一.登录功能
1.需求

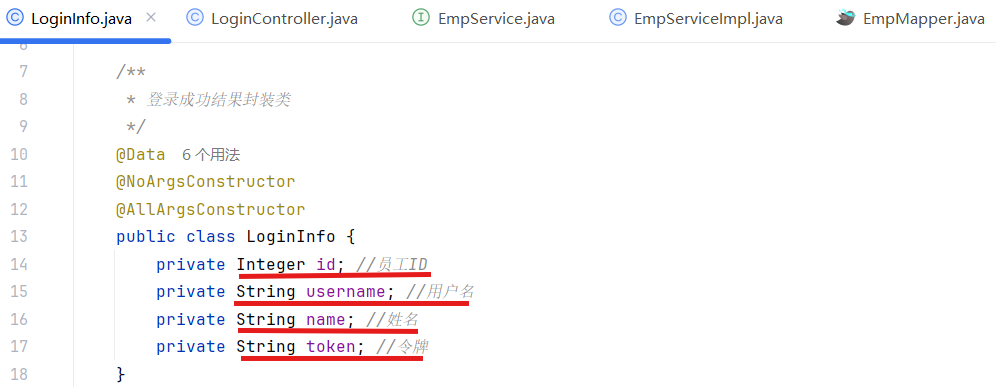
2.接口描述
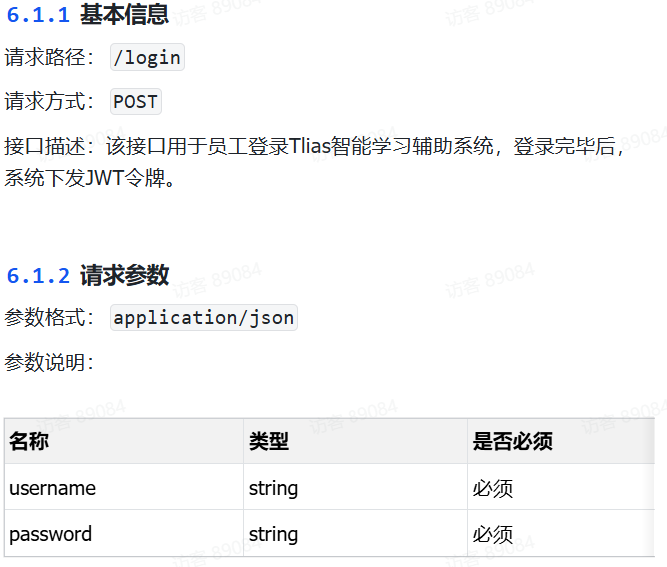
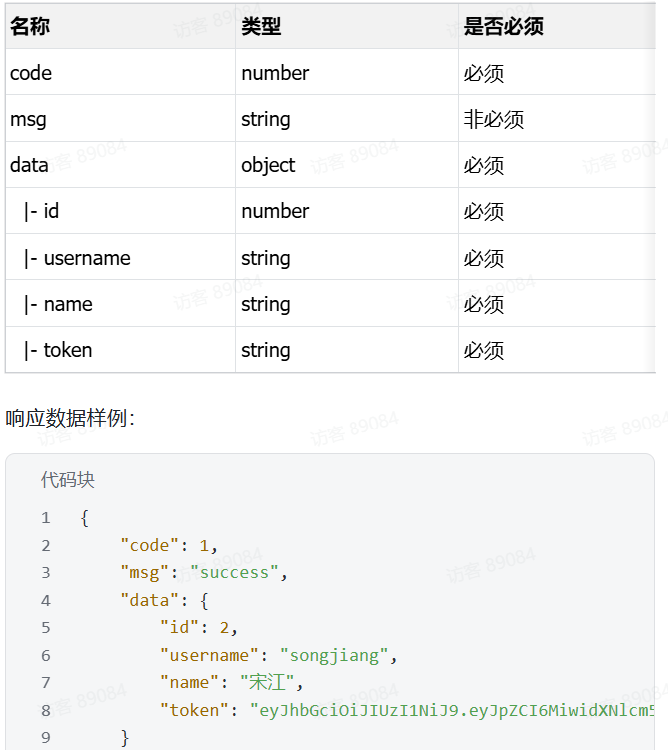
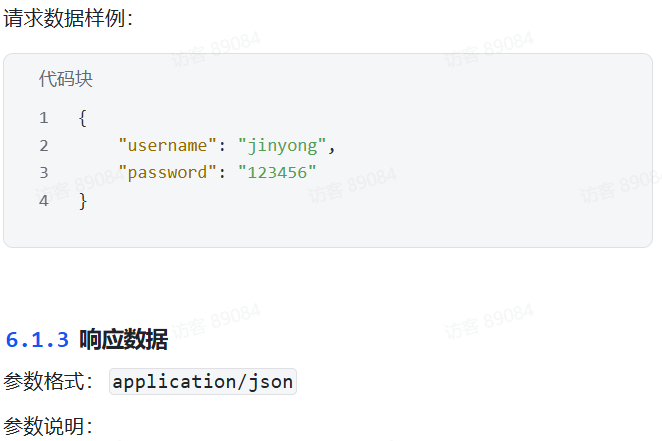 请求数据属性在emp有
请求数据属性在emp有
3.思路分析
-
怎么样才算登录成功了呢?
-
用户名和密码都输入正确,登录成功
-
否则,登录失败
-
-
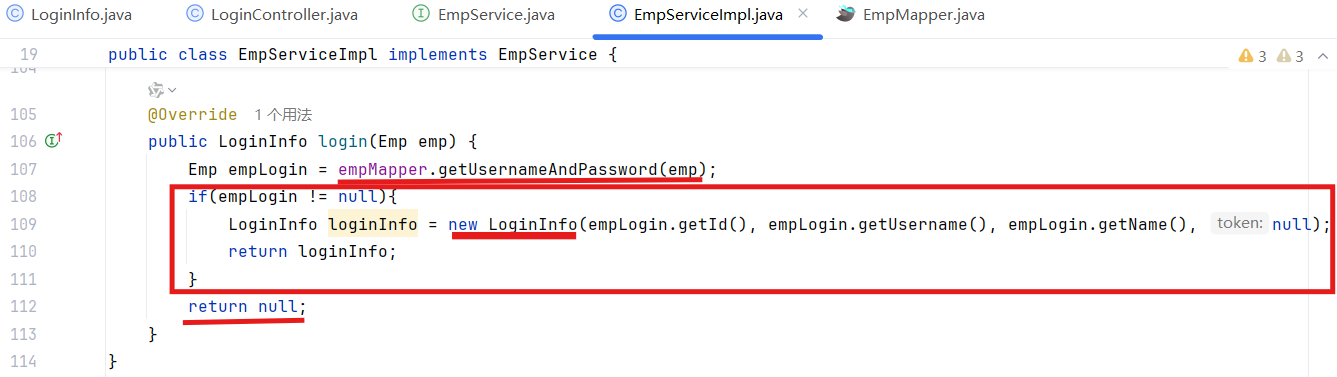
登录功能的本质是什么?
-
查询
-
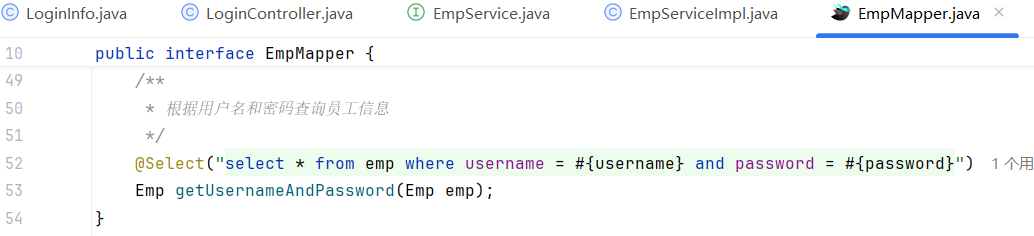
根据用户名和密码查询员工信息
-
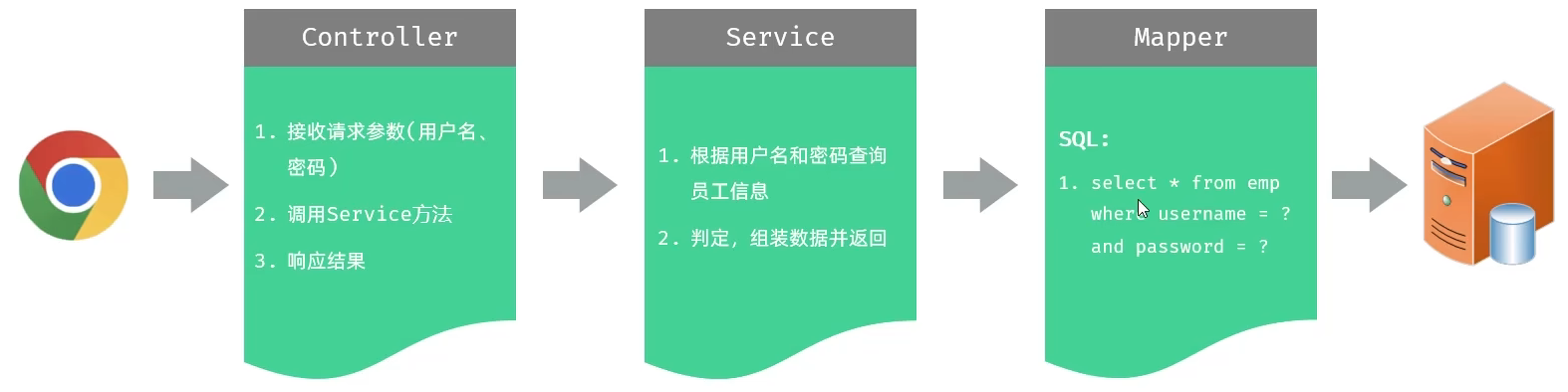
4.功能开发
请求数据属性在emp有
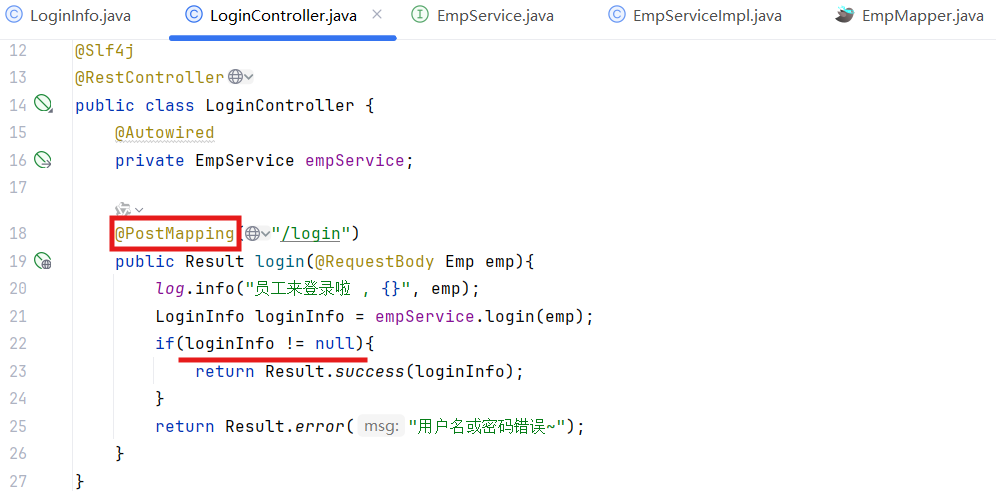
@PostMapping(即 POST 请求)主要是出于安全性、数据传输规范
(GET:用于获取资源(是 "读操作"),不应该用于提交敏感数据、修改数据;
POST:用于提交数据、创建资源(是 "写操作"),登录属于 "提交账号密码并请求认证" 的写操作场景,符合 POST 的语义。)
5.测试
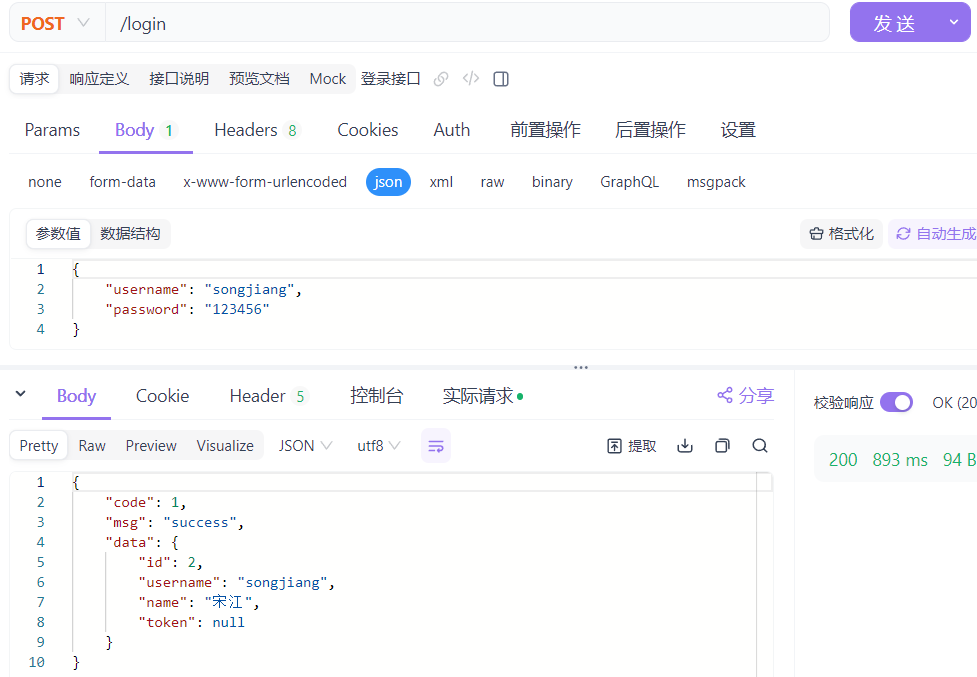
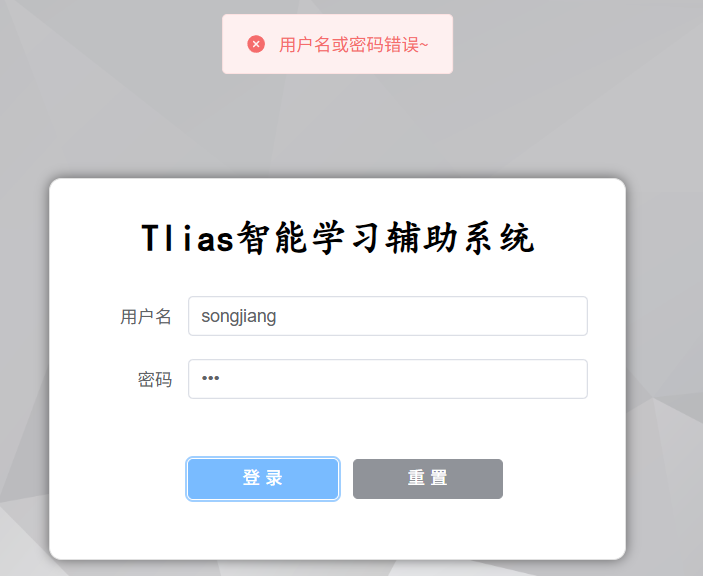
但是当我们在浏览器中新的页面上输入地址:http://localhost:90,发现没有登录仍然可以进入到后端管理系统页面。
而真正的登录功能应该是:登陆后才能访问后端系统页面,不登陆则跳转登陆页面进行登陆。
为什么会出现这个问题?因为针对于我们当前所开发的部门管理、员工管理以及文件上传等相关接口 来说,我们在服务器端并没有做任何的判断 ,没有去判断用户是否登录了。所以无论用户是否登录,都可以访问部门管理以及员工管理的相关数据。而我们要想解决这个问题,我们就需要完成一步非常重要的操作:登录校验。
二.登录校验
登录校验指的是我们在服务器端接收到浏览器发送过来的请求之后,首先我们要对请求进行校验。先要校验一下用户登录了没有,如果用户已经登录了,就直接执行对应的业务操作就可以了;如果用户没有登录,此时就不允许他执行相关的业务操作,直接给前端响应一个错误的结果,最终跳转到登录页面,要求他登录成功之后,再来访问对应的数据。
1.思路
前面在讲解HTTP协议的时候,我们提到HTTP协议是无状态协议。
所谓无状态,指的是每一次请求都是独立的,下一次请求并不会携带上一次请求的数据。而浏览器与服务器之间进行交互,基于HTTP协议也就意味着现在我们通过浏览器来访问了登陆这个接口,实现了登陆的操作,接下来我们在执行其他业务操作时,服务器也并不知道这个员工到底登陆了没有。因为HTTP协议是无状态的,两次请求之间是独立的,所以是无法判断这个员工到底登陆了没有。
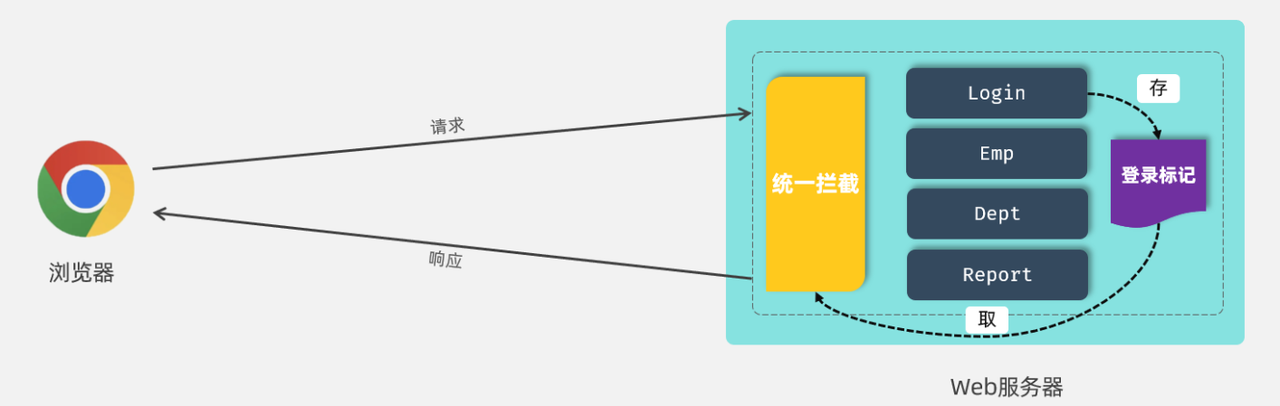
那应该怎么来实现登录校验的操作呢?具体的实现思路可以分为两部分:
-
在员工登录成功 后,需要将用户登录成功的信息存起来,记录用户已经登录成功的标记。
-
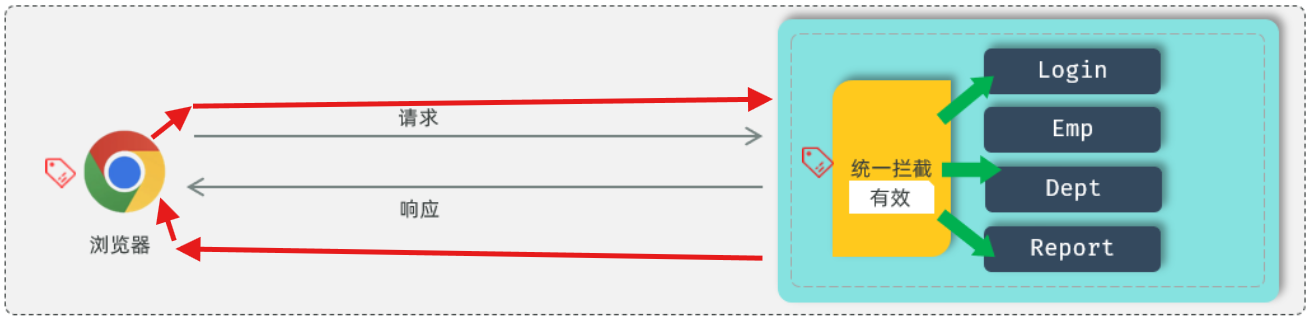
在浏览器发起请求 时,需要在服务端进行统一拦截 ,拦截后进行登录校验。

要完成以上操作,会涉及到web开发中的两个技术:
-
会话技术:用户登录成功之后,在后续的每一次请求中,都可以获取到该标记。
-
统一拦截技术:过滤器Filter、拦截器Interceptor
2.会话技术
1.介绍
在web开发当中,会话指的就是浏览器与服务器 之间的一次连接,我们就称为一次会话。

会话是和浏览器关联的,当有三个浏览器客户端和服务器建立了连接时,就会有三个会话;同一个浏览器在未关闭之前请求了多次服务器,这多次请求是属于同一个会话。当我们关闭浏览器之后,这次会话就结束了。而如果我们是直接把web服务器关了,那么所有的会话就都结束了。
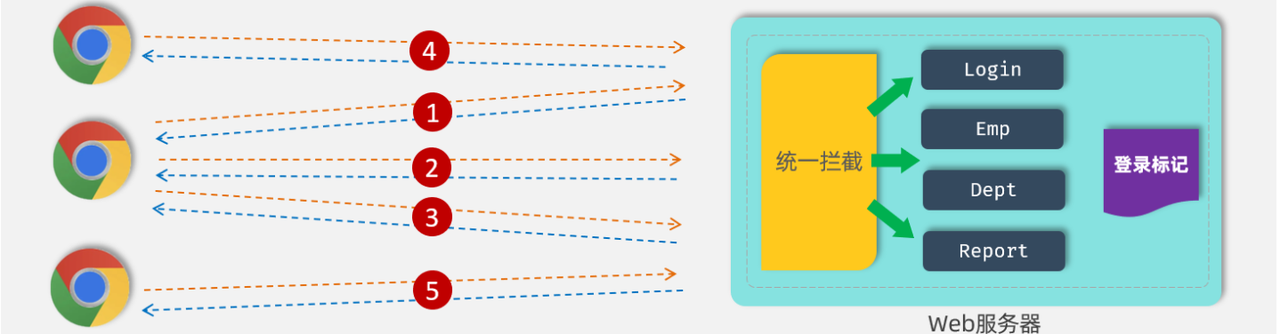
2.会话跟踪方案
会话跟踪: 一种维护浏览器状态 的方法,服务器 需要识别多次请求 是否来自于同一浏览器 ,以便在同一次会话的多次请求间共享数据。
(1)方案一:Cookie(客户端会话跟踪技术):数据存储在客户端浏览器当中
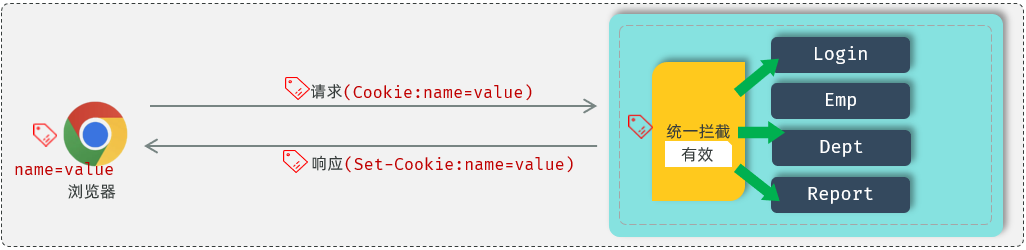
①在++浏览器第一次发起请求++ 来请求服务器的时候,++登录接口执行完成之后,++ 我们在服务器端来设置一个cookie 存储用户相关的一些数据信息(用户名,用户的ID)。服务器端在给客户端在++响应++ 数据的时候,会自动的将 cookie 响应给浏览器,②浏览器接收到响应回来的 cookie 之后,会自动 的将 cookie 的值++存储++在浏览器本地。③接下来在后续的每一次++请求++ 当中,都会将浏览器本地所存储的 cookie 自动 地++携带++到服务端。
接下来在服务端就可以获取到 cookie 的值。判断一下这个 cookie 的值是否存在。
(为什么这一切都是自动化进行的?
cookie 是 HTTP 协议当中所支持的技术。在 HTTP 协议官方提供了一个响应头和请求头:
-
响应头 Set-Cookie :设置Cookie数据的
-
请求头 Cookie:携带Cookie数据的
 )
)

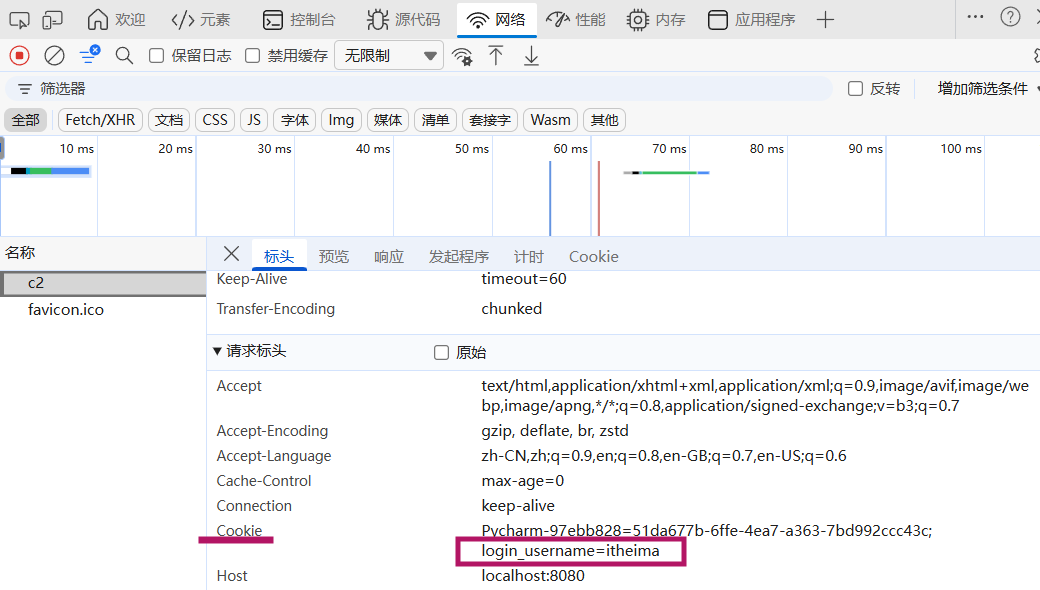
A. 访问c1接口,设置Cookie,http://localhost:8080/c1
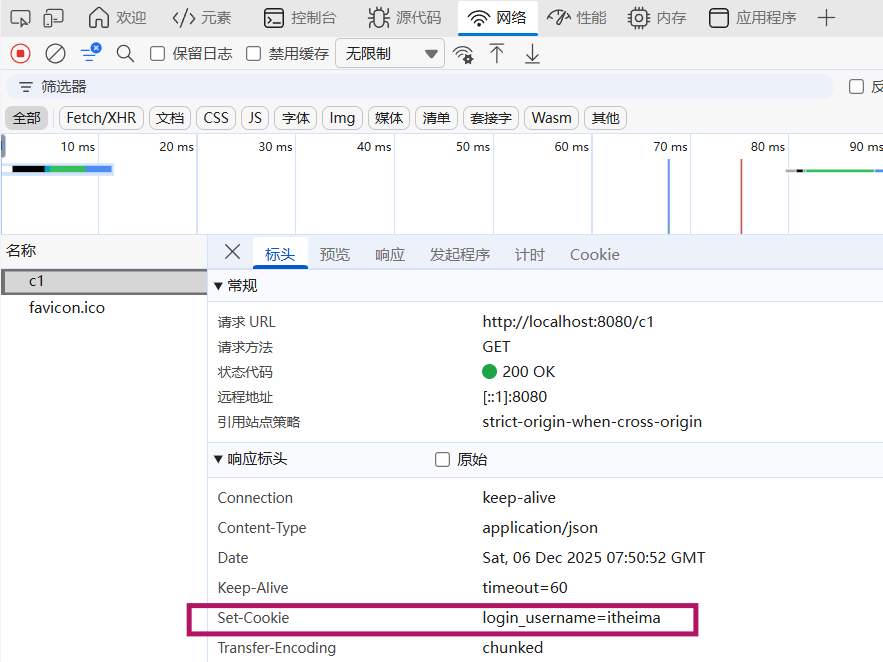
我们可以看到,设置的cookie,通过**响应头Set-Cookie**响应给浏览器,并且浏览器会将Cookie,存储在浏览器端。
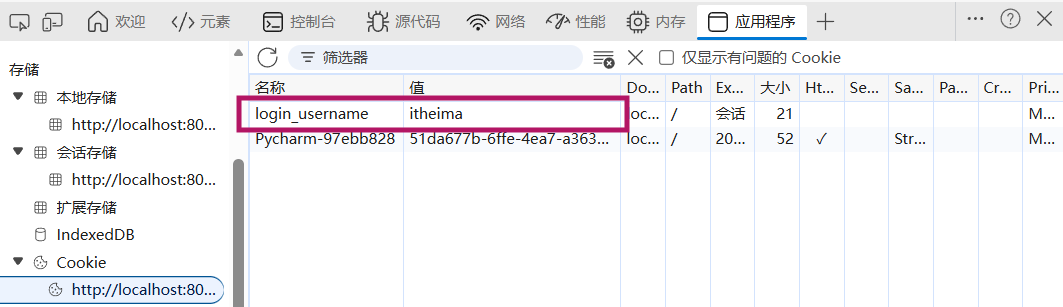
B. 访问c2接口 http://localhost:8080/c2,此时浏览器会自动的将Cookie携带到服务端,是通过**请求头Cookie**,携带的。
优缺点:

跨域介绍:
-
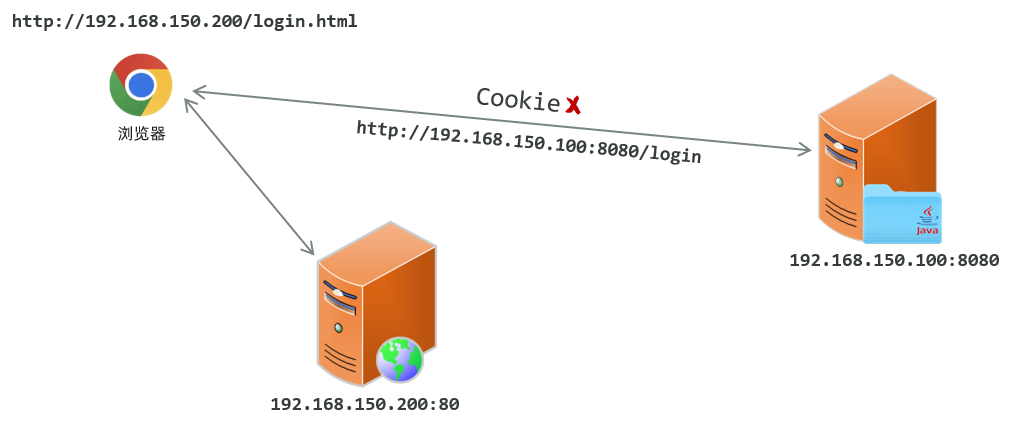
现在的项目,大部分都是前后端分离的,前后端最终也会分开部署,前端部署在服务器 192.168.150.200 上,端口 80,后端部署在 192.168.150.100上,端口 8080
-
我们打开浏览器直接访问前端工程,访问url:http://192.168.150.200/login.html
-
然后在该页面发起请求到服务端,而服务端所在地址不再是localhost,而是服务器的IP地址192.168.150.100,假设访问接口地址为:http://192.168.150.100:8080/login
-
那此时就存在跨域操作了,因为我们是在 http://192.168.150.200/login.html 这个页面上访问了http://192.168.150.100:8080/login 接口
-
此时如果服务器设置了一个Cookie,这个Cookie是不能使用的,因为Cookie无法跨域
区分跨域的维度(三个维度有任何一个维度不同,那就是跨域操作):协议 ,IP/协议 ,端口
举例:
-
http://192.168.150.200/login.html ----------> https://192.168.150.200/login 协议不同,跨域
-
http://192.168.150.200/login.html ----------> http://192.168.150.100/login IP不同,跨域
-
http://192.168.150.200/login.html ----------> http://192.168.150.200:8080/login 端口不同,跨域
-
http://192.168.150.200/login.html ----------> http://192.168.150.200/login 不跨域
(2)方案二:Session(服务端会话跟踪技术):数据存储在储在服务端
- 获取Session
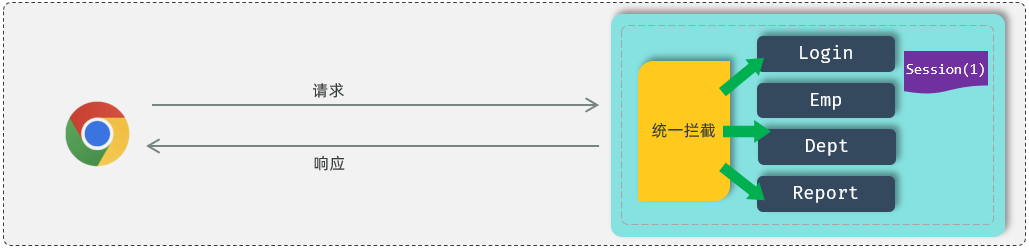
浏览器++在第一次请求服务器++ 的时候,我们就可以直接在服务器当中来获取到会话对象Session 。如果是第一次请求Session ,会话对象是不存在的,这个时候服务器会自动的创建一个会话对象Session 。而++每一个会话对象Session ,它都有一个ID++(示意图中Session后面括号中的1,就表示ID),我们称之为 Session 的ID。
- 响应Cookie (JSESSIONID)
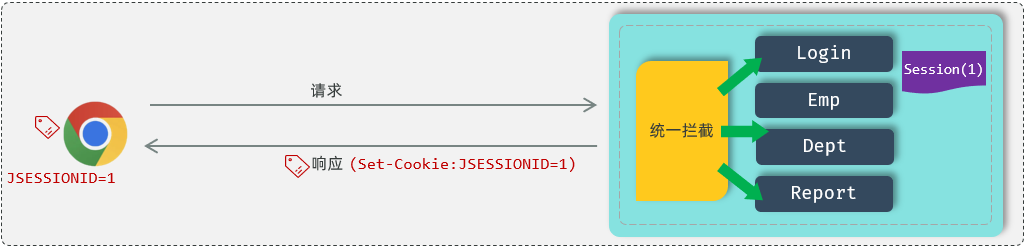
接下来,服务器端在给浏览器响应数据的时候,它会将**++Session 的 ID 通过 Cookie++响应给浏览器** 。cookie 的名字是固定的++JSESSIONID++ 代表的服务器端会话对象 Session 的 ID。浏览器会自动识别这个响应头,然后自动将Cookie存储在浏览器本地。
- 查找Session
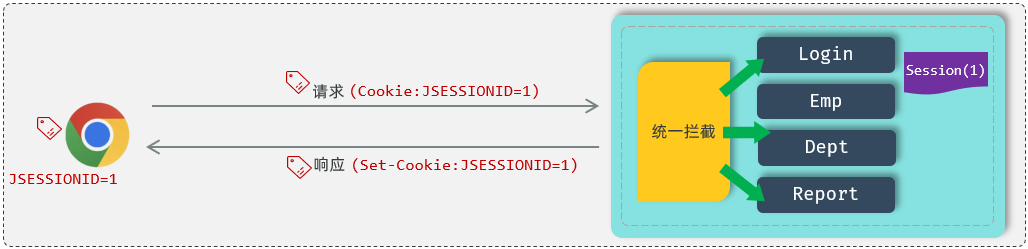
接下来,在后续的每一次请求当中,都会将Cookie 的数据获取 出来,并且携带到服务端 。接下来服务器拿到JSESSIONID这个 Cookie 的值,也就是 Session 的ID。拿到 ID 之后,就会从众多的 Session 当中来找到当前请求对应的会话对象Session。
pom.xml引入Servlet API 依赖:
XML
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>javax.servlet-api</artifactId>
<version>4.0.1</version>
<scope>provided</scope>
</dependency>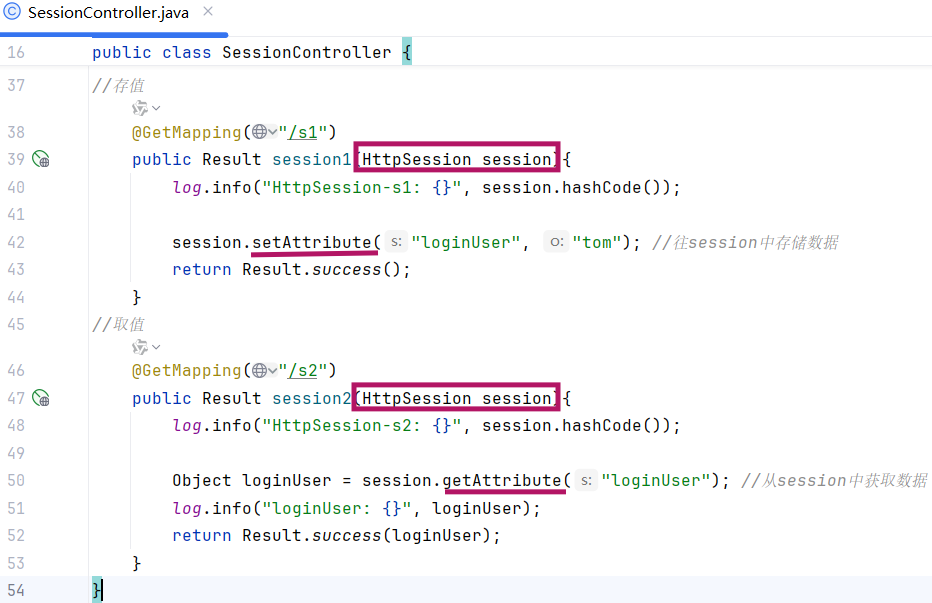
A. 访问 s1 接口,http://localhost:8080/s1
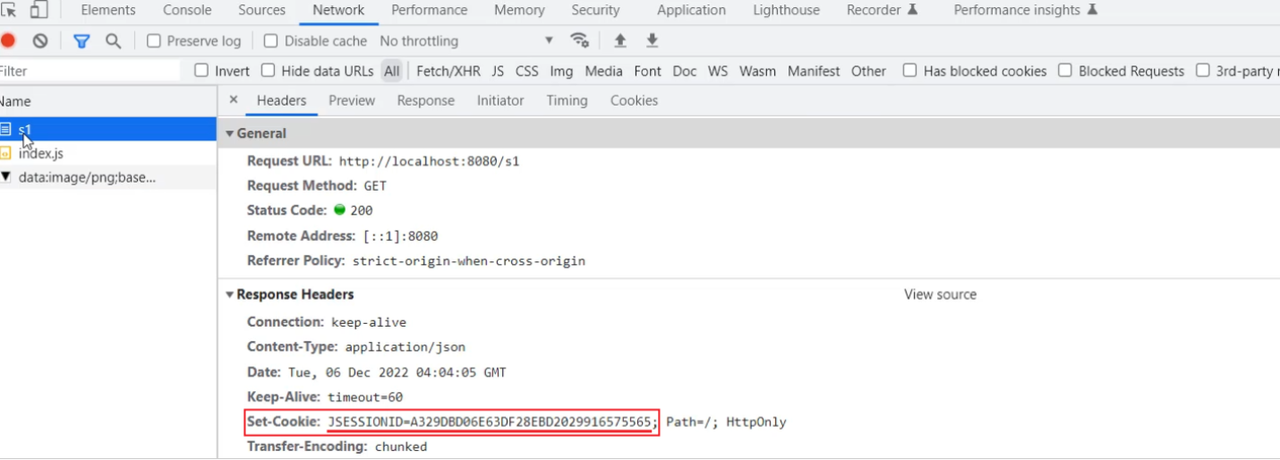
请求完成之后,在响应头中,就会看到有一个Set-Cookie的响应头,里面响应回来了一个Cookie,就是JSESSIONID,这个就是服务端会话对象 Session 的ID。
B. 访问 s2 接口,http://localhost:8080/s2
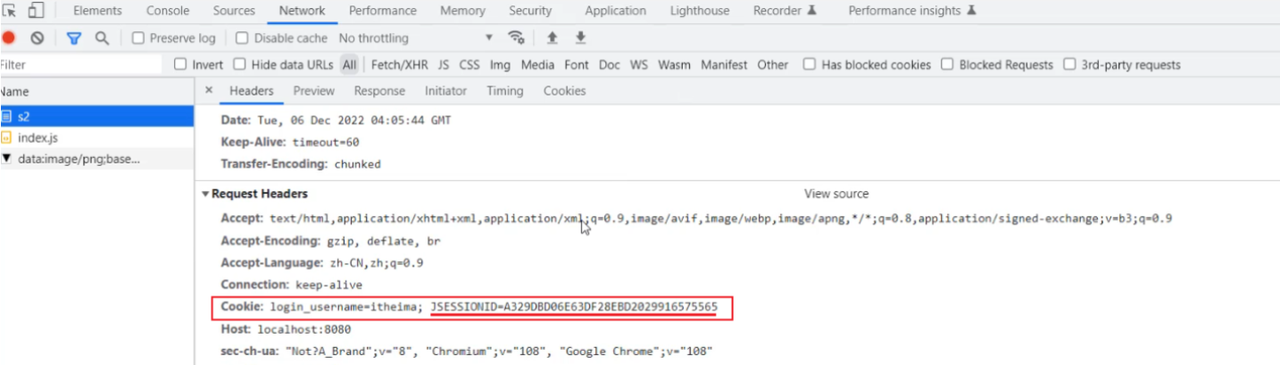
接下来,在后续的每次请求时,都会将Cookie的值,携带到服务端,那服务端呢,接收到Cookie之后,会自动的根据JSESSIONID的值,找到对应的会话对象Session。
那经过这两步测试,在控制台中输出如下日志:

两次请求,获取到的Session会话对象的hashcode是一样的,就说明是同一个会话对象。而且,第一次请求时,往Session会话对象中存储的值,第二次请求时,也获取到了。 那这样,我们就可以通过Session会话对象,在同一个会话的多次请求之间来进行数据共享了。
优缺点:


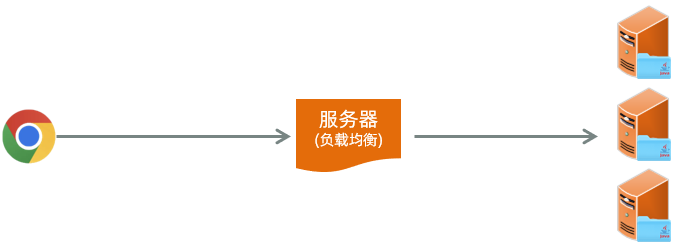
服务器集群环境为何无法使用Session?
- 首先第一点,我们现在所开发的项目,一般都不会只部署在一台服务器上,因为一台服务器会存在一个很大的问题,就是单点故障。所谓单点故障,指的就是一旦这台服务器挂了,整个应用都没法访问了。
所以在现在的企业项目开发当中,最终部署的时候都是以集群的形式来进行部署,也就是同一个项目它会部署多份。比如这个项目我们现在就部署了 3 份。
用户在访问的时候,他会访问一台前置的服务器,++负载均衡服务器:++ 将前端发起的请求均匀的分发给后面的这三台服务器。
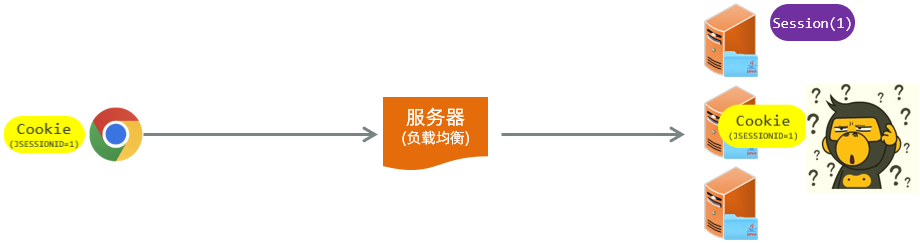
- 此时假如我们通过 session 来进行会话跟踪,可能就会存在这样一个问题。用户打开浏览器要进行登录操作,此时会发起登录请求。登录请求到达负载均衡服务器,将这个请求转给了++第一台 Tomca++ t 服务器。Tomcat 服务器接收到请求之后,要获取到会话对象session。获取到会话对象 session 之后,要给浏览器响应数据,最终在给浏览器响应数据的时候,就会携带这么一个 cookie 的名字,就是 JSESSIONID ,下一次再请求的时候,又会将 Cookie 携带到服务端.此时假如又执行了一次查询操作,要查询部门的数据。这次请求到达负载均衡服务器之后,负载均衡服务器将这次请求++转给了第二台++Tomcat 服务器,此时他就要到第二台 Tomcat 服务器当中。根据JSESSIONID 也就是对应的 session 的 ID 值,要找对应的 session 会话对象。在第二台服务器当中没有这个ID的会话对象 Session。此时同一个浏览器发起了 2 次请求,结果获取到的不是同一个会话对象,在服务器集群环境下无法直接使用Session。
| 维度 | Cookie | Session |
|---|---|---|
| 数据存储位置 | 客户端(浏览器) | 服务器端(内存 / 数据库 / Redis) |
| 交互依赖 | 直接在请求 / 响应中携带自身数据 | 依赖 Cookie(或 URL)传递 SessionID |
| 安全性 | 较低(存在客户端,可被篡改) | 较高(数据存在服务器,仅传 ID) |
| 存储容量 | 有限(一般单个 Cookie≤4KB) | 较大(由服务器资源决定) |
Cookie 是 "客户端存数据,自己带数据";Session 是 "服务器存数据,只带 ID(靠 Cookie 传 ID)"
(3)方案三-令牌技术(常用)
令牌是一个用户身份的标识,本质是一个字符串。
如果通过令牌技术来跟踪会话,我们就可以在++浏览器发起请求++ 。在请求登录接口的时候,如果登录成功,我就可以生成一个++令牌++ ,令牌就是用户的合法身份凭证。接下来在响应数据的时候,就可以直接++将令牌响应给前端++。
接下来前端程序当中接收到令牌之后,就需要将这个令牌++存储++起来。这个存储可以存储在 cookie 当中,也可以存储在其他的存储空间(比如:localStorage)当中。
接下来在后续的++每一次请求++ 当中,都需要++将令牌携带到服务端++。携带到服务端之后,接下来我们就需要来校验令牌的有效性。
优缺点:

3.JWT令牌
JWT令牌最典型的应用场景就是登录认证:
-
在浏览器发起请求来执行登录操作,此时会访问登录的接口,如果登录成功之后,我们需要生成一个jwt令牌,将生成的 jwt令牌返回给前端。
-
前端拿到jwt令牌之后,会将jwt令牌存储起来。在后续的每一次请求中都会将jwt令牌携带到服务端。
-
服务端统一拦截请求之后,先来判断一下这次请求有没有把令牌带过来,如果没有带过来,直接拒绝访问,如果带过来了,还要校验一下令牌是否是有效。如果有效,就直接放行进行请求的处理。

1.介绍


JWT是如何将原始的JSON格式数据,转变为字符串的呢?
-
其实在生成JWT令牌时,会对JSON格式的数据进行一次编码:进行base64编码
-
Base64:是一种基于64个可打印的字符(A到Z、a到z、 0- 9,一个加号,一个斜杠)来表示二进制数据的编码方式。还有一个符号,那就是等号,是一个补位的符号。
-
需要注意的是Base64是编码方式 ,而不是加密方式。头部指定的alg才是签名算法,凭此来加密。
2.两步操作:生成和校验
XML
<!-- JWT依赖-->
<dependency>
<groupId>io.jsonwebtoken</groupId>
<artifactId>jjwt</artifactId>
<version>0.9.1</version>
</dependency>在引入完JWT来赖后,就可以调用工具包中提供的API来完成JWT令牌的生成和校验。工具类:Jwts
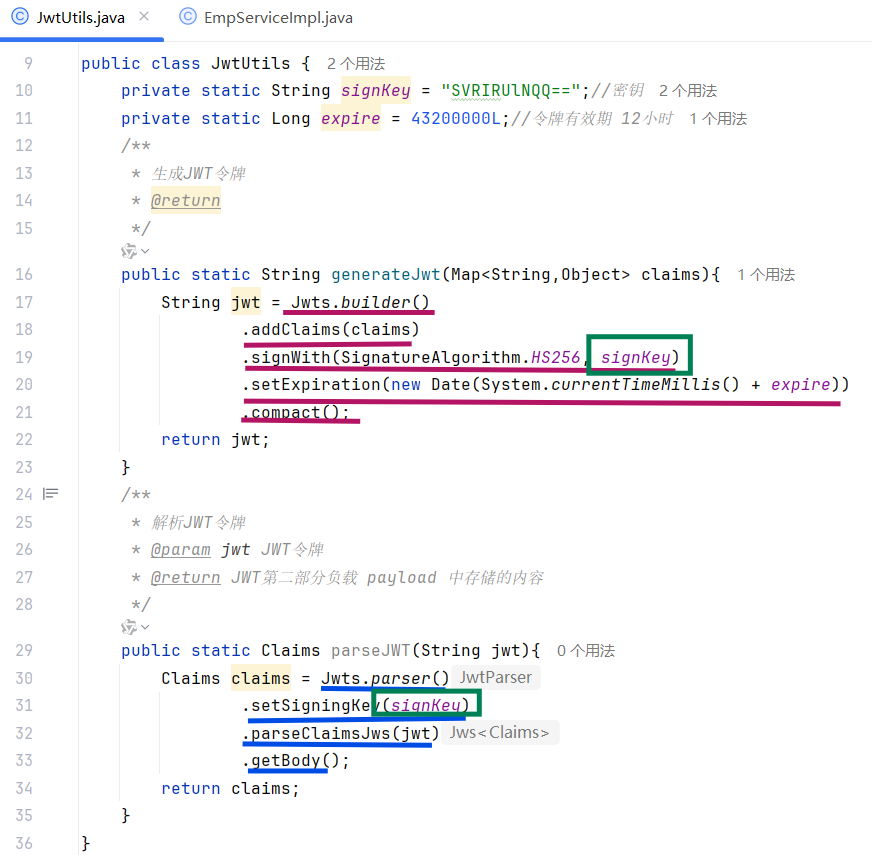
1.生成JWT(Jwts.builder())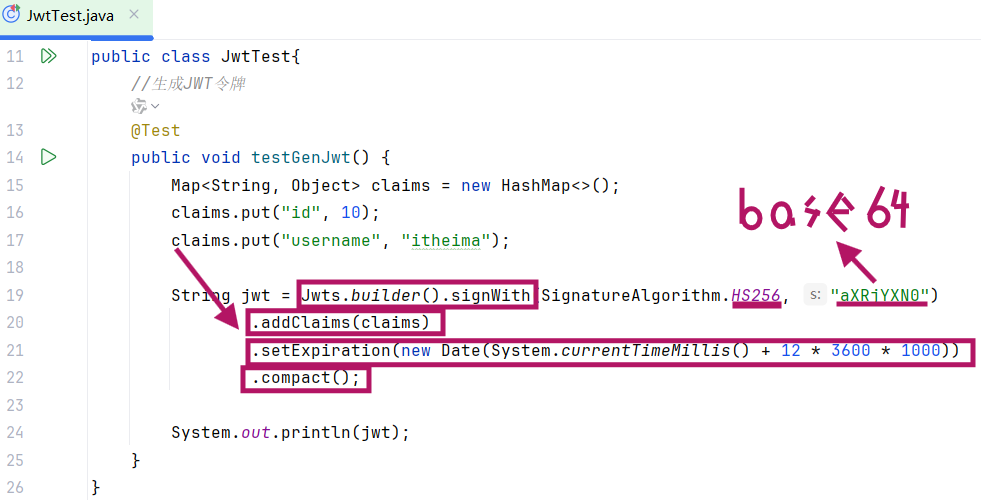
- signWith(SignatureAlgorithm.HS256, "aXR1YXNOI"):使用HS256 对称加密算法 ,并指定密钥 (此处密钥为aXR1YXNOI,生产环境需使用复杂密钥)。
- addClaims(claims):将自定义声明 添加到 JWT 中。
- setExpiration(...):设置令牌过期时间 (此处为当前时间 + 12 小时)。
- compact():生成最终的 JWT 字符串 (由 Header、Payload、Signature 三部分组成,以.分隔,各部分均为 Base64 编码)。

我们可以将生成的令牌复制一下,然后打开JWT的官网,将生成的令牌直接放在Encoded位置,此时就会自动的将令牌解析出来。
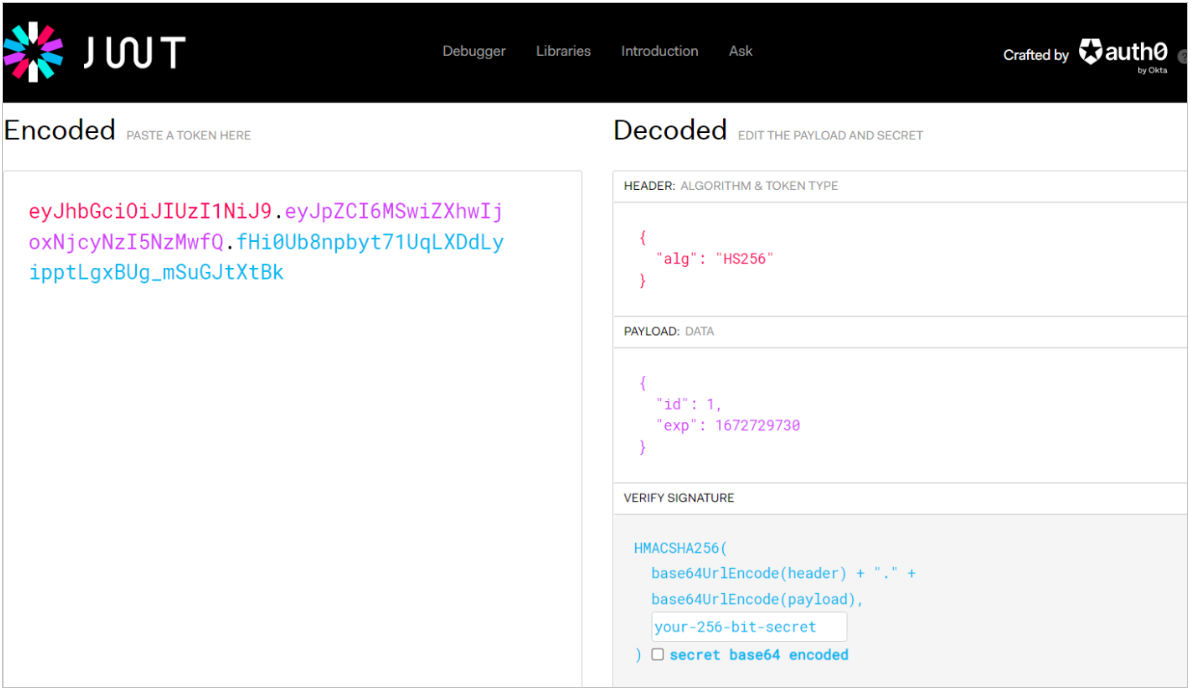
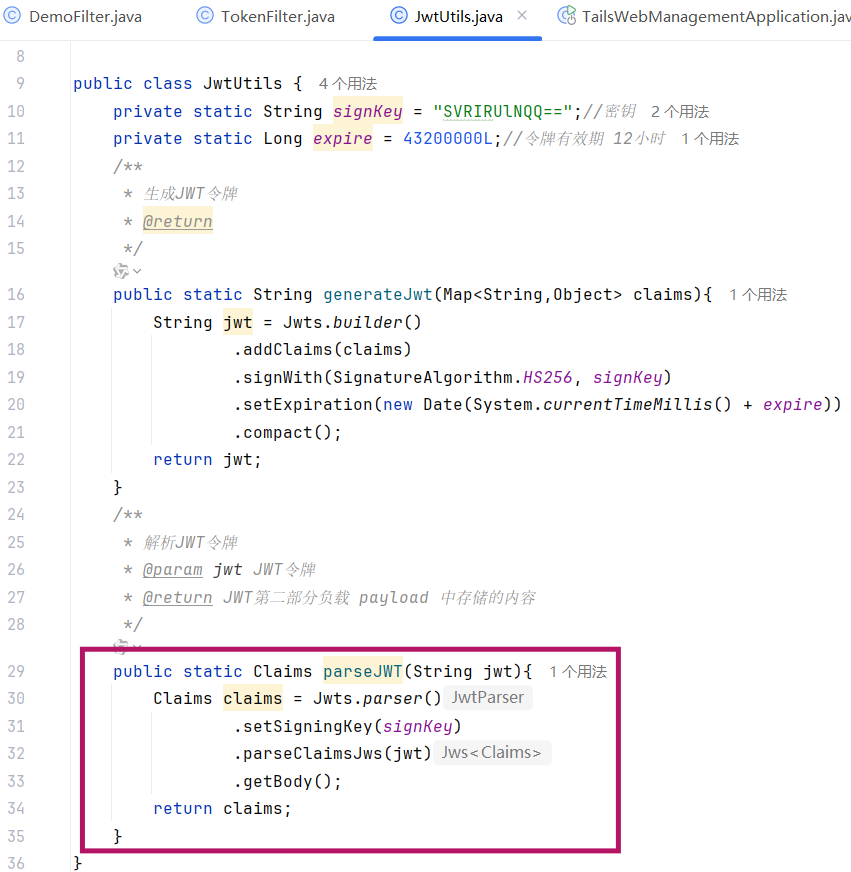
2.校验JWT令牌(解析生成的令牌)(Jwts.parser())
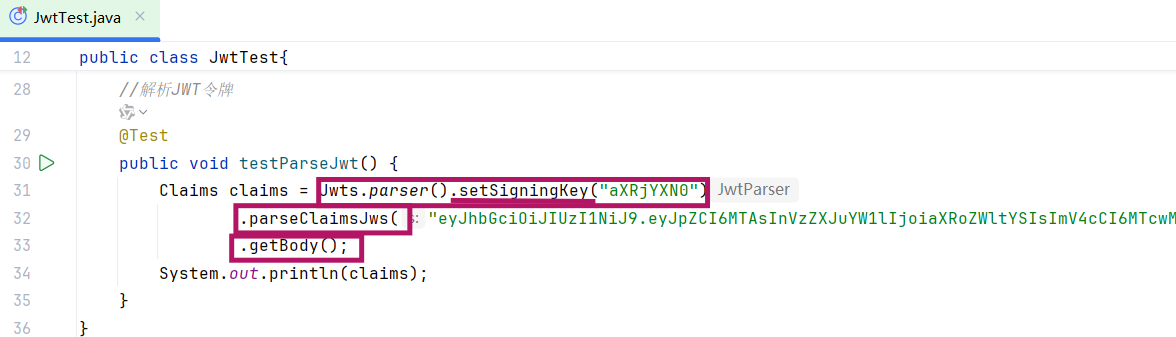
- setSigningKey("aXR1YXNOI"):设置与生成令牌时一致的密钥 (需完全匹配,否则解析失败);
- parseClaimsJws(...):传入 JWT 字符串,验证 令牌的签名合法性、是否过期;
- getBody():获取 JWT 的 Payload 部分 (即生成令牌时存入的自定义声明Claims )。


3.登录时下发令牌
1.引入JWT工具类
2.完善 EmpServiceImpl中的 login 方法逻辑, 登录成功,生成JWT令牌并返回
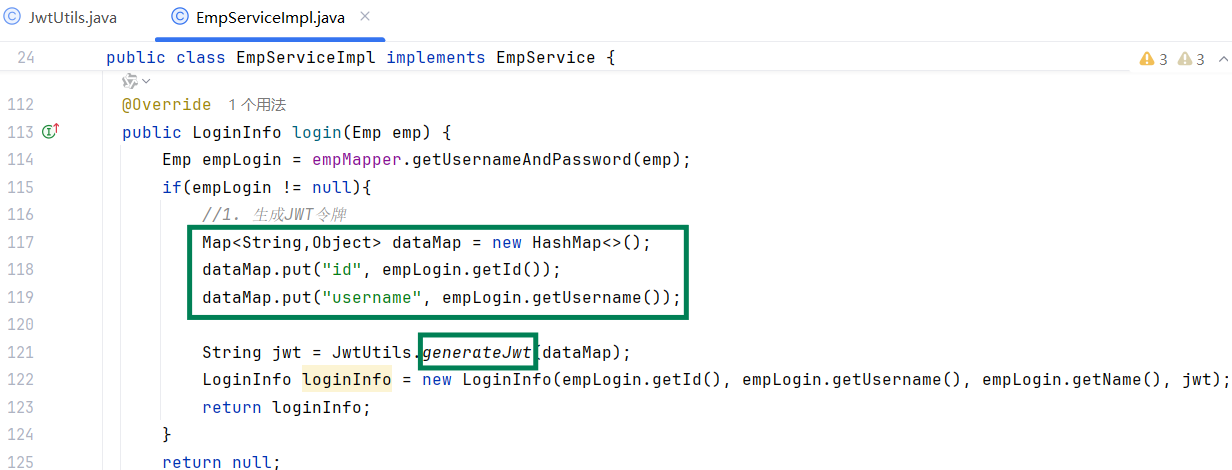
测试:
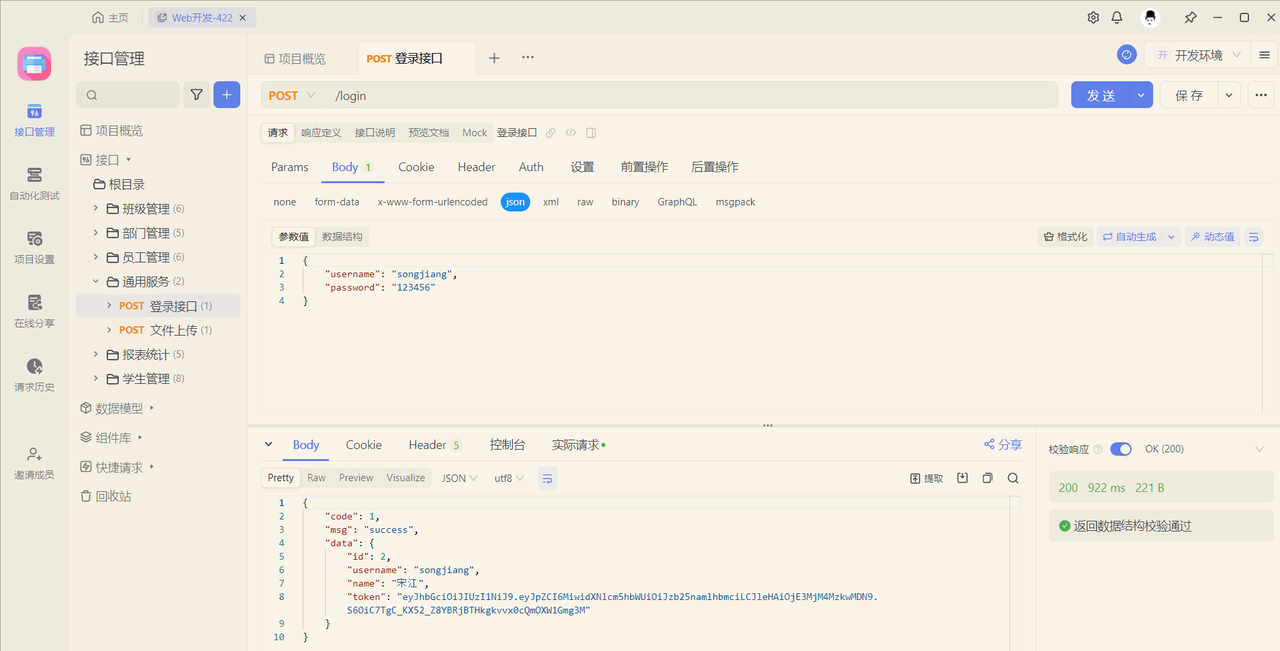
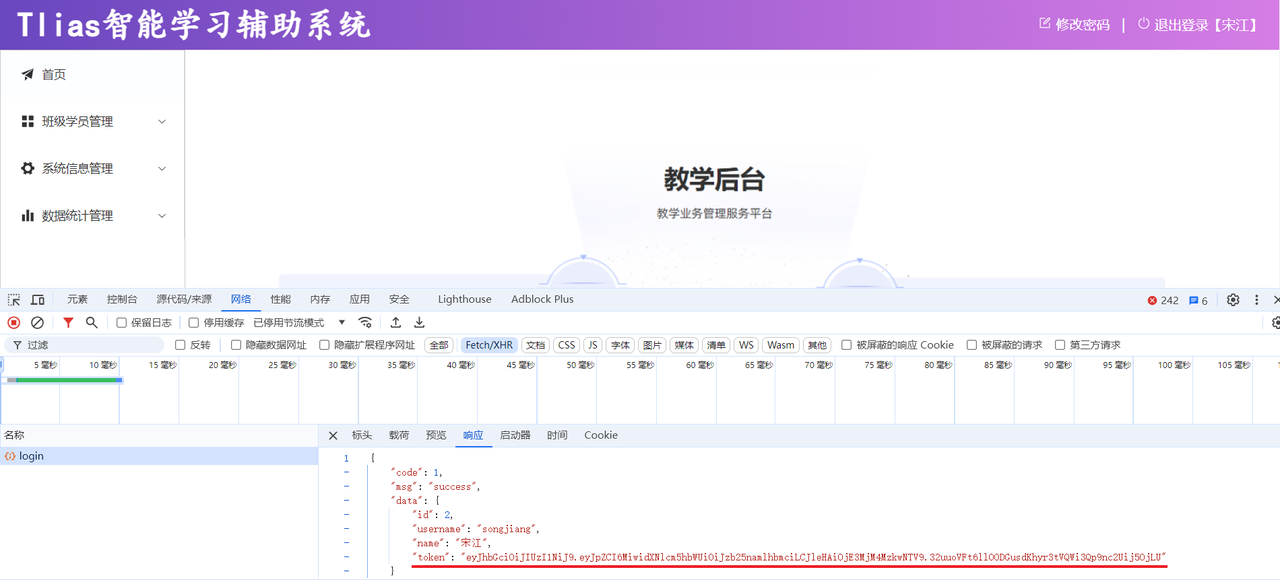
服务器响应的JWT令牌存储在本地浏览器哪里了呢?
在当前案例中,JWT令牌存储在浏览器的本地存储空间 localstorage**(前端自己存)**中了。 localstorage 是浏览器的本地存储,在移动端也是支持的。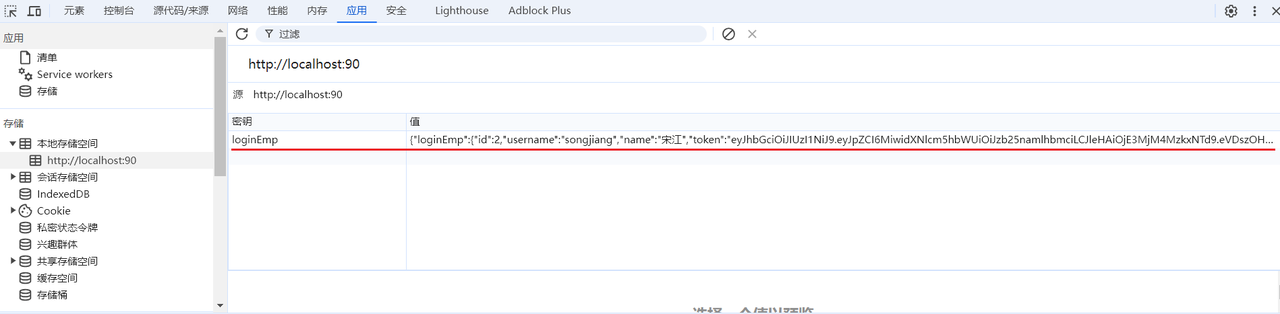
我们在发起一个查询部门数据的请求,此时我们可以看到在请求头中包含一个token(JWT令牌),后续的每一次请求当中,都会将这个令牌携带到服务端。

| 维度 | Cookie/Session | Token(如 JWT) |
|---|---|---|
| 数据存储位置 | Session 存在服务器,Cookie 存在客户端 | 无服务器存储(JWT 是自包含令牌,Token 本身带用户信息);若用 Redis 存 Token 黑名单,仅存 "无效 Token" |
| 交互方式 | 依赖 Cookie 自动携带 SessionID | 前端手动在请求头 / 参数中携带 Token |
| 分布式 / 跨域支持 | 差(Session 存在单台服务器,跨域需配置 Cookie 跨域) | 好(Token 无状态,任意服务器都能解析验证,跨域只需前端在请求头带 Token) |
| 安全性 | Session 安全(数据在服务端),但 Cookie 易被 CSRF | 需防 XSS(Token 存在前端存储,XSS 会窃取),但天然防 CSRF(无自动携带机制) |
| 过期 / 注销 | Session 可服务端主动销毁,Cookie 可设置过期 | JWT 本身无法主动注销(需配合 Redis 黑名单),可设置短期过期 + 刷新令牌(Refresh Token) |
4.过滤器filter
通过浏览器的开发者工具,我们可以看到在后续的请求当中,都会在请求头中携带JWT令牌到服务端,而服务端需要统一拦截所有的请求,从而判断是否携带的有合法的JWT令牌。
那怎么样来统一拦截到所有的请求校验令牌的有效性呢?这里有两种解决方案:
-
Filter过滤器
-
Interceptor拦截器
1.Filter快速入门

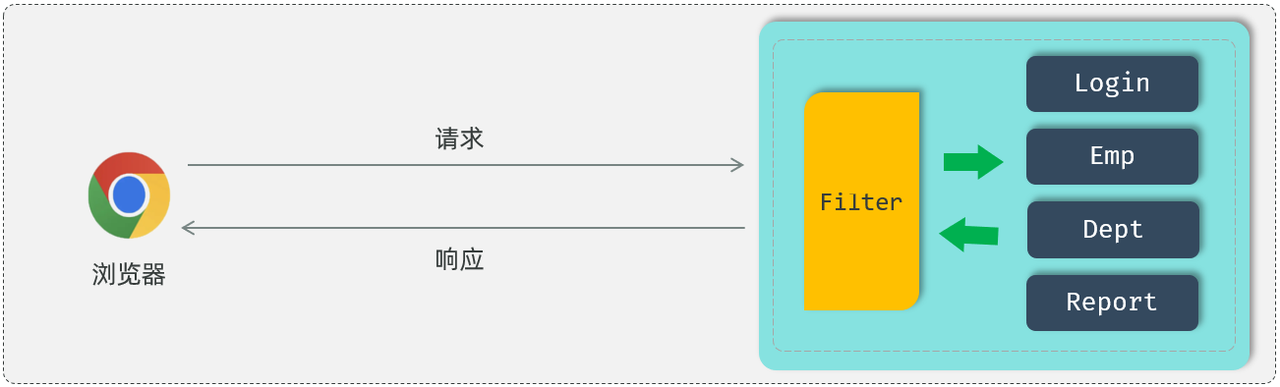
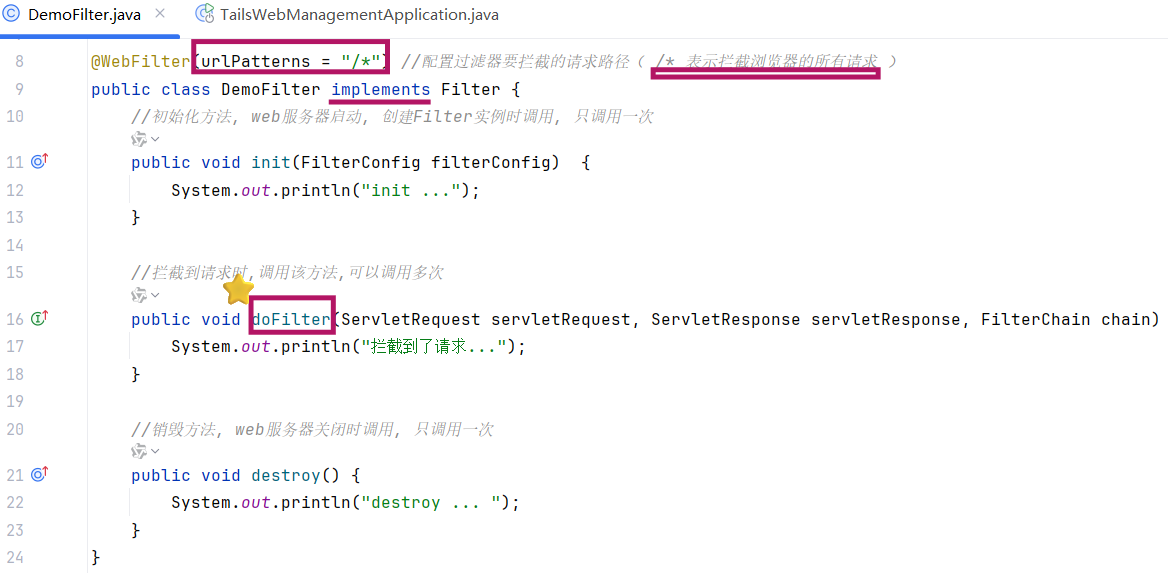
Filter快速入门程序掌握过滤器的基本使用操作:
-
第1步,定义过滤器 :1.定义一个类,++实现 Filter 接口,并重写其所有方法++。
-
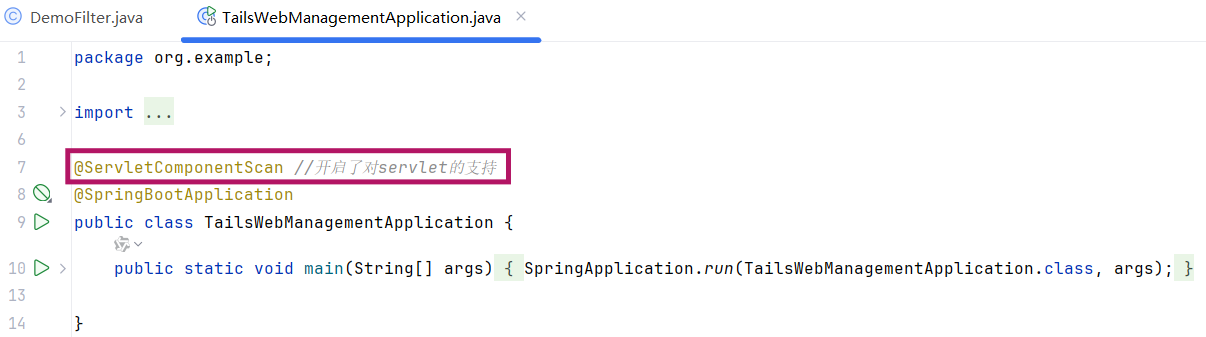
第2步,配置过滤器:++Filter类++ 上加 @WebFilter 注解,配置拦截资源的路径。++引导类++ 上加 @ServletComponentScan 开启Servlet组件支持。




2.登录校验过滤器
(1)分析
回顾下前面分析过的登录校验的基本流程:
-
要进入到后台管理系统,我们必须先完成登录操作,此时就需要访问登录接口login。
-
登录成功之后,我们会在服务端生成一个JWT令牌,并且把JWT令牌返回给前端,前端会将JWT令牌存储下来。
-
在后续的每一次请求当中,都会将JWT令牌携带到服务端,请求到达服务端之后,要想去访问对应的业务功能,此时我们必须先要校验令牌的有效性。
-
对于校验令牌的这一块操作,我们使用登录校验的过滤器,在过滤器当中来校验令牌的有效性。如果令牌是无效的,就响应一个错误的信息,也不会再去放行访问对应的资源了。如果令牌存在,并且它是有效的,此时就会放行去访问对应的web资源,执行相应的业务操作。
大概清楚了在Filter过滤器的实现步骤了,那在正式开发登录校验过滤器之前,两个问题:
-
所有的请求,拦截到了之后,都需要校验令牌吗 ?
答案:登录请求例外,它是令牌的 "生产环节",而非 "使用环节"
-
拦截到请求后,什么情况下才可以放行,执行业务操作 ?
答案:有令牌,且令牌校验通过(合法);否则都返回未登录错误结果
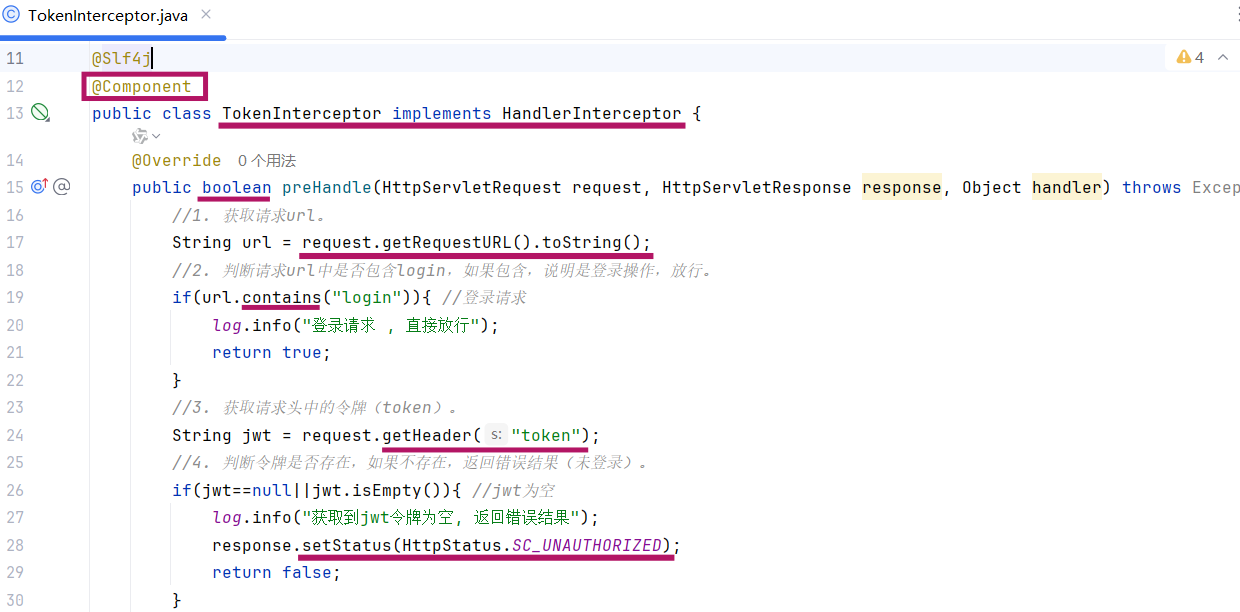
(2)具体流程
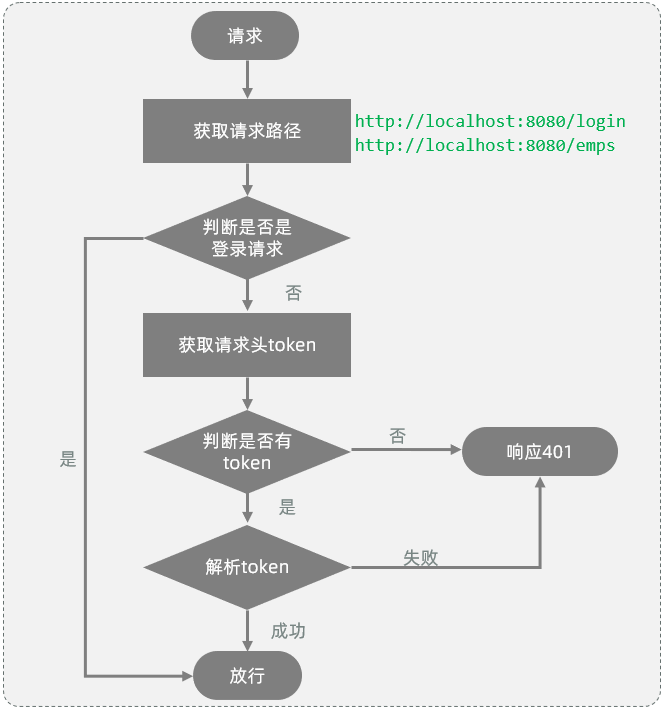
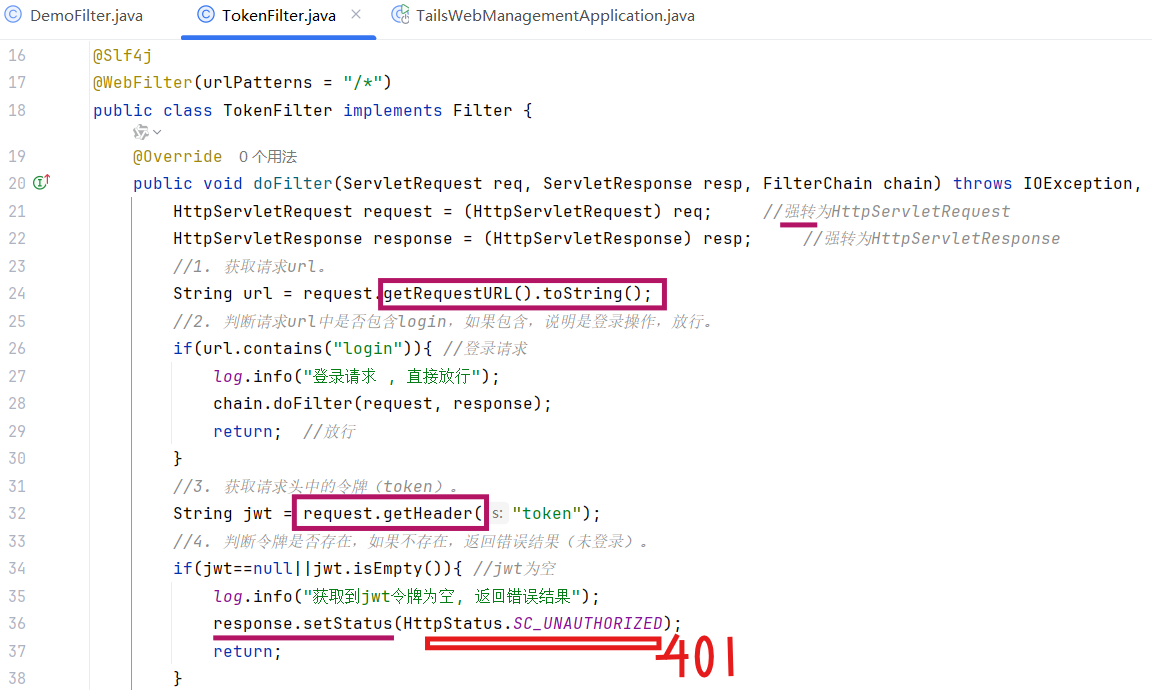
-
获取请求url
-
判断请求url中是否包含login,如果包含,说明是登录操作,放行
-
获取请求头中的jwt令牌(token)
-
判断令牌是否存在,如果不存在,响应 401
-
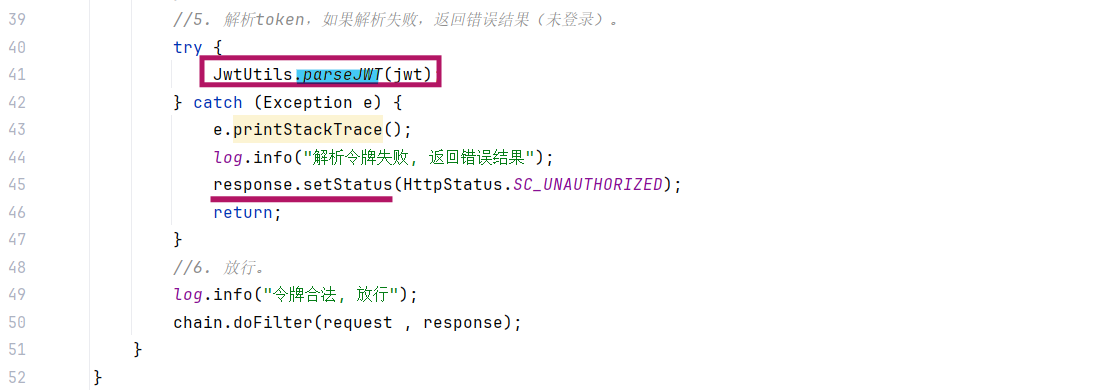
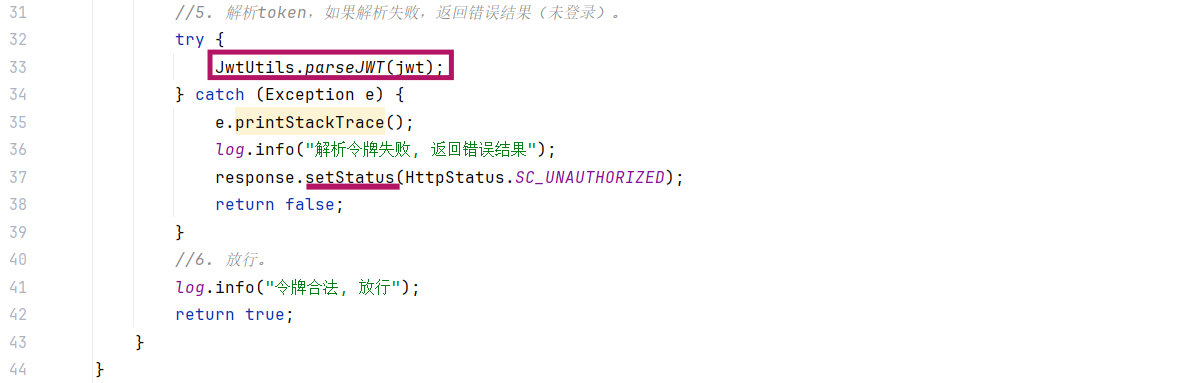
解析token,如果解析失败,响应 401
-
放行
(3)代码实现(doFilter方法没有返回值 直接return代表结束)
(
 )
)
3.Filter详解
(1)执行流程
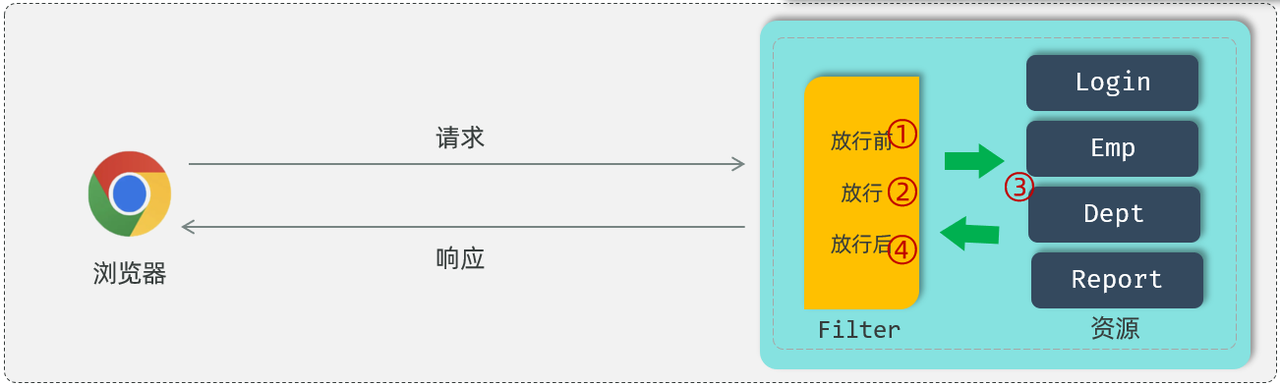
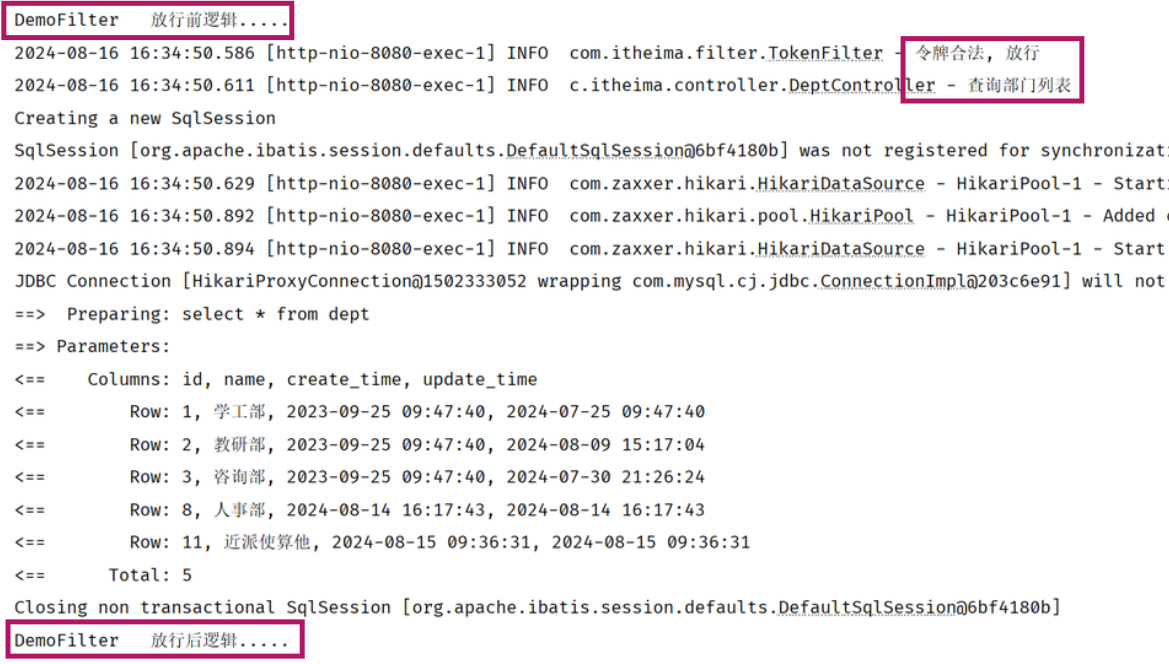
过滤器当中我们拦截到了请求之后,如果希望继续访问后面的web资源,就要执行放行操作,放行就是调用 FilterChain对象当中的doFilter()方法,在调用chain.doFilter()这个方法之前所编写的代码属于放行之前的逻辑。
在放行后访问完 web 资源之后还会回到过滤器当中,回到过滤器之后如有需求还可以执行放行之后的逻辑,放行之后的逻辑我们写在doFilter()这行代码之后。
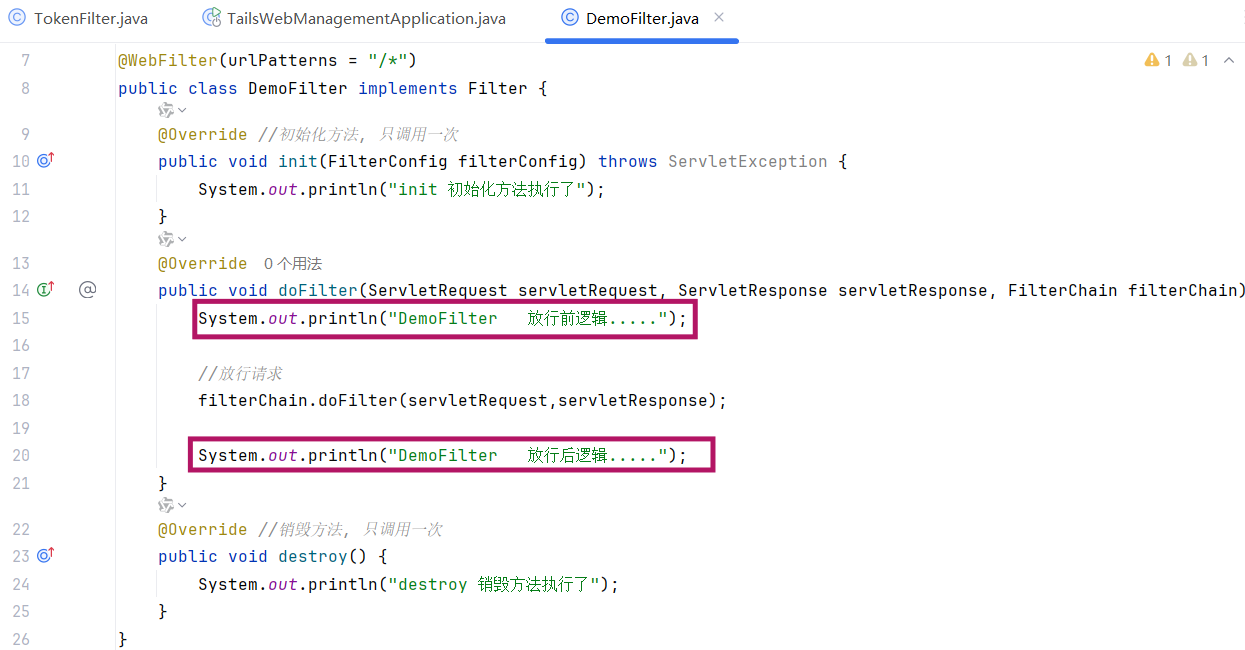

(2)拦截路径
Filter可以根据需求,配置不同的拦截资源路径:

(3)过滤器链
过滤器链指的是在一个web应用程序当中,可以配置多个过滤器,多个过滤器就形成了一个过滤器链。
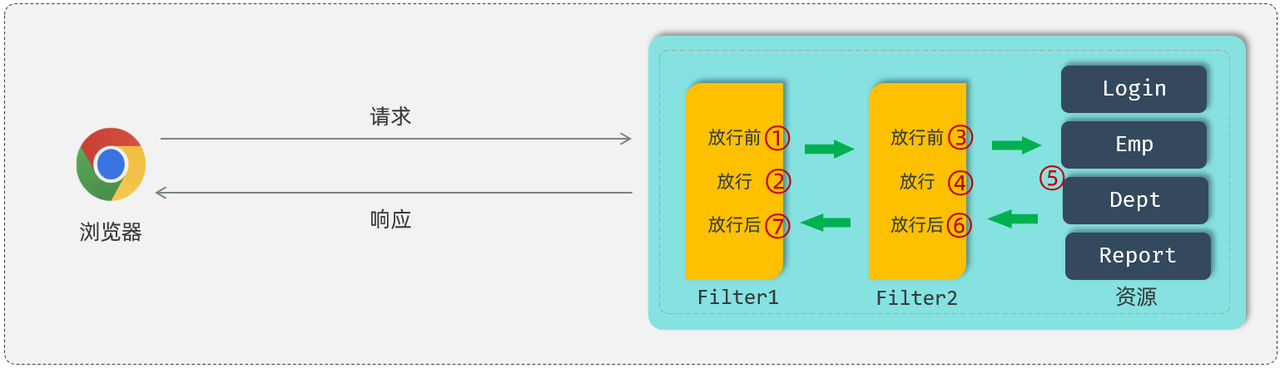
比如:在我们web服务器当中,定义了两个过滤器,这两个过滤器就形成了一个过滤器链。
而这个链上的过滤器在执行的时候会一个一个的执行,会先执行第1个Filter,放行之后再来执行第2个Filter,如果执行到了最后一个过滤器放行之后,才会访问对应的web资源。
访问完web资源之后,先要执行过滤器2放行之后的逻辑,再来执行过滤器1放行之后的逻辑,最后在给浏览器响应数据。

5.拦截器interceptor
1.快速入门
什么是拦截器?
-
是一种动态拦截方法调用的机制,类似于过滤器。
-
拦截器是++Spring框架++中提供的,用来动态拦截控制器方法的执行。
-
拦截器的作用:拦截请求,在指定方法调用前后,根据业务需要执行预先设定的代码。
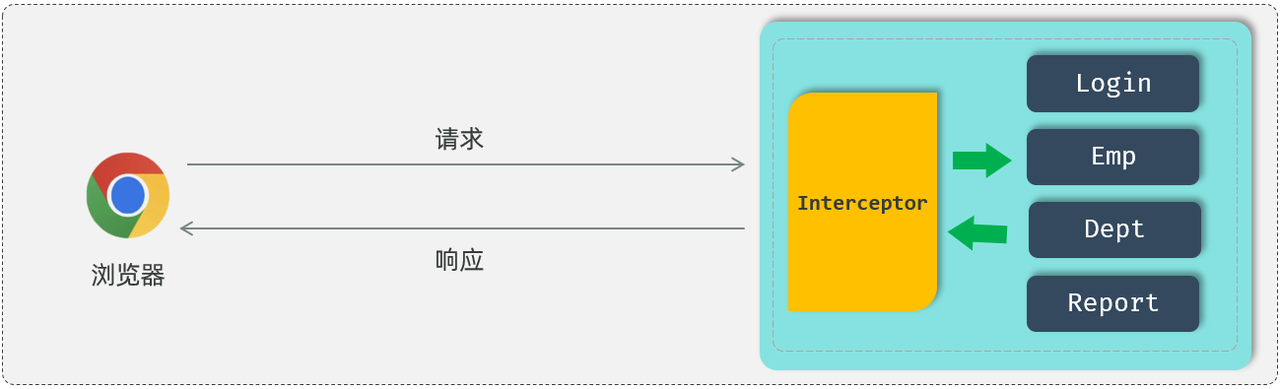
在拦截器当中,我们通常也是做一些通用性的操作,比如:我们可以通过拦截器来拦截前端发起的请求,将登录校验的逻辑全部编写在拦截器当中。在校验的过程当中,如发现用户登录了(携带JWT令牌且是合法令牌),就可以直接放行,去访问spring当中的资源。如果校验时发现并没有登录或是非法令牌,就可以直接给前端响应未登录的错误信息。
拦截器的使用步骤和过滤器类似,也分为两步:
1.定义拦截器(拦截请求,在请求的不同生命周期执行自定义逻辑)
3个生命周期方法(实现++HandlerInterceptor接口++):
preHandle:目标接口方法执行前 触发(如校验 Token、权限),返回**true则放行** 请求,false则拦截;postHandle:目标接口方法执行后、视图渲染前触发(如修改响应数据);afterCompletion:视图渲染完成后触发(如资源清理)。前后端分离 很少用到。
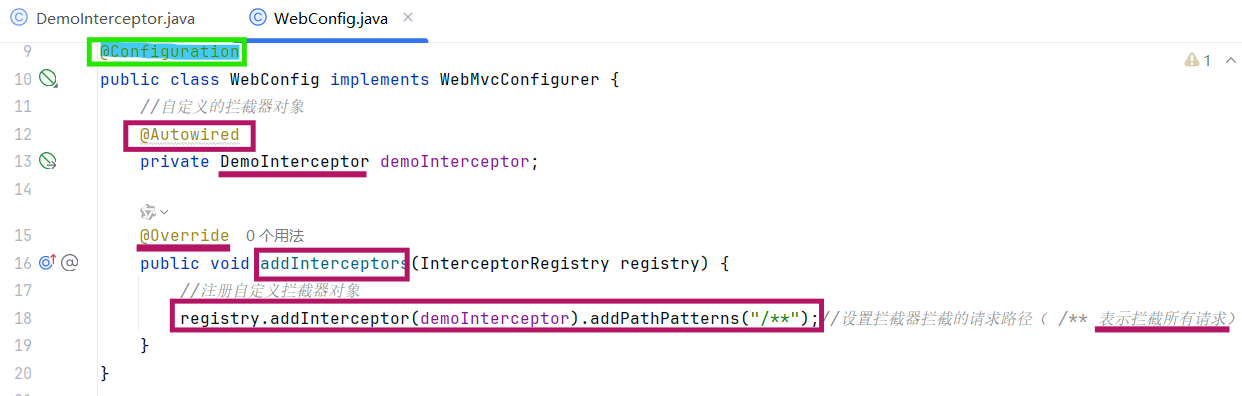
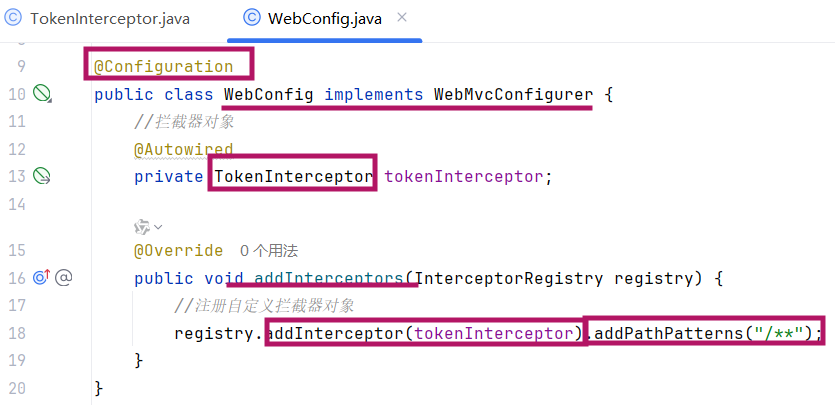
2.注册配置拦截器(将拦截器注册到 Spring 容器,并配置拦截规则)
@Configuration:标记为配置类;@Autowired:注入自定义拦截器DemoInterceptor;addInterceptors:注册拦截器,并通过addPathPatterns("/**")设置 "拦截所有请求"。
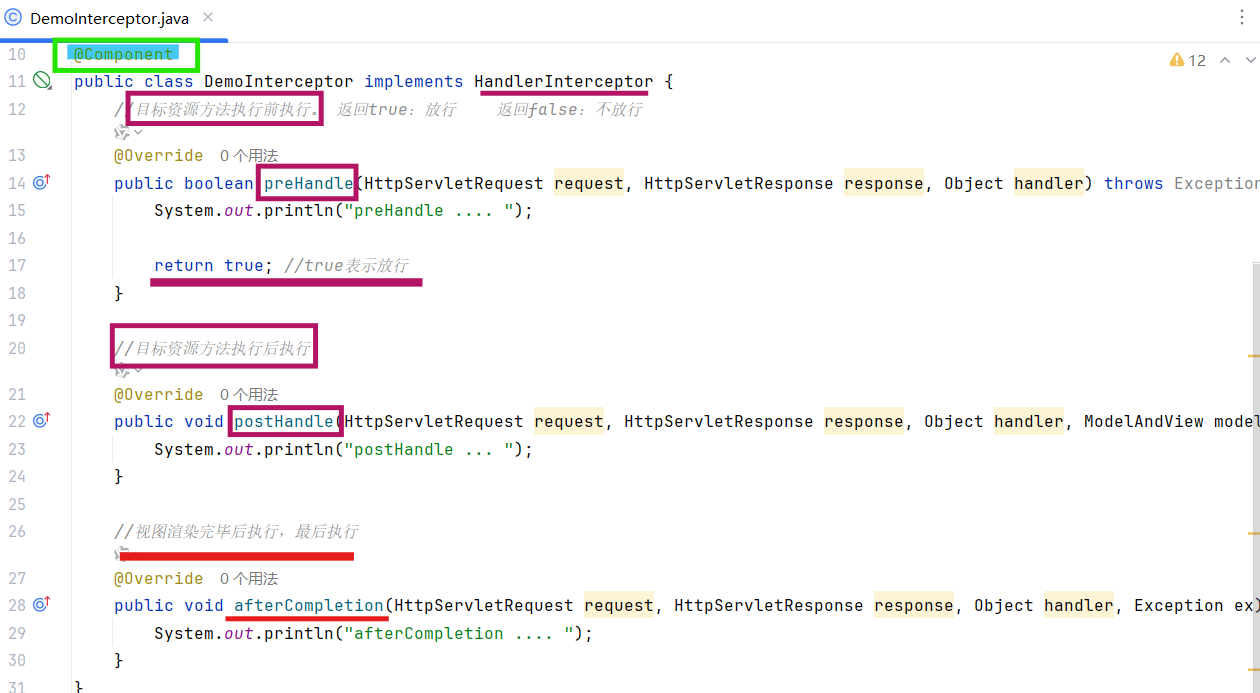
拦截器是Spring框架中提供的,需要交给IOC容器管理-->component
一、第一步:项目启动时的++初始化流程++(只执行一次)
核心是把++拦截器注册到 Spring 容器,并绑定拦截规则++:
-
Spring 扫描到
WebConfig类上的@Configuration注解,将其加载为配置类; -
Spring 通过
@Autowired自动创建DemoInterceptor实例,并注入到WebConfig中; -
执行
WebConfig的addInterceptors方法:-
把
DemoInterceptor注册到拦截器链; -
设置拦截规则:
addPathPatterns("/**")→ 拦截所有请求(无豁免路径时);
-
-
初始化完成,拦截器等待接收请求。
二、第二步:运行时的请求拦截流程(每次请求触发)
当客户端发起任意请求(如/test、/login),执行完整生命周期:
客户端请求 → preHandle → 目标接口方法 → postHandle → 视图渲染 → afterCompletion → 响应客户端2.令牌校验Interceptor(preHandler返回值类型为布尔)
和Filter一样 也是这些流程
登录校验的过滤器和拦截器,我们只需要使用其中的一种就可以了。
3.Interceptor详解
(1)拦截路径
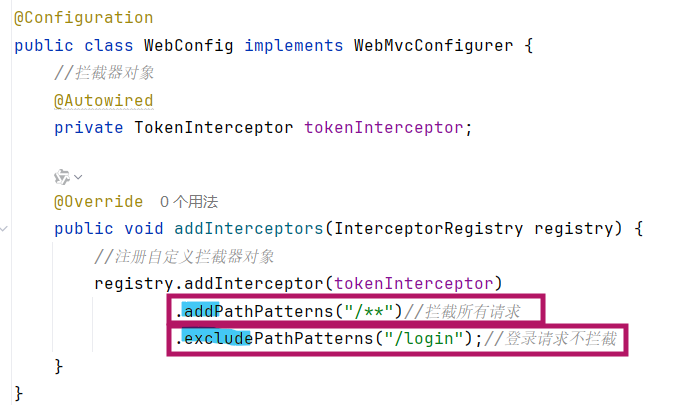
通过**addPathPatterns("要拦截路径")**方法,就可以指定要拦截哪些资源。
在入门程序中我们配置的是/**,表示拦截所有资源,而在配置拦截器时,不仅可以指定要拦截哪些资源,还可以指定不拦截哪些资源,只需要调用**excludePathPatterns("不拦截路径")**方法,指定哪些资源不需要拦截。
一些常见拦截路径设置:

(2)执行流程
-
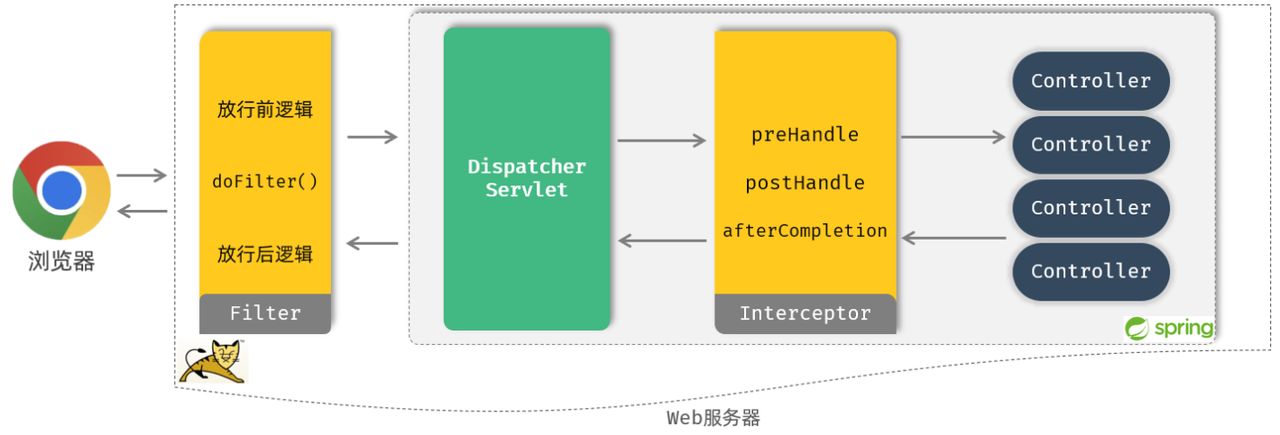
当我们打开浏览器来访问部署在web服务器当中的web应用时,此时我们所定义的++过滤器会拦截++ 到这次请求。拦截到这次请求之后,它会先执行++放行前++ 的逻辑,然后再执行++放行++ 操作。而由于我们当前是基于springboot开发的,所以放行之后是++进入到了spring的环境++当中,也就是要来访问我们所定义的controller当中的接口方法。
-
Tomcat并不识别所编写的Controller程序,但是它识别Servlet程序,所以在Spring的Web环境中提供了一个非常核心的Servlet:++DispatcherServlet(前端控制器)++,所有请求都会先进行到DispatcherServlet,再将请求转给Controller。
-
当我们定义了拦截器后,会在执行Controller的方法之前,请求++被拦截器拦截住++ 。执行++
preHandle()++ 方法,这个方法执行完成后需要返回一个布尔类型的值,如果返回++true++ ,就表示放行本次操作,才会继续++访问controller++中的方法;如果返回false,则不会放行(controller中的方法也不会执行)。 -
在controller当中的方法执行完毕之后,再回过来++执行
postHandle()这个方法以及afterCompletion()方法++ ,然后再返回给++DispatcherServlet++ ,最终再来执行++过滤器当中放行后++ 的这一部分逻辑的逻辑。执行完毕之后,最终++给浏览器响应++数据。
过滤器和拦截器之间的区别:
-
接口规范不同:过滤器需要实现Filter接口,而拦截器需要实现HandlerInterceptor接口。
-
拦截范围不同:过滤器Filter会拦截所有的资源,而Interceptor只会拦截Spring环境中的资源。
| 维度 | 过滤器(Filter) | 拦截器(Interceptor) |
|---|---|---|
| 所属技术栈 | Servlet 规范(Java EE 标准) | Spring MVC/Spring Boot 框架(Spring 体系) |
| 拦截时机 | 请求进入容器后、进入 Servlet 前(更早) | 进入 Servlet 后、目标接口方法执行前(更晚) |
| 拦截对象 | 所有请求(包括静态资源、非 Spring 接口) | 仅 Spring 管理的接口(Controller 方法) |
| 生命周期方法 | init(初始化)、doFilter(拦截逻辑)、destroy(销毁) |
preHandle、postHandle、afterCompletion(3 个生命周期) |
| 可操作对象 | ServletRequest、ServletResponse(仅请求 / 响应对象)-->强转 |
可操作HandlerMethod(目标接口方法)、ModelAndView(视图对象) |
| 依赖注入支持 | 不支持(默认无法注入 Spring Bean,需额外配置) | 支持(可直接@Autowired注入 Spring 组件) |