deepseek-ai/DeepSeek-Math-V2开源地址:https://github.com/deepseek-ai/DeepSeek-Math-V2