上次我们主要介绍了requests库基于正则表达式的方法实现爬虫,简单提了xpath的方法。
今天我们正式学习导入lxml库使用xpath的方法实现爬虫,介绍第二个爬虫库selenium。
requests库用来向网页发送请求,返回一个包含html文件、content等内容的对象,实现根据网页内容结构特点设计代码爬取网页内容,但是它无法驱动浏览器的行为,比如鼠标单击翻页等,selenium就是用来驱动浏览器行为。
lxml库xpath语法实现爬虫
在上一篇网页爬虫的博客中,我们通过分析 requests 库返回内容的结构特点,设计正则表达式来提取目标数据。这种方法需要精准观察目标内容的上下文特征来编写匹配规则,但正则表达式对 HTML 结构的容错性差,一旦网页标签嵌套、属性格式稍有变化,正则就可能失效。
而 HTML 本身是遵循固定语法的结构化文档,标签嵌套、属性定义都有明确规范 ------ 针对这种 "整齐" 的网页结构,有没有更规范、更易维护的爬取方法?答案是肯定的,lxml 库 就是处理这类场景的绝佳选择。
lxml库
lxml 是基于 C 语言库 libxml2 封装的高性能 XML/HTML 解析库。具有如下优势:
- 结构化解析:直接识别 HTML 标签的层级、属性、文本等语义,无需关注 "字符层面" 的匹配;
- 支持 XPath/CSS 选择器:两种简洁的语法定位目标元素,比正则更贴合 HTML 结构;
- 容错性强:能自动修复不规范的 HTML 代码(如未闭合的标签),适配实际场景中 "不完美" 的网页;
- 性能优异:底层基于 C 实现,解析速度远快于纯 Python 实现的解析方式。
xpath语法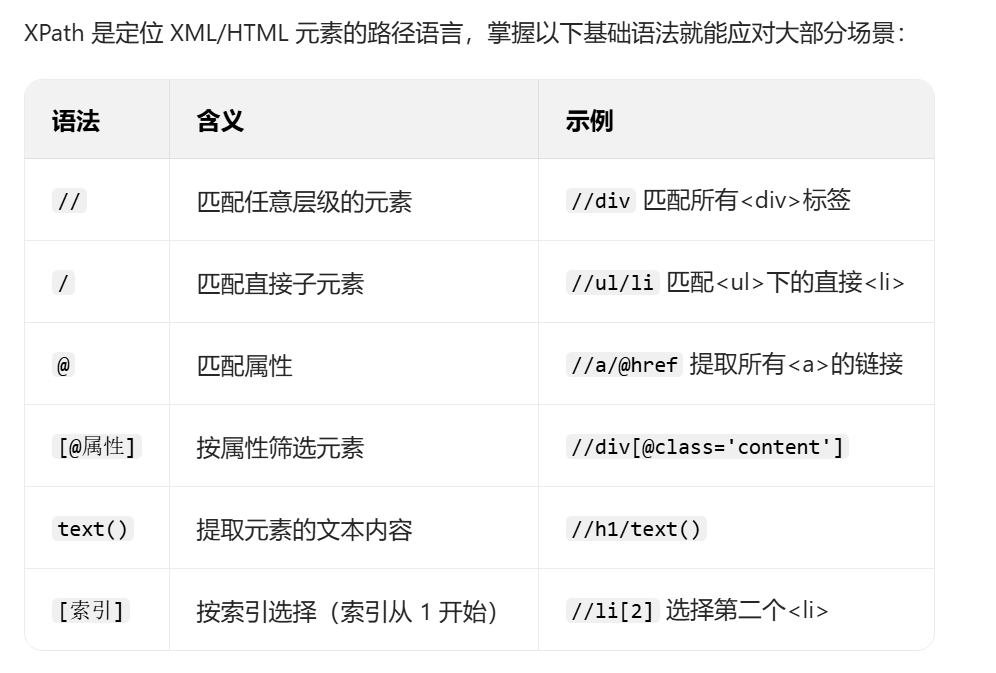
注意事项
案例
目标:爬取虎扑热榜信息,网站https://m.hupu.com/hot
网页: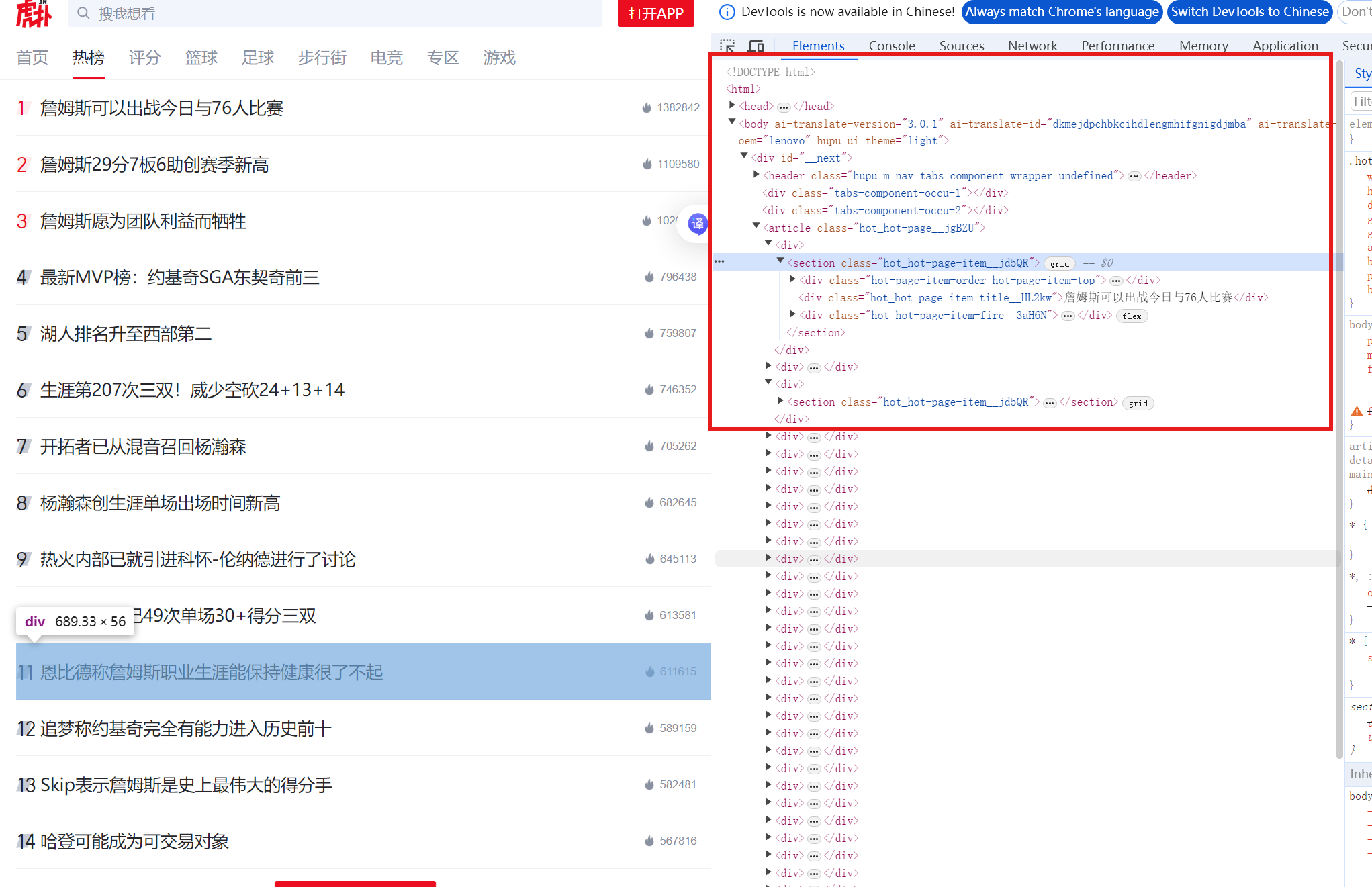
思路:通过//div@class="hot_hot-page-item-title__HL2kw"找到所有热榜信息所在的div容器,xpath()方法返回成列表结构,循环结构输出。
代码:
python
'''爬取虎扑热榜(xpath)更简洁'''
import requests
from lxml import etree
r=requests.get("https://m.hupu.com/hot")
# HTML 提供解析在线html文件的方法
tree=etree.HTML(r.text)
topics=tree.xpath('//div[@class="hot_hot-page-item-title__HL2kw"]/text()')
#etree.xpath()方法会返回列表形式
for i,j in enumerate(topics):
print('热点第',i+1,'话题:',j)enumerate() 是 Python 处理列表(或可迭代对象)的常用技巧,核心作用是同时获取列表元素的「索引」和「对应的值」 。
执行结果: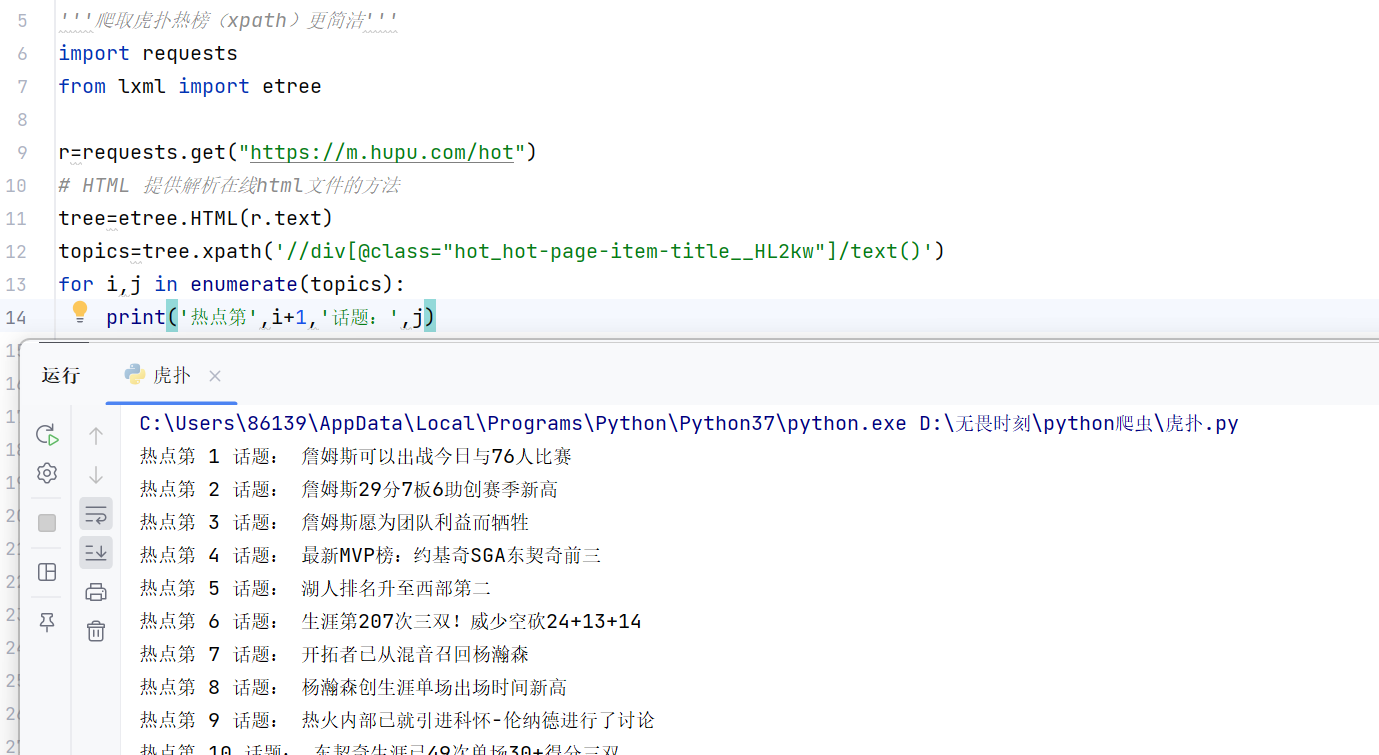
ua伪装
上一篇博客我们通过手动的方法找到网页的User-Agent进行ua伪装,今天通过相关fake_useragent
实现。
案例
目标:爬取网页图片24张。
网页:https://10wallpaper.com/List_wallpapers/page/1
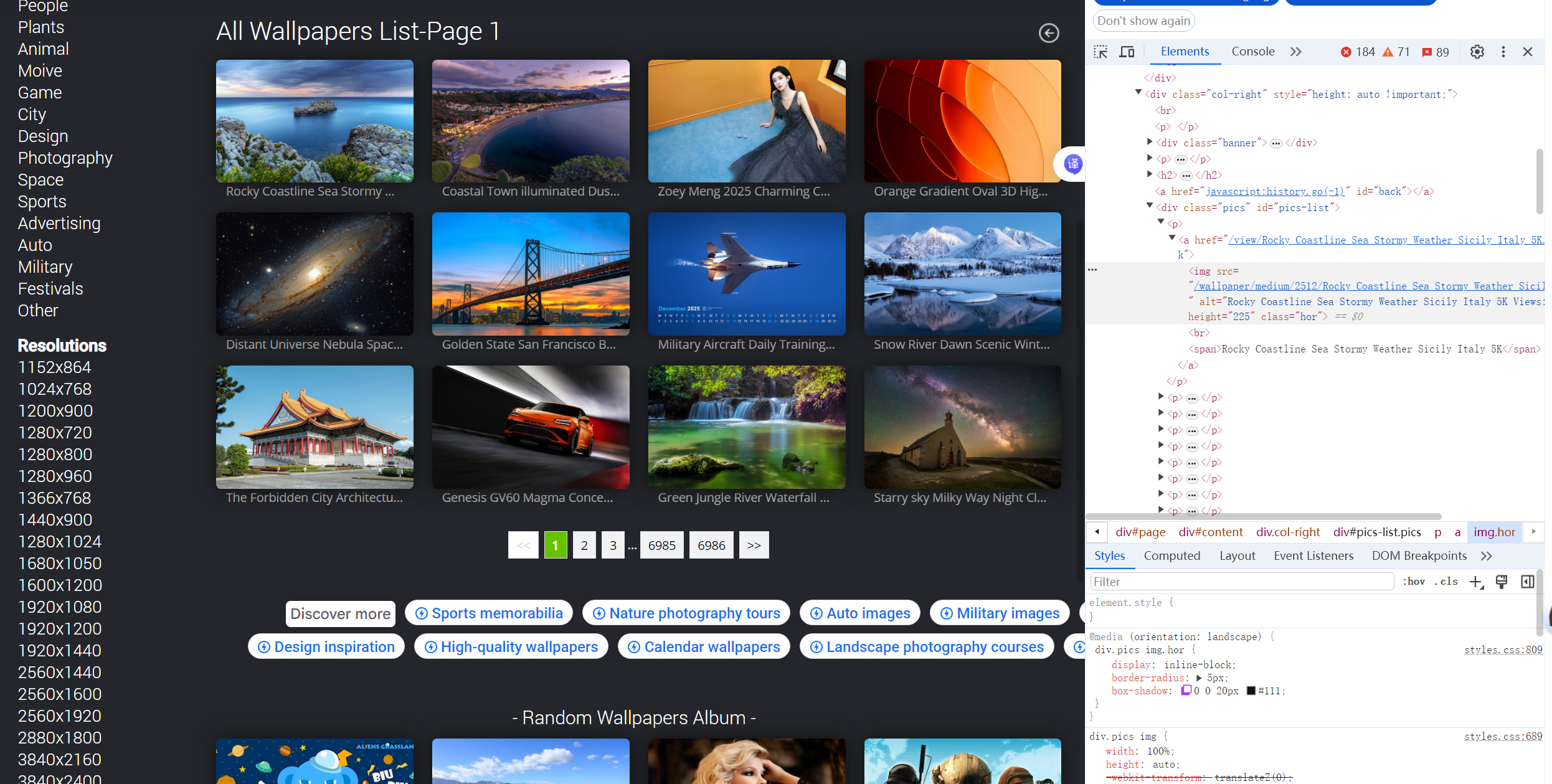
思路:xpath()方法返回图片的url(网址),循环结构存储图片。导入第三方库fake_useragent实现ua伪装。
代码:
python
import fake_useragent
import requests
from lxml import etree
import os #操作文件夹存储图片
n=0
def count():
global n
n+=1
return n
# 新建一个文件夹用于存储图片
if not os.path.exists("./Picture"):
os.mkdir("./Picture")
head = {
"User-Agent": fake_useragent.UserAgent().random
} #定义头文件用于后面ua伪装
for i in range(1, 3): #爬取三十张图片分布在三张网页,循环结构来实现翻页
url = f"https://10wallpaper.com/List_wallpapers/page/{i}"
# 发送请求
resp = requests.get(url, headers=head) #请求的头文件进行ua伪装
# 响应回去的返回数据
result = resp.text
tree = etree.HTML(result) #etree库解析网页
p_list = tree.xpath("//div[@id='pics-list']/p")
for p in p_list:
img_url = p.xpath("./a/img/@src")[0]
img_url2='https://10wallpaper.com'+img_url
print(img_url2)
img_name = count()
print(img_name)
img_resp = requests.get(img_url2, headers=head)
img_content = img_resp.content #获取图片,网页的图片存在requests.get返回对象的content
with open(f"./Picture/{img_name}.jpg", "wb") as fp:
fp.write(img_resp.content)执行:
案例2:爬取豆瓣电影信息,自行尝试
代码:
python
'''爬取豆瓣电影信息'''
# pip install fake_useragent -i https://pypi.tuna.tsinghua.edu.cn/simple
# pip install lxml -i https://pypi.tuna.tsinghua.edu.cn/simple
import fake_useragent
import requests
from lxml import etree
import re
url = 'https://movie.douban.com/top250'
header={'User-Agent':fake_useragent.UserAgent().random}
resp = requests.get(url, headers=header)
# 新增:设置响应编码,避免中文乱码
resp.encoding = 'utf-8'
# 获取请求返回的数据
# print(resp.text)
result = resp.text
fp = open("doubanFilm.txt","w",encoding="utf8")
# 数据解析
# 错误1:注释掉了tree定义,导致tree变量未定义 → 取消注释
tree = etree.HTML(result)
li_list = tree.xpath("//ol[@class='grid_view']/li")
for li in li_list:
try:
film_name = li.xpath("./div/div[2]/div[1]/a/span[1]/text()")[0]
film_actor = li.xpath("./div/div[2]/div[2]/p[1]/text()")
# 错误2:pattern关键字参数后跟位置参数,违反语法规则 → 移除pattern=
# 错误3:正则匹配容错性差,优化正则表达式
actor_text = "".join([line.strip() for line in film_actor if line.strip()])
dir_match = re.match(r"导演: (.+?) .+?主演: (.+)", actor_text)
film_daoyan = dir_match.group(1) if dir_match else "未知导演"
film_zhuyan = dir_match.group(2) if dir_match else "未知主演"
# 错误4:用re.search替代re.match(match只匹配开头,search全局匹配),避免年份提取失败
year_match = re.search(r"(\d{4})", actor_text)
film_year = year_match.group(1) if year_match else "未知年份"
# 错误5:提取引言时未做容错,无引言会报错 → 先判断列表是否为空
film_quote_list = li.xpath("./div/div[2]/div[2]/p[2]/span/text()")
film_quote = film_quote_list[0] if film_quote_list else "无引言"
film_star = li.xpath("./div/div[2]/div[2]/div/span[2]/text()")[0]
print(film_name, film_quote, film_star, film_daoyan, film_zhuyan, film_year)
fp.write(film_name+'#'+film_quote+'#'+film_star+'#'+film_daoyan+'#'+film_zhuyan+'#'+film_year+'\n')
except Exception as e:
print(f"处理{film_name if 'film_name' in locals() else '未知电影'}时出错:{e}")
pass
fp.close()执行结果: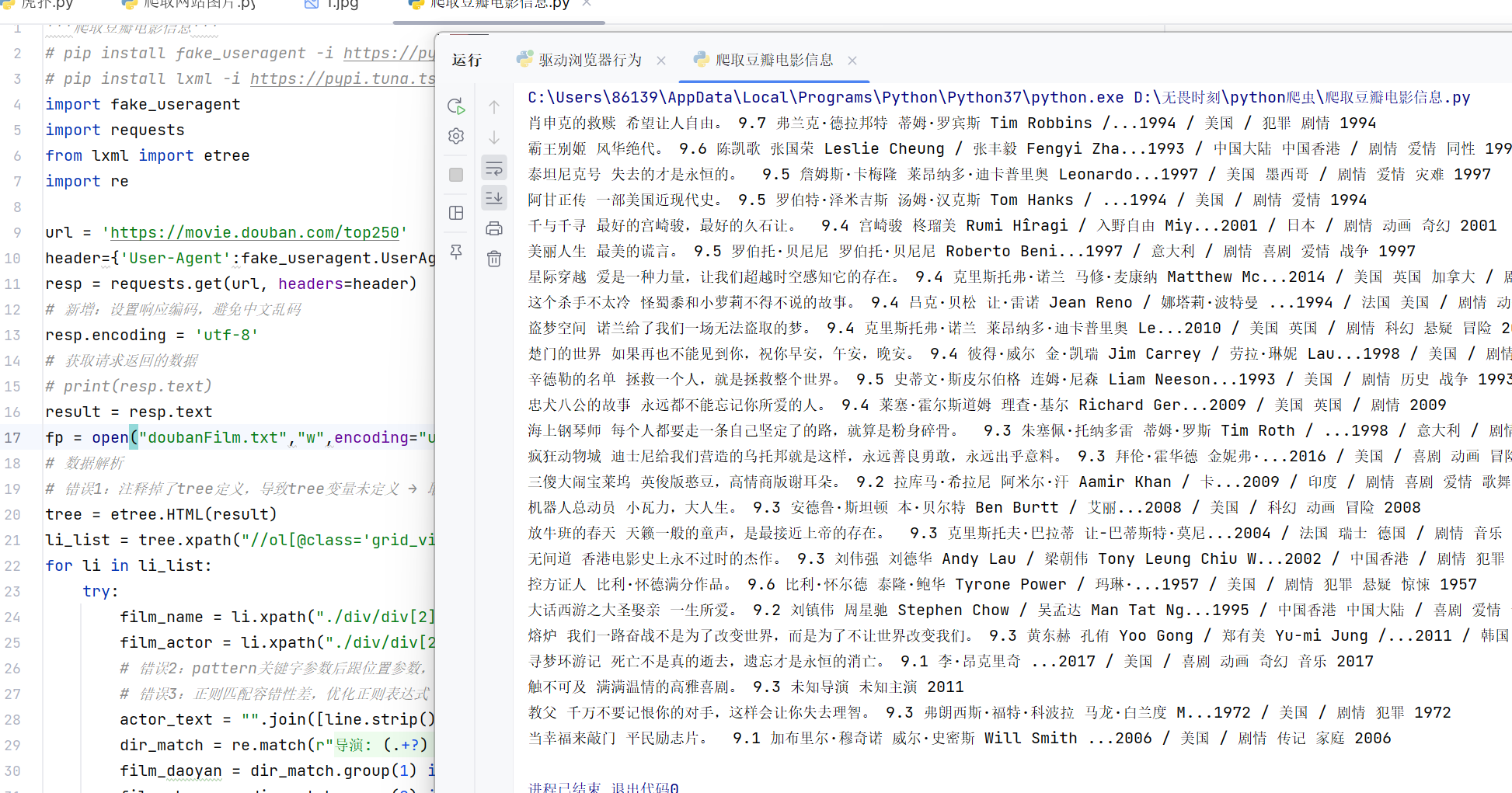
selenium库
selenium库介绍
1、 selenium是什么?
用于Web应用程序测试的工具。可以驱动浏览器执行特定操作,自动按照脚本
代码做出点击,输入,打开,验证等操作,就像真实用户所做的一样。
支持的浏览器包括IE,Firefox,Safari,edge,Chrome等。
2、 与requests库的区别?
selenium库是基于浏览器的驱动程序来驱动浏览器执行操作的,且浏览器可以实现网页源代码的渲染,
因此通过selenium库还可以轻松获取网页中渲染后的数据信息
3、selenium的工作原理
浏览器具有webdriver驱动,这个驱动是根据不同的浏览器开发的,
不同的浏览器使用不同的webdriver驱动程序且需要对应相应的浏览器版本,
webdriver驱动程序可以通过浏览器内核控制浏览执行指定命令
4、如何使用selenium?
使用前准备: a、安装selenium库 b、驱动浏览器的内核驱动
a、安装selenium,使用pip install selenium==4.11.0 -i https://pypi.mirrors.ustc.edu.cn/simple/
或在pycharm中安装
b、edge内核驱动地址 360浏览器使用的就是edge的内核,QQ浏览器使用IE,IE,
首先确定你的浏览器是使用哪个内核??
windows系统:下载下来的文件解压后放置在python安装地址的Scripts中
Linux和Mac系统:同上,注意:系统存在2个Python版本,确定当前运行的python
版本配置在环境变量中
edge驱动下载地址:https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/?ch=1\&form=MA13LH
chrome驱动下载地址:https://chromedriver.storage.googleapis.com/index.html
firefox驱动下载地址:https://github.com/mozilla/geckodriver/releases
案例
打开一个网页:
python
'''打开一个网页'''
from selenium import webdriver #从selenium导入 webdriver(浏览器驱动)
from selenium.webdriver.edge.options import Options #导入Edge浏览器的options类,这个类允许我们配置WebDriver的行为。
edge_options = Options() ##创建一个0ptions类的实例,这将用于设置Edge浏览器的启动选项。
edge_options.binary_location = r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"
driver =webdriver.Edge(options=edge_options)
driver.get('https://10wallpaper.com/List_wallpapers/page/1')
input('dengdai')执行结果: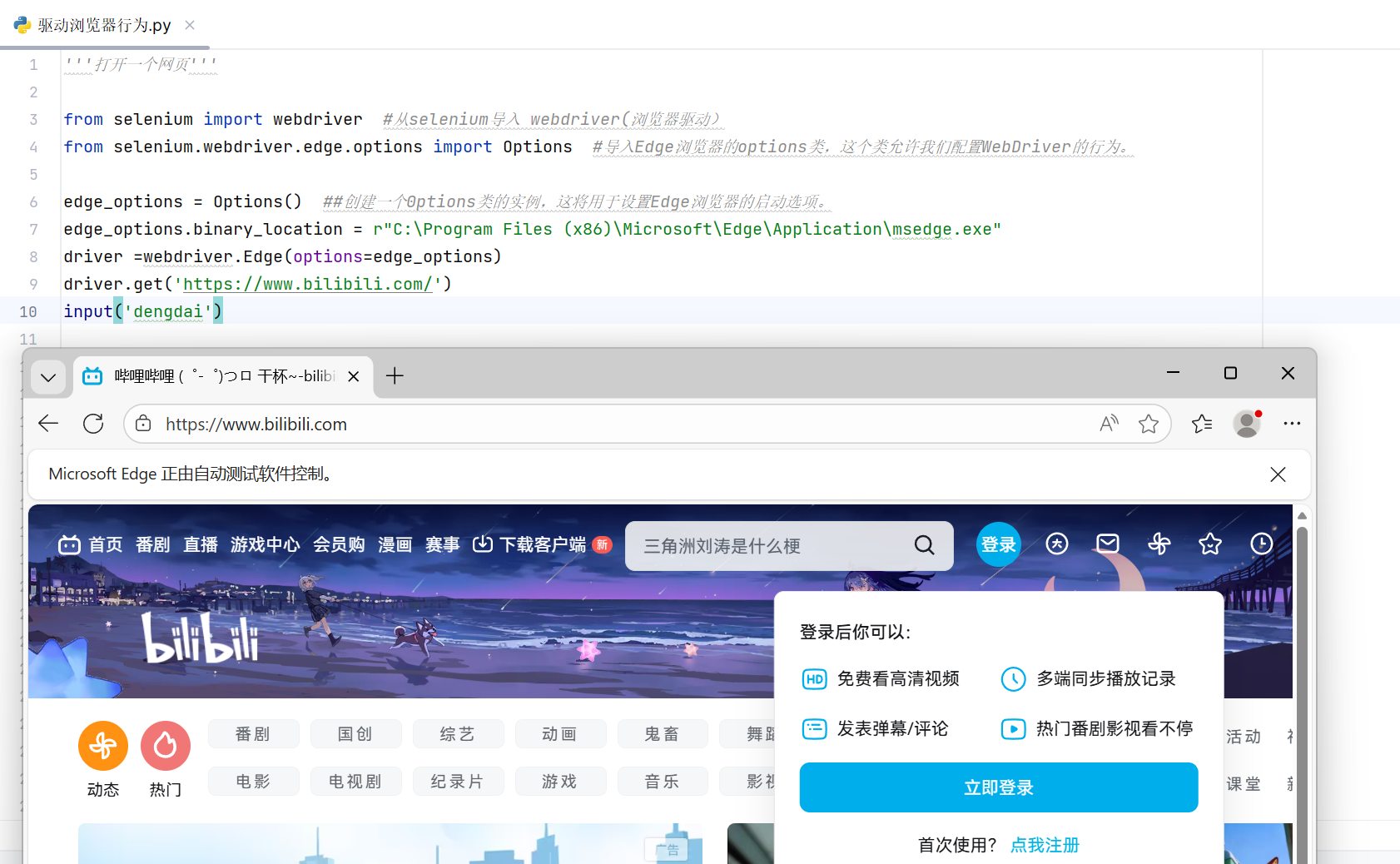
作业
大家可以基于前面的案例尝试完成作业代码
目标:使用selenium库实现网页翻页来爬取不同页面的图片
网页:www.gamewallpapers.com/index.php?start=0&page=
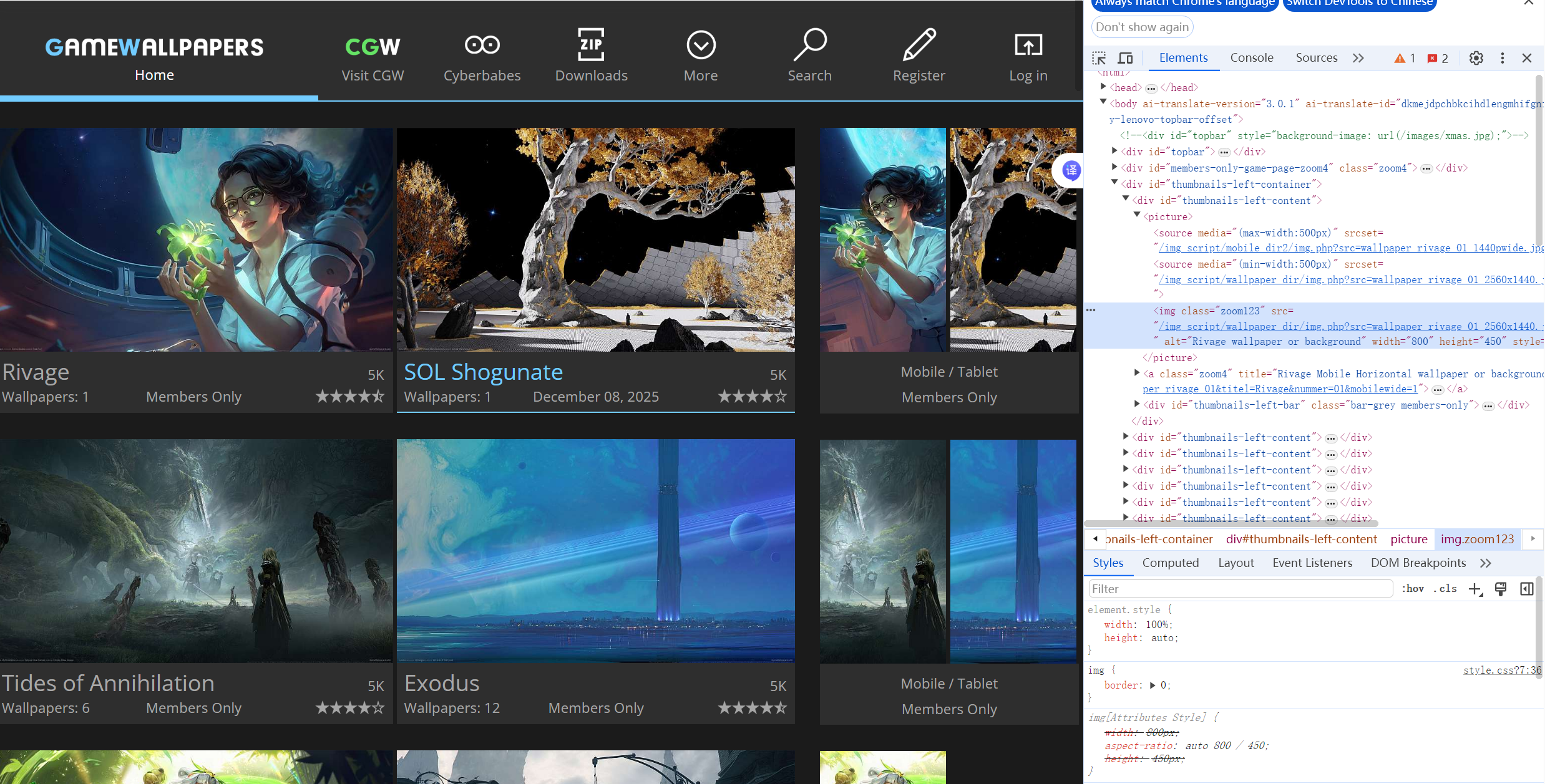
思路:xpath()方法输入图片所在位置//img[@class="zoom123" and @width="800",返回图片网址的列表,循环结构存入文件。
模拟浏览器单击实现翻页:
page2_btn = driver.find_element(By.XPATH, '//a//div[@id="page-number" and @class="zoom3" and text()="{j}"')
page2_btn.click()
代码:
python
from lxml import etree #导入lxml库用于解析网页,使用xpath
import os #导入os库用于操作文件夹,存入图片
import requests #导入requests库,使用content返回图片
from selenium.webdriver.common.by import By #导入by,在模拟单机行为时,选择路径语法
import time #导入时间库
from selenium.webdriver.edge.options import Options #导入options类,用来配置浏览器启动行为
from selenium import webdriver #导入webdriver模块,用来启动浏览器实现点击等操作
# 创建Edge浏览器配置对象
edge_options = Options()
# 指定Edge浏览器程序的安装路径
edge_options.binary_location = r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"
# 初始化Edge驱动并应用配置
driver = webdriver.Edge(options=edge_options)
# 访问游戏壁纸网站的分页页面
driver.get('https://www.gamewallpapers.com/index.php?start=0&page=')
# 新建一个文件夹用于存储图片
if not os.path.exists("./Picture2"):
os.mkdir("./Picture2")
n=0
for j in range(2,4):
#获取网页html,xpath找到图片地址返回一个列表
result = driver.page_source
tree = etree.HTML(result)
img_src_list = tree.xpath('//img[@class="zoom123" and @width="800"]/@src') #这里使用两个@匹配图片结构img,因为我第一次只用了一个,结果还有另一类型图片也是class=zoom123,导致多下载了好多图片
#循环结构存储图片
for i in img_src_list:
head = "https://www.gamewallpapers.com/"
url = head + i
n += 1
print(n)
print(url) #打印下载的图片
a = requests.get(url)
b = a.content
with open(f"./Picture3/{n}.jpg", "wb") as fp:
fp.write(b) #将图片导入文件夹
page2_btn = driver.find_element(By.XPATH, '//a//div[@id="page-number" and @class="zoom3" and text()="{j}"')
page2_btn.click() #模拟浏览器单击实现翻页执行结果: