在当今的现代数据架构(Data Lakehouse)中,我们面临着一个幸福却又痛苦的烦恼:选择太多,互通太难。
Apache Iceberg、Apache Hudi 和 Delta Lake 并称为数据湖格式的"三驾马车"。它们各自拥有强大的功能和庞大的生态系统,但它们之间却存在着厚厚的"墙"。一旦你选择了一种格式,往往意味着你需要绑定特定的计算引擎,或者需要昂贵的 ETL 过程才能在不同工具间迁移数据。
Apache XTable(原名 OneTable)的出现,正是为了推倒这堵墙。
1. 设计目的:为什么我们需要 XTable?
Apache XTable 的核心设计哲学可以概括为一句话:存储层的互操作性(Interoperability)。
在 XTable 出现之前,数据架构师通常面临以下困境:
•工具锁定(Vendor Lock-in): Databricks 偏好 Delta Lake,Snowflake 拥抱 Iceberg,EMR/Athena 可能对 Hudi 或 Iceberg 支持更好。为了适配不同的查询引擎,你可能需要维护多份数据副本。•迁移成本高昂: 如果想从 Hudi 迁移到 Iceberg,通常需要重写所有历史数据,耗时且昂贵。•架构僵化: 在项目初期选定的格式,随着业务发展可能不再适用,但更换格式的代价让人望而却步。
XTable 的设计目的就是解耦"数据本身"与"元数据格式"。 它允许用户自由选择最适合写入的格式,同时又能让任何读取引擎无缝访问这些数据,而无需复制数据文件。
2. 核心原理:它是如何工作的?
Apache XTable 并不是一个新的存储引擎,它更像是一个轻量级的元数据转换层(Metadata Translation Layer)。
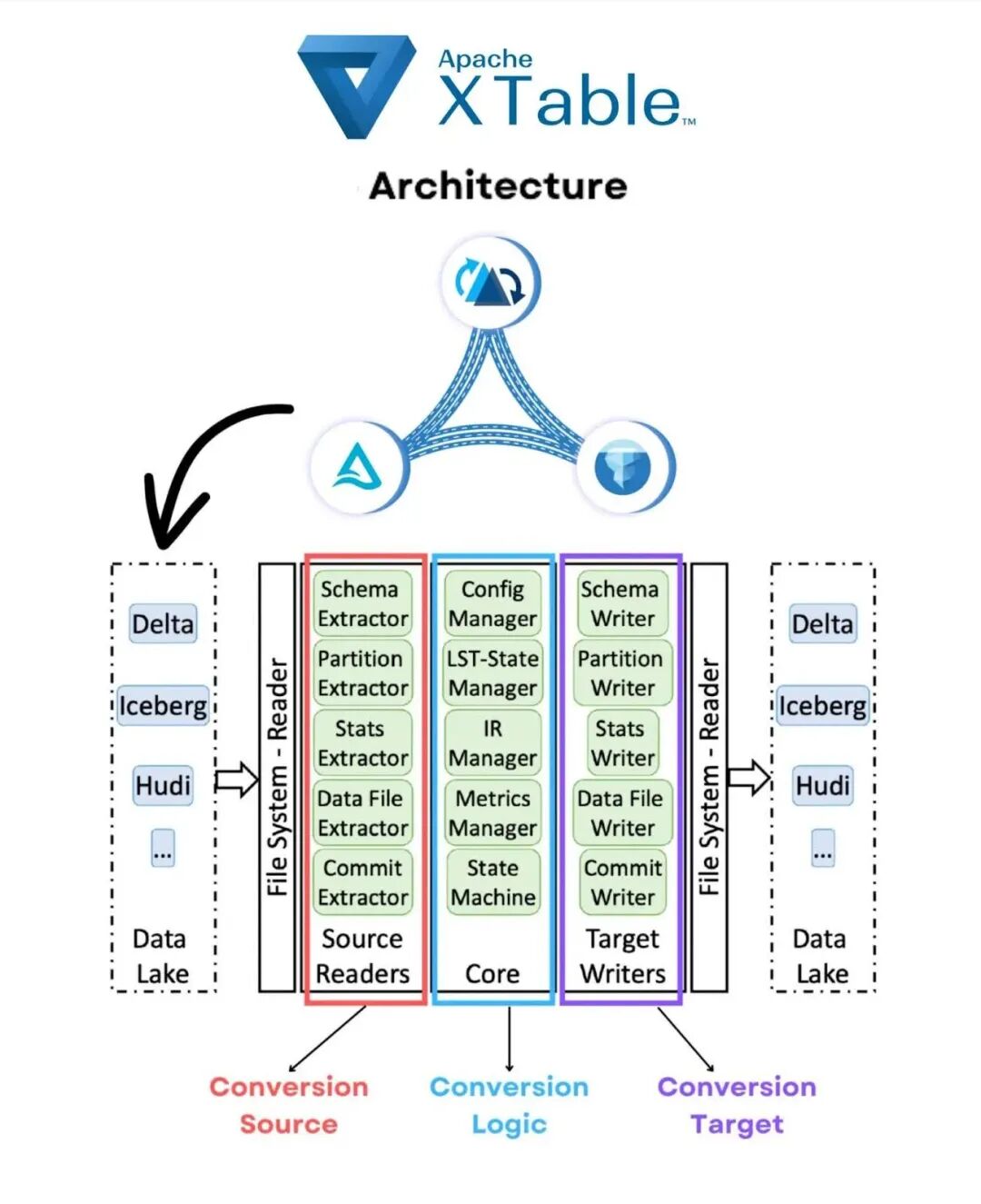
关键概念:Zero-Copy(零拷贝)
这是 XTable 最具革命性的特点。现有的三大湖格式(Hudi, Iceberg, Delta)底层存储的通常都是标准的 Parquet 文件。它们的主要区别在于**元数据(Metadata)**是如何组织和记录的(例如:谁记录了文件列表?谁管理快照?谁处理 Schema 演变?)。
XTable 的工作流程如下:
1.读取源元数据: 解析源格式(例如 Hudi)的提交日志和文件清单。2.转换为中间状态: 将源元数据映射到 XTable 的通用内部表示(Internal Representation)。3.写入目标元数据: 将内部表示"翻译"为目标格式(例如 Iceberg 和 Delta)所需的元数据文件(如 metadata.json 或 _delta_log)。
结果: 你的 S3 桶里不仅有原始的 Hudi 结构,旁边还通过 XTable 生成了合法的 Iceberg 和 Delta 元数据文件。所有格式都指向同一组 Parquet 数据文件。
3. Apache XTable 能做什么?
3.1 全向互操作性(Omni-directional Interoperability)
XTable 不是单向的。它支持多向转换:
•Hudi ➔ Iceberg & Delta•Delta ➔ Hudi & Iceberg•Iceberg ➔ Hudi & Delta
这意味着你可以利用 Hudi 强大的 Upsert/Compaction 能力进行写入 ,同时利用 Snowflake 对 Iceberg 的原生支持进行读取 ,再利用 Databricks 对 Delta 的优化进行机器学习训练。
3.2 逐步迁移(Gradual Migration)
以前,更改表格式需要一次性"大爆炸"式的重写。有了 XTable,你可以同时维护两种格式的视图。这使得企业可以安全地测试新格式,验证性能和兼容性,最后平滑过渡,风险极低。
3.3 统一数据视图
对于大型组织,不同部门可能使用了不同的技术栈(A 部门用 Databricks/Delta,B 部门用 Flink/Hudi)。XTable 可以作为中间件,将这些异构数据源"虚拟化"为统一的格式,供全公司的数据目录(Data Catalog)管理,而无需物理搬运数据。
4. 实战场景示例
假设你是一个实时数仓的架构师:
1.写入端: 你使用 Flink 结合 Apache Hudi 摄入实时日志数据,因为 Hudi 对流式写入和主键索引支持非常好。2.转换端: 你部署了一个轻量级的 XTable 任务,定期(例如每 5 分钟)扫描 Hudi 表,并同步生成 Apache Iceberg 的元数据。3.消费端: •数据分析师使用 Snowflake 或 Amazon Athena 直接查询 Iceberg 格式的视图(享受高性能查询)。•数据科学家使用 Spark 读取 Hudi 格式进行特征工程。
在这个过程中,没有产生任何 Parquet 数据文件的复制,存储成本几乎没有增加,且数据延迟极低。
5. 总结
Apache XTable 正在重新定义数据湖的开放性。它不再强迫用户在"三驾马车"中做排他性选择,而是通过一种抽象层的方式,让数据格式变成了一个可选项,甚至是可共存项。
一句话总结 XTable 的价值:
它将数据的所有权从单一的格式供应商手中夺回,交还给了用户,实现了真正的"Write Once, Read Anywhere"。