上一章咱们给数据库装了个"写缓存",相当于在市中心车库外建了个临时停车场。确实,车流(写操作)不堵门了。但问题是------这停车场是露天的,且只有三个车位。
一旦遇上"双十一"式的高频数据洪流(想象一群饿疯了的吃货同时涌向自助餐厅),这方案立刻露出短板:缓存写满的速度比手机掉电还快 ,数据要么排队等到天荒地老,要么面临丢失风险。
显然,临时方案扛不住持久战。接下来咱们关掉美颜,直面痛点,一步步拆解如何为持续的高频写入设计一个既扛得住、又稳得起 的系统方案。
道路就在前方,咱们开始铺路。
1 业务背景:日亿万级请求日志收集如何不影响主业务
业务狂飙突进,某天,一家公司的日活用户冲上了 500万 。
基于当时的模式,业务方一拍桌子要求:全面埋点 ,精准记录用户在特定页面的所有行为。
目的很明确:
- 数据分析 ------ 理解用户,优化产品。
- 与第三方结算费用 ------ 这事关商业模式,深层逻辑本章暂不展开。
与此同时,业务方还要求能在后台实时查询 用户行为与统计报表。不过,此"实时"并非毫秒级的较真------略有延迟可以接受,更准确地说,是 "准实时" 。
为了方便后续理解方案设计,这里对真实业务中复杂的数据结构进行了去枝减蔓 ,仅保留核心字段。如下表所示。
| 指标 | 备注 |
|---|---|
| IMEI | 用户设备的IMEI |
| 定位点 | 经纬度 |
| 用户ID | 用户唯一ID |
| 目标ID | 每个页面、按钮、banner都有唯一ID |
| 目标类型 | 页面、按钮、baner等 |
| 事件动作 | 点击、进人、跳出等 |
| FromURL | 来源URL |
| CurrentURL | 当前URL |
| TOURL | 去向URI |
| 动作时间 | 触发这个动作的时间 |
| 进人时间 | 进人该页面的时间 |
| 跳出时间 | 跳出该页面的时间 |
| ... | ... |
在这样一套数据结构支撑下,业务团队在后台查询时,手里就像握着一把 "多维数据遥控器" :
第一,灵活查明细
他们可以任意组合筛选条件------按城市(由经纬度实时换算)、性别、年龄 按目标类型、具体事件动作
......实时透视每一位用户的行为轨迹,跟玩数据侦探游戏一样。
第二,秒出统计报表
系统还能从多个维度快速聚合出业务指标,例如:
- 按天/周/月/年 + 性别 + 年龄 等多维度交叉分析
- 查看每个目标ID的总点击量、人均点击次数、页面转化率等
(这还只是统计需求的冰山一角,业务方的报表愿望清单往往比你想象的长得多。)
而为了支撑费用结算 这个关键任务,所需收集的数据结构(简化版)则如下表所示。
| 字段 | 备注 |
|---|---|
| 日期 | 结算的日期 |
| 目标ID | 原始数据中的目标 ID,比如页面 ID、按钮 ID、banner ID |
| 点击人数 | 有多少人点击了目标 (同一人点多次算一次) |
| 点击人次 | 有多少人次点击 (同一人点多次算多次) |
| 费用 | 此目标 ID当天的收费总计 |
这样一来,数据不仅要"流得进来",还得能"被看得清、算得明"。下一步,就是设计一套能扛住高并发写入、同时支持灵活查询与实时统计的架构方案。
2. 技术选型思路
基于以上业务场景,项目组提炼出 六大核心需求 ,并给出了对应的技术选型思路:
- 原始数据海量 → 初步选用 HBase 持久化,专治数据"膨胀症"。
- 埋点响应要快 → 埋点服务先将日志丢进缓存层 ,保证用户无感。具体缓存方案有几副"牌"可打,稍后详解。
- 后台可查询原始数据 → 若直接用 HBase 查询,速度略慢。故额外引入 Elasticsearch ,专门承载查询条件字段与活动ID,实现"秒查"。(用ES快速筛选出查询条件,再用条件去HBase拿完整数据,各司其职,既快又省。 )
- 多样统计报表 → 虽可选用 Kibana、Grafana 等现成可视化工具,但为追求灵活度,决定自主设计 统计功能。
- 依埋点生成结算数据 → 费用相关数据存 MySQL ,保证事务清晰、计算稳妥。
- 需框架处理缓存数据并分流至 ES / HBase / MySQL → 因业务要求"准实时",必须选用实时处理引擎。当前主流三兄弟:Storm、Spark Streaming、Apache Flink ,选谁?下文分解。
根据以上思路,初步架构如下图所示。
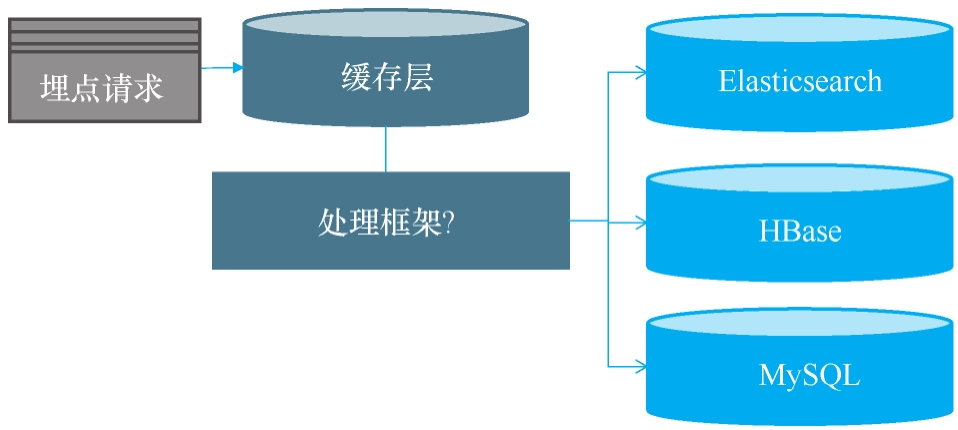
眼尖的你一定发现了,这张架构图上还挂着醒目的问号 ❓没错,悬念就此埋下------它们正对应着接下来要拆解的四道核心难题。咱们往下看,问题马上揭晓。
2.1 使用什么技术保存埋点数据的第一现场
面对海量埋点数据,第一道关卡就是:用啥技术接住这"第一现场"? 主流选项有三:Redis、Kafka、本地日志 。项目组最终拍了板:本地日志。为啥不选 Redis 或 Kafka?来,我们掰开揉碎说一说。
2.1.1 先说 Redis:快,但有"记忆漏洞"
Redis 靠 AOF 机制持久化数据(写缓存章节提过),但其刷盘节奏是个关键选择:
- 若配置
appendfsync everysec:每秒刷一次盘 。速度不错,但宕机可能丢一秒数据。 - 若配置
appendfsync always:每次操作都刷盘 。数据稳了,但速度会有影响。
埋点要求响应飞快,等不及 always;又怕丢数据,不敢信 everysec。Redis:出局。
2.1.2 再说 Kafka:稳,却要"等确认"
Kafka 通过多副本保障可靠性,其 Producer 的 acks 配置直接决定速度与安全的取舍:
| acks 值 | 行为 | 结果 |
|---|---|---|
| 0 | Leader 不收妥就直接回复客户端 | ⚡️ 速度起飞,📉 数据可能"蒸发" |
| 1 | Leader 落盘即回复,不等 Follower 同步 | ⚡️ 速度较快,📉 副本未同步,仍有丢失风险 |
| all | 等 Leader + 指定数量 Follower 全部同步后才回复 | 📦 数据稳如磐石,🐢 响应速度感人 |
想要数据不丢?就得选 acks=all,但响应延迟就上去了。Kafka:要么快,要么稳,难两全。
****所以选本地日志:鱼与熊掌这次兼得了
既不想丢数据,又要响应快------项目组最终决定:直接把埋点数据写入服务器本地日志文件。
- 💡 响应极快:写完本地就返回,无需等待网络同步或副本确认。
- 💾 数据可靠:日志文件即时落盘,系统崩溃也不怕。
- 🔄 后续可异步处理:日志文件可作为可靠数据源,供下游实时或批量消费。
结论 :在高并发埋点场景下,本地日志成为了那个兼顾性能与可靠性的"朴实却聪明"的起点。接下来的问题,就是如何把这些日志高效、有序地"搬运"到下游存储了。
2.2 日志搬运工-如何收集日志数据到持久化层
最简单的办法,当然是直接用 Logstash 把日志文件数据"灌入"Elasticsearch。但问题来了:业务要求存进ES的记录,是一份"完整档案" (需包含城市、性别、年龄等业务字段),而原始日志里只有用户行为"骨架",血肉(业务数据)还得去业务系统里抽。这样一来,光有Logstash就不够用了------中间缺了一道"数据拼装"工序。
🧩** 如果非要Logstash直传,有三种"补丁式"方案,但各有硬伤:**
| 方案 | 操作 | 问题 |
|---|---|---|
| 1. 自定义Filter | 在Logstash里用Ruby写过滤器,现场调业务接口补数据 | 代码臃肿,维护吃力,耦合度高 |
| 2. 改客户端 | 埋点时就在客户端提前捞好业务数据一起上报 | 业务方拍桌子拒绝:查询条件每变一次就得发版一次,太折腾 |
| 3. 改服务端 | 服务端写日志前,先查库补全数据再落盘 | 服务端不同意:每个请求都同步查库,性能骤降,用户体验受损 |
****不仅如此,不用Logstash直传还有两个关键原因:
- 数据要分送两处 (ES + HBase),Logstash多输出源在同一个Pipeline里,一旦一个输出源"卡壳",另一个也跟着"停工"------互相拖累。
- MySQL里的费用结算数据 ,需要动态分析计算埋点日志才能生成,这已超出Logstash"搬运"的职责范围,它算不明白。
结论:必须请出"计算框架"
正因为数据需要补全、拆分、计算 ,项目组最终决定:引入一个实时计算框架,让它负责这段"复杂搬运+加工"流水线。至此,完整的技术架构演进如图所示。
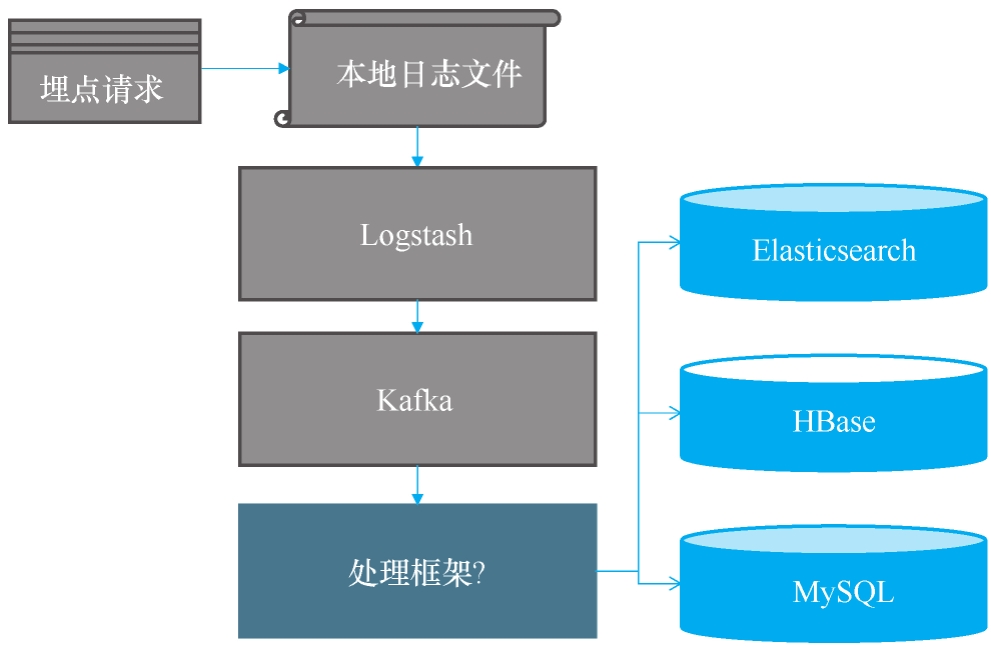
最终确定的方案流程如下:日志文件 → Logstash → 消息队列(MQ)→ 实时计算框架 → 持久化层 。
简单说,就是先把日志"搬进"消息队列,再交给实时计算框架集中处理。框架的核心任务有二:
1️⃣ 补全业务数据 ------为原始埋点记录注入城市、性别、年龄等字段;
2️⃣ 生成费用数据 ------动态统计并计算出可用于结算的结构化结果。
处理完成后,数据会分门别类存入相应的持久化存储中。
****关于 Logstash 的补充说明
Logstash 本身由 Ruby 编写,资源消耗较大,因此官方推出了更轻量的 Filebeat 。常见做法是使用 Filebeat 收集日志,再交由 Logstash 进行过滤处理。
如果不需要 Logstash 强大的过滤功能,也可以直接用 Filebeat 将数据发送至 Kafka。但 Filebeat 采用轮询机制 检测文件变化,可能存在明显采集延迟;而 Logstash 能够实时监听 文件变动,时效性更好。
综合考量后,项目组决定继续沿用 Logstash ------其资源消耗在可接受范围内,且能保证数据采集的实时性。
接下来,我们将分别探讨两个关键组件:消息队列 Kafka 与分布式实时计算框架 的选择与设计。
2.3 为什么使用Kafka
Kafka,出身名门(LinkedIn开源),天生就是为吞日志而生的。它有两个醒目标签:超高吞吐 + 无限堆积(数据扩展性近乎无上限)。官方曾晒出一组"成绩单":仅用3台普通配置的机器 ,就能实现每秒写入200万条记录。

它凭什么这么快?
关键藏在存储设计 里。来看一张官方的结构示意图:
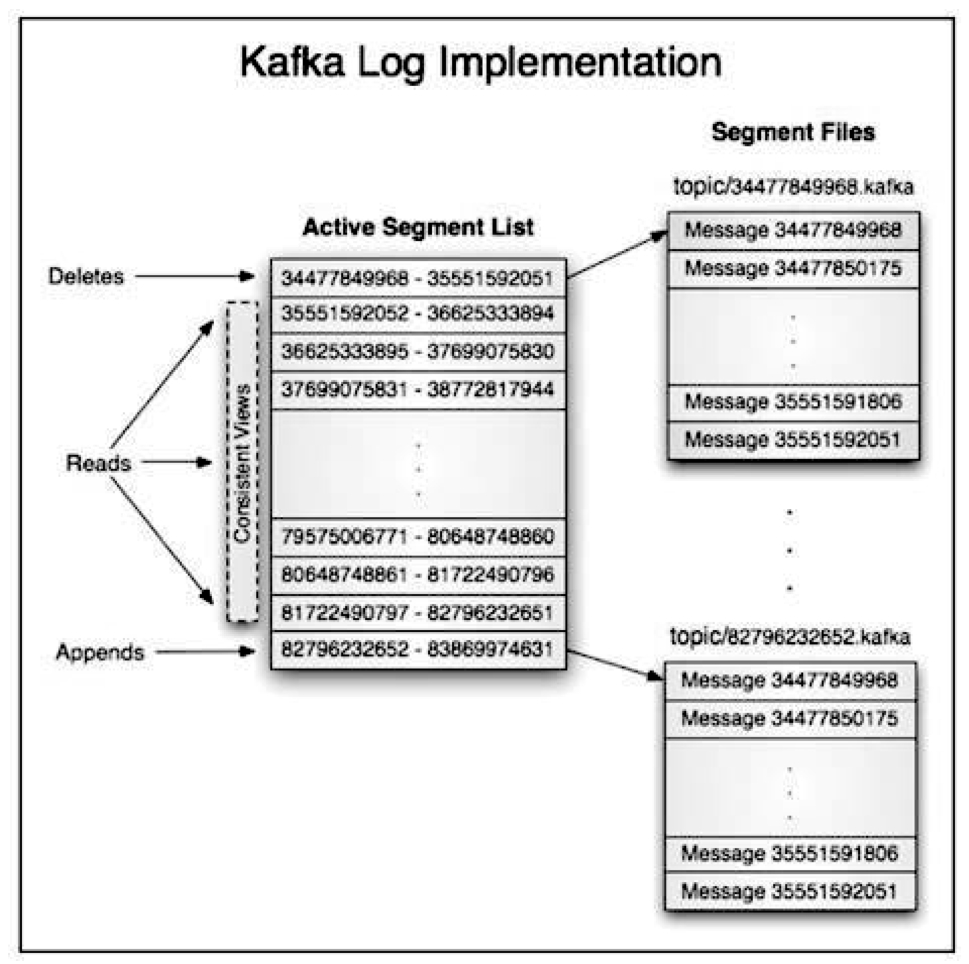
你可以把 Kafka 的每个 Topic 分区想象成一个不断增长的巨型文件 ,而这个大文件又由许多 Segment 小文件 拼接而成。
其读写模式极其简洁:
✍️ Producer 只做"顺序写" ------永远在文件末尾追加数据;
📖 Consumer 只做"顺序读" ------沿着文件依次读取。
这种顺序读写 的架构,让读操作几乎不阻塞写操作,磁盘 I/O 效率拉满,吞吐量自然飙高。
为什么适合日志场景?
除了读写快,Kafka 还有一个"懒人优势":只要磁盘够大,消息就能一直堆下去 (理论无限堆积)。
这对于海量、持续产生的日志数据来说,简直是量身定做的解决方案------既能扛住洪峰流量,又不必频繁清理历史数据。
于是,在日志收集这条赛道上,Kafka 凭借快 + 稳 + 能囤 的三板斧,顺利入选项目的核心枢纽。
2.4 使用什么技术把Kafka的数据迁移到持久化层
2.4.1 技术选型
要把 Kafka 中海量的数据"消化"并存入各个持久层,就得请出 分布式实时计算框架。原因很明确:
- 数据量太大,必须"分布式"群殴 :每天上亿条埋点数据,要在业务要求的时间内完成分析、补全、统计,并分别写入 ES、HBase 和 MySQL。单机肯定跑不动,必须靠多个节点并发处理 ------这是典型的大数据分布式计算诉求。
- 业务要求"准实时" :报表和查询不能等隔夜批处理,必须有个实时流水线 来持续处理数据流。
目前主流的分布式实时计算框架有 Storm、Spark Streaming、Apache Flink 三剑客。选哪个?答案是:看家底和喜好。
- 如果公司已有现成的,直接用,别折腾。
- 如果从零开始,那就凭偏好选。
作者推荐 Apache Flink ,理由有二:一是性能强悍 :阿里巴巴在双11等大促中,靠它实现了每秒处理17亿条数据 的峰值。二是机制贴心 :它提供 Exactly-Once(精确一次) 的容错保证,还有基于事件时间(Event Time) 的窗口计算能力------这两点对于业务来说至关重要。
2.4.2 容错机制:消息到底被处理了几次?
流处理中系统难免出故障,这就引出一个关键问题:消息会不会丢?会不会重复? 不同的容错机制决定了数据的一致性级别:
| 机制 | 含义 | 效果 |
|---|---|---|
| At-Most-Once | 至多一次 | 消息可能"丢了就丢了",可能丢失数据 |
| At-Least-Once | 至少一次 | 消息可能"发了又发",可能重复处理 |
| Exactly-Once | 精确一次 | 消息有且仅被正确处理一次 ,理想状态 |
在需要精确计费、统计的业务中,Exactly-Once 无疑是黄金标准 。Flink 的容错机制正是为此设计,能在保证高吞吐的同时,做到数据不丢不重。
2.4.3 时间窗口:按谁的时钟算?
统计"每小时用户数"时,如果按处理框架收到消息的时间 (处理时间)来划分窗口,可能会出错。
举个栗子 🌰:用户一条行为日志实际发生在 <font style="color:rgb(15, 17, 21);">6:30</font>,但框架 <font style="color:rgb(15, 17, 21);">6:32</font> 才收到。如果按处理时间统计 <font style="color:rgb(15, 17, 21);">6:01~6:30</font> 的数据,这条记录就被漏掉了------这显然不符合业务逻辑。
这里有一个简单的Flink代码示例,展示如何定义基于事件时间的一小时滚动窗口,并将每小时内的用户聚集到一个列表中:
java
// 创建Flink流处理执行环境
Final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置时间语义为处理时间(使用系统时钟时间)
env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);
// 可选的其他时间语义(当前被注释):
// env.setStreamTimeCharacteristic(TimeCharacteristic.IngestionTime); // 使用数据摄入时间
// env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime); // 使用事件自带时间戳
// 创建Kafka数据源,从指定topic读取数据
DataStream<MyEvent> stream = env.addSource(
new FlinkKafkaConsumer<MyEvent>(
topic, // Kafka主题名称
schema, // 消息反序列化模式
props // Kafka连接配置
)
);
// 构建数据处理流水线
stream
// 按用户ID进行数据分区(相同用户的数据发往同一分区)
.keyBy((event) -> event.getUser())
// 定义1小时的滚动时间窗口(基于处理时间)
.timeWindow(Time.hours(1))
// 增量聚合:使用reduce函数合并窗口内数据
.reduce((a, b) -> a.add(b)) // 假设MyEvent有add()方法
// 输出结果到目标系统(sink未指定具体实现)
.addSink(...);业务统计真正该依据的,是日志中记录的 事件发生时间(Event Time) 。Flink 的杀手锏之一,正是其基于事件时间(Event Time)的窗口机制 ,它能正确处理这种乱序到达的数据,确保统计结果忠实于用户真实的操作时刻,而不是系统的处理时钟。
总结 :选择 Flink,不仅是看中它的性能天花板 ,更是因为它用 Exactly-Once 机制 保证了数据处理的准确性,并用 Event Time 时间窗口 保障了业务统计的真实性。这两大特性,让它成为处理复杂实时流水线的可靠选择。
3.整体方案
最终,我们得到了如图所示的完整架构方案。
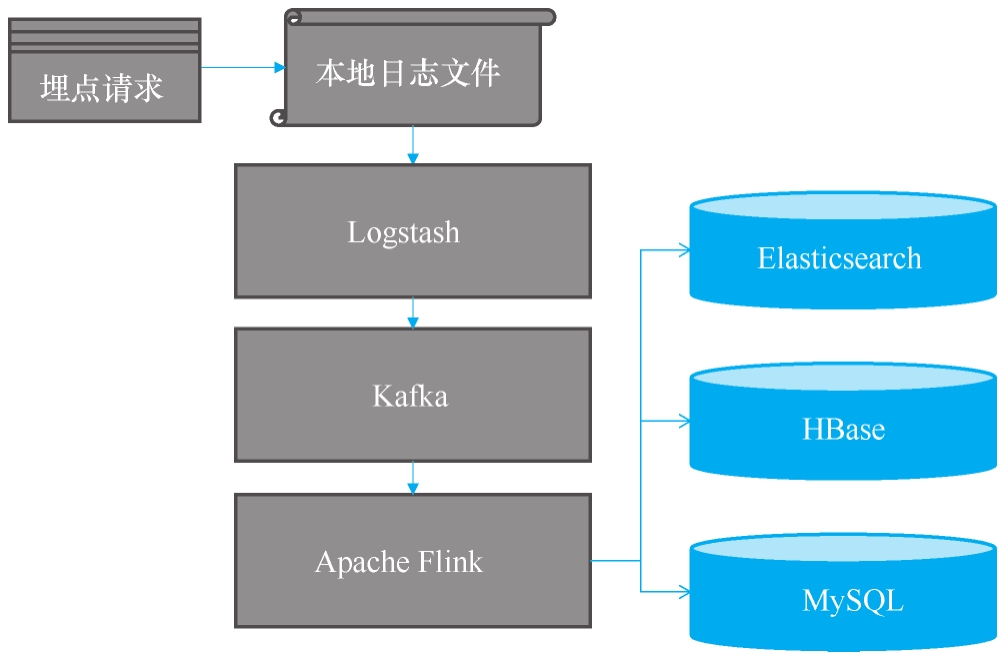
这个系统的运作,就像一个高度协同的数据流水线,其核心流程可以清晰地分为五步。
1.就地记录,保存"第一现场" :所有埋点请求到达后台服务后,第一时间被原封不动地写入服务器本地日志文件。
2.日志搬运,送入中转站 :Logstash 扮演勤恳的搬运工,从各服务器日志文件中抽取原始数据,不做任何加工,直接打包送入 Kafka 消息队列。这一步的目标是快速汇集,统一入口。
3.实时加工,智能分流 : Apache Flink 作为核心计算引擎,从 Kafka 中持续拉取原始数据流。在这里,数据完成了"华丽变身":补全业务字段、进行统计计算,然后被精准地分派到三个不同的目的地:Elasticsearch、HBase 和 MySQL。
4.查询分工,联合作战
- Elasticsearch 存储用于快速检索的索引字段(如用户ID、城市、事件类型等),负责处理复杂的条件筛选。它像一个超级目录,先快速找到符合条件的数据ID列表。
- HBase 则存储全量的、详细的原始请求数据。当 ES 返回ID列表后,系统再根据 ID 去 HBase 里提取完整的"档案"。
这种"索引+数据"的分离设计,既保证了查询速度,又满足了数据详查的需求。
5.结算数据,单独安放
经由 Flink 加工生成的、用于费用结算的结构化数据 ,被存入 MySQL。这类数据查询和处理频率相对较低,但要求较高的准确性和事务性,关系型数据库正是其合适归宿。
总结一下 :这套架构从本地日志的"快写"开始,经由 Kafka 缓冲,通过 Flink 进行实时加工与分流,最终让数据在 ES、HBase 和 MySQL 中各司其职,共同支撑起海量埋点数据的采集、处理、查询与结算的全链路需求,实现了性能、可靠性与灵活性的平衡。
4.小结
本章没有深挖复杂的技术细节,而是重点呈现了技术选型背后的"心路历程" ,希望能为你构建架构思维提供一份参考。
之所以未重复展开某些技术场景,是因为它们在前几章已有涉及。学习架构的秘诀在于:复杂的局面,往往是简单场景的叠加与复用 。因此后续内容会对已介绍过的场景适当精简,以便聚焦于更重要的新知识。这可能会让行文更"干"一些,但读到这里的你,已经可以带着自己的理解去吸收它们了。
说回我们设计的这个架构。它落地后表现稳健:数据丢失率极低,扩展性也经受住了考验 ------即使日活跃升至几千万,系统依然扛得住(当然,机器该加还得加,历史数据也要记得定时清理)。
还记得写缓存方案中留下的两个"未解题"吗?其中长期高并发写入 这一题,本章给出了答案。而另一题------高并发且需要争抢资源 的场景,正是我们下一章要攻克的**"秒杀"架构** 。这是一个综合性强、面试高频的重要战场,我们接着往下看。