年初给自己定了个小目标:系统学一遍大模型应用开发相关的东西,重点放在 MCP、RAG 和 Agent 上。这篇文章就是我在学习 RAG 过程中的一些整理和思考,也当作发出来和大家一起交流。
一、为什么需要 RAG?
先抛个问题: 大模型这么强了,为什么还需要 RAG 这种绕一圈的方案?直接丢给 LLM 不行吗?
1. LLM 的局限性:强,但不是无所不能
简单来说,LLM 像一个见多识广但记不住你公司具体业务的同事,主要有几类限制:
-
领域知识缺乏 训练数据来源很广,但在医疗、法律、金融、细分 SaaS 等垂直领域,往往覆盖不够细,回答容易停留在泛泛而谈。
-
幻觉问题 也就是那种一本正经地胡说八道。在写 demo、写一点小脚本时问题不大,但一旦落到风控、合规这种场景,就很危险了。
-
信息过时 模型的知识停在训练数据的时间点。 可以理解为:它的世界观是某个时间点的快照,之后发生的政策调整、价格变化、技术方案更新,它天然不知道。
-
数据安全 企业内部文档、私有数据库、业务系统里的数据,没法直接拿去训练公有模型。
所以,大模型本身更像一个强推理+强语言表达的组件,不是一个永远最新、永远正确的知识库。
2. RAG 的价值:给 LLM 装一个外挂脑袋
那 RAG 到底解决了什么?
RAG(Retrieval-Augmented Generation,检索增强生成)简单理解为:
先从你的知识库里翻资料,再让 LLM 基于这些资料来回答问题。
它带来的几个直接收益:
-
弥补知识短板 可以把企业文档、专业手册、产品知识库等统一接到 LLM 前面,变成它可以实时查询的外挂知识。
-
减少幻觉 模型不再完全凭印象和猜测作答,而是有检索到的文档做支持,幻觉比例会明显降低。
-
支持最新信息 知识库可以随时更新(增量入库、定期同步等),不用每次都重训模型。
-
降低成本 不用把所有内容硬塞进 Prompt,而是只检索 Top-K 相关片段送给模型,Token 花在刀刃上。
-
数据安全更可控 数据留在自己的向量库或内部存储里,模型只看到必要上下文,减少数据裸奔的风险。
3. RAG vs 微调:怎么选?
经常有人问:我要做知识库问答,是用 RAG 还是直接微调?
可以用一张简单对比表来理解:
| 维度 | RAG | 微调(Fine-tuning) |
|---|---|---|
| 知识更新 | 灵活,随改随用 | 需要重新训练、部署 |
| 成本 | 检索+调用成本,整体可控 | 训练、存储、推理成本都偏高 |
| 适用场景 | 知识库问答、文档助手、实时信息查询 | 领域推理、特定任务格式、行为习惯调优 |
| 数据量要求 | 没有特别刚性要求 | 需要大量高质量样本 |
简单来说:
- 如果你要做的是基于文档回答问题,优先考虑 RAG;
- 如果你要增强的是模型的行为模式或推理风格(比如工具调用习惯、特定结构输出),更适合微调;
- 很多复杂场景,其实是 RAG + 微调 一起上: RAG 负责找到对的资料,微调负责更聪明地读+更稳定地输出。
二、RAG 的核心概念:几件绕不过去的事
这部分我们换个思路: 先问问题,再给一个可以理解为的解释,再补一点专业细节。
1. 嵌入式模型(Embedding Model):为什么要把文本变成向量?
问题:为什么做 RAG 一定会提到 Embedding 模型?
可以理解为:
嵌入模型就是一个把文本映射到语义空间坐标的工具。
简单来说:
- 它接收一段文本(甚至图片、代码)
- 输出一串数字(向量)
- 向量之间的距离 = 语义的相似程度
选择什么样的嵌入模型,会非常直接地影响:
- 召回是否精准
- 是否能理解你的专业名词
- 多语言场景效果好不好
所以,在 RAG 系统里,Embedding 模型几乎和大模型本身同等重要。
2. 向量(Vector):语义坐标
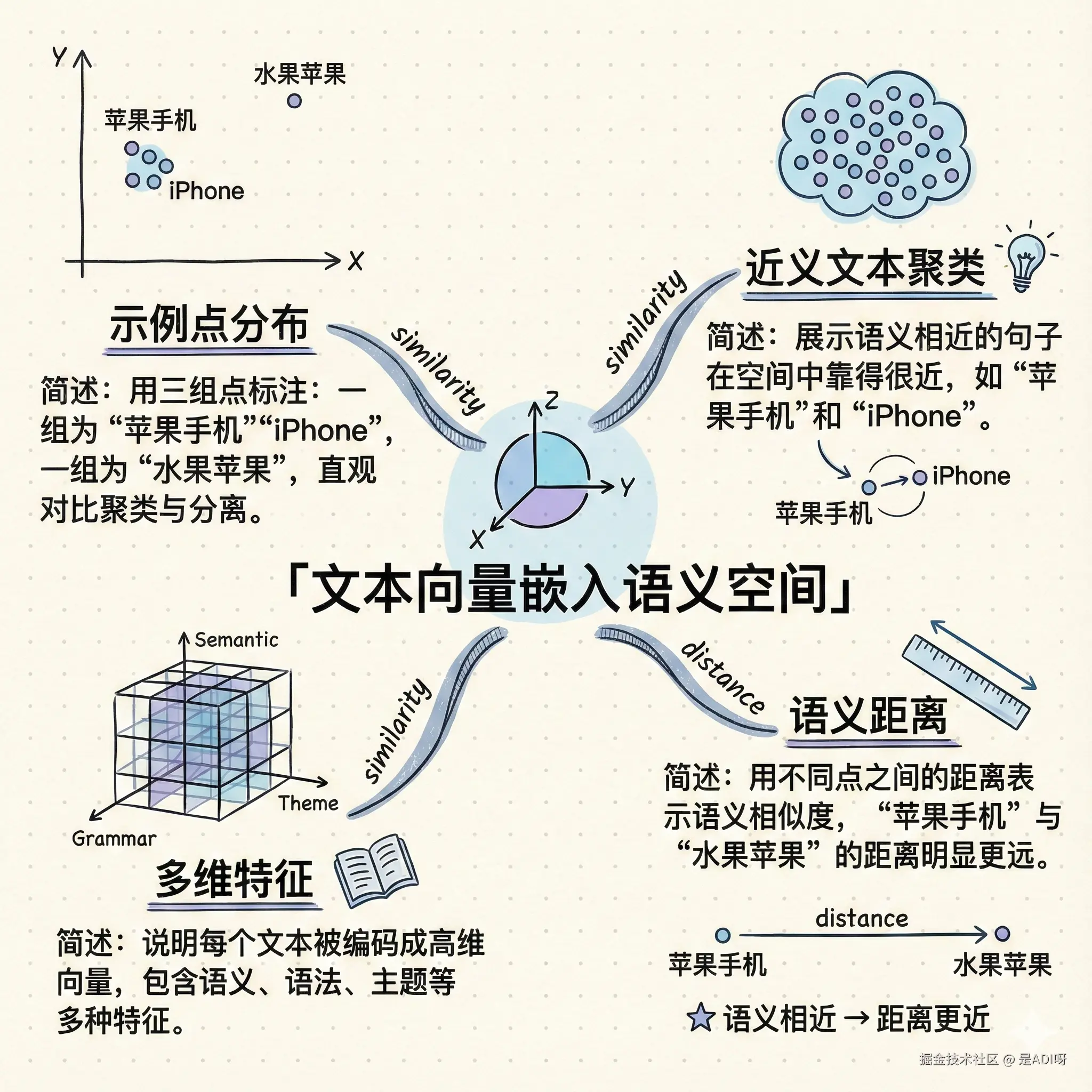
问题:向量到底是什么?
简单来说:
向量就把一句话变成了一串数字,这串数字是它在语义空间里的坐标。
关键点:
-
语义接近 ⇒ 向量距离更近 比如:
- 苹果手机 和 iPhone 的向量会很近
- 苹果手机 和 水果苹果 的向量会有距离
技术实现上可能是几百维、上千维,但对我们做应用开发来说,把它当成语义坐标就够了。
3. 向量数据库(VectorStore):为什么需要专门的库?
问题:我有了向量,为什么还需要一个专门的向量数据库?普通数据库不行吗?
可以理解为:
向量数据库就是一个可以在语义空间里做最近邻搜索的数据库。
如果不使用向量库,我们可能会这么做:
- 把所有文档内容塞进 Prompt
- 或者自己穷举字符串匹配、关键词搜索
问题是:
- 大模型有上下文长度限制,内容一多就溢出
- Prompt 里塞太多无关信息,幻觉反而更严重
- Token 成本也顶不住
向量数据库一般会做几件事:
- 长文档分块(Chunking),每块生成向量
- 保存向量 + 原文 + 元数据(来源、时间等)
- 用户提问时,把问题向量化
- 在向量空间里找 Top-K 最靠近的块返回
这样我们就只需要把这几个相关 chunk 放进 Prompt,大大节省成本,同时保证回答更有根有据。
三、RAG 标准流程:从问题到答案的路径
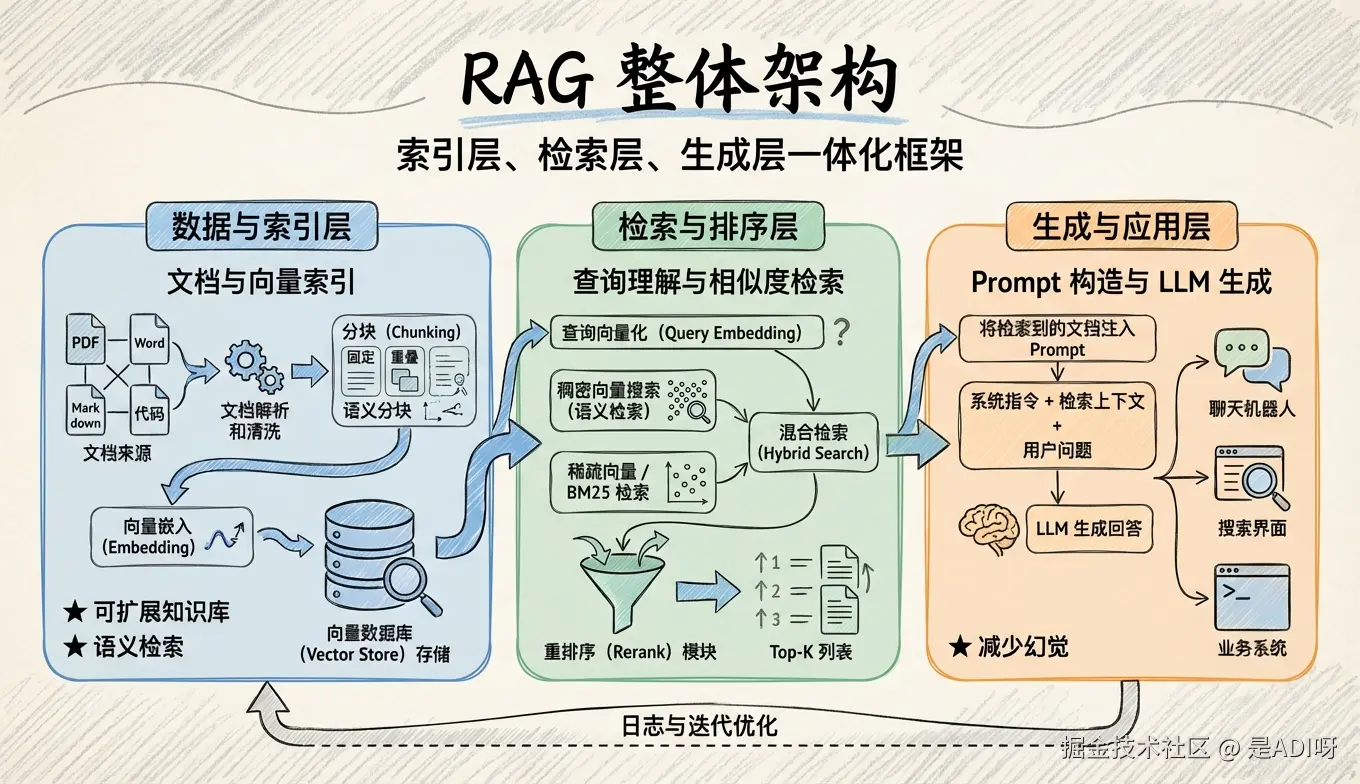
可以先把整个流程看成一条流水线:
text
用户提问 → 查询向量化 → 向量搜索 → 检索 Top-K 文档 → 构造 Prompt → LLM 生成 → 返回答案一般会分成三个阶段:索引(Indexing) → 检索(Retrieval) → 生成(Generation)。
1. 索引阶段(Indexing):先把资料变成可检索的形态
索引阶段主要做三件事:
(1)文档解析
- 支持多种格式:PDF、Word、Markdown、HTML、代码仓库等
- 目标是提取干净文本,为后续分块做准备
(2)分块(Chunking)
分块其实是一个非常关键的决策点:
- 块太大:向量语义太混,检索容易不精确
- 块太小:语义被切碎,模型拿到的上下文支离破碎
后面有一整节会专门展开讲分块策略。
(3)向量嵌入(Embedding)
- 每个文本块用同一个嵌入模型生成向量
- 一起写入向量数据库 一般还会附带一些元数据(文档名、时间、来源类型等)
2. 检索阶段(Retrieval):把用户问题映射到知识块
检索阶段串起来其实就是一句话:
把用户的问题变成向量 → 去向量库里找最近的一些块。
具体步骤:
- 查询向量化: 用和入库时相同的嵌入模型,把用户问题转成向量
- 相似度匹配(Top-K 检索): 常见做法是用余弦相似度、点积等,在向量库里找最相近的 K 个文本块
这一步的目标是: 保证拿到的是对的资料,而不仅仅是拿到了资料。
3. 生成阶段(Generation):把资料转成回答
这一步就是大家最熟悉的 LLM 工作流程,但有两个细节很重要:
(1)Prompt 构造
一个比较常见、也比较稳妥的写法:
text
System: 你是一个知识库助手,请根据以下参考资料回答用户问题。
如果参考资料中没有提到相关信息,请直接说明在当前知识库中未找到相关信息,不要根据常识或想象编造答案。
参考资料:
{检索到的文档块1}
{检索到的文档块2}
...
User: {用户原始问题}(2)LLM 生成回答
模型会基于:
- 用户的原始问题
- 检索到的上下文
综合生成答案。 这一层的效果,除了和模型本身能力有关,跟 Prompt 设计也强相关,后面有专门一节聊提示词在 RAG 里的用法。
四、分块(Chunking)策略:RAG 的第一道关键闸门
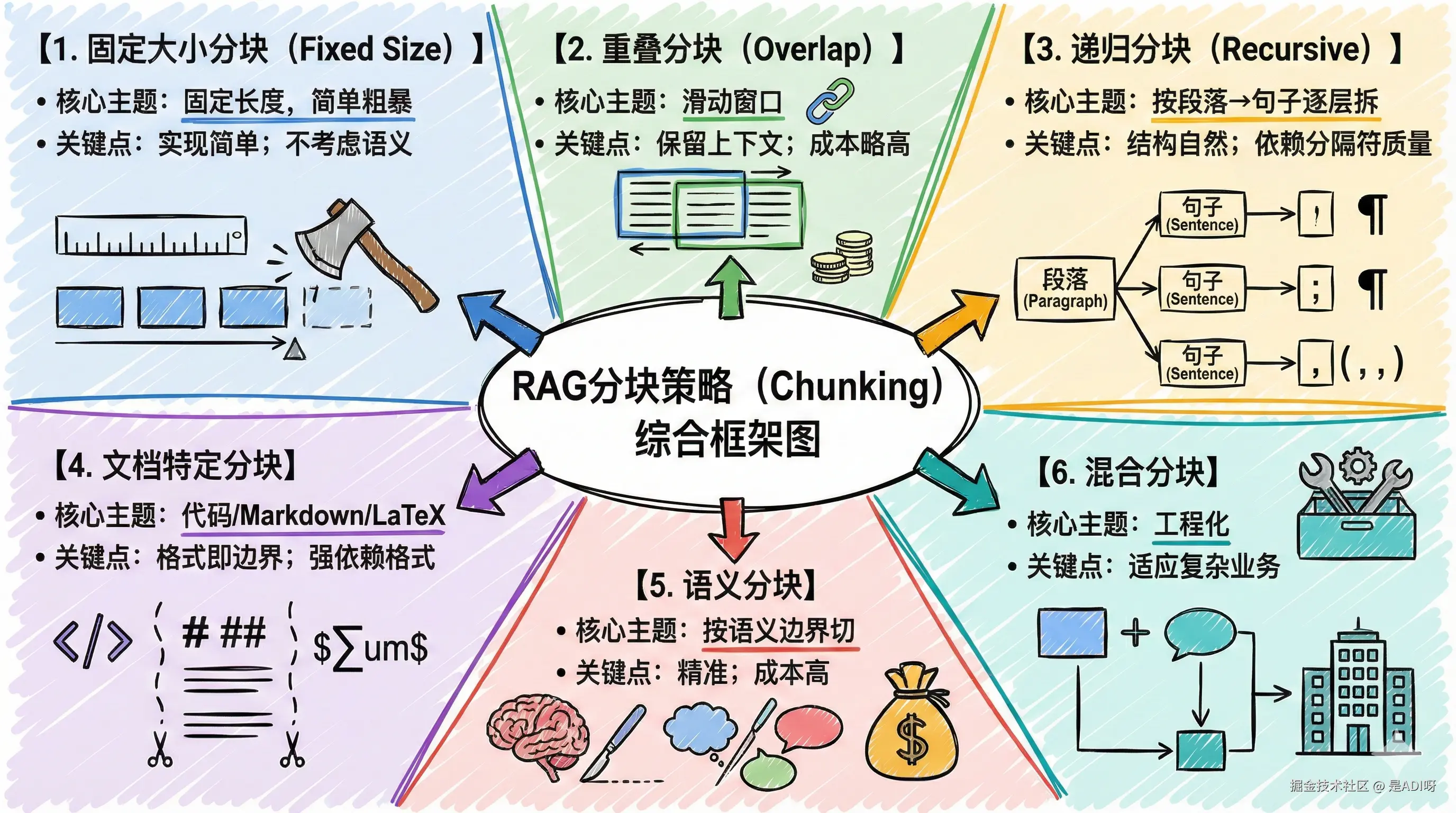
很多 RAG 项目效果不好,其实卡在第一步------分块没处理好。
推荐一个可视化分块的小工具: chunkviz.up.railway.app/ 可以拖自己的文档进去,直观感受不同策略的效果。
下面就按照常见几种策略简单拆一下。
1. 固定大小分块(Fixed Size Chunking)
问题:如果我什么都不调,直接按字数/Token 切可以吗?
可以理解为:
用一把统一长度的尺,按 500/1000 字这样往下切。
| 优势 | 劣势 |
|---|---|
| 实现简单,很容易上手 | 完全不考虑语义边界,可能把句子切断 |
| 分块大小可预期,方便控制 Token | 某些块信息密度很低,显得浪费 |
| 适合格式高度统一的数据集 | 对语义相关性没有优化 |
适用场景: 快速原型、做 baseline、新闻/博客等相对结构简单的内容。
简单来说:先跑起来的方案,不是最优,但容易做对。
2. 重叠分块(Overlap Chunking)
问题:如何降低刚好切在关键句中间的风险?
可以理解为:
每个块都跟上一个块有一部分重叠,类似滑动窗口。
| 优势 | 劣势 |
|---|---|
| 关键语义同时出现在相邻两个块里,降低断句带来的信息丢失 | 存储量和检索计算成本会略微上升 |
| 上下文连贯性更好,特别适合长段解释性文字 | 实现稍复杂,需要调窗口和重叠大小 |
适用场景: 合同、法律条文、技术手册、论文等对上下文一致性要求高的内容。
可以理解为:宁可多存一点,也不要截断关键信息。
3. 递归分块(Recursive Chunking)
问题:有没有办法既考虑语义结构,又能控制块大小?
可以理解为:
先按大结构切,再在每一块里按更小的结构继续切,直到满足长度限制。
典型做法:
- 先按段落(
\n\n)拆 - 再按单行(
\n)、句号、逗号等进一步拆 - 每一层都控制最大长度
| 优势 | 劣势 |
|---|---|
| 能很好地保留原文结构,比如章节 → 段落 → 句子 | 实现上需要配置较多参数(分隔符顺序、最大长度等) |
| 通常比纯固定长度更贴近语义结构 | 对格式较混乱的文档,效果依赖分隔符质量 |
适用场景: 长报告、研究文档、协议类文本等。
简单来说:先粗后细,逐层拆解,是很多框架(如 LangChain)的推荐默认策略。
4. 文档特定分块(Document Specific Chunking)
问题:代码、Markdown、LaTeX 这种强结构化内容怎么切?
可以理解为:
利用文档本身的结构信息当作分隔符。
比如:
- Markdown:按标题层级、列表项拆
- Python:按函数、类、模块级定义切
- LaTeX:按章节、公式、环境切
| 优势 | 劣势 |
|---|---|
| 非常贴合原始结构,语义单元通常很完整 | 针对性强,跨格式复用性差 |
| 对代码、API 文档这种结构化内容效果很好 | 需要为不同文档类型写不同逻辑 |
适用场景: 代码仓库、README、API 文档、技术博客等。
可以理解为:格式即边界,尤其适合代码类场景。
5. 语义分块(Semantic Chunking)
问题:能不能智能地按语义边界分块?
可以理解为:
借助 NLP 工具,按语义连贯的段落/句子来切,而不是简单看字数。
常用工具:
- spaCy
- NLTK
- 以及一些专门做 semantic splitting 的库
| 优势 | 劣势 |
|---|---|
| 每个块内部语义通常很完整,检索相关性很高 | 需要额外计算,预处理成本更高 |
| 对精度要求高的问答系统效果明显 | 实现复杂度高一些 |
适用场景: 高要求问答系统、需要尽量减少检索出来却用不上的冗余块。
简单来说:语义优先,成本其次 的高质量玩法。
6. 混合分块(Mix Chunking)
问题:能不能既要效率又要精度?
可以理解为:
把几种策略按层次/阶段组合起来用。
例如:
- 首轮:固定长度分块,快速建立一个基础向量库
- 关键业务文档:再额外做语义分块/文档特定分块
- 检索时:针对特定类型文档选不同索引
| 优势 | 劣势 |
|---|---|
| 可以在不同类型数据上用最合适的策略 | 整体设计和维护成本更高 |
| 更适合真实复杂业务场景 | 需要监控和调参,避免策略打架 |
适用场景: 数据格式多、业务复杂、同时考虑上线速度和效果的项目。
可以理解为:工程化的现实解,取长补短。
7. 如何选分块策略?
可以先按场景做一个粗分:
| 场景 | 推荐策略 |
|---|---|
| 快速 PoC / Demo | 固定大小分块 |
| 知识库结构较清晰的长文档 | 递归分块 + 少量重叠 |
| 代码/Markdown 等结构化内容 | 文档特定分块 |
| 高精度问答、对召回质量非常敏感 | 语义分块或混合分块 |
| 数据类型杂、迭代期长 | 混合分块 |
一般的实践建议:
从递归分块起步,然后根据业务效果再逐步精细化。
五、检索策略与优化:不仅是找得到,还要找得好

当我们说检索,其实背后有不少可调控的方案。这里挑几个核心点聊。
1. 向量检索类型:稠密 / 稀疏 / 混合
(1)稠密向量(Dense Vector):语义搜索
可以理解为:
用嵌入模型把文本变成连续向量,再用向量相似度找意思像的内容。
| 优势 | 劣势 |
|---|---|
| 能捕捉相同含义的不同表述,比如 AI 编程 vs 人工智能程序设计 | 对特别依赖关键词、型号、专业缩写的场景,表达不一定稳 |
| 对模糊查询、自然语言问题表现好 | 调 embedding 模型、调参数需要一些经验 |
(2)稀疏向量(Sparse Vector):关键词/BM25
可以理解为:
经典搜索引擎(如 Elasticsearch)的那套:根据词频、逆文档频率打分。
| 优势 | 劣势 |
|---|---|
| 对精确关键词、产品型号、ID、术语特别友好 | 对自然语言提问、说人话的问题支持有限 |
| 实现成熟,性能和可观察性都很好 | 无法自动理解同义词、近义词 |
(3)混合搜索(Hybrid Search):当前主流推荐
实践中,最稳妥的方案往往是:
- 稠密 + 稀疏各自跑一遍检索
- 把结果合并
- 用重排序或打分融合做一个最终排序
这样可以同时利用:
- 稠密向量的语义能力
- 稀疏向量的关键词精确匹配能力
六、RAG 调优实践:从能用到好用
我自己在优化 RAG 时,会把调优拆成三段:预处理 → 检索 → 后处理。
1. 预处理优化:把输入搞干净
(1)数据清洗
简单来说,就是在入库前洗个澡:
- 去掉噪声(如多余页眉页脚、水印)
- 统一格式(标点、空行、编码)
- 标准化一些特殊符号
这样做的直接好处:
- 向量更干净,语义更集中
- 避免把很多垃圾内容当成知识塞进模型
(2)分块策略调优
前面已经展开讲过,这里只补一句:
分块策略本身就是一个极其重要的调参维度。
可以通过:
- 调 chunk 大小
- 调重叠比例
- 针对不同文档类型用不同策略
来慢慢找一个适合自己业务的平衡点。
2. 检索优化:让该来的都来
(1)元数据过滤
问题:只靠向量相似度够吗?
很多时候不够,比如:
- 同一个问题,不同年份政策答案不一样
- 你只想看某个系统/某个部门/某个国家的文档
这时候元数据就派上用场了,比如:
- 文档来源
- 时间
- 分类标签
- 作者/团队
常见两种用法:
| 策略 | 说明 | 特点 |
|---|---|---|
| Pre-filtering(预过滤) | 先用元数据筛出一个候选子集,再做向量检索 | 检索速度快,但有可能把本来相关的文档提前排除 |
| Post-filtering(后过滤) | 先做向量检索,再在 Top-K 上用元数据筛选 | 召回更完整,但整体延迟可能更高 |
可以根据业务选择:很多系统是两种会结合使用。
(2)查询转换(Query Transformation)
问题:用户问法和文档写法,往往不一样怎么办?
这就是让 LLM 帮忙翻译问题的场景。
HyDE(Hypothetical Document Embeddings)
可以理解为:
让模型先脑补一段可能的回答,再用这段回答去做向量检索。
或者像文中那种做法: 为每个文档块预先生成这个文档可以回答哪些问题,入库时把这些问题也嵌入。查询时做问题-问题的匹配,通常效果更好。
多查询检索(Multi-Query Expansion, MQE)
让模型根据用户原始问题,生成多个不同表述的查询,一起去检索。
这样可以覆盖更多语义区域,减少刚好没碰上的情况。
查询扩展
把核心关键词的同义词、相关专业术语、上下位概念都挖出来,用来扩展检索范围。
这些玩法本质上都是在解决同一个问题: 用户怎么问 ≠ 文档怎么写。
(3)自查询(Self-Query):自动挖出元数据
有些关键信息其实在用户问题里已经隐含了,例如:
- 2023 年之后的政策
- 关于 FBA 发货的要求
- 跨境电商里 TikTok 的相关内容
可以让 LLM 帮你从自然语言问题中提取这些结构化信息,拿去做元数据过滤。 这样检索会更聚焦,而不是完全靠向量去盲撞。
3. 后处理优化:把原始检索结果变成好答案
(1)提示压缩(Context Compression)
问题:检索出来的块太多,Prompt 放不下怎么办?
可以理解为:
先用模型或者规则,在检索结果内部做一次内容筛选/摘要,只保留和问题最相关的部分。
好处:
- 降低 Token 消耗
- 减少无关内容对回答的干扰
- 提高回答的聚焦度
(2)重排序(Reranking)
向量检索其实更像是粗排:
- 速度优先
- 不保证 Top-1 一定是最佳答案
重排序模型则是精排:
- 逐条精细判断这段内容和这个问题到底有多相关
常见选择:
| 模型 | 描述 | 适用场景 |
|---|---|---|
| Cohere Rerank | 商业 API,开箱即用,效果不错 | 商业项目,追求上线速度 |
| BGE-Reranker | 开源,支持中英双语 | 中文场景、私有部署 |
| Cross-Encoder | 基于 BERT,每次对问题+文档一起编码 | 精度优先、小规模检索 |
| ColBERT | 在效率和精度之间做平衡 | 大规模检索场景 |
另外一种做法是:
直接用大模型来给每个文档打相关性分。
| 优势 | 劣势 |
|---|---|
| 不用额外部署重排序模型 | Token 成本和延迟都比较高 |
| 可以灵活定义相关性的标准 | 结果会受 Prompt 和模型状态影响,波动略大 |
实践上,我会建议:
- 小规模系统 / 内部工具:可以先试 LLM 重排序
- 真正上生产:考虑用专业的 reranker 模型,效果更稳、成本可控
七、提示工程在 RAG 中的作用
在 RAG 里,Prompt 不是最后随便写一段,而是系统效果的核心组成部分之一。
这里用一个具体场景:跨境电商问答助手,来串几个常用技巧。
1. 提示的四个基础元素
可以理解为,每个提示至少要说清四件事:
| 要素 | 说明 | 示例(跨境电商) |
|---|---|---|
| 指令(Instruction) | 你要干什么 | 你是一个亚马逊运营顾问 |
| 上下文(Context) | 你能参考的资料 | 以下是从知识库中检索到的平台政策片段 |
| 输入数据(Input) | 用户的问题是什么 | FBA 发货有什么要求? |
| 输出指示符(Output Indicator) | 你要以什么形式输出 | 用 Markdown 列清单,分点回答 |
2. 一些实用的小套路
这里就快速过一下,更多细节可以根据你自己的业务调整。
- 具体指令:告诉模型重点说啥、不说啥
- Few-shot 示例:用 1-2 个例子教它你期望的回答风格
- 默认兜底策略: 明确写上如果知识库查不到,请直接说查不到,不要瞎猜
- 角色设定: 比如你是跨境运营顾问,只对亚马逊平台负责,不回答其他平台的问题等
- 多语言支持: 指定用用户提问的语言回复,专业术语中英双标
- 结构化输出: 要求它用固定的标题/列表结构输出,方便前端渲染或后续处理
另外一个很重要的点:
提示词本身要做版本管理。
可以简单做一张表记录:
| 版本 | 日期 | 修改内容 | 大致效果 |
|---|---|---|---|
| v1.0 | 2024-01-01 | 初始版本 | 用作 baseline |
| v1.1 | 2024-01-15 | 增加角色设定、禁止编造 | 回答更稳定、幻觉减少 |
| v1.2 | 2024-02-01 | 补充多语言和结构化输出 | 对接前端更方便 |
八、RAG 效果评估:怎么判断这套系统到底行不行
最后一个大块: 我们如何知道当前这套 RAG 配置是不是靠谱的?
1. 三个核心指标
可以简单记成三个字母:CR / AR / F
-
CR(Context Relevancy)检索相关性 检索出来的内容,和用户问题到底有多相关?
-
AR(Answer Relevancy)答案相关性 模型给的答案,是否真正解决了用户的提问?
-
F(Faithfulness)可信度 回答内容是否忠于检索到的文档,有没有自己编故事?
RAG 最大的卖点其实就是 F:
我不是纯靠猜,我是有文档支撑的。
2. 几种实战评估方法
(1)人工标注测试集
这一步虽然传统又费时间,但非常有价值:
-
收集一批真实用户问题(比如 50 ~ 100 条)
-
为每条问题标注:
- 标准答案
- 对应的关键文档片段
-
跑你的 RAG 系统,看:
- 是否检索到了这些关键片段
- 是否能生成接近标准答案的内容
你能从中看到很多问题:
- 某些问题总是检索不准
- 某些文档总是被忽略
- 某些回答总是遗漏关键点
(2)A/B 测试
当你有多个版本(比如不同分块策略、不同 Top-K 设置)时:
- 用同一批问题分别跑 A/B 两套配置
- 对比 CR/AR/F、人工侧感受、用户反馈
- 再决定上线哪个版本
(3)LLM-as-Judge(用大模型做评审)
可以让另一个模型来帮你打分,比如:
- 判定回答是否切题
- 回答有没有违背文档内容
- 是否存在明显的编造
这能在一定程度上节省人工评估的成本。不过要注意:
- 评审模型本身也会有偏差
- 建议和人工评估结合使用
(4)用户反馈闭环
最后也是最重要的一条:用户用着爽不爽。
常见做法:
- 在前端加有用/没用按钮
- 记录追问(比如为什么这么回答、你是不是搞错了)
- 针对 bad case 做集中分析,反向优化分块/检索/Prompt
可以重点关注:
- 用户满意度(thumbs up/down)
- 追问率
- 需要人工介入的频率
3. 常见问题 & 优化方向
-
检索结果不相关
- 方向:调分块、换 embedding、增加元数据过滤
-
检索对了,答案却答偏了
- 方向:优化 Prompt(强调只根据文档回答)、增加 few-shot
-
答案只对一半
- 方向:调高 Top-K、做重排序、优化块粒度
-
出现明显幻觉
- 方向:加上查不到就说查不到的兜底、检测相关性不足时拒答
-
术语处理差
- 方向:术语表+查询扩展、考虑领域专用 Embedding
-
响应很慢
- 方向:使用更轻量的模型、优化索引结构、减少不必要的 LLM 调用
-
长文档效果差
- 方向:层次化索引(摘要+详细块)、父子块策略
-
多语言不稳定
- 方向:多语言 Embedding、按语言划分索引、必要时做翻译中转
小结 & 一点个人感受
如果用一句话总结 RAG:
RAG 是让大模型带着你的知识库一起工作的一套工程方案。
它并不是某个具体框架、某种固定算法,而更像一整条链路上的一堆工程决策:
- 文档怎么清洗和分块
- 嵌入模型怎么选
- 检索怎么做(单向量/多向量/混合)
- Prompt 怎么写
- 效果怎么评估和迭代
我现在对 RAG 的理解也还在不断修正,很多地方也是边做边学、边踩坑边回头复盘。这篇更多是一个阶段性的整理。
如果你在实战中有更好用的分块策略、检索配置、评估方法,或者对文中某些地方有不同看法,非常欢迎你留言/私信一起讨论。