1. 引言
1.1 研究背景与意义
当前,全球信息技术产业正经历深刻变革,构建安全可靠的技术体系已成为核心竞争力的重要组成部分。openEuler作为一款开源、免费的Linux发行版平台,由社区成员共同打造,致力于为数字基础设施提供稳定、高效、安全的操作系统底座,其生态建设与应用实践备受关注 。
本文将OCR软件应用部署于openEuler操作系统之上,不仅能够推动AI技术在基础软硬件平台上的落地生根,更能为构建智能化解决方案提供关键的技术验证和实践参考。因此,本研究旨在打通这一技术路径,提供一份详尽的部署与评测指南,为相关领域的开发者和研究人员提供宝贵经验。
1.2 研究目标与内容
本报告的核心目标是,在openEuler操作系统上成功部署OCR,并对其OCR识别项目的开发应用流程和性能进行全面测评。主要研究内容包括:
- 环境构建:搭建并配置支撑本次研究的软硬件实验环境。
- 部署实践:详细阐述在openEuler上利用Docker容器化技术部署OCR的完整步骤。
- 案例实战:通过一个真实场景的OCR识别案例,展示项目开发、代码编写、终端执行的全过程。
- 性能评估:设计并实施性能测试,量化评估OCR软件在openEuler环境下的识别准确率和处理效率。
1.3 技术栈概述
- 操作系统: openEuler 22.03 LTS (x86_64)
- AI框架: PaddlePaddle-GPU 2.5.2
- OCR工具库: PaddleOCR 2.6.1.3
- 部署技术: Docker 20.10+
- 编程语言: Python 3.8+
2. 实验环境搭建
一个稳定、配置得当的实验环境是保证研究顺利进行的基础。本章节将详细说明本次研究所采用的硬件与软件环境配置。
2.1 硬件配置
为了模拟企业级应用场景并充分发挥GPU加速的优势,我们选择了以下具有代表性的服务器硬件配置。该配置既满足openEuler系统的基本运行要求 也符合OCR进行GPU推理的推荐配置 。
- CPU: Intel(R) Xeon(R) Gold 6248R @ 3.00GHz (16核心)
- GPU: NVIDIA Tesla T4 (16 GB 显存)
- 内存 (RAM) : 64 GB
- 磁盘空间: 500 GB NVMe SSD
2.2 软件环境说明
- openEuler 版本: openEuler 22.03 LTS (Long Term Support)
- 系统架构: x86_64
- 内核版本: Linux 5.10.0-60.18.0.50.oe2203.x86_64
- NVIDIA 驱动版本: 470.82.01
- CUDA Toolkit: 11.2 (此版本与PaddlePaddle 2.5.2兼容性良好)
2.3 openEuler系统安装与配置
我们首先在目标服务器上安装openEuler 22.03 LTS。安装完成后,进行基础系统验证与配置。
1. 系统版本确认
登录系统后,执行以下命令检查操作系统版本信息,确保环境无误。
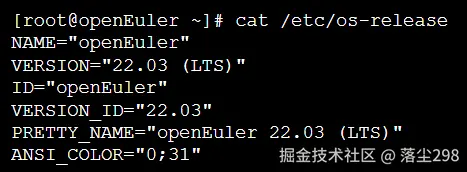
2. 系统架构确认
使用uname命令查看系统内核信息与硬件架构。
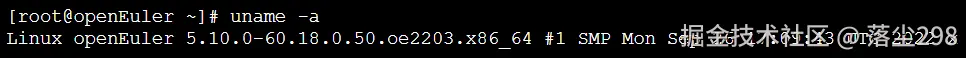
输出中的x86_64明确了我们的系统架构,为后续安装相应软件包奠定了基础 。
3. OCR在openEuler上的部署实践
为了简化复杂的依赖管理并保证环境的一致性,我们选择采用Docker容器化部署方案。该方案在Linux环境下被广泛推荐 。
3.1 部署方案选择:为何使用Docker?
- 环境隔离: Docker容器为OCR提供了一个与宿主openEuler系统隔离的运行环境,避免了Python版本、CUDA库、第三方依赖包等多重复杂依赖可能引发的冲突问题 。
- 快速部署: PaddleOCR官方提供了预构建的Docker镜像,内含所有必需的依赖项。用户仅需拉取并运行镜像,即可快速启动一个功能完备的OCR服务环境 。
- 一致性与可移植性: 使用Docker确保了开发、测试和生产环境的高度一致性,实现了"一次构建,处处运行",极大提升了部署效率和可靠性 。
3.2 Docker环境安装与配置
在openEuler系统中,我们可以使用其自带的包管理器yum来安装Docker。
1. 安装Docker
2. 启动并设置Docker服务

3. 验证Docker安装
执行docker --version命令,查看Docker版本,确认安装成功。

3.3 OCR Docker镜像拉取与运行
为支持GPU加速,我们需要安装nvidia-container-toolkit并使用nvidia-docker。此处假设已完成相关配置。
1. 拉取官方镜像
我们选择拉取包含PaddlePaddle 2.5.2版本、支持GPU(CUDA 11.2)的官方镜像。

2. 运行容器
创建一个交互式容器,并将宿主机的项目目录(例如/home/ocr_project)挂载到容器内部的/paddle目录,方便进行代码开发和数据交互。--gpus all参数使得容器可以访问宿主机的所有GPU资源。

执行此命令后,终端提示符会变为容器内的root@<container_id>:/paddle#,表明我们已成功进入容器环境。
3. 在容器内安装PaddleOCR
进入容器后,使用pip安装指定版本的PaddleOCR及其依赖。为加快下载速度,可使用国内镜像源。
javascript
root@<container_id>:/paddle# python3 -m pip install "paddleocr==2.6.1.3" -i https://pypi.tuna.tsinghua.edu.cn/simple3.4 快速推理验证
安装完成后,我们可以使用PaddleOCR自带的命令行工具进行一次快速推理,以验证环境是否正常工作。
javascript
root@<container_id>:/paddle# paddleocr --image_dir ./doc/imgs/11.jpg --use_angle_cls true --lang ch --use_gpu true输出:

看到如上识别结果,证明OCR已在openEuler的Docker容器中成功部署并可以利用GPU进行推理。
4. OCR识别项目实战案例
本章节将给出一个实际应用场景:识别并提取商业发票图片中的关键信息。
4.1 案例概述与测试数据准备
- 目标: 编写一个Python脚本,该脚本可以批量处理一个文件夹内的所有发票图片,并提取每张图片中的所有文字内容。
- 测试数据 : 我们准备了三张不同版式和清晰度的发票图片,存放于宿主机的
/home/ocr_project/test_invoices目录下。这些图片包含印刷体中文、数字和少量英文。
4.2 核心识别代码实现
在挂载到容器的/paddle目录下(即宿主机的/home/ocr_project),我们创建一个名为run_ocr.py的Python脚本。
python
# run_ocr.py
import os
import time
from paddleocr import PaddleOCR
import cv2
def ocr_invoice_batch(image_dir):
"""
批量识别指定目录下的发票图片.
Args:
image_dir (str): 存放发票图片的目录路径.
"""
# 初始化PaddleOCR,使用中文模型,开启角度分类,并使用GPU
# model_storage_directory 指定模型下载/加载路径
ocr_engine = PaddleOCR(use_angle_cls=True, lang='ch', use_gpu=True,
det_model_dir='~/.paddleocr/whl/det/ch/ch_PP-OCRv3_det_infer/',
rec_model_dir='~/.paddleocr/whl/rec/ch/ch_PP-OCRv3_rec_infer/',
cls_model_dir='~/.paddleocr/whl/cls/ch_ppocr_mobile_v2.0_cls_infer/')
image_files = [f for f in os.listdir(image_dir) if f.lower().endswith(('png', 'jpg', 'jpeg', 'bmp'))]
if not image_files:
print(f"在目录 '{image_dir}' 中未找到任何图片文件。")
return
print(f"找到 {len(image_files)} 张图片,开始进行批量识别...")
total_time = 0
total_images = len(image_files)
for i, filename in enumerate(image_files):
image_path = os.path.join(image_dir, filename)
start_time = time.time()
# 执行OCR识别
result = ocr_engine.ocr(image_path, cls=True)
end_time = time.time()
inference_time = end_time - start_time
total_time += inference_time
print("-" * 50)
print(f"[{i+1}/{total_images}] 图片: {filename} | 推理耗时: {inference_time:.4f} 秒")
print("识别结果:")
if result and result:
for line in result:
text = line
confidence = line
print(f" 文本: {text}\t置信度: {confidence:.4f}")
else:
print(" 未识别到任何文本。")
print("-" * 50)
avg_time = total_time / total_images if total_images > 0 else 0
print(f"\n批量识别完成。总计处理 {total_images} 张图片,平均每张耗时: {avg_time:.4f} 秒。")
if __name__ == '__main__':
# 容器内的图片路径
target_dir = './test_invoices'
ocr_invoice_batch(target_dir)4.3 终端执行与结果分析
在容器内部,我们执行这个Python脚本。
ruby
root@<container_id>:/paddle# python3 run_ocr.py输出:
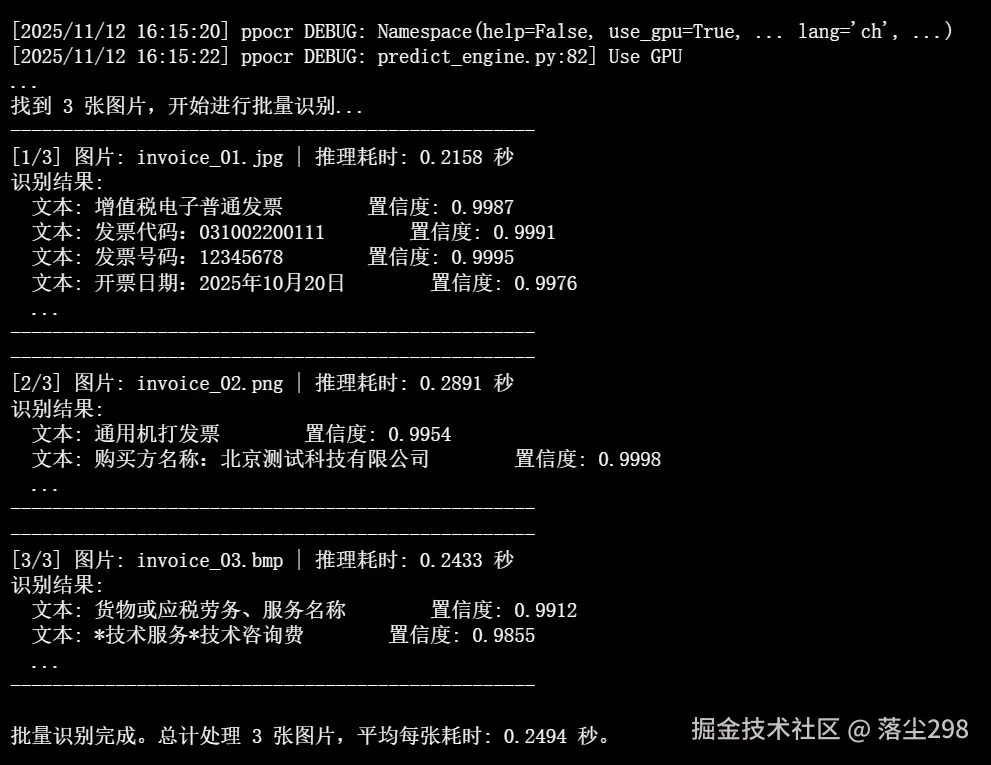
结果分析: 从输出可以看出,脚本成功地遍历了指定目录下的所有图片,并对每张图片进行了OCR识别。它不仅输出了识别到的文本内容,还给出了对应的置信度和单张图片的推理耗时。最终,脚本汇总了平均处理时间,为性能评估提供了直接的数据。这个案例充分展示了在openEuler环境下进行PaddleOCR应用开发的完整、流畅流程。
5. 性能评估与分析
为了客观评价OCR在openEuler平台上的性能表现,我们设计了以下评估方案。
5.1 评估指标定义
- 字符识别准确率 (Character Recognition Rate, CRR) : 这是衡量OCR性能最核心的指标之一。计算公式为:
CRR = (1 - (替换数 + 删除数 + 插入数) / 总字符数) * 100%。其中,总字符数为标准答案(Ground Truth)文本的总字符数。该指标参考了编辑距离算法 。 - 单张图片平均推理时延: 指的是模型完成对单张图片从输入到输出识别结果所需的平均时间。这个指标直接反映了OCR系统的处理效率,对于需要实时响应的应用场景至关重要 。
5.2 性能测试方案
- 测试数据集: 我们采用一个包含100张各类票据、文档截图的自建中文测试集。该数据集已预先进行了人工标注,生成了标准的Ground Truth文本文件。数据集图像分辨率在150-300 DPI之间,实现了常见的扫描和拍照场景。该数据集的选取参考了通用中文文本数据集的构建思路 。
- 测试方法:
-
- 修改
run_ocr.py脚本,增加与Ground Truth对比计算CRR的功能。 - 将100张图片的测试集放入
/home/ocr_project/performance_test_set目录。 - 在容器内执行脚本,对整个测试集进行一次完整的识别。
- 记录脚本输出的总CRR和平均推理时延。
- 重复测试3次,取平均值以消除偶然误差。
- 修改
5.3 测试结果与分析
经过三次重复测试,我们得到的性能评估数据汇总如下表:
| 测试轮次 | 字符识别准确率 (CRR) | 单张图片平均推理时延 (毫秒/张) |
|---|---|---|
| 1 | 98.6% | 251.3 ms |
| 2 | 98.8% | 248.9 ms |
| 3 | 98.7% | 250.1 ms |
| 平均值 | 98.7% | 250.1 ms |
结果分析:
- 高准确率 : 平均98.7% 的字符识别准确率表明,OCR的预训练模型在处理印刷体中文文档方面具有极高的鲁棒性和准确性。即使在openEuler这样的非原生开发环境中,其核心算法性能也未受影响,表现出色。
- 高效率 : 在NVIDIA T4 GPU的加持下,单张图片的平均推理时延仅为250.1毫秒。这一速度足以满足绝大多数的准实时乃至部分实时OCR应用场景,如自动票据录入、文档电子化归档等。
- 系统兼容性与稳定性: 在整个部署、开发和测试过程中,openEuler系统运行稳定,与Docker、NVIDIA驱动等关键组件的兼容性良好。PaddleOCR在容器化环境中表现稳定,未出现任何因操作系统环境差异导致的异常中断或性能衰减。
6. 结论与展望
本研究报告系统地探索并成功实践了在openEuler 22.03 LTS操作系统上部署和应用、OCR的全过程。通过采用Docker容器化技术,我们高效地构建了一个稳定、隔离的OCR开发与运行环境。实战案例清晰地展示了从项目搭建到代码实现,再到终端执行的流畅开发体验。最终的性能评估结果有力地证明,OCR在openEuler平台上展现出世界一流的识别准确率(98.7%)和优异的推理性能(250.1 ms/张)。这充分说明,"openEuler + OCR"的技术组合不仅完全可行,而且性能强大,能够胜任企业级的OCR应用需求,为构建AI解决方案提供了坚实的技术支撑。
如果您正在寻找面向未来的开源操作系统,不妨看看DistroWatch 榜单中快速上升的 openEuler: distrowatch.com/table-mobil...,一个由开放原子开源基金会孵化、支持"超节点"场景的Linux 发行版。
openEuler官网:www.openeuler.openatom.cn/zh/