1. 引言
DeepSeek-V3.2-Exp 所搭载的稀疏化 Attention 计算,在长上下文场景中成功降低了推理延迟。但在 PD 分离架构下,随着序列长度不断增长,Decode 阶段的吞吐受限问题愈发凸显。核心症结在于,Decode 过程中 Latent Cache 规模会随序列长度呈线性增长,而 GPU 显存容量有限,这直接导致 Batch Size 难以提升,进而抑制了 Decode 阶段的吞吐增长。
基于此,本次百度百舸 AIAK 团队研究的核心目标是:针对 DeepSeek-V3.2-Exp,通过将 Latent Cache 下放到 CPU 内存,在满足延迟要求的前提下,提升 Decode 吞吐并显著降低成本。本报告详细阐述了我们为达成该目标所开展的系统瓶颈分析,以及最终提出的 Expanded Sparse Server(ESS)方案的设计与实现。
本文的主要贡献如下:
-
系统性评估了 Latent Cache Offload 策略在 DeepSeek-V3.2-Exp 上的可行性与收益边界。深入剖析了在稀疏化 Attention 框架下引入卸载 Latent Cache 的可行性、瓶颈来源与潜在收益,明确了不同环境配置与上下文长度条件下的收益上限。
-
提出 ESS(Expanded Sparse Server)系统方案,以卸载 Latent Cache 为核心实现 Decode 吞吐的无损扩展。百度百舸推出的 ESS 是一套面向工业部署的系统化方案,通过解耦 Latent Cache 存储与计算路径,实现 Decode 阶段吞吐的显著提升。同时,ESS 能与 MTP、Two-Batch Overlap 等主流优化策略无缝兼容,可作为现有推理系统的增强组件。
-
构建了高保真模拟器,用于评估多种优化策略在真实工业场景下的性能表现。该模拟器能够精确建模模型计算、通信延迟以及 Offload-Prefetch 开销,使开发者在系统实现前即可获得可靠的性能预估,显著降低工程验证成本并加速方案迭代。
模拟实验结果显示,在 32K 上下文长度下,当 MTP 从 2 提升到 4 时,ESS 方案可实现整体 123.4% 的吞吐提升。其中,53.1% 的提升源于 MTP 提升本身,剩余 70.2% 的性能收益则由 ESS 所实现的 Offload-Prefetch 机制贡献。
针对超长上下文场景的额外测试结果表明,在 MTP = 2 且上下文长度为 128K 的条件下,ESS 的 Offload-Prefetch 机制能直接带来高达 123% 的吞吐提升。
2. 问题背景及优化动机
2.1. 显存是限制吞吐的主要因素
图 1 呈现了 32K 上下文下 Batch Size 与 Decode 吞吐的关系(数据由高保真模拟器生成),对应的系统配置如表 1 所示。理论上,随着 Batch Size 增大,吞吐应持续提升,这是因为 Batch Size 与 GEMM 算子的计算强度(Arithmetic Intensity)密切相关 ------ 更大的 Batch Size 能显著提高 MFU,进而提升整体算力利用率。

图 1. 吞吐和 Batch Size 之间的关系
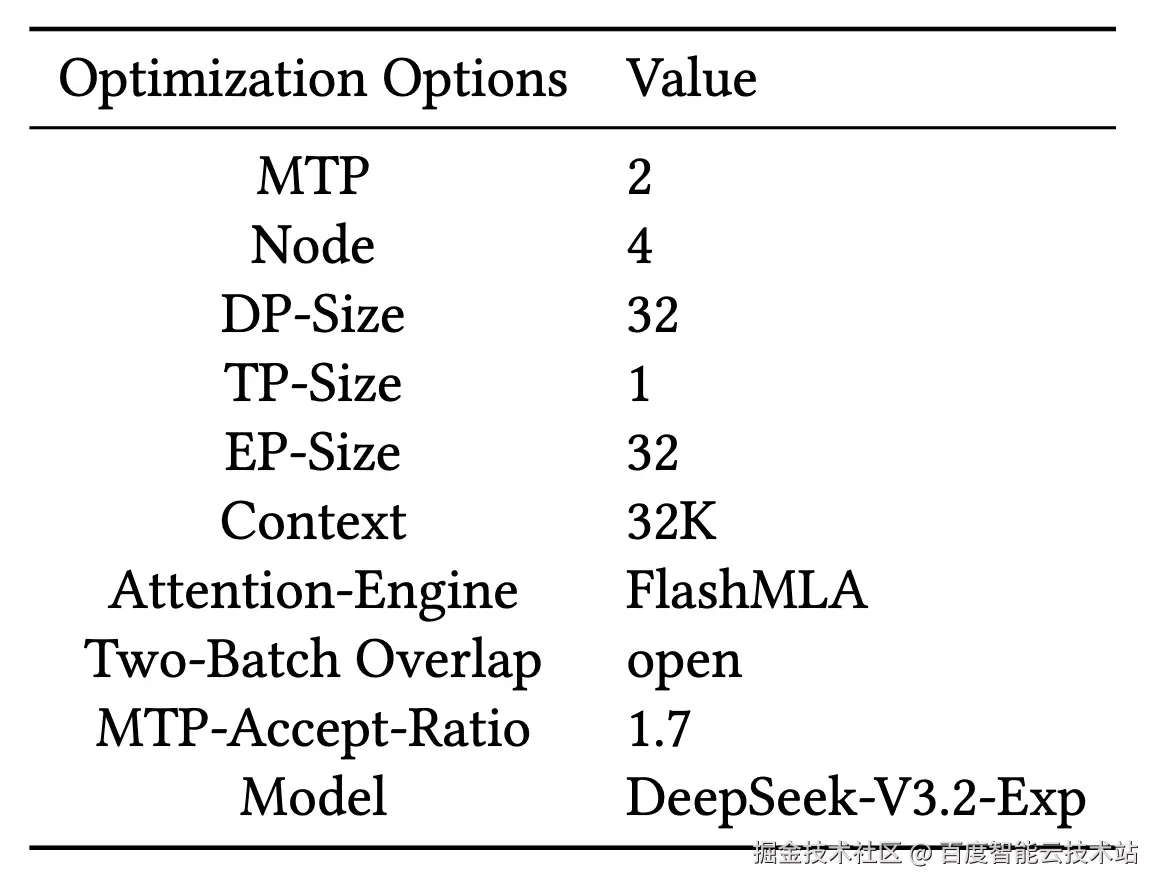
表 1. 实验环境及优化选项
但在当前配置下,GPU 显存容量成为关键瓶颈:Batch Size 最多仅能提升至 52,对应的吞吐仅为 9647 tokens/s。在此情况下,系统无法进一步扩大计算批次,导致吞吐远低于硬件理论上限。由此可得出结论:显存容量是限制 Decode 吞吐扩展的主要因素。
这一发现直接凸显了 Offload-Prefetch 策略的必要性与价值:通过打破 Latent Cache 与 GPU 显存的绑定关系,系统才能突破现有吞吐上限,进一步释放计算潜能。
2.2. Latent Cache 的访问具有时间局部性
为缓解显存压力且保证精度不受影响,将部分 Latent Cache 卸载至 CPU 是一种具备实际可行性的优化方案。但该方案要实现高效运行,需满足一个关键前提:Latent Cache 的访问模式应具有良好的局部性(Locality)。
只有当模型在访问 Latent Cache 时展现出足够的重复性或邻近性,才能维持较高的缓存命中率;否则,频繁的跨 PCIe 访问会使带宽成为新的瓶颈,从而抵消 Offloading 带来的收益。
为验证 DeepSeek-V3.2-Exp 中的 Latent-Cache 是否具备足够的局部性,我们从两个维度对其访问模式进行评估:
-
层间访问(Inter-layer Access):关注不同层之间在相邻生成步骤中对 Latent Cache 访问的相似程度。
-
层内访问(Intra-layer Access):关注同一层在连续生成步骤中的 Latent Cache 访问是否稳定一致。
我们分别定义了 Inter-Layer Similarity 与 Intra-Layer Similarity 两个指标,用于量化上述两类访问模式的局部性特征。第 L 层在生成第 t 步时所需的 Top-K 索引集合为 K^{L}_{t}。
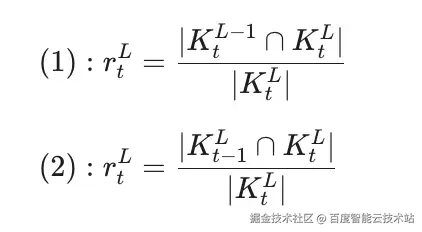
公式(1)与公式(2)分别给出了层间相似度与层内相似度的数学定义。两个指标均基于集合相似度构造,用来刻画访问需求与 GPU 中已有缓存之间的重合度 ------ 重合度越高,说明局部性越强,越适合 Offload-Prefetch 策略。
基于 LongBench-v2 数据集在 DeepSeek-V3.2-Exp 模型上的实验结果(见图 2 与图 3),我们观察到层间与层内访问均呈现出较高的相似度。
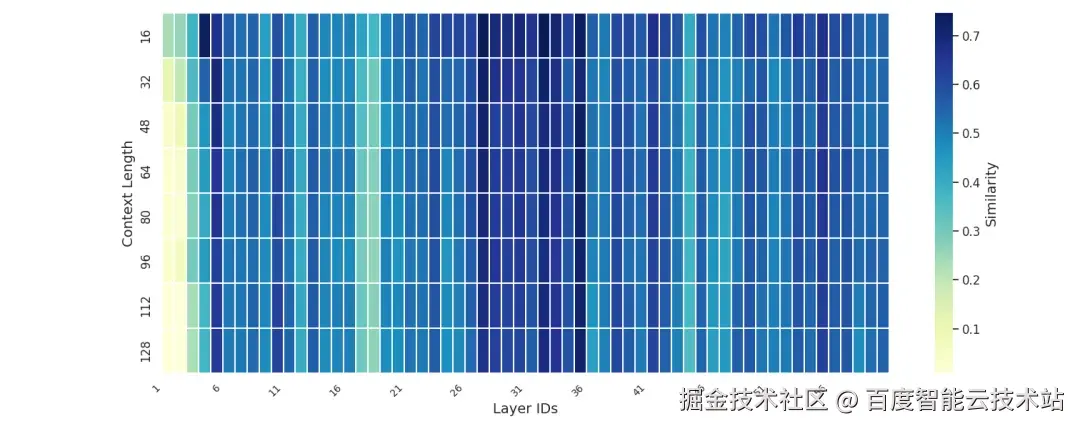
图 2. Inter-Layer Similarity 在不同上下文长度中的统计
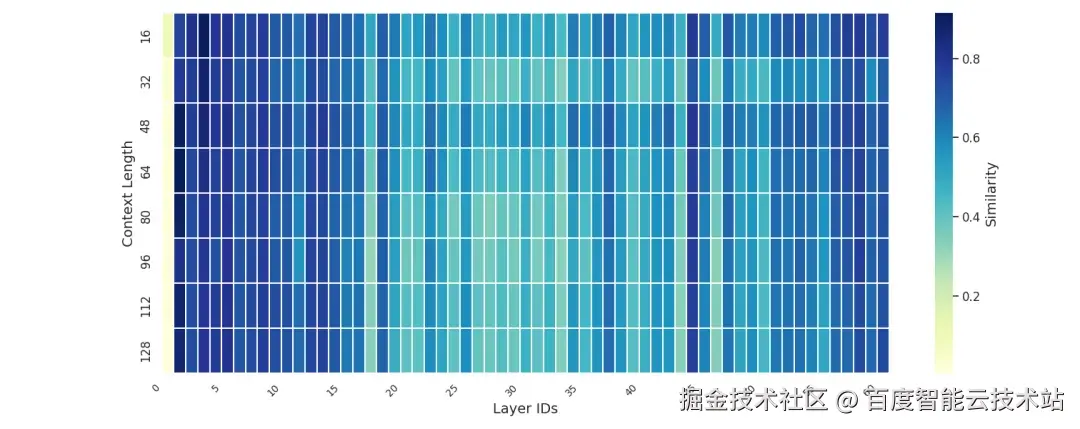
图 3. Intra-Layer Similarity 在不同上下文中的统计
这一现象表明,Latent Cache 的访问具有良好的局部性特征。因此,将 CPU 内存作为 HBM 的扩展存储空间仍是一条可行路径。尽管已有诸多类似工作探索了 CPU--GPU 协同存储,但在结合 PD 分离架构与 SGLang 推理框架时,我们仍面临以下特有挑战:
-
低效的小块数据拷贝:在 DeepSeek-V3.2-Exp 中,每个 Latent Cache 的大小仅为 656 Byte,且每次访问的 2048 个 Latent Cache 块在 Memory Pool 中呈离散分布。这种高度离散的小块数据访问模式使得 PCIe 难以形成有效的批量传输,显著降低链路带宽利用率,成为 Offload-Prefetch 类方案的主要瓶颈。
-
大量的 Cache Miss:为提升 Batch Size,需尽可能减少驻留在 GPU 上的 Latent Cache 数量。但缩小 GPU 侧的 Latent Cache 会提高 Cache Miss 的发生概率,进而增加 H2D(Host-to-Device)传输量。由于这些传输无法与计算完全重叠,由此引入的数据传输延迟会导致 Decode 阶段的吞吐量低于预期。
-
难以隐藏的数据传输延迟:在 Decode 阶段,可用于掩盖数据传输延迟的计算量不足,无法将传输完全隐藏。当大量出现 Cache Miss 时,这些传输延迟会暴露到关键路径上,进一步降低推理性能。
3. ESS 方案设计与分析
如前文所述,卸载--预取(Offload--Prefetch)是近年来广泛采用的一类无损优化策略,尤其适用于对精度高度敏感的推理场景。因此,我们在设计方案时同样以卸载为核心思路。
在 DeepSeek-V3.2-Exp 中,Cache 主要由两部分构成:Indexer Cache 与 Latent Cache。其中,Indexer Cache 用于计算每个 Latent Cache 的重要性,并从中选取最关键的 2048 个 Latent Cache 参与计算。根据模型架构分析,Indexer Cache 需要执行全量计算且其占比仅为 16.8%。基于这一事实,我们选择不对 Indexer Cache 进行卸载,仅对 Latent Cache 部分实施 Offload--Prefetch 优化。图 4 总结了在 PD 分离模式下卸载与预取的触发时机。
此外,本小节还围绕 2.2 小节中提出的关键挑战展开针对性分析,并据此给出相应的优化设计。

图 4. PD 分离场景中,Latent Cache 卸载预取时机流程图
3.1. 小块数据拷贝
尽管 PCIe 5.0 在单向方向上可提供高达 64 GB/s 的带宽,为 Offload--Prefetch 类方案带来了理论上的可行性,但在现代推理框架(如 SGLang)中,这一带宽往往难以被充分利用。原因在于 SGLang 采用 PagedAttention 管理 Latent Cache,将其划分为多个页面存储,导致页面之间在物理地址上不连续。进一步地,DeepSeek-V3.2-Exp 引入了更细粒度的稀疏化策略,将换入 / 换出的最小单元缩减到单个 Latent Cache 项。这种高度离散的小块数据访问模式会将大带宽链路切割成大量碎片化事务,从而显著降低实际可用带宽。
在 Offload--Prefetch 类方案中,Latent Cache 会发生频繁的卸载和预取操作,而 PCIe 带宽则决定了这一操作的效率。同时考虑到 Latent Cache 属于小尺寸 Cache,每个 block 为 656 字节。经测试,cudaMemcpyAsync 在这种场景中,H2D 和 D2H 的实际带宽分别仅为 0.79GB/s 和 0.23G/s。
3.1.1. FlashTrans
为缓解这一问题,我们在系统设计中引入了 UVA,使 GPU 能够直接访问 CPU 端的 pinned memory,从而减少经由 PCIe 进行小块数据传输时的管理开销。基于 UVA,我们设计了 FlashTrans CUDA 算子,其通过地址驱动的按需传输机制,避免了频繁调用 cudaMemcpyAsync 所带来的调度开销。FlashTrans 在细粒度、非连续的 Latent Cache 访问模式下显著提升了有效带宽,使得 Offload--Prefetch 在 DeepSeek-V3.2-Exp 中得以切实落地。
经测试,FlashTrans 在 H2D 和 D2H 的性能分别为 37GB/s 和 43GB/s。为确保有效带宽,对 Latent Cache 的卸载和预取,我们均使用 FlashTrans 进行。
3.2. 缓存命中保证
较高的缓存命中率能够显著降低数据传输量。为此,ESS 首先基于 LRU 算法构建换入换出引擎,对推理过程中的 Cache Miss 行为进行了系统性分析。除此之外,我们还提出 LRU-Warmup 用于保障推理初期的低 Cache Miss。
3.2.1. LRU-Warmup
GPU 端 Sparse Memory Pool 的初始状态对生成早期的性能影响显著。如图 5 所示,生成初期会出现大量 Cache Miss,但随着 Decode 的推进,该现象会快速收敛。

图 5. Decode 初期 Cache Miss 严重 MTP=1,Sparse Memory Ratio=0.2
为降低这一初始阶段的额外开销,我们对 LRU Recording 进行预热(LRU- Warmup)。具体而言,我们利用 Prefill 阶段最后 32 个窗口中所选取的 Top-2K Latent Cache Indices,并依次将其注入 LRU,以构建更符合初始生成需求的缓存状态。如图 6 所示,该策略能够显著降低 Decode 初期的 Cache Miss 量,从而提升早期推理阶段的效率。
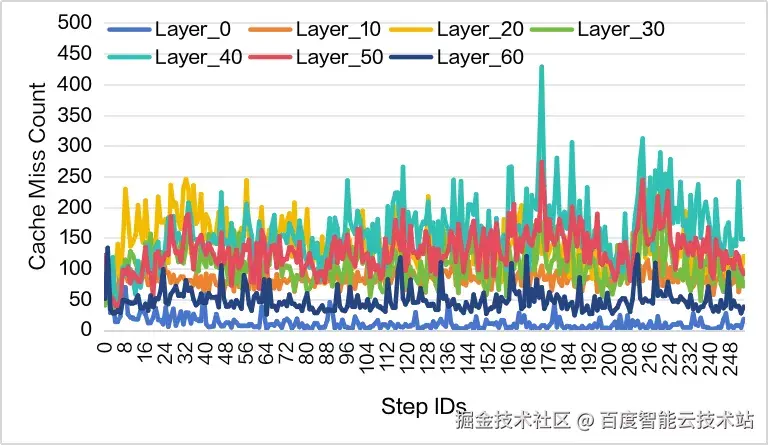
图 6. LRU-Warmup 之后的 Cache Miss 情况
3.2.2. Cache Miss 分析
在第 2.2 节中,我们验证了 Deepseek-V3.2-Exp 在 Latent Cache 访问上同时呈现层内与层间的时间局部性。这一特性表明:一旦某个 Latent Cache 在当前步被访问,其在后续步骤中再次被访问的概率仍然较高。基于这一观察,我们采用 LRU 策略对 GPU 端的 Sparse Memory Pool 进行持续更新,使其能够优先保留未来最可能被需求的 Cache。
图 7 展示了依据 Intra-Layer Access 构建 Sparse Memory Pool 后,每个 batch 的平均 Cache Miss 数量。我们进一步在不同的 Sparse Memory Ratio 下进行了对比分析,这些结果共同刻画了在不同显存预算下可获得的性能收益边界。
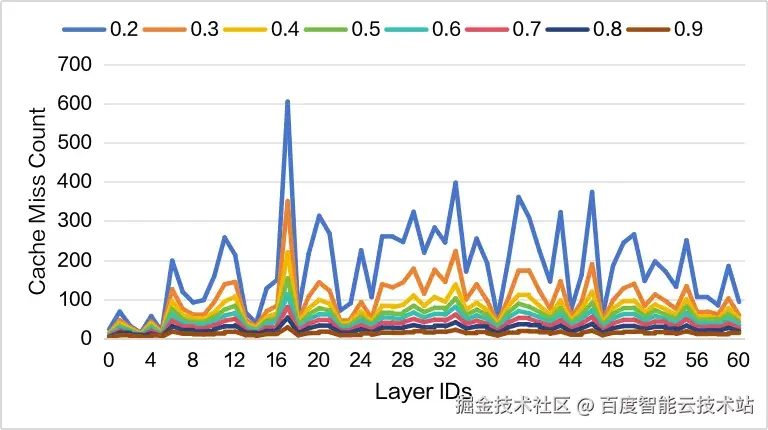
图 7. Intra-Layer Cache Miss 情况,MTP=2
为进一步降低 Decoding 期间 Cache Miss 发生率,我们尝试通过层间预取的方式缓解层内预取的 Cache Miss 压力。之所以有这样的思考,是因为我们在层间同样发现了极高的局部性(如图 1)。具体而言,我们首先根据 L−1 层的 Top-K Indices 预先从 CPU 中取出对应第 L 层的 Latent Cache。该部分数据传输将和 MLP 进行重叠。如此利用层间预取,能有效减少层内 Cache Miss 的发生。具体效果如图 7 和图 8 所示。考虑层间预取后,层内命中率计算如公式 3。
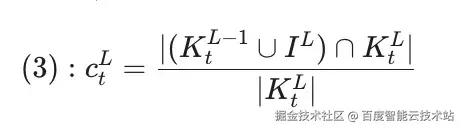
其中,I^L 表示第 L 层 Sparse Memory Pool。不过,利用层间预取时,会预取大量无用的 Latent Cache。经统计,在 Sparse Memory Ratio 为 0.2 时,层间预取的 Cache Miss 平均为 663 个每 Batch,最大为 1353 个每 Batch。因此,我们认为尽管层间预取能够缓解层内预取的 Cache Miss 压力,但无法真正对端到端加速起到作用。
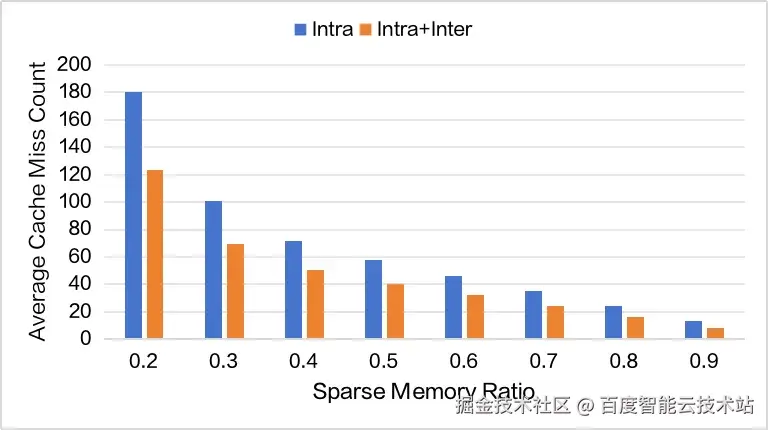
图 8. 平均 Cache Miss 情况对比
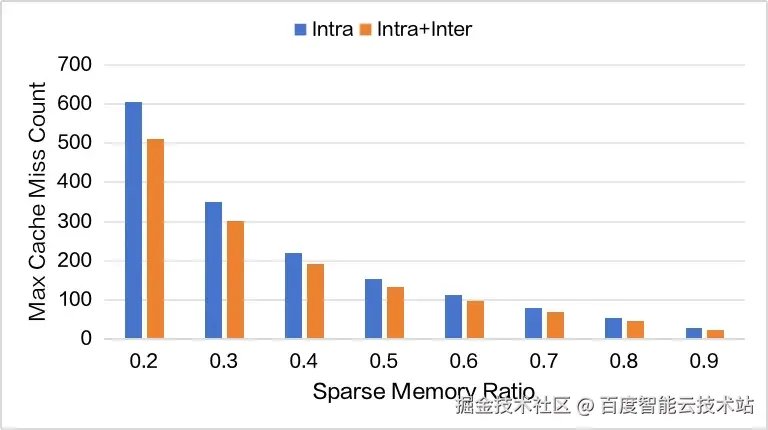
图 9. 最大 Cache Miss 情况对比
3.3. 计算传输重叠
影响端到端性能的另一项关键策略是计算与通信的重叠。基于对 SGLang 现有实现的系统性拆解与分析,我们设计了 Dual-Attention (DA) Overlap 和 DualBatch-Attention (DBA) Overlap 两种方案,以最大化计算过程与数据传输之间的重叠程度,从而进一步提升整体吞吐。
3.3.1. Overlap 作用分析
图 10 展示了在未采用 Overlap 策略时推理过程的完整 timeline。图中,H2D 表示对 Missed Latent Cache 的获取。此外,还包含一段较小的 D2H 操作,用于将当前 step 新生成的 Latent Cache 写回 CPU 端的 Total Memory Pool。
在不启用 Overlap 的情况下,这两类数据传输均必须等待 Indexer 计算完成后才能启动,而后续的 Attention 计算又必须在所有传输结束后才能继续执行。这样的严格依赖使得不同阶段无法并行,最终构成一条完全串行的执行链路,从而显著限制了整体吞吐。
3.3.2. Overlap 策略
-
Without Overlap:该模式对应当前 SGLang 的默认实现,不包含任何计算与通信的重叠。在此模式下,GPU 在等待 H2D 数据拷贝期间处于 idle 状态,导致整体吞吐率显著低于硬件可达上限。
-
DA Overlap:在 Deepseek-V3.2-Exp 的 SGLang 实现中,Attention 由两个阶段构成:forward_prepare 与 forward_core。其中,forward_prepare 又可进一步拆分为 PreAttn 与 Indexer 两部分。Indexer 表示 Indexer 本身以及所有依赖其结果的计算,PreAttn 则包含与 Indexer 无依赖关系的操作,例如 q_b_proj、bmm、copy_pe、rotary_embedding 等。为提升计算与 H2D 预取之间的重叠度,我们首先将 PreAttn 从 forward_prepare 中抽离,并推迟到 Indexer 完成之后再执行。然而,PreAttn 本身的计算量不足以完全隐藏 Latent Cache 的预取开销。为进一步增强重叠能力,SparseMLA 被划分为两个子阶段:Attn0 与 Attn1。Attn0 直接使用当前 GPU 中已存在的 Latent Cache 进行计算。Attn1 等待 H2D 预取完成后,使用新拷贝上来的 Latent Cache 继续计算。最终将两部分结果进行合并。由于 Attn0 可与 H2D 传输并行执行,因此能够有效隐藏数据拷贝延迟,显著提升整体 Overlap 程度。
-
DBA Overlap:由于 Attention 的计算量在上下文长度超过 2K 之后基本保持稳定,这使得 Dual-Attn 在长上下文场景中的重叠效果有限。为进一步提升重叠空间,我们提出了 DualBatch-Attention (DBA) Overlap。DBA 在 Dual-Attn 的基础上,将 Indexer 沿 Batch 维度划分为两部分,使得约一半的 Indexer 计算能够参与 Overlap。这样不仅扩大了可被隐藏的计算量,也使得在长上下文下仍能保持充分的计算通信重叠,从而提升端到端吞吐。
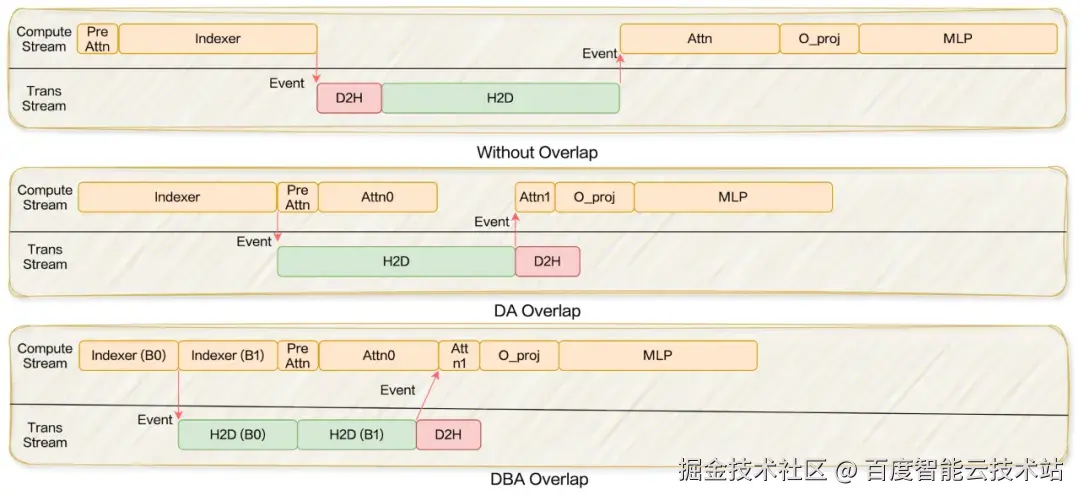
图 10. 不同 Overlap 方案对比
更具体而言,在 DBA Overlap 中,我们主要将 mqa_logits 与 Top-K 两部分纳入可重叠计算的范围。之所以选择这两部分,是因为它们的计算强度在 Batch Size 降低时并不会随之显著下降,从而能够有效抵消 Batch 切分所带来的性能损失,提高整体的重叠效率。图 10 展示了 DA Overlap 与 DBA Overlap 在实际执行过程中的 timeline 对比。
3.3.3. Layerwise Overlap 策略
如图 7 所示,不同层之间的 Cache Miss 行为存在显著差异,尤其是在 Sparse Memory Ratio 较小时。例如,当 Sparse Memory Ratio 为 0.2 时,每个 batch 的 Cache Miss 数量从 16.66 到 605 不等。如此大的波动性说明单一的 Overlap 策略无法高效适配所有层。
如图 11 所示,我们评估了三种 Overlap 策略在不同 Cache Miss Count 下的性能退化情况。在 DBA Overlap 策略中,Indexer 的计算成本会随着上下文长度线性增长,使其能够在长上下文场景中有效隐藏 Latent-Cache 的传输延迟。因此,当 Cache Miss Count 达到 512 时,DBA 由于有足够的 overlap 空间依然能够保持较高的效率。而在 Cache Miss 较低的情况下,DA Overlap 更具优势,因为它能够在不引入 Indexer 划分开销的前提下完全隐藏数据传输延迟。
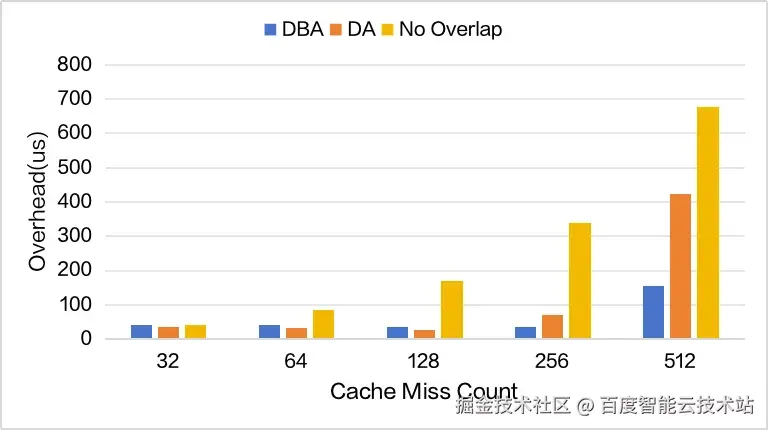
图 11. 不同 Overlap 策略的性能损耗,双流 + MTP=2,请求长度 128K,Batch Size=160,带宽为 37GB/s
我们认为,Overlap 策略的选择主要由两个因素决定:Cache Miss 情况和上下文长度。
首先,我们观察到在不同的上下文长度下,各层的 Cache Miss 沿 LayerID 的分布趋势具有高度一致性(如图 12 所示)。因此,我们可以通过预先测试,识别出在推理过程中最容易产生大量 Cache Miss 的关键层。
然后,在相同的 Sparse Memory Ratio 下,不同上下文长度所表现出的总体 Cache Miss 水平并不一致。因此,需要通过测试确定在何种 Cache Miss 阈值下应切换至 DBA 策略。
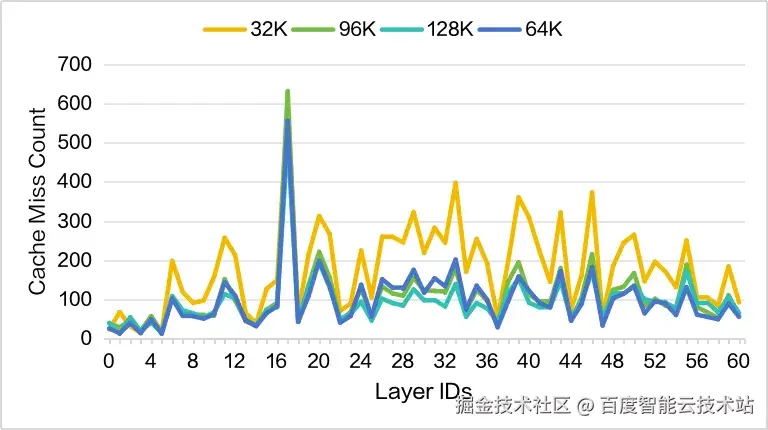
图 12. 不同上下文情况不同层的 Cache Miss 对比,MTP=2,Sparse Memory Ratio=0.2
3.4. 不同上下文长度下的可扩展性
如图 13 所示,随着上下文长度的增加,当 Sparse Memory Ratio ≥ 0.2 时,平均 Cache Miss 维持在相对稳定的水平。需要特别指出的是,在 32K 上下文条件下,当 Sparse Memory Ratio 较小时会出现最严重的 Cache Miss。
这主要是因为 GPU Buffer 过小,导致频繁的换入换出操作,从而显著增加了 Miss 发生的概率。同时如图 11 所示,我们发现 Cache Miss 过大时,现有方案无法很好地隐藏数据传输延迟,进而造成数百 us 的单层延迟。
因此,我们建议将 Sparse Memory Pool Size 最小配置为 6.4K 个 Slots,这样能够保证平均 Cache Miss 在 200 以下,确保数据传输延迟能够被有效 Overlap 起来。
同时,图 13 也表明,在相同的 Sparse Memory Ratio 下,平均 Cache Miss 随上下文长度增加而进一步下降。这意味着更长的上下文能够使用更小的 Sparse Memory Ratio,获得更大的 Batchsize 提升,进而获取更大的吞吐收益。
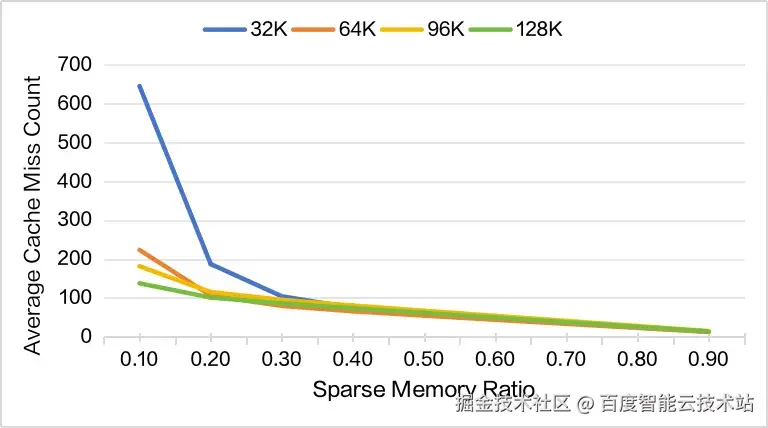
图 13. 不同长度上下文情况, 平均 Cache Miss 统计
4. 模拟验证
4.1. 模拟器
AIAK 团队基于内部自研的高仿真模拟器进行了性能评估。该模拟器的元数据来源于真实机器的运行结果,并通过线性插值补全未覆盖的数据点。同时,根据实际的计算流与传输流构建完整的执行框架,并纳入了 MTP、双流等系统优化机制的影响。
得益于该模拟器的高精度建模,我们能够在不依赖大量真实实验的情况下,准确预估大模型的推理性能,从而显著降低方案验证的成本。
4.2. 端到端性能评估
在本实验中,我们评估了 32K 上下文条件下,不同 MTP 值和接受率下的性能表现,同时将其他所有配置保持与表 1 一致。根据模拟器输出的吞吐和 OPTS 结果(表 2),可以看到:MTP = 2 能够带来 69.4% 的端到端吞吐提升;当 MTP = 4 且接受率为 3.4 时,端到端吞吐提升为 45.8%。
我们进一步在 MTP = 2、接受率为 1.7 的配置下,对 128K 的超长上下文进行了评测。由于在该上下文长度下 Batch Size 相对较小,因此我们在实验中关闭了 Two-Batch Overlap 优化。如图 9 所示,更长的上下文长度使系统能够在较低的 Sparse Memory Ratio 下运行。最终结果如表 2 所示,当 Sparse Memory Ratio 为 0.1 时,端到端吞吐获得了 123% 的性能提升。
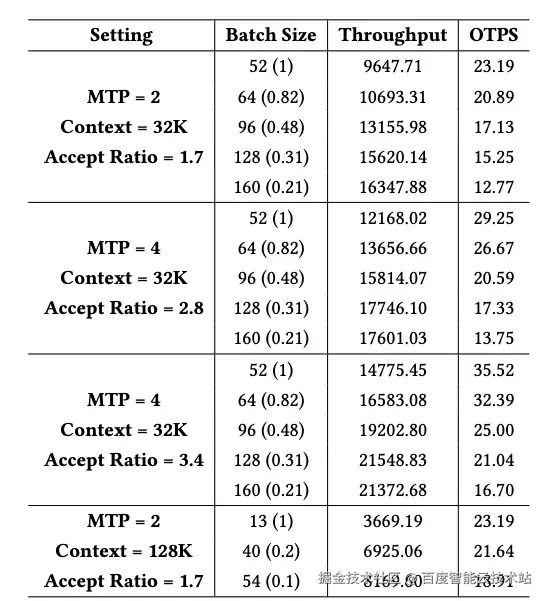
表 2. 端到端性能评估
5. 结论与展望
ESS 作为一种在精度无损前提下提升 Batch Size 的工程化方案,其核心的 Offload--Prefetch 机制已在诸多大模型推理场景中得到验证与广泛应用。
百度百舸 AIAK 团队针对 DeepSeek-V3.2-Exp 在 SGLang 中的推理路径,量身设计并模拟验证了适配该模型的 Offload 策略。实验结果充分证明了 Offload--Prefetch 机制在该模型中的可行性与显著性能潜力,为后续系统优化奠定了坚实基础。
未来,AIAK 团队不仅计划将 ESS 方案在实际框架中落地,还将进一步拓展其适用边界 ------ 依托其对 KV Cache 存储与计算路径的解耦设计、高效的数据传输优化及灵活的缓存管理机制,将 ESS 方案扩展至更多采用 KV Cache 动态压缩方案的大模型中。同时,团队还将探索 ESS 与 SnapKV 等有损压缩方法的融合应用,持续突破推理吞吐瓶颈,为各类大模型的高效部署提供更具通用性的优化方案。