一、基础原理
1. 核心逻辑
信息抽取的本质是将非结构化数据(文本、文档等)转化为结构化格式(表格、JSON、数据库等)的过程。传统方法依赖规则引擎或有监督学习,需人工设计特征和标注数据,适配性差。而大模型 + Schema的方案通过以下核心逻辑实现高效抽取:
- **Schema 引导约束:**提前定义结构化目标的字段、类型、关系(如 "新闻" Schema 包含标题、发布时间、作者、关键词、摘要),为大模型提供明确的输出框架;
- **大模型语义理解:**利用大模型强大的自然语言理解(NLU)能力,解析非结构化文本中的实体、属性、关系,无需人工设计特征;
- **格式对齐与校验:**大模型根据 Schema 要求输出结构化结果,结合后处理逻辑(格式校验、冲突修正)确保数据准确性。
2. 技术支撑
- **大模型语义编码:**将文本转化为高维语义向量,捕捉实体、属性、逻辑关系(如 LLaMA、ChatGLM 的 Transformer 编码器)
- **Schema 解析与映射:**将 Schema(JSON/XML 格式)转化为大模型可理解的自然语言指令或结构化提示(Prompt)
- **输出格式约束:**通过 Prompt Engineering(如 Few-shot 示例、格式模板)强制大模型输出符合 Schema 的结构化数据
- **后处理校验:**解决大模型输出的格式错误、字段缺失、逻辑冲突(如日期格式统一、数值范围校验)
3. 执行流程
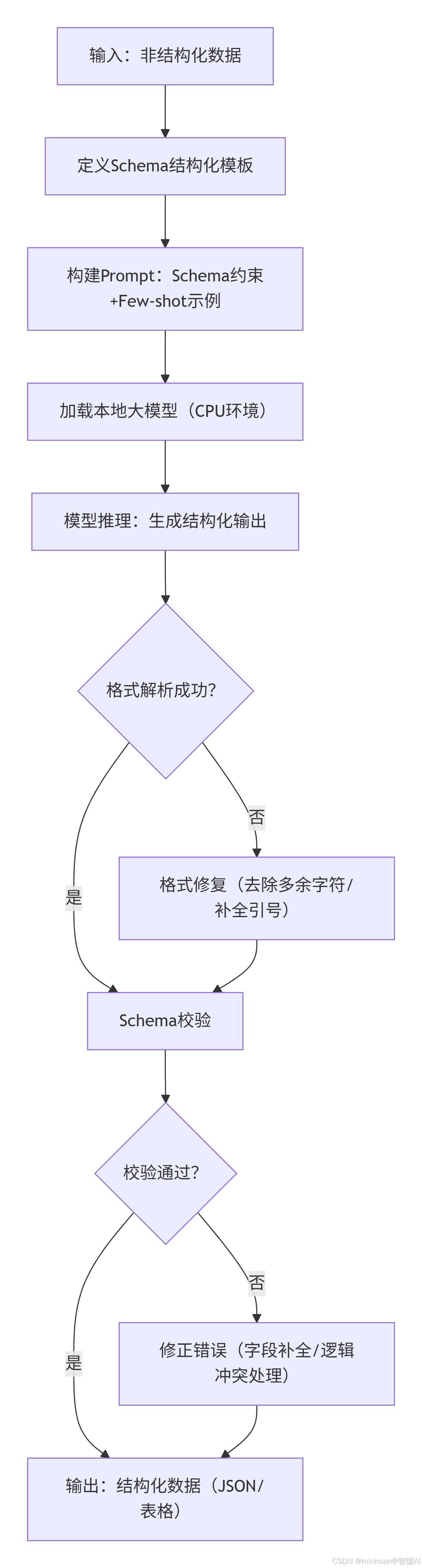
步骤说明:
-
- 输入:非结构化数据
- 输入待处理的原始文本数据,这些数据没有固定的格式,如新闻文章、报告、对话记录等。
-
- 定义Schema结构化模板
- 根据要抽取的信息,定义结构化的模板(Schema),包括字段名、数据类型、约束条件等,以规范输出格式。
-
- 构建Prompt:Schema约束+Few-shot示例
- 将Schema和少量的示例(Few-shot)整合到Prompt中,以引导大模型按照指定格式进行信息抽取。
-
- 加载本地大模型(CPU环境)
- 在CPU环境下加载本地部署的大模型(如Qwen1.5-1.8B-Chat),准备进行推理。
-
- 模型推理:生成结构化输出
- 将构建好的Prompt输入大模型,模型根据提示生成结构化的输出(通常是JSON格式的字符串)。
-
- 判断格式解析成功
- 检查模型输出的字符串是否符合JSON格式,如果不符合,进入格式修复步骤;如果符合,则直接进行Schema校验。
-
- 格式修复(去除多余字符/补全引号)
- 对模型输出的字符串进行清理,去除多余的非JSON字符,补全缺失的引号或括号,使其成为合法的JSON字符串。
-
- Schema校验
- 将解析后的JSON数据与定义的Schema进行比对,检查字段是否齐全、数据类型是否符合、约束条件是否满足等。
-
- 校验是否通过
- 如果校验通过,则输出最终的结构化数据;如果校验不通过,则进入修正错误步骤。
-
- 修正错误(字段补全/逻辑冲突处理)
- 根据校验结果,对缺失的字段进行补全(如设置为null),或处理逻辑冲突(如根据规则调整数据),然后再次尝试输出。
-
- 输出:结构化数据(JSON/表格)
- 将经过验证和修正的结构化数据以JSON或表格等形式输出,供后续使用。
二、核心概念
1. Schema(结构化模板)
- **定义:**描述目标结构化数据的 "蓝图",包含字段名称、数据类型、约束条件、字段关系。
- 核心要素:
- 字段(Field):如"title"(标题)、"publish_time"(发布时间);
- 类型(Type):字符串(string)、日期(date)、数组(array)、对象(object);
- 约束(Constraint):必填(required)、可选(optional)、枚举(enum,如"category": {"enum": "科技", "财经", "体育"});
- 嵌套关系:支持复杂结构(如"author": {"name": string, "affiliation": string})。
- 示例(新闻抽取 Schema)
javascript
{
"type": "object",
"properties": {
"title": {"type": "string", "required": true},
"publish_time": {"type": "string", "format": "YYYY-MM-DD HH:mm:ss", "required": true},
"author": {"type": "string", "required": false},
"category": {"type": "string", "enum": ["科技", "财经", "体育", "娱乐"], "required": true},
"keywords": {"type": "array", "items": {"type": "string"}, "required": true},
"abstract": {"type": "string", "required": true}
}
}2. Prompt 约束
- **定义:**通过设计精准的提示词,让大模型理解 Schema 要求并输出符合格式的结果,核心是 "语义理解 + 格式引导"。
- 关键技巧:
- 明确 Schema 说明:将 JSON Schema 转化为自然语言描述;
- Few-shot 示例:提供 1-3 个 "输入文本 + 结构化输出" 示例;
- 格式模板:指定输出格式(如 JSON、CSV),强制字段顺序。
3. 后处理(Post-processing)
- **定义:**对大模型输出的结构化数据进行清洗、校验、补全,解决模型的 "不确定性错误"。
- 核心场景:
- 格式标准化:如将 "2024 年 5 月 20 日" 统一为 "2024-05-20 00:00:00";
- 字段补全:对缺失的非必填字段填充 "无" 或通过上下文推断;
- 逻辑校验:如 "发布时间" 不能晚于当前时间,"分类" 必须在枚举列表中;
- 冲突修正:如文本中同时出现两个发布时间,取最新或最权威来源。
三. 大模型信息抽取
在基于大模型 + Schema 的结构化信息抽取场景中,Schema 是核心约束(定义 "抽什么、怎么输出"),而 Zero-shot、Few-shot、Chain-of-Thought(CoT)是三种适配不同复杂度场景的抽取范式,本质是通过不同的 Prompt 设计策略,让大模型理解 Schema 并完成抽取。
1. 统一的 Schema 定义
先定义通用的新闻抽取 Schema(后续所有范式均基于此),明确抽取目标和约束:
javascript
{
"type": "object",
"properties": {
"title": {"type": "string", "required": true, "description": "新闻标题(10-100字)"},
"publish_time": {"type": "string", "required": true, "format": "YYYY-MM-DD HH:mm:ss", "description": "发布时间"},
"category": {"type": "string", "required": true, "enum": ["科技", "财经", "体育", "娱乐"], "description": "新闻分类"},
"keywords": {"type": "array", "items": {"type": "string"}, "required": true, "minItems": 2, "maxItems": 5, "description": "核心关键词"},
"abstract": {"type": "string", "required": true, "description": "50-200字核心摘要"}
}
}该 Schema 明确了:字段名称、数据类型、必填性、格式约束(如时间格式)、枚举值(如分类)、数量限制(如关键词 2-5 个),是所有抽取范式的 "目标蓝图"。
2. Zero-shot 抽取(零样本抽取)
2.1 核心定义
仅向大模型提供Schema 约束 + 待抽取文本,不提供任何标注示例,让模型仅通过 Schema 的自然语言描述完成抽取。适用于通用场景、Schema 简单、文本结构规整的场景(如标准化新闻、通用简历)。
2.2 核心逻辑
利用大模型的 "预训练语义知识",将 Schema 的结构化要求转化为自然语言指令,让模型直接映射文本内容到 Schema 字段。
2.3 结合 Schema 的示例
2.3.1 Prompt 设计(仅含 Schema + 文本)
python
def build_zero_shot_prompt(raw_text, schema_desc):
prompt = f"""
### 任务
请严格按照以下Schema要求,抽取文本中的新闻信息,仅输出JSON格式结果(无多余内容)。
### Schema约束
{schema_desc}
### 待抽取文本
{raw_text}
### 输出要求
必须符合以下规则:
1. 字段完全匹配Schema,不得新增/缺失字段;
2. publish_time格式为YYYY-MM-DD HH:mm:ss;
3. category仅可选:科技、财经、体育、娱乐;
4. keywords为2-5个字符串组成的数组;
5. 仅输出JSON,无任何解释性文字。
"""
return prompt
# Schema自然语言描述(零样本核心:清晰传达约束)
schema_desc = """
- title:新闻标题(必填,10-100字)
- publish_time:发布时间(必填,格式YYYY-MM-DD HH:mm:ss)
- category:新闻分类(必填,仅可选:科技、财经、体育、娱乐)
- keywords:核心关键词(必填,2-5个,数组格式)
- abstract:核心摘要(必填,50-200字)
"""
# 待抽取文本
raw_text = """
【标题】2024年中国新能源汽车销量突破3000万辆 【发布时间】2025-01-20 10:30
【正文】中国汽车工业协会发布数据,2024年新能源汽车销量3020万辆,同比增长25.1%,连续8年全球第一,
电池技术升级和政策支持是核心驱动力。
"""2.3.2 模型调用与输出
python
# Qwen1.5-1.8B-Chat调用(Zero-shot模式)
messages = [
{"role": "system", "content": "你是精准的信息抽取助手,仅输出JSON格式结果。"},
{"role": "user", "content": build_zero_shot_prompt(raw_text, schema_desc)}
]
input_ids = tokenizer.apply_chat_template(messages, return_tensors="pt").to("cpu")
outputs = model.generate(input_ids, max_new_tokens=512, temperature=0.01, do_sample=False)
result = tokenizer.decode(outputs[0][input_ids.shape[1]:], skip_special_tokens=True)
# 输出结果(Zero-shot成功抽取)
{
"title": "2024年中国新能源汽车销量突破3000万辆",
"publish_time": "2025-01-20 10:30:00",
"category": "财经",
"keywords": ["新能源汽车", "销量", "3000万辆", "全球第一"],
"abstract": "2025年1月20日中国汽车工业协会发布数据,2024年新能源汽车销量达3020万辆,同比增长25.1%,连续8年位居全球第一,电池技术升级和政策支持是核心驱动力。"
}2.4 优缺点与适用场景
- 优点:无需标注示例、开发成本极低
- 缺点:复杂 Schema、模糊文本易抽取错误
- 适用场景:通用场景、Schema 简单、文本标准化
3. Few-shot 抽取(少样本抽取)
3.1 核心定义
在 Zero-shot 的基础上,补充1-5 个 "文本 + 符合 Schema 的结构化输出" 示例,让模型通过示例学习 Schema 的映射规则,提升专业场景的抽取精度。适用于Schema 较复杂、文本场景特殊(如专业领域)、Zero-shot 抽取精度不足的场景(如医疗报告、法律文书、行业新闻)。
3.2 核心逻辑
大模型的 "少样本学习能力"+ Schema 约束,通过示例具象化 "文本内容如何对应 Schema 字段",降低模型对抽象 Schema 的理解成本,提升抽取准确性。
3.3 结合 Schema 的示例
3.3.1 Prompt 设计(Schema+3 个示例 + 待抽取文本)
python
def build_few_shot_prompt(raw_text, schema_desc):
# 示例1:科技新闻(锚定Schema字段映射)
example1_text = """
【标题】ChatGLM-6B-int4版本发布 支持CPU本地运行 【发布时间】2024-03-15 09:00
【正文】智谱AI推出ChatGLM-6B的4位量化版本,普通CPU即可运行,内存占用仅8GB,适配信息抽取场景。
"""
example1_output = """
{
"title": "ChatGLM-6B-int4版本发布 支持CPU本地运行",
"publish_time": "2024-03-15 09:00:00",
"category": "科技",
"keywords": ["ChatGLM-6B", "int4量化", "CPU运行", "信息抽取"],
"abstract": "2024年3月15日智谱AI发布ChatGLM-6B-int4版本,普通CPU即可运行,内存占用仅8GB,适配信息抽取场景。"
}
"""
# 示例2:体育新闻(锚定枚举值约束)
example2_text = """
【标题】国足世预赛3-0击败越南 【发布时间】2024-06-20 20:00
【正文】2024年世预赛亚洲区比赛中,国足3-0战胜越南队,斩获小组赛首胜,进攻端效率显著提升。
"""
example2_output = """
{
"title": "国足世预赛3-0击败越南",
"publish_time": "2024-06-20 20:00:00",
"category": "体育",
"keywords": ["国足", "世预赛", "3-0", "越南"],
"abstract": "2024年6月20日世预赛亚洲区比赛中,国足3-0击败越南队,斩获小组赛首胜,进攻端效率显著提升。"
}
"""
# 示例3:娱乐新闻(锚定关键词数量约束)
example3_text = """
【标题】周杰伦新专辑《最伟大的作品》销量破千万 【发布时间】2024-07-01 12:00
【正文】周杰伦2024年新专辑上线7天销量突破1000万张,主打歌全网播放量超5亿次。
"""
example3_output = """
{
"title": "周杰伦新专辑《最伟大的作品》销量破千万",
"publish_time": "2024-07-01 12:00:00",
"category": "娱乐",
"keywords": ["周杰伦", "新专辑", "销量破千万"],
"abstract": "2024年7月1日周杰伦新专辑《最伟大的作品》上线7天销量突破1000万张,主打歌全网播放量超5亿次。"
}
"""
prompt = f"""
### 任务
严格按照以下Schema要求,抽取文本中的新闻信息,仅输出JSON格式结果(无多余内容)。
### Schema约束
{schema_desc}
### 参考示例(共3个)
示例1输入:{example1_text}
示例1输出:{example1_output}
示例2输入:{example2_text}
示例2输出:{example2_output}
示例3输入:{example3_text}
示例3输出:{example3_output}
### 待抽取文本
{raw_text}
### 输出要求
完全遵循Schema约束,输出格式与示例一致,仅输出JSON!
"""
return prompt
# 待抽取文本(专业财经场景,Zero-shot易出错)
raw_text = """
【标题】2024年A股上市公司净利润同比增长8.2% 【发布时间】2025-01-30 15:30
【正文】证监会发布2024年A股年报数据,全部上市公司净利润合计5.6万亿元,同比增长8.2%,
其中金融行业贡献35%,制造业增长10.5%,消费行业复苏明显。
"""3.3.2 模型调用与输出
python
# Qwen1.5-1.8B-Chat调用(Few-shot模式)
messages = [
{"role": "system", "content": "你是精准的信息抽取助手,仅输出JSON格式结果。"},
{"role": "user", "content": build_few_shot_prompt(raw_text, schema_desc)}
]
input_ids = tokenizer.apply_chat_template(messages, return_tensors="pt").to("cpu")
outputs = model.generate(input_ids, max_new_tokens=512, temperature=0.01, do_sample=False)
result = tokenizer.decode(outputs[0][input_ids.shape[1]:], skip_special_tokens=True)
# 输出结果(Few-shot精准抽取专业字段)
{
"title": "2024年A股上市公司净利润同比增长8.2%",
"publish_time": "2025-01-30 15:30:00",
"category": "财经",
"keywords": ["A股", "上市公司", "净利润", "同比增长8.2%", "金融行业"],
"abstract": "2025年1月30日证监会发布2024年A股年报数据,全部上市公司净利润合计5.6万亿元,同比增长8.2%,金融行业贡献35%,制造业增长10.5%,消费行业复苏明显。"
}3.4 关键优化
- 示例数量:1-3 个最优(过多会导致 Prompt 过长,CPU 模型推理效率下降);
- 示例选择:覆盖 Schema 的核心约束(如枚举值、格式、数量限制);
- 示例格式:与目标输出完全一致(字段顺序、格式、约束均匹配 Schema)。
3.5 优缺点与适用场景
- 优点:精度高于 Zero-shot、适配专业场景
- 缺点:需要少量标注示例、Prompt 较长
- 适用场景:专业领域、Schema 复杂、Zero-shot 精度
4. Chain-of-Thought(CoT)抽取(思维链抽取)
4.1 核心定义
将复杂的 Schema 抽取任务拆解为多步逻辑推理,让模型 "分步思考":先识别文本中的核心信息→再匹配 Schema 字段→最后校验约束,适用于Schema 极复杂(嵌套结构、多维度关联)、文本信息零散、抽取逻辑复杂的场景(如企业年报、多实体关联的新闻)。
4.2 核心逻辑
- 利用大模型的 "逻辑推理能力",将 Schema 的多约束抽取拆解为单步任务;
- 每一步输出中间结果,最终汇总为符合 Schema 的结构化数据;
- 本质是 "CoT 推理 + Schema 约束" 的结合,降低单步抽取的复杂度。
4.3 结合 Schema 的示例
4.3.1 Schema 升级(复杂嵌套结构)
先扩展为复杂嵌套 Schema(CoT 的核心适用场景):
python
{
"type": "object",
"properties": {
"title": {"type": "string", "required": true},
"publish_time": {"type": "string", "required": true, "format": "YYYY-MM-DD HH:mm:ss"},
"category": {"type": "string", "required": true, "enum": ["科技", "财经", "体育", "娱乐"]},
"core_data": { // 嵌套结构(CoT重点处理)
"type": "object",
"properties": {
"total_value": {"type": "string", "required": true, "description": "核心数值(带单位)"},
"growth_rate": {"type": "string", "required": true, "description": "同比增长率"},
"contribution_sectors": {"type": "array", "items": {"type": "string"}, "required": true}
}
},
"keywords": {"type": "array", "items": {"type": "string"}, "required": true, "minItems": 2},
"abstract": {"type": "string", "required": true}
}
}4.3.2 Prompt 设计(CoT+Schema + 分步推理)
python
def build_cot_prompt(raw_text, schema_desc):
prompt = f"""
### 任务
请按照以下步骤抽取文本信息,最终输出符合Schema的JSON结果(无多余内容)。
### Schema约束
{schema_desc}
### 推理步骤(必须严格执行)
步骤1:从文本中提取新闻标题、发布时间、分类(仅选:科技/财经/体育/娱乐);
步骤2:从文本中提取核心数据:总数值(带单位)、同比增长率、贡献行业列表;
步骤3:从文本中提取2-5个核心关键词;
步骤4:基于以上信息,撰写50-200字的摘要;
步骤5:将所有信息整合为符合Schema的JSON格式,检查约束(格式、数量、枚举值)。
### 待抽取文本
{raw_text}
### 输出要求
先输出每一步的推理过程,最后输出最终JSON结果(仅JSON)!
"""
return prompt
# 待抽取文本(信息零散+嵌套Schema,普通范式易出错)
raw_text = """
【标题】2024年中国数字经济规模突破60万亿元 【发布时间】2025-02-10 11:00
【正文】工信部2025年2月发布《2024数字经济发展报告》:
1. 全年数字经济总规模60.5万亿元,同比增长10.3%;
2. 产业数字化贡献75%(制造业占40%、服务业占35%);
3. 数字产业化增长8.7%,人工智能、云计算是核心驱动力。
"""4.3.3 模型调用与输出
python
# Qwen1.5-1.8B-Chat调用(CoT模式)
messages = [
{"role": "system", "content": "你是具备逻辑推理能力的信息抽取助手,严格按步骤推理。"},
{"role": "user", "content": build_cot_prompt(raw_text, schema_desc)}
]
input_ids = tokenizer.apply_chat_template(messages, return_tensors="pt").to("cpu")
outputs = model.generate(input_ids, max_new_tokens=1024, temperature=0.01, do_sample=False)
result = tokenizer.decode(outputs[0][input_ids.shape[1]:], skip_special_tokens=True)
# 模型输出(先推理,后输出JSON)
"""
步骤1:提取基础信息
- 标题:2024年中国数字经济规模突破60万亿元
- 发布时间:2025-02-10 11:00:00
- 分类:科技
步骤2:提取核心数据
- 总数值:60.5万亿元
- 同比增长率:10.3%
- 贡献行业:制造业、服务业、人工智能、云计算
步骤3:提取关键词
- 关键词:数字经济、60.5万亿元、同比增长10.3%、制造业、人工智能
步骤4:撰写摘要
- 摘要:2025年2月10日工信部发布《2024数字经济发展报告》,全年数字经济总规模达60.5万亿元,同比增长10.3%,产业数字化贡献75%(制造业占40%、服务业占35%),数字产业化增长8.7%,人工智能、云计算是核心驱动力。
步骤5:整合JSON
{
"title": "2024年中国数字经济规模突破60万亿元",
"publish_time": "2025-02-10 11:00:00",
"category": "科技",
"core_data": {
"total_value": "60.5万亿元",
"growth_rate": "10.3%",
"contribution_sectors": ["制造业", "服务业", "人工智能", "云计算"]
},
"keywords": ["数字经济", "60.5万亿元", "同比增长10.3%", "制造业", "人工智能"],
"abstract": "2025年2月10日工信部发布《2024数字经济发展报告》,全年数字经济总规模达60.5万亿元,同比增长10.3%,产业数字化贡献75%(制造业占40%、服务业占35%),数字产业化增长8.7%,人工智能、云计算是核心驱动力。"
}
"""
# 提取最终JSON结果(过滤推理步骤)
json_start = result.find("{")
json_end = result.rfind("}") + 1
final_result = json.loads(result[json_start:json_end])4.4 CoT+Schema 的关键设计
- 步骤拆解:按 "信息识别→字段匹配→约束校验→整合输出" 拆分,每步聚焦一个 Schema 子集;
- 中间输出:强制模型输出每步推理结果(提升可解释性,便于后处理);
- 约束嵌入:每步推理中明确 Schema 规则(如步骤 1 校验分类枚举值,步骤 2 校验数值格式)。
4.5 优缺点与适用场景
- 优点:适配复杂 Schema、抽取逻辑清晰、精度最高
- 缺点:Prompt 最长、推理耗时久、CPU 占用高
- 适用场景:Schema 嵌套/多约束、文本信息零散、专业复杂场景
5. 三者抽取方式决策
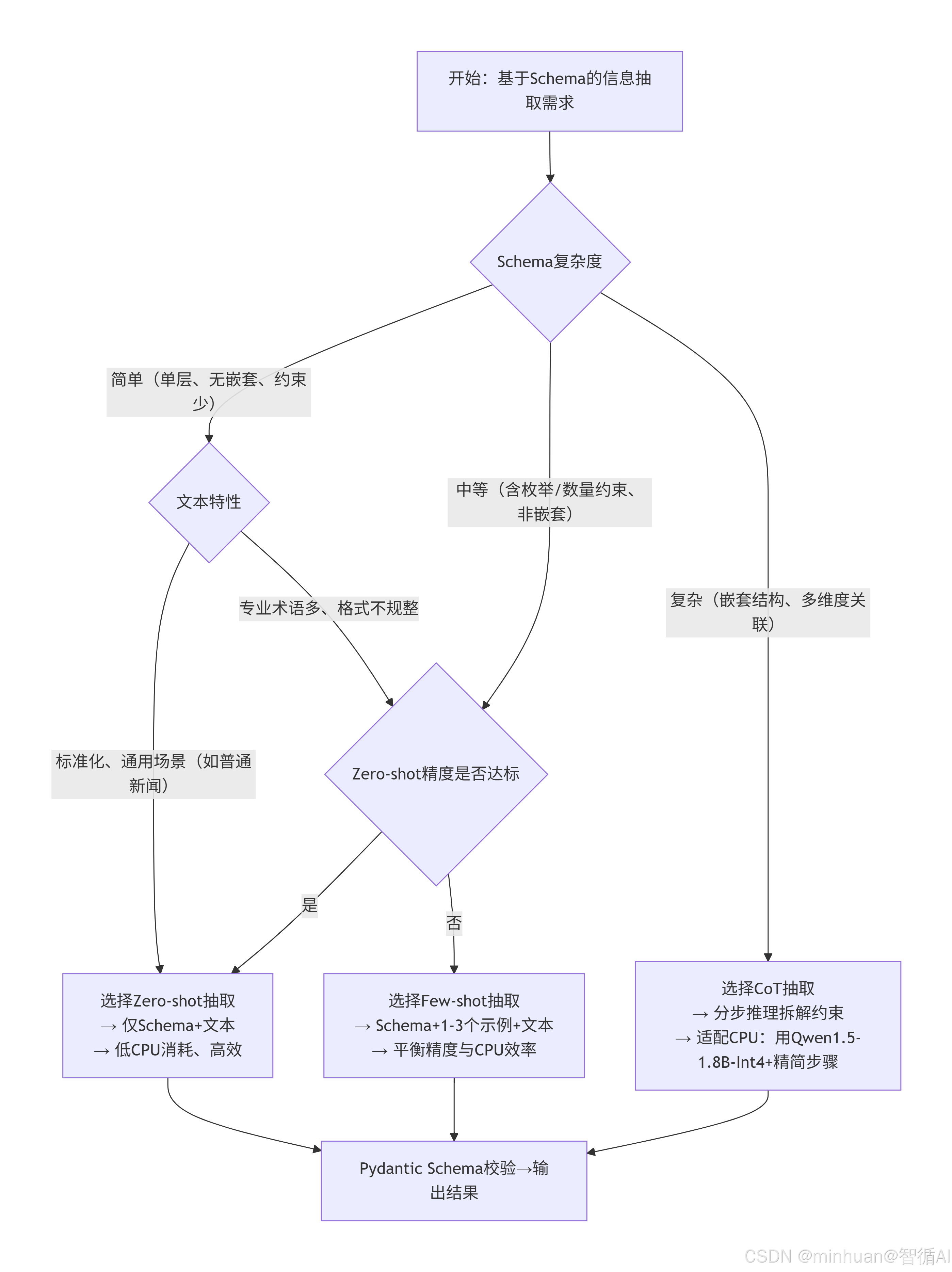
简单说明:
这个流程图描述了根据Schema复杂度和文本特性选择最合适的抽取策略的过程:
- 1. Schema复杂度判断: 根据Schema的结构复杂度分为三个级别
- 简单:单层结构,无嵌套,约束少
- 中等:包含枚举、数量约束等,但无复杂嵌套
- 复杂:多层嵌套结构,多维度关联
- 2. 文本特性判断 (针对简单Schema)
- 标准化、通用场景:适合零样本抽取
- 专业术语多、格式不规整:需要评估精度
- 3. 精度评估 (针对中等Schema)
- 如果零样本精度达标,使用零样本抽取
- 否则使用少样本抽取
- 4. 策略选择结果
- 零样本抽取:最低CPU消耗,最高效
- 少样本抽取:平衡精度与CPU效率
- CoT抽取:分步推理,适配CPU环境使用量化模型
- **5. 最终统一校验:**所有策略的输出都通过Pydantic Schema进行最终校验和格式化
四、应用示例
1. 最简单的Schema抽取
通过简单的Schema提取文本中的公司名称
python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
from modelscope.hub.snapshot_download import snapshot_download
# 加载模型
model_id = "qwen/Qwen1.5-1.8B-Chat"
cache_dir = "D:\\modelscope\\hub"
local_model_path = snapshot_download(model_id, cache_dir=cache_dir)
tokenizer = AutoTokenizer.from_pretrained(local_model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
local_model_path,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True
)
model.eval()
print("模型加载完成")
def simple_extract(text, schema):
"""最简单的抽取函数"""
prompt = f"""
请从文本中提取信息,输出JSON格式:
文本:{text}
Schema要求:{schema}
只输出JSON,不要其他内容。"""
messages = [{"role": "user", "content": prompt}]
inputs = tokenizer.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
input_ids = tokenizer(inputs, return_tensors="pt").to(model.device)
with torch.no_grad():
outputs = model.generate(
**input_ids,
max_new_tokens=200,
temperature=0.1
)
response = tokenizer.decode(outputs[0][input_ids.input_ids.shape[1]:],
skip_special_tokens=True)
return response
# 测试1:提取公司名称
text1 = "苹果公司是美国的一家科技公司。"
schema1 = '{"company_name": "公司名称"}'
result1 = simple_extract(text1, schema1)
print("示例1 - 提取公司名称")
print(f"输入: {text1}")
print(f"输出: {result1}\n")输出结果:
示例1 - 提取公司名称
输入: 苹果公司是美国的一家科技公司。
输出: {
"company_name": "苹果公司"
}
2. 多字段抽取
提取文本中的公司名称、成立年份、总部地点、首席执行官。
python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
from modelscope.hub.snapshot_download import snapshot_download
# 加载模型
model_id = "qwen/Qwen1.5-1.8B-Chat"
cache_dir = "D:\\modelscope\\hub"
local_model_path = snapshot_download(model_id, cache_dir=cache_dir)
tokenizer = AutoTokenizer.from_pretrained(local_model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
local_model_path,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True
)
model.eval()
print("模型加载完成")
def extract_multiple_fields():
"""多字段抽取示例"""
text = "特斯拉公司成立于2003年,总部在德克萨斯州奥斯汀,CEO是埃隆·马斯克。"
schema = {
"company_name": "公司名称",
"founded_year": "成立年份",
"headquarters": "总部地点",
"ceo": "首席执行官"
}
prompt = f"""请从文本中提取信息:
文本:{text}
请按照以下字段提取:
{json.dumps(schema, ensure_ascii=False, indent=2)}
输出JSON格式:"""
messages = [{"role": "user", "content": prompt}]
inputs = tokenizer.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
input_ids = tokenizer(inputs, return_tensors="pt").to(model.device)
with torch.no_grad():
outputs = model.generate(
**input_ids,
max_new_tokens=300,
temperature=0.1
)
response = tokenizer.decode(outputs[0][input_ids.input_ids.shape[1]:],
skip_special_tokens=True)
return response
import json
result2 = extract_multiple_fields()
print("示例2 - 多字段抽取")
print(f"输入: 特斯拉公司成立于2003年,总部在德克萨斯州奥斯汀,CEO是埃隆·马斯克。")
print(f"输出: {result2}\n")输出结果:
示例2 - 多字段抽取
输入: 特斯拉公司成立于2003年,总部在德克萨斯州奥斯汀,CEO是埃隆·马斯克。
输出: {
"company_name": "特斯拉公司",
"founded_year": "2003",
"headquarters": "德克萨斯州奥斯汀",
"ceo": "埃隆·马斯克"
}
3. 数组类型抽取
从文本中指定要求的经营产品列表,返回一个数据集合。
python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
from modelscope.hub.snapshot_download import snapshot_download
# 加载模型
model_id = "qwen/Qwen1.5-1.8B-Chat"
cache_dir = "D:\\modelscope\\hub"
local_model_path = snapshot_download(model_id, cache_dir=cache_dir)
tokenizer = AutoTokenizer.from_pretrained(local_model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
local_model_path,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True
)
model.eval()
print("模型加载完成")
def extract_array():
"""数组类型抽取"""
text = "华为的主要产品有手机、笔记本电脑、平板电脑、智能手表和耳机。"
schema = {
"company": "公司名称",
"products": ["产品列表", "字符串数组"]
}
prompt = f"""从文本中提取结构化信息:
文本:{text}
提取以下字段:
1. company: 公司名称
2. products: 产品列表,用数组表示
输出JSON格式:"""
messages = [{"role": "user", "content": prompt}]
inputs = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
input_ids = tokenizer(inputs, return_tensors="pt").to(model.device)
with torch.no_grad():
outputs = model.generate(**input_ids, max_new_tokens=300, temperature=0.1)
response = tokenizer.decode(outputs[0][input_ids.input_ids.shape[1]:],
skip_special_tokens=True)
return response
result3 = extract_array()
print("示例3 - 数组类型抽取")
print(f"输入: 华为的主要产品有手机、笔记本电脑、平板电脑、智能手表和耳机。")
print(f"输出: {result3}\n")输出结果:
示例3 - 数组类型抽取
输入: 华为的主要产品有手机、笔记本电脑、平板电脑、智能手表和耳机。
输出: {
"company": "华为",
"products": "手机", "笔记本电脑", "平板电脑", "智能手表", "耳机"
}
4. 嵌套对象抽取
从一段示例内容中提取指定的嵌套内容信息。
python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
from modelscope.hub.snapshot_download import snapshot_download
# 加载模型
model_id = "qwen/Qwen1.5-1.8B-Chat"
cache_dir = "D:\\modelscope\\hub"
local_model_path = snapshot_download(model_id, cache_dir=cache_dir)
tokenizer = AutoTokenizer.from_pretrained(local_model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
local_model_path,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True
)
model.eval()
print("模型加载完成")
def extract_nested():
"""嵌套对象抽取"""
text = "小米14手机,售价3999元,搭载骁龙8Gen3处理器,12GB内存,256GB存储。"
schema = """
{
"product_name": "产品名称",
"price": "价格",
"specs": {
"processor": "处理器",
"memory": "内存",
"storage": "存储"
}
}
"""
prompt = f"""请从产品描述中提取信息:
文本:{text}
严格按照以下JSON Schema格式输出:
{schema}
只输出JSON,不要其他内容。"""
messages = [{"role": "user", "content": prompt}]
inputs = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
input_ids = tokenizer(inputs, return_tensors="pt").to(model.device)
with torch.no_grad():
outputs = model.generate(**input_ids, max_new_tokens=400, temperature=0.1)
response = tokenizer.decode(outputs[0][input_ids.input_ids.shape[1]:],
skip_special_tokens=True)
return response
result4 = extract_nested()
print("示例4 - 嵌套对象抽取")
print(f"输入: 小米14手机,售价3999元,搭载骁龙8Gen3处理器,12GB内存,256GB存储。")
print(f"输出: {result4}\n")输出结果:
示例4 - 嵌套对象抽取
输入: 小米14手机,售价3999元,搭载骁龙8Gen3处理器,12GB内存,256GB存储。
输出: {
"product_name": "小米14手机",
"price": 3999,
"specs": {
"processor": "骁龙8Gen3",
"memory": "12GB",
"storage": "256GB"
}
}
5. 关系抽取(三元组)
从示例内容中提取三元组内容信息。
python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
from modelscope.hub.snapshot_download import snapshot_download
# 加载模型
model_id = "qwen/Qwen1.5-1.8B-Chat"
cache_dir = "D:\\modelscope\\hub"
local_model_path = snapshot_download(model_id, cache_dir=cache_dir)
tokenizer = AutoTokenizer.from_pretrained(local_model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
local_model_path,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True
)
model.eval()
print("模型加载完成")
def extract_relations():
"""关系抽取示例"""
text = "任正非创立了华为,华为总部在深圳,胡厚崑是华为的轮值董事长。"
schema = """
{
"relations": [
{
"subject": "主体",
"predicate": "关系类型",
"object": "客体"
}
]
}
"""
prompt = f"""从文本中抽取实体关系:
文本:{text}
抽取(主体, 关系, 客体)三元组。关系类型包括:创立、位于、担任。
输出格式:
{schema}
只输出JSON:"""
messages = [{"role": "user", "content": prompt}]
inputs = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
input_ids = tokenizer(inputs, return_tensors="pt").to(model.device)
with torch.no_grad():
outputs = model.generate(**input_ids, max_new_tokens=500, temperature=0.1)
response = tokenizer.decode(outputs[0][input_ids.input_ids.shape[1]:],
skip_special_tokens=True)
return response
result5 = extract_relations()
print("示例5 - 关系抽取")
print(f"输入: 任正非创立了华为,华为总部在深圳,胡厚崑是华为的轮值董事长。")
print(f"输出: {result5}\n")输出结果:
示例5 - 关系抽取
输入: 任正非创立了华为,华为总部在深圳,胡厚崑是华为的轮值董事长。
输出: {
"relations": [
{"subject": "任正非", "predicate": "创立", "object": "华为"},
{"subject": "华为", "predicate": "位于", "object": "深圳"},
{"subject": "胡厚崑", "predicate": "担任", "object": "华为的轮值董事长"}
]
}
6. 复杂对象数组
从文本内容中提取复杂对象数组。
python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
from modelscope.hub.snapshot_download import snapshot_download
# 加载模型
model_id = "qwen/Qwen1.5-1.8B-Chat"
cache_dir = "D:\\modelscope\\hub"
local_model_path = snapshot_download(model_id, cache_dir=cache_dir)
tokenizer = AutoTokenizer.from_pretrained(local_model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
local_model_path,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True
)
model.eval()
print("模型加载完成")
def extract_complex_array():
"""复杂对象数组抽取"""
text = """
公司员工信息:
1. 张三,30岁,软件工程师,月薪25000元
2. 李四,28岁,产品经理,月薪30000元
3. 王五,35岁,技术总监,月薪50000元
"""
schema = """
{
"employees": [
{
"name": "姓名",
"age": "年龄",
"position": "职位",
"salary": "月薪"
}
]
}
"""
prompt = f"""从文本中提取员工信息:
文本:{text}
提取所有员工信息,填充到数组中。
输出格式:
{schema}
只输出JSON:"""
messages = [{"role": "user", "content": prompt}]
inputs = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
input_ids = tokenizer(inputs, return_tensors="pt").to(model.device)
with torch.no_grad():
outputs = model.generate(**input_ids, max_new_tokens=600, temperature=0.1)
response = tokenizer.decode(outputs[0][input_ids.input_ids.shape[1]:],
skip_special_tokens=True)
return response
result6 = extract_complex_array()
print("示例6 - 复杂对象数组")
print(f"输入: 公司员工信息...")
print(f"输出: {result6}\n")输出结果:
示例6 - 复杂对象数组
输入: 公司员工信息...
输出: {
"employees": [
{"name": "张三", "age": 30, "position": "软件工程师", "salary": 25000},
{"name": "李四", "age": 28, "position": "产品经理", "salary": 30000},
{"name": "王五", "age": 35, "position": "技术总监", "salary": 50000}
]
}
7. Schema信息抽取公共方法
封装统一的公共执行方法,单组指定每类需要提取的信息。
python
#!/usr/bin/env python3
"""
Schema信息抽取 - 完整可执行脚本
"""
import json
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
from modelscope import snapshot_download
class QwenSchemaExtractor:
def __init__(self):
print("初始化模型...")
model_id = "qwen/Qwen1.5-1.8B-Chat"
cache_dir = "D:\\modelscope\\hub"
print("正在下载/校验模型缓存...")
local_model_path = snapshot_download(model_id, cache_dir=cache_dir)
self.tokenizer = AutoTokenizer.from_pretrained(
local_model_path,
trust_remote_code=True
)
self.model = AutoModelForCausalLM.from_pretrained(
local_model_path,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True
)
self.model.eval()
print("模型加载完成")
def extract(self, text, schema_desc):
"""执行抽取"""
prompt = f"""请从文本中提取信息,输出JSON格式。
文本:{text}
提取要求:{schema_desc}
只输出JSON,不要其他内容。"""
messages = [{"role": "user", "content": prompt}]
inputs = self.tokenizer.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
input_ids = self.tokenizer(inputs, return_tensors="pt").to(self.model.device)
with torch.no_grad():
outputs = self.model.generate(
**input_ids,
max_new_tokens=300,
temperature=0.1,
do_sample=True
)
response = self.tokenizer.decode(
outputs[0][input_ids.input_ids.shape[1]:],
skip_special_tokens=True
)
return response
# 创建抽取器
extractor = QwenSchemaExtractor()
# 演示1:产品信息
print("\n" + "="*50)
print("演示1:产品信息抽取")
print("="*50)
product_text = "华为Mate 60 Pro手机,售价6999元,搭载麒麟9000S芯片,支持卫星通信。"
product_schema = "提取:产品名称、价格、芯片型号、特殊功能"
result = extractor.extract(product_text, product_schema)
print(f"产品:{product_text}")
print(f"输出:{result}")
# 演示2:公司信息
print("\n" + "="*50)
print("演示2:公司信息抽取")
print("="*50)
company_text = "腾讯控股有限公司成立于1998年,总部在深圳,主要业务是社交和游戏。"
company_schema = "提取:公司名称、成立年份、总部地点、主要业务"
result = extractor.extract(company_text, company_schema)
print(f"公司:{company_text}")
print(f"输出:{result}")输出结果:
==================================================
演示1:产品信息抽取
==================================================
产品:华为Mate 60 Pro手机,售价6999元,搭载麒麟9000S芯片,支持卫星通信。
输出:{
"product_name": "华为Mate 60 Pro",
"price": "6999元",
"chip_model": "麒麟9000S",
"special_features": [
"卫星通信"
]
}
==================================================
演示2:公司信息抽取
==================================================
公司:腾讯控股有限公司成立于1998年,总部在深圳,主要业务是社交和游戏。
输出:{
"公司名称": "腾讯控股有限公司",
"成立年份": "1998年",
"总部地点": "深圳",
"主要业务": "社交和游戏"
}
五、总结
基于大模型 + Schema 的信息抽取中,Zero-shot、Few-shot、CoT 三种范式核心差异在于对 Schema 的适配策略与场景匹配度。
- Zero-shot以 "Schema 约束 + 待抽文本" 为核心,无需标注示例,Prompt 成本极低,适配单层、无嵌套的简单 Schema,适合通用新闻等标准化文本,但复杂场景易出错,CPU 资源消耗最低。
- Few-shot补充 1-3 个 "文本 + 结构化输出" 示例,通过具象化映射帮模型理解 Schema 的枚举、数量等约束,精度优于 Zero-shot,适配医疗、法律等专业场景,Prompt 成本与 CPU 消耗中等。
- CoT将复杂嵌套 Schema 拆解为 "信息识别→字段匹配→校验整合" 步骤,强制模型分步推理,精度最高,可处理多维度关联的 Schema,但 Prompt 最长、推理耗时久,CPU 占用高。
实际落地需按 Schema 复杂度择取:通用简单场景优先 Zero-shot,专业场景升级 Few-shot,仅 Schema 嵌套或文本零散时用 CoT,最终均需 Pydantic 校验 Schema 约束。