引言:GitHub 榜首项目的"生产环境陷阱" 对于 Python 开发者而言,本周最火的项目莫过于 TrendRadar。它结合了 Playwright 爬虫和 LLM(大模型),能自动聚合抖音、知乎、微博等 35+ 个平台的热点,并生成 AI 简报。 作为一名热衷于自动化工具的架构师,我第一时间在服务器上 Pull 了代码并跑了起来。前两天体验极佳,飞书群里的情报推送源源不断。
然而,第三天早上,服务全挂了。
查看 Docker 日志,屏幕上赫然一行红字: OSError: Errno 28 No space left on device 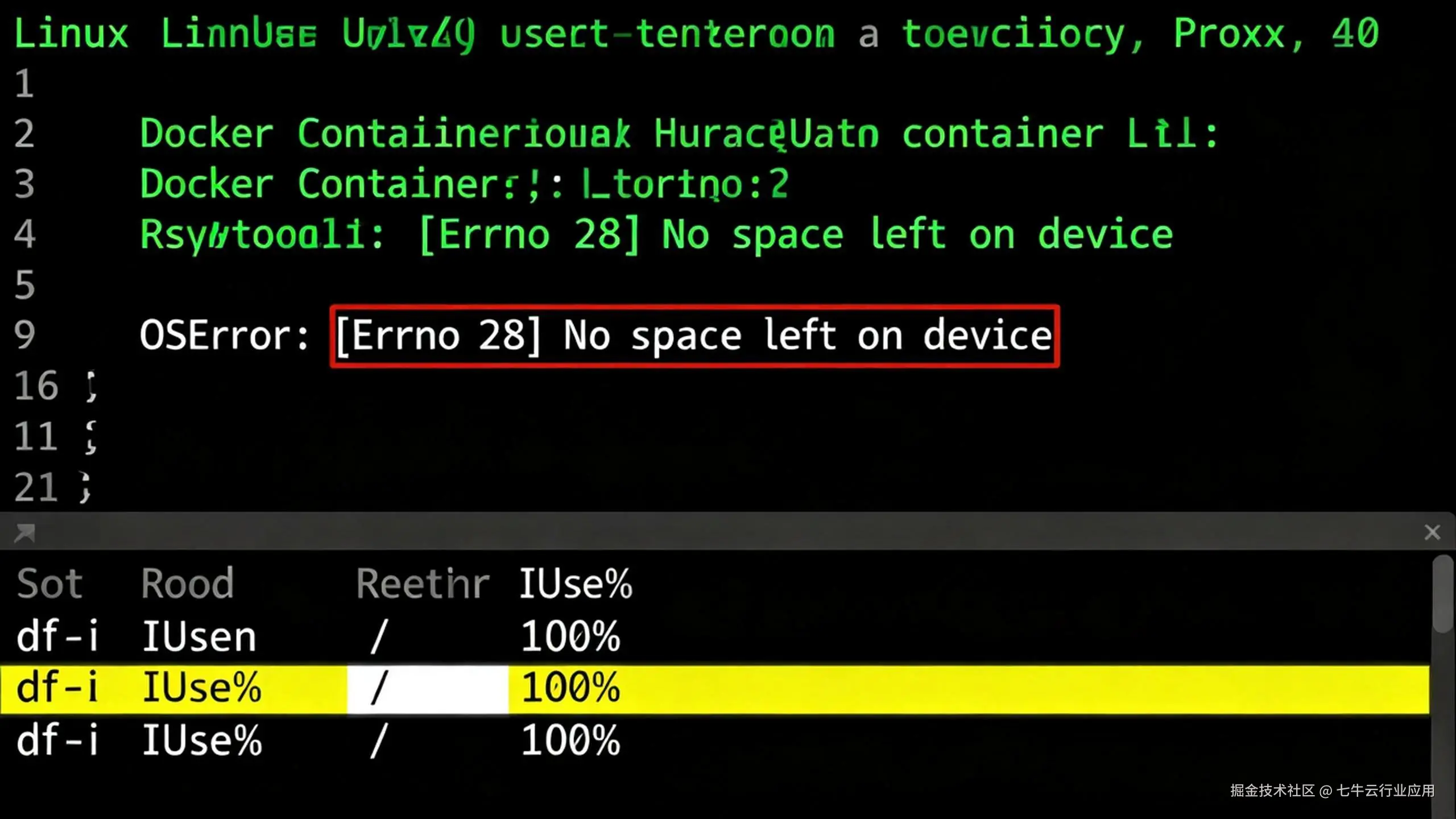
这就是开源 Demo 与工业级应用的差距:如果不解决存储架构问题,TrendRadar 就是一个"硬盘粉碎机"。
一、 事故复盘:如何确认是 Inode 爆掉?
在报错现场,我首先执行了 df -h,结果显示磁盘空间仅使用了 45%。这就非常诡异:明明还有几十 G 空间,为什么提示空间不足? 这时候,老运维都知道要查一下 Inode(索引节点)。
1. 排查 Inode 使用率
执行命令: code Bash
bash
df -i结果显示:IUse% 达到了 100%。
这意味着虽然磁盘还有空间,但文件系统的"户口本"已经发完了。TrendRadar 为了留存舆情证据,会为每一条热点保存高清截图和 HTML 快照,短短 72 小时生成了数万个小文件,直接吃光了 Inode。
2. 定位"元凶"目录
为了确认是哪个目录在搞鬼,可以使用以下组合命令快速统计各目录文件数: code Bash
bash
for i in /*; do echo $i; find $i | wc -l; done很快我们定位到了罪魁祸首:TrendRadar/data/snapshots/。
结论: 在爬虫类应用中,本地文件系统(尤其是 Ext4)并不适合存储海量小文件。我们需要架构级的改造。
二、 架构抉择:为什么爬虫必须"存算分离"?
面对海量非结构化数据(图片/日志),我们对比了两种常见的扩容方案。这次我们不仅看功能,更看量化指标 : 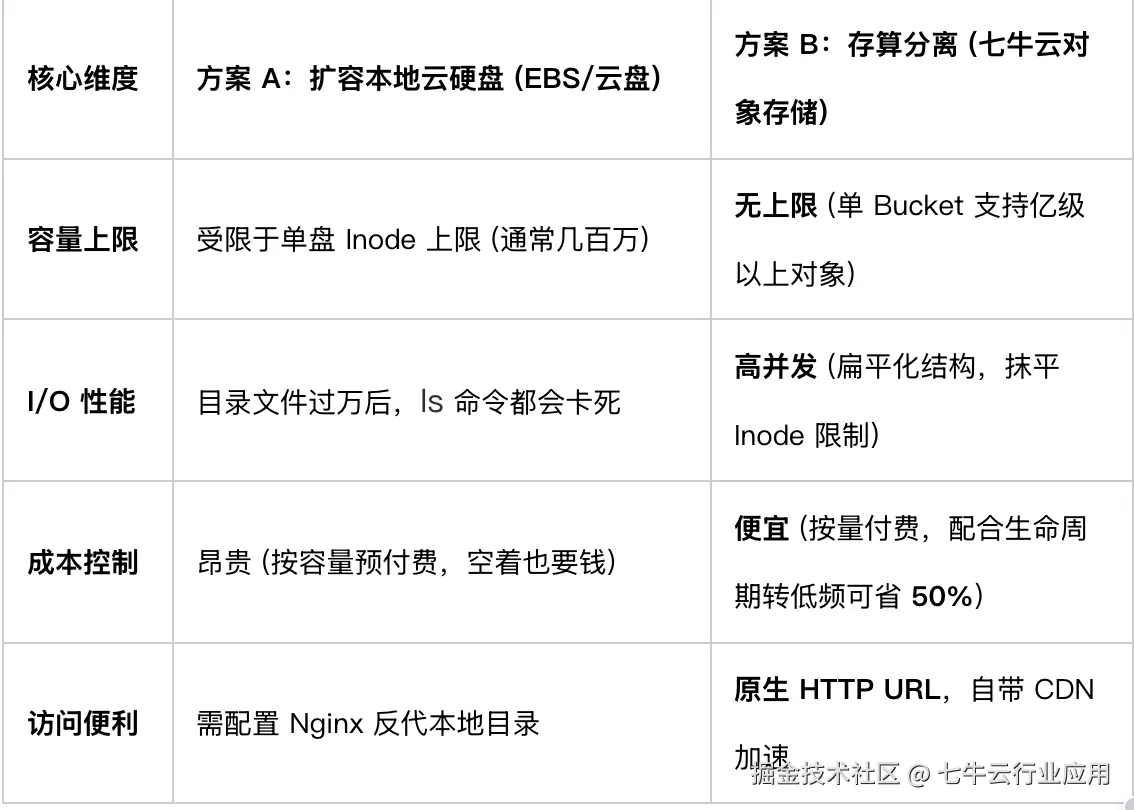
架构决策: 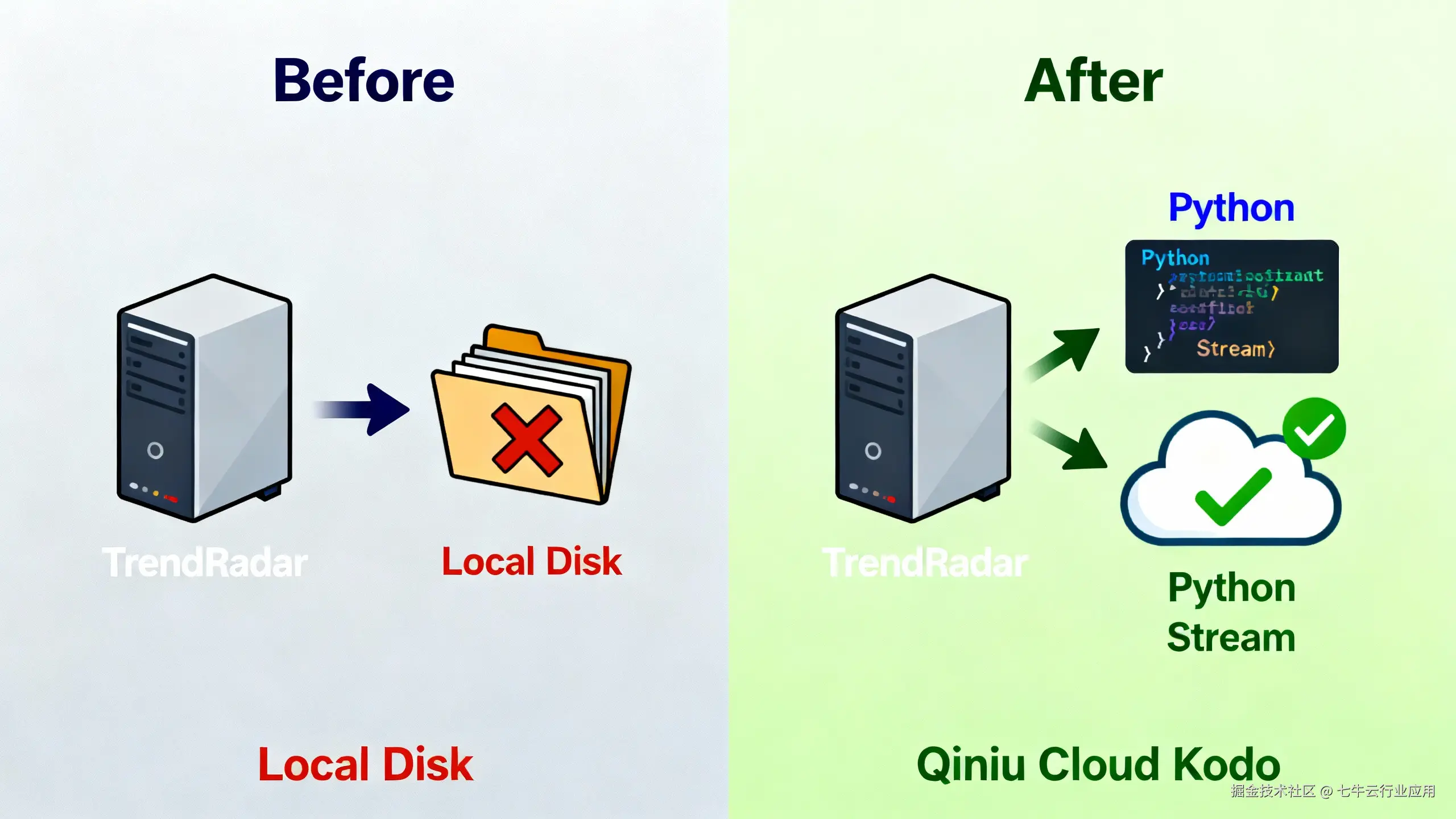
为了保证 Crawler(计算层)的无状态,必须实施存算分离。将所有持久化数据"外包"给专业的七牛云 Kodo。
三、 源码二开实战:从 Local Save 到 Cloud Stream
TrendRadar 是基于 Python + Playwright 编写的。改造的核心思路是:利用 Playwright 原生能力截获内存 Buffer,直接推送到云端。
第一步:环境准备
安装七牛云 Python SDK:
bash
pip install qiniu第二步:封装"云存储管理器"
我们在 utils 目录下新建 oss_manager.py,封装统一的上传接口。 code Python
python
# utils/oss_manager.py
from qiniu import Auth, put_data
import os
# 建议从环境变量读取,适配 Docker/K8s 部署
ACCESS_KEY = os.getenv('QINIU_AK')
SECRET_KEY = os.getenv('QINIU_SK')
BUCKET_NAME = os.getenv('QINIU_BUCKET')
CDN_DOMAIN = os.getenv('QINIU_DOMAIN')
q = Auth(ACCESS_KEY, SECRET_KEY)
def upload_bytes_stream(data_bytes, file_key):
"""
内存直传:直接将二进制流上传到七牛云,完全不占用本地磁盘
"""
token = q.upload_token(BUCKET_NAME, file_key, 3600)
ret, info = put_data(token, file_key, data_bytes)
if info.status_code == 200:
return f"{CDN_DOMAIN}/{file_key}"
else:
return None第三步:魔改截图逻辑 (Core Refactoring)
Playwright 的 page.screenshot() 方法如果不传 path 参数,默认就会返回 bytes (二进制流)。这是一个官方支持的高效路径,也是社区中将 Playwright 对接 S3 的标准做法。
我们找到 TrendRadar 的截图代码,进行如下修改:
修改后 (Cloud Native):
code Python
python
from utils.oss_manager import upload_bytes_stream
import time
def capture_snapshot(page, filename):
# 1. 获取截图的二进制 Buffer (不落盘)
# 这与上传 S3 的套路一致,但七牛云在国内的连接稳定性更佳
screenshot_bytes = page.screenshot()
# 2. 构造云端存储路径(按日期分层)
date_str = time.strftime("%Y/%m/%d")
cloud_key = f"snapshots/{date_str}/{filename}"
# 3. 内存直传七牛云
url = upload_bytes_stream(screenshot_bytes, cloud_key)
if url:
print(f"[Success] Snapshot uploaded: {url}")
return url
else:
print("[Error] Upload failed")
return None第四步:打通飞书/企微通知
修改完存储后,最关键的一步是将返回的 url 写入到通知模版中。这样,当飞书机器人推送热点简报时,用户点击图片链接,直接访问的是七牛云 CDN 加速后的高清图,既验证了集成成功,又提升了加载体验。
四、 部署建议与生命周期管理
1. 像管理 Secrets 一样管理密钥
为了保持 TrendRadar 官方 Docker 部署的优雅体验,不要把 AK/SK 硬编码在代码里。建议在 docker-compose.yml 中添加环境变量,与现有的 FEISHU_WEBHOOK_URL 保持一致: code Yaml
yaml
environment:
- QINIU_AK=your_access_key
- QINIU_SK=your_secret_key
- QINIU_BUCKET=trend-radar-assets
- QINIU_DOMAIN=http://assets.example.com2. 用"生命周期"榨干每一分成本
舆情数据的时效性极强。针对这一点,我们可以利用云对象存储的标准能力------生命周期管理 (Lifecycle)。 在七牛云 Kodo 后台,只需配置一条简单的规则:
●前缀匹配: snapshots/
●转低频 : 上传 30天 后 -> 转为 低频存储 (Standard-IA),成本降低约 50%。
●过期删除 : 上传 90天 后 -> 自动删除。
这套策略是云存储的通用标准,既保留了近期的热点证据,又将长期存储成本压到了最低,完全不需要写 Crontab 脚本去维护。 五、 总结与替代方案对比 当然,解决 Inode 耗尽还有其他"土办法",比如:
1.重新格式化磁盘: 使用 mkfs.ext4 -N 调大 Inode 数。(缺点:需要停机,数据全丢,治标不治本)
2.更深的目录分层: 缓解目录索引压力。(缺点:逻辑复杂,无法解决总容量限制)
相比之下,"对象存储 + 代码改造" 是一条一劳永逸的云原生路径。它不仅解决了眼前的崩溃问题,更为 TrendRadar 赋予了无限的扩展能力。
让算力归算力(Docker),让存储归存储(七牛云),这才是 AI Agent 时代该有的架构素养。