前言
持续更新中
面试顺序:做笔试、开始面试、自我介绍、笔试题问答、技术栈问答、简历项目问答、咨询HR、反问HR
一、C/C++基础
1.1 自增自减的两种情况
取决于对于变量其值使用时的时机,比如:如果值(地址)要提前使用访问,然后再加1为下个地址。
1.2 strlen与sizeof的区别
strlen: 是 C 语言库函数 ,专门计算字符串「实际有效长度」(仅统计 '\0' 之前的字符个数,不含 '\0');
sizeof: 是 C 语言内置运算符 ,计算「数据 / 数据类型占用的内存总字节数」(包含 '\0' 或类型的固定内存大小),二者的本质、计算逻辑、适用场景完全不同。
注:sizeof(指针) 的结果只由操作系统的位数(寻址空间)决定,和指针指向的内容(字符串、数组、结构体等)、指向内容的长度完全无关:32 位系统(x86):sizeof(任意指针) = 4 字节(32 位地址总线,可寻址 2³²=4GB 内存,4 字节刚好存储一个内存地址);64 位系统(x86_64):sizeof(任意指针) = 8 字节(64 位地址总线,8 字节存储内存地址)。
1.3 结构体大小计算方法
(1)明确两个关键概念:
自对齐值: 单个成员的对齐基准,默认等于该成员的类型大小(如char=1、int=4、double=8);若手动指定对齐值(如#pragma pack(n)),则取「成员类型大小」和n的较小值。
**最大对齐值:**结构体所有成员「自身对齐值」的最大值,是结构体总大小的对齐基准。
(2)通用规则:
首成员规则: 结构体第一个成员的偏移量(相对于结构体起始地址)为 0x00(就是0)。
成员偏移规则: 每个成员的偏移量(必须以0x00为起始,如果前面有其他变量,必须0x00加上前面的变量所占大小)必须是其「自身对齐值」的整数倍,不足则填充空白字节(Padding)。
总大小规则: 结构体总大小必须是「最大对齐值」的整数倍,不足则在末尾填充字节。
嵌套结构体规则:嵌套结构体的偏移量是其自身「最大对齐值」的整数倍;结构体整体的最大对齐值需包含嵌套结构体的最大对齐值。
**数组规则:**数组按「单个元素的类型」计算对齐值(如int arr3等价于 3 个int,对齐值仍为 4)。
(3)计算步骤(通用流程)
确定每个成员的「自身对齐值」;
按声明顺序计算每个成员的偏移量(不足则填充);
计算所有成员的总占用字节(最后一个成员的偏移 + 成员大小);
确保总大小是「最大对齐值」的整数倍(不足则末尾填充)。
cpp
struct A {
char a; // 类型大小1,自身对齐值1,偏移0,占用1字节
int b; // 类型大小4,自身对齐值4;偏移需为4的倍数 → 补3字节(偏移0+1+3=4),占用4字节(4~7)
double c; // 类型大小8,自身对齐值8;偏移8(4+4=8,刚好8的倍数),占用8字节(8~15)
};
成员总占用:1(a)+3(填充)+4(b)+8(c)= 16 字节;
最大对齐值:max (1,4,8)=8;
总大小:16(是 8 的整数倍)→ 最终大小 16。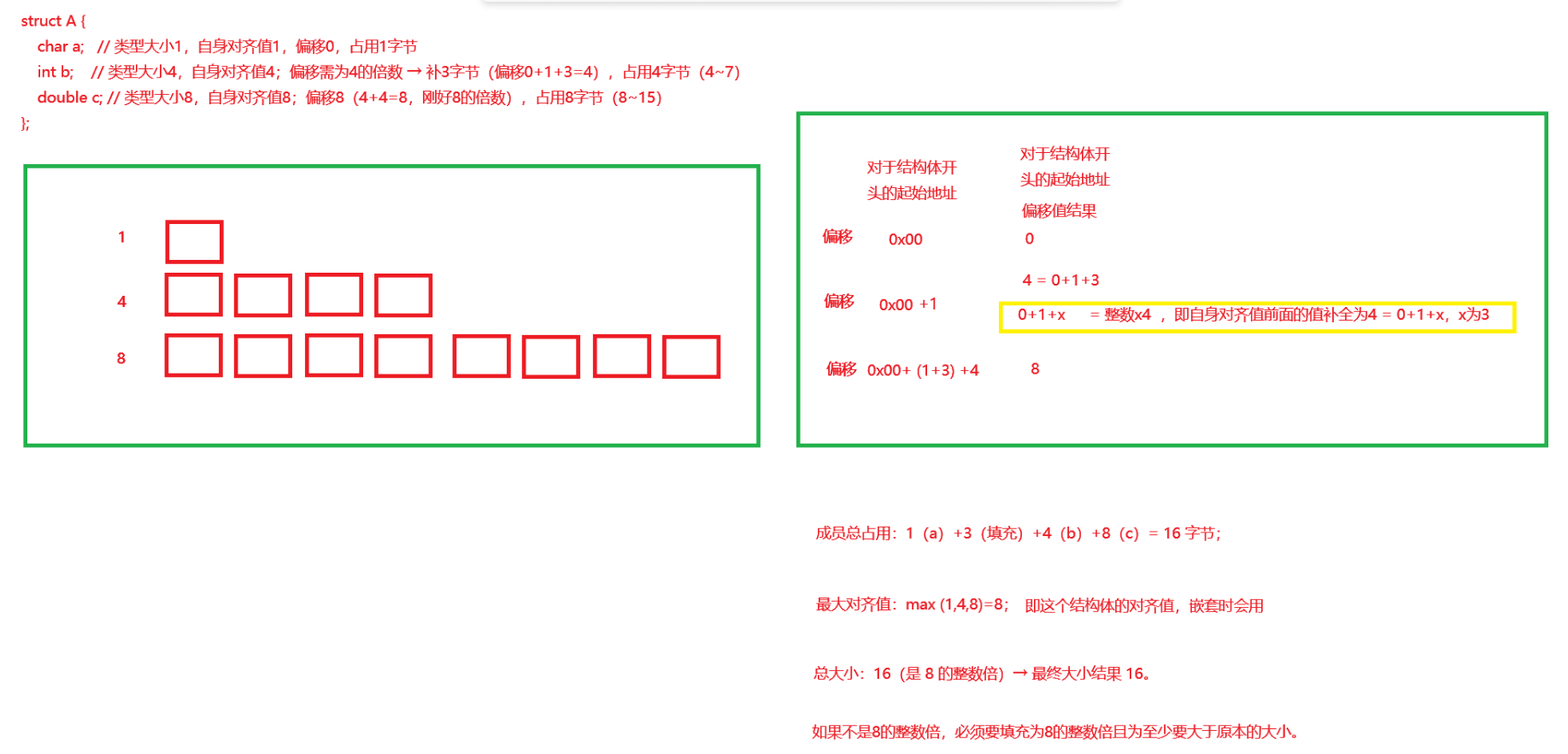
cpp
// 复用示例1的struct A(大小16,最大对齐值8)
struct C {
short s; // 类型大小2,自身对齐值2,偏移0,占用2字节
struct A a; // 嵌套结构体的最大对齐值8 → 偏移需为8的倍数,补6字节(偏移0+2+6=8),占用16字节(8~23)
char ch; // 自身对齐值1,偏移24,占用1字节(24~24)
};
成员总占用:2+6+16+1=25 字节;
最大对齐值:max (2,8,1)=8;
总大小:25 不是 8 的倍数,补 7 字节 → 最终大小 32。
cpp
手动指定对齐值(#pragma pack (n))
通过#pragma pack(n)可强制指定最大对齐值为n(n 通常为 1/2/4/8/16):
c
运行
#pragma pack(2) // 强制最大对齐值为2
struct D {
char a; // 自身对齐值min(1,2)=1,偏移0,占用1字节
int b; // 自身对齐值min(4,2)=2,偏移2(补1字节),占用4字节(2~5)
double c; // 自身对齐值min(8,2)=2,偏移6,占用8字节(6~13)
};
#pragma pack() // 恢复默认对齐
成员总占用:1+1+4+8=14 字节;
最大对齐值:2;
总大小:14 是 2 的整数倍 → 最终大小 14。1.4 队列和栈的区别
1.4.1 队列(Queue)
先进先出(FIFO, First In First Out)
仅在栈顶(单一端点)进行所有操作
空:队首指针 = 队尾指针;满:(队尾指针 + 1)% 数组长度 = 队首指针(循环队列)
实现方式:可以数组,可以链表
1.4.2 栈(Stack)
后进先出(LIFO, Last In First Out)
在队尾入队 、队首出队(两个端点)操作
空:栈顶指针 =-1;满:栈顶指针 = 数组长度 - 1
实现方式:可以数组,可以链表,但在 FreeRTOS 中,队列(核心通信组件) 和 任务栈(任务运行依赖的栈) 均基于连续内存(数组) 实现;而 FreeRTOS 内核的链表模块 (用于管理任务 / 定时器等节点)则基于双向循环链表 实现(并非栈 / 队列的实现,而是内核管理工具)。
1.5 冒泡排序与二分查找
1.5.1 冒泡排序
冒泡排序是一种简单的交换排序算法,核心思想是通过相邻元素的两两比较与交换,将最大(或最小)的元素逐步 "冒泡" 到数组的末尾,重复此过程直到整个数组有序。
1. 核心原理
遍历数组,依次比较相邻的两个元素,若顺序错误(如升序要求下前大后小)则交换;
每一轮遍历后,当前未排序部分的最大元素会被 "推" 到末尾,因此下一轮遍历的范围可缩小一位;
若某一轮遍历中没有发生任何交换,说明数组已完全有序,可提前终止(优化点)。
| 特性 | 说明 |
|---|---|
| 排序稳定性 | 稳定(相等元素的相对位置不变) |
| 时间复杂度 | 最坏 / 平均 O (n²),最好 O (n)(已排序) |
| 空间复杂度 | O (1)(原地排序,无需额外空间) |
| 适用场景 | 小规模数据、对稳定性有要求的简单场景 |
1.5.2 二分查找
二分查找是一种高效的查找算法 ,仅适用于有序的数组(升序 / 降序),核心思想是通过不断缩小查找范围(每次排除一半元素),快速定位目标值。
1. 核心原理
- 定义查找区间的左边界
left和右边界right(初始为数组首尾); - 计算区间中间位置
mid = (left + right) // 2(避免溢出可写left + (right - left) // 2); - 比较中间元素
arr[mid]与目标值target:- 若
arr[mid] == target:找到目标,返回mid; - 若
arr[mid] > target:目标在左半区间,更新右边界right = mid - 1; - 若
arr[mid] < target:目标在右半区间,更新左边界left = mid + 1;
- 若
- 重复上述步骤,直到
left > right(说明目标不存在)。
2. 特点
| 特性 | 说明 |
|---|---|
| 适用场景 | 有序数组、静态数据(无需频繁增删) |
| 时间复杂度 | O (logn)(效率远高于顺序查找 O (n)) |
| 空间复杂度 | 迭代版 O (1),递归版 O (logn)(栈空间) |
| 局限性 | 仅支持随机访问(数组),不支持链表 |
1.6 快速排序如何用在链表上
1.6.1 链表快速排序的核心思路
快速排序的核心是分治思想 :选基准值 → 分区(将元素分为小于 / 等于 / 大于基准的三部分)→ 递归处理子区间。链表与数组的核心差异是无法随机访问,因此需要调整:
- 基准选择:优先选链表尾节点(或首节点),避免额外遍历找随机节点;
- 分区操作:通过遍历链表、调整指针,将节点划分为三个子链表(小于 / 等于 / 大于基准);
- 递归与拼接:递归排序 "小于" 和 "大于" 的子链表,再拼接三部分得到有序链表。
1.6.2 关键步骤拆解
1. 链表节点定义
以 Python 为例,定义单向链表节点:
python
class ListNode:
def __init__(self, val=0, next=None):
self.val = val
self.next = next2. 分区函数(核心)
遍历原链表,将节点分配到 small(小于基准)、equal(等于基准)、large(大于基准)三个子链表,返回这三个链表的头和尾(方便后续拼接)。
3. 递归排序
- 终止条件:链表为空或只有一个节点(无需排序);
- 递归处理:对
small和large子链表递归排序; - 拼接结果:
small → equal → large。
python
class ListNode:
def __init__(self, val=0, next=None):
self.val = val
self.next = next
def quickSortLinkedList(head: ListNode) -> ListNode:
# 终止条件:空链表或单个节点
if not head or not head.next:
return head
# 步骤1:选择尾节点作为基准(避免随机访问,简化实现)
pivot = get_tail(head)
pivot_val = pivot.val
# 步骤2:分区:small(<基准)、equal(=基准)、large(>基准)
small_head = small_tail = ListNode(0) # 哨兵节点,简化头节点处理
equal_head = equal_tail = ListNode(0)
large_head = large_tail = ListNode(0)
curr = head
while curr:
if curr.val < pivot_val:
small_tail.next = curr
small_tail = small_tail.next
elif curr.val == pivot_val:
equal_tail.next = curr
equal_tail = equal_tail.next
else:
large_tail.next = curr
large_tail = large_tail.next
# 断链:避免原链表的环,或子链表包含多余节点
curr = curr.next
# 收尾:将三个子链表的尾节点next置空
small_tail.next = None
equal_tail.next = None
large_tail.next = None
# 步骤3:递归排序small和large子链表
sorted_small = quickSortLinkedList(small_head.next) # 跳过哨兵节点
sorted_large = quickSortLinkedList(large_head.next)
# 步骤4:拼接结果:sorted_small → equal → sorted_large
return concat(sorted_small, equal_head.next, sorted_large)
# 辅助函数:获取链表尾节点
def get_tail(head: ListNode) -> ListNode:
curr = head
while curr.next:
curr = curr.next
return curr
# 辅助函数:拼接三个链表(处理空链表情况)
def concat(small: ListNode, equal: ListNode, large: ListNode) -> ListNode:
# 拼接small和equal
dummy = ListNode(0)
curr = dummy
if small:
curr.next = small
curr = get_tail(curr)
curr.next = equal
if equal:
curr = get_tail(curr)
# 拼接large
curr.next = large
return dummy.next
# 测试代码:打印链表
def print_linked_list(head: ListNode):
curr = head
res = []
while curr:
res.append(str(curr.val))
curr = curr.next
print(" → ".join(res))
# 测试用例
if __name__ == "__main__":
# 构建链表:4 → 2 → 5 → 1 → 3
head = ListNode(4)
head.next = ListNode(2)
head.next.next = ListNode(5)
head.next.next.next = ListNode(1)
head.next.next.next.next = ListNode(3)
print("原链表:")
print_linked_list(head)
sorted_head = quickSortLinkedList(head)
print("排序后:")
print_linked_list(sorted_head)1.6.3 对比数组快速排序
| 特性 | 数组快速排序 | 链表快速排序 |
|---|---|---|
| 随机访问 | 支持(O (1)) | 不支持(O (n)) |
| 元素交换 | 需临时空间 | 仅调整指针(无空间) |
| 空间复杂度 | O (log n)(递归)+ 临时空间 | O (log n)(仅递归) |
| 基准选择 | 灵活(首 / 尾 / 随机) | 优先尾节点(无需遍历) |
1.7 函数指针与指针函数,指针数组与数组指针的区别
(1)函数指针 vs 指针函数(核心:看本质是指针还是函数)
| 类型 | 本质 | 语法示例 | 核心特点 |
|---|---|---|---|
| 函数指针 | 指向函数的指针 | int (*fp)(int) = &add; |
指针变量,存函数入口地址 |
| 指针函数 | 返回指针的函数 | int* func(int a); |
函数,返回值为指针类型 |
(2)指针数组 vs 数组指针(核心:看本质是数组还是指针)
| 类型 | 本质 | 语法示例 | 核心特点 |
|---|---|---|---|
| 指针数组 | 数组(元素是指针) | int* arr[3]; |
3 个 int 指针的数组,arr 0 是指针 |
| 数组指针 | 指针(指向数组) | int (*p)[3] = &arr; |
指向 "3 个 int 的数组" 的指针 |
1.8 static与普通变量的区别
| 维度 | static 变量 | 普通变量(auto) |
|---|---|---|
| 作用域 | 局部 static:当前函数;全局 static:当前文件 | 局部:当前函数;全局:整个程序 |
| 生命周期 | 程序全程(静态存储期) | 局部:函数调用期;全局:程序全程 |
| 存储位置 | 数据段(静态区) | 局部:栈;全局:数据段 |
| 初始化 | 仅初始化一次 | 局部:每次调用初始化;全局:启动时 |
| 多文件可见性 | 全局 static:其他文件不可见 | 全局:可通过 extern 访问 |
1.9 指针常量与常量指针的区别
口诀:const 靠近谁,谁就不可变;
- 常量指针(指向常量的指针):
const int* p/int const* p→ 指向的内容不可改(*p=10报错),指针本身可改(p=&b合法); - 指针常量(指针本身是常量):
int* const p→ 指针本身不可改(p=&b报错),指向的内容可改(*p=10合法)。
1.10 extern关键字
核心作用:声明外部变量 / 函数,实现跨文件访问(仅声明,不分配内存);
- 用法 1:跨文件访问全局变量文件 A:
int g_val = 10;(定义),文件 B:extern int g_val;(声明,可访问); - 用法 2:跨文件访问函数(函数默认 extern,可省略);
- 注意:局部变量不能用 extern,仅全局变量 / 函数可用;extern 不能初始化(如
extern int g_val=10是定义,非法)。
1.11 static与const存放在内存的哪个区域
内存分区:栈、堆、数据段(静态区:.data/.bss)、代码段(常量区:.rodata);
- static 变量:无论局部 / 全局,均存数据段 :
- 初始化 static → .data 区;未初始化 static → .bss 区(启动时置 0);
- const 变量:
- 全局 const → 代码段(.rodata,只读);
- 局部 const → 通常在栈(编译器优化可能入常量区);
- static const → 仍在代码段,仅作用域限制在当前文件。
1.12 volatile关键字
volatile是 C/C++ 中核心的类型修饰符,核心作用是禁止编译器对变量做 "不必要的优化" ,强制程序每次访问该变量时都直接从内存(而非 CPU 寄存器) 读取 / 写入 ------ 这一特性在嵌入式开发(如 STM32、Linux 驱动)中至关重要,因为嵌入式场景中变量常被硬件、中断、多线程修改,编译器无法感知这类 "外部修改"。
| 需要的应用场景 | 原理说明 | 典型示例(STM32/Linux) |
|---|---|---|
| 1. 硬件寄存器访问 | 硬件寄存器(如 GPIO/USART/ADC 寄存器)的值由硬件实时修改,编译器无法感知 | volatile uint32_t *GPIOA_IDR = (volatile uint32_t*)0x40010800;(STM32 GPIO 输入寄存器) |
| 2. 中断与主函数共享变量 | 中断服务函数(ISR)修改的变量,主函数读取时需避免编译器优化 | 主函数中volatile uint8_t flag = 0;,中断中flag = 1;,主函数循环检测flag |
| 3. 多线程 / 多任务共享变量 | RTOS(如 FreeRTOS)中,不同任务 / 线程共享的变量,需避免缓存优化 | volatile int cnt = 0;,任务 1 修改cnt,任务 2 读取cnt |
| 4. 延时函数(空循环) | 编译器会优化掉 "无操作的空循环",加volatile强制执行循环 |
for(volatile int i=0; i<10000; i++);(STM32 简单延时,避免被优化为空) |
| 5. 内存映射的外设地址 | Linux 驱动中,外设地址映射到内存后,需volatile保证读写实时性 |
volatile unsigned int *uart_base = ioremap(0x12345678, 0x100); |
注:编译器优化等级(-O0/-O1/-O2/-O3)越高,对变量的缓存优化越激进:
-O0(无优化):即使不加volatile,编译器也会每次读内存(调试模式可用,量产不推荐);
-O1/-O2(量产常用):必须为外部修改的变量加volatile,否则必出逻辑错误;
-O3(极致优化):甚至会优化掉 "看似无意义的 volatile 变量赋值",需结合代码逻辑调整。
1.13
二、嵌入式基础知识
2.1 4种输入4种输出
2.1.1 输入
模拟输入
上拉输入
下拉输入
浮空输入
2.1.2 输出
推挽输出
推挽复用输出
开漏输出
开漏复用输出
2.2 IIC的读操作
2.2.1 当前地址读:
起始+设备号7位+读1位+从机ACK1位+从机数据8位+主机NACK1位+结束
2.2.2指定地址读:
起始+设备号7位+写1位+从机ACK1位+主机写寄存器地址8位+从机ACK1位+起始+设备号7位+读1位+从机ACK1位+从机返回数据8位+主机NACK1位+结束
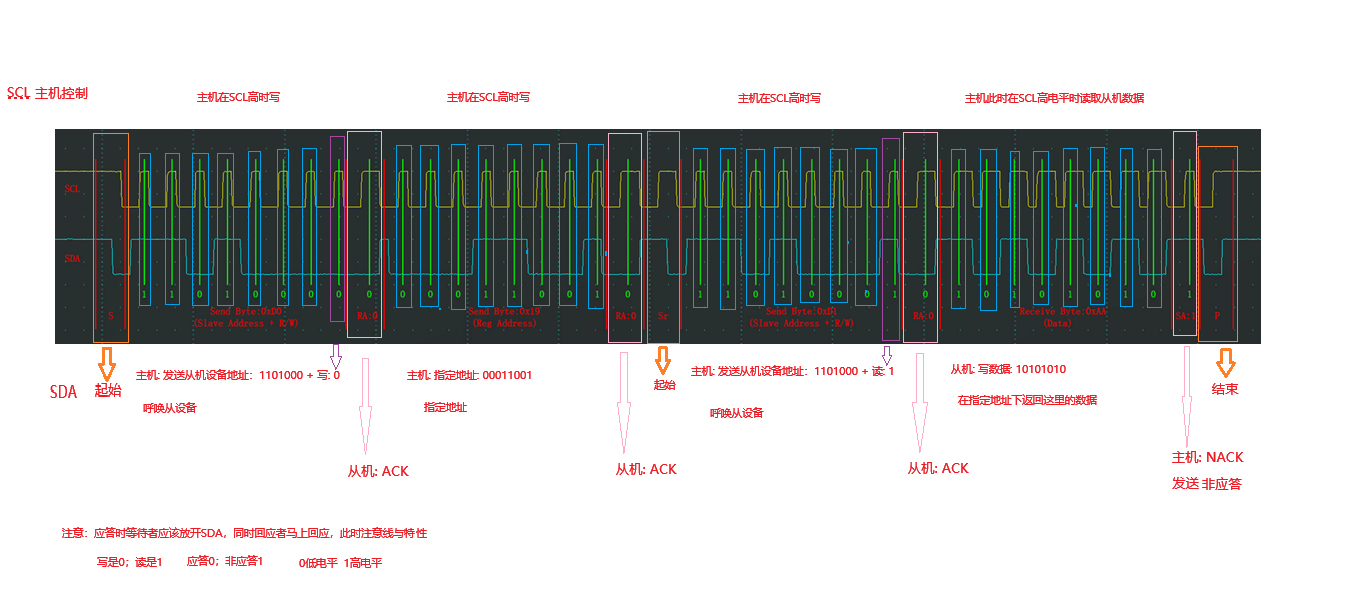
【Embedded Development】【IIC】IIC通信协议的时序学习过程记录-CSDN博客
2.3 为什么IIC要设置为开漏
主要为了符合IIC协议,规定IIC不能输出高电平,而IIC总线默认总是高电平由电路控制,信号控制就是开漏驱动出低电平拉低。
I²C(IIC)总线的 SDA(数据)和 SCL(时钟)引脚必须配置为开漏输出(Open Drain),核心原因是适配 I²C 总线的 "多主设备、线与逻辑、电平兼容" 特性,具体如下:
| 核心原因 | 详细说明 |
|---|---|
| 实现 "线与" 逻辑 | 开漏输出的引脚只能主动拉低电平,无法主动拉高,电平拉高依赖外部上拉电阻。当多个主设备同时驱动总线时,只要有一个设备拉低引脚,总线就为低;所有设备释放(输出高阻)时,总线被上拉电阻拉为高 ------ 这是 I²C 多主设备避免总线冲突的核心逻辑(若用推挽输出,多个设备同时输出高低电平会导致短路)。 |
| 兼容不同电平标准 | 上拉电阻可灵活匹配电压(如 3.3V/5V),实现不同电压域设备(如 3.3V MCU 和 5V 传感器)的通信,推挽输出无法做到电平灵活适配。 |
| 维持总线空闲态 | I²C 总线空闲时要求 SDA/SCL 为高电平,开漏 + 上拉电阻可稳定维持高电平;若无开漏,引脚高阻态会导致电平浮动,总线状态不可控。 |
| 支持双向通信 | 开漏输出的引脚可在 "输出(拉低)" 和 "输入(高阻,检测总线电平)" 之间切换,满足 SDA/SCL 既作为输出(主设备发数据)又作为输入(从设备 / 其他主设备发数据)的双向通信需求。 |
补充:开漏输出需搭配上拉电阻(典型值 1.8kΩ~10kΩ),电阻值需平衡:阻值太小功耗大、总线上升沿太快易振铃;阻值太大上升沿太慢,限制 I²C 通信速率。
2.4 如何管理100个软件定时器
管理 100 个软件定时器的核心是基于 "定时基准 + 有序链表 / 时间轮" 设计,避免逐一遍历所有定时器导致的性能损耗,以下是工业级实现方案:
2.4.1 核心设计思路
- 定时基准:用硬件定时器(如 SysTick、TIMx)产生固定周期中断(如 1ms),作为所有软件定时器的时间基准;
- 定时器结构体:每个定时器包含「定时时长、剩余时长、状态(使能 / 暂停 / 单次 / 周期)、回调函数、优先级」等字段;
- 高效管理容器:优先选择「按超时时间排序的单向链表」或「时间轮算法」(100 个定时器推荐链表,简单且高效)。
2.4.2 具体实现步骤
(1)定时器结构体定义
typedef struct SoftTimer {
uint32_t total_ticks; // 总定时时长(ms)
uint32_t remain_ticks; // 剩余时长(ms)
uint8_t state; // 0:未使能,1:运行中,2:暂停
uint8_t mode; // 0:单次触发,1:周期触发
void (*callback)(void); // 定时到期回调函数
struct SoftTimer *next; // 链表节点指针
} SoftTimer_t;(2)链表管理(按剩余时长升序)
- 初始化:创建空链表,100 个定时器初始化为未使能状态;
- 添加定时器:按
remain_ticks插入链表(超时时间近的在前),避免每次遍历全部 100 个; - 定时中断处理(核心):
- 仅遍历链表头部节点,将其
remain_ticks--; - 若
remain_ticks == 0,触发回调函数; - 若为周期模式,重置
remain_ticks = total_ticks,并将节点重新插入链表;若为单次模式,标记为未使能并从链表移除; - 仅当头部节点处理完成后,才处理下一个节点(100 个定时器仅需遍历 "即将超时的节点",而非全部)。
- 仅遍历链表头部节点,将其
(3)批量管理优化
- 提供统一接口:
timer_create()(创建)、timer_start()(启动)、timer_stop()(暂停)、timer_delete()(删除); - 优先级处理:回调函数中避免耗时操作(如阻塞),若需高优先级处理,可通过消息队列触发任务;
- 防重入:中断中仅标记 "定时器到期",回调函数在主循环执行(避免中断嵌套)。
3. 进阶方案:时间轮算法
若定时器数量进一步增加(如 > 500),可采用时间轮:将时间划分为 "轮盘槽位"(如 0~99 槽,对应 0~99ms),每个槽位挂载定时器;定时中断每 1ms 移动 "指针",仅处理当前槽位的定时器,遍历开销固定(与定时器数量无关)。
2.5 MODBUS的格式
MODBUS 是工业串行通信协议,分RTU 模式(主流) 和ASCII 模式,核心帧结构如下:
2.5.1 MODBUS-RTU(远程终端单元)
工业现场最常用,二进制传输,效率高,帧边界靠 "总线空闲时间" 区分(≥3.5 个字符时间),帧结构:
| 字段 | 字节数 | 说明 |
|---|---|---|
| 起始位 | - | 总线空闲≥3.5 字符时间(无实际字节,用于帧同步) |
| 从机地址 | 1 | 0~247(0 为广播地址,1~247 为从机地址) |
| 功能码 | 1 | 指示操作类型(如 03H 读保持寄存器、05H 写单线圈) |
| 数据域 | N | 操作参数(如寄存器地址、寄存器数量、写入数据,长度随功能码变化) |
| CRC 校验 | 2 | 循环冗余校验(低字节在前,高字节在后,覆盖地址、功能码、数据域) |
| 结束位 | - | 总线空闲≥3.5 字符时间(标记帧结束) |
示例(读从机 1 的 0001~0002 寄存器):01 03 00 01 00 02 C4 0B
- 01:从机地址;03:读保持寄存器;00 01:起始寄存器地址;00 02:读取数量;C4 0B:CRC 校验。
2.5.2 MODBUS-ASCII
文本格式传输,可读性强但效率低,帧结构:
| 字段 | 字符数 | 说明 |
|---|---|---|
| 起始符 | 1 | 冒号 ":"(标记帧开始) |
| 从机地址 | 2 | 十六进制 ASCII(如 01→"01") |
| 功能码 | 2 | 十六进制 ASCII(如 03→"03") |
| 数据域 | 2N | 十六进制 ASCII(每个字节转 2 个字符) |
| LRC 校验 | 2 | 纵向冗余校验(覆盖地址、功能码、数据域) |
| 结束符 | 2 | 回车 + 换行(CR+LF,标记帧结束) |
2.6 MODBUS中的遥控帧用在什么场景,功能码是多少
MODBUS "遥控帧" 本质是对离散输出线圈(Coil)的强制写操作,用于远程控制工业现场的开关量设备,核心功能码和场景如下:
2.6.1 核心功能码
| 功能码 | 名称 | 用途 | 遥控帧特性 |
|---|---|---|---|
| 05H | 强制单线圈 | 控制单个开关量输出 | 最常用的遥控帧,单点操作 |
| 0FH | 强制多线圈 | 批量控制多个开关量输出 | 多点批量遥控 |
2.6.2 应用场景
工业设备启停:遥控电机、泵体、风机的启停(线圈对应继电器吸合 / 断开);
阀门控制:远程控制电磁阀、气动阀的开关(如水管 / 气管阀门);
指示灯 / 报警器:遥控现场指示灯亮灭、声光报警器启停;
紧急操作:远程急停、复位等安全指令(优先级高,需搭配硬件冗余);
设备模式切换:遥控设备在 "自动 / 手动" 模式间切换(单个线圈对应模式)。
示例(05H 遥控帧):从机地址 1,强制 0001 线圈为 ON:01 05 00 01 FF 00 8C 3A
01:从机地址;05:强制单线圈;00 01:线圈地址;FF 00:置 ON(00 00 为置 OFF);8C 3A:CRC 校验。
2.7 在没有中断的情况下,该如何实现MODBUS-RTU的收发
无中断时需通过轮询(查询)方式 实现,核心是利用 "字符时间计算 + 总线空闲检测" 识别帧边界,缺点是 CPU 占用率高,适合对实时性要求低的场景,具体步骤:
2.7.1 前期准备
- 配置 UART:波特率(如 9600)、8 位数据位、1 位停止位、无校验(8N1),禁用 UART 接收 / 发送中断;
- 计算字符时间:每字节传输时间 = 10 / 波特率(含起始位 + 8 数据位 + 1 停止位),如 9600 波特率下字符时间≈1.04ms,3.5 字符时间≈3.64ms(帧边界判定阈值)。
2. 接收实现(核心:帧边界检测)
uint8_t rcv_buf[32]; // 接收缓冲区
uint8_t rcv_len = 0; // 接收长度
uint32_t last_rcv_tick = 0; // 最后一次接收字节的时间戳
void modbus_rtu_rcv(void) {
// 1. 轮询UART接收寄存器,检测是否有字节可读
if (UART_FLAG_RXNE) {
rcv_buf[rcv_len++] = UART_DR; // 读取字节到缓冲区
last_rcv_tick = get_sys_tick(); // 记录当前时间(ms)
if (rcv_len >= 32) rcv_len = 0; // 防止缓冲区溢出
}
// 2. 检测总线空闲(超过3.5字符时间无字节接收),判定帧结束
if (rcv_len > 0 && (get_sys_tick() - last_rcv_tick) > 3.64) {
// 3. CRC校验(验证帧完整性)
if (crc_check(rcv_buf, rcv_len)) {
modbus_parse(rcv_buf, rcv_len); // 解析帧并处理
}
// 4. 重置接收状态
rcv_len = 0;
last_rcv_tick = 0;
}
}3. 发送实现
void modbus_rtu_send(uint8_t *data, uint8_t len) {
// 1. 等待总线空闲(避免发送冲突)
while ((get_sys_tick() - last_rcv_tick) < 3.64);
// 2. 轮询发送每一字节
for (uint8_t i = 0; i < len; i++) {
while (!UART_FLAG_TXE); // 等待发送寄存器为空
UART_DR = data[i]; // 发送字节
}
// 3. 发送完成后,等待总线空闲
last_rcv_tick = get_sys_tick();
}2.8 解释一下优先级翻转
优先级翻转是实时操作系统(RTOS)中高优先级任务被低优先级任务阻塞,导致中等优先级任务优先执行的现象,是破坏 RTOS 实时性的典型问题,具体如下:
2.8.1 核心场景(三步触发)
- 低优先级任务(L)持有高优先级任务(H)所需的互斥锁(如串口、外设);
- 高优先级任务(H)就绪,抢占 CPU 但因等待互斥锁进入阻塞态;
- 中等优先级任务(M)就绪,抢占低优先级任务(L)的 CPU,导致高优先级任务(H)被 "卡" 在 M 之后执行 ------ 优先级发生 "翻转"。
2.8.2 危害
高优先级任务本应优先执行(如紧急中断处理、安全指令),但因优先级翻转导致响应超时,违反 RTOS "实时性" 核心诉求。
2.8.3 解决方法
- 优先级继承(FreeRTOS 互斥锁默认实现):低优先级任务(L)持有互斥锁时,临时继承高优先级任务(H)的优先级,避免被中等优先级任务(M)抢占;释放锁后恢复原优先级;
- 优先级天花板:给互斥锁设置 "天花板优先级"(所有使用该锁的任务中最高优先级),任务获取锁时直接提升到天花板优先级,释放后恢复。
2.8.4 比喻
没有加优先级继承:
家庭主妇妈妈给二儿子洗澡(低级任务),占用着厕所,而大儿子实在想上厕所(高级任务),可是厕所门锁了,同时来了一个电话需要接(中级任务),则抢占了了给二儿子洗澡(低级任务)的时间,大儿子还在门外等着妈妈打完电话(中级任务)和给二儿子洗澡(低级任务)的事件做完,大儿子才能上厕所(高级任务)。
注:但是(高级任务)不能等太久,否则会出问题
加优先级继承:
家庭主妇妈妈给二儿子洗澡(低级任务),占用着厕所,而大儿子实在想上厕所(高级任务),此时,妈妈给二儿子洗澡加快速度(低级任务暂时继承为高级任务的优先等级),即使,来了一个电话需要接(中级任务)也不接,给二儿子洗完就马上开门(释放互斥锁,同时,临时的高级任务变回原来的低级任务),大儿子开关门去上厕所,然后妈妈去打电话(中级任务)。
2.9 解释一下什么是死锁
死锁是多个任务 / 进程互相持有对方所需的资源,且均不释放已持有的资源,导致所有任务永久阻塞的现象,是多任务系统的致命问题,具体如下:
2.9.1 死锁的四大必要条件(缺一不可)
| 件 | 说明 |
|---|---|
| 互斥 | 资源同一时间只能被一个任务占用(如串口、互斥锁) |
| 请求与保持 | 任务持有已获取的资源,同时请求新的资源 |
| 不可剥夺 | 资源只能由持有任务主动释放,其他任务无法强制剥夺 |
| 循环等待 | 任务 A 等待任务 B 的资源,任务 B 等待任务 C 的资源,...,任务 N 等待任务 A 的资源 |
2.9.2 典型场景
- 任务 A 持有资源 1,请求资源 2;
- 任务 B 持有资源 2,请求资源 1;
- 两者均不释放已持有的资源,互相等待,永久阻塞。
2.9.3 解决 / 避免方法
- 破坏 "循环等待":给资源编号,任务按编号升序申请资源(如先申请资源 1,再申请资源 2);
- 破坏 "请求与保持":任务一次性申请所有所需资源,若申请失败则释放已持有的资源;
- 超时释放:任务申请资源时设置超时,超时后放弃申请并释放已持有的资源;
- 资源剥夺:内核强制剥夺低优先级任务的资源(仅适合非关键资源)。
2.10 六层板的层叠结构、ADC的输入阻抗匹配等硬件相关问题
2.10.1 六层板的层叠结构
六层板的层叠设计核心原则:电源 / 地平面紧邻、信号层与地 / 电源层相邻、模拟 / 数字层隔离、控制阻抗,工业级主流层叠方案如下(优先推荐):
| 层序 | 类型 | 作用 |
|---|---|---|
| Top | 信号层 | 走低速数字信号、接口信号(如 UART、IIC),禁止走高速 / 模拟信号 |
| L2 | 地平面(GND) | 作为 Top 层信号的参考平面,减少 EMI(电磁干扰),提供回流路径 |
| L3 | 信号层 | 走高速信号(如 SPI、以太网)、核心控制信号(MCU 核心) |
| L4 | 电源平面(Power) | 给核心器件(MCU、ADC/DAC)供电,紧邻地平面(L2/L5)减少电源噪声 |
| L5 | 信号层 | 走模拟信号(如 ADC 输入、运放输出),远离数字信号层 |
| Bottom | 信号层 | 走电源接口、外设接口信号,可铺地增强屏蔽 |
其他可选方案(按需求调整):
- Top→Power→GND→Signal→GND→Bottom(双地平面,适合强干扰场景);
- Top→Signal→GND→Power→GND→Bottom(模拟信号走内层,屏蔽更好)。
设计要点:
- 模拟地 / 数字地单点连接,避免地环路干扰;
- 高速信号(如 > 100MHz)走内层,与地平面紧邻,控制阻抗(如 50Ω/90Ω);
- 电源平面分割(如 3.3V/5V / 模拟电源),分割处做隔离。
2.10.2 ADC 的输入阻抗匹配
ADC 输入阻抗匹配的核心是保证采样电容快速充电、减少信号反射 / 干扰,提升采样精度,具体要求和实现如下:
1. ADC 输入特性
ADC 内部包含 "采样保持电容(Cs)",采样瞬间需要从前端电路吸取大电流给 Cs 充电;若前端阻抗过高,Cs 充电不充分,采样值会失真。
2. 阻抗匹配核心要求
- 驱动阻抗匹配:前端信号源 / 驱动电路的输出阻抗 ≤ ADC 输入阻抗的 1/10(ADC 输入阻抗通常为 MΩ 级,因此前端输出阻抗需≤100kΩ);
- 采样时间匹配:前端电路给 Cs 充电的时间 ≤ ADC 的采样时间(如 12 位 ADC 采样时间通常为 1μs,需保证 Cs 在 1μs 内充电至 99% 以上);
- 高频阻抗匹配:若信号含高频分量(>100kHz),需串联匹配电阻(如 50Ω)减少信号反射。
3. 实现方法
- 低阻抗驱动:若信号源阻抗高(如传感器输出阻抗 1MΩ),加运放缓冲器(如 OPA2340)做阻抗变换(运放输出阻抗 < 100Ω);
- RC 滤波匹配:ADC 输入端加 RC 低通滤波器(如 1kΩ 电阻 + 100nF 电容),电阻值需匹配前端输出阻抗,滤除高频噪声的同时保证充电速度;
- 布线优化:模拟信号走线短、粗、直,远离数字信号,底层铺模拟地,减少干扰导致的阻抗变化;
- 避免负载过重:ADC 输入引脚不挂载过多器件(如多个电阻分压),防止输入阻抗降低。
示例:12 位 ADC(输入阻抗 10MΩ,采样时间 1μs),前端传感器输出阻抗 10kΩ→加 1kΩ 串联电阻 + 100nF 电容,满足 "驱动阻抗≤1MΩ(10MΩ/10)",且 RC 充电时间(τ=1k×100n=100μs,实际采样时间内可充至 99% 以上)。
2.11 STM32哪种IO工作模式功耗最低
STM32 IO 口功耗最低的工作模式是 模拟输入模式(Analog Input) ;若 IO 口需保持数字特性,下拉 / 上拉输入模式 次之,而输出模式、复用功能模式功耗显著更高。
2.12 STM32有哪些低功耗模式
| 模式名称 | 内核状态 | 时钟状态 | 存储 / 寄存器保留 | 典型功耗(3.3V@25℃) | 主要唤醒源 | 适用场景 |
|---|---|---|---|---|---|---|
| 睡眠模式(Sleep) | 内核停止,外设运行 | 系统时钟(SYSCLK)仍运行,仅内核暂停 | 全部保留(SRAM / 寄存器) | ~1-5mA(F4 系列) | 中断(任意外设 / EXTI)、SysTick 中断 | 短延时等待(如传感器采样间隙) |
| 停止模式(Stop) | 内核 + 系统时钟停止 | HSI/HSE/PLL 关闭,低速时钟(LSI/LSE)可选运行 | SRAM / 寄存器保留 | ~10-50μA(F4)/ ~1μA(L4 低功耗系列) | EXTI 中断、RTC 闹钟、DMA、I2C/SPI 唤醒(部分系列) | 中等时长休眠(如 1 分钟采集一次数据) |
| 待机模式(Standby) | 内核 + 电源域关闭 | 仅备份域时钟(LSE/LSI)可选运行 | 仅备份域(RTC / 备份寄存器)保留,SRAM / 寄存器丢失 | ~0.1-1μA(F4)/ ~0.01μA(L4) | WKUP 引脚、RTC 闹钟、NRST 复位、入侵检测 | 长时间休眠(如小时级唤醒) |
| 关机模式(Shutdown) | 所有电源域关闭 | 仅备份域(可选)运行 | 仅备份域保留 | ~0.001μA(L4/H7) | WKUP 引脚、RTC 闹钟、NRST 复位 | 极致低功耗(如天级唤醒) |
STM32 低功耗模式功耗排序(从高到低):睡眠模式(Sleep);停止模式(Stop);待机模式(Standby); 关机模式(Shutdown)
2.13 信号量与互斥量的区别
| 维度 | 互斥量(Mutex) | 信号量(Semaphore) |
|---|---|---|
| 核心用途 | 临界区互斥(独占资源) | 同步 / 有限资源访问(计数许可) |
| 所有权 | 加锁线程必须解锁(有所有权) | 无所有权(任意线程可解锁) |
| 取值 | 二值(0/1) | 计数型(≥0) |
| 优先级反转 | 可通过优先级继承避免 | 无法避免 |
| 死锁风险 | 高(忘记解锁) | 计数型低,二值型类似互斥 |
总结:互斥是 "独占",信号量是 "计数许可";互斥量解决 "谁先谁后",信号量解决 "同步 / 资源数"。
记住:互斥量(Mutex):核心解决公共资源的独占访问(临界区问题),保证同一时间只有一个任务访问资源;可通过优先级继承规避 "优先级反转" 问题。
信号量(Semaphore):核心解决任务同步(二值信号量) + 有限资源的计数访问(计数型信号量)(比如最多 3 个任务同时访问某资源,或计数已完成的任务数)。
2.14 流媒体的使用场景
核心是 "边传边播",典型场景:
- 娱乐:直播、短视频、在线视频 / 音乐、游戏直播;
- 安防:摄像头实时监控、NVR 回放;
- 工业 / 物联网:流水线视频监控、无人机图传、设备远程运维视频流;
- 教育医疗:在线直播课、远程手术直播、医疗影像实时传输;
- 通信:视频通话、会议直播;
- 车载:行车记录仪回传、车载大屏在线视频。
2.15 MQTT的主题订阅与发布机制
MQTT 是发布 / 订阅(Pub/Sub)模型,核心角色:发布者、订阅者、Broker(代理);
- 发布:发布者向 Broker 指定 "主题"(层级化,/ 分隔)发消息,无需知道订阅者;
- 订阅:订阅者向 Broker 订阅主题(支持通配符:+ 单层、# 多层),Broker 记录订阅关系;
- 转发:Broker 接收消息后,向所有订阅匹配主题的订阅者转发,实现发布者与订阅者解耦。
注:必须有代理进行转发
2.16 STM32的BOOT的启动模式
2.16.1 BOOT 引脚电平与启动模式对照表
| BOOT0 电平 | BOOT1 电平 | 启动模式 | 启动源 | 核心作用与应用场景 |
|---|---|---|---|---|
| 低电平(0) | 任意电平 | 主闪存启动(默认) | 芯片内置的主 Flash 存储器 | 正常产品运行模式:程序固化在主 Flash 中,上电 / 复位后直接执行 Flash 中的代码(开发完成后的默认模式) |
| 高电平(1) | 低电平(0) | 系统存储器启动 | 芯片内置的 Bootloader 区域 | ISP 下载模式:通过串口(UART)、USB 等接口,向主 Flash 烧录程序(适用于程序丢失 / 首次烧录的场景) |
| 高电平(1) | 高电平(1) | 内置 SRAM 启动 | 芯片的内置静态随机存储器 | 调试 / 测试模式:程序临时加载到 SRAM 中运行(无 Flash 擦写风险,适合调试大程序或临时验证代码) |
2.16.2 各模式的关键说明
-
主闪存启动(默认模式)
- 启动源是 STM32 的主 Flash(容量从几 KB 到几 MB 不等,因型号而异);
- 是产品量产、正常运行的唯一模式,程序需提前通过下载工具(如 J-Link)烧录到主 Flash 中。
-
系统存储器启动(ISP 模式)
- 启动源是 STM32 出厂时预烧录的内置 Bootloader(不可修改);
- 无需外部下载器,仅需通过串口(如 USART1)连接电脑,用官方工具(如 STM32CubeProgrammer)烧录程序;
- 适用于 "下载器损坏""首次烧录""程序崩溃后恢复" 等场景。
-
内置 SRAM 启动
- 启动源是 STM32 的内置 SRAM(容量通常远小于 Flash,如 F103C8T6 的 SRAM 仅 20KB);
- 程序不会固化(掉电丢失),仅用于调试阶段(如验证代码功能、测试大程序的部分模块);
- 需在编译器中修改 "程序存储地址" 为 SRAM 的起始地址(如 F1 系列 SRAM 起始地址为
0x20000000)。
2.16.3 注意事项
- 部分低容量 STM32(如 STM32F030)仅保留
BOOT0引脚,无BOOT1:此时BOOT0=1直接进入系统存储器启动模式; - 上电 / 复位时,
BOOT0/BOOT1的电平会被芯片采样,之后修改引脚电平不影响当前启动流程(需重新复位才会切换模式); - 若需切换启动模式,需在复位前将
BOOT0/BOOT1拉到对应电平,复位后再恢复(如 ISP 下载完成后,需将BOOT0拉低再复位,回到主闪存模式)。
2.17 DMA的方向
| 传输方向 | 定义(源 → 目的) | 核心原理 | 典型应用场景(STM32) |
|---|---|---|---|
| 1. 外设 → 内存(Periph→Mem) | 片上外设数据寄存器 → 内存(SRAM/Flash) | 外设产生数据后,DMA 自动将数据从外设寄存器(如 USART_DR、ADC_DR)搬运到内存,无需 CPU 干预 | - USART/UART 接收数据(串口数据自动存到内存缓冲区)- ADC 采集(采样值自动存到内存数组)- SPI/I2C 从设备接收数据 |
| 2. 内存 → 外设(Mem→Periph) | 内存(SRAM/Flash)→ 片上外设数据寄存器 | DMA 从内存读取数据,自动写入外设寄存器,外设再将数据发送出去 | - USART/UART 发送数据(内存字符串自动通过串口发送)- SPI/I2C 主设备发送数据- DAC 输出(内存波形数据自动输出)- TIM PWM+DMA(输出固定占空比序列) |
| 3. 内存 → 内存(Mem→Mem) | 内存区域 A → 内存区域 B(SRAM/SRAM、Flash/SRAM) | 纯软件触发,DMA 直接在内存间搬运数据(无需外设参与),效率远高于 CPU 循环拷贝 | - 大容量数据拷贝(如 Flash 固件升级时,将接收的固件数据拷贝到指定 Flash 区域)- 内存数据格式转换(如批量字节转半字)- 缓冲区数据搬移(环形缓冲区读写) |
2.18 内联函数与宏函数的区别
| 维度 | 宏函数(Macro) | 内联函数(Inline Function) |
|---|---|---|
| 实现阶段 | 预处理阶段(文本替换,无编译检查) | 编译阶段(编译器优化,有完整编译检查) |
| 类型安全 | 无类型检查,参数 / 返回值可能隐含类型错误 | 严格类型检查(同普通函数),参数 / 返回值类型不匹配会编译报错 |
| 参数处理 | 直接文本替换,易因参数副作用(如自增 / 自减)出问题 | 参数先求值再传递,无副作用(同普通函数) |
| 作用域 | 全局生效(预处理无作用域概念),易命名冲突 | 遵循普通函数作用域(如局部内联函数仅在当前作用域有效) |
| 函数特性 | 无函数语义(无栈帧、无返回值检查、不支持递归) | 保留函数语义(支持递归、返回值检查、可调试) |
| 编译器控制 | 强制替换(预处理阶段必须执行) | 编译器自主决策(可忽略inline,如函数体过大时不内联) |
| 重载 / 多态 | 不支持重载(宏名是文本,无法区分参数类型) | 支持重载、类成员内联函数可支持多态(虚函数除外) |
| 内存占用 | 替换越多,代码膨胀越严重(无编译器优化) | 编译器可平衡内联与代码膨胀(如仅对高频小函数内联) |
| 场景 | 推荐使用 | 原因 |
|---|---|---|
| 高频小函数(如数值计算、简单判断) | 内联函数 | 类型安全、无副作用、编译器可灵活优化 |
| 需预处理阶段替换(如编译开关、常量) | 宏函数 | 仅预处理阶段生效,支持条件编译等特性 |
| 类成员函数 | 内联函数 | 隐式 inline,结合类的封装性,类型安全 |
| 需要重载 / 多态 | 内联函数 | 宏不支持重载,内联函数兼容普通函数特性 |
注:内联函数就是会比宏函数直接替换的方式安全得多,会有语法检查,只不过比较适合较短/简单的函数替换来减小开销,必须看使用场景,否则就是负优化。
2.19
三、网络知识
3.1 TCP的连接与断开的过程
3.1.1 三次握手四次挥手
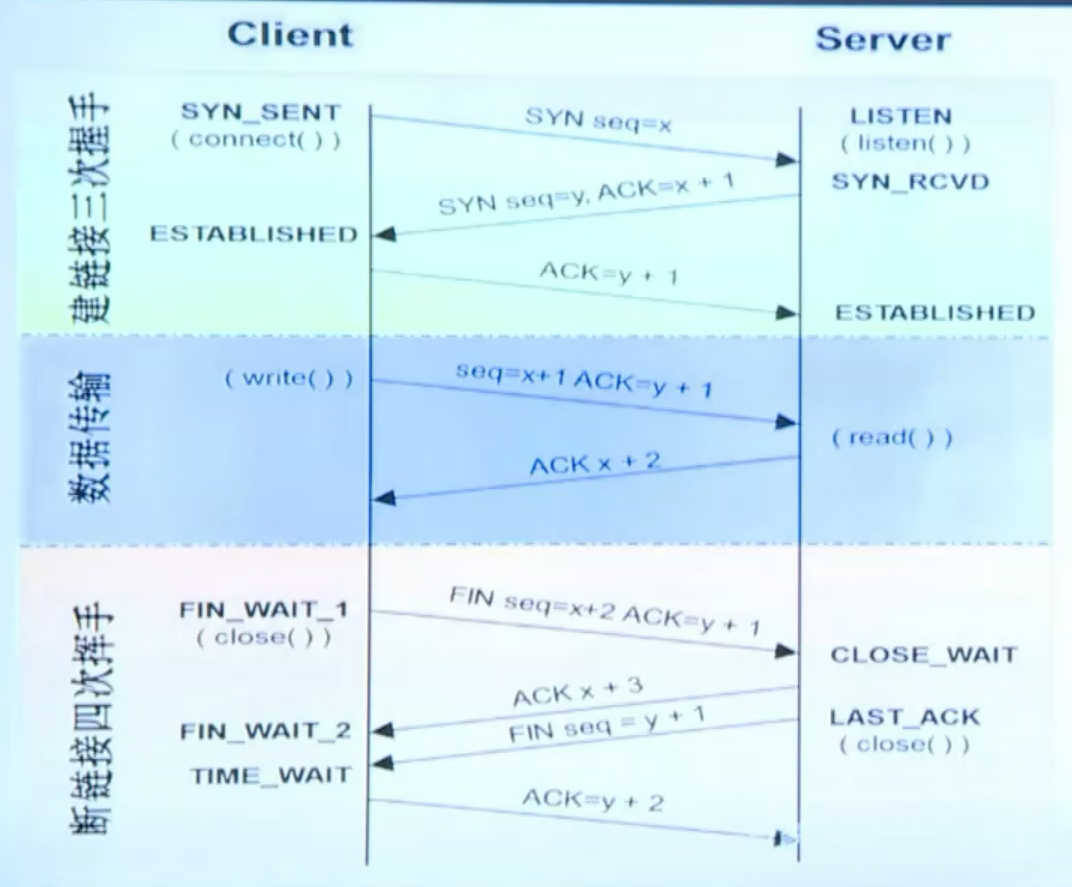
3.2 HTTP与MQTT的区别与使用场景
HTTP:「请求 - 响应」模式,适用于客户端主动获取数据、Web 交互、设备配置查询,开销较高,无实时性保障;
MQTT:「发布 - 订阅」模式,适用于物联网设备实时数据上报、远程控制、低带宽 / 低功耗场景,开销极低,支持 QoS 分级可靠传输。
| 对比维度 | HTTP(1.1/2) | MQTT(3.0) |
|---|---|---|
| 通信模式 | 请求 - 响应(Client 发起请求,Server 被动响应) | 发布 - 订阅(Broker 中转,多 Client 解耦通信) |
| 连接方式 | 短连接(默认)/ 长连接(需配置 Keep-Alive) | 长连接(默认,心跳包维持) |
| 数据开销 | 高(头部冗余大,如 HTTP 头占数十 KB) | 极低(固定头部 2 字节, payload 纯数据) |
| 实时性 | 低(需客户端主动轮询,延迟取决于轮询周期) | 高(消息实时推送,延迟毫秒级) |
| QoS(服务质量) | 无原生支持(需自定义重试 / 确认) | 三级 QoS:0(最多一次)、1(至少一次)、2(恰好一次) |
| 功耗表现 | 高(频繁建立连接、头部传输消耗算力 / 带宽) | 低(长连接减少握手开销,适合电池供电设备) |
| 嵌入式实现难度 | 简单(LwIP 原生支持 HTTP 客户端 / 服务器) | 中等(需集成 MQTT 客户端库,如 Paho-MQTT) |
| 适用设备 | 算力 / 带宽充足的设备(如带屏终端、网关) | 低算力 / 低带宽设备(如 STM32+GPRS/NB-IoT、传感器) |
| 消息路由 | 点对点(Client→指定 Server) | 多对多(发布者→Broker→所有订阅者) |
| 离线消息 | 不支持(断开连接后无法接收消息) | 支持(Broker 缓存消息,客户端重连后推送) |
| 核心场景 | 设备配置查询、Web 界面交互、偶尔数据获取 | 传感器实时上报、设备远程控制、多设备协同 |
优先选 MQTT 的场景:
(1)传感器实时数据上报(如每秒 / 每分钟一次);
(2)设备远程控制(如开关、电机调速);
(3)低功耗设备(如电池供电的土壤传感器,NB-IoT/GPRS 模块);
(4)多设备协同(如智能家居、工业物联网多传感器联动)。
优先选 HTTP 的场景:
(1)设备配置查询 / 修改(如查询设备固件版本、设置 WiFi 参数);
(2)设备与 Web 服务器交互(如带 Web 界面的网关);
(3)低频数据传输(如每天一次的设备状态上报);
(4)无 MQTT Broker 部署条件(如简单单机设备)。
混合使用场景:
(1)设备上电后通过 HTTP 获取 MQTT Broker 地址、Topic 配置;
(2)实时数据通过 MQTT 上报,设备配置 / 固件更新通过 HTTP 实现。
3.3 TCP和UDP的区别
| 对比维度 | TCP(传输控制协议) | UDP(用户数据报协议) |
|---|---|---|
| 核心定位 | 面向连接的可靠传输协议 | 无连接的轻量级传输协议 |
| 连接性 | 面向连接(需三次握手建立连接,四次挥手释放连接) | 无连接(发送数据前无需建立连接,直接封装数据报发送) |
| 可靠性保障 | 1. 确认应答(ACK);2. 超时重传;3. 序号 / 确认号(保证数据有序);4. 重传机制(ARQ);5. 校验和 | 仅提供校验和(可选,用于检测数据错误,无重传机制),不保证数据送达 / 有序 |
| 数据顺序 | 保证数据按发送顺序接收(通过序号排序、重传丢失报文) | 不保证顺序(数据报独立传输,可能乱序、丢失、重复) |
| 流量控制 | 有(滑动窗口机制,避免接收方缓冲区溢出) | 无(发送方无节制发送,可能导致接收方拥塞丢失) |
| 拥塞控制 | 有(慢启动、拥塞避免、快速重传、快速恢复,适应网络带宽变化) | 无(不感知网络拥塞,持续发送数据,可能加剧网络拥堵) |
| 头部开销 | 较大(固定头部 20 字节,可选选项字段,总长度可达 60 字节) | 极小(固定头部 8 字节,无可选字段,开销仅为 TCP 的 1/3~1/4) |
| 传输效率 | 较低(连接建立 / 释放、重传、拥塞控制等机制引入延迟) | 极高(无额外控制机制,延迟低、实时性强) |
| 数据边界 | 字节流服务(无数据边界,接收方需自行处理数据拆分) | 数据报服务(每个数据报独立,接收方按数据报完整接收,保留发送方的数据边界) |
| 端口与寻址 | 基于端口号,支持一对一通信(默认),不支持多播 / 广播 | 基于端口号,支持一对一、一对多、多播 / 广播通信 |
| 资源占用 | 高(需维护连接状态、滑动窗口、重传队列等,消耗 CPU / 内存资源多) | 低(无连接状态维护,协议栈处理逻辑简单,适合资源受限设备) |
| 嵌入式 / 物联网适用场景 | 1. 需可靠传输的控制指令(如设备配置、远程控制);2. 文件传输(固件升级、日志上传);3. 关键数据上报(如报警信息) | 1. 实时性要求高的场景(如传感器数据采集、视频流传输);2. 低功耗 / 低带宽设备(如 LoRa 网关数据转发);3. 广播 / 多播场景(如设备发现、组播通知) |
| 典型应用协议 | HTTP/HTTPS、FTP、SSH、Telnet、MQTT(默认基于 TCP) | DNS、DHCP、SNMP、RTP(音视频传输)、MQTT-SN(轻量级 MQTT,支持 UDP)、CoAP(物联网应用层协议,支持 UDP) |
3.4
四、项目工程知识问答
4.1 PID算法核心
PID 算法是工业控制领域最核心的闭环控制算法,其核心可概括为:以 "目标值 - 实际值" 的误差为唯一驱动源,通过比例(P)、积分(I)、微分(D)三个维度的协同调控,在 "响应速度、稳态精度、系统稳定性" 三者间找到最优平衡,最终让被控对象的实际值快速、准确、稳定地跟踪目标值。
4.2 MQTT分为哪几个等级
MQTT 核心等级为 3 个服务质量(QoS)等级,用于定义消息传输的可靠性
| 等级 | 名称 | 可靠性 | 开销 | 适用场景 |
|---|---|---|---|---|
| QoS0 | 最多一次 | 可能丢失 | 最小 | 传感器心跳、实时温湿度 |
| QoS1 | 至少一次 | 无丢失、可能重复 | 中等 | 设备控制指令 |
| QoS2 | 恰好一次 | 无丢失无重复 | 最大 | 固件升级、金融交易等核心数据 |
| QoS 等级 | 核心定义 | 传输机制 | 适用场景 | 嵌入式应用示例 |
|---|---|---|---|---|
| QoS 0(最多一次) | 消息仅发送一次,不确认、不重发 | 发送方→接收方(无反馈) | 网络稳定、允许丢失的场景(如传感器周期性上报) | STM32 采集温湿度,定时向网关发送数据(丢失可容忍) |
| QoS 1(至少一次) | 消息确保送达,可能重复 | 发送方→接收方→发送方(PUBACK 确认) | 需确保送达、允许重复的场景(如控制指令下发) | FreeRTOS 任务向设备发送 "启动电机" 指令(必须收到,重复可通过逻辑去重) |
| QoS 2(恰好一次) | 消息确保送达且仅一次,无重复 | 四步握手(PUB→PUBREC→PUBREL→PUBCOMP) | 严格禁止重复、需精准传输的场景(如数据上报、指令确认) | 嵌入式设备向云平台上报报警数据(避免重复计数) |
4.3 OTA的大致分类,一般使用哪些OTA升级
| 分类名称 | 英文缩写 | 升级对象 | 核心特点 | 典型应用场景 |
|---|---|---|---|---|
| 固件升级 | FOTA(Firmware OTA) | 设备底层固件(如 MCU/SoC 的程序) | 影响硬件核心功能,需重启生效,安全性要求高 | 物联网传感器、智能家居设备、汽车 ECU |
| 软件升级 | SOTA(Software OTA) | 应用层软件(如 APP、操作系统) | 不影响底层硬件,可动态更新,灵活性强 | 智能手机系统更新、车载娱乐系统、智能电视 APP |
| 配置升级 | COTA(Configuration OTA) | 设备参数配置(如网络参数、工作模式) | 无需重启,更新速度快,数据量小 | 工业设备远程参数调整、智能家居场景模式切换 |
| 诊断升级 | DOTA(Diagnostics OTA) | 设备诊断程序 / 日志系统 | 用于远程故障排查、性能优化 | 汽车远程诊断、工业设备预测性维护 |
| 升级方式 | 核心特点 | 存储空间需求 | 网络带宽需求 | 升级失败风险 | 适用设备类型 |
|---|---|---|---|---|---|
| 全量升级 | 完整镜像替换,不依赖旧版本 | 中(仅需目标版本存储空间) | 高 | 中 | 所有设备,尤其首次升级、跨大版本更新 |
| 差分升级(增量升级) | 仅传输新旧版本差异部分,需基础版本 | 低(基础版本空间 + 补丁包空间) | 低 | 中高 | 物联网低功耗设备、频繁小版本迭代场景 |
| 分块升级 | 镜像分块下载,支持断点续传 | 中(目标版本空间 + 单块缓存空间) | 中(弱网适应性强) | 低 | 偏远地区设备、卫星通信设备、大镜像升级 |
| 非 A/B 单分区升级 | 单分区直接更新,升级中不可用 | 低(仅需目标版本空间) | 中 | 高 | 8 位 MCU、小型传感器等资源受限低端设备 |
| 固件冗余升级 | 存储多版本(运行版 + 备份版 + 出厂版),支持快速回滚 | 高(多版本存储空间叠加) | 中 | 极低 | 工业控制器、医疗设备、汽车安全系统等关键设备 |
| 拷贝升级 | 先下载到临时存储区,验证后拷贝至运行分区 | 中(临时存储区 + 目标版本空间) | 中 | 低 | STM32 等 32 位 MCU 嵌入式设备 |
| 乒乓升级(A/B 系统升级) | 双分区(A 区运行 + B 区更新),无缝切换 | 高(双倍目标版本存储空间) | 中 | 极低 | 智能手机、自动驾驶汽车、服务器等高可用性要求设备 |