在高并发系统中,缓存就像数据库的"御前侍卫",能拦截绝大部分重复请求,让系统性能飙升。但如果配置不当,这个"侍卫"可能瞬间"倒戈",导致数据库CPU飙满、响应超时,甚至整个系统连锁崩溃------这背后往往是缓存穿透、击穿、雪崩三大难题在作祟。今天我们就从原理到实践,结合真实代码示例,彻底解决这三大痛点,让你的系统在流量洪峰中稳如泰山。
一、缓存基础:先搞懂"侍卫"的工作逻辑
在解决问题前,我们得先明确缓存的核心价值和工作流程。缓存本质是基于内存的高速数据存储层,核心目标是存储"读多写少、计算耗时"的数据(比如商品详情、用户信息),减少数据库IO压力。
1. 核心工作流程(读场景)
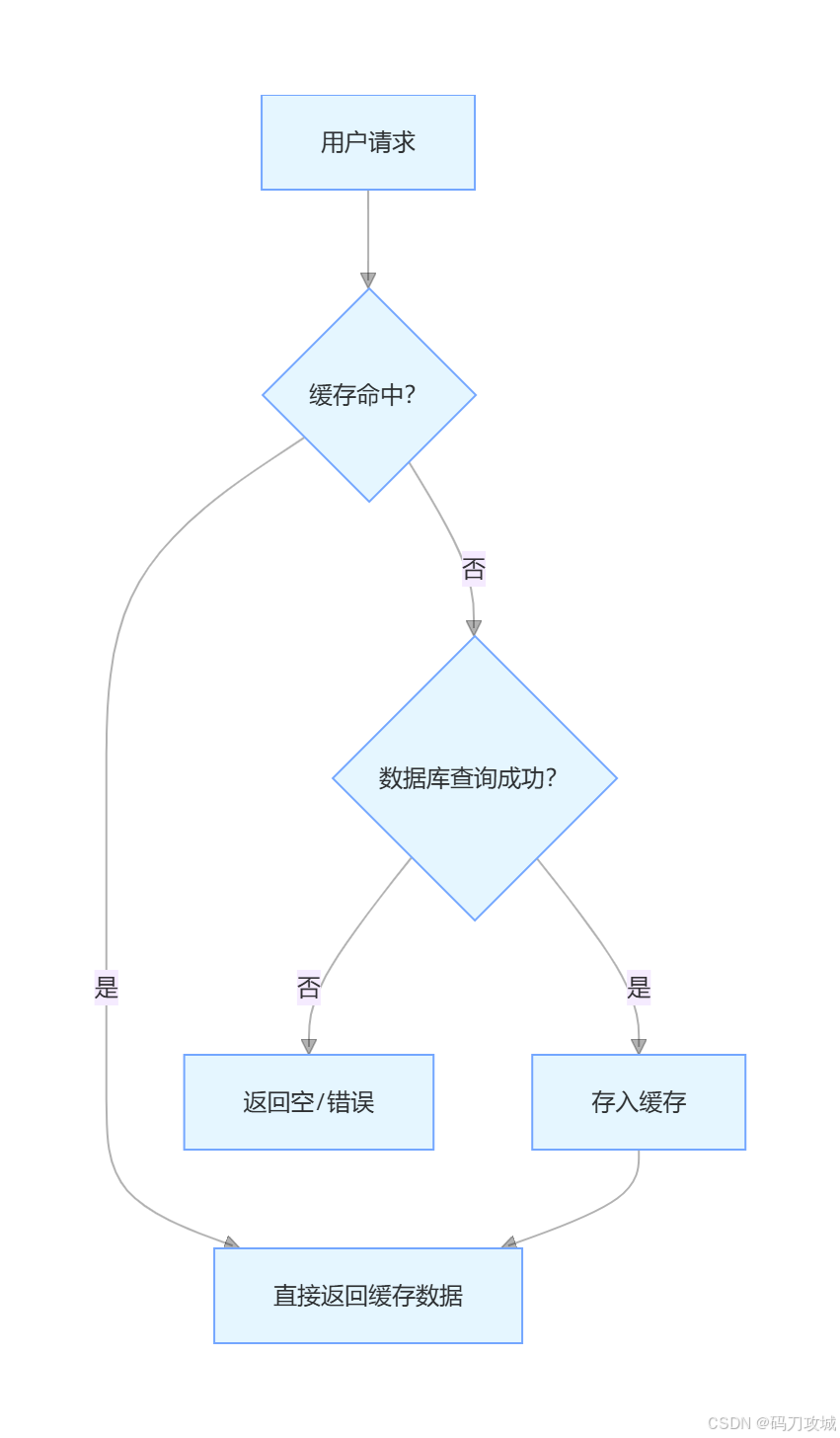
这个流程看似简单,但每个环节都可能出问题。比如缓存和数据库都没有的数据、热点数据过期瞬间、大量缓存同时失效------这就是我们接下来要解决的三大难题。
2. 常见缓存组件
实际开发中,常用的缓存组件有:
- Redis:分布式场景首选,支持多种数据结构、过期时间、集群部署
- Guava Cache:本地缓存,适合单应用场景,无需网络开销
- Caffeine:新一代本地缓存,性能优于Guava,支持自动刷新
本文以应用最广泛的Redis为例,结合Java(Spring Boot)和Python(Flask)代码示例,给出可直接落地的解决方案。
二、缓存穿透:不存在的数据"轰炸"数据库
1. 问题本质
请求查询的数据在缓存和数据库中都不存在 ,导致每次请求都"穿透"缓存,直接命中数据库。比如恶意攻击者用随机无效ID(如user_id=-999、商品ID=abc123)发起高并发请求,数据库会被这些无效查询拖垮。
2. 危害
- 数据库连接耗尽、CPU飙至100%,直接宕机
- 大量无效请求占用网络带宽,影响正常用户访问
3. 解决方案(从简单到进阶)
方案1:接口层参数校验(第一道防线)
在请求进入缓存和数据库前,先对参数进行合法性校验,直接拦截明显无效的请求。
Java(Spring Boot)示例:
java
@RestController
@RequestMapping("/user")
public class UserController {
@Autowired
private UserService userService;
@GetMapping("/{userId}")
public Result<User> getUser(@PathVariable Long userId) {
// 参数校验:拦截负数ID、0、空值
if (userId == null || userId <= 0) {
return Result.error("无效用户ID");
}
return Result.success(userService.getUserById(userId));
}
}Python(Flask)示例:
python
from flask import Flask, jsonify
app = Flask(__name__)
@app.route('/user/<<int:user_id>')
def get_user(user_id):
# 参数校验:拦截负数ID
if user_id <= 0:
return jsonify({"code": -1, "msg": "无效用户ID", "data": None}), 400
return jsonify({"code": 0, "msg": "success", "data": get_user_from_service(user_id)})方案2:缓存空对象(低成本方案)
如果数据库查询结果为空,仍将该key存入缓存,值设为null(或特殊标记如"NOT_EXIST"),并设置较短的过期时间(如5-10分钟)。下次相同请求会直接命中缓存,避免访问数据库。
Java + Redis 示例:
java
@Service
public class UserService {
@Autowired
private StringRedisTemplate redisTemplate;
@Autowired
private UserMapper userMapper;
private static final String CACHE_KEY_USER = "user:info:";
private static final long CACHE_NULL_TTL = 300; // 空对象缓存5分钟
public User getUserById(Long userId) {
String cacheKey = CACHE_KEY_USER + userId;
// 1. 先查缓存
String cacheValue = redisTemplate.opsForValue().get(cacheKey);
if (cacheValue != null) {
// 命中缓存:如果是特殊标记,返回null
if ("NOT_EXIST".equals(cacheValue)) {
return null;
}
// 反序列化返回
return JSON.parseObject(cacheValue, User.class);
}
// 2. 缓存未命中,查数据库
User user = userMapper.selectById(userId);
if (user != null) {
// 3. 数据库有数据,存入缓存(设置正常过期时间,如1小时)
redisTemplate.opsForValue().set(cacheKey, JSON.toJSONString(user), 3600, TimeUnit.SECONDS);
} else {
// 4. 数据库无数据,缓存空对象
redisTemplate.opsForValue().set(cacheKey, "NOT_EXIST", CACHE_NULL_TTL, TimeUnit.SECONDS);
}
return user;
}
}缺点:
- 缓存中会存储大量无效的
null键,占用内存 - 若攻击者使用随机key(如
user:12345、user:67890),缓存空对象的效果会大打折扣
方案3:布隆过滤器(终极方案)
布隆过滤器是一种空间效率极高的概率性数据结构,核心作用是"判断一个元素是否在集合中",能从源头拦截不存在的key。
布隆过滤器原理
- 由一个二进制位数组(bitmap)和多个独立哈希函数组成
- 初始化时,将所有可能存在的有效key(如所有用户ID、商品ID)通过哈希函数映射到位数组,标记为1
- 收到请求时,先通过布隆过滤器判断key是否存在:
- 若不存在:直接返回,拦截请求
- 若存在:可能存在(有极小误判率),继续查询缓存和数据库
代码实现(Google Guava布隆过滤器)
1. 引入依赖(Java)
xml
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>32.0.0-jre</version>
</dependency>2. 初始化布隆过滤器(项目启动时加载有效key)
java
@Component
public class BloomFilterConfig {
@Autowired
private UserMapper userMapper;
// 布隆过滤器:存储所有有效用户ID
private BloomFilter<Long> userBloomFilter;
// 项目启动时初始化
@PostConstruct
public void initBloomFilter() {
// 1. 查询所有有效用户ID
List<Long> allUserId = userMapper.selectAllUserId();
// 2. 初始化布隆过滤器(预计数据量10万,误判率0.01)
userBloomFilter = BloomFilter.create(
Funnels.longFunnel(),
allUserId.size(),
0.01 // 误判率越低,需要的内存越大
);
// 3. 将所有用户ID加入布隆过滤器
for (Long userId : allUserId) {
userBloomFilter.put(userId);
}
}
// 提供判断方法
public boolean mightContain(Long userId) {
return userBloomFilter.mightContain(userId);
}
}3. 在Service中使用
java
@Service
public class UserService {
@Autowired
private BloomFilterConfig bloomFilterConfig;
// ... 其他依赖
public User getUserById(Long userId) {
// 1. 布隆过滤器拦截:不存在直接返回
if (!bloomFilterConfig.mightContain(userId)) {
return null;
}
// 2. 后续流程:查缓存 -> 查数据库(同方案2)
String cacheKey = CACHE_KEY_USER + userId;
String cacheValue = redisTemplate.opsForValue().get(cacheKey);
if (cacheValue != null) {
return "NOT_EXIST".equals(cacheValue) ? null : JSON.parseObject(cacheValue, User.class);
}
User user = userMapper.selectById(userId);
if (user != null) {
redisTemplate.opsForValue().set(cacheKey, JSON.toJSONString(user), 3600, TimeUnit.SECONDS);
} else {
redisTemplate.opsForValue().set(cacheKey, "NOT_EXIST", 300, TimeUnit.SECONDS);
}
return user;
}
}布隆过滤器优缺点
- 优点:内存占用极小(10万数据+0.01误判率,仅需约120KB)、查询效率极高(O(k),k为哈希函数个数)
- 缺点:存在极小误判率(可通过调整参数控制)、不支持删除操作(若需删除,可使用布谷鸟过滤器)
三、缓存击穿:热点key的"过期危机"
1. 问题本质
某个热点key(如秒杀商品详情、热门活动页面)在缓存过期的瞬间,大量并发请求同时涌入,导致所有请求都直接访问数据库,造成数据库瞬间压力暴增。
关键区别
- 与穿透的不同:热点key在数据库中真实存在,只是缓存刚好过期
- 与雪崩的不同:击穿是"单点问题"(单个热点key),雪崩是"全局问题"(大量key)
2. 解决方案
方案1:互斥锁(分布式锁)
核心思路:缓存过期时,只允许一个请求去查询数据库并更新缓存,其他请求等待或返回默认值,避免数据库被同时冲击。
Java + Redis分布式锁示例:
java
@Service
public class GoodsService {
@Autowired
private StringRedisTemplate redisTemplate;
@Autowired
private GoodsMapper goodsMapper;
private static final String CACHE_KEY_GOODS = "goods:info:";
private static final String LOCK_KEY_GOODS = "lock:goods:";
private static final long LOCK_TTL = 3000; // 锁过期时间3秒(防止死锁)
public Goods getGoodsById(Long goodsId) {
String cacheKey = CACHE_KEY_GOODS + goodsId;
// 1. 先查缓存
String cacheValue = redisTemplate.opsForValue().get(cacheKey);
if (cacheValue != null) {
return JSON.parseObject(cacheValue, Goods.class);
}
// 2. 缓存未命中,获取分布式锁
String lockKey = LOCK_KEY_GOODS + goodsId;
boolean lockAcquired = false;
try {
// 使用Redis SETNX实现分布式锁(NX:不存在则设置,PX:过期时间)
lockAcquired = redisTemplate.opsForValue().setIfAbsent(
lockKey, "1", LOCK_TTL, TimeUnit.MILLISECONDS
);
if (lockAcquired) {
// 3. 抢到锁:查数据库 -> 更新缓存
Goods goods = goodsMapper.selectById(goodsId);
if (goods != null) {
// 缓存设置较长过期时间(如1小时)
redisTemplate.opsForValue().set(cacheKey, JSON.toJSONString(goods), 3600, TimeUnit.SECONDS);
}
return goods;
} else {
// 4. 未抢到锁:休眠100ms后重试(或返回默认值)
Thread.sleep(100);
return getGoodsById(goodsId); // 递归重试
}
} catch (InterruptedException e) {
log.error("获取锁失败", e);
return null;
} finally {
// 5. 释放锁(只有抢到锁的线程才释放)
if (lockAcquired) {
redisTemplate.delete(lockKey);
}
}
}
}方案2:逻辑过期("永不过期")
核心思路:缓存不设置物理过期时间(TTL),而是在value中嵌入"逻辑过期时间"。当请求发现数据逻辑过期时,异步更新缓存,其他请求仍返回旧数据,保证用户体验。
实现步骤
- 设计缓存value结构:包含真实数据+逻辑过期时间
- 初始化缓存时,设置逻辑过期时间(如1小时)
- 收到请求时,先判断逻辑是否过期:
- 未过期:直接返回数据
- 已过期:抢锁异步更新缓存,当前请求返回旧数据
Java示例:
java
// 1. 定义缓存value结构
@Data
public class CacheData<T> {
private T data; // 真实数据
private long expireTime; // 逻辑过期时间(时间戳,毫秒)
}
@Service
public class GoodsService {
@Autowired
private StringRedisTemplate redisTemplate;
@Autowired
private GoodsMapper goodsMapper;
private static final String CACHE_KEY_GOODS = "goods:info:";
private static final String LOCK_KEY_GOODS = "lock:goods:";
private static final long LOGIC_EXPIRE = 3600 * 1000; // 逻辑过期1小时
private static final ExecutorService CACHE_UPDATE_POOL = Executors.newFixedThreadPool(5); // 异步更新线程池
public Goods getGoodsById(Long goodsId) {
String cacheKey = CACHE_KEY_GOODS + goodsId;
// 1. 查缓存
String cacheValue = redisTemplate.opsForValue().get(cacheKey);
if (cacheValue == null) {
// 缓存未初始化,查数据库并初始化(略,同方案1)
return initCache(goodsId);
}
// 2. 解析缓存数据
CacheData<Goods> cacheData = JSON.parseObject(cacheValue, new TypeReference<CacheData<Goods>>() {});
Goods goods = cacheData.getData();
long expireTime = cacheData.getExpireTime();
// 3. 判断逻辑是否过期
if (System.currentTimeMillis() < expireTime) {
// 未过期,直接返回
return goods;
}
// 4. 已过期,抢锁异步更新
String lockKey = LOCK_KEY_GOODS + goodsId;
boolean lockAcquired = redisTemplate.opsForValue().setIfAbsent(lockKey, "1", 3000, TimeUnit.MILLISECONDS);
if (lockAcquired) {
// 异步更新缓存
CACHE_UPDATE_POOL.submit(() -> {
try {
// 查数据库
Goods newGoods = goodsMapper.selectById(goodsId);
// 更新缓存(逻辑过期时间=当前时间+1小时)
CacheData<Goods> newCacheData = new CacheData<>();
newCacheData.setData(newGoods);
newCacheData.setExpireTime(System.currentTimeMillis() + LOGIC_EXPIRE);
redisTemplate.opsForValue().set(cacheKey, JSON.toJSONString(newCacheData));
} catch (Exception e) {
log.error("异步更新缓存失败", e);
} finally {
// 释放锁
redisTemplate.delete(lockKey);
}
});
}
// 5. 返回旧数据(保证用户体验)
return goods;
}
// 初始化缓存(首次查询或缓存被删除时调用)
private Goods initCache(Long goodsId) {
Goods goods = goodsMapper.selectById(goodsId);
CacheData<Goods> cacheData = new CacheData<>();
cacheData.setData(goods);
cacheData.setExpireTime(System.currentTimeMillis() + LOGIC_EXPIRE);
redisTemplate.opsForValue().set(CACHE_KEY_GOODS + goodsId, JSON.toJSONString(cacheData));
return goods;
}
}两种方案对比
| 方案 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 互斥锁 | 数据一致性高(无脏数据) | 可能导致请求等待,体验差 | 对数据一致性要求高的场景 |
| 逻辑过期 | 无请求等待,体验好 | 存在短期脏数据 | 秒杀、热门商品等场景 |
四、缓存雪崩:系统性的"灭顶之灾"
1. 问题本质
大量缓存key在同一时间过期,或缓存服务(如Redis)直接宕机,导致所有请求瞬间涌向数据库,数据库无法承载压力而崩溃,进而引发整个系统的连锁故障(如服务熔断、API超时)。
关键区别
- 与击穿的不同:雪崩是"面的问题"(大量key/整个缓存服务),击穿是"点的问题"(单个key)
2. 解决方案(预防+兜底)
方案1:错开过期时间(预防核心)
最简单有效的预防手段:给每个key的过期时间加上随机值,避免大量key同时过期。
Java示例:
java
// 原固定过期时间:1小时
// 优化后:1小时 + 0-300秒随机值
private static final long BASE_TTL = 3600; // 基础过期时间(秒)
private static final long RANDOM_TTL = 300; // 随机值范围(秒)
// 存入缓存时设置过期时间
redisTemplate.opsForValue().set(
cacheKey,
JSON.toJSONString(data),
BASE_TTL + new Random().nextInt((int) RANDOM_TTL),
TimeUnit.SECONDS
);Python示例:
python
import redis
import random
redis_client = redis.Redis(host='localhost', port=6379, db=0)
def set_cache(key, value):
base_ttl = 3600 # 1小时
random_ttl = random.randint(0, 300) # 0-300秒随机值
redis_client.setex(key, base_ttl + random_ttl, value)方案2:构建高可用缓存集群(预防缓存宕机)
缓存服务单点故障是雪崩的重要诱因,通过集群部署保证缓存服务的高可用性:
Redis高可用方案
- 哨兵模式(Sentinel):1主N从+哨兵节点,主节点宕机后哨兵自动选举新主节点
- 集群模式(Cluster):将数据分片存储在多个主节点,每个主节点有从节点,支持故障自动切换
Redis Cluster配置要点(极简版)
- 部署至少3个主节点,每个主节点对应1个从节点
- 开启集群模式,配置节点间通信端口(默认+10000)
- 数据通过哈希槽(16384个)分片存储,每个主节点负责部分槽位
方案3:服务降级与熔断(兜底措施)
当缓存宕机或数据库压力过大时,通过降级/熔断保护数据库,保证核心功能可用。
使用Sentinel实现熔断示例(Java):
- 引入依赖
xml
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-core</artifactId>
<version>1.8.6</version>
</dependency>- 配置熔断规则
java
@Configuration
public class SentinelConfig {
@PostConstruct
public void initFlowRules() {
// 针对数据库查询方法配置熔断规则
DegradeRule rule = new DegradeRule();
rule.setResource("selectGoodsById"); // 资源名(方法名)
rule.setGrade(RuleConstant.DEGRADE_GRADE_EXCEPTION_RATIO); // 按异常比例熔断
rule.setCount(0.5); // 异常比例阈值(50%)
rule.setTimeWindow(10); // 熔断时间窗口(10秒)
DegradeRuleManager.loadRules(Collections.singletonList(rule));
}
}- 在Service中使用
java
@Service
public class GoodsService {
// 标记为Sentinel资源
@SentinelResource(value = "selectGoodsById", fallback = "selectGoodsFallback")
public Goods selectGoodsById(Long goodsId) {
// 数据库查询逻辑
return goodsMapper.selectById(goodsId);
}
// 熔断降级兜底方法
public Goods selectGoodsFallback(Long goodsId) {
// 返回默认数据或提示信息
Goods fallbackGoods = new Goods();
fallbackGoods.setId(goodsId);
fallbackGoods.setName("系统繁忙,商品信息暂时无法获取");
return fallbackGoods;
}
}五、缓存最佳实践与拓展思考
1. 缓存更新策略(避免数据不一致)
缓存与数据库同步是高频问题,常用更新策略:
- Cache-Aside(旁路缓存):读走缓存、写走数据库,写后删除缓存(本文示例使用此策略)
- Write-Through(写透缓存):写操作同时更新缓存和数据库,缓存与数据库强一致(适合写少读多)
- Write-Back(写回缓存):写操作先更新缓存,异步批量更新数据库(性能高,但有数据丢失风险)
2. 缓存粒度选择
- 避免缓存过大的数据(如整个表数据),建议按业务场景拆分(如用户基本信息、用户扩展信息分开缓存)
- 避免缓存过细的数据(如单个字段),增加缓存key数量和维护成本
3. 缓存常见坑
- 缓存穿透:随机key攻击时,布隆过滤器+缓存空对象组合使用
- 缓存一致性:更新数据库后,务必删除缓存(而非更新缓存),避免并发场景下的数据不一致
- 死锁风险:分布式锁必须设置过期时间,避免锁未释放导致死锁
- 内存溢出:缓存key设置合理的过期时间,定期清理无效缓存,Redis开启内存淘汰策略(如LRU)
4. 进阶优化
- 本地缓存+分布式缓存:热点数据先查本地缓存(Caffeine),再查Redis,减少网络开销
- 缓存预热:系统启动时,提前将热点数据加载到缓存,避免首次请求穿透
- 监控告警:监控缓存命中率、过期key数量、数据库压力,设置阈值告警(如缓存命中率低于90%告警)
总结
缓存三大难题的核心都是"请求绕过缓存直接冲击数据库",但解决思路各有侧重:
- 穿透:重点是"拦截无效请求"(参数校验、布隆过滤器)
- 击穿:重点是"控制热点key并发请求"(互斥锁、逻辑过期)
- 雪崩:重点是"分散风险+兜底保护"(随机过期时间、集群高可用、熔断降级)
根据实际业务场景选择合适的解决方案。缓存不是"银弹",合理的架构设计+完善的监控告警,才能让系统在高并发场景下真正稳如泰山。