目录
[1.1 困局与破局:总线架构在多核时代为何"堵车"?](#1.1 困局与破局:总线架构在多核时代为何“堵车”?)
[1.2 CMN-700的定位:为高性能计算而生的互连引擎](#1.2 CMN-700的定位:为高性能计算而生的互连引擎)
[1.3 核心设计理念:模块化、可配置与层级化](#1.3 核心设计理念:模块化、可配置与层级化)
[1.4 全景速览:一个完整SoC中CMN-700的典型部署图景](#1.4 全景速览:一个完整SoC中CMN-700的典型部署图景)
[1.5 本章小结与思维导图](#1.5 本章小结与思维导图)
第二章:绘制CMN-700的骨架------拓扑、路由与寻址
[2.1 拓扑选型艺术:Mesh为何成为高性能计算的首选?](#2.1 拓扑选型艺术:Mesh为何成为高性能计算的首选?)
[2.2 关键"地标"节点初次亮相:RN、HN、SN、MN、XP的角色定义](#2.2 关键“地标”节点初次亮相:RN、HN、SN、MN、XP的角色定义)
[2.3 地址映射与路由策略:快递系统里的智能导航](#2.3 地址映射与路由策略:快递系统里的智能导航)
[2.3.1 系统地址映射 (SAM) ------ 城市的邮政编码系统](#2.3.1 系统地址映射 (SAM) —— 城市的邮政编码系统)
[2.3.2 路由策略 ------ 道路导航算法](#2.3.2 路由策略 —— 道路导航算法)
[2.5 示例:典型16核SoC的CMN-700拓扑部署](#2.5 示例:典型16核SoC的CMN-700拓扑部署)
[3.1 CHI协议栈分层:链路层、网络层、协议层与传输层的分工](#3.1 CHI协议栈分层:链路层、网络层、协议层与传输层的分工)
[3.1.1 协议层(Protocol Layer)------ "外交辞令与规则"](#3.1.1 协议层(Protocol Layer)—— "外交辞令与规则")
[3.1.2 网络层(Network Layer)------ "邮政地址与路由"](#3.1.2 网络层(Network Layer)—— "邮政地址与路由")
[3.1.3 链路层(Link Layer)------ "邮差与投递保证"](#3.1.3 链路层(Link Layer)—— "邮差与投递保证")
[3.1.4 物理层(Physical Layer)------ "道路与交通工具"](#3.1.4 物理层(Physical Layer)—— "道路与交通工具")
[3.2 数据包解剖学:Request、Data、Response格式与字段精讲](#3.2 数据包解剖学:Request、Data、Response格式与字段精讲)
[3.2.1 通用包头字段](#3.2.1 通用包头字段)
[3.2.2 请求包详解](#3.2.2 请求包详解)
[3.2.3 数据包详解](#3.2.3 数据包详解)
[3.2.4 响应包详解](#3.2.4 响应包详解)
[3.3 缓存一致性状态(CState):U、I、SC、SD、UC的深刻内涵](#3.3 缓存一致性状态(CState):U、I、SC、SD、UC的深刻内涵)
[3.4 关键事务类型详解:ReadNoSnp, ReadOnce, WriteNoSnp, WriteBack](#3.4 关键事务类型详解:ReadNoSnp, ReadOnce, WriteNoSnp, WriteBack)
[3.4.1 ReadNoSnp](#3.4.1 ReadNoSnp)
[3.4.2 ReadOnce](#3.4.2 ReadOnce)
[3.4.3 WriteNoSnp](#3.4.3 WriteNoSnp)
[3.4.4 WriteBack](#3.4.4 WriteBack)
[3.5 排序模型与屏障(Barrier):如何建立全局内存访问秩序?](#3.5 排序模型与屏障(Barrier):如何建立全局内存访问秩序?)
[3.5.1 排序点与观察者](#3.5.1 排序点与观察者)
[3.5.2 CHI排序规则](#3.5.2 CHI排序规则)
[3.5.3 内存屏障(Memory Barrier)](#3.5.3 内存屏障(Memory Barrier))
[3.6 一次完整缓存行读缺失(ReadNoSnp)的协议时序对话](#3.6 一次完整缓存行读缺失(ReadNoSnp)的协议时序对话)
[4.1 HN家族分化:HN-F(全功能)、HN-I(仅监听)、HN-D(仅目录)的微架构差异](#4.1 HN家族分化:HN-F(全功能)、HN-I(仅监听)、HN-D(仅目录)的微架构差异)
[4.2 HN-F深度剖解:全能型市政厅的架构奥秘](#4.2 HN-F深度剖解:全能型市政厅的架构奥秘)
[4.2.1 请求处理前端:QoS、仲裁与协议检查](#4.2.1 请求处理前端:QoS、仲裁与协议检查)
[4.2.2 目录(Directory)结构设计:Tag与状态的存储方式](#4.2.2 目录(Directory)结构设计:Tag与状态的存储方式)
[稀疏目录 vs. 全映射目录](#稀疏目录 vs. 全映射目录)
[4.2.3 窥探(Snoop)与一致性控制引擎:如何生成并管理监听请求?](#4.2.3 窥探(Snoop)与一致性控制引擎:如何生成并管理监听请求?)
[4.2.4 数据缓存与合并:MBU(Merge Buffer Unit)的设计奥秘](#4.2.4 数据缓存与合并:MBU(Merge Buffer Unit)的设计奥秘)
[4.2.5 后端接口:与XP、内存控制器(SN)的对接逻辑](#4.2.5 后端接口:与XP、内存控制器(SN)的对接逻辑)
[4.3 关键实现细节](#4.3 关键实现细节)
[4.3.1 流水线深度与延迟权衡](#4.3.1 流水线深度与延迟权衡)
[4.3.2 死锁与活锁的避免机制](#4.3.2 死锁与活锁的避免机制)
[4.3.3 电源状态管理与动态时钟门控](#4.3.3 电源状态管理与动态时钟门控)
[4.4 HN-F内部微架构数据通路与状态机流转](#4.4 HN-F内部微架构数据通路与状态机流转)
[4.5 设计案例:为AI训练芯片配置HN-F](#4.5 设计案例:为AI训练芯片配置HN-F)
[5.1 RN的设计哲学:协议转换与流量整形](#5.1 RN的设计哲学:协议转换与流量整形)
[5.1.1 RN的类型分化](#5.1.1 RN的类型分化)
[5.1.2 RN-F的微架构剖析:CPU集群的"全能管家"](#5.1.2 RN-F的微架构剖析:CPU集群的"全能管家")
[事务跟踪器(TxnTracker)------ RN的"记忆中枢"](#事务跟踪器(TxnTracker)—— RN的"记忆中枢")
[监听过滤器(SnoopFilter)------ 聪明的"门卫"](#监听过滤器(SnoopFilter)—— 聪明的"门卫")
[5.1.3 RN-I与RN-D的设计简析](#5.1.3 RN-I与RN-D的设计简析)
[5.2 SN的设计实现:内存系统与终结点的守门人](#5.2 SN的设计实现:内存系统与终结点的守门人)
[5.2.1 SN的类型](#5.2.1 SN的类型)
[5.2.2 SN-F深度剖析:内存控制器的"智能代理"](#5.2.2 SN-F深度剖析:内存控制器的"智能代理")
[事务表(Transaction Table)](#事务表(Transaction Table))
[5.2.3 SN-I的设计要点](#5.2.3 SN-I的设计要点)
[5.3 协议转换桥:AXI/ACE到CHI的"翻译官"](#5.3 协议转换桥:AXI/ACE到CHI的"翻译官")
[5.4 RN-F发起请求到收到响应的完整内部数据流](#5.4 RN-F发起请求到收到响应的完整内部数据流)
[5.5 设计案例:为高性能AI芯片集成RN-I和SN-F](#5.5 设计案例:为高性能AI芯片集成RN-I和SN-F)
[6.1 XP的架构本质:一个NxM的非阻塞交换矩阵](#6.1 XP的架构本质:一个NxM的非阻塞交换矩阵)
[6.2 内部微架构:输入缓冲、路由计算、交叉矩阵与输出调度](#6.2 内部微架构:输入缓冲、路由计算、交叉矩阵与输出调度)
[6.2.1 输入缓冲区与虚拟通道分离](#6.2.1 输入缓冲区与虚拟通道分离)
[6.2.2 路由计算:确定前进方向](#6.2.2 路由计算:确定前进方向)
[6.2.3 交叉矩阵仲裁:决定谁先通过](#6.2.3 交叉矩阵仲裁:决定谁先通过)
[6.2.4 输出调度与链路层接口](#6.2.4 输出调度与链路层接口)
[6.3 虚拟通道(VC)设计细节:深度、仲裁与流控](#6.3 虚拟通道(VC)设计细节:深度、仲裁与流控)
[6.3.1 VC缓冲区深度设计](#6.3.1 VC缓冲区深度设计)
[6.3.2 VC间仲裁策略](#6.3.2 VC间仲裁策略)
[6.3.3 基于信用点的流控机制](#6.3.3 基于信用点的流控机制)
[6.4 物理链路层实现:时序、功耗与可靠性](#6.4 物理链路层实现:时序、功耗与可靠性)
[6.4.1 源同步时序架构](#6.4.1 源同步时序架构)
[6.4.2 链路宽度与频率权衡](#6.4.2 链路宽度与频率权衡)
[6.4.3 功耗优化技术](#6.4.3 功耗优化技术)
[6.4.4 可靠性特性](#6.4.4 可靠性特性)
[6.5 性能与面积权衡:如何确定XP的规格?](#6.5 性能与面积权衡:如何确定XP的规格?)
[6.5.1 设计决策清单](#6.5.1 设计决策清单)
[6.5.2 面积估算模型](#6.5.2 面积估算模型)
[6.5.3 性能评估指标](#6.5.3 性能评估指标)
[6.6 XP内部数据包从输入到输出的多VC竞争与仲裁流程](#6.6 XP内部数据包从输入到输出的多VC竞争与仲裁流程)
[6.7 设计实例:为数据中心芯片优化XP设计](#6.7 设计实例:为数据中心芯片优化XP设计)
[7.1 MN的功能总览:性能分析、事件追踪、系统控制](#7.1 MN的功能总览:性能分析、事件追踪、系统控制)
[7.2 性能监测单元(PMU)实现](#7.2 性能监测单元(PMU)实现)
[7.2.1 可计数事件:为每个关键指标装上"传感器"](#7.2.1 可计数事件:为每个关键指标装上"传感器")
[7.2.2 分布式计数器架构:从本地计数到全局汇聚](#7.2.2 分布式计数器架构:从本地计数到全局汇聚)
[7.2.3 中断生成与阈值管理](#7.2.3 中断生成与阈值管理)
[7.3 追踪单元(Trace Unit)设计:捕获片上网络的"思维流"](#7.3 追踪单元(Trace Unit)设计:捕获片上网络的"思维流")
[7.3.1 追踪数据源与过滤机制](#7.3.1 追踪数据源与过滤机制)
[7.3.2 追踪数据格式与压缩](#7.3.2 追踪数据格式与压缩)
[7.3.3 追踪缓冲区管理与输出接口](#7.3.3 追踪缓冲区管理与输出接口)
[7.4 配置与控制接口:通过MN编程整个CMN-700](#7.4 配置与控制接口:通过MN编程整个CMN-700)
[7.4.1 配置寄存器映射](#7.4.1 配置寄存器映射)
[7.4.2 配置分发机制](#7.4.2 配置分发机制)
[7.4.3 动态重配置支持](#7.4.3 动态重配置支持)
[7.5 调试支持:从硅前验证到硅后调试](#7.5 调试支持:从硅前验证到硅后调试)
[7.5.1 硅前验证基础设施](#7.5.1 硅前验证基础设施)
[7.5.2 硅后调试接口](#7.5.2 硅后调试接口)
[7.5.3 性能分析方法论](#7.5.3 性能分析方法论)
[7.6 MN通过追踪总线收集全网事件的架构](#7.6 MN通过追踪总线收集全网事件的架构)
[7.7 设计实例:为自动驾驶SoC设计安全关键的MN](#7.7 设计实例:为自动驾驶SoC设计安全关键的MN)
[8.1 服务质量(QoS)的硬件实现:从高速公路到VIP专用通道](#8.1 服务质量(QoS)的硬件实现:从高速公路到VIP专用通道)
[8.1.1 QoS架构全景图](#8.1.1 QoS架构全景图)
[8.1.2 QoS域的硬件编码](#8.1.2 QoS域的硬件编码)
[8.1.3 XP中的QoS仲裁策略](#8.1.3 XP中的QoS仲裁策略)
[8.1.4 HN中的请求优先级管理](#8.1.4 HN中的请求优先级管理)
[8.2 系统级缓存(SLC)的集成设计与优化](#8.2 系统级缓存(SLC)的集成设计与优化)
[8.2.1 SLC架构与HN的协同](#8.2.1 SLC架构与HN的协同)
[8.2.2 Way Partitioning:缓存资源的精细划分](#8.2.2 Way Partitioning:缓存资源的精细划分)
[Way Partitioning的实现](#Way Partitioning的实现)
[动态Way Partitioning](#动态Way Partitioning)
[8.2.3 加速器缓存一致性(HAC)支持](#8.2.3 加速器缓存一致性(HAC)支持)
[8.2.4 SLC预取策略](#8.2.4 SLC预取策略)
[8.3 动态缓存管理(DCM):如何根据运行负载调整缓存策略?](#8.3 动态缓存管理(DCM):如何根据运行负载调整缓存策略?)
[8.3.1 DCM架构](#8.3.1 DCM架构)
[8.3.2 自适应替换策略](#8.3.2 自适应替换策略)
[8.3.3 基于机器学习预测的缓存管理](#8.3.3 基于机器学习预测的缓存管理)
[8.4 带QoS标签的事务在HN和XP中经历的优先级仲裁流程](#8.4 带QoS标签的事务在HN和XP中经历的优先级仲裁流程)
[8.5 设计案例:为云原生服务器优化QoS和缓存分配](#8.5 设计案例:为云原生服务器优化QoS和缓存分配)
[9.1 场景一:多核竞争下的窥探风暴(Snoop Storm)](#9.1 场景一:多核竞争下的窥探风暴(Snoop Storm))
[9.2 场景二:DMA引擎的一致性读入](#9.2 场景二:DMA引擎的一致性读入)
[9.3 场景三:原子操作的硬件支持](#9.3 场景三:原子操作的硬件支持)
[9.4 场景四:低功耗状态进入与优雅降频](#9.4 场景四:低功耗状态进入与优雅降频)
[9.5 本章小结与设计启示](#9.5 本章小结与设计启示)
[10.1 设计起点:将SoC需求翻译为CMN-700配置参数](#10.1 设计起点:将SoC需求翻译为CMN-700配置参数)
[10.2 节点规格制定:为每个"建筑"设计蓝图](#10.2 节点规格制定:为每个"建筑"设计蓝图)
[10.2.1 HN规格设计:一致性大脑的配置](#10.2.1 HN规格设计:一致性大脑的配置)
[10.2.2 RN规格设计:门户的差异化配置](#10.2.2 RN规格设计:门户的差异化配置)
[10.2.3 SN规格设计:终点站的性能关键](#10.2.3 SN规格设计:终点站的性能关键)
[10.2.4 XP规格设计:交换机的容量规划](#10.2.4 XP规格设计:交换机的容量规划)
[10.3 拓扑权衡清单:绘制城市交通网络图](#10.3 拓扑权衡清单:绘制城市交通网络图)
[10.3.1 Mesh尺寸选择:黄金分割点](#10.3.1 Mesh尺寸选择:黄金分割点)
[10.3.2 环形子网(RING)的利弊分析](#10.3.2 环形子网(RING)的利弊分析)
[10.3.3 多芯片扩展(C2C)的设计考量](#10.3.3 多芯片扩展(C2C)的设计考量)
[10.3.4 布线拥塞预测与缓解](#10.3.4 布线拥塞预测与缓解)
[10.4 时钟与复位架构设计:系统的心跳与重启](#10.4 时钟与复位架构设计:系统的心跳与重启)
[10.4.1 多时钟域策略](#10.4.1 多时钟域策略)
[10.4.2 复位策略与初始化序列](#10.4.2 复位策略与初始化序列)
[10.4.3 电源管理集成](#10.4.3 电源管理集成)
[10.5 终极检查表:CMN-700架构师设计清单](#10.5 终极检查表:CMN-700架构师设计清单)
[10.6 结语:构建高效、弹性片上网络的设计思维](#10.6 结语:构建高效、弹性片上网络的设计思维)
第一章:启程:通往一致性未来的片上高速网络
1.1 困局与破局:总线架构在多核时代为何"堵车"?
想象一下,二十年前的处理器小镇。镇上只有一两户人家(CPU核心),一座中央仓库(内存)。他们之间只有一条简单的双车道公路(系统总线)相连。当一户人家需要去仓库取点东西(内存读取),就自己开车上路,来回一趟,简单直接。交通规则(协议)也很简单,先来后到,大家相安无事。
然而,科技的发展让小镇变成了超级大都市。现在的 SoC(片上系统)城市里,林立着数十个甚至上百个"功能社区":
-
密集的居民区:高性能CPU核心集群、能效CPU核心集群。
-
庞大的计算工厂:GPU着色器集群、NPU张量计算单元。
-
高速物流中心:DMA引擎、各种硬件加速器。
-
巨型中央仓库:由多个通道组成的DRAM内存系统。
-
对外港口:PCIe、CXL、以太网等高速I/O接口。
如果还只用那一条古老的双车道"总线"连接所有这一切,会发生什么?史诗级大堵车!
经典总线架构的"四大绝症":
-
带宽瓶颈:所有通信都挤占同一共享通道。一个GPU在狂吞纹理数据时,CPU的紧急中断请求可能被堵在后面"按喇叭"。
-
** scalability 灾难**:每增加一个主设备(如一个CPU核心),总线负载和仲裁复杂度就非线性增长,延迟飙升,最终无法扩展。
-
时钟树噩梦:为了让所有设备同步,一个巨大的全局时钟网络需要覆盖整个芯片,功耗极高,且频率难以提升。
-
一致性维护困难:当多个CPU核心都有自己的本地缓存时,如何确保它们看到同一内存地址的数据是一致的?总线上的"窥探"机制会随着核心数增加而变得极其复杂和低效。
就在这时,一位名叫 NoC(Network-on-Chip,片上网络) 的城市规划大师站了出来。他提出了革命性的理念:
"别再把所有建筑都连到一条主干道上了!让我们建造一个纵横交错、多层次的立体交通网络 。每个社区(IP)都有自己的标准出入口(网络接口) 。数据被打包成一个个标准集装箱(数据包) ,在网络中通过智能交换节点(路由器/交叉开关) 自主寻路,并行传输。"
ARM的 CMN(Coherent Mesh Network,一致性网状网络) ,特别是我们本书的主角 CMN-700 ,就是这位大师为当今最复杂的"超大规模SoC城市"量身定制的终极片上交通网络蓝图。
它不仅仅解决"通勤"问题,更内建了一套全球统一、高效的内存一致性法律体系,确保无论数据拷贝在哪个CPU、GPU或加速器的私人缓存里,所有"市民"看到的永远是一份权威的"真相"。
1.2 CMN-700的定位:为高性能计算而生的互连引擎
那么,CMN-700在这个新时代扮演什么角色?它远不止是"连接线"。
它是SoC的:
-
一致性骨架:定义了整个系统缓存一致性的规则和基础设施。
-
数据高速公路网:提供高带宽、低延迟、可扩展的数据传输通道。
-
系统资源仲裁者与协调员:通过QoS机制管理不同流量优先级。
-
性能与可观测性的窗口:内置丰富的性能监测和追踪功能。
CMN-700的典型应用场景,正是那些对性能和一致性要求最苛刻的领域:
-
数据中心服务器CPU:如Neoverse V系列、N系列平台。
-
高端移动SoC:支持超大核集群和强大GPU的旗舰手机芯片。
-
汽车ADAS与座舱芯片:需要融合多个高性能计算岛。
-
网络基础设施与DPU:处理海量并行数据流。
与它的前任CMN-600相比,CMN-700在 "容量、带宽、效率" 三大维度进行了全面升级。例如,支持更多的Mesh网络维度,增强的SLC(系统级缓存)管理,更精细的QoS控制,以及对新兴互连标准(如CXL)更好的支持。它为下一个十年的计算需求铺平了道路。
1.3 核心设计理念:模块化、可配置与层级化
CMN-700的成功并非偶然,它源于三个核心的、相辅相成的设计理念,这些理念将贯穿我们后续对每一个模块的剖析。
理念一:模块化
CMN-700不是一个不可分割的黑盒。它是由一系列功能清晰、接口标准化的预制构件(节点) 组成的。就像乐高积木:
-
HN(Home Node):是处理一致性和请求转发的"核心枢纽"积木。
-
RN(Request Node):是连接各种处理器或IO设备的"出入口"积木。
-
SN(Subordinate Node):是连接内存或外设的"终点站"积木。
-
XP(Crosspoint):是负责数据包路由的"十字路口/立交桥"积木。
-
MN(Mesh Network):是负责性能监控的"交通指挥中心"积木。
你可以根据SoC的规模,选择所需数量和类型的积木进行拼接。这种模块化极大地提高了设计的复用性和灵活性。
理念二:可配置
每一块"积木"内部都有丰富的"旋钮和开关"。作为架构师,你可以根据目标市场的需求进行精细调节:
-
为HN配置目录的大小(支持多少缓存行)、关联度。
-
为XP配置端口的数量、数据位宽(128-bit, 256-bit, 512-bit)。
-
为RN配置请求队列的深度、支持的CHI协议版本。
-
为SN配置地址映射范围、支持的突发长度。
这种可配置性使得CMN-700既能服务于对面积和功耗极端敏感的移动边缘设备,也能扩展支撑追求极致性能的数据中心芯片。
理念三:层级化
CMN-700的架构是分层的,每一层解决不同的问题,这使得复杂系统变得井然有序。
-
协议层 :使用CHI(Coherent Hub Interface)协议 。这是节点间通信的"外交语言",规定了"请求"、"数据"、"响应"等各种"外交文书"的格式和语义,核心是定义一致性规则。
-
网络层 :负责将CHI事务打包成数据包(Flit) ,并依据路由算法(如XY路由)决定其在Mesh网络中的行进路径。它关心的是"从哪来,到哪去"。
-
链路层:负责相邻节点间数据包的可靠传输,包括流量控制(如基于信用点)、错误检测等。它关心的是"当前这一段路怎么走稳"。
-
物理层:定义电气特性、时钟、并串转换等。在RTL设计阶段,我们主要关注其时序和接口。
这种清晰的层级划分,使得设计、验证和调试都可以分层进行,大大降低了复杂度。
1.4 全景速览:一个完整SoC中CMN-700的典型部署图景
理论说得再多,不如一张"城市规划总图"来得直观。下面,让我们通过一个架构图,鸟瞰一个典型的、面向高端应用的SoC如何集成CMN-700。
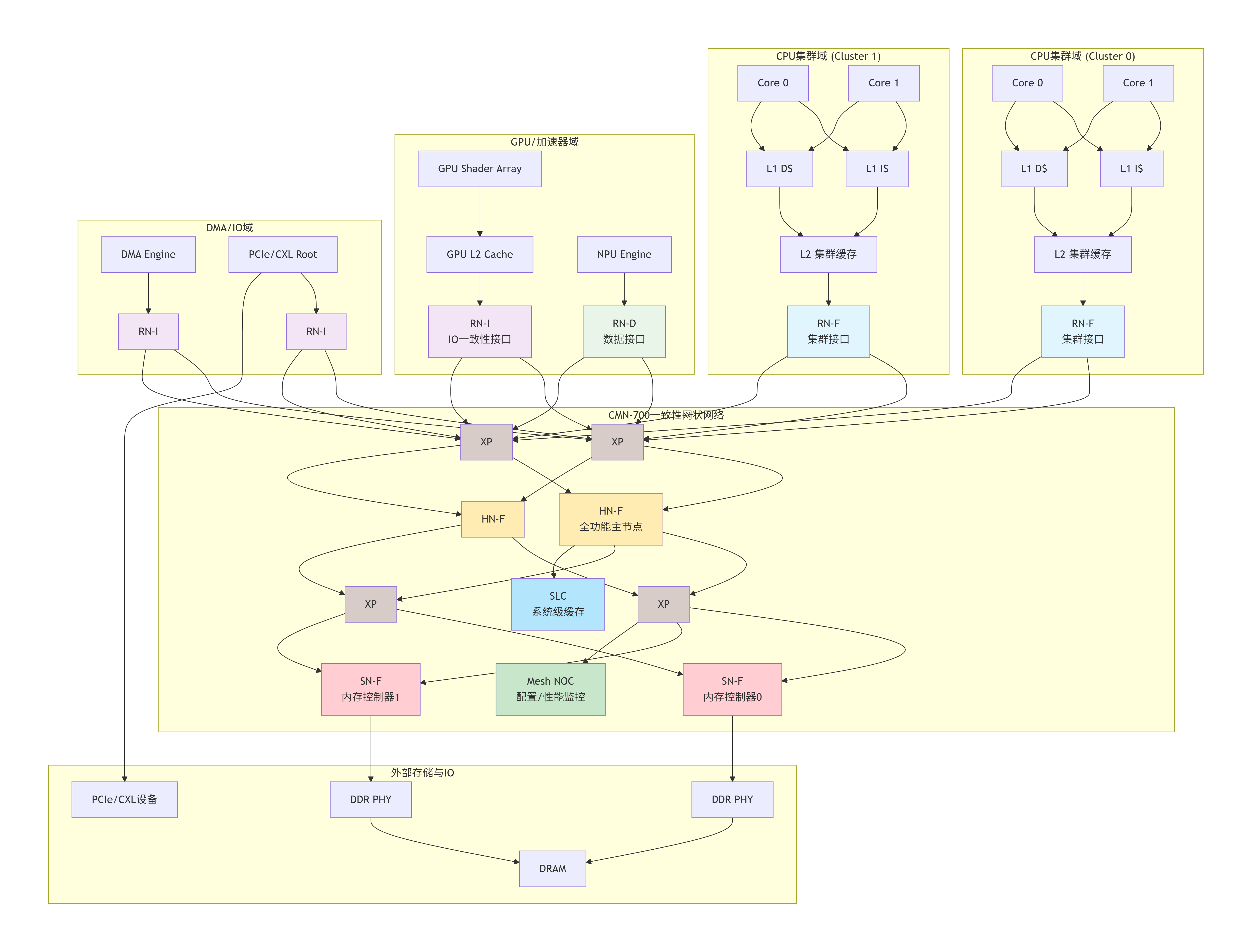
这张图告诉了我们什么?
-
入口多样化:不同类型的计算单元通过不同类型的RN接入网络。
-
RN-F (Full) :CPU集群使用,支持完整的缓存一致性协议(监听与被监听)。
-
RN-I (IO) :GPU、DMA、PCIe/CXL使用,通常作为仅发起请求的节点,可支持被监听以维护一致性。
-
RN-D (Data) :像NPU这样的纯数据生产者/消费者使用,不涉及一致性,只做简单数据传输。
-
-
网络核心是Mesh :多个XP(交叉开关) 构成了网络的数据平面。数据包在XP之间"跳步"前进。Mesh结构提供了极高的并行带宽 和可扩展性。图中的XP之间其实还有横向和纵向的连接(为简化未画出),形成一个网格。
-
一致性处理中心 :HN-F(全功能主节点) 是系统的"一致性大脑"。所有需要维护一致性的请求(比如CPU的读、写,GPU的一致性读)最终都会路由到某个HN-F。HN-F内部维护着一个目录,记录着每一行数据在系统中所有缓存里的状态,并负责发起监听(Snoop)来协调数据更新。
-
终点站 :SN-F 是内存控制器在CMN网络中的代理。当数据最终需要写入DDR或从DDR读取时,请求会到达SN-F。SN-F也可能连接着片上只读存储器(如Boot ROM)。
-
共享资源 :SLC 是一个由所有HN共享的大型末级缓存,能极大降低访问延迟和内存带宽压力。MN则像网络的操作系统后台,负责初始化、配置、性能统计和调试追踪。
-
数据流示例(图中橙色箭头是一个简化示意):
-
CPU Cluster 0 的 Core 0 想读取一个内存地址。
-
请求先经过其私有的L1、L2缓存,未命中。
-
RN-F0 将请求(使用CHI协议)注入CMN网络。
-
网络根据地址,通过 XP0 和 XP2 将请求路由到负责该地址域的 HN-F0。
-
HN-F0 查询目录:发现该数据行在 CPU Cluster 1 的L2缓存中有脏(Dirty) 副本。
-
HN-F0 通过CMN网络向 RN-F1 发起一个监听请求。
-
RN-F1 让 Cluster 1 的L2缓存将脏数据写回,并通过网络将数据返回给 HN-F0。
-
HN-F0 将数据同时转发给最初的请求者 RN-F0(从而送给Core 0),并更新目录状态。
-
(如果目录显示所有缓存都没有副本,HN-F0会将请求转发给SN-F去访问DDR)。
-
看,一次简单的内存读取,在CMN-700构建的城市里,可能引发一场跨越多个"城区"的、井然有序的协同作业。这,就是现代片上互连的魅力。
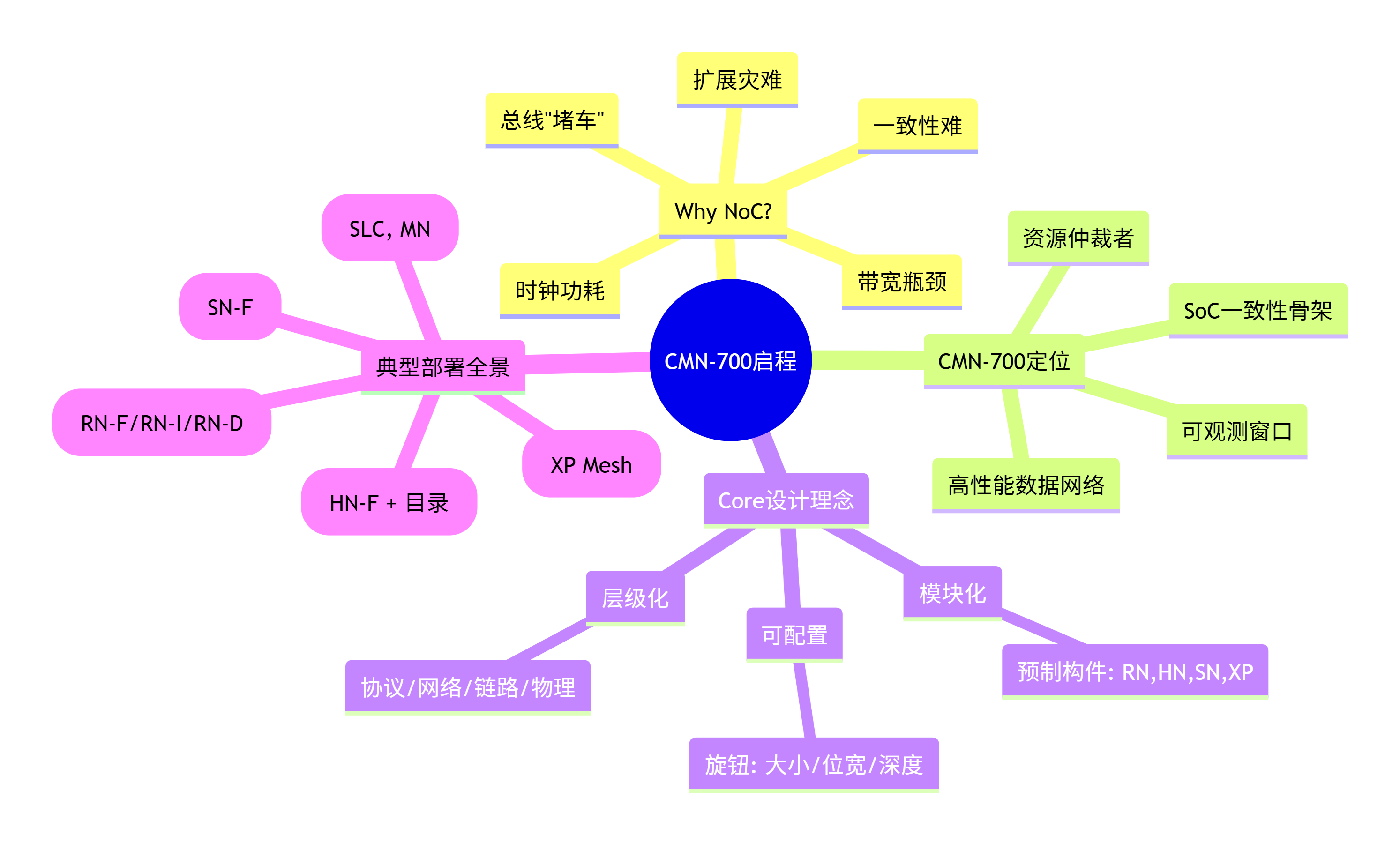
1.5 本章小结与思维导图
本章我们共同迈出了成为CMN-700架构师的第一步:
-
认知升级 :我们理解了从总线 到片上网络(NoC) 是必由之路,是为了解决多核/众核SoC在带宽、延迟、可扩展性和一致性上的根本挑战。
-
明确目标 :ARM CMN-700 是为高性能、高一致性需求场景设计的先进互连IP,它扮演着SoC"一致性骨架"和"数据高速公路"的核心角色。
-
掌握心法 :CMN-700的成功建立在模块化 (像乐高)、可配置 (像调音台)、层级化(像网络协议栈)三大设计理念之上。
-
俯瞰全景 :通过一张架构图,我们看到了CMN-700在一个复杂SoC中的实际部署形态,理解了RN, HN, SN, XP, MN等关键节点如何各司其职,协同完成一次一致性内存访问。
让我们用一张思维导图来固化本章的核心脉络:
第二章:绘制CMN-700的骨架------拓扑、路由与寻址
2.1 拓扑选型艺术:Mesh为何成为高性能计算的首选?
欢迎来到CMN-700的"城市规划局"!在开始动工建造我们的片上网络城市之前,第一项也是最重要的决策就是:选择城市的主干道路网布局 ,即网络拓扑。
拓扑决定了数据包从源头到目的地的可能路径数量、最大跳数、带宽潜力以及容错能力 。在NoC的世界里,常见的拓扑有如棋盘般规整的Mesh(网格) 、如环路般的Ring(环) ,以及更复杂的Torus(环面) 、Fat-Tree(胖树) 等。
那么,为何CMN-700等现代高性能互连几乎不约而同地选择了Mesh?
让我们做个对比实验:
-
Ring(环状)拓扑:
-
结构:所有节点串联成一个环,每个节点只与左右邻居相连。
-
优点 :结构简单,布线规整,非常适合小规模集群(如8-16个核心)的本地互连。ARM的CoreLink CCI/CONNECT系列就常用Ring。
-
缺点 :致命伤在于扩展性。随着节点数N增加,网络直径(最远两点的跳数)线性增长(~N/2)。想象一下,在一个64个节点的环上,数据包在最坏情况下需要穿越31个节点才能到达目的地!这不仅带来高延迟,而且环上任何一段链路都会成为带宽瓶颈,因为所有流量都共享这些串行的"单车道"。
-
-
Mesh(网格)拓扑:
-
结构:节点排列成二维(甚至三维)网格,每个节点(通常是XP交叉开关)与东、南、西、北四个方向的邻居相连(称为2D Mesh)。就像一个规划整齐的曼哈顿街区。
-
优点:
-
卓越的可扩展性:对于一个N×N的2D Mesh,网络直径约为2*(N-1)。对于64个节点(假设8x8 Mesh),最坏情况跳数约为14,远优于Ring的32。延迟增长更平缓。
-
巨大的聚合带宽 :Mesh提供了多条并行路径 。多个位于不同行列的数据流可以同时传输而互不干扰,网络的总带宽随节点数增加而近似线性增长。这就像从单条环线地铁升级成了纵横交错的地铁网络。
-
天然的局部性优化:通信频繁的节点(如一个CPU集群及其专属的HN)可以放置在Mesh中相邻的位置,实现极低的1-2跳访问延迟。
-
-
缺点:布线复杂度稍高,需要规划纵横交错的通道。但对于当今先进工艺下的自动布局布线(APR)工具而言,这已是成熟可控的挑战。
-
CMN-700的拓扑选择:
CMN-700的核心是2D Mesh 。它将XP(交叉开关) 作为网格的交叉点,而RN、HN、SN等功能节点则"悬挂"在XP的端口上。一个XP可以连接多个功能节点,就像一个大型交通枢纽连接多个社区。
*设计考量:当你的SoC核心数超过16-24个,或需要极高的聚合内存带宽(如>200GB/s)时,Mesh拓扑几乎是唯一的选择。对于更小规模的设计,CMN-700也支持将多个Mesh子网通过桥接器(C2C)连接,提供了灵活性。*
2.2 关键"地标"节点初次亮相:RN、HN、SN、MN、XP的角色定义
在我们的Mesh城市中,有几种不同类型的"建筑",它们通过标准接口连接到XP枢纽上。理解它们是理解数据流的关键。
| 节点类型 | 类比 | 核心职能 | 关键特性 |
|---|---|---|---|
| XP (Crosspoint) | 立交桥/交换机 | 数据包的路由和交换。接收来自多个输入端口的包,根据其目标地址,将其转发到正确的输出端口。 | 构成Mesh网络的骨干。内部通常包含多个虚拟通道(VC) 以避免死锁,并实现服务质量(QoS) 仲裁。 |
| RN (Request Node) | 社区出入口/收费站 | 代表一个发起事务的代理(如CPU集群、GPU、DMA)。它将内部协议(如ACE或AXI)转换为标准的CHI协议包,注入网络;并处理返回的响应和数据。 | 分为RN-F (全功能,支持一致性)、RN-I (IO,通常为请求者)、RN-D (数据,非一致性)。是事务的起点。 |
| HN (Home Node) | 市政府/交通指挥中心 | 是一致性域的主管 。每个HN负责管理系统物理地址空间的一部分(一个"域")。所有需要一致性维护的请求(如读、写)都必须路由到其对应的HN。HN查阅目录来追踪数据行状态,并协调监听(Snoop)操作。 | 一致性的大脑 。分为HN-F (全功能,含目录和监听逻辑)、HN-I (仅监听)、HN-D (仅目录)。通常与SLC(系统级缓存) 紧密耦合。 |
| SN (Subordinate Node) | 仓库大门/终点站 | 代表一个事务的终点,通常是内存控制器(如DMC)、片上ROM或配置寄存器空间。它接收来自网络的请求,转换为对底层硬件的访问,并返回响应和数据。 | 是数据的最初来源或最终目的地 。分为SN-F (全功能)、SN-I(IO从节点)。 |
| MN (Mesh Network) | 城市规划与监控中心 | 提供全局配置、性能监控和调试追踪功能。它不是数据流的必经之路,而是用于观测和控制整个网络。 | 通过一个专用端口连接到Mesh上。 |
设计考量:在规划SoC时,你需要决定各种节点的数量。例如,HN的数量决定了系统地址域的划分粒度(影响目录大小和热点);RN和SN的数量由计算单元和内存控制器数量决定;XP的数量和Mesh尺寸则由总节点数和带宽需求决定。
2.3 地址映射与路由策略:快递系统里的智能导航
现在,我们的城市有了路网(Mesh)和建筑(节点)。当一个数据包从RN"出发"时,它如何知道自己该去往哪个"目的地"HN或SN?这依赖于两套紧密协作的系统:地址映射 和 路由算法。
2.3.1 系统地址映射 (SAM) ------ 城市的邮政编码系统
SAM是CMN-700内部的一个关键硬件模块。它负责将输入的物理内存地址,解析并映射到两个关键信息:
-
目标节点类型 :这个地址是归某个HN 管(需要一致性服务),还是直接去往某个SN(如外设寄存器,无需一致性)?
-
目标节点ID:具体是哪一个HN或SN?
SAM的配置非常灵活,通常通过编程一系列地址范围寄存器来实现。例如:
// 示例性 SAM 配置
SAM_Rule_0: 地址范围 0x0000_0000 - 0x3FFF_FFFF -> 映射到 HN0
SAM_Rule_1: 地址范围 0x4000_0000 - 0x7FFF_FFFF -> 映射到 HN1
SAM_Rule_2: 地址范围 0x8000_0000 - 0xBFFF_FFFF -> 映射到 SN0 (DDR通道0)
SAM_Rule_3: 地址范围 0xC000_0000 - 0xFFFF_FFFF -> 映射到 SN1 (DDR通道1)设计实例:在一个双路服务器SoC中,你可以将两块CPU物理内存空间分别映射到两个不同的HN,实现NUMA(非统一内存访问)架构,让每个CPU主要访问本地HN管辖的内存,以获得更低延迟。
2.3.2 路由策略 ------ 道路导航算法
知道了目的地ID(比如,目标是位于Mesh坐标(2,2)的HN1),数据包在由XP构成的Mesh中该如何一步步"跳转"过去?这由每个XP内部的路由逻辑决定。
CMN-700最常用的是确定性的 维度顺序路由 ,最常见的是 XY路由:
-
先走X轴(水平方向):数据包首先在水平方向上移动,直到其X坐标与目标节点的X坐标一致。
-
再走Y轴(垂直方向):然后在垂直方向上移动,直到到达目标节点。
举个例子 :
假设数据包从(0,0)的RN出发,目的地HN在(2,2)。
-
路径1(XY路由):
(0,0) -> (1,0) -> (2,0) -> (2,1) -> (2,2)。总共4跳。 -
路径2(YX路由):
(0,0) -> (0,1) -> (0,2) -> (1,2) -> (2,2)。同样是4跳。
XY路由的优点:
-
简单、无死锁 :由于严格规定了先水平后垂直的顺序,不可能形成循环等待,从而避免了路由死锁。
-
实现成本低:每个XP只需要根据本地坐标和目标坐标做简单的比较运算。
XY路由的缺点:
-
路径单一,可能造成热点:所有从左侧发往右侧的流量,都会在中间某条垂直链路上汇合,可能造成局部拥塞。
-
非最短路径:在某些情况下(如从(0,2)到(2,0)),XY路由并非最短路径。
高级选项 :为了平衡负载,CMN-700支持更灵活的路由策略,如可编程路由表 ,允许架构师为特定的源-目的地对指定路径,或者使用自适应路由(根据网络拥塞情况动态选择路径),但这会引入更高的实现复杂性和验证挑战。
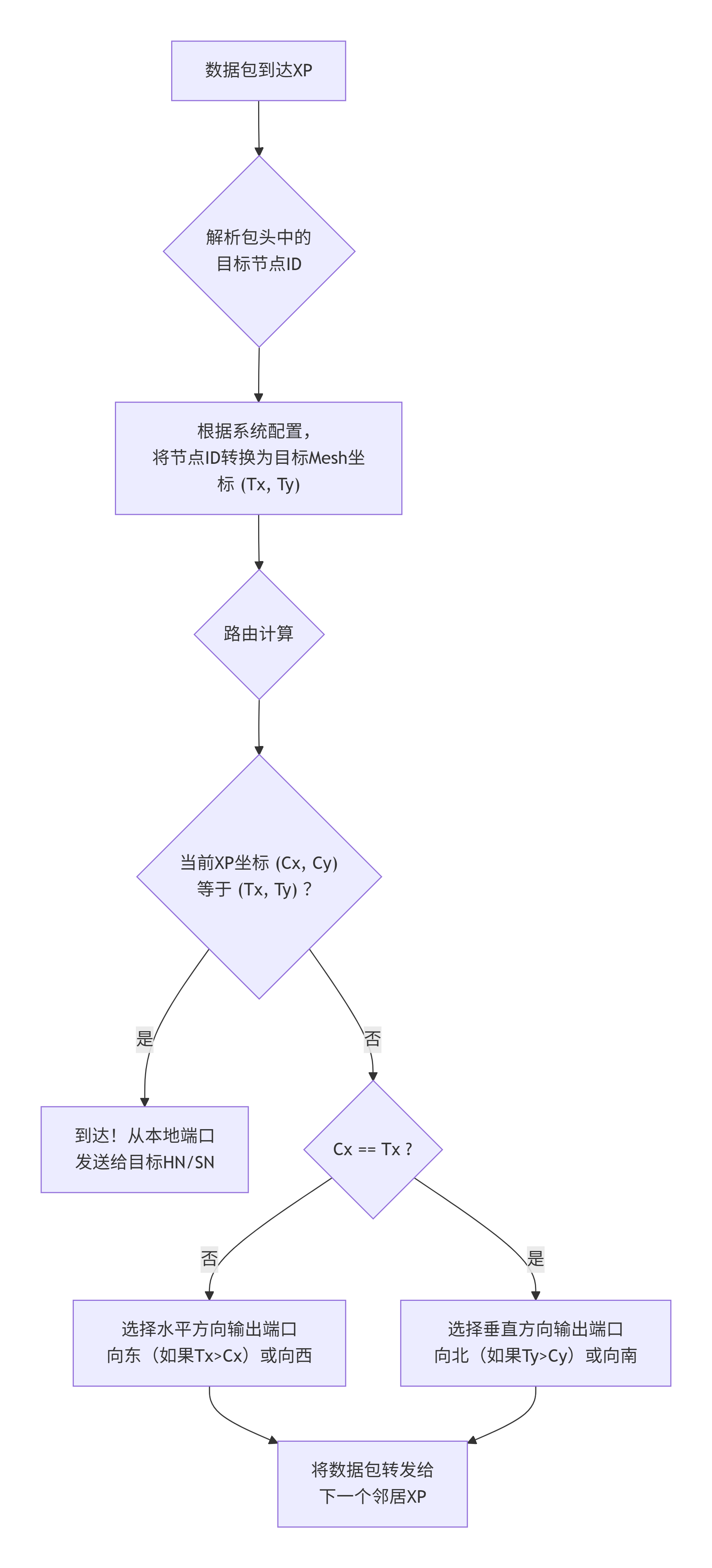
设计考量:对于大多数设计,简单的XY路由已足够。只有在网络规模非常大(如>8x8)、且流量模式极度不均匀时,才需要考虑更复杂的路由方案。选择复杂路由前,务必用网络仿真工具进行建模分析。
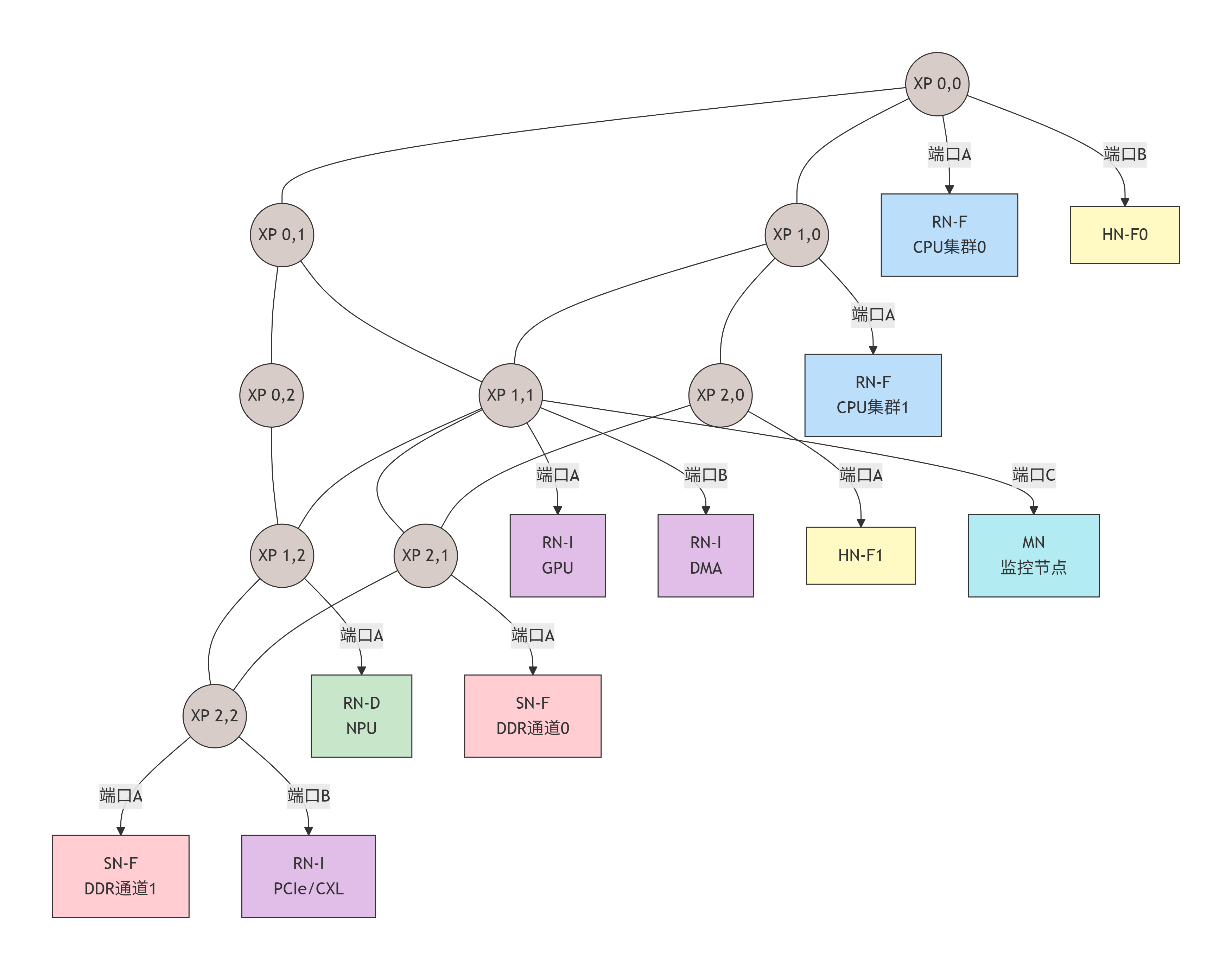
2.5 示例:典型16核SoC的CMN-700拓扑部署
让我们将本章的所有概念融合到一个具体的设计实例中。假设我们要为一个高性能移动SoC(如旗舰手机处理器)设计CMN-700网络,它包含:
-
1个高性能CPU集群(4个大核+4MB共享L2)
-
1个高能效CPU集群(4个小核+2MB共享L2)
-
1个高性能GPU(带自己的L2缓存)
-
1个NPU
-
1个DMA引擎
-
双通道LPDDR5内存控制器
-
一个PCIe/CXL根端口
我们的目标是:设计一个低延迟、高带宽的互连,并优化CPU和GPU对内存的访问。
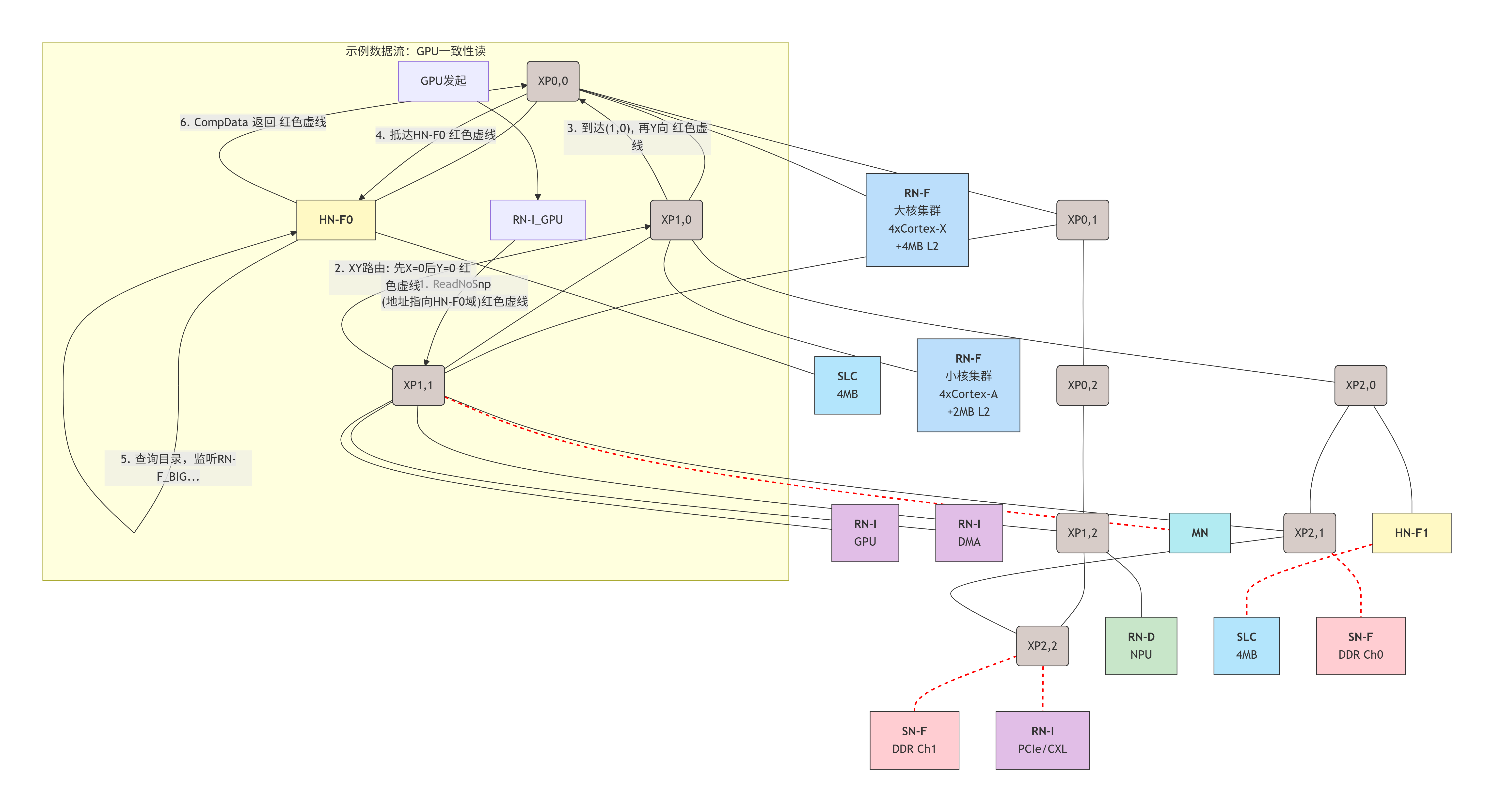
设计解析与考量:
-
拓扑选择 :采用了 3x3 Mesh。对于包含约10个主要发起者(RN)和多个目标(HN/SN)的系统,3x3提供了良好的连接性和适中的跳数(最坏情况约4跳)。
-
节点放置策略(关键!):
-
局部性优化 :将大核CPU集群(RN-F_BIG) 和其最常访问的主节点(HN-F0) 放在同一个XP (0,0) 上。这意味着CPU的大部分本地内存访问,在1跳内就能到达其"归属"HN,延迟极低。
-
负载均衡 :我们设置两个HN(HN-F0和HN-F1),将系统的物理地址空间一分为二。这避免了单个HN成为热点。大核和小核集群分别靠近不同的HN。
-
内存通道亲和性:两个内存控制器(SN-F0/1)放在Mesh的右侧(X=2),与两个HN距离对称。数据从HN到内存的路径均衡。
-
IO集中管理:GPU、DMA、PCIe等IO设备集中在Mesh中部的XP11附近,方便相互间DMA操作,也处于访问两个HN和内存的中间位置。
-
-
路由 :采用默认的XY路由 。从GPU (RN-I at 1,1) 发起到HN-F0 (0,0) 的请求,路径将是:
(1,1) -> (0,1) -> (0,0),共2跳。 -
SAM配置示例:
-
0x0000_0000 - 0x7FFF_FFFF-> 映射到 HN-F0 (管理低端4GB物理地址) -
0x8000_0000 - 0xFFFF_FFFF-> 映射到 HN-F1 (管理高端4GB物理地址) -
0x1_0000_0000 - ...(DDR地址) -> 根据交错算法,映射到 SN-F0 或 SN-F1。
-
通过这样的精心规划,我们构建的不仅仅是一个互连网络,而是一个为特定工作负载优化过的计算生态系统。在接下来的章节中,我们将深入这座城市的每个关键建筑(节点),拆解它们内部的精妙构造。
第三章:通用语言:深入CHI协议层
3.1 CHI协议栈分层:链路层、网络层、协议层与传输层的分工
欢迎来到CMN-700的"外交官培训学院"!在这里,所有节点都必须学习一种名为CHI(Coherent Hub Interface) 的精确、高效、无歧义的"外交语言"。CHI不是单一的协议,而是一个严谨的分层协议栈,每一层都解决特定层面的通信问题。理解这些层次,就如同理解外交交流中从电报编码到外交辞令再到实际行动的完整链条。
让我们逐层深入:
3.1.1 协议层(Protocol Layer)------ "外交辞令与规则"
这是CHI的灵魂所在 ,定义了缓存一致性的核心语义。它规定了:
-
事务类型(Transaction Types) :各种"外交请求"的类别,如
ReadNoSnp(请求数据但不窥探他人)、WriteNoSnp(写入数据)、SnpOnce(一次性窥探)等。每种事务都有明确的预期行为和响应要求。 -
缓存状态(Cache States) :数据在缓存中的"身份状态",如
UC(Unique Clean,唯一且干净)、UD(Unique Dirty,唯一且脏)、SC(Shared Clean,共享且干净)等。这是维护一致性的核心机制。 -
事务排序与屏障:确保内存操作按程序期望的顺序完成。
设计视角:当你设计一个HN或RN时,协议层逻辑是你需要实现的最复杂的状态机。它决定了节点如何解读事务、如何更新目录或缓存状态、以及如何生成响应。
3.1.2 网络层(Network Layer)------ "邮政地址与路由"
这一层负责将协议层的"外交文书"打包成可以通过Mesh网络传输的"标准信封"。
-
数据包格式定义 :它规定了
Request(请求)、Data(数据)、Response(响应)三种基本数据包的结构。每个数据包都包含关键的路由信息,如:-
TgtID(目标节点ID):这封信要寄给谁? -
SrcID(源节点ID):这封信是谁寄的? -
TxnID(事务ID):这封信是哪个事务的?用于匹配请求和响应。 -
Opcode(操作码):这封信是什么类型(读、写、窥探等)?
-
-
路由功能 :网络层利用
TgtID和SrcID,结合系统地址映射(SAM) 和路由算法,为数据包规划路径。
实现细节 :在RTL中,网络层逻辑通常位于节点的"前端"或"接口"模块。它负责打包/解包,并与XP的链路层握手。数据包的位宽(如128位、256位)和TxnID的位宽(决定支持多少未完成事务)是可配置的关键参数。
3.1.3 链路层(Link Layer)------ "邮差与投递保证"
这一层负责相邻两个节点(如一个RN和它直连的XP,或两个相邻的XP)之间点对点的可靠数据传输。
-
流量控制(Flow Control) :采用基于信用点(Credit) 的机制。发送方必须先从接收方获得"信用点"(表示接收方有空闲缓冲区),才能发送一个数据包。这避免了缓冲区溢出和数据丢失。
-
虚拟通道(Virtual Channels, VC) :为了避免协议性死锁(例如,一个请求包在等待响应包,而响应包又在等待请求包释放资源),CHI定义了独立的虚拟通道。典型的划分是:
-
VC0:请求通道(Request Channel)
-
VC1:响应通道(Response Channel)
-
VC2:数据通道(Data Channel)
-
VC3:窥探通道 (Snoop Channel)
每个VC有独立的信用点和缓冲区,确保不同类的数据流不会相互阻塞。
-
-
错误检测:包含简单的奇偶校验等机制。
物理实现考量 :链路层逻辑通常集成在XP和每个功能节点的接口中。信用点的初始数量和深度是需要精心设计的参数:太浅会限制带宽,太深则会增加面积和延迟。
3.1.4 物理层(Physical Layer)------ "道路与交通工具"
定义了电气特性、时钟、并串转换等。在RTL设计阶段,我们主要关心其时序接口:数据、有效信号、就绪信号在时钟边沿如何交互(通常采用标准的Valid/Ready握手)。对于高速SerDes接口(如CXL),物理层会更复杂。

 设计心得:清晰的层次划分是CHI协议可扩展、可验证的基石。作为架构师,你需要为每一层指定关键参数:协议层支持哪些事务类型?网络层的数据包位宽和ID位宽是多少?链路层的VC数量和信用点深度如何?这些决策共同决定了你实现的CMN-700子系统的性能、面积和功能。
设计心得:清晰的层次划分是CHI协议可扩展、可验证的基石。作为架构师,你需要为每一层指定关键参数:协议层支持哪些事务类型?网络层的数据包位宽和ID位宽是多少?链路层的VC数量和信用点深度如何?这些决策共同决定了你实现的CMN-700子系统的性能、面积和功能。
3.2 数据包解剖学:Request、Data、Response格式与字段精讲
现在,让我们拿起手术刀,解剖CHI协议中流通的三种"生命体":请求包(Request Flit)、数据包(Data Flit)、响应包(Response Flit)。一个"Flit"是网络中的基本传输单元。
3.2.1 通用包头字段
所有类型的包都共享一些通用字段,主要在网络层添加:
-
QoS:服务质量域,4位。用于标识事务的优先级(0-15)。高优先级的包在网络仲裁和节点处理时享有优先权。 -
TgtID,SrcID:如前所述,目标节点和源节点的唯一标识符。通常与Mesh坐标或节点索引相关。 -
TxnID:事务ID,8-16位可配置。这是匹配请求与响应的关键。同一个RN发起的每个未完成事务必须有唯一的TxnID。HN在返回响应和数据时,必须原样携带此ID。 -
Opcode:操作码,定义包的类型(如ReadNoSnp,CompData等)。 -
Addr:物理地址(或部分地址)。对于请求包,这是要访问的地址;对于窥探包,这是要被窥探的地址。 -
Size和Mask:指示传输的数据大小(如一个缓存行64字节)以及字节使能掩码(用于部分写)。
3.2.2 请求包详解
请求包由事务发起者(RN)发出,流向目标(HN或SN)。
-
关键字段:
-
Opcode:ReadNoSnp,ReadOnce,WriteNoSnp,WriteBack,CleanUnique,SnpOnce等。 -
Order:排序要求,如Ordered或Unordered。 -
Excl:是否请求独占访问(用于原子操作或写)。 -
RetToSrc:数据是否应直接返回给源(RN),而不经过HN。这是CHI的优化,减少跳数。
-
-
设计举例 :一个CPU想读取地址0x8000_0000。其RN-F会发出一个
ReadNoSnp请求包,其中TgtID根据SAM映射到HN1,SrcID为自己,TxnID设为0x5A,Addr=0x8000_0000,Size=64字节。
3.2.3 数据包详解
数据包携带实际的数据内容,可以在请求者、HN和监听者之间流动。
-
关键字段:
-
Opcode:CompData(包含数据)、CompDBIDResp(仅确认,无数据)、SnpRespData(窥探响应数据)等。 -
Data:有效负载,位宽可配(如512位,对应64字节缓存行)。 -
CCS(Coherent Cache State):数据所附带的新的一致性状态 。例如,当HN将数据返回给RN时,会告知RN"你现在应该以UC状态缓存此数据"。 -
RespErr:指示传输是否出错。
-
-
设计举例 :HN在处理完上述
ReadNoSnp后,发现数据来自另一个RN-F的缓存。HN会向那个RN-F发送一个SnpOnce请求包。该RN-F在回送数据时,会发送一个SnpRespData数据包给HN,数据字段包含缓存行,CCS字段可能置为I(无效,因为数据已被拿走)。
3.2.4 响应包详解
响应包用于确认一个事务已完成,或传递状态信息,通常不携带数据。
-
关键字段:
-
Opcode:Comp(完成,表示请求已满足)、RespSepData(响应与数据分离)、DBIDResp(数据缓冲区ID响应,用于信用点管理)等。 -
Resp:详细的响应类型,如OKAY,ERROR,DONE等。
-
-
设计举例 :SN-F在将数据写入DDR后,会向HN返回一个
Comp响应包,表示写入完成。HN再向原始的RN-I返回Comp,整个写事务结束。
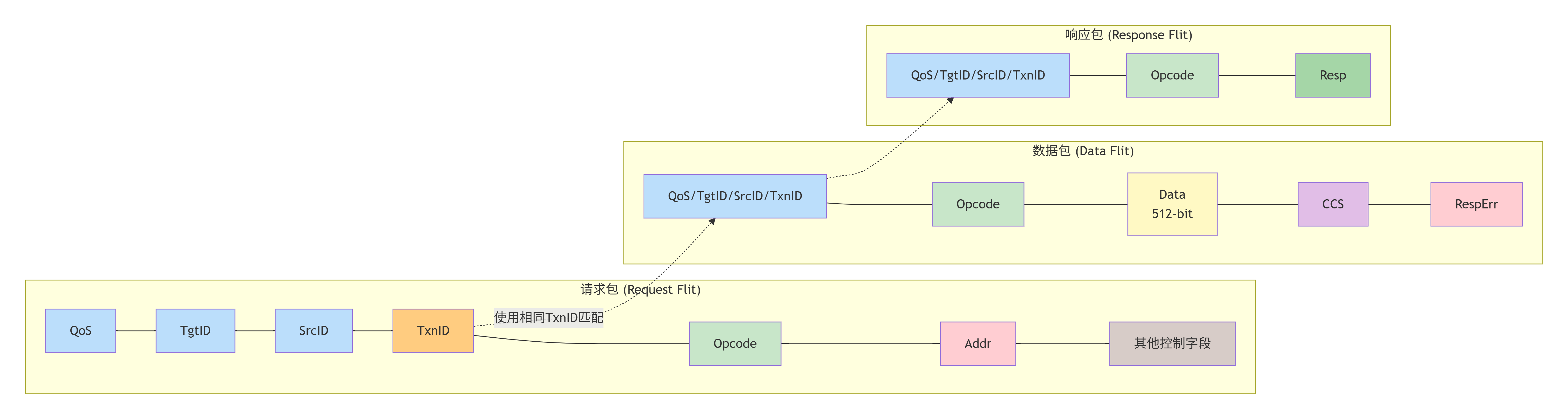
关键点:TxnID是贯穿整个事务生命周期的"事务护照",必须始终保持一致。CCS字段是实现分布式缓存状态同步的核心机制。
3.3 缓存一致性状态(CState):U、I、SC、SD、UC的深刻内涵
缓存一致性状态的本质是为每一行缓存数据(通常是64字节)分配一个"社交身份",这个身份定义了:谁拥有它?有多少份?是否与内存一致?能否修改?CHI协议定义了一套清晰的状态机,所有缓存(L1、L2、SLC)和HN的目录都必须遵守这套规则。
让我们来认识CHI协议中的核心"社交身份":
| 状态 | 全称 | 中文释义 | 含义与规则 |
|---|---|---|---|
| I | Invalid | 无效 | 数据副本无效,不能使用。这是所有行的初始状态。 |
| SC | Shared Clean | 共享干净 | 数据在一个或多个 缓存中有效,且与内存一致。任何持有者都不能直接修改。若要修改,必须先升级到U状态。 |
| SD | Shared Dirty | 共享脏 | 数据在多个 缓存中有效,但内存副本是过时的。其中一份是"脏"的(已修改)。这是一个过渡状态,最终需要写回内存。 |
| UC | Unique Clean | 唯一干净 | 数据在唯一一个 缓存中有效,且与内存一致。该缓存有权未来修改它(通过转为UD),无需通知他人。 |
| UD | Unique Dirty | 唯一脏 | 数据在唯一一个 缓存中有效,且内存副本是过时的。该缓存是数据的"主人",最终需要负责写回内存。 |
| UCE | Unique Clean Exclusive | 唯一干净独占 | 一种优化状态,表示缓存独占此数据(唯一),且计划立即写入,从而可以跳过一次状态转换。 |
状态转换的黄金法则:
-
从I开始:任何缓存行最初都是I。
-
读操作通常获得SC或UC:如果系统中没有其他副本,读请求者获得UC;如果已有其他共享副本,则获得SC。
-
写操作需要U状态 :要写入一行,缓存必须持有该行的U状态(UC或UD)。如果当前是SC,需要先发起一个
CleanUnique事务,让其他所有持有者无效化(转I),自己升级为UC。 -
脏数据必须被追踪:UD状态表示数据是"脏"的,HN的目录会记录这一点。当其他节点需要这行数据时,HN会要求UD持有者将数据写回(或直接转发)。
-
SD是一个关键的优化状态:当一行数据在多个缓存中(SC),其中一个缓存需要写它时,传统做法是先让所有其他缓存无效化(转I),然后写。但CHI允许先转为SD,然后由需要写的缓存获取数据并升级为UD,这样可以避免从内存重新读取数据。
目录的作用 :HN中的目录记录了每一行数据在系统中的全局状态。它不存储数据本身,只存储元数据:这行数据是UC/UD(在哪一个RN?)还是SC/SD(在哪些RN的集合中?)。目录是实现这些状态转换的"裁判"。
设计实例:假设我们有两个CPU集群(RN-F0和RN-F1)。
-
场景A :RN-F0读取地址X,没有其他缓存有副本。HN将数据从内存取出,送给RN-F0,并告知
CCS=UC。目录记录:X -> RN-F0 (UC)。 -
场景B :RN-F1随后读取同一地址X。HN查询目录,发现RN-F0持有UC。HN会向RN-F0发送
SnpOnce。RN-F0将数据转发给HN(或直接给RN-F1,如果RetToSrc),并将自己的状态降级为SC。HN将数据送给RN-F1,告知CCS=SC。目录更新:X -> {RN-F0, RN-F1} (SC)。 -
场景C :RN-F0要写入地址X。它必须先从SC升级为UC。RN-F0向HN发送
CleanUnique请求。HN向所有持有者(RN-F0和RN-F1)发送SnpCleanUnique。RN-F1使其副本无效(转I),RN-F0升级为UC。然后RN-F0才能执行写操作,完成后状态变为UD。目录更新:X -> RN-F0 (UD)。
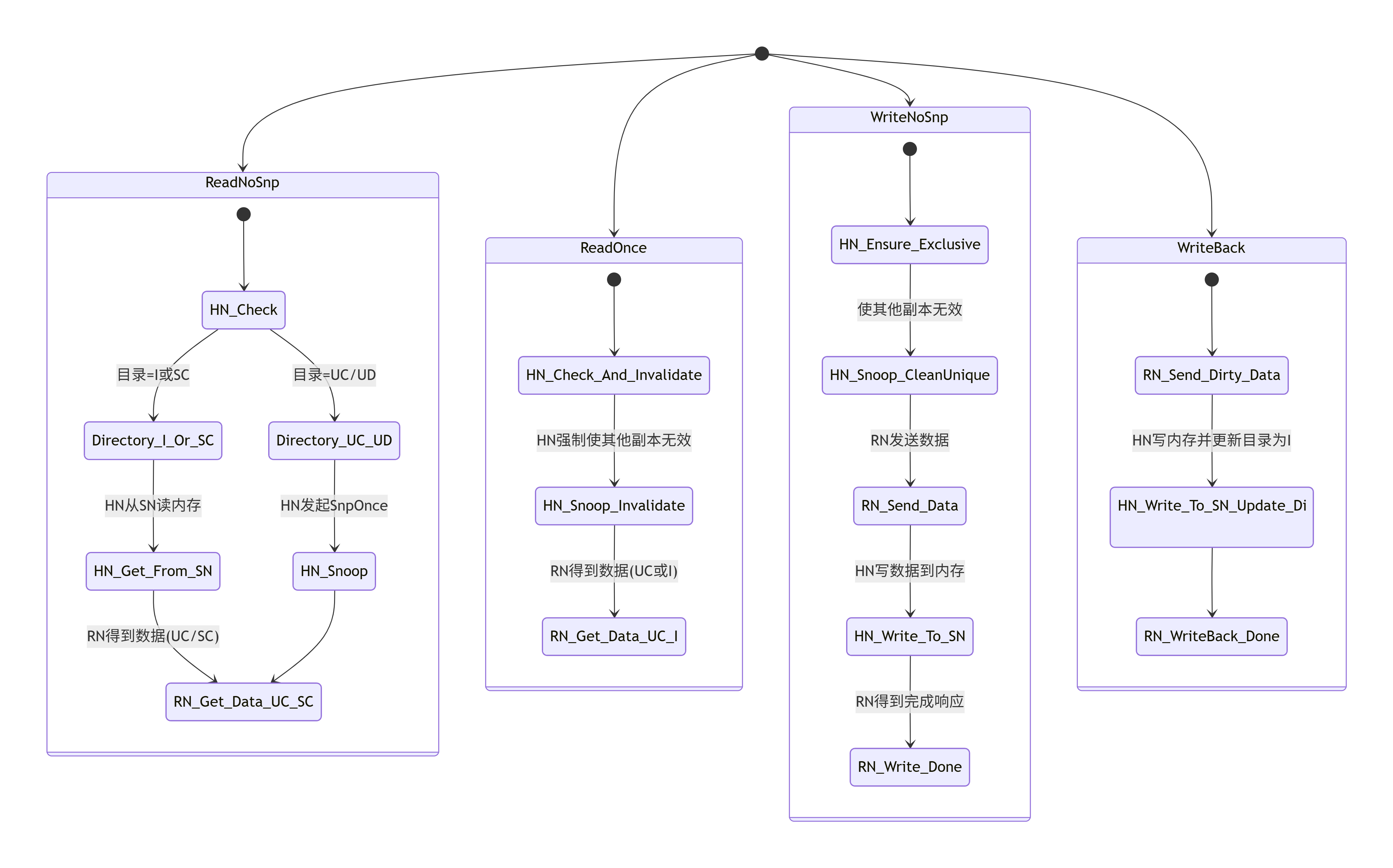
3.4 关键事务类型详解:ReadNoSnp, ReadOnce, WriteNoSnp, WriteBack
CHI定义了丰富的事务类型来覆盖所有可能的操作。我们来深入理解几个最核心、最常用的事务。
3.4.1 ReadNoSnp
-
发起者:RN(通常是RN-F或RN-I)。
-
目标:HN(对于可缓存地址)或SN(对于不可缓存地址)。
-
语义 :"请把地址A的数据给我,不要 去窥探其他缓存(如果可能的话)。" 这是一个"懒惰"的请求,HN会先检查自己的目录。如果目录显示数据是UC/UD在某个缓存,则HN必须 去窥探(
SnpOnce),因为需要获取最新数据。如果目录显示是SC/SD或不在任何缓存(I),则HN可以直接从内存(通过SN)提供数据,无需窥探。 -
典型用途:CPU的普通内存读取。这是最常用的读事务。
3.4.2 ReadOnce
-
发起者:RN(通常是RN-I,如GPU/DMA)。
-
目标:HN。
-
语义 :"把地址A的数据给我,并且确保 在把数据给我之后,所有其他缓存中的副本都无效化 。" 即使数据原本是共享的,HN也会强制发起窥探使其他副本无效。最终,请求者获得数据,并以
I或UC状态缓存(取决于配置)。 -
典型用途 :GPU或DMA读取即将被修改的数据。这避免了后续的
CleanUnique操作,因为数据已经是独占的了。
3.4.3 WriteNoSnp
-
发起者:RN(任何类型)。
-
目标:HN或SN。
-
语义 :"我要把数据写到地址A。" 对于可缓存地址,HN需要确保写之前,该地址在所有其他缓存中的副本都无效化(通过
SnpCleanUnique或依赖目录)。写完成后,数据在请求者缓存中处于UD状态(如果可缓存)。 -
数据流 :这是一个"带数据"的请求。通常,RN先发送
WriteNoSnp请求包,然后紧跟着一个或多个Data包。HN在确保独占性并收到数据后,会向SN发起写内存操作,并向RN返回完成响应。 -
典型用途:CPU的存储指令。
3.4.4 WriteBack
-
发起者:RN(通常是RN-F)。
-
目标:HN。
-
语义 :"我这里有一行脏数据(状态UD),我现在要把它写回内存,并放弃所有权。" 发送者将脏数据和
WriteBack请求一起发送给HN。HN将数据写入内存(通过SN),并更新目录,将该行状态标记为I或SC(如果其他缓存有请求)。 -
典型用途 :缓存替换。当CPU的L2缓存需要腾出空间给新数据时,如果被替换的行是脏的,就必须发起
WriteBack。
3.5 排序模型与屏障(Barrier):如何建立全局内存访问秩序?
在多处理器系统中,内存操作的完成顺序至关重要,尤其是对于同步原语(如锁、信号量)。CHI提供了强大的排序模型来满足程序员的需求。
3.5.1 排序点与观察者
-
排序点 :一个事务在某个特定观察者 看来"完成"的时刻。对于请求者RN ,一个读事务在收到所有数据和
Comp响应时完成;一个写事务在收到Comp响应时完成。 -
观察者 :可以是一个特定的RN ,或者是内存系统(SN)。
3.5.2 CHI排序规则
-
单一发起者顺序 :同一个RN 发起的到同一个目标的事务,按照它们被RN发出的顺序被目标观察到。
-
地址依赖 :对同一个地址的操作,在所有观察者看来都保持相同的顺序。这由HN的目录序列化机制保证(目录对同一地址的请求排队处理)。
-
弱于依赖:对不同地址且没有显式屏障的事务,系统不保证它们的完成顺序。这允许了性能优化(乱序执行、预取)。
3.5.3 内存屏障(Memory Barrier)
当程序需要严格的全局顺序时,就使用屏障。在CHI中,屏障是一种特殊的事务。
-
典型屏障事务 :
DBarrier(Data Barrier),MBarrier(Memory Barrier)。 -
工作原理 :RN发出一个屏障事务。这个屏障事务本身没有数据,但它像一个"标记"。
-
在屏障之前 从该RN发出的所有内存访问事务,必须在屏障事务到达目标之前完成。
-
在屏障之后 从该RN发出的所有内存访问事务,必须在屏障事务到达目标之后才能开始。
-
屏障事务会确保其效果被系统中所有相关的HN和RN观察到。
-
-
实现细节 :在HN中,屏障通常会导致一个排序点,HN会清空与该RN相关的所有未完成事务,然后再处理屏障之后的事务。屏障的实现是HN设计中最微妙的部分之一,需要仔细处理以避免死锁和性能下降。
设计举例 :在自旋锁的实现中,"获取锁"通常包含一个原子的读-修改-写操作(如LDXR/STXR循环),后面跟着一个DBarrier。这个屏障确保锁获取操作完成之前,其后的临界区内存访问不会提前执行,从而保证了互斥。
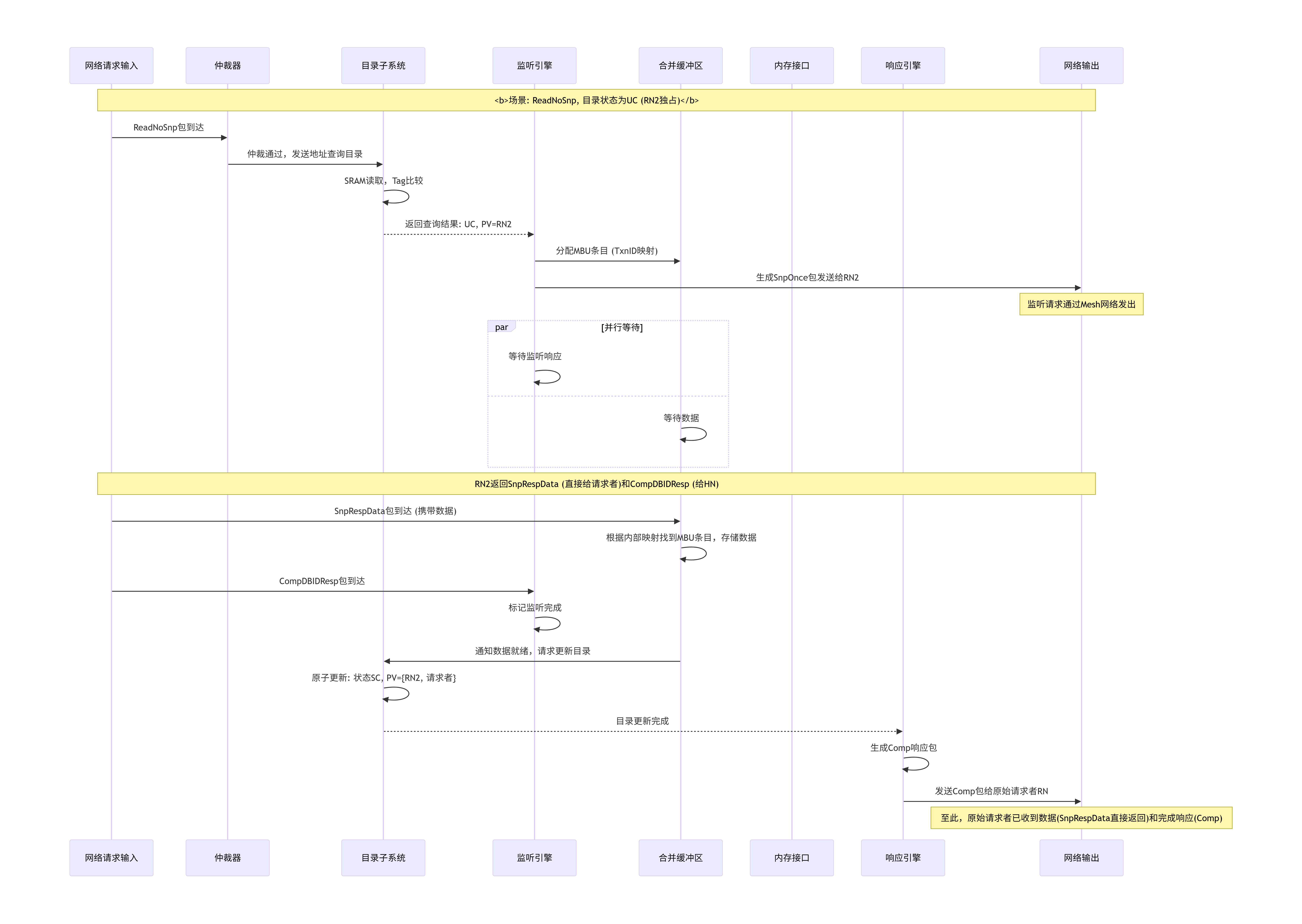
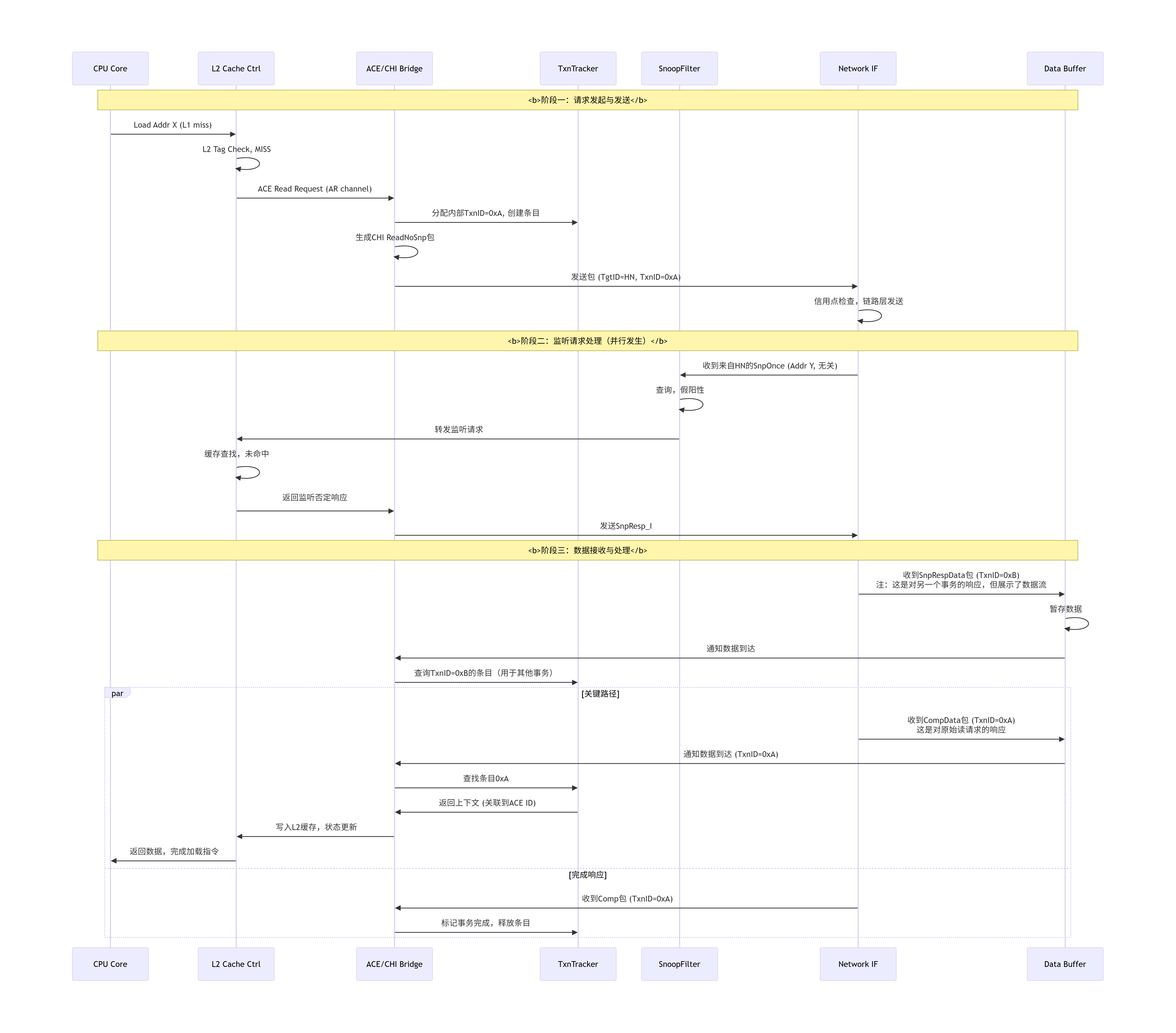
3.6 一次完整缓存行读缺失(ReadNoSnp)的协议时序对话
让我们将本章的所有知识串联起来,通过一个详细的Mermaid序列图 ,直观展示一次典型的缓存读缺失在CMN-700网络中引发的完整协议对话。我们假设一个稍微复杂的场景:CPU集群0的Core 0读取一个地址,该地址的数据正以UD状态缓存在CPU集群1的L2缓存中。
这张时序图揭示的关键设计要点:
-
分离的响应与数据 :注意,数据(
SnpRespData)直接由RN1返回给了RN0(这是一个RetToSrc优化),而完成响应(Comp)则由HN在收到所有确认后发送。这减少了数据路径的跳数,降低了延迟。 -
事务ID的匹配 :原始读请求的
TxnID=0xAA,而HN发起的监听请求使用了新的TxnID=0xBB。在RN0端,它需要将TxnID=0xBB的数据包与本地等待的TxnID=0xAA的请求关联起来(通过地址或内部映射表)。HN则负责将TxnID=0xBB的完成与TxnID=0xAA的请求关联。 -
信用点管理 :
CompDBIDResp是信用点管理包,用于释放RN1和HN之间用于监听事务的缓冲区。图中未显示所有的信用点流,但它们是链路层无阻塞运行的基础。 -
目录状态更新:HN在收到所有响应后,才原子性地更新目录状态。这确保了系统在任何时刻都有一致性的视图。
通过本章的学习,你已经掌握了CMN-700这座城市的"通用语言"------CHI协议。你知道了外交辞令(协议层)、邮政系统(网络层)、邮差规则(链路层)如何协同工作,也理解了数据包的结构、缓存状态的社交规则、关键事务的语义,以及如何维护内存秩序。现在,你已准备好走进这座城市的核心建筑内部。在下一章,我们将深入主节点(HN) 的设计与实现,探索这个"一致性大脑"的奥秘。
第四章:核心枢纽设计与实现:主节点(HN)
4.1 HN家族分化:HN-F(全功能)、HN-I(仅监听)、HN-D(仅目录)的微架构差异
欢迎来到CMN-700的"市政厅"------主节点(Home Node)。如果说XP是城市道路的立交桥,那么HN就是城市的交通指挥中心、档案馆和调度站三合一。它不仅是数据流转的必经枢纽,更是整个一致性系统的"大脑",掌握着每一份数据副本的"户籍档案"。
但并非所有市政厅都需要处理同样复杂的事务。CMN-700提供了三种不同定位的HN变体,让架构师可以根据系统需求进行精准配置:
| 节点类型 | 全称 | 类比 | 核心能力 | 典型应用场景 |
|---|---|---|---|---|
| HN-F | Full-function Home Node | 全能型市政厅 | 拥有完整的目录(Directory) 、监听处理逻辑 、请求处理流水线 和系统级缓存(SLC)接口。能处理所有一致性事务。 | SoC内部的主要一致性域管理者。大多数设计都使用HN-F。 |
| HN-I | Intervention Home Node | 交警分局 | 只有监听处理逻辑 ,没有目录。它不负责维护数据的状态档案,但可以代表其他HN执行监听请求。 | 用于多芯片扩展(C2C)。主芯片的HN-F可以将对辅芯片的监听任务委托给辅芯片上的HN-I,避免跨芯片的目录查询延迟。 |
| HN-D | Directory-only Home Node | 档案管理局 | 只有目录 ,没有监听处理逻辑。它仅维护数据状态档案,但具体的监听操作由其他节点完成。 | 用于分离式架构。例如,将目录集中管理,而监听逻辑分布到各个计算单元附近,以减少监听延迟。 |
选择指南:
-
95%的场景选择HN-F:对于单芯片SoC,HN-F是最自然、最完整的选择。
-
当需要跨芯片一致性时考虑HN-I:在多芯片系统中,每个芯片上部署HN-I作为本地监听代理,主芯片的HN-F通过它们间接管理整个系统的缓存。
-
极端优化的分离架构考虑HN-D:当系统规模极大,需要将目录存储和监听逻辑物理分离以优化时序和功耗时,但这会引入额外的网络流量和复杂度。
在本章,我们将深度剖析最核心、最复杂的HN-F。一旦掌握了HN-F,理解HN-I和HN-D将水到渠成。
4.2 HN-F深度剖解:全能型市政厅的架构奥秘
让我们推开HN-F厚重的大门,看看这座"市政厅"内部如何运作。下图展示了其核心微架构模块和数据流:

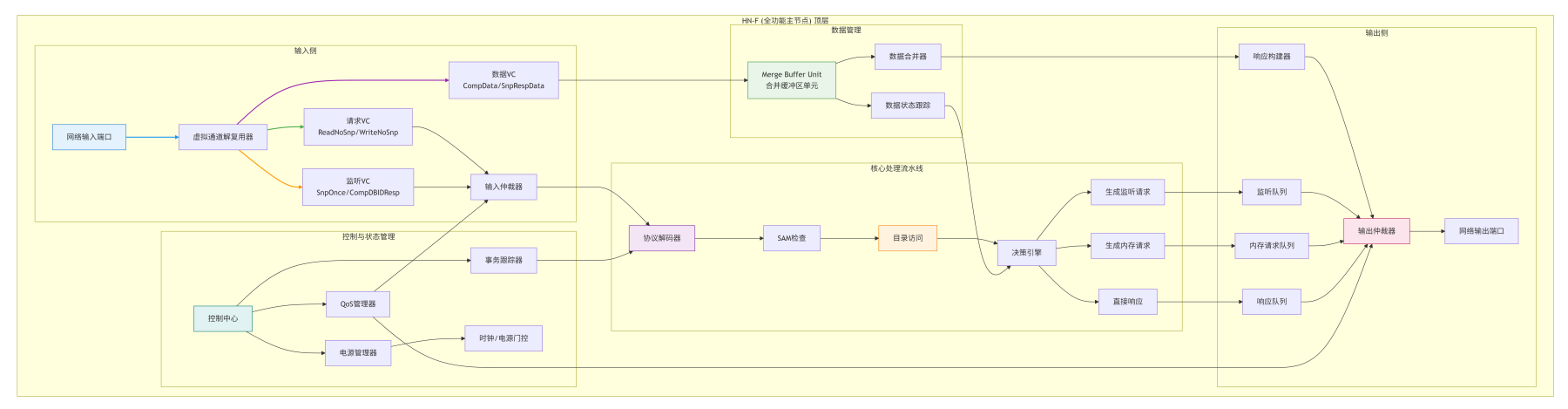
4.2.1 请求处理前端:QoS、仲裁与协议检查
当一个请求包(如ReadNoSnp)从Mesh网络抵达HN-F的输入端口时,它的处理之旅就开始了。
-
虚拟通道(VC)分离 :输入端口首先根据包的类型(请求、响应、数据、监听),将其放入对应的虚拟通道缓冲区 。这防止了不同类别的流量相互阻塞,是避免协议死锁的基础。例如,一个等待数据的
ReadNoSnp请求不能阻塞SnpOnce请求的接收,因为后者可能正是获取数据的关键。 -
仲裁与QoS :每个周期,请求仲裁器会从待处理的请求队列中选出一个进行处理。仲裁策略结合了:
-
QoS优先级:来自高优先级请求者(如实时CPU核心)的包会获得优先服务。
-
公平性:采用Round-Robin等算法防止低优先级请求者被"饿死"。
-
关键性 :某些事务类型(如屏障
Barrier)可能被赋予更高权重。
-
-
协议解码与安全检查 :被选中的请求包被解码,其
Opcode、Addr、TxnID等字段被提取。同时进行一系列安全检查:-
地址是否对齐?
-
Opcode对本HN是否合法?(例如,一个SnpOnce不应该发给HN,应该是HN发出) -
事务ID是否在有效范围内?
-
-
SAM二次确认 :虽然网络层已经根据SAM将请求路由到了本HN,但HN内部会再次检查地址是否确实属于自己的管辖范围。这是一个重要的防御性设计,防止错误配置导致数据错乱。如果不属于,HN会将该请求包原路"弹回"网络(通过其连接XP的另一个端口),并附带一个错误标记。
4.2.2 目录(Directory)结构设计:Tag与状态的存储方式
目录是HN-F的"户籍档案库",记录了系统中每一行可缓存数据(Cache Line)的全局状态 和持有者信息。其设计是HN-F面积、性能和复杂度的核心权衡点。
稀疏目录 vs. 全映射目录
-
全映射目录 :为系统物理内存中的每一行都分配一个目录条目。对于4GB内存、64字节行大小,需要 6400万条目!这完全不现实。
-
稀疏目录(Sparse Directory) :只记录那些确实被缓存在系统中某处 的数据行。这像一个缓存一样工作,只保存活跃的条目。CMN-700采用稀疏目录。
稀疏目录的微架构
一个稀疏目录通常组织为一个组相连(Set-Associative) 的结构,类似于CPU缓存。
-
索引与标签:物理地址被划分为三个部分:
// 假设物理地址48位,缓存行64字节(低6位为偏移) [47:12] // Tag (36位): 用于唯一标识一个缓存行 [11:6] // Index (6位): 用于选择目录中的组(Set)。2^6 = 64个组。 [5:0] // Byte Offset (忽略) -
目录条目内容:
-
Valid Bit:该条目是否有效。
-
Tag:存储地址的Tag部分,用于比较。
-
状态(State) :该数据行的全局一致性状态(如
I,SC,UC,UD,SD)。 -
存在向量(Presence Vector/PV) :一个位图,每一位对应系统中的一个可能持有该行副本的RN-F 。如果位被置1,表示对应的RN-F缓存中有该行。这是追踪共享者的关键。
-
脏位(Dirty Bit):指示唯一持有者(UC/UD)的数据是否与内存一致。通常状态字段已隐含此信息。
-
其他元数据:如LRU位(用于替换)、锁定位(用于原子操作)等。
-
目录操作示例
假设一个8路组相连目录,系统中有4个RN-F。
-
查询 :收到地址
Addr,用Index找到对应的组(Set)。同时比较组内8个条目的Tag和Valid。若命中,读取其State和PV。假设State=UC,PV=0100(表示RN-F2独占)。 -
更新 :处理完事务后,需要更新目录。例如,RN-F1读走了该行数据,则需将状态更新为
SC,PV更新为0110(RN-F2和RN-F1共享)。目录更新必须是原子的,以防止竞态条件。 -
替换 :如果查询未命中(即该行未被任何缓存记录),则需要分配一个新条目。如果组已满,则根据LRU策略替换一个旧条目。被替换的条目如果状态是
UD(脏且唯一),则HN必须先将该行数据写回内存(通过SN)才能替换,这称为目录写回(Directory Writeback)。
设计参数抉择:
-
目录大小(条目数) :决定了能同时追踪多少活跃缓存行。太小时,目录溢出会导致频繁的写回和性能下降。经验法则是目录大小应不小于所有客户端缓存总大小的10%(例如,4个4MB L2缓存,目录至少1.6MB条目?实际是按行数算)。
-
相连度:高相连度减少冲突未命中,但增加比较器和面积。通常选择8路或16路。
-
存在向量位宽:等于系统中RN-F的数量。需要在设计早期确定,因为这会固定目录条目的格式。
4.2.3 窥探(Snoop)与一致性控制引擎:如何生成并管理监听请求?
这是HN-F协议层的"决策中枢"。它根据请求类型 和目录查询结果,决定下一步的行动方案。
监听请求生成器 是一个复杂的状态机。我们以ReadNoSnp请求为例,展示其决策逻辑:
监听请求队列管理 :
生成的监听请求(如SnpOnce)被放入监听请求队列。HN-F必须追踪每个发出的监听请求,并与其原始请求关联(通过内部事务ID映射)。当监听响应返回时,HN-F需要找到对应的原始请求上下文,继续处理。
关键挑战------监听风暴(Snoop Storm) :
当一个热门数据行被许多核心共享(SC状态)时,突然一个核心请求写入(需要CleanUnique)。HN-F需要向所有共享者 发送SnpCleanUnique使其无效化。如果PV很大(例如64位),这会产生大量的监听请求,淹没网络。CMN-700通过监听过滤器(Snoop Filter) 和广播/组播优化来缓解,但设计时仍需注意共享数据的热点问题。
4.2.4 数据缓存与合并:MBU(Merge Buffer Unit)的设计奥秘
数据可能在监听响应、内存响应等多个时间点、以多个数据包的形式返回。HN-F需要将它们正确合并,并可能进行格式转换。合并缓冲区单元(MBU) 就是负责这项工作的"装配车间"。
MBU的典型结构 :
MBU由多个条目(Entry) 组成,每个条目对应一个未完成的、需要数据合并的请求。每个条目包含:
-
有效位和标签:用于标识。
-
目标地址。
-
数据缓冲区:一个64字节的缓冲区,用于暂存数据。
-
字节有效掩码(Byte Valid Mask):一个64位的位图,指示缓冲区中哪些字节已经收到有效数据。
-
期望的数据来源计数 :例如,对于
SD状态,可能需要等待多个监听响应。 -
状态机:跟踪该条目的合并进度。
MBU工作流程------以部分写(Partial Write)为例:
-
RN-F发送一个
WriteNoSnp,但只写一个缓存行的前32字节(通过Mask字段指示)。 -
HN-F收到请求,查询目录,确保独占性。
-
HN-F为这个写请求在MBU分配一个条目。
-
如果数据是脏的 :HN-F可能需要先发起
SnpOnce获取当前数据。当监听响应数据到达时,MBU根据其来源地址,将数据写入对应条目的缓冲区,并更新字节有效掩码。 -
写入新数据 :当
WriteNoSnp的数据包到达时,MBU根据Mask将新数据合并到缓冲区的相应位置。 -
读内存补全:如果有些字节既不是脏的也没有被新数据覆盖(即需要从内存读取旧值),HN-F会发起一个内存读,将读回的数据合并。
-
完成合并:当字节有效掩码显示所有64字节都已就绪,MBU通知响应生成器,将完整的缓存行写入内存(通过SN),并发送完成响应给请求者。
MBU的大小设计:MBU的条目数决定了HN-F能同时处理的、需要进行数据合并的请求数量。太小的MBU会成为性能瓶颈,尤其是在有大量部分写或原子操作的场景。通常,MBU条目数为8-16。
4.2.5 后端接口:与XP、内存控制器(SN)的对接逻辑
HN-F的后端是数据"出发"的地方。它有多个输出通道:
-
监听请求通道 :向其他RN-F发送
SnpOnce等请求。 -
内存请求通道 :向SN发送
MemRead、MemWrite。 -
响应/数据通道 :向原始请求者返回
Comp、CompData等。
这些通道共享物理输出端口,但逻辑上独立。输出仲裁器负责调度这些通道的流量。调度策略同样考虑QoS、公平性和紧迫性(例如,内存读请求通常比监听请求更紧迫,因为它在关键路径上)。
信用点管理 :每个输出通道都有独立的信用点计数器,跟踪目标节点(XP或SN)的缓冲区空间。只有信用点>0时,才能发送数据包。信用点的初始深度和返回机制是保证链路层无阻塞的关键。
4.3 关键实现细节
4.3.1 流水线深度与延迟权衡
HN-F是一个高度流水线化的设计,典型的流水线可能有5-8级:
-
RCV:接收与VC分配。
-
ARB:仲裁与解码。
-
DIR:目录访问(包括Tag比较、状态读取)。
-
SNP:监听决策与生成。
-
MBU:数据合并与缓冲。
-
RSP:响应生成。
-
SND:发送。
关键路径 通常是目录访问阶段,因为它涉及较大的SRAM阵列读取和复杂的比较逻辑。为了达到高频(如2GHz+),可能需要将目录访问拆分为两到三级流水线。
延迟与频率的权衡:更深的流水线可以提高时钟频率,但增加了请求的固定处理延迟(每个请求都要经历更多周期)。对于延迟敏感的应用(如CPU的L2缓存未命中),需要精心优化流水线,减少不必要的级数。
4.3.2 死锁与活锁的避免机制
死锁避免:
-
虚拟通道:如前所述,分离请求、响应、数据、监听通道。
-
资源顺序:确保资源获取顺序一致。例如,HN-F内部在处理一个请求时,如果需要分配MBU条目和目录条目,总是按固定顺序(如先目录后MBU)分配。
-
无循环依赖:确保协议事务不会形成等待环。CHI协议本身已被证明是无死锁的,但RTL实现必须严格遵守协议规定的依赖关系。
活锁避免 :
活锁指事务不断重试但无法完成。例如,两个核心同时写同一地址,互相使对方无效化。解决方案是序列化(Serialization):
-
HN-F的目录对同一地址的请求自然序列化。因为目录状态更新是原子的,第二个请求必须等待第一个请求的目录操作完成。
-
对于高争用地址,HN-F可以实现一个小型的请求缓冲区,将冲突请求排队,而不是让请求者重试。
4.3.3 电源状态管理与动态时钟门控
HN-F是功耗大户。其功耗管理包括:
-
时钟门控:当输入缓冲区和所有内部处理单元空闲时,关闭大部分逻辑的时钟。
-
电源门控 :在深度睡眠状态(整个SoC休眠),可以关闭HN-F的电源。但目录内容必须保留!因为其中可能包含脏数据(UD状态)尚未写回内存。解决方案有两种:
-
使用保持寄存器(Retention Register):目录SRAM使用特殊的能保持数据的低功耗单元,在掉电时数据不丢失。
-
写回并失效:在进入深度睡眠前,由软件触发,将所有UD状态的行写回内存,并将目录条目置为I。这增加了唤醒延迟,但简化了硬件。
-
-
动态电压频率调整(DVFS):HN-F可以运行在不同的电压/频率点上。当系统负载低时,降低频率和电压以节省功耗。这需要与整个SoC的电源管理单元(PMU)协同。
4.4 HN-F内部微架构数据通路与状态机流转
下面我们用一个更动态的序列图,展示一个ReadNoSnp在HN-F内部的完整处理流程,涵盖目录访问、监听生成、数据合并和响应返回。
4.5 设计案例:为AI训练芯片配置HN-F
假设我们设计一款AI训练芯片,特点如下:
-
32个AI核心,每个核心有私有L1缓存,每4个核心共享一个L2缓存(共8个L2)。
-
高带宽HBM2e内存,4个控制器。
-
工作负载:大量矩阵计算,写后读依赖重,部分写频繁。
HN-F配置决策:
-
HN数量 :使用4个HN-F。将物理地址空间划分为4个区域,分别由4个HN-F管理。这平衡了负载,减少了单个HN的目录压力。
-
目录结构:
-
大小:每个L2缓存8MB,总L2容量64MB。目录大小设为L2总容量的~15%,即约10MB条目(但注意,目录存储的是元数据,不是数据本身)。按每个条目(Tag+State+PV)约20字节估算,10MB条目需要200MB存储?不,这里计算有误。实际上,目录条目数应等于它能追踪的缓存行数。64MB L2 / 64B/行 = 1M行。目录大小设为150K条目(15%)。每个条目大小:Tag(36b)+State(3b)+PV(32位=4B)+其他≈12字节。总大小≈150K * 12B ≈ 1.8MB。这个大小更合理。
-
相连度:选择16路组相连,以降低冲突未命中。
-
PV位宽:32位(对应32个可能的缓存代理,但实际只有8个L2 RN-F,可优化)。
-
-
MBU大小 :由于部分写频繁,配置较大的MBU------每个HN-F配置16个条目。
-
流水线:目标频率1.5GHz,采用7级深度流水线,将目录访问拆分为两级(地址生成与SRAM读、Tag比较与状态解码)。
-
QoS策略:为内存读请求赋予最高优先级,因为AI训练中权重加载是关键路径。
通过这样的定制化配置,HN-F能够高效地管理AI芯片复杂的一致性需求,为计算提供稳定的数据供应。
至此,我们已经深入了解了CMN-700的"大脑"------HN-F的运作机理。在下一章,我们将转向网络的"门户"------请求节点(RN)和"终点站"------从节点(SN),探索它们如何与HN协同,完成片上数据之旅。
第五章:门户与终端设计:请求节点(RN)与从节点(SN)
5.1 RN的设计哲学:协议转换与流量整形
欢迎来到CMN-700的"城市出入口"------请求节点(Request Node)。如果说HN是市政厅,那么RN就是每个社区的物业服务中心 。所有想要进出CMN网络的"居民"(CPU核、GPU、加速器)都必须通过RN。RN的核心使命是:为不同的"居民"提供标准化的出入服务,翻译他们的"方言",并管理他们的"快递包裹"。
5.1.1 RN的类型分化
根据所服务"居民"的特性和需求,RN分为三类:
| 类型 | 全称 | 类比 | 一致性角色 | 典型连接对象 |
|---|---|---|---|---|
| RN-F | Full-function Request Node | 高档社区的物业 | 完整的居民:既能主动发起请求,也能接收并处理来自市政厅(HN)的"核查通知"(监听请求)。它代表拥有私有缓存的智能体。 | CPU集群(带L1/L2缓存)、智能网卡 |
| RN-I | I/O Request Node | 物流公司的收发站 | 主动型访客:主要发起请求,但也能被动接受"核查"以保持货物(数据)正确。通常自身只有简单缓冲区。 | GPU、DMA引擎、PCIe/CXL设备 |
| RN-D | Data Request Node | 原材料加工厂 | 纯生产者/消费者:只关心原材料(数据)进出,不关心产权(一致性)。 | 显示引擎、视频编解码器、简单加速器 |
设计决策点:为一个IP选择哪种RN,取决于三个问题:1)它需要发起内存请求吗?2)它有自己的缓存吗?3)它需要与其他缓存保持一致性吗?回答这些问题决定了RN的类型。
5.1.2 RN-F的微架构剖析:CPU集群的"全能管家"
RN-F是最复杂的RN,我们深入其内部。它必须处理两大核心任务:向外发起请求 和向内处理监听。下图展示了其核心模块:
前端接口与协议桥
这是RN-F与所连接的CPU集群的边界。如果CPU集群使用ACE(AXI Coherency Extensions) 协议,则需要一个复杂的协议桥进行转换。ACE和CHI虽然理念相通,但细节不同:
-
ACE是面向连接的(基于ID),而CHI是面向数据包的(基于TxnID)。
-
ACE的监听是广播式的,而CHI是基于目录的点对点监听。
协议桥需要维护ACE ID到CHI TxnID的映射,并处理ACE的通道分离(读/写通道)到CHI虚拟通道的转换。
设计挑战:协议桥是延迟的关键路径之一。优化其流水线深度和缓冲区大小对性能至关重要。如果CPU原生支持CHI(如ARM Neoverse内核),则此模块大大简化。
事务跟踪器(TxnTracker)------ RN的"记忆中枢"
这是RN-F的核心状态机 。它为每一个从CPU发起的、尚未收到最终完成响应的未完成事务(Outstanding Transaction) 维护一个条目。每个条目包含:
-
本地事务ID(内部映射)。
-
分配的CHI TxnID(用于网络包)。
-
事务状态:已发送请求、已收到部分数据、等待完成响应等。
-
地址、大小、操作类型。
-
指向数据缓冲区的指针(如果需要)。
-
监听关联信息(如果该事务触发了监听)。
实现细节 :TxnTracker通常实现为一个内容可寻址存储器(CAM) 或 带搜索逻辑的SRAM阵列 。当收到一个网络响应包时,需要用其携带的TxnID快速查找到对应的条目。TxnTracker的深度决定了RN-F能同时处理的最大未完成事务数(OT)。对于高性能CPU,OT通常需要支持32-128个。
监听过滤器(SnoopFilter)------ 聪明的"门卫"
当来自HN的监听请求(如SnpOnce)到达时,RN-F需要判断请求的地址是否真的在自己的缓存中。遍历整个L2缓存(可能几MB)是不现实的。监听过滤器 是一个小的、粗略的标签目录 ,它记录了本地缓存中可能存在的地址子集。
-
工作原理 :当CPU缓存行被加载或驱逐时,监听过滤器会同步更新。它是一个集合关系 的结构(如布谷鸟过滤器或精简的标签阵列)。监听请求到达时,先查询过滤器。如果肯定不命中 ,RN-F可以立即回复一个
SnpResp_I(表示"我没有"),而完全不去打扰真正的缓存控制器。这显著降低了监听延迟和功耗。 -
权衡 :过滤器越小,面积和功耗越少,但假阳性(过滤器说有,但缓存实际没有)概率越高,导致不必要的缓存查找。通常过滤器大小是L2缓存的1-2%。
数据缓冲区与合并器
RN-F需要处理来自网络的数据流,这些数据可能:
-
以多个数据包(Flit) 的形式到达(如果一个缓存行被分割传输)。
-
来自不同的来源(如HN的直接内存数据,或其他RN-F的监听响应数据)。
数据缓冲区 临时存储这些数据片段。数据合并器则根据字节掩码将它们拼装成完整的缓存行,然后提交给CPU的缓存或返回给CPU核心。
信用点管理器
管理RN-F与相连的XP之间各个虚拟通道(VC) 的信用点。它跟踪可用的发送额度,并在收到接收方的信用点返回包时更新计数器。信用点机制的实现必须无死锁 且高效,通常采用计数器加阈值告警的方式。
5.1.3 RN-I与RN-D的设计简析
RN-I :结构类似RN-F,但通常简化或移除监听过滤器 ,因为其连接的设备(如GPU)虽然有缓存,但监听频率可能较低,或者其缓存结构复杂,过滤器收益有限。RN-I的重点是高带宽 和大批量事务处理能力。它的TxnTracker可能非常深(支持上千个OT),数据缓冲区很大,以支持GPU的批量数据搬运。
RN-D :最简单。它没有监听处理路径 (因为不涉及一致性)。其主要模块是请求生成器、简单的TxnTracker(仅跟踪请求完成)、数据缓冲区和信用点管理器。设计重点在于低延迟 和确定性的数据传输。
5.2 SN的设计实现:内存系统与终结点的守门人
从节点(Subordinate Node)是CMN-700网络的"终点站"。它代表了一片物理地址空间的终点 ,最常见的就是内存控制器(DMC) 的代理。SN的任务是将网络上的CHI事务,转换为对底层物理设备(如DRAM、SRAM、寄存器组)的具体操作。
5.2.1 SN的类型
| 类型 | 全称 | 类比 | 典型连接对象 |
|---|---|---|---|
| SN-F | Full-function Subordinate Node | 中央仓库的智能装卸平台 | 动态内存(DDR/HBM)、大型片上SRAM(如System Cache)。支持完整的读写、原子操作、错误注入等。 |
| SN-I | I/O Subordinate Node | 特定设备的专属接口 | 外设配置寄存器、Boot ROM、GPIO控制器等。通常只支持简单的加载/存储。 |
5.2.2 SN-F深度剖析:内存控制器的"智能代理"
SN-F是连接CMN与复杂内存系统的桥梁。其设计质量直接影响整个系统的内存带宽和延迟。

地址解码与命令生成
SN-F首先需要确认收到的请求地址是否在自己的管辖范围内(通过SAM配置)。然后,将CHI的逻辑地址 转换为内存控制器所需的物理地址,包括:
-
通道(Channel)选择 :对于多通道内存,SN-F可能内部集成一个简单的地址交错(Interleaving) 逻辑,将连续的地址轮流分配到不同通道,以最大化带宽。
-
Bank、Row、Column地址:根据内存的拓扑结构生成。
-
命令生成 :将
ReadNoSnp转换为内存读命令 ,将WriteNoSnp转换为带数据的内存写命令 。对于WriteBack,也转换为写命令。
事务表(Transaction Table)
类似于RN的TxnTracker,SN-F需要跟踪所有未完成的内存请求。每个条目记录:
-
CHI事务的
SrcID和TxnID(用于构建返回包)。 -
请求类型、地址、大小。
-
状态:已发送到内存控制器、等待数据、数据已返回等。
-
对于读操作,指向读数据缓冲区的指针。
SN-F的OT能力决定了其支持的内存请求并发度,直接影响带宽利用率。
内存调度器
这是SN-F性能的核心。它接收来自命令队列的内存请求(读、写、刷新等),并决定发送给内存控制器的顺序。调度器的目标是:
-
最大化带宽 :通过Bank交错访问,避免连续访问同一Bank导致的预充电延迟。
-
降低读延迟:通常赋予读请求更高的优先级,因为它在CPU的关键路径上。
-
避免写阻塞读 :维护一个写数据缓冲区,允许写命令在后台进行,而不阻塞紧急的读请求。
调度算法非常复杂,可能包括FR-FCFS(先就绪先服务)等策略,并与内存控制器内部的调度协同。
数据路径与对齐
-
写路径 :CHI写数据包到达后,存入写数据缓冲区。当对应的写命令被调度执行时,数据被取出,并根据内存控制器的要求进行位宽转换 (如将256位CHI数据转换为64位DDR数据)和对齐。
-
读路径 :从内存返回的数据经过ECC纠错 (如果使能)后,存入读数据缓冲区。然后被组装成CHI的
CompData包,并附上正确的TxnID和SrcID,发回网络。
原子操作单元
CHI支持的原子操作(如AtomicStore, AtomicSwap)需要在SN-F内部原子地完成"读-修改-写"循环。这需要:
-
地址锁定:在操作期间,防止其他请求对同一地址的访问。
-
执行引擎:一个小型的ALU,执行加法、比较交换等操作。
-
顺序保证 :确保原子操作相对于其他内存操作的正确顺序。
原子操作单元是SN-F设计中的关键验证难点。
错误处理与可靠性
SN-F是内存可靠性的第一道防线:
-
ECC:在数据写入内存前计算并添加ECC校验位;读出时进行校验和纠错。
-
地址错误:检查访问是否越界。
-
协议错误:检查不支持的请求类型。
-
错误响应 :当检测到错误时,在返回的CHI响应包中设置
RespErr位,并可配置触发中断。
5.2.3 SN-I的设计要点
SN-I通常用于连接简单的、内存映射的IO设备。其设计比SN-F简单得多:
-
轻量级事务管理:OT能力很小。
-
简单的数据缓冲。
-
寄存器访问转换:将CHI读写转换为对设备寄存器的加载/存储。
-
可能不支持原子操作和ECC 。
SN-I的关键在于低延迟 和确定性的访问时序,特别是对于控制寄存器的访问。
5.3 协议转换桥:AXI/ACE到CHI的"翻译官"
这是一个在实践中至关重要的模块,尤其当SoC中混合使用新旧IP时。我们以ACE到CHI桥为例,解析其关键设计。
核心挑战 :ACE是通道化、基于ID的流式协议 ,而CHI是基于数据包、面向事务的协议。桥需要在两个世界之间建立映射。
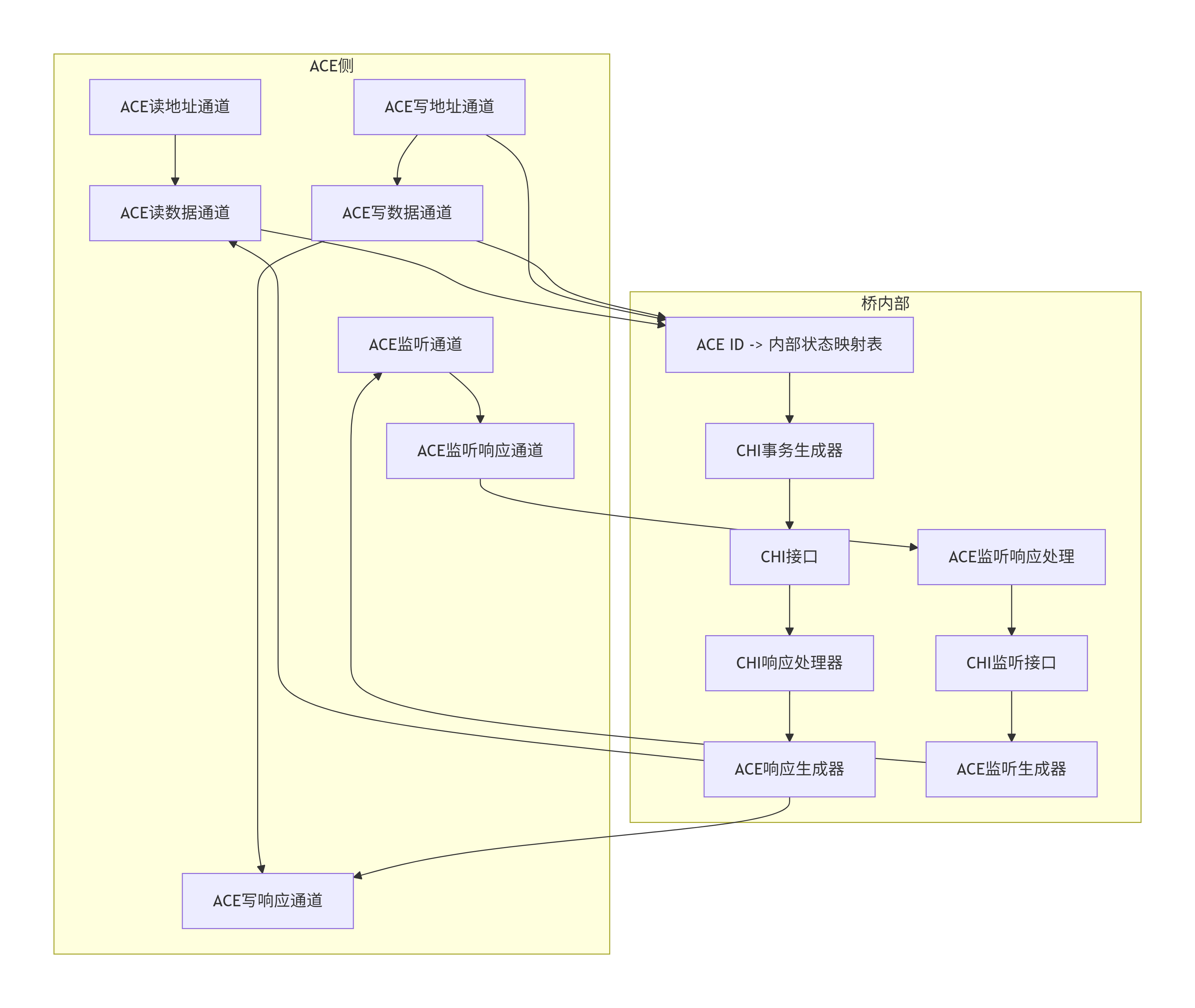
关键设计模块:
-
ID映射表 :将ACE的
ARID/AWID映射到内部分配的CHITxnID。由于ACE允许多个请求乱序返回,桥必须维护这个映射直到事务完成。 -
请求合并与拆分 :ACE可能发起大于缓存行大小的突发传输(Burst)。桥需要将其拆分 为多个CHI缓存行事务。反之,CHI返回的数据需要合并以匹配ACE的突发传输。
-
监听通道转换:这是最复杂的部分。ACE的监听是广播的(到所有ACE端口),而CHI的监听是点对点的。桥需要:
-
将收到的CHI
SnpOnce转换为ACE的AC通道信号。 -
监听ACE的
CR/CD通道,捕获其他ACE端口的监听响应和数据。 -
将ACE的监听响应汇总并转换为CHI的
SnpResp返回给HN。
-
-
排序保证:ACE有严格的排序规则(如相同ID顺序)。桥必须确保即使经过CHI网络,这些顺序仍然被遵守。
性能优化:桥的缓冲区深度和OT能力需要仔细设计,以防止其成为瓶颈。通常,桥的OT数应至少等于所连接ACE主设备的最大OT数。
5.4 RN-F发起请求到收到响应的完整内部数据流
下面,我们通过一个详细的内部数据流图,展示一个CPU读请求在RN-F内部的完整旅程。场景:CPU读地址X,本地L2缓存缺失,数据最终由另一个RN-F提供。
流程解读与设计要点:
-
请求发起:本地缓存未命中触发ACE请求。桥接器是协议转换的关键点。
-
事务跟踪:TxnTracker在请求发出时分配条目,这是后续所有匹配的基石。
-
监听旁路处理:展示了监听过滤器如何工作。即使是一个无关的监听请求(Addr Y),由于过滤器假阳性,仍然触发了缓存查找,增加了功耗和延迟。这凸显了过滤器精度的设计权衡。
-
数据与响应分离 :数据包(
CompData)和完成响应包(Comp)可能分开发送、独立到达。RN-F必须能够处理这种分离,并在收到数据和完成响应后分别采取行动:数据用于满足CPU,完成响应用于释放资源。 -
并发处理:RN-F必须能够同时处理外发请求、传入监听、传入数据/响应,这要求其内部有良好的并发设计和缓冲区管理。
5.5 设计案例:为高性能AI芯片集成RN-I和SN-F
场景:设计一款AI训练芯片,包含32个AI核心,每个核心有本地SRAM,通过一个DMA引擎与4个HBM2E内存栈交互。
RN-I for DMA引擎:
-
需求:DMA需要极高的带宽,持续搬运大块数据(MB级)。
-
设计:
-
深流水线与大OT:TxnTracker支持1024个OT,以保持大量未完成的DMA请求。
-
大数据缓冲区:输入/输出数据缓冲区各为32KB,以吸收网络和内存延迟的波动。
-
简化一致性 :由于AI核心通过SRAM工作,DMA通常操作一致性区域。RN-I配置为支持
ReadOnce和WriteNoSnp,以获取独占访问权,避免后续的监听。 -
带宽优化 :使用512位CHI数据位宽,并启用最大突发传输(MaxBurstLength)配置,让每个CHI请求尽可能搬运更多数据。
-
SN-F for HBM2E控制器:
-
需求:每个HBM2E栈提供高达400GB/s的带宽,访问延迟需要优化。
-
设计:
-
多独立实例:为每个HBM2E控制器配备一个独立的SN-F实例,实现完全并行的访问。
-
智能地址交错 :在系统SAM层面,将AI模型的权重、激活值等数据细粒度交错(如128字节块)映射到4个HBM栈,最大化聚合带宽。
-
高性能调度器 :实现支持Bank Group感知的调度算法,充分利用HBM2E的高Bank并行性。读优先级高于写,但设置写缓冲区高水位线以防止写饥饿。
-
原子操作支持:为分布式训练中的梯度同步(如All-Reduce)提供高效的原子加操作硬件支持。
-
增强的ECC :支持ECC和CRC,并设计错误注入与容错测试接口,以满足高可靠性计算需求。
-
通过为不同角色量身定制RN和SN,我们构建了一个能够满足AI芯片极端性能要求的、高效的数据供给网络。
本章小结 :
我们深入探索了CMN-700网络的"门户"与"终点站"------RN和SN。RN作为请求者的代理,其设计的核心在于协议转换、事务管理和监听处理的平衡;SN作为目标的代理,其核心在于高效、可靠地访问物理内存或设备。理解它们的内部架构和设计权衡,是构建一个均衡、高性能SoC互连的基础。
第六章:数据高速公路:交叉开关(XP)与链路层
6.1 XP的架构本质:一个NxM的非阻塞交换矩阵
欢迎来到CMN-700的"立体交通枢纽"------交叉开关(Crosspoint,简称XP)。如果说RN和SN是城市的社区出入口,HN是市政厅,那么XP就是连接所有社区的高速公路立交桥系统。XP构成了CMN-700 Mesh网络的骨干,数据包在这里被智能地路由和交换,从源头流向目的地。
从本质上看,XP是一个非阻塞的N×M交换矩阵:
-
N个输入端口:可以同时接收来自多个方向的数据流。
-
M个输出端口:可以将数据流导向多个目的地。
-
交换核心:在任意输入和输出端口之间建立临时连接,实现数据包的转发。
"非阻塞"意味着:只要输出端口空闲,任何输入端口的合法数据包都能立即被转发,而不会因为内部资源竞争被阻塞(除了正常的缓冲区管理和仲裁延迟)。这种设计确保了网络的高吞吐量和低延迟。
一个典型的XP在2D Mesh中具有5个双向端口:
-
东(East):连接右侧相邻XP
-
南(South):连接下方相邻XP
-
西(West):连接左侧相邻XP
-
北(North):连接上方相邻XP
-
本地(Local):连接功能节点(RN、HN、SN等)
每个端口既是输入也是输出,形成全双工通信。
6.2 内部微架构:输入缓冲、路由计算、交叉矩阵与输出调度
让我们拆开一个XP,看看这个精密的交通枢纽内部是如何工作的。下图展示了一个典型XP的微架构:
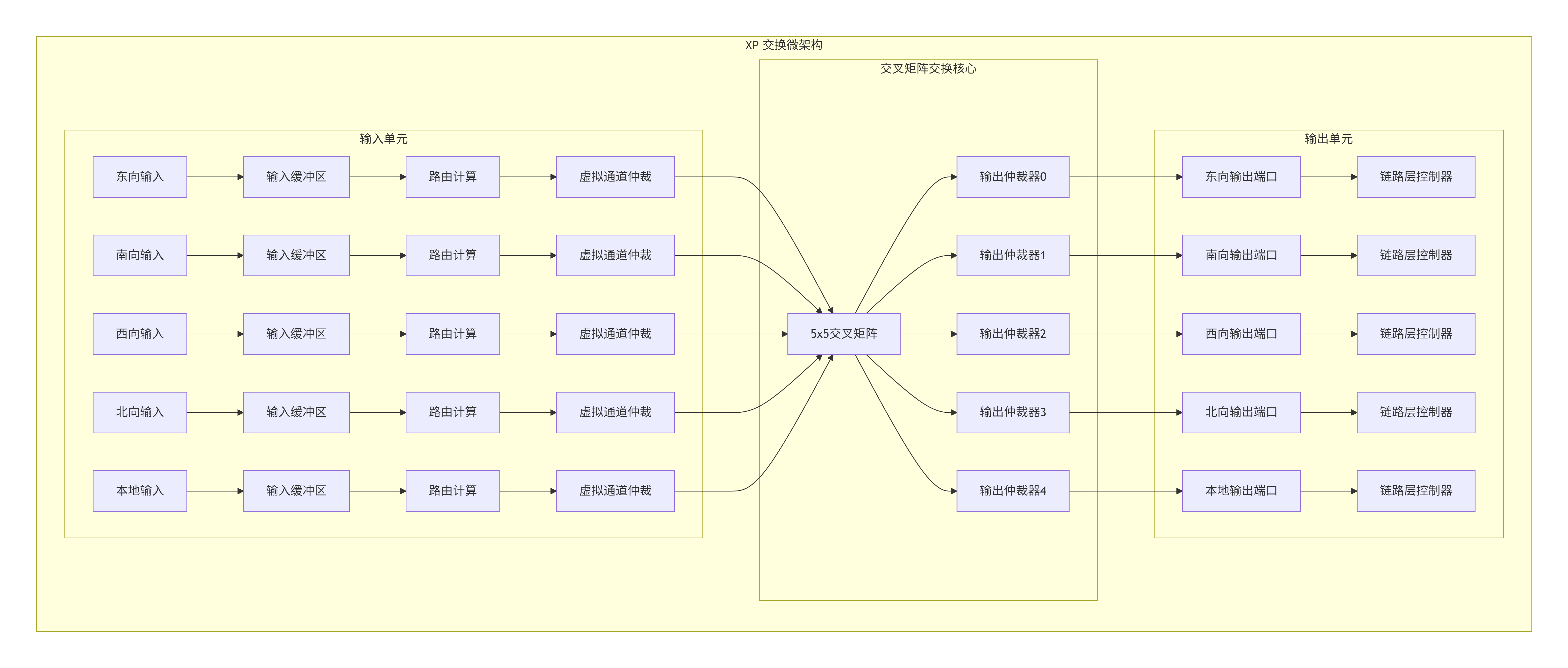
6.2.1 输入缓冲区与虚拟通道分离
当数据包到达XP的输入端口时,首先进入输入缓冲区 。这个缓冲区不是单一的队列,而是按照虚拟通道(Virtual Channel,VC) 分离的多个独立队列。
为什么需要虚拟通道?
考虑这样一个场景:一个请求包在等待数据包返回,而数据包又在等待请求包释放资源,形成协议死锁。虚拟通道通过为不同类型的数据流提供独立的缓冲和传输资源,打破了这种循环依赖。
在CMN-700中,典型的虚拟通道划分包括:
-
VC0:请求通道 - 用于
ReadNoSnp、WriteNoSnp等请求包 -
VC1:响应通道 - 用于
Comp、RespSepData等响应包 -
VC2:数据通道 - 用于
CompData、SnpRespData等数据包 -
VC3:监听通道 - 用于
SnpOnce、SnpClean等监听请求包
每个VC有独立的缓冲队列和信用点管理。一个VC的阻塞不会影响其他VC的数据流。
6.2.2 路由计算:确定前进方向
每个输入端口都有一个路由计算模块 。它的任务很简单:查看数据包的目标节点ID(TgtID),决定应该从哪个输出端口离开当前XP。
XY路由算法示例 :
假设XP位于Mesh坐标(2,3),数据包的目标节点对应的Mesh坐标是(5,1)。
-
先比较X坐标:当前X=2,目标X=5,所以需要向东移动。
-
如果X坐标相同,再比较Y坐标:当前Y=3,目标Y=1,所以需要向南移动。
-
在XY路由中,先水平后垂直。所以当前应该选择东向输出端口。
路由计算通常在数据包进入缓冲区时就完成,结果(输出端口选择)与数据包一起存储在缓冲区中。
高级路由选项:
-
可编程路由表:允许架构师为特定的源1目标对指定路径,绕过故障链路或优化特定流量。
-
自适应路由:根据网络拥塞情况动态选择路径,但实现复杂且可能引起乱序问题。
6.2.3 交叉矩阵仲裁:决定谁先通过
这是XP设计的核心挑战:当多个输入端口的包都想前往同一个输出端口时,谁先通过?这由交叉矩阵仲裁器决定。
两级仲裁架构:
-
虚拟通道级仲裁(每个输入端口内部):
-
同一个输入端口中,不同VC的包可能都想去往不同(或相同)的输出端口。
-
需要决定哪个VC的包参与本轮交叉矩阵竞争。
-
策略:通常基于固定优先级 (如请求>监听>数据>响应)或加权轮询。
-
-
交叉矩阵级仲裁(每个输出端口):
-
来自不同输入端口的包竞争同一个输出端口。
-
需要决定哪个输入端口获胜。
-
策略:Round-Robin (公平)、优先级仲裁 (基于QoS)、年龄优先(等待时间长的优先)。
-
仲裁示例 :
假设东向和本地输入端口的包都想前往北向输出端口。
-
首先,每个输入端口内部选择要竞争的包。
-
然后,北向输出端口的仲裁器比较这两个包:
-
如果采用Round-Robin:上次选了东向,这次就选本地。
-
如果采用优先级:比较包的QoS字段,优先级高的获胜。
-
如果采用年龄优先:比较包在缓冲区中的等待时间。
-
交叉矩阵实现 :
交叉矩阵通常用多路选择器(MUX)树实现。对于5×5的XP,每个输出端口需要一个5:1的MUX。数据位宽可能很大(如256位),所以这些MUX的面积和功耗不容忽视。一些优化技术包括:
-
分时复用:在较低频率下,一个物理交叉矩阵可以分时服务多个虚拟通道。
-
多级交换:对于更大规模的XP,可以使用Clos等多级交换网络来减少交叉点数量。
6.2.4 输出调度与链路层接口
获胜的数据包被传输到输出端口的缓冲区。输出调度器负责:
-
检查下游信用点:确保接收方(下一个XP或功能节点)有足够的缓冲区空间。
-
组装传输单元 :可能需要将数据包拆分为更小的流控制单元(Flit)。
-
驱动物理链路:在正确的时钟周期发送数据。
输出缓冲区的作用:
-
吸收上游(交叉矩阵)和下游(链路)之间的速度不匹配。
-
允许多个包在等待信用点时排队。
-
实现虚拟输出队列(VOQ):为每个输出端口维护独立的队列,避免队头阻塞。
6.3 虚拟通道(VC)设计细节:深度、仲裁与流控
虚拟通道的设计直接影响网络的性能和死锁避免。让我们深入几个关键方面:
6.3.1 VC缓冲区深度设计
每个VC的缓冲区深度需要精心设计:
-
太浅:容易导致拥塞,性能下降,信用点频繁往返增加延迟。
-
太深:增加面积和功耗,且收益递减。
经验法则:
-
请求/监听VC:深度较浅(4-8个条目),因为控制包小,且数量相对较少。
-
数据VC:需要较深(8-16个条目),因为数据包大,且可能有突发传输。
-
响应VC:深度中等(6-10个条目)。
计算方法 :
缓冲区深度应至少覆盖往返延迟(Round-Trip Time, RTT) 期间能到达的数据量。
最小深度 = RTT(周期) × 链路带宽(字节/周期)例如,如果从XP到下一个节点的延迟是2周期,返回信用点的延迟是2周期,总RTT=4周期。链路带宽为32字节/周期(256位),那么最小深度=4×32=128字节。对于一个64字节的缓存行,相当于2个条目。
6.3.2 VC间仲裁策略
同一个输入端口中,多个VC可能有包等待发送。仲裁策略需要考虑:
-
严格优先级:
// 伪代码示例 always_comb begin if (vc0_req_valid) grant = VC0; else if (vc1_req_valid) grant = VC1; else if (vc2_req_valid) grant = VC2; else if (vc3_req_valid) grant = VC3; end-
优点:高优先级包(如CPU读响应)延迟低。
-
缺点:低优先级包可能被"饿死"。
-
-
加权轮询(WRR):
-
每个VC分配一个权重。
-
服务计数器按权重分配服务机会。
-
优点:保证公平性和最小带宽。
-
-
年龄优先:
-
选择等待时间最长的包。
-
优点:最大化公平性,减少最坏情况延迟。
-
缺点:实现复杂,需要跟踪每个包的到达时间。
-
CMN-700的典型配置:结合QoS字段和固定优先级。包的QoS值影响其在VC内部和交叉矩阵仲裁中的优先级。
6.3.3 基于信用点的流控机制
信用点流控是保证无数据丢失的关键。工作流程如下:
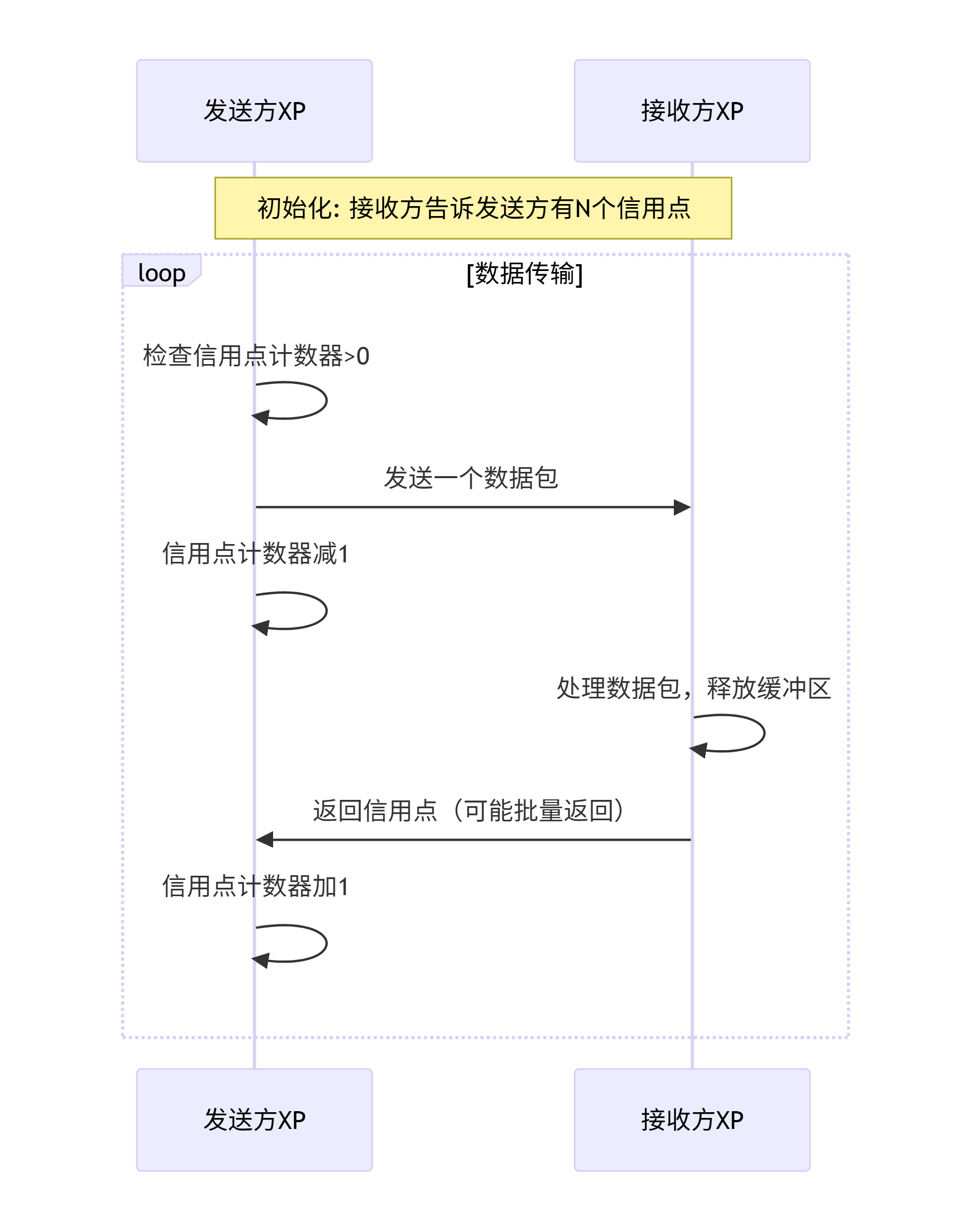
信用点返回策略:
-
每个包返回一个信用点:简单但开销大。
-
累积信用点:积累一定数量或时间后返回,减少控制流量。
-
基于计数器的信用点:接收方定期发送当前可用缓冲区数量。
设计要点:
-
信用点计数器需要足够位宽,防止溢出。
-
信用点返回路径必须有足够带宽,避免成为瓶颈。
-
需要考虑错误情况下的信用点恢复(如链路重训练)。
6.4 物理链路层实现:时序、功耗与可靠性
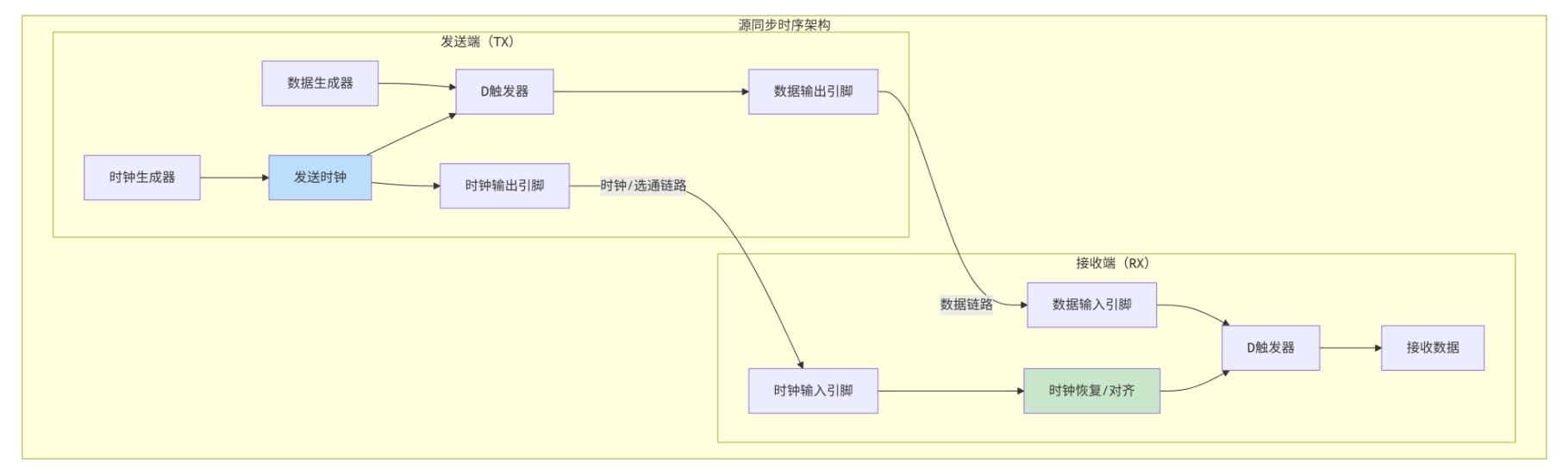
6.4.1 源同步时序架构
CMN-700通常采用源同步时序:
-
发送方在发送数据的同时,发送一个随路时钟(或选通信号)。
-
接收方用这个时钟采样数据。
-
优点:避免全局时钟偏移问题,支持更高频率。
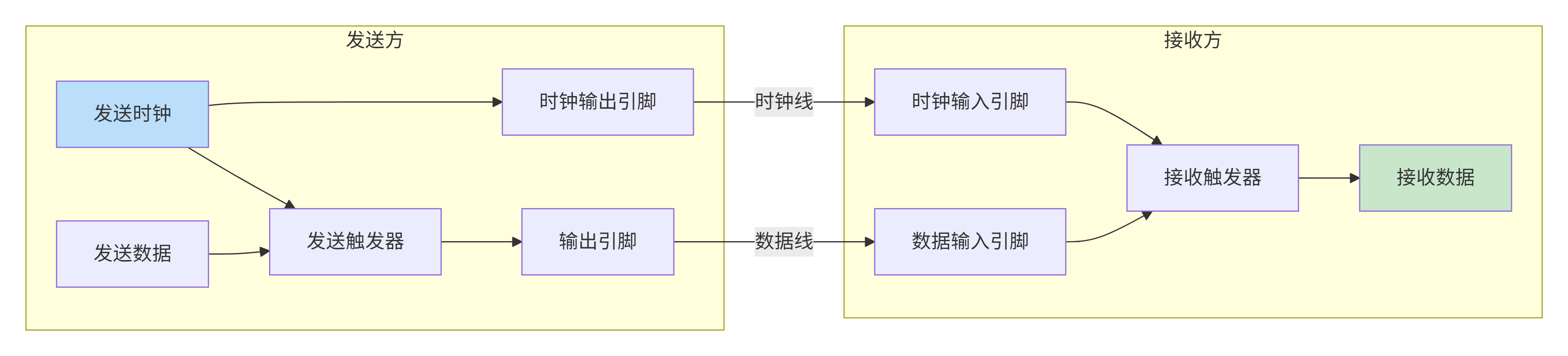
时序约束:
-
时钟和数据线需要长度匹配,保证同时到达。
-
需要占空比校正,因为高频时钟占空比可能失真。
-
可能需要多相位采样,以增加时序裕量。
6.4.2 链路宽度与频率权衡
链路设计需要在带宽、面积、功耗之间权衡:
| 配置 | 数据位宽 | 典型频率 | 单方向带宽 | 优点 | 缺点 |
|---|---|---|---|---|---|
| 窄高频 | 128位 | 3.0 GHz | 48 GB/s | 布线简单,时钟树小 | 时序难,功耗高 |
| 宽中频 | 256位 | 2.0 GHz | 64 GB/s | 平衡性好 | 布线资源中等 |
| 超宽低频 | 512位 | 1.0 GHz | 64 GB/s | 时序宽松,电压可降低 | 布线拥塞,面积大 |
选择建议:
-
高性能设计:256位@2GHz是甜点。
-
面积敏感设计:128位@2.5GHz。
-
跨芯片连接:可能需要串行链路(SerDes)。
6.4.3 功耗优化技术
-
时钟门控:
-
当链路空闲时,关闭发送器和接收器的时钟。
-
细粒度门控:甚至可以按字节通道单独门控。
-
-
电源门控:
-
在深度睡眠状态,关闭整个链路电源。
-
需要保持寄存器保存状态。
-
-
自适应电压频率缩放(AVFS):
-
根据链路利用率动态调整电压和频率。
-
需要复杂的控制器和电压域划分。
-
-
数据编码:
-
使用总线反转编码减少跳变次数。
-
例如,如果下一周期数据跳变超过一半,就发送反码并附加一个反转标志位。
-
6.4.4 可靠性特性
-
奇偶校验:
-
每个数据包添加奇偶校验位。
-
检测单比特错误。
-
-
前向纠错(FEC):
-
对于关键链路(如跨芯片),使用ECC编码。
-
可以纠正单比特错误,检测多比特错误。
-
-
链路训练与校准:
-
上电时发送训练序列。
-
接收方调整采样相位找到最佳眼图中心。
-
定期重校准以补偿温度电压变化。
-
-
重试机制:
-
检测到错误时,请求重发。
-
需要发送方保留副本直到确认。
-
6.5 性能与面积权衡:如何确定XP的规格?
设计XP时,你需要做出一系列关键决策:
6.5.1 设计决策清单
-
端口数量:
-
2D Mesh:5端口(东南西北+本地)
-
3D Mesh:7端口(增加上下)
-
带旁路端口:6端口(增加快速通道)
-
-
数据位宽:
-
基于带宽需求计算:
位宽 = 所需带宽 / (频率 × 利用率) -
例如:需要64GB/s,频率2GHz,利用率80% →
位宽 = 64e9×8 / (2e9×0.8) = 320位,取整为256或512位。
-
-
虚拟通道配置:
-
数量:通常4个(Req, Rsp, Data, Snoop)
-
深度:根据RTT计算,考虑最坏情况拥塞
-
-
仲裁策略:
-
VC内部:固定优先级+老化机制
-
交叉矩阵:Round-Robin with QoS权重
-
-
流水线级数:
-
典型:输入缓冲(1级)、路由计算(1级)、VC仲裁(1级)、交叉矩阵(1级)、输出调度(1级)→ 总共5级流水
-
高频设计可能需要更深流水
-
6.5.2 面积估算模型
XP的面积主要来自:
-
输入缓冲区 :
面积 = 端口数 × VC数 × 缓冲区深度 × 位宽 × 存储单元面积 -
交叉矩阵 :
面积 ≈ 端口数² × 位宽 × MUX单元面积 -
控制逻辑:仲裁器、路由计算、信用点管理等
示例计算 :
假设5端口、4VC、8条目深度、256位宽:
-
缓冲区:
5 × 4 × 8 × 256b = 40,960b = 5KBSRAM -
交叉矩阵:
5×5 × 256b MUX ≈ 6,400个等效门 -
控制逻辑:约10K门
-
总计:约0.1 mm² @ 7nm(估算)
6.5.3 性能评估指标
-
吞吐量:
-
理想:每个周期每个端口都能传输数据
-
实际:受仲裁、拥塞影响,通常达到70-90%理想值
-
-
延迟:
-
零负载延迟:数据包穿过XP的最小周期数(通常3-5周期)
-
饱和延迟:网络拥塞时的延迟
-
-
公平性:
-
Jain's Fairness Index:衡量不同流量是否获得公平服务
-
饥饿检测:确保低优先级流量不会被无限期阻塞
-
6.6 XP内部数据包从输入到输出的多VC竞争与仲裁流程
下面通过一个详细的时序图,展示两个数据包在XP内部竞争同一输出端口的完整流程:
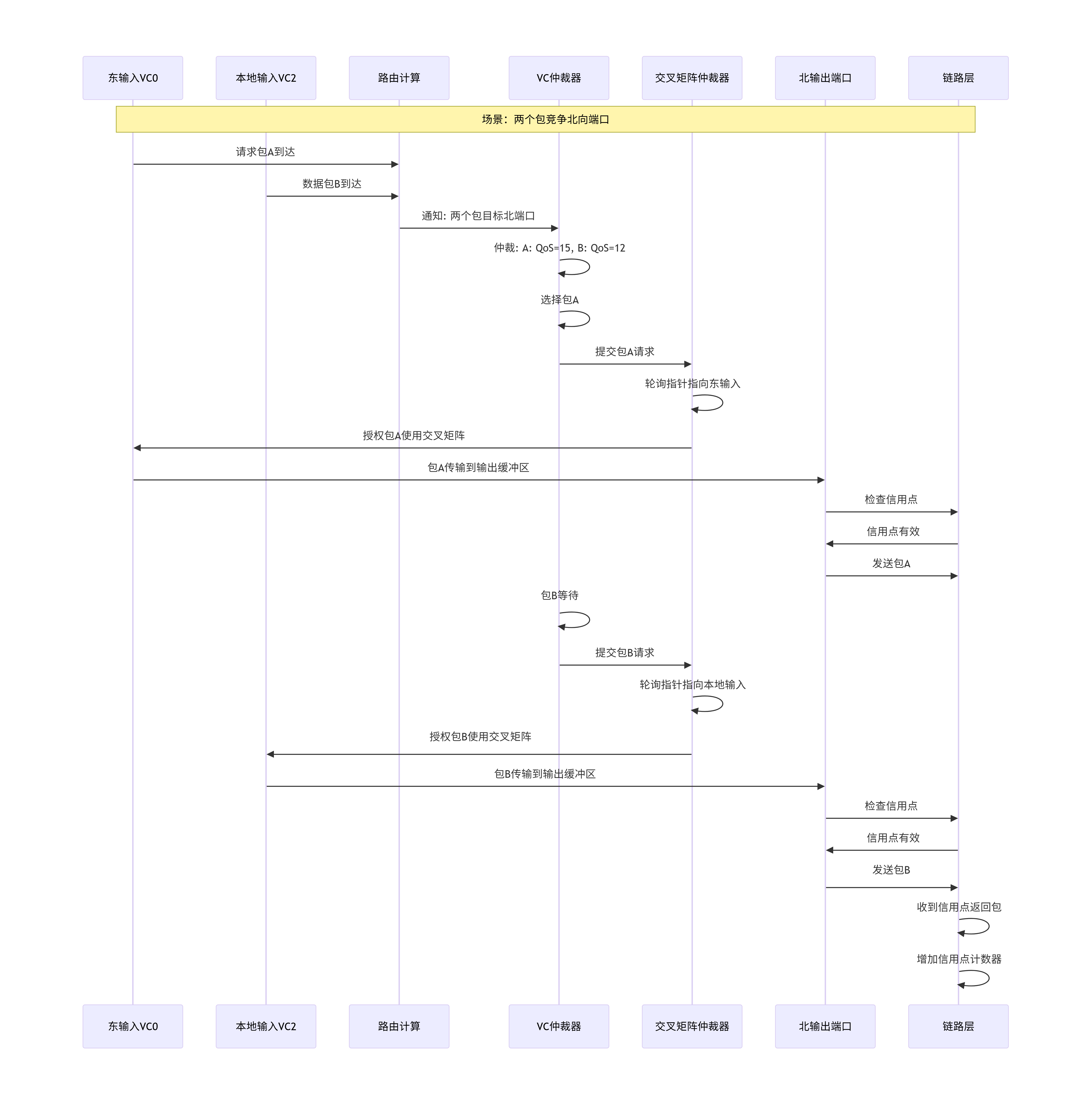 关键设计要点:
关键设计要点:
-
流水线操作:注意各个阶段是流水线化的。当包A在周期3传输时,包B已经在周期2完成了路由计算,周期4就可以开始仲裁。理想情况下,每个周期都能开始一个新的传输。
-
仲裁策略组合:
-
VC内部:基于QoS和等待时间的混合策略,确保高优先级和公平性。
-
交叉矩阵:Round-Robin保证基本公平,避免饥饿。
-
-
信用点同步:信用点检查发生在传输之前,如果信用点不足,传输会被暂停,直到信用点返回。这需要仔细设计信用点返回的延迟,避免性能下降。
-
输出缓冲区作用:输出缓冲区允许交叉矩阵传输和链路层发送解耦。即使链路暂时忙,交叉矩阵仍然可以完成传输,将数据暂存在输出缓冲区。
-
轮询指针维护:每个输出端口的仲裁器维护自己的轮询指针,确保公平性。指针更新策略(如仅在授权后更新)影响公平性。
6.7 设计实例:为数据中心芯片优化XP设计
场景:设计一个面向云数据中心的高性能SoC,具有以下特点:
-
64个CPU核心,16个内存控制器
-
Mesh网络规模:8×8
-
目标频率:2.5GHz
-
要求:高带宽、低延迟、良好的多租户隔离
XP设计决策:
-
端口配置:标准5端口(东、南、西、北、本地)
-
数据位宽:512位
-
计算:目标聚合带宽 > 1TB/s
-
单链路带宽 = 512b × 2.5GHz = 160GB/s(理论)
-
实际考虑:编码开销、利用率 → 约120GB/s有效
-
8×8 Mesh有大量并行链路,可满足总带宽需求
-
-
虚拟通道配置:
-
增加两个VC用于多租户隔离:
-
VC0: 租户A请求
-
VC1: 租户B请求
-
VC2: 租户A响应
-
VC3: 租户B响应
-
VC4: 数据(共享)
-
VC5: 监听(共享)
-
-
深度:请求VC=8,响应VC=8,数据VC=16,监听VC=8
-
-
仲裁策略:
-
VC内部:严格优先级 + 每VC最小带宽保证
-
交叉矩阵:基于租户QoS的加权轮询
-
支持突发优先:长突发传输获得连续授权,减少开销
-
-
高级特性:
-
可编程路由表:支持流量工程,可以将特定租户的流量导向特定路径
-
拥塞感知路由:轻量级拥塞检测,避免热点
-
细粒度功耗管理:每链路独立DVFS,根据利用率调整
-
-
可靠性增强:
-
端到端CRC,每跳奇偶校验
-
关键路径上的ECC保护
-
链路故障检测和自动绕行
-
面积估算:
-
每个XP约0.25 mm² @ 7nm
-
8×8 Mesh需要64个XP → 约16 mm²
-
占总芯片面积的~5%,可接受
性能验证 :
通过仿真验证在合成工作负载下的表现:
-
零负载延迟:4周期/跳
-
饱和吞吐量:达到理论值的85%
-
公平性指数:>0.9(良好)
-
最坏情况延迟:可预测,满足服务质量协议(SLA)
这个设计展示了如何针对特定应用场景定制XP的各个方面,在性能、面积和功能之间取得最佳平衡。
本章小结 :
我们深入探索了CMN-700的"高速公路系统"------交叉开关(XP)与链路层。XP作为网络的核心交换单元,其非阻塞架构、虚拟通道分离和智能仲裁机制确保了数据包的高效转发。链路层的信用点流控和物理实现保证了可靠的数据传输。通过精心设计XP的规格和策略,我们可以构建出适应各种应用需求的片上网络。
第七章:城市监控中心:监控节点(MN)与调试追踪
7.1 MN的功能总览:性能分析、事件追踪、系统控制
在CMN-700这座片上网络"城市"中,监控节点(Mesh Network,MN) 扮演着"城市监控中心"的角色。它不像其他节点那样直接参与数据传输,而是像一个无处不在的观察者和协调者,为架构师和软件工程师提供了一双洞察系统内部运作的"眼睛"和一只进行精细调控的"手"。
MN的核心使命三重奏:
-
性能分析:实时收集和分析网络流量、延迟、带宽利用率等关键指标,帮助发现瓶颈。
-
事件追踪:捕获协议事务的完整生命周期,为复杂问题的调试提供详细线索。
-
系统控制:作为配置接口,初始化并动态调整CMN-700的运行参数。
MN在SoC中的典型部署
MN通常作为Mesh网络中的一个特殊节点连接,其位置选择对监控效果有重要影响:
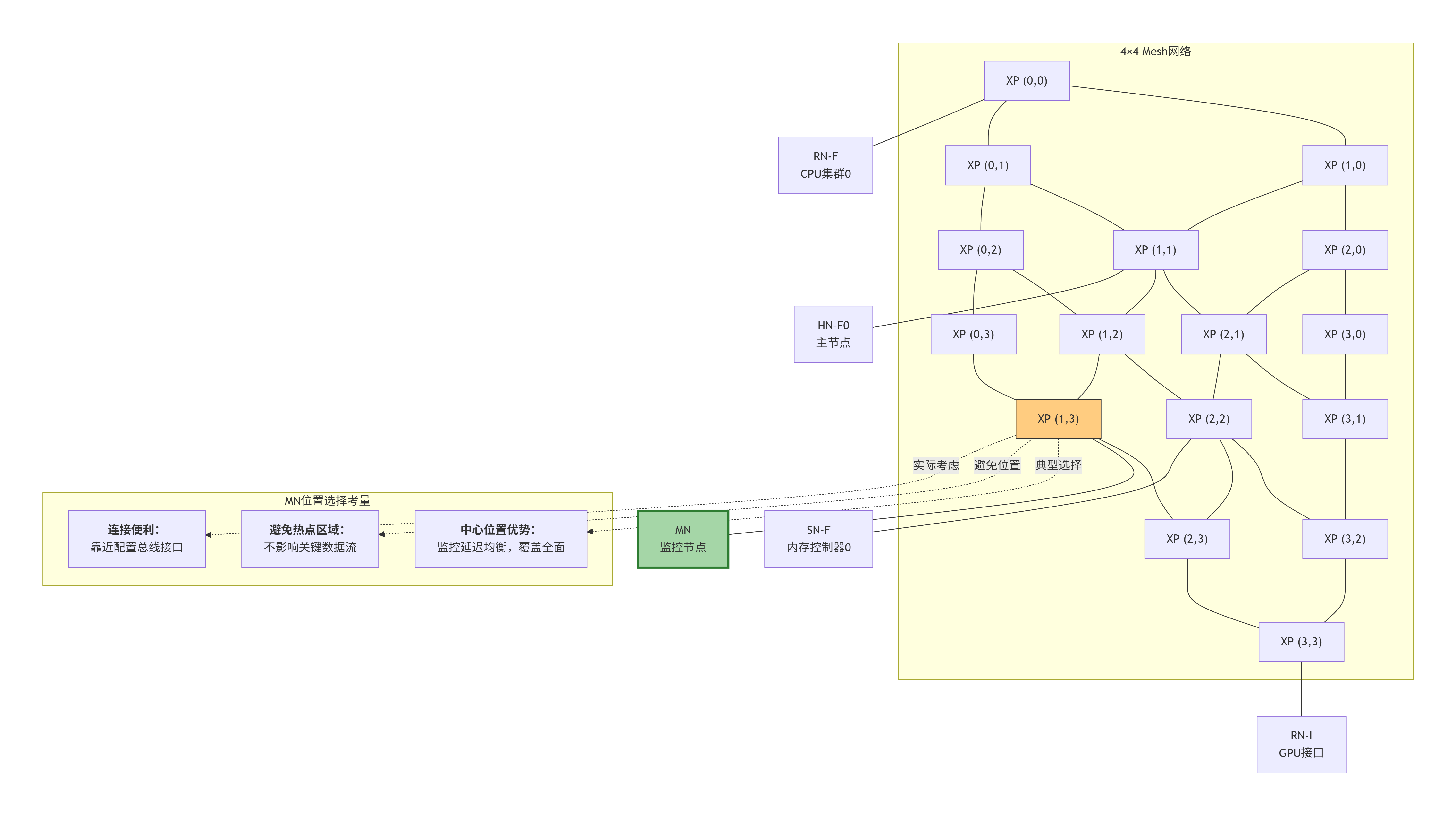
位置选择策略:
-
中心化放置(如图中XP1,3):监控延迟均衡,能观测全网流量
-
靠近配置接口:方便软件通过APB总线访问
-
避免关键路径:不放在CPU集群与HN之间等高流量路径上
7.2 性能监测单元(PMU)实现
7.2.1 可计数事件:为每个关键指标装上"传感器"
CMN-700的PMU支持数百种可计数事件,这些事件像遍布城市的传感器,实时报告各个角落的状况。事件分为几个大类:
| 事件类别 | 具体事件示例 | 监控目的 | 典型配置 |
|---|---|---|---|
| 带宽相关 | XP0_EAST_IN_BYTES HN0_REQ_RECEIVED |
测量链路和节点吞吐量 | 每10ms采样一次 |
| 延迟相关 | RN0_READ_LATENCY HN0_DIR_ACCESS_CYCLES |
识别性能瓶颈 | 累积分布直方图 |
| 流量特征 | REQ_TYPE_READNOSNP SNP_TYPE_SNPONCE |
了解工作负载类型 | 分类计数器 |
| 资源利用率 | XP0_VC0_BUFFER_FULL HN0_MBU_OCCUPANCY |
发现资源争用 | 阈值触发中断 |
| 错误与异常 | PARITY_ERROR_COUNT PROTOCOL_VIOLATION |
系统健康监控 | 实时警报 |
事件选择与分组 :
每个计数器可以编程为监控特定事件。为了高效使用有限的硬件计数器,MN支持事件多路复用 和分组计数:
// PMU计数器配置寄存器示例
typedef struct packed {
logic [7:0] event_select; // 选择监控的事件
logic enable; // 计数器使能
logic [1:0] node_filter; // 节点过滤器:00=全部,01=RN,10=HN,11=SN
logic [3:0] qos_filter; // QoS过滤器:仅监控特定QoS域
logic edge_detect; // 边沿检测 vs 电平检测
} pmu_counter_config_t;
// 事件选择编码示例
localparam EVENT_XP_IN_BYTES = 8'h01;
localparam EVENT_XP_OUT_BYTES = 8'h02;
localparam EVENT_HN_REQ_COUNT = 8'h10;
localparam EVENT_HN_SNOOP_COUNT = 8'h11;
localparam EVENT_RN_LATENCY = 8'h20;7.2.2 分布式计数器架构:从本地计数到全局汇聚
由于CMN-700规模庞大,PMU采用分布式-集中式混合架构:
收集策略:
-
定期推送:每个本地PMU每隔N个周期将计数值发送给MN
-
按需轮询:MN主动读取特定节点的计数器
-
事件触发:当计数值达到阈值时自动报告
硬件实现细节:
-
本地计数器:每个节点有4-8个32位计数器,由轻量级PMU管理
-
网络开销:计数器数据被封装为特殊的CHI监控包,使用专用VC避免干扰正常流量
-
时间同步:所有本地计数器使用MN广播的全局时间戳同步
7.2.3 中断生成与阈值管理
PMU不仅能计数,还能在检测到异常时主动告警:
阈值寄存器配置:
// 阈值配置示例
pmu_threshold_config_t threshold_cfg;
threshold_cfg.counter_id = 5; // 监控HN0的请求队列深度
threshold_cfg.threshold_value = 48; // 阈值:队列深度48(75%)
threshold_cfg.direction = 1; // 1=超过阈值触发,0=低于阈值触发
threshold_cfg.debounce_cycles = 100;// 防抖:持续100周期才触发
threshold_cfg.interrupt_enable = 1; // 使能中断
threshold_cfg.interrupt_id = 3; // 中断ID=3
// 写入MN配置寄存器
mn_write_config(PMU_THRESHOLD_REG, threshold_cfg);中断处理流程:
1. HN0请求队列深度达到49(>阈值48)
2. HN0本地PMU检测到阈值超限
3. 等待100周期确认(防抖)
4. 发送中断事件包给MN
5. MN设置中断状态寄存器位
6. MN通过中断控制器向CPU发出中断
7. CPU读取MN的中断状态寄存器,确认是计数器5触发
8. CPU读取计数器5的值和相关信息
9. 执行中断处理程序(如动态调整QoS、记录日志等)
10. 清除中断状态7.3 追踪单元(Trace Unit)设计:捕获片上网络的"思维流"
如果说PMU是"心电图机",记录系统的总体健康指标,那么追踪单元就是"脑电图机",捕捉每一次"思维活动"(协议事务)的完整轨迹。
7.3.1 追踪数据源与过滤机制
CMN-700的追踪单元可以从多个源头捕获数据:
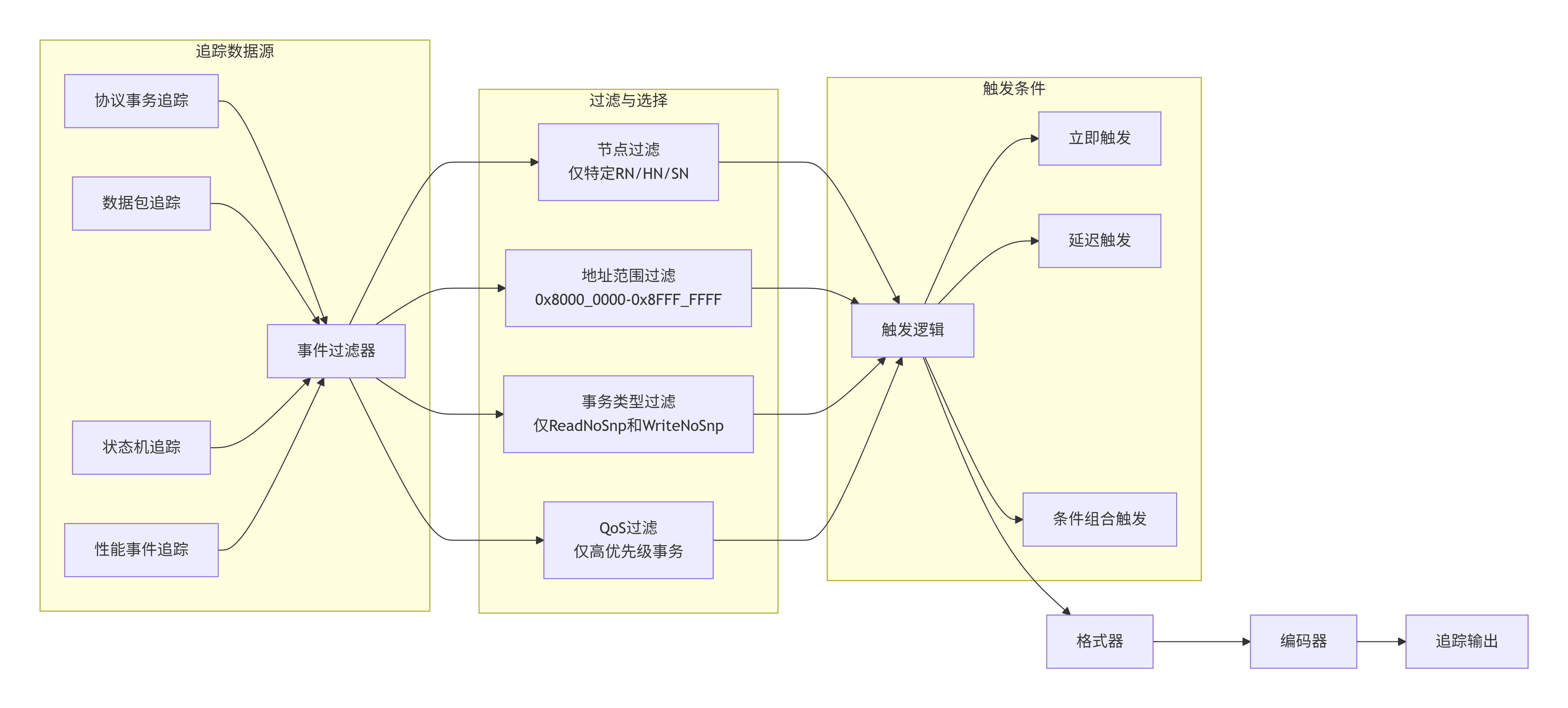
高级触发条件示例:
// 复杂触发条件:捕获特定竞争场景
TRIGGER_CONDITION =
(事务类型 == ReadNoSnp) &&
(目标地址 == 0x8000_1234) &&
(时间窗口内有另一个WriteNoSnp到相同地址) &&
(两个请求来自不同的RN-F) &&
(间隔时间 < 100周期)
// 这将帮助调试缓存一致性问题7.3.2 追踪数据格式与压缩
追踪数据量极大(每个事务可能产生几十字节的追踪数据),因此需要高效的格式和压缩:
基本追踪记录格式:
| 字段 | 位宽 | 描述 |
|------|------|------|
| 时间戳 | 48位 | 全局同步时间戳 |
| 节点ID | 8位 | 产生事件的节点 |
| 事件类型 | 4位 | 请求/响应/数据/监听等 |
| 事务ID | 8位 | CHI事务ID |
| 地址 | 48位 | 物理地址(部分) |
| 状态信息 | 16位 | 缓存状态、QoS等 |
| 数据摘要 | 32位 | 数据的CRC或哈希 |压缩技术:
-
差分编码:只记录变化的字段
-
字典压缩:常见模式(如特定事务序列)用短编码表示
-
运行长度编码:重复事件压缩
-
选择性追踪:只记录满足条件的事件
压缩示例:
未压缩:3个连续的ReadNoSnp请求
[时间T, RN0, ReadNoSnp, TxnA, AddrX, ...]
[时间T+2, RN0, ReadNoSnp, TxnB, AddrX+64, ...]
[时间T+4, RN0, ReadNoSnp, TxnC, AddrX+128, ...]
压缩后:
[时间T, RN0, ReadNoSnp, TxnA, AddrX, 计数=3, 步长=64]7.3.3 追踪缓冲区管理与输出接口
追踪数据需要在片上缓冲,然后通过专用接口输出:
缓冲区层次结构:
1. 节点级小缓冲区(每个节点2-4KB)
- 临时存储本地事件
- 初步过滤和格式化
2. MN级大缓冲区(64-256KB)
- 集中存储来自各节点的事件
- 排序和去重(相同事件多个节点报告)
- 进一步压缩
3. 系统级追踪缓冲区(可选,外部DRAM)
- 长期存储,支持深度追踪
- 软件可访问分析输出接口选项:
| 接口类型 | 带宽 | 用途 | 复杂度 |
|---|---|---|---|
| JTAG | 低(~10MB/s) | 硅后调试 | 低,标准接口 |
| SerDes | 高(1-10GB/s) | 实时性能分析 | 高,需要专用引脚 |
| PCIe | 中高(1-5GB/s) | 系统集成调试 | 中,复用现有接口 |
| 内存映射 | 可变 | 软件访问追踪数据 | 低,但占用内存带宽 |
环形缓冲区管理:
module trace_buffer #(
parameter DEPTH = 16384, // 16K条目
parameter WIDTH = 64 // 64位/条目
)(
input clk, reset,
input write_en,
input [WIDTH-1:0] trace_data,
input read_en,
output [WIDTH-1:0] trace_out,
output logic full,
output logic empty,
output logic [15:0] occupancy
);
logic [WIDTH-1:0] buffer [0:DEPTH-1];
logic [14:0] write_ptr, read_ptr; // 15位支持32K
logic [15:0] count;
always_ff @(posedge clk) begin
if (reset) begin
write_ptr <= '0;
read_ptr <= '0;
count <= '0;
end else begin
// 写操作
if (write_en && !full) begin
buffer[write_ptr] <= trace_data;
write_ptr <= write_ptr + 1;
count <= count + 1;
end
// 读操作
if (read_en && !empty) begin
trace_out <= buffer[read_ptr];
read_ptr <= read_ptr + 1;
count <= count - 1;
end
// 循环指针处理
if (write_ptr == DEPTH) write_ptr <= '0;
if (read_ptr == DEPTH) read_ptr <= '0;
end
end
assign full = (count == DEPTH);
assign empty = (count == 0);
assign occupancy = count;
endmodule7.4 配置与控制接口:通过MN编程整个CMN-700
MN是所有配置和控制操作的单一入口点,软件通过它"指挥"整个CMN-700交响乐团。
7.4.1 配置寄存器映射
MN内部的寄存器通过标准APB(Advanced Peripheral Bus)总线暴露给软件:

关键配置寄存器示例:
// MN全局控制寄存器
typedef struct {
uint32_t enable : 1; // CMN-700使能
uint32_t soft_reset : 1; // 软复位
uint32_t low_power_mode : 2; // 低功耗模式
uint32_t qos_enable : 1; // QoS使能
uint32_t parity_check : 1; // 奇偶校验使能
uint32_t reserved : 26;
} mn_global_ctrl_t;
// HN配置寄存器(每个HN一组)
typedef struct {
uint32_t directory_size : 16; // 目录条目数
uint32_t directory_ways : 4; // 目录相连度
uint32_t mbu_entries : 4; // MBU条目数
uint32_t snoop_filter_enable : 1; // 监听过滤器使能
uint32_t atomic_unit_enable : 1; // 原子操作单元使能
uint32_t reserved : 6;
} hn_config_t;
// QoS配置寄存器
typedef struct {
uint32_t priority_levels : 4; // 支持的优先级数
uint32_t default_qos : 4; // 默认QoS值
uint32_t rn_qos_map[8]; // RN QoS映射表
uint32_t hn_qos_weight[4]; // HN QoS权重
} qos_config_t;7.4.2 配置分发机制
当软件写入MN的配置寄存器后,MN需要将这些配置分发到各个节点:
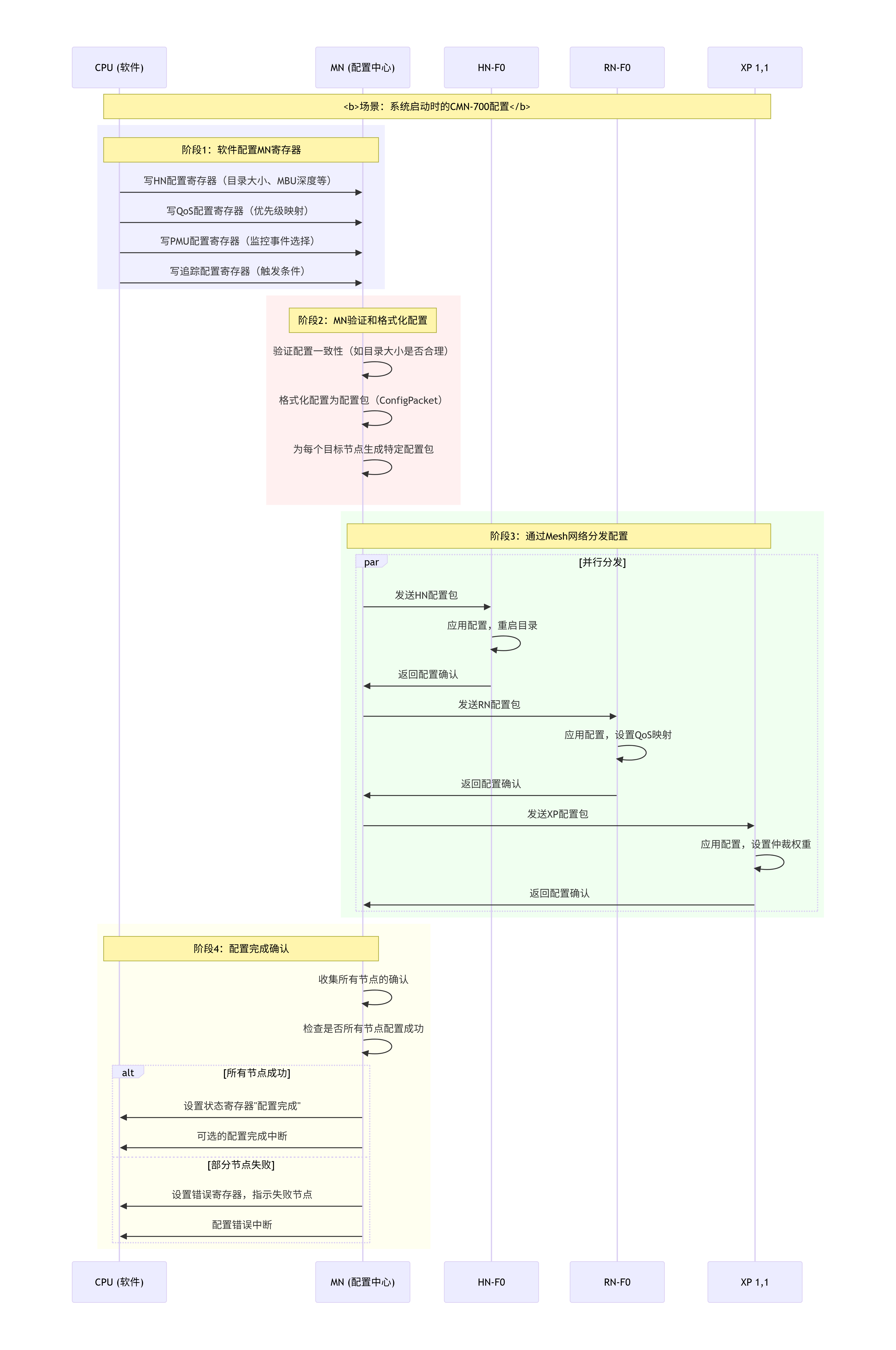
配置包格式:
配置包头:
| 字段 | 位宽 | 描述 |
|------|------|------|
| 目标节点ID | 8位 | 配置发送的目标节点 |
| 配置类型 | 4位 | HN配置/RN配置/XP配置等 |
| 配置版本 | 4位 | 配置数据结构版本 |
| 序列号 | 16位 | 用于确认和重试 |
| 配置数据长度 | 16位 | 后续配置数据的字节数 |
配置数据:
根据配置类型不同而不同,如:
- HN配置:目录参数、MBU深度、监听过滤器大小等
- RN配置:QoS映射表、TxnTracker深度、缓冲区大小等
- XP配置:VC深度、仲裁权重、链路宽度等7.4.3 动态重配置支持
CMN-700支持运行时动态重配置,以适配工作负载变化:
动态重配置场景:
-
工作负载切换:从CPU密集型切换到GPU密集型
-
功耗管理:进入低功耗模式,降低频率和电压
-
错误恢复:绕过故障节点,重新路由
-
性能优化:根据监控数据调整QoS权重
安全的重配置流程:
1. 软件向MN发送重配置请求
2. MN暂停受影响节点的新事务接收
3. MN等待受影响节点的所有进行中事务完成
4. MN发送新的配置包
5. 节点应用新配置,内部状态机重置
6. 节点报告重配置完成
7. MN恢复节点的事务接收
8. MN向软件报告重配置完成7.5 调试支持:从硅前验证到硅后调试
7.5.1 硅前验证基础设施
在设计阶段,MN提供了丰富的验证钩子(hooks):
| 验证特性 | 用途 | 实现方式 |
|---|---|---|
| 协议检查器 | 检测CHI协议违规 | 每个节点内嵌检查器,违规时报告MN |
| 死锁检测 | 检测系统死锁 | 超时计数器,长时间无进展触发 |
| 覆盖率监控 | 验证激励覆盖度 | 标记关键状态转换,统计覆盖率 |
| 断言支持 | 验证设计属性 | 可编程断言,违反时中断仿真 |
| 随机错误注入 | 测试错误恢复 | 可控地注入奇偶错误、协议错误等 |
错误注入示例:
// 错误注入控制寄存器
typedef struct {
logic [7:0] error_type; // 错误类型:0=奇偶错误,1=协议错误等
logic [15:0] target_node; // 目标节点ID
logic [31:0] error_time; // 注入时间(周期数)
logic [7:0] error_rate; // 错误率(0-255/255)
logic auto_recover; // 是否自动恢复
} error_injection_ctrl_t;
// 通过MN配置错误注入
error_injection_ctrl_t err_ctrl;
err_ctrl.error_type = 0; // 奇偶错误
err_ctrl.target_node = 0x10; // HN0
err_ctrl.error_time = 100000; // 在100,000周期后注入
err_ctrl.error_rate = 128; // 50%概率
err_ctrl.auto_recover = 1; // 自动恢复
mn_write_config(ERROR_INJECT_REG, err_ctrl);7.5.2 硅后调试接口
芯片生产出来后,MN通过标准调试接口支持硅后调试:
JTAG调试链:
JTAG TAP控制器 → MN调试模块 → 各节点调试接口
支持的调试操作:
1. 扫描链访问:读取/写入任意节点的内部状态
2. 断点设置:在特定事务或地址设置断点
3. 单步执行:逐步执行协议状态机
4. 追踪捕获:通过JTAG输出追踪数据
5. 错误状态读取:读取错误寄存器和日志系统调试模式:
1. 功能模式:正常操作,带监控
2. 调试模式:暂停正常操作,允许深度检查
3. 制造测试模式:扫描链测试,BIST执行
4. 安全模式:受限访问,防止恶意调试7.5.3 性能分析方法论
MN收集的数据需要正确的分析方法才能转化为洞察:
性能分析工作流:
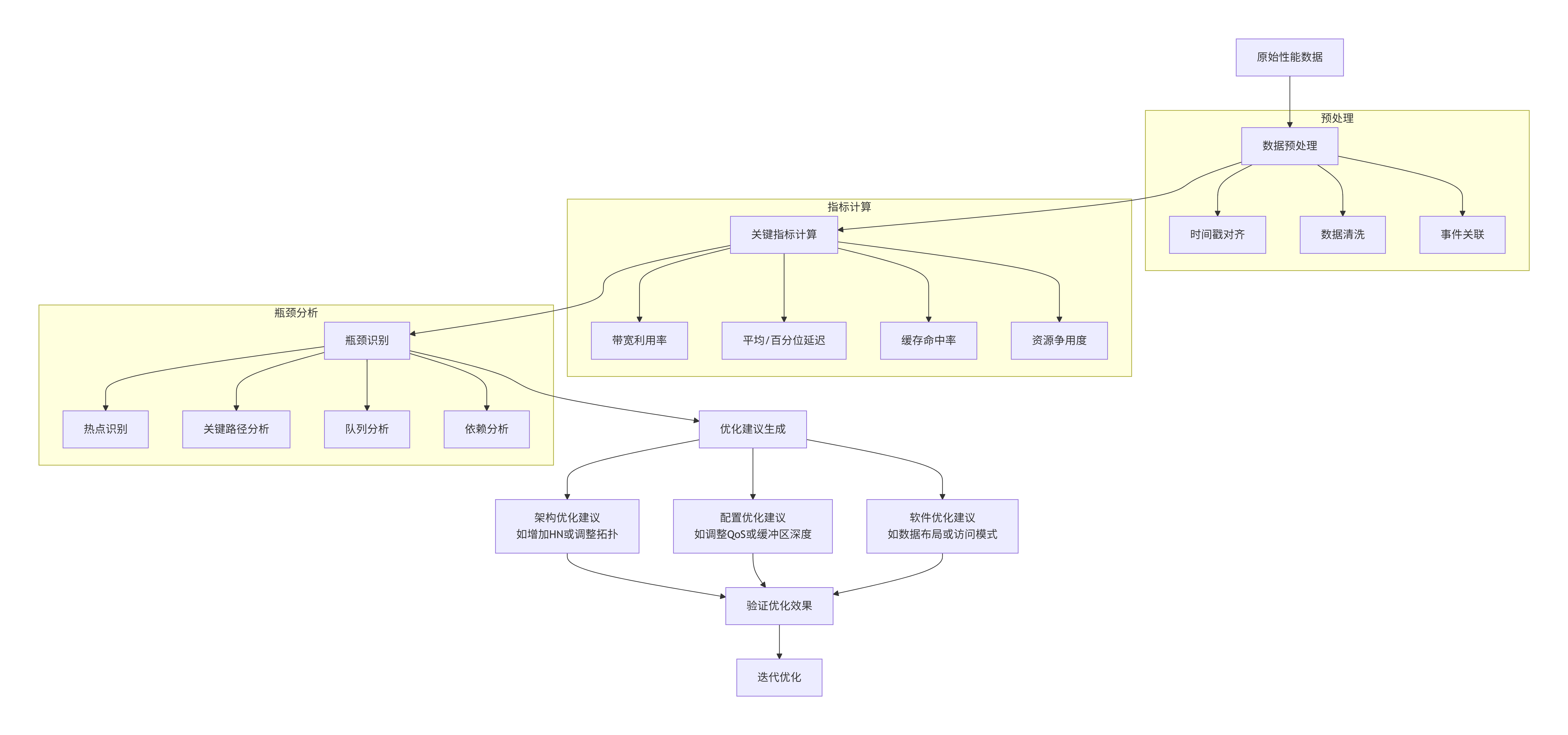
实际案例分析:
问题现象:某AI推理芯片在批量处理图片时,吞吐量低于预期。
MN数据分析:
1. PMU数据显示:SN-F(内存控制器)利用率达到95%,但HN利用率只有40%
2. 追踪数据显示:大量GPU的ReadOnce请求需要访问内存
3. 延迟分析:内存访问延迟是预期的1.5倍
根本原因:
- GPU以ReadOnce方式读取权重数据,每次都会使CPU缓存无效
- CPU需要频繁重新加载数据,导致缓存颠簸
- 内存控制器成为瓶颈
解决方案(通过MN重配置):
1. 调整GPU的QoS映射,降低ReadOnce优先级
2. 为权重数据分配专用SLC区域
3. 启用预测性预取,减少内存访问
结果:吞吐量提升35%,内存控制器利用率降至75%7.6 MN通过追踪总线收集全网事件的架构
下面是一个完整的MN追踪收集系统架构图,展示了从事件产生到最终输出的完整数据流:
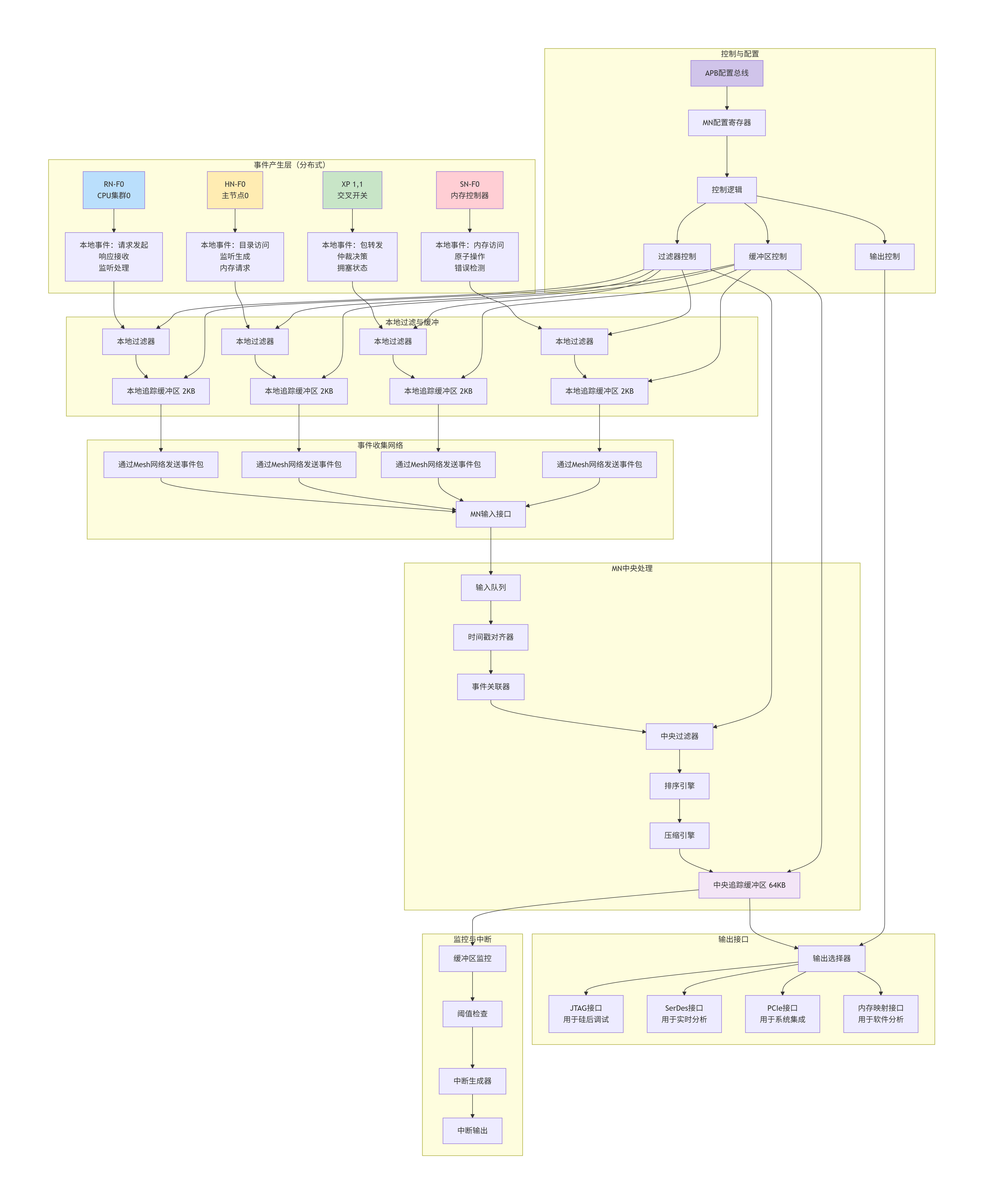
7.7 设计实例:为自动驾驶SoC设计安全关键的MN
场景:设计一款面向L4级自动驾驶的域控制器SoC,CMN-700需要满足ASIL-D功能安全等级。
MN安全增强设计:
安全监控特性
-
双核锁步监控:
主MN:正常操作 影子MN:完全相同的配置,并行监控 比较器:比较两个MN的输出,不一致则报错 -
完整性检查:
// 关键数据的CRC保护 typedef struct { logic [63:0] data; logic [15:0] crc16; } protected_data_t; // 每次读写都验证CRC always_ff @(posedge clk) begin if (write_en) begin buffer[addr] <= {data, compute_crc16(data)}; end if (read_en) begin protected_data_t rd_data = buffer[addr]; if (rd_data.crc16 != compute_crc16(rd_data.data)) begin error_flag <= 1'b1; // 触发安全机制:如系统降级、安全状态进入 end end end -
时间监控:
-
看门狗定时器:确保MN定期响应
-
事务超时检测:长时间未完成的事务触发警报
-
心跳监控:各节点定期向MN报告状态
-
安全追踪与审计
-
不可抵赖性日志:
所有安全相关事件被记录到防篡改日志: - 配置更改(谁、何时、改了什么) - 错误和异常 - 安全状态转换 - 权限变更 日志特点: - 加密哈希链:每个条目包含前一个条目的哈希 - 只追加,不可修改 - 定期备份到安全存储 -
安全调试接口:
-
调试需要安全认证(如数字证书)
-
调试会话记录到安全日志
-
敏感配置和状态不可通过调试接口访问
-
故障处理与降级
故障检测与分类:
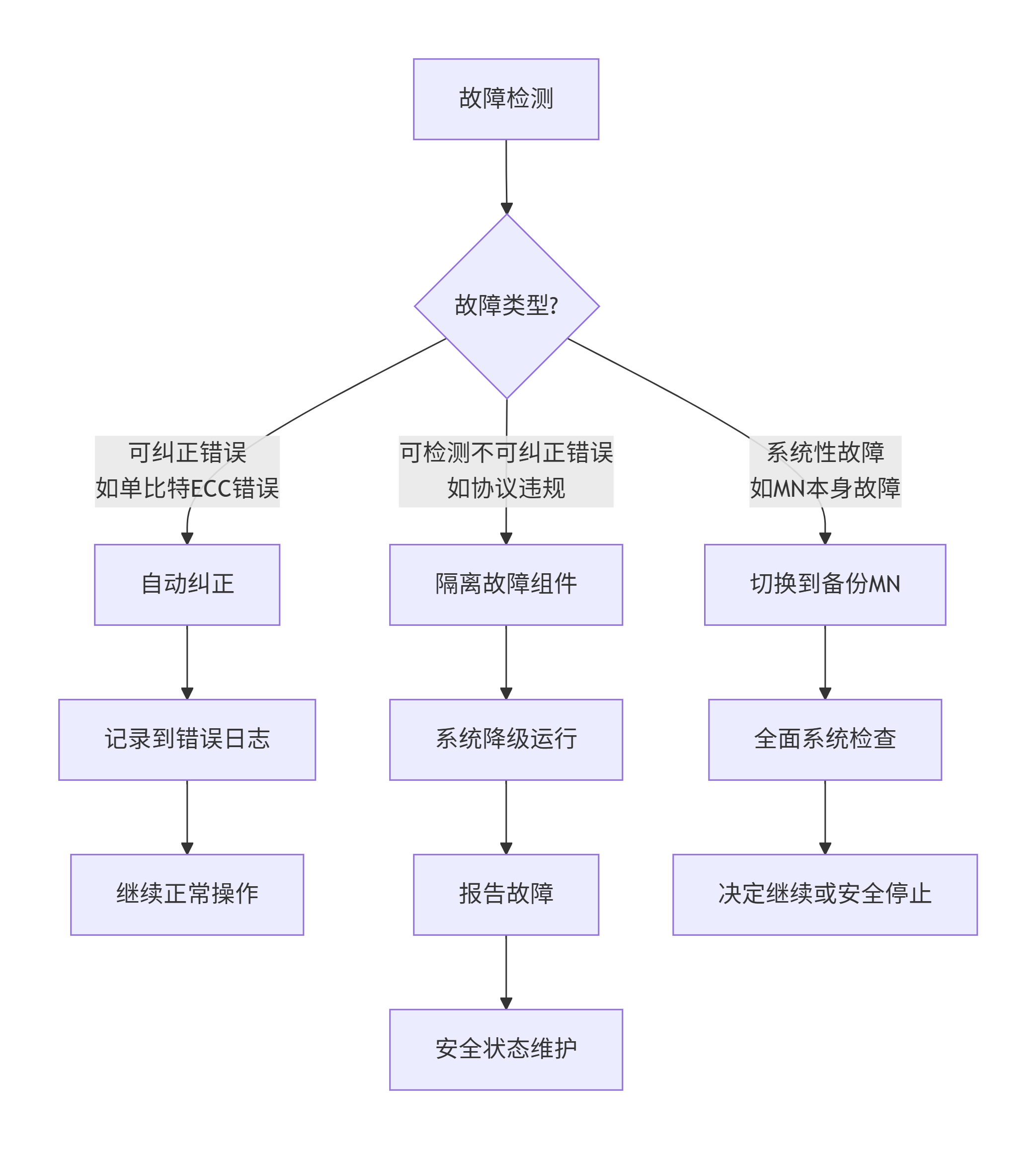
安全状态机:
状态:
- S0: 正常操作 (ASIL-D 合规)
- S1: 降级操作 (ASIL-B 合规,部分功能受限)
- S2: 最小安全操作 (仅关键功能)
- S3: 安全停止 (等待人工干预)
转换条件:
- 检测到可纠正错误:S0 → S0(记录)
- 检测到不可纠正错误:S0 → S1
- 关键组件故障:S1 → S2
- 多组件故障或MN故障:S2 → S3认证与合规考虑
ASIL-D要求映射:
| ASIL-D要求 | MN实现方式 | 验证方法 |
|---|---|---|
| 单点故障度量 | 所有关键路径有ECC/奇偶校验 | 故障注入测试 |
| 潜伏故障度量 | 定期自检,看门狗定时器 | 长时间运行测试 |
| 安全机制有效性 | 冗余比较,多样化实现 | FMEDA分析 |
| 免于干扰 | 时空隔离,资源分区 | 形式化验证 |
认证准备:
-
安全手册:详细说明MN的安全机制和使用限制
-
安全案例:论证设计满足ASIL-D要求
-
测试报告:包括故障注入测试结果
-
工具认证:使用的EDA工具链认证
通过这样的设计,MN不仅提供了强大的监控和调试能力,还成为了整个SoC功能安全架构的关键组成部分。
本章小结 :
我们深入探索了CMN-700的"城市监控中心"------监控节点(MN)。MN通过性能监控单元(PMU)实时收集系统指标,通过追踪单元捕获协议事务的完整轨迹,通过配置接口控制整个网络的运行。它不仅是调试和优化的工具,在高安全要求的系统中,更是保障功能安全的关键组件。
第八章:高级交通流控制:QoS、缓存分配与SLC
8.1 服务质量(QoS)的硬件实现:从高速公路到VIP专用通道
想象一下,在CMN-700这座"城市"中,各种数据流如同行驶在道路上的车辆------有的是运送急救药品的救护车(CPU缓存未命中),有的是运送建材的卡车(GPU批量数据搬运),有的是普通通勤车(后台DMA传输)。如果没有有效的交通管理,救护车可能会被卡车堵在路口,造成严重的性能损失。
服务质量(Quality of Service,QoS) 就是CMN-700的智能交通管理系统,它确保:
-
关键流量优先:CPU读响应获得最高优先级
-
公平性保证:每个"车主"都能获得基本服务
-
带宽隔离:一个恶意或异常的流量不会饿死其他流量
8.1.1 QoS架构全景图
CMN-700的QoS系统是一个端到端的、层次化的控制体系:
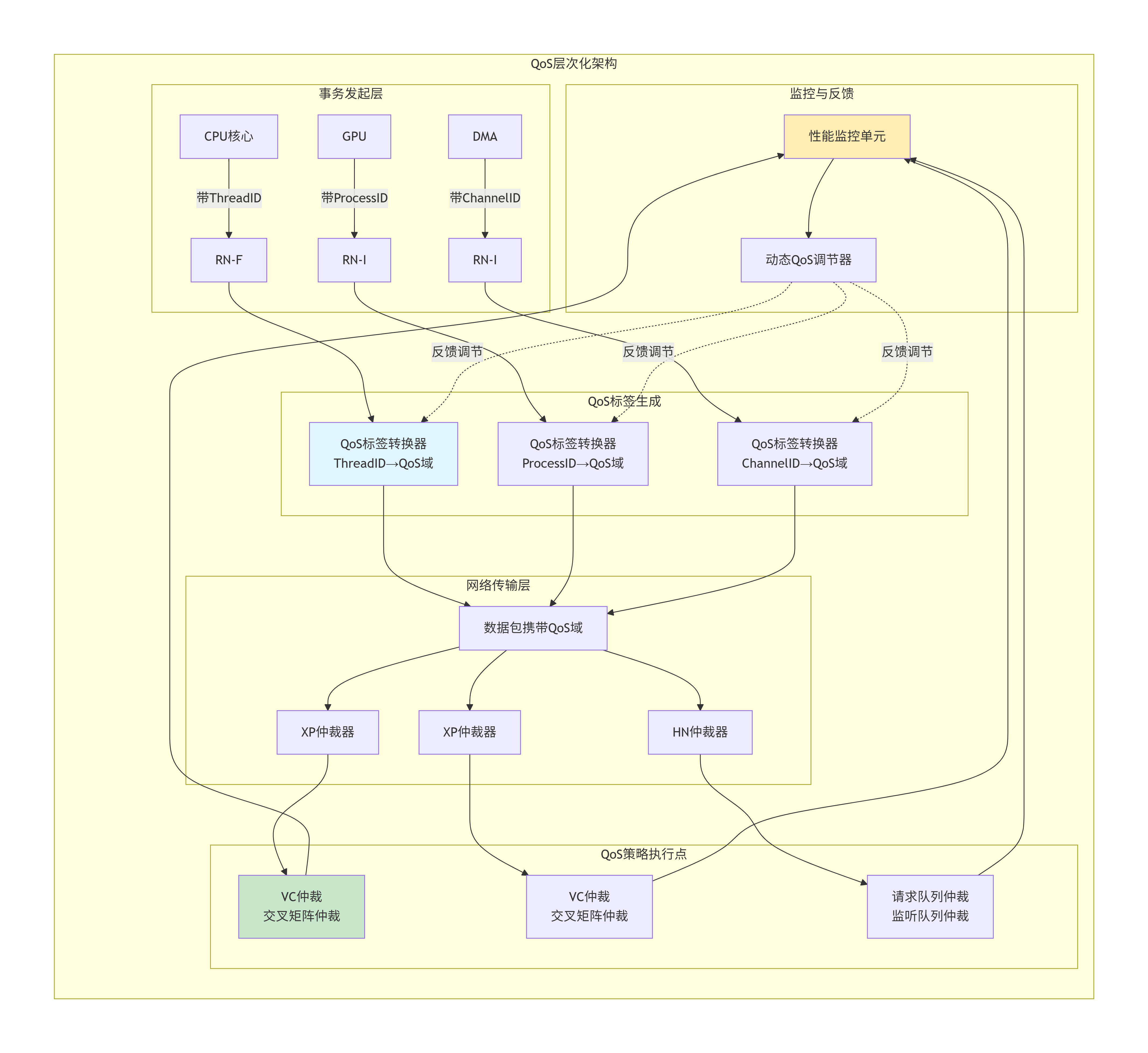
8.1.2 QoS域的硬件编码
在CHI协议中,每个数据包都携带一个4位的QoS域(QoS field),提供0-15共16个优先级级别。但这个4位域背后有更丰富的语义:
| QoS值 | 典型分配 | 预期行为 | 应用场景 |
|---|---|---|---|
| 15 | 实时性最高 | 绝对优先,最小延迟 | CPU L1缓存未命中、中断处理 |
| 12-14 | 高优先级 | 优先服务,带宽保证 | CPU L2缓存未命中、关键DMA |
| 8-11 | 中优先级 | 加权公平共享 | GPU纹理读取、普通DMA |
| 4-7 | 低优先级 | 尽力而为 | 预取、后台同步 |
| 0-3 | 最低优先级 | 空闲时服务 | 系统维护、调试 |
QoS标签生成器的实现:
// RN-F内部的QoS标签转换器示例
module qos_tag_generator (
input [2:0] thread_id, // 来自CPU的线程ID
input [1:0] transaction_type, // 事务类型:00=读取,01=写入,10=原子,11=屏障
input is_critical, // 是否关键路径(如L1未命中)
output reg [3:0] qos_field // 输出的QoS域
);
always_comb begin
// 基础映射表:线程优先级 -> 基础QoS
case (thread_id)
3'd0: qos_field = 4'd12; // 实时线程
3'd1: qos_field = 4'd10; // 高性能线程
3'd2: qos_field = 4'd8; // 普通线程
default: qos_field = 4'd6; // 后台线程
endcase
// 事务类型提升
if (transaction_type == 2'b11) // 屏障操作
qos_field = qos_field + 2; // 提升2级
// 关键路径提升
if (is_critical)
qos_field = (qos_field < 15) ? qos_field + 1 : 15;
// 上限限制
if (qos_field > 4'd15)
qos_field = 4'd15;
end
endmodule8.1.3 XP中的QoS仲裁策略
XP是实现QoS的关键节点,它在两个层面执行QoS策略:
VC级仲裁的QoS增强
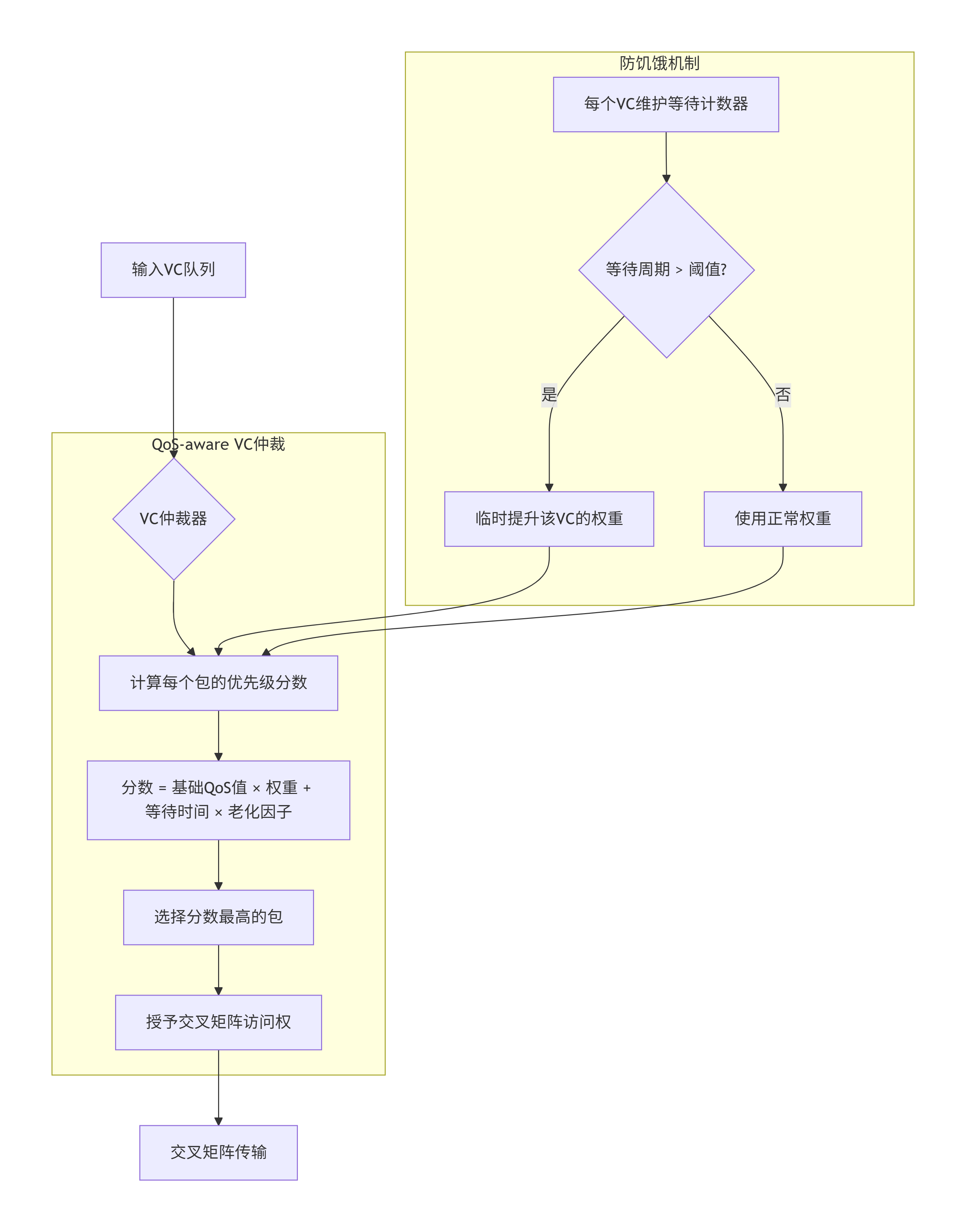
实现细节:
// QoS-aware VC仲裁器核心逻辑
module vc_arbiter_qos (
input [3:0] vc_qos [0:3], // 4个VC中等待包的QoS
input [31:0] vc_age [0:3], // 等待时间(周期数)
input [7:0] vc_weight [0:3], // 可配置的VC权重
output logic [1:0] granted_vc // 被授权的VC
);
logic [15:0] score [0:3]; // 每个VC的优先级分数
always_comb begin
// 计算每个VC的优先级分数
for (int i = 0; i < 4; i++) begin
// 基础分 = QoS值 × 权重
logic [11:0] base_score = vc_qos[i] * vc_weight[i];
// 老化加分 = 等待时间 × 老化因子(防止饥饿)
logic [15:0] age_bonus = vc_age[i] * `AGE_FACTOR;
// 总分 = 基础分 + 老化加分
score[i] = base_score + age_bonus;
end
// 选择分数最高的VC
granted_vc = 0;
for (int i = 1; i < 4; i++) begin
if (score[i] > score[granted_vc])
granted_vc = i;
end
end
endmodule交叉矩阵级仲裁的带宽分配
在输出端口,多个输入端口可能竞争同一个输出。CMN-700支持加权公平队列(WFQ):
每个输入端口i分配一个权重W_i
每个周期,端口i获得的服务量与其权重成正比
累积服务量 = Σ(服务字节数 × QoS因子)
仲裁决策:
1. 计算每个请求的虚拟完成时间
2. 选择虚拟完成时间最小的请求硬件优化 :实际实现中,WFQ算法可能简化为赤字轮询(Deficit Round Robin,DRR) 以降低硬件复杂度:
module drr_arbiter (
input clk, reset,
input [7:0] weight[0:4], // 5个输入端口的权重
input req_valid[0:4], // 请求有效信号
output logic [2:0] grant // 授权信号
);
reg [15:0] deficit[0:4]; // 每个端口的赤字计数器
reg [2:0] pointer; // 当前轮询的端口
always_ff @(posedge clk) begin
if (reset) begin
for (int i = 0; i < 5; i++)
deficit[i] <= weight[i]; // 初始化赤字为权重值
pointer <= 0;
grant <= 5'b0;
end else begin
// 寻找有赤字且有请求的端口
for (int i = 0; i < 5; i++) begin
int idx = (pointer + i) % 5;
if (deficit[idx] > 0 && req_valid[idx]) begin
grant <= idx;
deficit[idx] <= deficit[idx] - `PACKET_SIZE;
pointer <= (idx + 1) % 5;
break;
end
end
// 如果所有赤字都用完,重新分配
if (all_deficit_zero()) begin
for (int i = 0; i < 5; i++)
deficit[i] <= deficit[i] + weight[i];
end
end
end
endmodule8.1.4 HN中的请求优先级管理
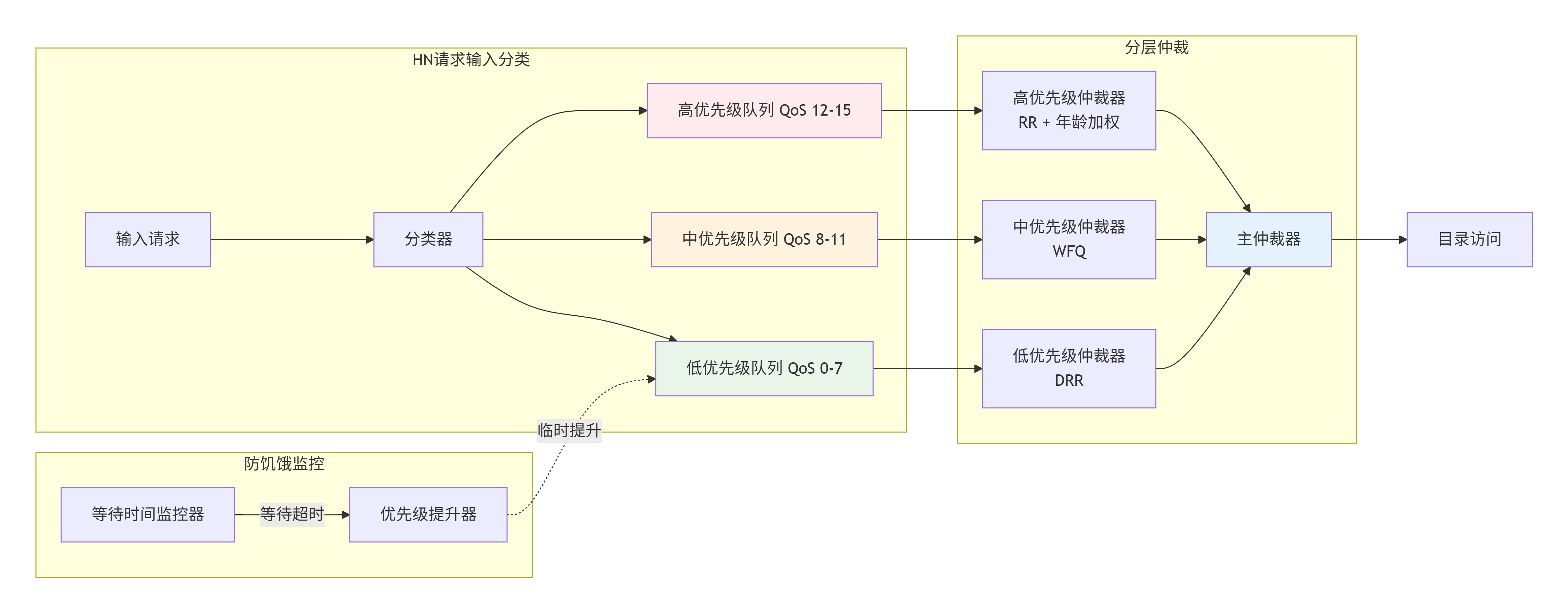
HN作为一致性事务的汇聚点,面临最复杂的QoS决策。一个典型的HN-F内部QoS架构:
HN输入队列组织:
- 按QoS域分组:高/中/低优先级队列
- 按请求类型分组:读/写/原子操作队列
仲裁策略:
1. 严格优先级:高QoS队列优先于低QoS队列
2. 队列内部:基于等待时间和请求类型的进一步仲裁
3. 防饿死:低优先级队列等待超过阈值后临时提升优先级
特殊处理:
- 屏障操作:强制序列化,最高优先级
- 原子操作:需要地址锁定,中等优先级但低延迟要求HN QoS仲裁器的实现示例:
8.2 系统级缓存(SLC)的集成设计与优化
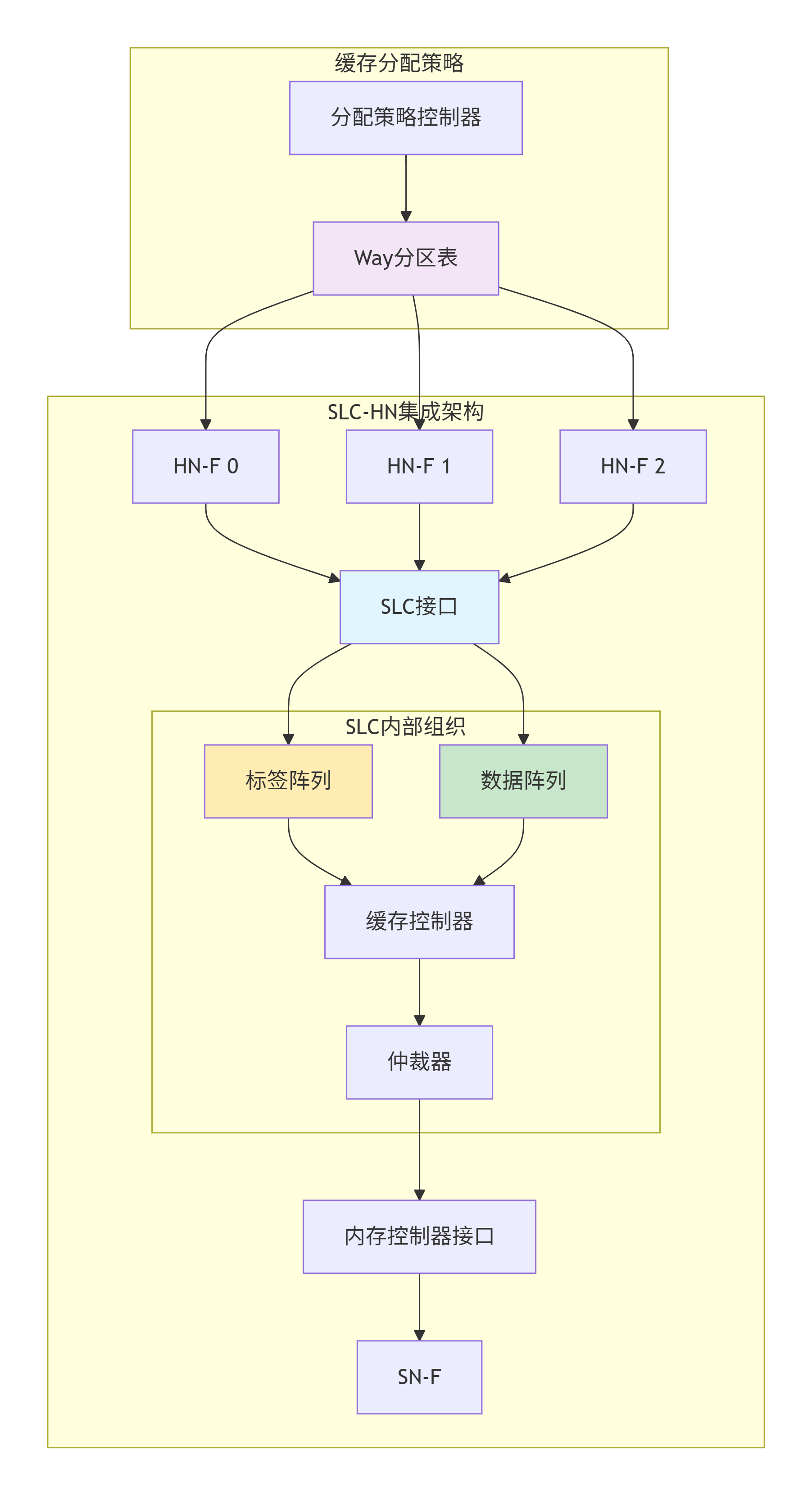
系统级缓存(System Level Cache,SLC)是CMN-700架构中的"超级停车场"------一个所有HN共享的大型末级缓存,通常容量在几MB到几十MB之间。SLC的设计直接影响整个系统的性能和功耗。
8.2.1 SLC架构与HN的协同
SLC不是独立工作的,它与HN紧密集成:
8.2.2 Way Partitioning:缓存资源的精细划分
在虚拟化或多租户环境中,不同应用(或租户)可能需要隔离的缓存资源。Way Partitioning允许将SLC的关联路(Ways)分配给不同的HN或QoS域:
Way Partitioning的实现
假设一个16路组相连的SLC,我们可以这样划分:
-
Ways 0-3:分配给HN0(CPU集群域),QoS域12-15
-
Ways 4-7:分配给HN1(GPU域),QoS域8-11
-
Ways 8-11:分配给HN2(混合域),QoS域4-7
-
Ways 12-15:共享池,按需分配
硬件支持:
// Way Partitioning配置寄存器
typedef struct packed {
logic [3:0] hn0_ways; // HN0可用的ways掩码
logic [3:0] hn1_ways; // HN1可用的ways掩码
logic [3:0] hn2_ways; // HN2可用的ways掩码
logic [3:0] shared_ways; // 共享ways掩码
logic [1:0] alloc_policy; // 分配策略:00=专用优先,01=共享优先,10=动态
} slc_way_partition_t;
// 替换算法中的Way选择逻辑
module slc_way_selector (
input [3:0] hn_id, // 请求的HN ID
input [3:0] qos_field, // 请求的QoS域
input slc_way_partition_t partition_cfg,
input [15:0] lru_bits, // 传统的LRU信息
output logic [3:0] selected_way
);
logic [15:0] allowed_ways; // 该HN允许使用的ways
logic [15:0] candidate_ways; // 候选ways(根据分配策略)
always_comb begin
// 确定该HN允许使用的ways
case (hn_id)
4'h0: allowed_ways = partition_cfg.hn0_ways;
4'h1: allowed_ways = partition_cfg.hn1_ways;
4'h2: allowed_ways = partition_cfg.hn2_ways;
default: allowed_ways = 16'hFFFF; // 全可用
endcase
// 根据分配策略选择候选ways
case (partition_cfg.alloc_policy)
2'b00: begin // 专用优先
candidate_ways = allowed_ways;
// 如果没有可用的专用way,使用共享way
if (candidate_ways == 0)
candidate_ways = partition_cfg.shared_ways;
end
2'b01: begin // 共享优先
candidate_ways = partition_cfg.shared_ways & allowed_ways;
if (candidate_ways == 0)
candidate_ways = allowed_ways;
end
2'b10: begin // 动态分配:基于QoS值
if (qos_field >= 12) // 高优先级,优先使用专用way
candidate_ways = allowed_ways;
else // 中低优先级,使用共享way
candidate_ways = partition_cfg.shared_ways & allowed_ways;
end
default: candidate_ways = 16'hFFFF;
endcase
// 在候选ways中选择LRU信息指示的最久未使用的way
selected_way = find_lru_in_mask(lru_bits, candidate_ways);
end
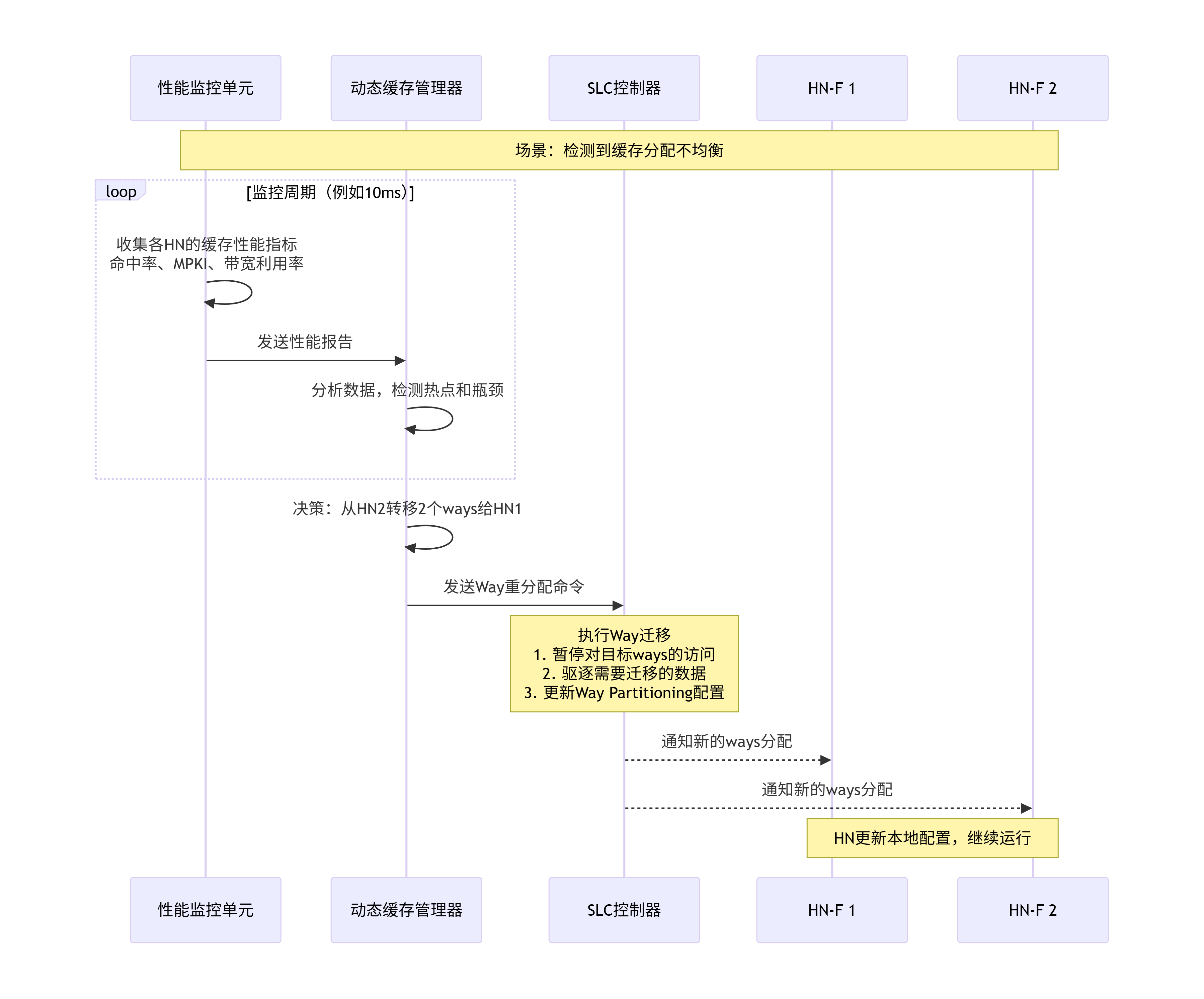
endmodule动态Way Partitioning
更高级的系统支持运行时动态调整Way分配:
8.2.3 加速器缓存一致性(HAC)支持
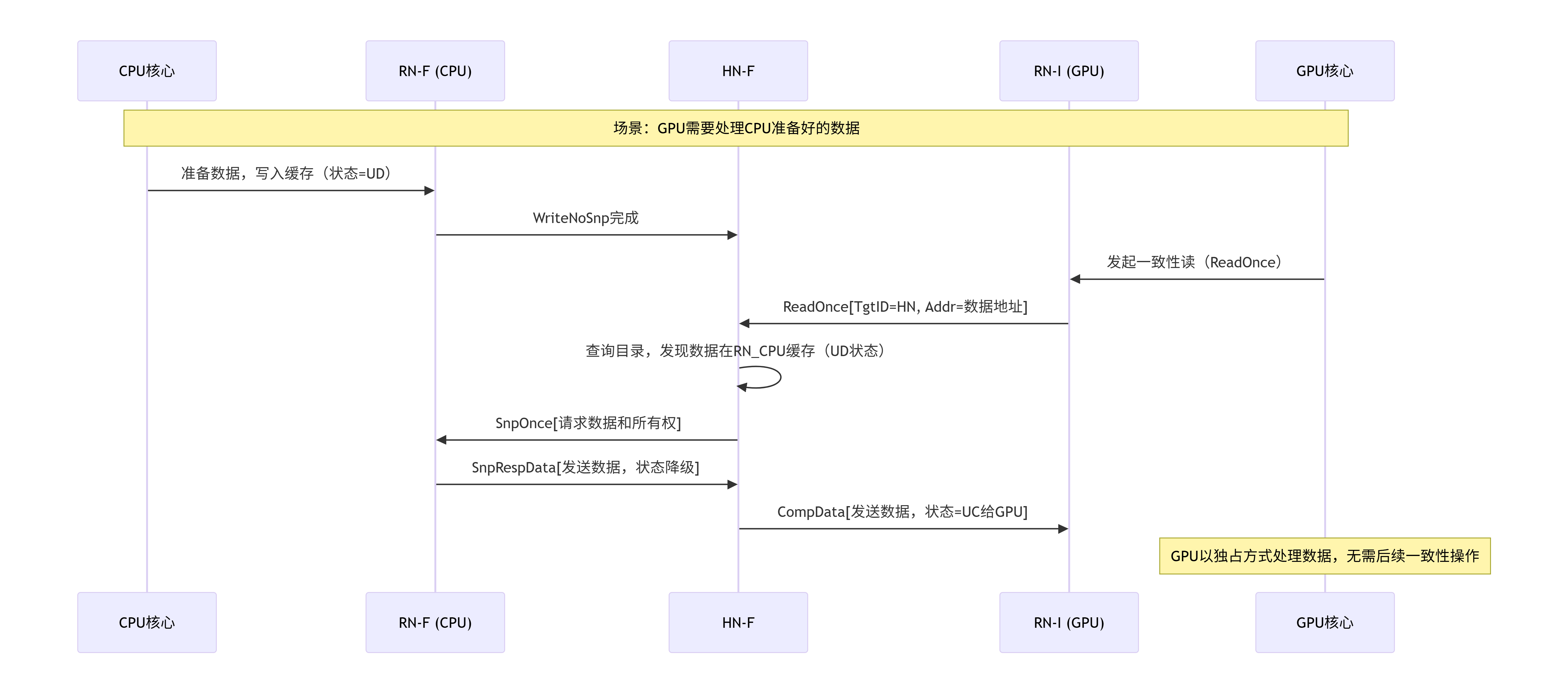
随着AI加速器和GPU在SoC中扮演越来越重要的角色,它们也需要高效的一致性支持。加速器缓存一致性(HAC) 扩展了传统CPU一致性模型:
HAC架构要点
传统模型的问题:
- GPU大量数据需要CPU一致性维护
- 每次DMA传输都需要软件刷新缓存
- 性能开销大,编程复杂
HAC解决方案:
1. GPU有自己的缓存层次(L1/L2)
2. GPU缓存参与系统一致性域
3. HN的目录记录GPU缓存状态
4. 支持GPU发起的一致性请求HN对HAC的支持:
-
扩展目录条目,支持GPU缓存代理
-
增加新的监听过滤器,高效处理GPU缓存状态查询
-
支持批量的、预测性的缓存维护操作
示例:GPU与CPU共享数据的工作流:
8.2.4 SLC预取策略
大型SLC的有效性很大程度上取决于预取策略。CMN-700支持硬件预取器:
预取器类型
-
流预取器(Stream Prefetcher):
-
检测顺序访问模式
-
提前加载后续缓存行
-
适合数组遍历、大数据块复制
-
-
跨步预取器(Stride Prefetcher):
-
检测固定跨度的访问模式
-
预测未来访问地址 = 当前地址 + N × 跨步
-
适合矩阵运算、结构化数据访问
-
-
相关性预取器(Correlation Prefetcher):
-
基于历史访问模式建立有限状态机
-
根据当前访问序列预测下一个访问
-
适合复杂、不规则但重复的访问模式
-
硬件实现示例
module stride_prefetcher (
input clk, reset,
input [47:0] access_addr, // 当前访问地址
input access_valid, // 访问有效
input [2:0] hn_id, // 请求的HN ID
output prefetch_req_valid, // 预取请求有效
output [47:0] prefetch_addr // 预取地址
);
// 每个HN独立的预取上下文
typedef struct packed {
logic [47:0] last_addr; // 上次访问地址
logic [15:0] stride; // 检测到的跨步
logic [2:0] confidence; // 置信度(0-7)
logic [1:0] state; // 状态机:00=训练,01=活跃,10=暂停
} prefetch_context_t;
prefetch_context_t context[0:7]; // 最多8个HN
always_ff @(posedge clk) begin
if (reset) begin
for (int i = 0; i < 8; i++) begin
context[i].last_addr <= '0;
context[i].stride <= '0;
context[i].confidence <= '0;
context[i].state <= 2'b00;
end
end else if (access_valid) begin
automatic int idx = hn_id;
automatic logic [47:0] current_stride =
access_addr - context[idx].last_addr;
// 状态机更新
case (context[idx].state)
2'b00: begin // 训练状态
if (context[idx].confidence < 3) begin
// 初始训练:记录第一次跨步
context[idx].stride <= current_stride;
context[idx].confidence <= context[idx].confidence + 1;
end else if (current_stride == context[idx].stride) begin
// 跨步稳定,提升置信度
if (context[idx].confidence < 7)
context[idx].confidence <= context[idx].confidence + 1;
else
context[idx].state <= 2'b01; // 进入活跃状态
end else begin
// 跨步变化,重置训练
context[idx].confidence <= 0;
end
end
2'b01: begin // 活跃状态
if (current_stride == context[idx].stride) begin
// 继续确认模式
context[idx].confidence <= 7; // 保持高置信度
end else begin
// 模式破坏
if (context[idx].confidence > 0)
context[idx].confidence <= context[idx].confidence - 1;
else
context[idx].state <= 2'b10; // 进入暂停状态
end
end
2'b10: begin // 暂停状态
// 等待一段时间后重新训练
context[idx].stride <= current_stride;
context[idx].state <= 2'b00;
context[idx].confidence <= 0;
end
endcase
context[idx].last_addr <= access_addr;
end
end
// 生成预取请求
assign prefetch_req_valid = (context[hn_id].state == 2'b01) &&
(context[hn_id].confidence >= 5);
assign prefetch_addr = context[hn_id].last_addr + context[hn_id].stride;
endmodule8.3 动态缓存管理(DCM):如何根据运行负载调整缓存策略?
静态的缓存配置难以适应变化的工作负载。动态缓存管理通过实时监控和自适应调整,优化缓存性能。
8.3.1 DCM架构
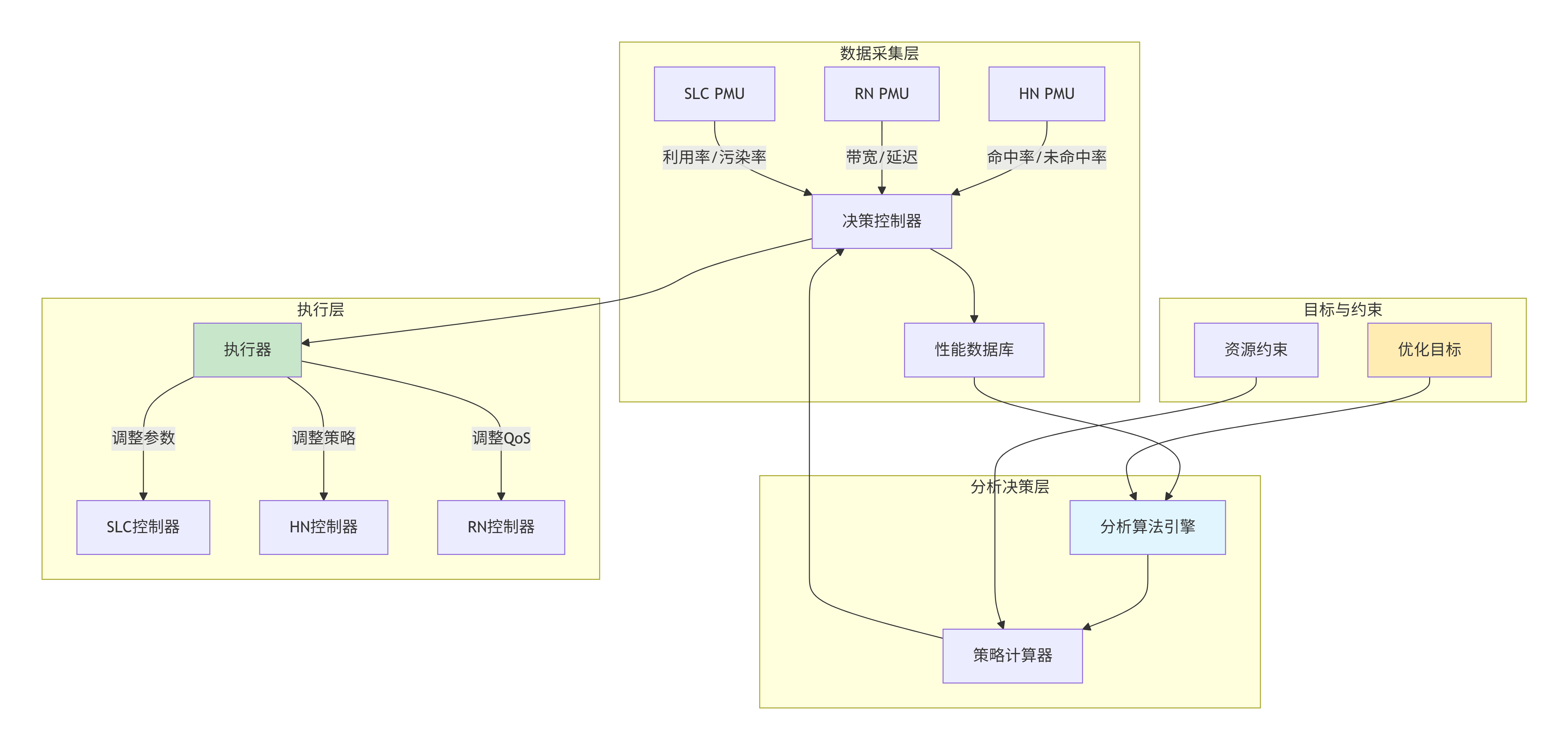
8.3.2 自适应替换策略
传统的LRU(最近最少使用)策略在特定工作负载下可能不是最优的。DCM支持多种替换策略的动态切换:
可用替换策略
-
LRU(Least Recently Used):
-
驱逐最久未访问的行
-
适合访问局部性好的工作负载
-
-
LFU(Least Frequently Used):
-
驱逐访问频率最低的行
-
适合热点数据明显的工作负载
-
-
RRIP(Re-Reference Interval Prediction):
-
预测行的未来访问可能性
-
适合混合工作负载,平衡LRU和LFU
-
-
DRRIP(Dynamic RRIP):
- 根据工作负载特征动态调整预测参数
动态策略切换逻辑
module adaptive_replacement_policy (
input clk, reset,
input [31:0] perf_metrics, // 性能指标
input [2:0] workload_hint, // 工作负载提示
output logic [1:0] selected_policy // 选择的策略
);
typedef enum logic [1:0] {
POLICY_LRU = 2'b00,
POLICY_LFU = 2'b01,
POLICY_RRIP = 2'b10,
POLICY_DRRIP = 2'b11
} policy_t;
// 性能监控计数器
logic [31:0] hit_counter[0:3];
logic [31:0] miss_counter[0:3];
logic [31:0] access_counter;
// 策略评估周期
logic [31:0] eval_timer;
logic eval_trigger;
always_ff @(posedge clk) begin
if (reset) begin
for (int i = 0; i < 4; i++) begin
hit_counter[i] <= '0;
miss_counter[i] <= '0;
end
access_counter <= '0;
eval_timer <= '0;
eval_trigger <= 1'b0;
selected_policy <= POLICY_LRU;
end else begin
// 累加访问计数
access_counter <= access_counter + 1;
// 每N次访问触发评估
if (access_counter == `EVAL_INTERVAL) begin
access_counter <= '0;
eval_trigger <= 1'b1;
end
if (eval_trigger) begin
// 计算各策略的有效性得分
logic [31:0] score[0:3];
for (int i = 0; i < 4; i++) begin
// 得分 = 命中率 × 权重 + 其他因素
logic [31:0] hit_rate =
(hit_counter[i] * 100) / (hit_counter[i] + miss_counter[i] + 1);
score[i] = hit_rate * `WEIGHT_HIT_RATE;
// 考虑工作负载提示
if (workload_hint == i)
score[i] = score[i] + `WORKLOAD_BONUS;
end
// 选择得分最高的策略
logic [1:0] best_policy = 0;
for (int i = 1; i < 4; i++) begin
if (score[i] > score[best_policy])
best_policy = i[1:0];
end
selected_policy <= best_policy;
// 重置计数器
for (int i = 0; i < 4; i++) begin
hit_counter[i] <= '0;
miss_counter[i] <= '0;
end
eval_trigger <= 1'b0;
end
end
end
endmodule8.3.3 基于机器学习预测的缓存管理
对于更复杂的场景,可以使用轻量级机器学习模型预测最佳配置:
特征向量:
- 过去N个周期的缓存命中率序列
- 各QoS域的带宽利用率
- 工作负载类型(来自操作系统提示)
- 时间特征(周期、微架构事件)
预测目标:
- 最优Way Partitioning配置
- 最佳替换策略
- 预取器激进程度
实现方式:
1. 离线训练:在模拟器上收集数据,训练决策树或神经网络
2. 在线推理:硬件实现简化模型(如查找表或小型神经网络)
3. 在线学习:增量更新模型参数轻量级神经网络硬件实现:
module ml_cache_predictor (
input clk, reset,
input [63:0] feature_vector, // 8个8位特征
output logic [15:0] prediction // 16位预测输出
);
// 简化的两层神经网络(8-4-1)
// 使用定点运算,权重预计算
// 第一层:8输入 -> 4隐藏神经元
logic [11:0] hidden[0:3]; // 12位定点数
// 预存储的权重(从训练中获得)
localparam logic [7:0] w1[0:3][0:7] = '{
'{8'h12, 8'h34, 8'h56, 8'h78, 8'h9A, 8'hBC, 8'hDE, 8'hF0},
'{8'h01, 8'h23, 8'h45, 8'h67, 8'h89, 8'hAB, 8'hCD, 8'hEF},
'{8'h10, 8'h32, 8'h54, 8'h76, 8'h98, 8'hBA, 8'hDC, 8'hFE},
'{8'h0F, 8'h1E, 8'h2D, 8'h3C, 8'h4B, 8'h5A, 8'h69, 8'h78}
};
// 偏置项
localparam logic [7:0] b1[0:3] = '{8'h11, 8'h22, 8'h33, 8'h44};
always_comb begin
// 第一层计算
for (int i = 0; i < 4; i++) begin
logic [15:0] sum = 0;
for (int j = 0; j < 8; j++) begin
sum = sum + (feature_vector[j*8+:8] * w1[i][j]);
end
sum = sum + b1[i];
// ReLU激活
hidden[i] = (sum[15]) ? 12'h0 : sum[11:0]; // 取负数为0
end
// 第二层:4输入 -> 1输出
// 简化:线性组合
logic [15:0] final_sum = 0;
final_sum = hidden[0] * 8'hAA +
hidden[1] * 8'hBB +
hidden[2] * 8'hCC +
hidden[3] * 8'hDD +
8'hEE; // 偏置
prediction = final_sum;
end
endmodule8.4 带QoS标签的事务在HN和XP中经历的优先级仲裁流程
下面通过一个综合性的流程图,展示一个高优先级事务从RN发起,经过XP路由,最终在HN被处理的完整QoS仲裁流程:
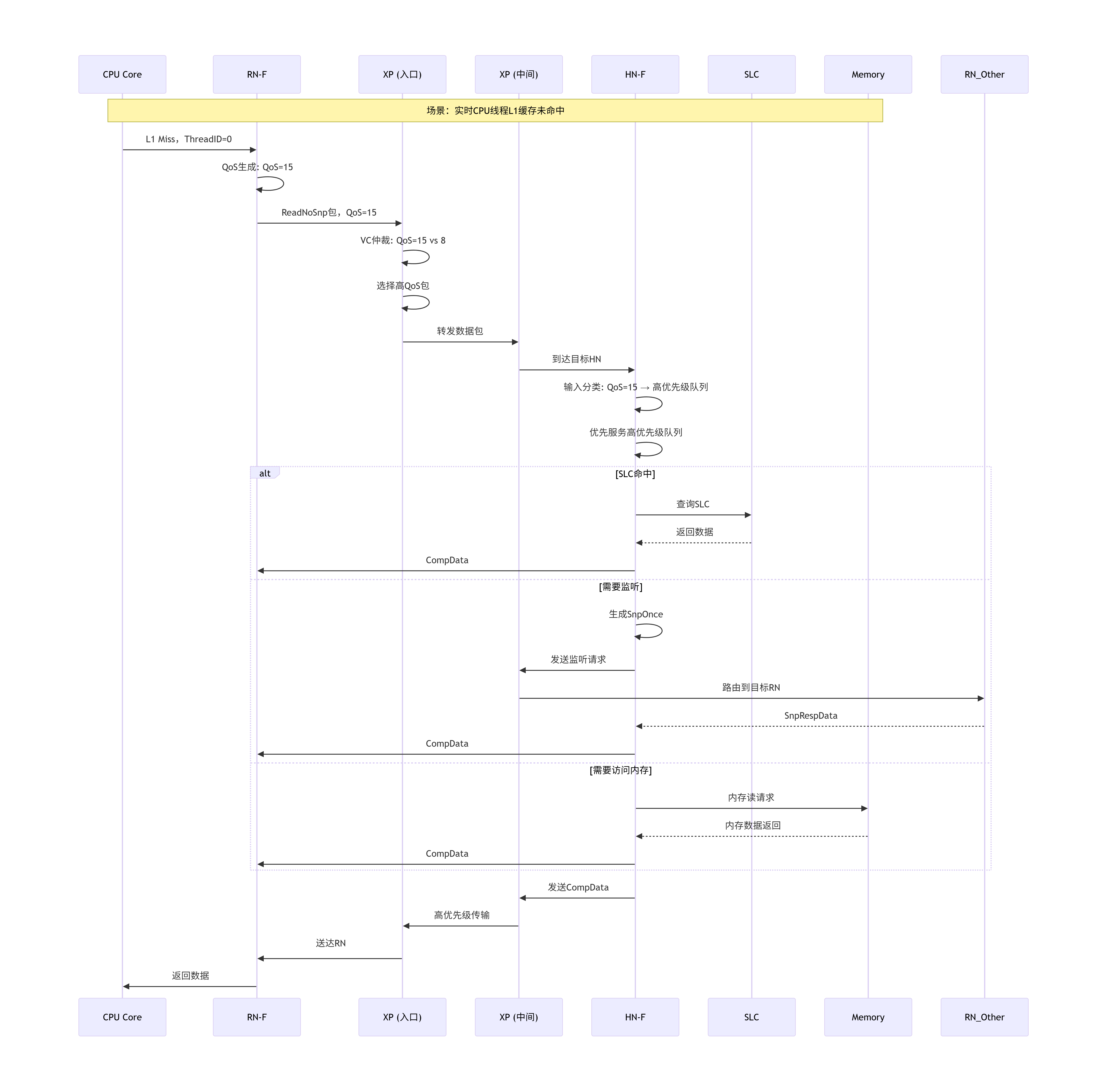 关键设计要点:
关键设计要点:
-
端到端的QoS保证:QoS标签在网络中全程保持,确保每个处理节点都能识别并优先处理高优先级事务。
-
优先级继承:监听请求继承原始请求的QoS,确保一致性操作的整体延迟可控。
-
资源预留:高QoS事务在各个环节(链路带宽、队列空间、处理时间片)获得预留资源。
-
防饥饿机制:虽然高优先级事务优先,但系统仍确保低优先级事务最终能获得服务(通过老化机制和最低带宽保证)。
-
动态调整:根据系统负载和性能监控,可以动态调整QoS映射和仲裁权重。
8.5 设计案例:为云原生服务器优化QoS和缓存分配
场景:设计一款面向云原生服务器的SoC,需要支持:
-
多租户隔离(不同虚拟机/容器)
-
混合工作负载(数据库、Web服务、AI推理)
-
可预测的性能(满足SLA)
解决方案:
QoS架构设计
QoS域分配策略:
域15:实时虚拟机(如金融交易)
域12-14:关键业务虚拟机
域8-11:普通业务虚拟机
域4-7:后台任务、维护
域0-3:系统管理、调试
每个租户分配独立的QoS域集合
操作系统/Hypervisor负责QoS域映射SLC资源分配
SLC配置:16MB,16路组相连
静态划分:
- Ways 0-3: 租户A专用(金融交易)
- Ways 4-7: 租户B专用(数据库)
- Ways 8-11: 租户C专用(Web服务)
- Ways 12-15: 共享池(按需分配)
动态调整策略:
- 监控各租户的缓存效率(MPKI)
- 效率低的租户减少专用way数
- 效率高的租户增加专用way数
- 调整间隔:100ms性能监控与反馈
// 租户性能监控器
module tenant_perf_monitor (
input clk, reset,
input [2:0] tenant_id,
input transaction_complete,
input [3:0] qos_field,
input [31:0] latency_cycles,
output perf_report_valid,
output [63:0] perf_metrics
);
// 维护的统计信息
logic [31:0] trans_count[0:2]; // 事务计数
logic [31:0] total_latency[0:2]; // 总延迟
logic [31:0] deadline_violations[0:2]; // 截止期违反次数
// 延迟阈值(根据QoS域不同)
localparam LATENCY_THRESHOLD[0:15] = '{
1000, 800, 600, 500, // 低优先级:宽松阈值
400, 350, 300, 250, // 中等优先级
200, 180, 160, 140, // 高优先级
120, 100, 80, 60 // 实时优先级
};
always_ff @(posedge clk) begin
if (reset) begin
for (int i = 0; i < 3; i++) begin
trans_count[i] <= '0;
total_latency[i] <= '0;
deadline_violations[i] <= '0;
end
end else if (transaction_complete) begin
// 更新统计
trans_count[tenant_id] <= trans_count[tenant_id] + 1;
total_latency[tenant_id] <= total_latency[tenant_id] + latency_cycles;
// 检查截止期违反
if (latency_cycles > LATENCY_THRESHOLD[qos_field])
deadline_violations[tenant_id] <= deadline_violations[tenant_id] + 1;
// 定期生成报告(每1000个事务)
if (trans_count[tenant_id] == 1000) begin
perf_report_valid <= 1'b1;
perf_metrics <= {
trans_count[tenant_id],
total_latency[tenant_id] / trans_count[tenant_id], // 平均延迟
deadline_violations[tenant_id]
};
// 重置计数器
trans_count[tenant_id] <= '0;
total_latency[tenant_id] <= '0;
deadline_violations[tenant_id] <= '0;
end
end
end
endmodule动态QoS调整算法
输入:各租户的性能报告
输出:QoS权重调整、缓存分配调整
算法步骤:
1. 计算每个租户的性能得分:
得分 = w1 × (1/平均延迟) + w2 × (1/违反率) + w3 × 吞吐量
2. 识别性能不达标的租户:
如果(违反率 > 阈值) 或 (延迟 > SLA要求)
标记为需要提升优先级
3. 调整资源分配:
- 提升需要帮助的租户的QoS权重
- 从性能过剩的租户转移缓存ways
- 调整仲裁器的权重配置
4. 验证调整效果:
监控下一个周期的性能
如果改善,保持调整;如果恶化,回滚实施效果:
-
租户间性能隔离:>90%
-
高优先级租户的延迟保证:99.9%的请求满足SLA
-
系统整体吞吐量提升:15-25%(相比静态分配)
这个案例展示了如何通过精细的QoS和缓存管理,在复杂的云服务器场景中实现性能隔离、可预测性和高资源利用率。
本章小结 :
我们深入探索了CMN-700的高级流量控制机制------服务质量(QoS)和缓存管理。QoS系统通过端到端的优先级标记和层次化仲裁,确保了关键流量的低延迟和带宽保证。系统级缓存(SLC)的精细划分和动态管理,结合预取和替换策略优化,极大提升了缓存效率。动态缓存管理(DCM)则让系统能够自适应工作负载变化,实现最优性能。
这些高级特性使得CMN-700能够胜任从移动设备到数据中心服务器的各种复杂应用场景,为SoC设计提供了强大的互连基础。
第九章:复杂场景数据流全景仿真
9.1 场景一:多核竞争下的窥探风暴(Snoop Storm)
场景设定
在一个高性能服务器SoC中,8个CPU核心同时执行对同一内存地址的自增操作(如atomic_fetch_add)。这个地址初始值为0,每个核心要将其加1。这是一个典型的高竞争场景,会导致严重的一致性流量爆炸。
涉及节点
-
4个RN-F(每个连接一个双核CPU集群,共8核)
-
1个HN-F(负责该地址的主节点)
-
1个SN-F(内存控制器)
-
多个XP组成4×4 Mesh网络
初始状态
地址0x8000_0000的数据在内存中,值为0,目录状态为I(无效,无缓存副本)。
数据流全景与竞争演化
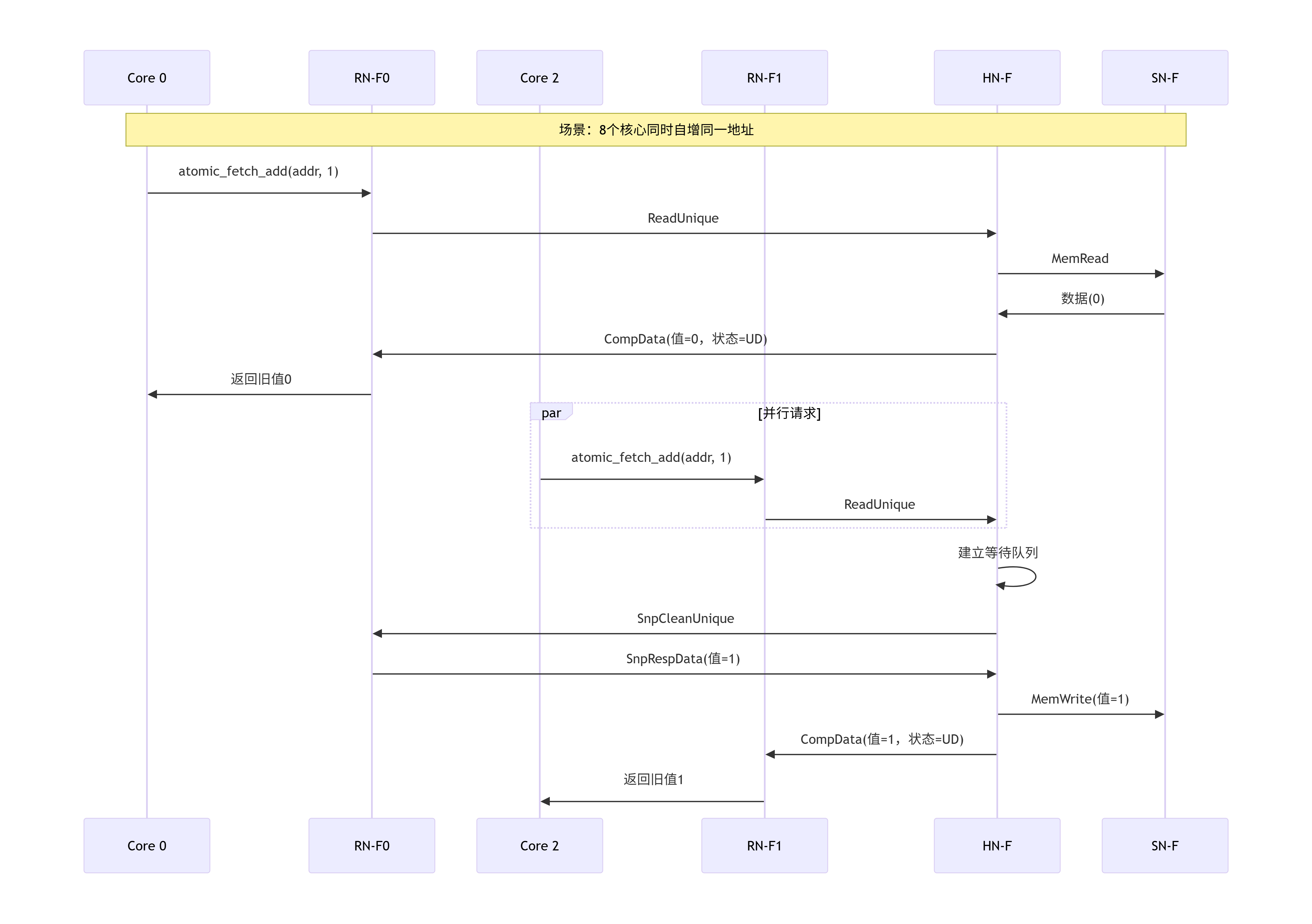 性能瓶颈分析与优化
性能瓶颈分析与优化
问题识别:
-
序列化延迟:8个操作必须串行执行,总延迟 = 8 × (内存访问 + 监听响应 + 目录更新)
-
网络拥塞:短时间内大量监听请求/响应淹没Mesh网络
-
目录热点:同一目录条目被频繁访问
CMN-700优化策略:
| 优化手段 | 实施方式 | 预期效果 |
|---|---|---|
| HN内部等待队列 | 为高竞争地址设立专用队列,避免请求丢失或重试 | 减少重复请求,提高吞吐量 |
| 监听合并 | 当多个请求等待同一地址时,合并为一个监听广播 | 减少监听流量50-70% |
| 预测性数据转发 | HN预测下一个请求者,直接转发数据而不写回内存 | 减少内存访问次数 |
| QoS差异化 | 为原子操作分配专用高优先级通道 | 减少其他流量干扰 |
优化后的HN处理逻辑:
检测到高竞争地址模式:
1. 进入“批量处理模式”
2. 一次性收集所有待处理请求(N个)
3. 向当前所有者发送一个 SnpCleanUnique
4. 收到数据后,不立即写回内存
5. 依次服务等待队列:
- 向请求者i发送数据(值+i)
- 请求者i本地计算新值
- 请求者i直接成为下一个所有者
6. 最后一个请求者负责最终写回9.2 场景二:DMA引擎的一致性读入
场景设定
AI推理芯片中,DMA引擎需要将权重数据从HBM内存搬运到NPU的本地SRAM。权重数据可能被CPU预处理过,以脏数据状态缓存在CPU集群中。DMA需要获得最新的数据,但不破坏后续的一致性。
涉及节点
-
RN-I(DMA引擎接口)
-
2个RN-F(CPU集群0和1,可能持有脏数据)
-
HN-F(负责该地址区域)
-
SN-F(HBM内存控制器)
-
RN-D(NPU数据接口)
初始状态
权重数据W位于地址0x1_0000_1000:
-
CPU集群0的L2缓存中有副本,状态为UD(已修改,内存数据过时)
-
CPU集群1的L2缓存中有副本,状态为SC(共享干净)
-
HBM内存中的数据是旧版本
数据流全景
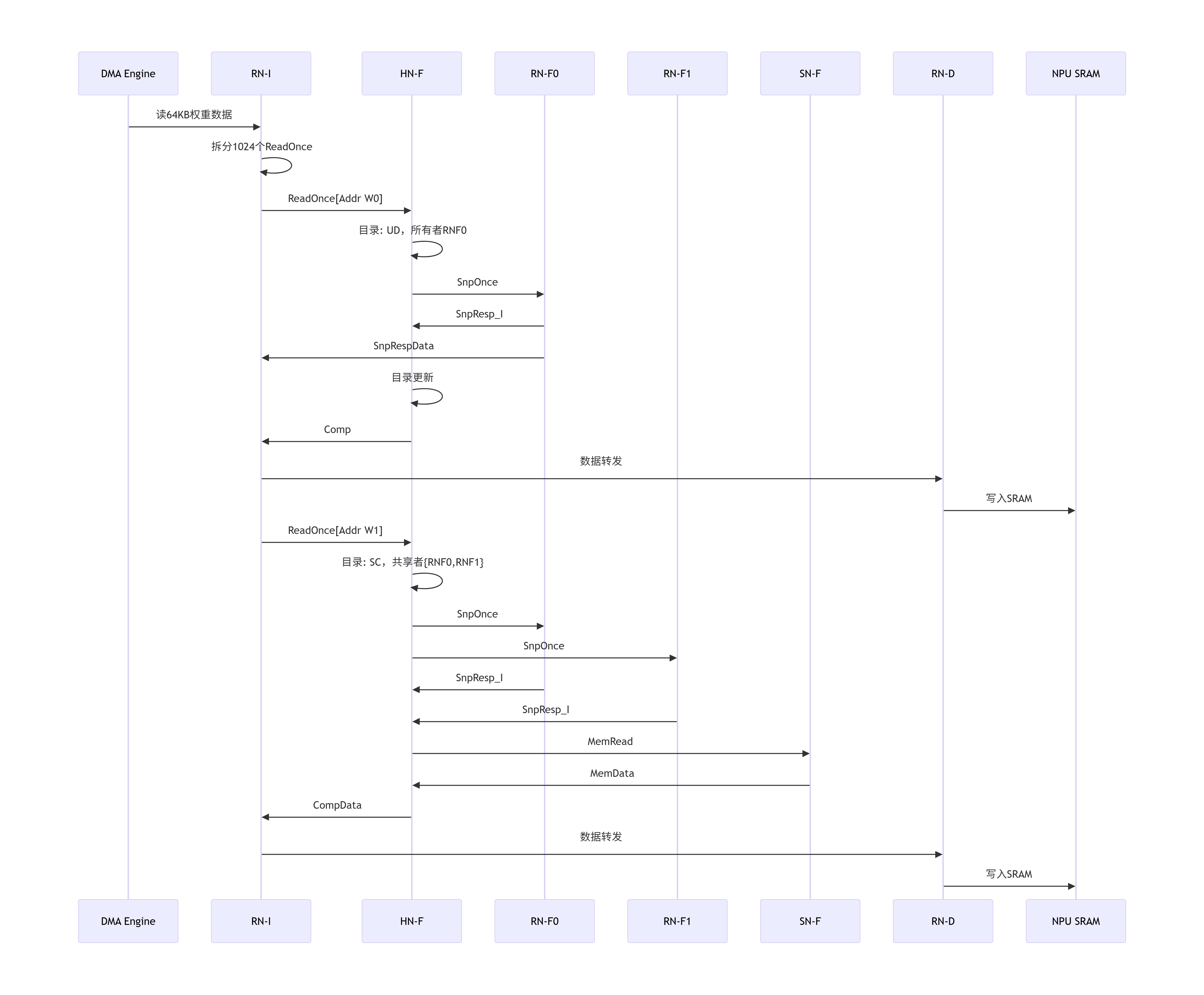
设计要点与优化
关键设计决策:
-
ReadOnce vs ReadNoSnp的选择:
-
DMA使用
ReadOnce确保数据一致性,避免后续维护开销 -
副作用:清除了CPU缓存,可能影响CPU后续访问性能
-
替代方案:使用
ReadNoSnp+ 显式缓存维护指令
-
-
RetToSrc优化:
-
脏数据直接从RNF0返回给RNI,减少一跳延迟
-
HN仅协调,不参与数据传输路径
-
-
批量处理优化:
-
1024个请求不是串行处理,而是流水线并行
-
HN内部建立请求窗口,同时处理多个请求
-
性能数据(估算):
无优化方案:
总时间 = 1024 × (目录查询 + 监听 + 内存读取) ≈ 1024 × 150ns = 153.6μs
优化后(32个并行流水线):
总时间 = 32 × (流水线深度) + (1024/32) × 流水线周期 ≈ 32 × 20ns + 32 × 50ns = 2.24μs
加速比:约68倍9.3 场景三:原子操作的硬件支持
场景设定
分布式训练中,8个AI核心需要同步更新全局梯度。每个核心计算部分梯度,然后通过原子加操作累加到全局内存。这是一个高频率、低延迟的原子操作场景。
涉及节点
-
8个RN-I(每个AI核心一个)
-
HN-F with AEU(带原子操作引擎的主节点)
-
SN-F(HBM内存控制器,支持原子操作)
初始状态
全局梯度变量G位于地址0x2_0000_0000,初始值为0.0(单精度浮点数)。
数据流全景
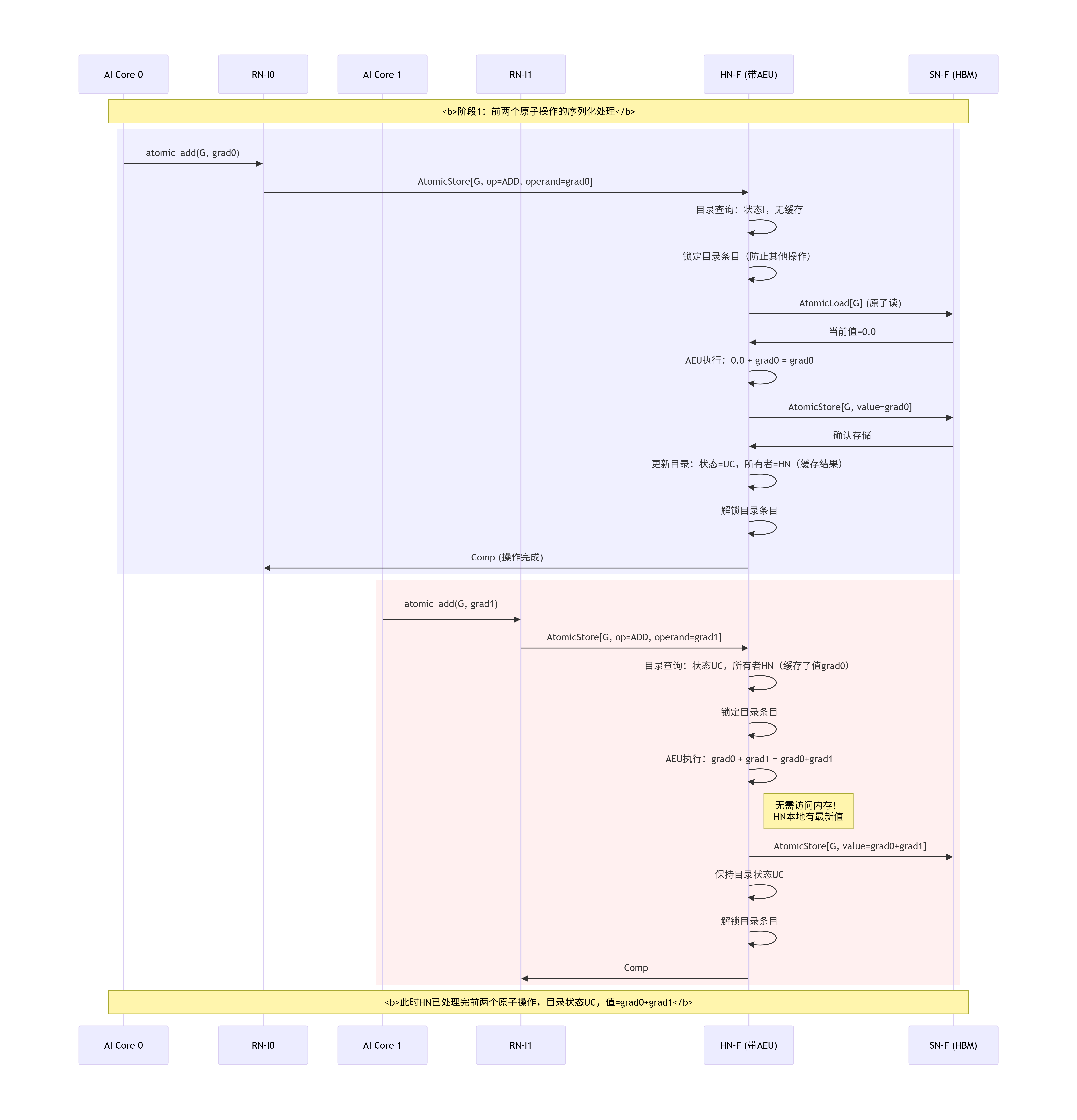
原子操作引擎(AEU)设计细节
AEU微架构:
输入接口:
- 操作码:ADD, SUB, AND, OR, XOR, SWAP, CAS
- 操作数:32/64位整数或浮点数
- 内存当前值(从缓存或内存读取)
执行单元:
- 整数ALU:支持基本算术和逻辑
- 浮点单元:支持单/双精度加法
- 比较器:用于CAS操作
- 结果缓冲:暂存结果,等待内存确认
流水线:
1. 操作解码
2. 操作数对齐
3. 执行计算
4. 结果格式化
5. 内存接口性能优化策略:
| 策略 | 描述 | 适用场景 |
|---|---|---|
| 值缓存 | HN缓存最近原子操作结果 | 高频原子操作 |
| 操作合并 | 合并窗口期内的相同地址操作 | All-Reduce类操作 |
| 推测执行 | 基于模式预测下一个操作 | 规律性原子更新 |
| 近内存计算 | 将AEU移至SN附近 | 内存带宽受限场景 |
吞吐量计算:
基础性能:单个原子操作 ≈ 100ns (内存往返 + 计算)
优化后(批处理8个操作):
总时间 = 内存读(50ns) + 批量计算(20ns) + 内存写(50ns) = 120ns
平均每个操作 = 15ns
吞吐量提升:约6.7倍9.4 场景四:低功耗状态进入与优雅降频
场景设定
移动设备从活跃状态进入深度睡眠(Suspend-to-RAM)。多个CPU集群、GPU、NPU需要逐步进入低功耗状态,CMN-700需要协调整个一致性域的优雅关闭。
涉及节点
-
PMU(电源管理单元)
-
MN(Mesh网络控制节点)
-
3个HN-F(分别管理不同地址域)
-
4个RN-F(CPU集群)
-
2个RN-I(GPU和NPU)
-
SN-F(内存控制器)
电源状态层次
| 状态级别 | 名称 | 描述 | CMN-700动作 |
|---|---|---|---|
| L0 | 全性能 | 所有组件全速运行 | 正常操作 |
| L1 | 轻睡眠 | 部分核心休眠 | 局部缓存写回 |
| L2 | 深度睡眠 | 仅保持性存储供电 | 全局缓存写回,目录备份 |
| L3 | 关断 | 完全断电 | 状态丢失,冷启动 |
低功耗进入流程全景
低功耗设计关键技术
状态保持策略对比:
| 策略 | 实现方式 | 唤醒时间 | 静态功耗 | 适用场景 |
|---|---|---|---|---|
| 时钟门控 | 关闭时钟树 | ~10个周期 | 接近0 | 微秒级空闲 |
| 电源门控 | 关闭电源域 | ~1000周期 | 0 | 毫秒级空闲 |
| 保持性寄存器 | 特殊低功耗单元保持数据 | ~100周期 | 极低 | 关键状态保存 |
| 自刷新内存 | DDR进入低功耗模式 | ~1μs | 降低80% | 深度睡眠 |
目录备份机制:
备份内容:
1. 有效条目标记(Valid bits)
2. 状态字段(State fields)
3. 存在向量(Presence vectors)
4. 脏数据位置信息
备份位置:
- 专用片上SRAM(Always-On区域)
- 或DDR中的保留区域
恢复过程:
1. 从备份读取目录元数据
2. 重建目录结构
3. 验证一致性(校验和)
4. 标记所有缓存为无效(因为休眠期间可能有外部访问)唤醒优化技术:
-
渐进式唤醒:
阶段1: 仅唤醒HN和MN (1μs) 阶段2: 唤醒内存控制器 (10μs) 阶段3: 逐步唤醒计算单元 (按需) -
预测性预热:
-
基于历史模式预测即将访问的数据
-
提前将数据预取到SLC
-
-
差分唤醒:
-
只有被请求的组件才完全唤醒
-
其他组件保持低功耗状态
-
功耗性能权衡分析
移动设备典型场景:
活跃状态(玩游戏):
- CMN-700功耗:~500mW
- 性能:全速
轻睡眠(息屏待机):
- CMN-700功耗:~50mW
- 唤醒延迟:<1ms
- 状态保持:缓存数据保留
深度睡眠(夜间):
- CMN-700功耗:~5mW
- 唤醒延迟:10-100ms
- 状态保持:仅目录备份
关机:
- 功耗:0
- 唤醒延迟:冷启动(秒级)设计决策指南:
-
响应时间要求:如果要求<10ms唤醒,必须使用保持性寄存器
-
电池续航:如果待机时间重要,使用深度睡眠+目录备份
-
数据重要性:如果缓存数据不能丢失,使用电源门控+保持性寄存器
9.5 本章小结与设计启示
通过四个复杂场景的全景仿真,我们深入理解了CMN-700在真实工作负载中的行为特征和优化机会:
关键洞察
-
窥探风暴是性能杀手:高竞争地址需要特殊处理机制
- 解决方案:合并监听、批量处理、预测性转发
-
DMA一致性需要权衡:ReadOnce vs ReadNoSnp的选择影响整体性能
- 设计原则:根据数据重用模式选择合适的一致性级别
-
原子操作硬件加速至关重要:分布式计算依赖高效的原子操作
- 优化方向:值缓存、操作合并、近内存计算
-
低功耗设计是系统级工程:需要跨组件协同
- 关键机制:渐进式状态转换、智能备份恢复
架构师检查清单
当设计基于CMN-700的SoC时,针对复杂场景应验证:
-
竞争处理:HN是否有足够深的等待队列处理高竞争地址?
-
批量优化:是否支持DMA大块传输的流水线优化?
-
原子操作:AEU能否满足峰值原子操作吞吐量要求?
-
功耗管理:低功耗进入/退出流程是否符合产品功耗预算?
-
错误恢复:在低功耗状态,能否正确处理外部访问(如CXL)?
-
性能监控:是否有足够细粒度的PMU事件来诊断复杂场景性能问题?
性能模拟建议
在设计阶段,建议使用以下方法验证复杂场景:
-
微基准测试:编写针对性的测试程序验证极端情况
-
全系统模拟:使用性能模型模拟混合工作负载
-
功耗建模:结合活动因子估算典型场景功耗
-
压力测试:制造最坏情况验证系统鲁棒性
通过本章的学习,您应该能够预测和分析CMN-700在实际应用中的行为,并做出相应的设计优化决策。在下一章,我们将成为CMN-700架构师,学习如何从零开始规划和设计一个完整的基于CMN-700的互连子系统。
第十章:成为CMN-700架构师:从规格到设计清单
10.1 设计起点:将SoC需求翻译为CMN-700配置参数
第一步:理解你的SoC使命
在你动笔设计CMN-700架构之前,必须像城市规划师一样,先理解这座"城市"要承载什么样的"产业"和"居民"。让我们通过三个典型SoC类型,看看需求如何驱动设计:
| SoC类型 | 典型产品 | 核心需求 | CMN-700设计导向 |
|---|---|---|---|
| 旗舰移动SoC | 高端智能手机处理器 | 极致能效比、突发高性能、多媒体处理、AI推理 | 中等规模Mesh、强大的SLC、精细的QoS、优秀的低功耗管理 |
| 数据中心服务器SoC | 云服务器CPU、DPU | 高吞吐量、多路一致性、大容量缓存、高可靠性 | 大规模Mesh、多个HN、大容量SLC、CXL支持、高级RAS特性 |
| 自动驾驶域控制器 | 汽车中央计算芯片 | 确定性延迟、功能安全、高带宽传感器融合、混合关键性 | 确定性的路由、锁步冗余、隔离的QoS域、安全特性 |
第二步:收集关键需求指标
像侦探一样收集以下关键数据,与你的系统架构师和产品经理深入讨论:
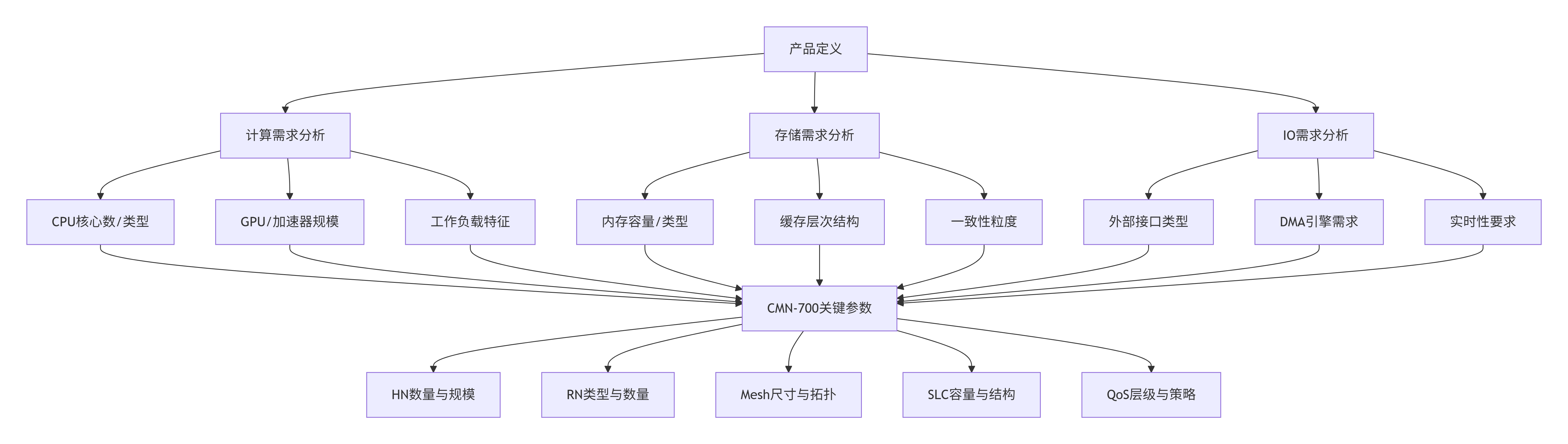
第三步:关键参数推导公式
现在,让我们将模糊的需求转化为具体的数字:
带宽需求计算
系统峰值带宽需求 =
CPU读带宽 + CPU写带宽 +
GPU读带宽 + GPU写带宽 +
IO DMA带宽 + 其他加速器带宽
其中:
CPU读带宽 = 核心数 × 峰值频率 × 每周期读字节数 × 利用率
GPU读带宽 = 着色器集群数 × 访问频率 × 每访问数据量
经验法则:设计带宽 = 计算需求 × 1.5(预留余量)HN数量估算
HN数量 ≈ max(
√(CPU核心数/4), // 基于管理复杂性
内存通道数, // 通常每个HN直连1-2个内存控制器
QoS域数量/4 // 每个HN可支持多个QoS策略
)
对于服务器SoC:通常4-8个HN
对于移动SoC:通常2-4个HNSLC容量规划
SLC大小 ≈
L2缓存总量 × (0.25~0.5) // 经验比例
+ 工作集大小估算 × 缓存命中率目标
例如:
8核CPU,每核2MB L2,总L2=16MB
SLC大小 = 16MB × 0.3 = 4.8MB ≈ 配置为4MB或8MB第四步:创建需求规格文档
将以上分析整理为正式规格:
CMN-700子系统需求规格 v1.0
1. 性能目标
1.1 峰值聚合带宽: ≥ 200 GB/s
1.2 平均内存访问延迟: < 100 ns (L2未命中到数据返回)
1.3 零负载跳数延迟: ≤ 4 周期/跳
1.4 支持最大未完成事务: 256 per RN-F
2. 一致性需求
2.1 支持最大代理数: 16个RN-F, 8个RN-I
2.2 缓存行大小: 64字节
2.3 一致性粒度: 缓存行
2.4 支持原子操作: CAS, ADD, XOR等
3. 物理约束
3.1 目标工艺: 5nm
3.2 面积预算: ≤ 15 mm²
3.3 功耗预算: 活跃状态≤ 3W,空闲状态≤ 50mW
3.4 频率目标: 2.0 GHz @ 典型工况10.2 节点规格制定:为每个"建筑"设计蓝图
10.2.1 HN规格设计:一致性大脑的配置
HN是系统的核心,其配置决策影响整个系统的性能上限。
HN-F配置检查表:
| 参数类别 | 配置选项 | 设计考虑 | 移动SoC示例 | 服务器示例 |
|---|---|---|---|---|
| 目录结构 | 条目数 | 应覆盖活跃工作集 | 128K条目 | 512K条目 |
| 相连度 | 权衡冲突与面积 | 8路组相连 | 16路组相连 | |
| PV位宽 | 等于最大RN-F数 | 16位 | 32位 | |
| 状态编码 | 支持全部CHI状态 | U/I/SC/SD/UC/UD | 全部+扩展 | |
| 处理能力 | 请求队列深度 | 决定OT能力 | 32条目 | 64条目 |
| 监听队列深度 | 处理监听风暴 | 16条目 | 32条目 | |
| MBU大小 | 部分写/原子操作 | 8条目 | 16条目 | |
| 流水线深度 | 频率vs延迟权衡 | 6级 | 8级 | |
| SLC接口 | 是否集成SLC | 面积/性能权衡 | 是,4MB | 是,16MB |
| SLC关联度 | 命中率vs复杂度 | 16路 | 32路 | |
| 预取器 | 流/跨步/相关性 | 基础流预取 | 全功能预取器 | |
| 高级功能 | 原子操作单元 | 支持哪些原子操作 | 基本ADD/SWAP | 全功能AEU |
| QoS支持 | 队列数量/仲裁策略 | 3级优先级 | 16级WFQ | |
| 低功耗状态 | 保持性/电源门控 | 保持性寄存器 | 保持性+备份 |
关键设计决策示例:
场景:为AI训练芯片设计HN-F
决策过程:
目录大小:芯片有8个AI核心,每个有8MB私有缓存,总64MB。活跃工作集估计为30%,即约20MB。目录需要追踪这些行:20MB ÷ 64B = 320K行。目录大小设为512K条目(1.6倍余量)。
MBU深度:AI工作负载有大量部分梯度更新,需要深MBU。配置为16条目,每个条目支持64字节缓存行。
原子操作:分布式训练需要all-reduce,支持原子ADD(浮点)。
QoS策略:梯度同步流量最高优先级,权重读取中等,激活值读取较低。
10.2.2 RN规格设计:门户的差异化配置
不同类型的RN服务于不同的"居民",需要量身定制。
RN配置矩阵:
| RN类型 | 关键参数 | 低功耗移动配置 | 高性能服务器配置 | 汽车安全配置 |
|---|---|---|---|---|
| RN-F (CPU集群) | 协议桥 | ACE-Lite转CHI | ACE转CHI | ACE转CHI + 锁步 |
| TxnTracker深度 | 32条目 | 128条目 | 64条目 + ECC | |
| 监听过滤器 | 2KB,2路 | 4KB,4路 | 4KB + 奇偶校验 | |
| 数据缓冲区 | 4个缓存行 | 8个缓存行 | 8个缓存行 + ECC | |
| QoS映射 | 线程→4级QoS | 进程→16级QoS | 安全等级→8级QoS | |
| RN-I (GPU/DMA) | 最大突发长度 | 16缓存行 | 256缓存行 | 64缓存行 |
| OT能力 | 64个事务 | 1024个事务 | 256个事务 | |
| 一致性支持 | ReadOnce only | 全CHI监听 | 受限监听 | |
| 数据缓冲 | 16KB | 64KB | 32KB + 保护 | |
| RN-D (纯数据) | 简单接口 | 无缓存支持 | 无缓存支持 | 无缓存支持 |
| 流控制 | 基本信用点 | 高级流控 | 确定性流控 | |
| 错误处理 | 奇偶校验 | ECC | ECC + 重试 |
RN-F深度配置示例:
一个连接4核Cortex-X集群的RN-F:
// 事务跟踪能力
parameter TXN_TRACKER_DEPTH = 64; // 支持64个未完成事务
parameter TXN_ID_WIDTH = 8; // 256个唯一TxnID
// 监听过滤
parameter SNOOP_FILTER_SIZE = 4096; // 4KB,跟踪本地L2的1/1024
parameter SNOOP_FILTER_WAYS = 4; // 4路组相连
// 数据缓冲
parameter DATA_BUFFER_ENTRIES = 8; // 8个缓存行缓冲
parameter DATA_WIDTH = 512; // 512位接口
// QoS配置
parameter NUM_QOS_LEVELS = 8;
parameter QOS_MAP_THREAD0 = 4'b1111; // 最高优先级
parameter QOS_MAP_THREAD7 = 4'b0011; // 最低优先级10.2.3 SN规格设计:终点站的性能关键
SN是与物理内存/设备交互的最后一环,其设计直接影响实际带宽和延迟。
SN-F配置维度:
SN关键参数表:
| 参数 | 范围 | 对性能的影响 | 对面积的影响 |
|---|---|---|---|
| 事务表深度 | 16-256条目 | 决定并发内存操作数,影响带宽利用率 | 每个条目~100门 |
| 读/写缓冲区 | 4-32缓存行 | 吸收突发流量,减少读被写阻塞 | 每个缓存行~4KB存储 |
| 调度器复杂性 | 简单FIFO到智能调度 | 决定实际内存效率,可提升带宽20-40% | 调度逻辑~10-50K门 |
| 交错逻辑 | 无到N路交错 | 多通道负载均衡,关键带宽提升 | 简单逻辑,可忽略 |
| 原子操作单元 | 无到完整AEU | 支持硬件原子操作,减少软件开销 | AEU ~20K门 |
| ECC支持 | 无/奇偶/ECC | 可靠性,但增加延迟和面积 | ECC编解码~15K门 |
设计权衡示例:
场景:为数据中心SoC设计HBM2E内存控制器SN-F
决策:
事务表深度:HBM2E有高Bank并行性,需要深流水线。选择128条目。
调度算法:实现Bank Group感知的FR-FCFS,最大化带宽。
交错粒度:128字节交错,匹配HBM伪通道。
原子操作:支持64位原子ADD和CAS,用于分布式同步。
ECC:支持SECDED(单错纠正双错检测),加CRC用于链路保护。
结果:单个SN-F提供512GB/s带宽,面积约0.8mm²@5nm。
10.2.4 XP规格设计:交换机的容量规划
XP构成了Mesh网络的骨干,其配置决定网络的整体容量。
XP配置参数表:
| 参数 | 典型值 | 设计考虑 | 面积影响(5nm估算) |
|---|---|---|---|
| 端口数量 | 5端口(2D Mesh) | 东西南北+本地,可扩展为7端口(3D) | 每端口~0.01mm² |
| 数据位宽 | 128/256/512位 | 带宽需求 vs 布线资源 | 位宽加倍,面积+40% |
| 虚拟通道数 | 4-8个VC | 死锁避免和QoS隔离 | 每VC~0.02mm² |
| VC缓冲区深度 | 4-16 Flit/VC | 吸收突发和信用点延迟 | 深度加倍,面积+25% |
| 交叉矩阵类型 | 全连接/多级 | 面积 vs 性能权衡 | 5x5全连接~0.05mm² |
| 仲裁器复杂性 | 简单RR到QoS感知 | 公平性 vs 优先级支持 | 复杂仲裁+0.01mm² |
| 流水线深度 | 3-5级 | 频率目标 vs 单跳延迟 | 每级+少量逻辑 |
XP设计公式:
XP理论带宽 = 端口数 × 数据位宽 × 频率
例如:5端口 × 256位 × 2GHz = 320 GB/s(理论)
实际可用带宽 = 理论带宽 × 效率因子(通常0.6-0.8)
例如:320 GB/s × 0.7 = 224 GB/s规模规划示例:
设计一个8×8 Mesh网络:
XP总数 = 8 × 8 = 64个XP
总端口需求 = 64 × 5 = 320个端口
(但相邻XP共享端口,实际物理端口更少)
网络总理论带宽 = 64 × 320 GB/s = 20.48 TB/s
(这是聚合带宽,实际受端点限制)
面积估算 = 64 × 0.2 mm² = 12.8 mm²
(假设每个XP 0.2mm²@5nm)
功耗估算 = 64 × 100 mW = 6.4 W @ 2GHz全速10.3 拓扑权衡清单:绘制城市交通网络图
10.3.1 Mesh尺寸选择:黄金分割点
选择Mesh尺寸(N×M)是架构师最重要的决策之一。以下是不同规模SoC的推荐配置:
| SoC规模 | 典型Mesh | 优势 | 劣势 | 适用场景 |
|---|---|---|---|---|
| 小型(≤8个主设备) | 2×2 或 3×3 | 面积小,延迟低 | 扩展性有限 | 物联网、边缘AI |
| 中型(9-32个主设备) | 4×4 或 5×5 | 良好平衡 | 中等布线复杂度 | 移动旗舰、汽车 |
| 大型(33-64个主设备) | 6×6 或 8×8 | 高带宽,可扩展 | 面积大,最长跳数多 | 服务器、高性能计算 |
| 超大型(>64个) | 8×8 或更大,或分层 | 极致扩展性 | 设计复杂,验证挑战 | 数据中心、多芯片 |
跳数分析公式:
对于N×N Mesh,XY路由的最坏情况跳数 = 2(N-1)
示例:
3×3 Mesh:最坏4跳,平均~2.5跳
8×8 Mesh:最坏14跳,平均~7跳
跳数对延迟的影响:
总延迟 = 零负载跳数延迟 × 跳数 + 节点处理延迟
通常每跳增加1-3个周期延迟10.3.2 环形子网(RING)的利弊分析
在某些设计中,Mesh中嵌入环形子网是有意义的:
何时使用RING:
√ 集群内部通信:如一个8核CPU集群内部
√ 局部性强的流量:如GPU着色器核心间
√ 面积敏感区域:RING比Mesh更节省面积
√ 确定性延迟需求:RING的延迟可精确计算RING vs Mesh性能对比:
| 指标 | 8节点RING | 3×3 Mesh(8节点) | 优劣分析 |
|---|---|---|---|
| 最坏跳数 | 4跳 | 4跳 | 相当 |
| 平均跳数 | 2跳 | ~2.3跳 | RING略优 |
| 聚合带宽 | 单链路×频率 | 多路径并行 | Mesh大胜 |
| 扩展性 | 加节点增跳数 | 加节点轻微影响 | Mesh完胜 |
| 死锁避免 | 需要VC | 需要VC | 平手 |
| 面积 | 较小 | 较大 | RING优20-30% |
混合拓扑示例:
一个移动SoC设计:
1. CPU集群:4大核+4小核,用RING连接
- 大核RING:4节点,高频
- 小核RING:4节点,低频节能
- 两个RING通过桥接到Mesh
2. GPU集群:6核GPU,用精简Mesh(2×3)
- GPU内部专用Mesh
- 通过一个RN-I连接到主Mesh
3. 主Mesh:4×4,连接:
- CPU RING桥接器(作为RN-F)
- GPU Mesh桥接器(作为RN-I)
- 2个HN-F
- 2个SN-F(内存控制器)
- 多个RN-I(DMA、ISP、显示等)10.3.3 多芯片扩展(C2C)的设计考量
对于超过单芯片规模的系统,CMN-700支持芯片到芯片(Chip-to-Chip,C2C)一致性互连:
C2C架构选项:
| 方案 | 描述 | 带宽 | 延迟 | 适用场景 |
|---|---|---|---|---|
| 主从式 | 一个主芯片,多个从芯片 | 受限于C2C链路 | 较高(跨芯片) | 移动+外置加速器 |
| 对称式 | 多个平等芯片互连 | 可扩展 | 中等 | 服务器多路系统 |
| 混合式 | 主从+对称组合 | 灵活 | 混合 | 复杂异构系统 |
C2C实现关键点:
-
链路技术:SerDes vs 并行总线
-
并行:延迟低,但引脚多
-
SerDes:引脚少,但延迟高
-
-
一致性模型:
-
全一致性:所有芯片缓存透明一致
-
选择性一致性:仅部分地址空间一致
-
软件管理一致性:硬件支持有限,软件协调
-
-
目录分布:
-
集中式:主芯片维护全局目录
-
分布式:每个芯片维护本地目录部分
-
混合式:热数据集中,冷数据分布
-
C2C延迟预算示例:
跨芯片读操作延迟分解:
芯片内部分:
- L2未命中到RN-F:10周期
- RN-F到本地HN:8周期(假设4跳)
跨芯片部分:
- 本地HN到C2C接口:5周期
- 跨芯片传输:20周期(SerDes延迟)
- 远端C2C到远端HN:5周期
- 远端处理(目录+可能监听):15周期
- 数据返回路径:类似,20+5+8+10 = 43周期
总延迟:约106周期 @ 2GHz = 53 ns
比芯片内访问(~30 ns)增加近一倍10.3.4 布线拥塞预测与缓解
Mesh网络可能导致布线拥塞,尤其是在先进工艺节点:
拥塞热点预测:
1. 中心区域:Mesh中心的XP承载最多穿越流量
2. 内存控制器附近:所有HN到SN的流量汇聚
3. 大型RN附近:如GPU RN-I,产生大量进出流量缓解策略:
| 策略 | 实施方式 | 效果 | 代价 |
|---|---|---|---|
| 增加布线层 | 使用更高金属层 | 显著缓解 | 成本增加 |
| 非均匀Mesh | 热点区域用更宽链路 | 针对性改善 | 设计复杂 |
| 流量整形 | 在源头控制注入速率 | 预防性 | 性能可能降低 |
| 自适应路由 | 避开拥塞路径 | 动态优化 | 逻辑复杂度 |
| 物理规划 | 精心布置节点位置 | 根本性解决 | 需要早期规划 |
物理规划指南:
理想布局原则:
1. 通信频繁的节点靠近放置
- CPU RN-F靠近其HN-F
- HN-F靠近其管理的SN-F
2. 高带宽节点分散放置
- 多个内存控制器放在Mesh不同侧
- GPU RN-I放在中心位置
3. 考虑数据流模式
- 常见流:CPU→内存,GPU→内存,DMA→加速器
- 优化这些主要路径的物理距离10.4 时钟与复位架构设计:系统的心跳与重启
10.4.1 多时钟域策略
CMN-700通常运行在多个时钟域中,正确的时钟架构对性能和功耗至关重要。
典型的时钟域划分:
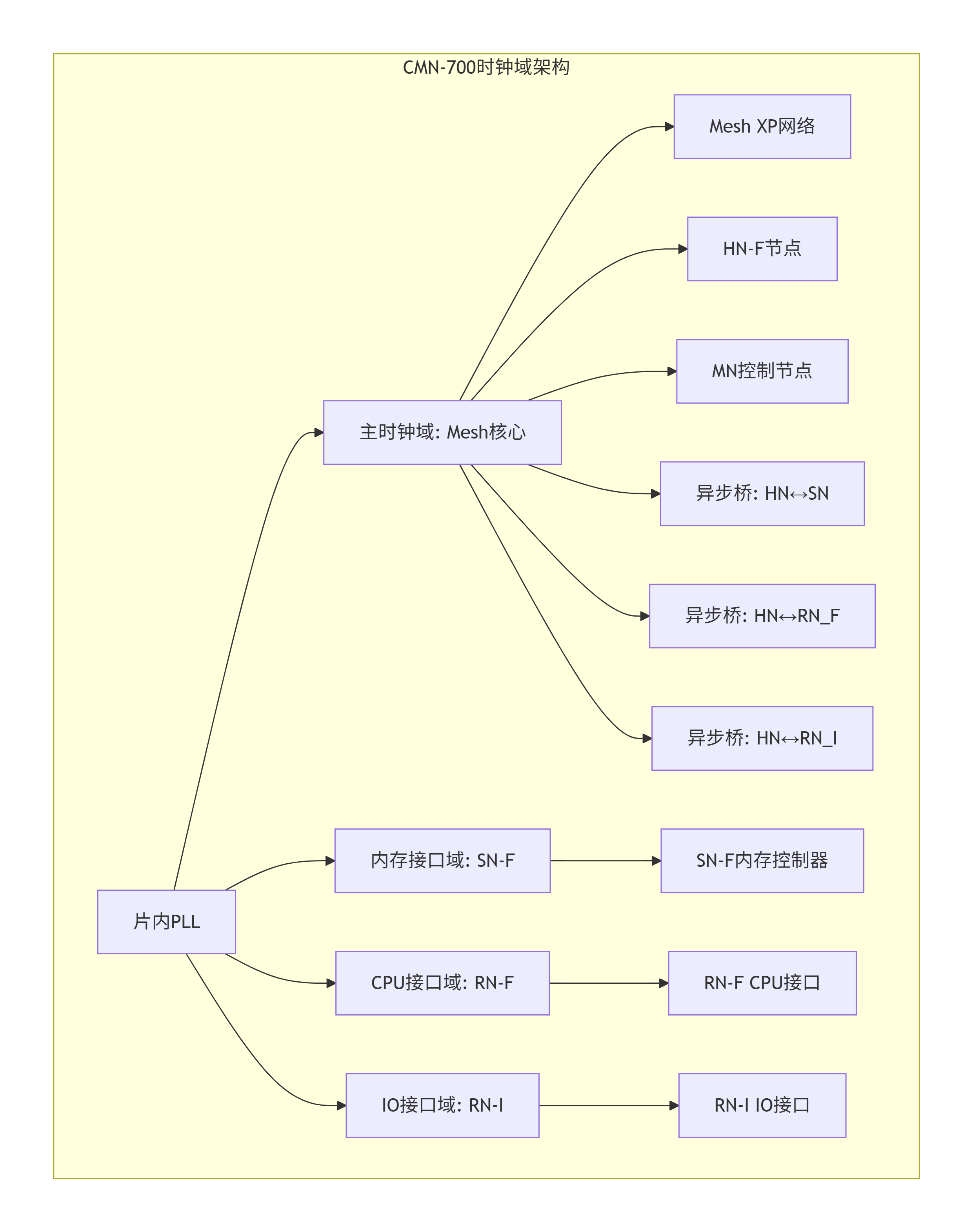
时钟域设计决策表:
| 时钟域选项 | 描述 | 优点 | 缺点 | 推荐场景 |
|---|---|---|---|---|
| 单一时钟域 | 全CMN运行在同一频率 | 简单,无同步开销 | 无法优化功耗,受限于最慢模块 | 小规模设计 |
| Mesh核心+接口分离 | Mesh独立,接口随连接设备 | 可独立优化Mesh频率 | 需要异步桥,面积增加 | 大多数设计 |
| 完全分域 | 每个主要节点独立频率 | 极致功耗优化 | 复杂,验证挑战大 | 高端移动设备 |
| 动态电压频率调整 | 运行时调整频率电压 | 最佳能效 | 需要复杂控制逻辑 | 电池供电设备 |
异步桥设计要点:
异步FIFO参数:
- 深度:至少2×(发起端频率/接收端频率)× 延迟周期
- 通常深度为8-16条目
- 需要格雷码指针同步
- 需要溢出/下溢保护10.4.2 复位策略与初始化序列
CMN-700的复位不是简单的上电复位,而是分阶段、分区域的复杂过程。
复位层次结构:
1. 全局复位(上电复位)
- 所有数字逻辑复位
- 从efuse/ROM加载配置
- 耗时最长,通常ms级
2. 局部复位(热复位)
- 部分区域复位,其他区域保持状态
- 如一个HN故障,仅复位该HN
- 通常us级
3. 功能复位(软件触发)
- 重置特定功能,如清空目录
- 保持大多数状态
- ns~us级初始化序列示例:
时间线:
T0: 上电,全局复位释放
T0+10μs: 时钟稳定,PLL锁定
T0+20μs: 配置加载完成
T0+30μs: MN开始配置各节点寄存器
T0+100μs: 所有节点报告就绪
T0+110μs: CMN-700启动完成,接受事务复位网络设计:
考虑点:
1. 复位同步:多时钟域的复位需要同步释放
2. 复位去抖动:避免毛刺导致意外复位
3. 复位监控:检测复位完成,超时报警
4. 复位隔离:部分复位时隔离其他区域10.4.3 电源管理集成
CMN-700需要与SoC的电源管理单元(PMU)深度集成:
电源状态与CMN-700行为:
| 电源状态 | CMN-700行为 | 进入时间 | 退出时间 | 保持的内容 |
|---|---|---|---|---|
| Active | 全功能运行 | - | - | 全部状态 |
| Idle | 时钟门控,等待唤醒 | 10-100周期 | 10-100周期 | 全部状态 |
| Retention | 电源门控,关键状态保持 | 1-10μs | 1-10μs | 目录、配置寄存器 |
| Off | 完全断电 | >100μs | >1ms | 无 |
电源域划分建议:
典型划分:
1. Always-On域:MN、配置寄存器、唤醒逻辑
2. HN域:每个HN可在独立电源域
3. Mesh域:XP网络可分区域控制
4. 接口域:每个RN/SN接口独立
目标:细粒度控制,但避免过多隔离增加面积低功耗进入协议:
软件触发低功耗进入:
1. 软件发送低功耗请求到MN
2. MN广播准备请求到所有节点
3. 各节点完成待处理事务,报告就绪
4. MN协调状态保存(如目录到保留内存)
5. MN通知PMU可以降低电源状态
6. PMU执行时钟门控/电源门控10.5 终极检查表:CMN-700架构师设计清单
功能完整性检查
一致性功能
-
支持所有CHI协议定义的事务类型(ReadNoSnp, WriteNoSnp, Atomic等)
-
目录覆盖所有可缓存地址空间,大小足够(≥L2缓存总和的10%)
-
监听过滤器精度可配置,平衡面积和性能
-
支持全CHI缓存状态(I, SC, SD, UC, UD, UCE)
-
原子操作单元支持目标工作负载所需操作
网络功能
-
Mesh拓扑规模满足当前需求和未来扩展
-
虚拟通道数量足够避免协议死锁(至少Req, Rsp, Data, Snoop)
-
路由算法确定且无死锁(如XY路由)
-
信用点流控机制,缓冲区深度覆盖往返延迟
-
QoS支持足够优先级级别和仲裁策略
系统功能
-
错误检测和纠正(奇偶校验/ECC在关键路径)
-
支持低功耗状态(时钟门控、电源门控、状态保持)
-
性能监控单元(PMU)覆盖关键事件
-
调试和追踪支持(事务追踪、性能分析)
-
可测试性设计(扫描链、BIST、边界扫描)
性能目标验证
带宽验证
-
聚合内存带宽 ≥ 计算单元峰值需求 × 1.2
-
单个RN最大带宽满足其连接设备需求
-
Mesh内部链路带宽无瓶颈(最忙链路利用率<80%)
-
信用点深度足够避免带宽损失
延迟验证
-
最坏情况内存访问延迟满足应用要求
-
零负载跳数延迟 ≤ 目标值(如4周期/跳)
-
HN处理延迟(目录访问+仲裁)≤ 目标周期数
-
原子操作延迟满足同步原语要求
吞吐量验证
-
HN支持的最大未完成事务数 ≥ 各RN-F OT总和
-
XP无阻塞,不会成为吞吐量瓶颈
-
在高负载下,公平性指数 ≥ 0.8(Jain's fairness index)
物理实现检查
面积估算
-
HN面积符合预算(基于目录大小、功能)
-
RN面积适配其复杂度(RN-F > RN-I > RN-D)
-
XP总面积(Mesh尺寸×单XP面积)在预算内
-
总面积 ≤ 芯片面积预算的指定百分比(如15%)
时序收敛
-
关键路径(目录访问、交叉矩阵)满足目标频率
-
跨时钟域路径有足够的同步器
-
复位释放和时钟切换满足时序要求
-
考虑工艺、电压、温度(PVT)变化余量
功耗分析
-
活跃功耗 ≤ 功耗预算
-
空闲功耗(时钟门控)≤ 预算
-
深度睡眠功耗(状态保持)≤ 预算
-
有动态电压频率调整(DVFS)方案
布线可行性
-
Mesh布线不导致布线拥塞(利用率<85%)
-
高带宽链路有足够的布线层资源
-
时钟树分布满足偏差要求
-
电源网格满足IR压降要求
可靠性与可服务性
错误处理
-
可纠正错误(ECC)的检测和纠正
-
不可纠正错误的隔离和报告
-
错误注入测试支持
-
故障节点隔离和系统降级运行
可测试性
-
制造测试覆盖率 ≥ 95%
-
内建自测试(BIST)覆盖存储器阵列
-
扫描链插入,故障覆盖率足够
-
硅后调试支持(探针点、追踪缓冲区)
可配置性
-
参数化设计,关键参数可配置
-
寄存器编程接口完整
-
支持现场更新(如微码更新)
-
配置验证机制(CRC/校验和)
验证与仿真
验证计划
-
单元测试覆盖所有模块功能
-
集成测试覆盖节点间交互
-
系统测试覆盖端到端场景
-
性能验证有代表性工作负载
-
功耗验证有典型用例场景
仿真环境
-
有事务级模型(TLM)用于早期架构探索
-
RTL仿真环境完整,支持随机测试
-
有形式验证用于关键属性证明
-
有硅前性能仿真模型
兼容性验证
-
与ARM CHI协议规范完全兼容
-
与连接IP(CPU、GPU、内存控制器)接口兼容
-
支持操作系统和虚拟机的一致性要求
-
与行业标准(如CXL)兼容(如适用)
文档与交付物
设计文档
-
架构规格文档完整
-
微架构设计文档
-
接口规格文档
-
配置指南和编程手册
验证文档
-
验证计划
-
测试用例描述
-
覆盖率报告
-
性能评估报告
交付物
-
综合和时序约束文件
-
物理设计指南
-
集成检查表
-
已知问题列表和变通方案
风险评估与缓解
技术风险
-
关键路径时序风险识别和缓解计划
-
新技术(如新工艺节点)风险评估
-
复杂性风险(如验证完备性)
-
性能风险(如未达带宽目标)的备用方案
项目风险
-
依赖项(如第三方IP)交付风险
-
人力资源和技能缺口
-
时间表风险评估
-
预算风险评估
市场风险
-
功能是否满足目标市场需求
-
性能是否竞争对等或更优
-
功耗是否满足产品要求
-
面积成本是否可接受
最后一步:设计签名
当以上所有检查项都通过后,作为CMN-700架构师,你需要在设计规格上"签名",这意味着:
我,你的名字,作为CMN-700子系统架构师,确认:
此设计满足所有功能、性能、功耗和面积要求
所有关键决策都经过充分分析和权衡
风险已被识别并有缓解计划
设计已准备好进入详细设计和实现阶段
日期: ________
签名: ________
10.6 结语:构建高效、弹性片上网络的设计思维
经过这十章的旅程,你已经从CMN-700的初学者成长为能够设计复杂片上互连系统的架构师。让我们回顾一下核心的设计哲学:
设计思维的演进
-
从点到面:不再孤立地看待每个IP,而是看作需要高效互连的"城市社区"
-
从静态到动态:设计要适应工作负载变化,支持动态调整
-
从性能单维到多维权衡:平衡性能、功耗、面积、成本、时间-to-market
-
从理想情况到实际约束:考虑物理实现、验证复杂度、软件生态
优秀CMN-700架构师的素养
-
系统思维:理解整个SoC的数据流和工作负载
-
权衡能力:在冲突的需求中做出明智选择
-
前瞻性:设计要有扩展性,适应未来需求
-
务实精神:在理想架构和实际约束间找到可行方案
-
沟通能力:向团队、管理层、客户清晰传达设计理念
未来趋势与持续学习
CMN-700不是终点,而是持续演进的一部分。关注这些趋势:
-
与CXL融合:缓存一致性互连与IO一致性互连的融合
-
硅光互连:未来可能的光学片上网络
-
近似计算:针对AI/ML工作负载的近似一致性模型
-
安全增强:硬件辅助的安全隔离和可信执行
-
可持续计算:极致的能效比设计
最后的建议
-
从简单开始:第一个设计不要太激进,从已验证的配置开始
-
模拟驱动设计:性能建模在早期至关重要
-
留有余量:带宽、面积、功耗都要留margin
-
迭代优化:设计是迭代过程,准备好多次优化
-
团队协作:优秀的架构需要整个团队的理解和执行
现在,你已经具备了设计CMN-700架构所需的知识和工具。真正的学习将在你开始第一个设计项目时开始。记住:每一个伟大的SoC背后,都有一个精心设计的互连网络。你的设计将决定数据的流动效率,从而决定整个芯片的性能上限。
祝你设计出卓越的CMN-700架构!