文章目录
- [第一章 C++20核心语法特性](#第一章 C++20核心语法特性)
-
- [1.11 \[likely] 和 \[unlikely]属性](#1.11 [[likely]] 和 [[unlikely]]属性)
-
- [1.11.1 作用与原理](#1.11.1 作用与原理)
- [1.11.2 举例](#1.11.2 举例)
- [1.12 特性测试宏](#1.12 特性测试宏)
-
- [1.12.1 作用与原理](#1.12.1 作用与原理)
- [1.12.2 举例](#1.12.2 举例)
- [1.12.3 常用宏列表总结](#1.12.3 常用宏列表总结)
本文记录C++20新特性之\[likely] ,\[unlikely]属性和特性测试宏。
第一章 C++20核心语法特性
1.11 \[likely] 和 \[unlikely]属性
现代 CPU 采用流水线技术执行指令。当遇到条件跳转(如 if 或 switch)时,CPU 需要猜测代码会走哪条路径,并预先加载该路径的指令。
如果CPU预测正确,流水线畅通无阻,性能极高。
如果CPU预测错了,就是一种控制冒险,CPU必须清空流水线,重新加载正确指令,这个过程需要几十个指令周期。
C++20之前,为了优化热点代码,开发者通常依赖编译器特定的扩展,例如 GCC/Clang 的 __builtin_expect:
cpp
// GCC/Clang 旧式写法
#define likely(x) __builtin_expect(!!(x), 1)
#define unlikely(x) __builtin_expect(!!(x), 0)
if (likely(ptr != nullptr)) { ... }这种写法,在MSVC上不支持,而且代码可读性较差。C++20为了将这一需求标准化,将这个属性纳入新版本中。
1.11.1 作用与原理
这两个属性可以应用于语句(Statements)和标签(Labels)。
\[likely]:告诉编译器,该分支执行的概率很高。
\[unlikely]:告诉编译器,该分支执行的概率很低。
编译器会利用这些信息做以下优化:
指令重排 (Code Layout Optimization):编译器会将 likely 的代码块紧挨着跳转指令放置,而将 unlikely 的代码块放到较远的内存位置(Cold Section)。这样可以提高指令缓存(I-Cache)的命中率。
分支预测提示:在某些架构上,编译器可能会生成特定的前缀指令来显式告诉 CPU 如何预测。
1.11.2 举例
示例1:优化if else分支
cpp
void process(int* ptr)
{
// 告诉编译器:ptr 为空的情况极少发生
if (ptr == nullptr) [[unlikely]]
{
// 这里的代码可能会被编译器扔到函数的末尾,避免污染指令缓存
throw std::runtime_error("Pointer is null");
}
// 告诉编译器:这个分支是主要路径
if (*ptr > 0) [[likely]]
{
std::cout << "Positive value processing..." << std::endl;
// ... 热点代码 ...
}
else
{
std::cout << "Non-positive processing..." << std::endl;
}
}示例2:优化 switch语句
在 switch 语句中,这两个属性可以标记在 case 标签上。
cpp
void handle_event(int event_type) {
switch (event_type) {
case 1: [[likely]] {
// 绝大多数时候都是处理事件 1
// 编译器可能会优先比较 event_type == 1
process_event_one();
break;
}
case 2: {
process_event_two();
break;
}
case 3: [[unlikely]] {
// 极罕见的事件
process_rare_event();
break;
}
}
}1.12 特性测试宏
在 C++20 之前,为了编写可移植的代码,开发者通常面临以下困境:
编译器碎片化:GCC 8 支持了部分 C++17 特性,Clang 6 支持了另一部分,MSVC 又是另一种情况。仅仅检查 __cplusplus 版本号(如 201703L)往往不够精确,因为编译器可能只实现了标准的一部分。
复杂的构建脚本:开发者被迫在 CMake 或 Makefile 中编写大量的 try_compile 脚本来探测编译器能力,这增加了构建系统的复杂性。
非标准宏:依赖 __has_include 或编译器特定的宏(如 __cpp_rtti),缺乏统一标准。
C++20(实际上从 C++17 SD-6 文档开始建议,C++20 正式入标)引入了一套标准化的预定义宏,让源代码自己就能"知道"编译器支持哪些特性。
1.12.1 作用与原理
特性测试宏本质上是编译器预定义的数字宏。
特性测试宏命名规范:语言特性宏通常以__cpp_开头,例如 __cpp_concepts。
宏的值:是一个整数,通常代表该特性被采纳或更新的年月。
头文件:语言特性宏直接由编译器预定义,无需包含头文件。
1.12.2 举例
示例1:假设当前正在使用C++20的Concepts,但为了兼容旧编译器,需要提供回退方案。
cpp
#ifdef __cpp_concepts
#include <concepts>
// 使用C++20实现:清晰简洁
template<typename T>
requires std::integral<T>
void process(T v)
{
std::cout << "Processing integral: " << v << std::endl;
}
#else
// 退回之前版本,使用enable_if
template<typename T, typename V = std::enable_if_t<std::is_integral_v<T>>>
void process(T v)
{
std::cout << "Processing integral: " << v << std::endl;
}
#endif
void test()
{
process(42); // 合法
//process(3.14); // 编译错误
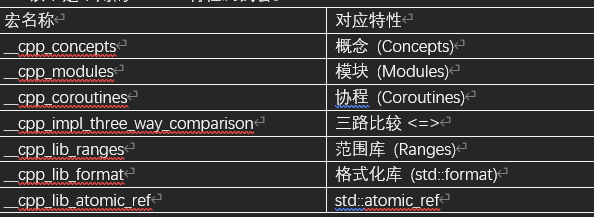
}1.12.3 常用宏列表总结
以下是常用的C++20特性测试宏。