CAD建模的"效率瓶颈",终于被大模型打破了?
传统CAD建模需要设计师手动绘制轮廓、调试参数,哪怕是简单的几何图形,也得耗费不少时间------而CAD-GPT的出现,让"上传一张草图→直接生成可编辑的CAD序列"成为可能。它本质是多模态大模型在工业设计领域的定制化落地,今天我们拆解它的核心架构逻辑。
一、CAD-GPT的基础:站在LLaVA1.5的肩膀上
CAD-GPT并非从零搭建,而是基于LLaVA1.5 7B(底座是Vicuna-LLaMA2)改造而来------LLaVA本身是成熟的"图像-文本"多模态模型,CAD-GPT则把它的输出从"自然语言"改成了"CAD序列",相当于给大模型装了个"CAD生成插件"。
二、三大模块:把图像"翻译"成CAD能读的语言
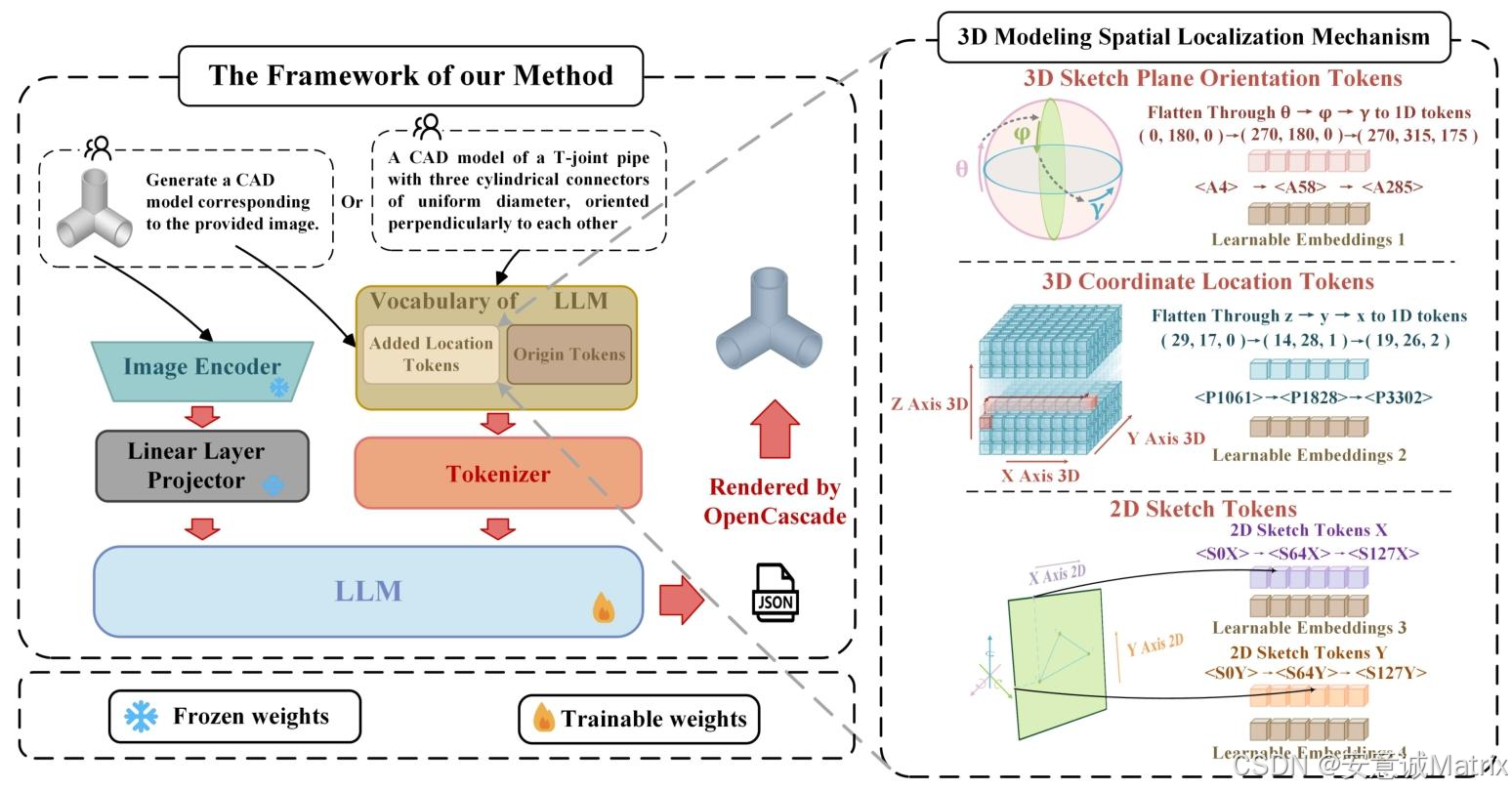
CAD-GPT的核心是**"图像→特征→CAD序列"的链路打通**,靠三个模块实现:
-
视觉编码器:给图像"拍X光"
用预训练的ViT-L/14-336px模型,把输入的草图/图像转成高维特征向量 Z v Z_v Zv------这个向量对人类来说是"乱码",但包含了图像的形状、轮廓等关键信息。
-
视觉-语言投影层:给图像"装文本外壳"
人类看不懂 Z v Z_v Zv,LLM也看不懂------这层的作用是把 Z v Z_v Zv映射到LLM的"文本特征空间",输出视觉token S v S_v Sv。相当于把图像信息翻译成LLM能"读"的格式,让大模型能把图像和文本指令放在一起处理。
-
LLM推理层:生成CAD序列的"大脑"
接收视觉token S v S_v Sv和你的文本指令(比如"三维圆柱" + 特定格式的几何坐标表达),LLM会按概率生成连续的CAD序列 S a S_a Sa------这个序列就是OCC等几何工具能直接解析的"建模代码",最终输出可视化的几何图形。
三、训练策略:用"冻结+微调"平衡效果与成本
CAD-GPT没把所有模块都重训一遍,而是做了个聪明的选择:
- 冻结视觉编码器+投影层的预训练权重(复用它们的图像理解能力);
- 只全量微调LLM推理层,用"图像-CAD序列""文本-CAD序列"的混合数据,让模型学会"图像/文字→CAD"的映射关系。
这样既节省了计算资源,又能快速让大模型适配CAD场景。
四、你可能关心:人类看不懂的向量,大模型怎么"理解"?
之前有朋友问:"视觉token是乱码,大模型真的能懂吗?"
其实大模型不需要"人类式的理解"------它靠两点实现关联:
- 空间匹配:投影层已经把图像特征转成LLM熟悉的token格式,相当于"说同一种语言";
- 训练关联:通过大量数据,模型学到了"看到这个视觉token,应该输出对应的CAD序列"的概率规律,不需要知道向量的"字面意思"。
总结
CAD-GPT的核心逻辑,是用多模态大模型打通"图像/文本→CAD"的链路------它没发明新模块,而是把成熟的视觉-语言模型,高效适配到了工业设计场景。后续如果用上更大的模型、更多的行业数据,说不定能实现更复杂的装配体、参数化建模。