每天面对成百上千个文件时,你是否也经历过这些场景:为了统一命名格式,对着文件夹里的文件逐个修改,鼠标点击到手腕发酸;想把分散的 TXT 文档合并成一个完整文件,复制粘贴花了整整一下午;整理照片时,因为文件名混乱,找一张特定图片要翻遍整个文件夹......
作为一名数据整理从业者,这些重复劳动曾占据我工作的 60% 以上时间。直到我基于 Python 开发了一款文件批处理工具,才彻底摆脱了这种低效困境。
今天想从技术实现和实际应用的角度,和大家分享批量文件处理的高效解决方案。
2422.操作演示视频
一、批量文件处理的核心痛点与解决方案
在日常工作中,文件处理的高频需求主要集中在四个场景:
- 批量重命名:无论是摄影后期的照片、视频素材,还是办公文档,统一命名格式能极大提升管理效率。但手动修改不仅耗时,还容易出现编号错误。
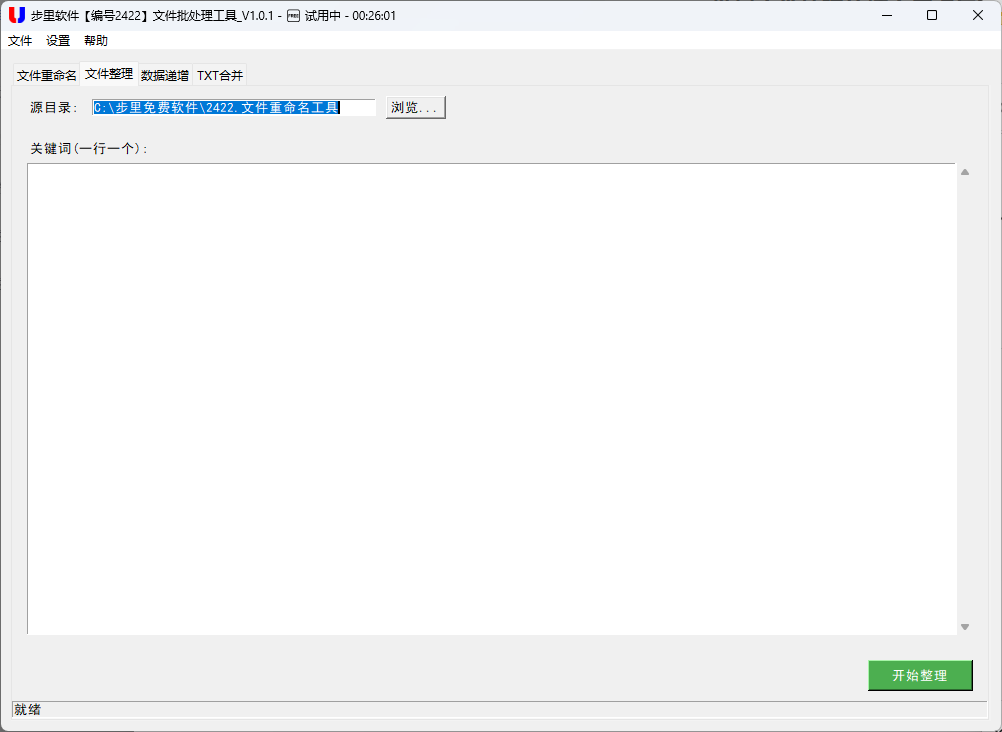
- 文件智能整理:按文件名创建文件夹并自动归类,解决 "一个文件夹塞几百个文件" 的混乱问题。
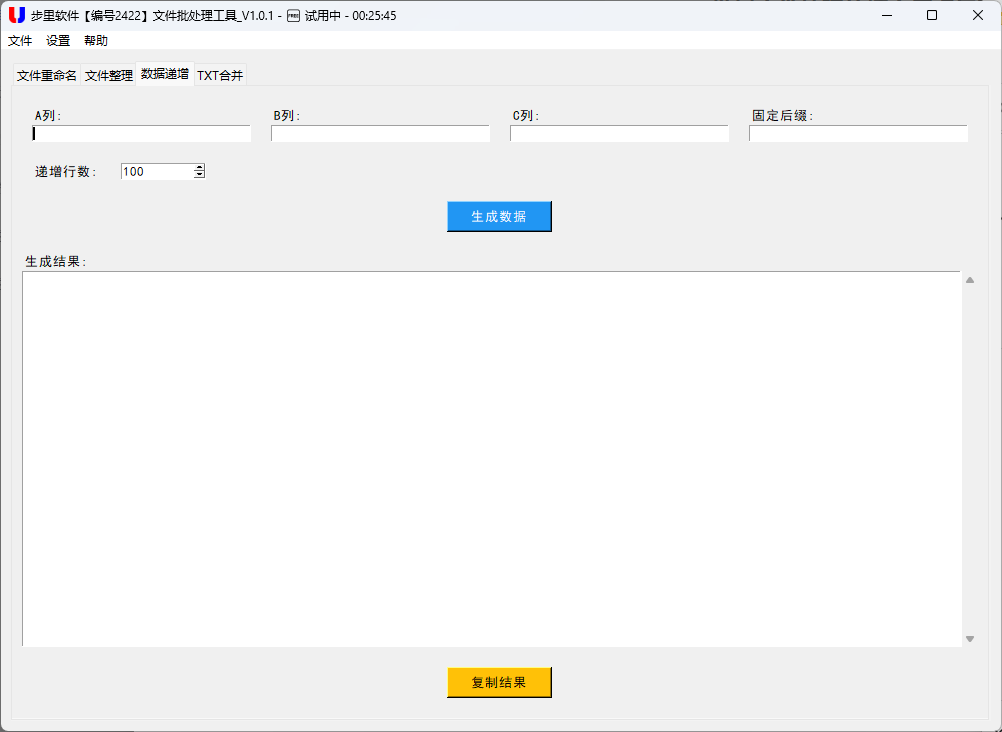
- 数据递增处理:给文件名批量添加有序编号,比如 "报告_001.docx"" 报告_002.docx",避免手动输入的繁琐。
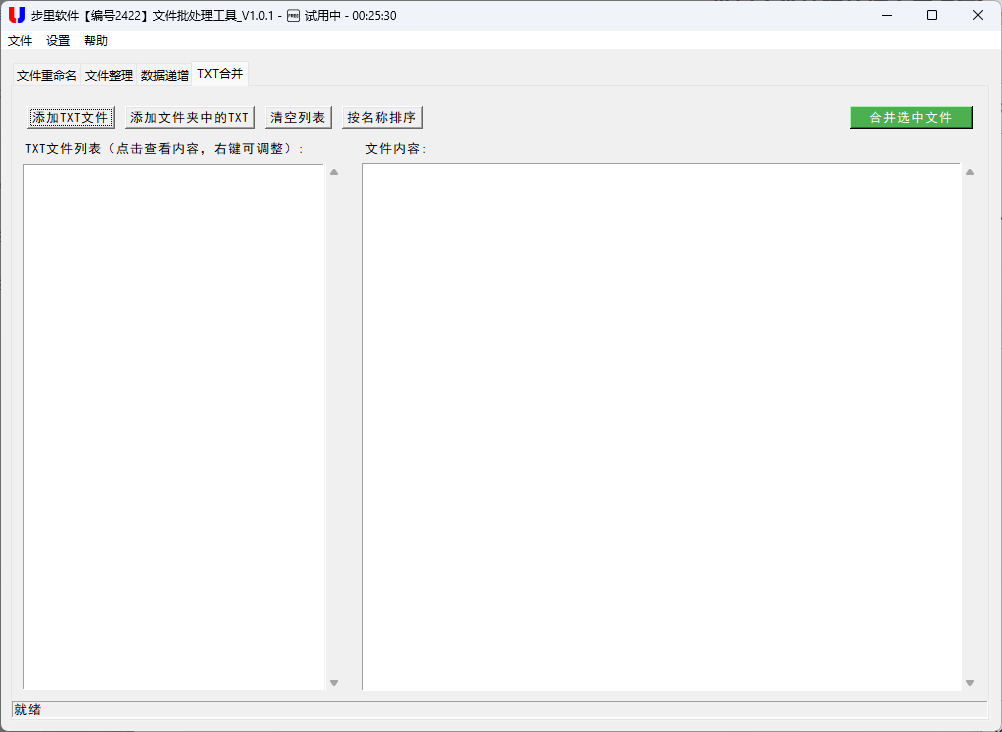
- TXT 文件合并:将多个文本片段整合为一个完整文档,常用于小说章节汇总、日志分析等场景。
针对这些需求,我开发的工具通过图形化界面,把复杂的批量处理逻辑封装成简单操作,既保留了技术的高效性,又降低了使用门槛。
二、核心功能的技术实现逻辑
一款实用的文件工具,核心在于平衡 "功能强大" 和 "操作简单"。下面从代码层面,拆解几个关键功能的实现思路。
1. 自然排序:让文件按 "人类逻辑" 排列
处理文件时,最容易遇到的问题是排序混乱。比如 "文件 10.txt" 会排在 "文件 2.txt" 前面,这是因为计算机默认按字符 ASCII 码排序。为了实现 "1、2、10" 的自然排序,工具中设计了专门的排序算法:
def rename_natural_sort_key(self, s):
"""自然排序(1、2、10顺序)"""
return [int(text) if text.isdigit() else text.lower() for text in re.split('(\d+)', s)]这段代码的原理是通过正则表达式拆分文件名中的数字和非数字部分,将数字转为整数后再排序,确保编号类文件按数值大小排列,符合人类的认知习惯。在选择文件夹或文件后,工具会自动调用这个方法,让文件列表按自然顺序展示,为后续批量处理打下基础。
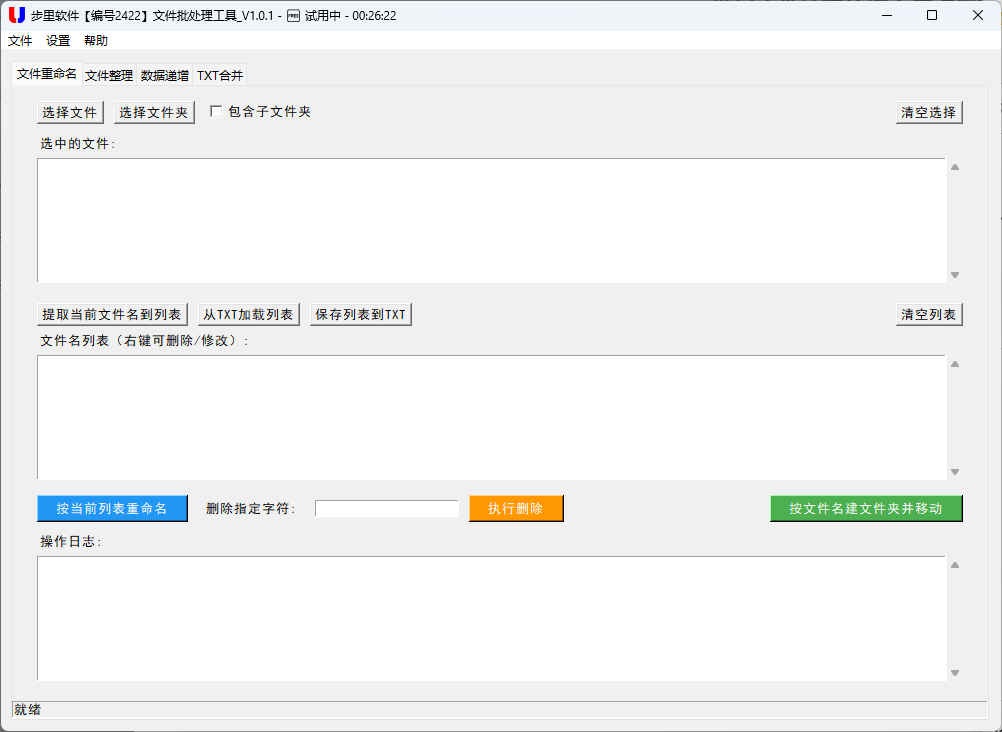
2. 批量重命名:从 "列表编辑" 到 "一键执行"
批量重命名的核心是建立 "原文件名 - 新文件名" 的映射关系。工具提供了三种灵活的命名方式:
- 提取当前文件名到编辑区,直接修改后批量应用
- 从 TXT 文件导入预设的命名列表(适合已有固定命名规则的场景)
- 自动删除文件名中的指定字符(比如批量去除广告前缀、多余符号)
其中,从 TXT 加载命名列表的实现逻辑如下:
def rename_load_names_from_txt(self):
"""从TXT加载文件名列表"""
txt_path = filedialog.askopenfilename(title="选择TXT文件", filetypes=[("文本文件", "*.txt")])
if not txt_path:
return
try:
with open(txt_path, 'r', encoding='utf-8') as f:
self.rename_filename_list = [line.strip() for line in f if line.strip()]
self.rename_update_filename_list_display()
self.rename_log(f"从 {os.path.basename(txt_path)} 加载 {len(self.rename_filename_list)} 个文件名")
except Exception as e:
messagebox.showerror("错误", f"加载失败: {str(e)}")这段代码通过文件选择对话框获取 TXT 路径,读取文件内容并过滤空行,形成新文件名列表。用户可以在图形界面中直接编辑这个列表,确认无误后点击 "按当前列表重命名",工具就会批量替换原文件名,整个过程可视化且可回溯。
3. TXT 文件合并:保留格式的高效整合
合并多个 TXT 文件时,最容易出现编码错误或格式混乱。工具的 TXT 合并功能通过统一编码处理和逐行读取,确保内容完整保留:
# TXT合并核心逻辑(简化版)
def merge_txt_files(self, file_list, output_path):
try:
with open(output_path, 'w', encoding='utf-8') as outfile:
for file_path in file_list:
with open(file_path, 'r', encoding='utf-8', errors='ignore') as infile:
# 写入文件名作为分隔符
outfile.write(f"\n===== {os.path.basename(file_path)} =====\n")
# 写入文件内容
for line in infile:
outfile.write(line)
self.txt_log(f"成功合并 {len(file_list)} 个TXT文件到 {output_path}")
except Exception as e:
messagebox.showerror("错误", f"合并失败: {str(e)}")这段代码的关键是使用errors='ignore'参数忽略个别文件的编码异常,同时在每个文件内容前添加文件名作为分隔符,让合并后的文档结构清晰。无论是小说爱好者合并章节,还是程序员汇总日志,都能快速得到整齐的结果。
三、从功能到体验:工具设计的细节考量
技术的价值最终要落地到使用体验上。在开发过程中,有几个细节设计显著提升了工具的实用性:
- 实时日志反馈:每个操作都会在日志区显示进度,比如 "已选择 25 个文件(自然排序)"" 从 list.txt 加载 30 个文件名 ",让用户清晰掌握处理状态。
- 右键菜单支持:在文件名列表编辑区,右键可以直接删除或修改某一行,无需繁琐的选中 - 删除操作,符合日常文本编辑习惯。
- 子文件夹穿透:选择文件夹时,可通过勾选 "包含子文件夹",一次性处理多层目录中的文件,避免逐层操作的重复劳动。
- 操作可逆性:所有批量修改前都会自动记录原路径,若操作失误,可通过 "撤销" 功能恢复(代码中通过列表存储操作历史实现)。
四、实际应用场景:效率提升的真实案例
在摄影工作室实习时,我曾用这个工具解决过一个实际问题:客户需要将 500 多张照片按 "日期_场景_序号" 的格式重命名。过去用系统自带的重命名功能,需要手动分组处理,至少花费 2 小时。而用工具处理的流程是:
- 选择存放照片的文件夹,工具自动按拍摄时间(通过文件名提取)自然排序;
- 提取当前文件名到列表,批量替换前缀为 "20231001_婚礼_";
- 在列表后批量添加递增序号 "001""002"...;
- 点击重命名,500 个文件在 10 秒内处理完成。
整个过程不到 5 分钟,且零错误。这种效率提升在需要高频处理文件的场景中,能显著减少重复劳动,让精力集中在更有价值的工作上。
文件处理看似是小事,但长期被低效流程消耗的时间累计起来,可能占据工作的很大比例。这款工具的开发初衷,就是通过技术手段将这些机械劳动自动化,让文件管理从负担变成轻松的事。无论是职场新人还是资深从业者,掌握高效的工具使用方法,都是提升竞争力的隐形武器。
如果你也常被批量文件处理困扰,不妨试试这类工具 ------ 技术的意义,不就是让复杂的事情变简单吗?
程序源码及软件成品下载地址:
百度:https://pan.baidu.com/s/5X6WVfCXPeknLYmCnMfLI7Q
阿里:https://www.alipan.com/s/4RvBsWkRNyA
夸克:https://pan.quark.cn/s/34600d6919d4
文件批量重命名工具,批量文件处理软件,TXT文件合并方法,文件批量改名技巧,自然排序算法实现,批量文件整理工具,Python文件处理脚本,批量重命名代码示例,多文件夹文件处理,文件批量编号工具