🎯 TimeSformer ------ 视频理解中的纯 Transformer 开创者
论文 :Is Space-Time Attention All You Need for Video Understanding?
作者 :Gedas Bertasius 等(Facebook AI, ICML 2021)
关键词:TimeSformer、视频 Transformer、时空注意力、动作识别
一、背景:为什么需要 TimeSformer?
在 ViT(Vision Transformer) 成功之后,研究者开始探索:
❓ 能不能用 纯 Transformer(无卷积)来理解视频?
传统方法如 I3D、SlowFast 使用 3D 卷积建模时空信息,但存在:
- 感受野有限;
- 难以建模长距离依赖(如"起跑→冲刺→撞线");
- 卷积核大小固定,不够灵活。
👉 TimeSformer 的提出正是为了验证:
✅ "是否仅靠自注意力机制,就能实现强大的视频理解?"
二、核心思想:用 Transformer 替代 3D 卷积
✅ 将视频视为一系列图像块(patches),直接在所有时空 patch 上应用自注意力机制,实现全局建模。
🔥 两大创新:
- 将视频拆分为 3D patches(时间 + 空间)
- 设计多种时空注意力机制,高效建模时间动态
三、网络结构详解
1. 整体流程
输入视频(T 帧 × H × W × 3)
↓
Patch Partition → 切分为 T × (H/P) × (W/P) 个 3D patch
↓
Linear Embedding → 每个 patch 映射为向量
↓
Positional Encoding → 加入位置信息(空间 + 时间)
↓
Transformer Encoder Blocks(堆叠)
↓
[CLS] token → 分类头 → 动作类别- 类似 ViT,但扩展到时间维度;
- 使用
[CLS]token 聚合全局信息用于分类。
2. Patch 划分(3D Patching)
- 将每帧划分为
P×P的空间 patch(如 16×16); - 时间维度也划分,每个 patch 包含连续
t帧(如 t=1 或 2); - 最终得到
T/t × H/P × W/P个时空 patch。
例如:32 帧 × 224×224 → 每帧 14×14 个 patch → 共
32×14×14 = 6272个 tokens。
3. 位置编码(Positional Encoding)
- 传统 ViT 只有 2D 位置编码;
- TimeSformer 引入 3D 位置编码 :
(t, h, w)三元组; - 支持两种方式:
- Joint:统一编码时空位置;
- Separate:分别编码空间和时间位置。
4. Transformer Block 结构
每个 block 包含:
- 多头自注意力(Multi-head Self-Attention)
- MLP
- LayerNorm
- 残差连接
但关键在于:如何设计注意力机制?
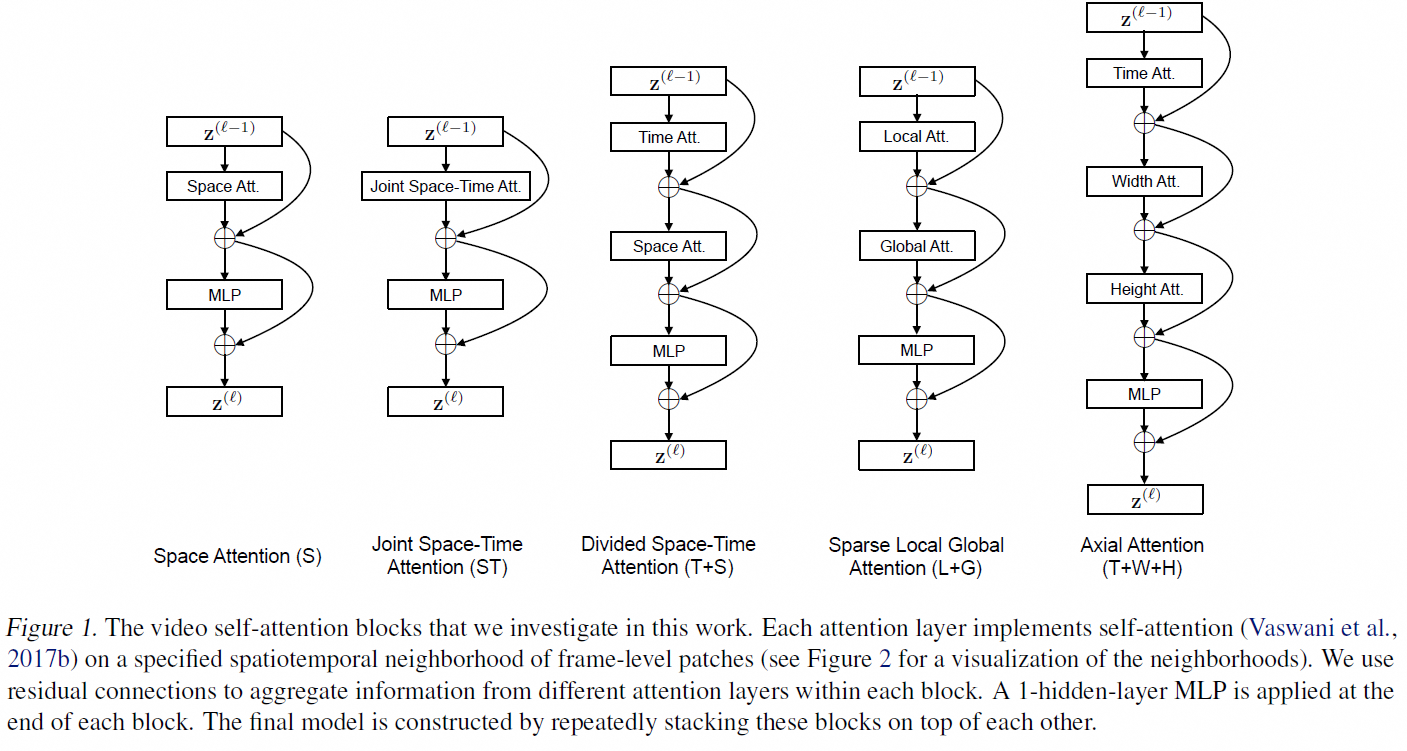

四、四种时空注意力机制(核心创新)
TimeSformer 提出了 四种不同的注意力策略,用于建模时空关系:
| 名称 | 注意力范围 | 说明 |
|---|---|---|
| 1. Full Attention | 所有 patch 之间全局注意力 | 计算量大,但建模最强 |
| 2. Factorized Encoder | 空间注意力 + 时间注意力 分离 | 先空间后时间,降低复杂度 |
| 3. Space-only | 只在空间维度做注意力 | 时间不变,类似 ViT |
| 4. Time-only | 只在时间维度做注意力 | 空间不变,建模运动 |
✅ 推荐组合:Factorized Encoder(空间 + 时间分离)
text
Step 1: 空间注意力
- 对每一帧内的所有空间 patch 做自注意力;
- 学习"这一帧中物体之间的关系";
Step 2: 时间注意力
- 对每个空间位置(如左上角 patch),在所有时间步上做自注意力;
- 学习"这个位置随时间的变化";✅ 优势:计算量从 O((T×H×W)2)O((T×H×W)^2)O((T×H×W)2) 降为 O(T×H2+H2×T)O(T×H^2 + H^2×T)O(T×H2+H2×T)
五、为什么 TimeSformer 强?
| 优势 | 说明 |
|---|---|
| ✅ 全局感受野 | 自注意力可直接建模任意两个 patch 的关系 |
| ✅ 长时依赖建模 | 能捕捉"开始"与"结束"的语义关联 |
| ✅ 无需卷积 | 完全基于注意力,结构统一 |
| ✅ 性能优异 | 在 Kinetics、Something-Something 上表现优异 |
| ✅ 可扩展性强 | 可结合其他 Transformer 技巧(如 DeiT、MAE) |
六、局限性
| 局限 | 说明 |
|---|---|
| ❌ 计算量大 | 全局注意力 O(N\^2) ,不适合长视频 |
| ❌ 参数量大 | Large 版本 >120M,训练成本高 |
| ❌ 对短动作不敏感 | 相比 TSM/TAdaConv,对快速动作建模略慢 |
| ❌ 需要大量数据 | 小数据集上容易过拟合 |
七、总结
| 项目 | 内容 |
|---|---|
| 🧠 核心思想 | 用纯 Transformer 替代 3D 卷积,建模时空关系 |
| 📦 输入形式 | 32或16 帧 × 224×224 |
| 🕒 时序建模 | 全局或分离式自注意力 |
| ✅ 优点 | 全局建模、结构统一、可解释性强 |
| ❌ 缺点 | 计算量大、参数多、训练贵 |
| 🚀 历史地位 | 首个成功的纯 Transformer 视频模型,开启新范式 |
💬 一句话概括 TimeSformer:
TimeSformer = ViT + 3D Patches + 时空注意力 = 视频理解的 Transformer 开创者
它证明了:"Space-Time Attention 真的可以用于视频理解!"