前言:
Spring中使用了三级缓存的设计,来解决单例模式下的属性循环依赖问题
这句话有两点需要注意
- 解决问题的方法是「三级缓存的设计」
- 解决的只是单例模式下的 Bean 属性循环依赖问题,对于多例 Bean 和 Prototype 作用域的 Bean的循环依赖问题,并不能使用三级缓存设计解决。
那么前言谈到了三级缓存解决单例模式下的属性循环依赖问题,什么是循环依赖呢?
一.循环依赖
java
public class A {
@Autowired
private B b;
}
public class B {
@Autowired
private A a;
}如上代码所示,即 A 里面注入 B,B 里面又注入 A。此时,就发生了「循环依赖」。
二.三级缓存
如果你曾经看过Spring解决循环依赖的博客,应该知道它其中有好几个Map,一个Map放的是最完整的对象,称为singletonObjects,一个Map放的是提前暴露出来的对象,称为earlySingletonObjects。
Spring中,单例Bean在被创建后会被放入IoC容器的缓存池中,并触发Spring对该Bean的生命周期管理
单例模式下,在第一次使用 Bean 时,会创建一个 Bean 对象,并放入 IoC 容器的缓存池中。后续再使用该 Bean 对象时,会直接从缓存池中获取。
保存单例模式 Bean 的缓存池,采用了三级缓存设计,如下代码所示。
java
/** Cache of singleton objects: bean name --> bean instance */
/** 一级缓存:用于存放完全初始化好的 bean **/
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<String, Object>(256);
/** Cache of early singleton objects: bean name --> bean instance */
/** 二级缓存:存放原始的 bean 对象(尚未填充属性),用于解决循环依赖 */
private final Map<String, Object> earlySingletonObjects = new HashMap<String, Object>(16);
/** Cache of singleton factories: bean name --> ObjectFactory */
/** 三级级缓存:存放 bean 工厂对象,用于解决循环依赖 */
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<String, ObjectFactory<?>>(16);
singletonFactories:这是三级缓存。在一级缓存和二级缓存中,缓存的 key 是 beanName,缓存的 value 则是一个 Bean 对象,但是在三级缓存中,缓存的 value 是一个 Lambda 表达式,通过这个 Lambda 表达式可以创建出来目标对象的一个代理对象。
2.1 使用三级缓存解决依赖问题
在 AbstractBeanFactory.doGetBean() 方法中,获取单例 Bean 的主要流程是在第一次调用时尝试从缓存中获取已存在的实例getSingleton(),而此方法就使用到了三级缓存
java
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
// Spring首先从singletonObjects(一级缓存)中尝试获取
Object singletonObject = this.singletonObjects.get(beanName);
// 若是获取不到而且对象在建立中,则尝试从earlySingletonObjects(二级缓存)中获取
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
synchronized (this.singletonObjects) {
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null && allowEarlyReference) {
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
//若是仍是获取不到而且允许从singletonFactories经过getObject获取,则经过singletonFactory.getObject()(三级缓存)获取
singletonObject = singletonFactory.getObject();
//若是获取到了则将singletonObject放入到earlySingletonObjects,也就是将三级缓存提高到二级缓存中
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
}
}
}
}
return (singletonObject != NULL_OBJECT ? singletonObject : null);
}
}分析getSingleton()的整个过程,可以知道三级缓存的使用过程如下:
- Spring会先从一级缓存**
singletonObjects**中尝试获取 Bean - 若是获取不到,而且对象正在建立中,就会尝试从二级缓存**
earlySingletonObjects**中获取 Bean。 - 若还是获取不到,且允许从三级缓存**
singletonFactories**中经过singletonFactory的getObject()方法获取 Bean 对象,就会尝试从三级缓存singletonFactories中获取 Bean。 - 若是在三级缓存中获取到了 Bean,会将该 Bean 存放到二级缓存中。
2.2第三级缓存为何能解决循环依赖
Spring解决循环依赖的诀窍在于singletonFactories这个三级缓存。
当我们创建一个 AService 的时候,通过反射刚把原始的 AService 创建出来之后,先去判断当前一级缓存中是否存在当前 Bean,如果不存在
- 首先向三级缓存中添加一条记录,记录的 key 就是当前 Bean 的 beanName,value 则是一个 Lambda 表达式
ObjectFactory,通过执行这个 Lambda 可以给当前AService生成代理对象。 - 然后如果二级缓存中存在当前
AServiceBean,则移除掉。
现在继续去给 AService 各个属性赋值,结果发现 AService 需要 BService,然后就去创建 BService,创建 BService 的时候,发现 BService 又需要用到 AService,于是就先去一级缓存中查找是否有 AService,如果有,就使用,如果没有,则去二级缓存中查找是否有 AService,如果有,就使用,如果没有,则去三级缓存中找出来那个 ObjectFactory,然后执行这里的 getObject 方法,这个方法在执行的过程中,会去判断是否需要生成一个代理对象,如果需要就生成代理对象返回,如果不需要生成代理对象,则将原始对象返回即可。最后,把拿到手的对象存入到二级缓存中以备下次使用,同时删除掉三级缓存中对应的数据。这样 AService 所依赖的 BService 就创建好了。
接下来继续去完善 AService,去执行各种后置的处理器,此时,有的后置处理器想给 AService 生成代理对象,发现 AService 已经是代理对象了,就不用生成了,直接用已有的代理对象去代替 AService 即可。
至此,AService 和 BService 都搞定。
下述是ObjectFactory接口的定义:
java
public interface ObjectFactory<T> {
T getObject() throws BeansException;
}在 Bean 建立过程当中,有两处比较重要的匿名内部类实现了该接口。一处是 Spring 利用其建立 Bean 的时候,另外一处就是在**addSingletonFactory**方法中,如下代码所示。
java
addSingletonFactory(beanName, new ObjectFactory<Object>() {
@Override
public Object getObject() throws BeansException {
return getEarlyBeanReference(beanName, mbd, bean);
}
});此处就是解决循环依赖的关键,这段代码发生在 createBeanInstance 以后
- 此时,单例 Bean 对象已经实例化(可以通过对象引用定位到堆中的对象),但尚未属性赋值和初始化。
- Spring 会将该状态下的 Bean 存放到三级缓存中,提早曝光给 IoC 容器("提早"指的是不必等对象完成属性赋值和初始化后再交给 IoC 容器)。也就是说,可以在三级缓存
singletonFactories中找到该状态下的 Bean 对象。
本质上,singletonFactories 是把 AOP 的过程提前了。
2.3 解决循环依赖实例分析
java
public class A {
@Autowired
private B b;
}
public class B {
@Autowired
private A a;
}-
创建对象A,完成生命周期的第一步实例化再调用完createBeanInstance方法后,会调用addSingletonFactory方法,将已实例化但未属性赋值未初始化的对象A放入三级缓存singletonFactories中,即将对象A提早曝光给IoC容器。
-
继续,执行对象 A 生命周期的第二步,即属性赋值(Populate)。此时,发现对象 A 依赖对象,所以就会尝试去获取对象 B。
-
继续,发现 B 尚未创建,所以会执行创建对象 B 的过程。
-
在创建对象 B 的过程中,执行实例化(Instantiation)和属性赋值(Populate)操作。此时发现,对象 B 依赖对象 A。
-
继续,尝试在缓存中查找对象 A。先查找一级缓存,发现一级缓存中没有对象 A(因为对象 A 还未初始化完成);转而查找二级缓存,二级缓存中也没有对象 A(因为对象 A 还未属性赋值);转而查找三级缓存
singletonFactories,对象 B 可以通过ObjectFactory.getObject拿到对象 A。 -
继续,对象 B 在获取到对象 A 后,继续执行属性赋值(Populate)和初始化(Initialization)操作。对象 B 完成初始化操作后,会被存放到一级缓存中,而A会被放入二级缓存中以备使用。
-
继续,转到「对象 A 执行属性赋值过程并发现依赖了对象 B」的场景。此时,对象 A 可以从一级缓存中获取到对象 B,所以可以顺利执行属性赋值操作。
-
继续,对象 A 执行初始化(Initialization)操作,完成后,会被存放到一级缓存中。
2.4 为何不能解决非单例Bean的循环依赖
**question1:**Spring 为什么不能解决构造器的循环依赖
answer: 对象的构造函数是在实例化阶段调用的**。**在对象已实例化后,才会将对象存入三级缓存中。
**question2:**Spring 为什么不能解决prototype作用域循环依赖answer: Spring IoC 容器只会管理单例 Bean 的生命周期,并将单例 Bean 存放到缓存池中(三级缓存)。Spring 并不会管理
prototype作用域的 Bean
**question3:**Spring 为什么不能解决多例的循环依赖answer: 多实例 Bean 是每次调用
getBean都会创建一个新的 Bean 对象,该 Bean 对象并不能缓存。而 Spring 中循环依赖的解决正是通过缓存来实现的。
非单例Bean的循环依赖如何解决
- 对于构造器注入产生的循环依赖,可以使用
@Lazy注解,延迟加载。 - 对于多例 Bean 和
prototype作用域产生的循环依赖,可以尝试改为单例 Bean。
2.5 为什么一定要三级缓存
为什么一定要三级缓存,使用二级缓存可以解决循环依赖吗?循环依赖问题解决不是只要加入一个缓存就可以了吗?那这样二级缓存应该够用了吧。来看下面这个图:
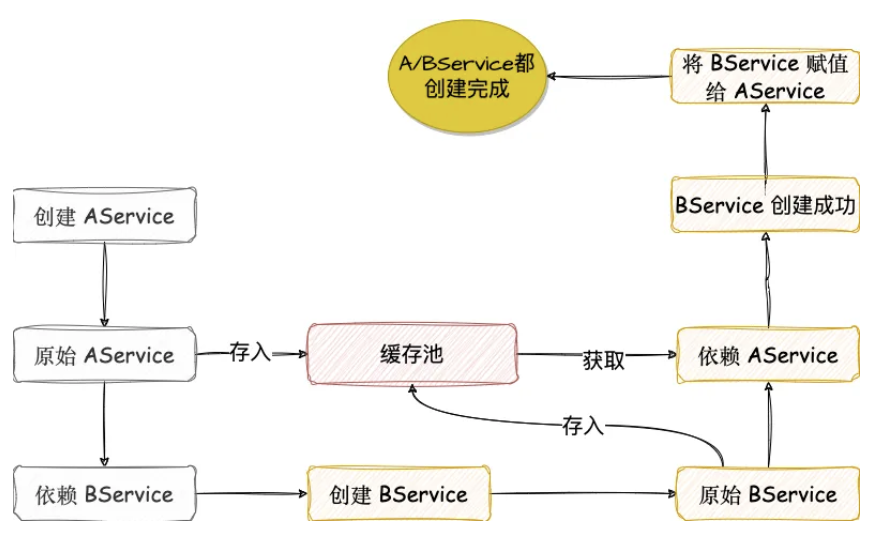
如上图所示,引入了一个缓存池。
当我们需要创建 AService 的实例的时候,会首先通过 Java 反射创建出来一个原始的 AService,这个原始 AService 可以简单理解为刚刚 new 出来(实际是刚刚通过反射创建出来)还没设置任何属性的 AService,此时,我们把这个 AService 先存入到一个缓存池中。
接下来我们就需要给 AService 的属性设置值了,同时还要处理 AService 的依赖,这时我们发 现 AService 依赖 BService,那么就去创建 BService 对象,结果创建 BService 的时候,发现 BService 依赖 AService,那么此时就先从缓存池中取出来 AService 先用着,然后继续 BService 创建的后续流程,直到 BService 创建完成后,将之赋值给 AService,此时 AService 和 BService 就都创建完成了。
可能有人会说,BService 从缓存池中拿到的 AService 是一个半成品,并不是真正的最终的 AService,但你要知道,Java 是引用传递(也可以认为是值传递,只不过这个值是内存地址),BService 当时拿到的是 AService 的引用,说白了就是一块内存地址而已,根据这个地址找到的就是 AService,所以,后续如果 AService 创建完成后,BService 所拿到的 AService 就是完整的 AService 了。
那么上面提到的这个缓存池,在 Spring 容器中有一个专门的名字,earlySingletonObjects,这是 Spring 三级缓存中的二级缓存,这里保存的是刚刚通过反射创建出来的 Bean,这些 Bean 还没有经历过完整生命周期,Bean 的属性可能都还没有设置,Bean 需要的依赖都还没有注入进来。
那按照上述的介绍,有人可能会觉得奇怪,一级缓存和二级缓存就足以解决循环依赖了,为什么还冒出来一个三级缓存?那就需要考虑AOP的情况了。
说到这里,先了解一下Spring中的AOP创建流程
正常来说是首先通过反射获取到一个Bean的实例,然后就是给这个Bean填充属性,属性填充完毕之后,接下来就是执行各种 BeanPostProcessor 了,如果这个 Bean 中有需要代理的方法,那么系统就会自动配置对应的后置处理器。
举一个简单例子,假设有如下一个 Service:
java
@Service
public class UserService {
@Async
public void hello() {
System.out.println("hello>>>"+Thread.currentThread().getName());
}
}那么系统就会自动提供一个名为 AsyncAnnotationBeanPostProcessor 的处理器,在这个处理器中,系统会生成一个代理的 UserService 对象,并用这个对象代替原本的 UserService。
那么要搞清楚的是,原本的 UserService 和新生成的代理的 UserService 是两个不同的对象,占两块不同的内存地址!!!
再来回顾下下面这张图:
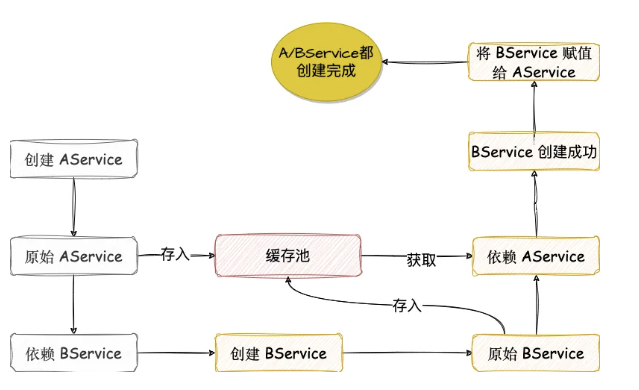
如果 AService 最终是要生成一个代理对象的话,那么 AService 存到缓存池的其实还是原本的 AService,因为此时还没到处理 AOP 那一步**(要先给各个属性赋值,然后才是 AOP 处理)**,这就导致 BService 从缓存池里拿到的 AService 是原本的 AService,等到 BService 创建完毕之后,AService 的属性赋值才完成,接下来在 AService 后续的创建流程中,AService 会变成了一个代理对象了,不是缓存池里的 AService 了,最终就导致 BService 所依赖的 AService 和最终创建出来的 AService 不是同一个。

二级缓存:
创建Bean A实例(原始对象)
✅ 直接放入二级缓存:earlySingletonObjects.put("A", 原始对象A)
Bean B需要注入A:从二级缓存拿到原始对象A
问题!Bean A实际上需要被代理,但B拿到的已经是原始对象了
后续给A创建代理对象时,B持有的还是旧的原始对象 → ❌ 不一致!
三级缓存
创建Bean A实例(原始对象)
✅ 放入三级缓存:singletonFactories.put("A", 工厂)
Bean B需要注入A:调用三级缓存中的工厂
工厂执行:getEarlyBeanReference("A", mbd, bean)
检查A是否需要代理 → 需要! → 创建代理对象A'
将代理对象A'放入二级缓存
Bean B拿到代理对象A'(正确的!)
后续A完成初始化,二级缓存中的代理对象A'被移到一级缓存
✅ Bean B和容器中的A保持一致性!
总的来说,Spring 解决循环依赖把握住两个关键点:
- 提前暴露:刚刚创建好的对象还没有进行任何赋值的时候,将之暴露出来放到缓存中,供其他 Bean 提前引用(二级缓存)。
- 提前 AOP:A 依赖 B 的时候,去检查是否发生了循环依赖(检查的方式就是将正在创建的 A 标记出来,然后 B 需要 A,B 去创建 A 的时候,发现 A 正在创建,就说明发生了循环依赖),如果发生了循环依赖,就提前进行 AOP 处理,处理完成后再使用(三级缓存)。
参考文章: