前言
打开某网页开发者工具后,网页自动关闭,根本不给你查看接口的机会
网址:aHR0cHM6Ly93d3cueGZiMzE1LmNvbS8=
原理
流程:
1、检测:网页通过JavaScript代码持续监控,判断你是否打开了开发者工具。你找到的 123这类数字,很可能就是检测逻辑的一部分,例如,作为时间差判断的阈值或性能比较的基准。
2、触发:一旦检测逻辑确认为"打开"状态,就会触发预设的"反击"函数。
3、执行:这个"反击"函数的核心命令就是 window.close(),试图关闭当前标签页。为了增强效果,网页还可能同时执行 window.location = "about:blank"来跳转到空白页,或尝试其他干扰操作
解决方法
禁用JavaScript:在开发者工具无法稳定打开的情况下,可以在 Chrome 设置中(设置 > 隐私和安全 > 网站设置 > JavaScript)直接为该网站禁用JavaScript,刷新页面后再尝试打开开发者工具。
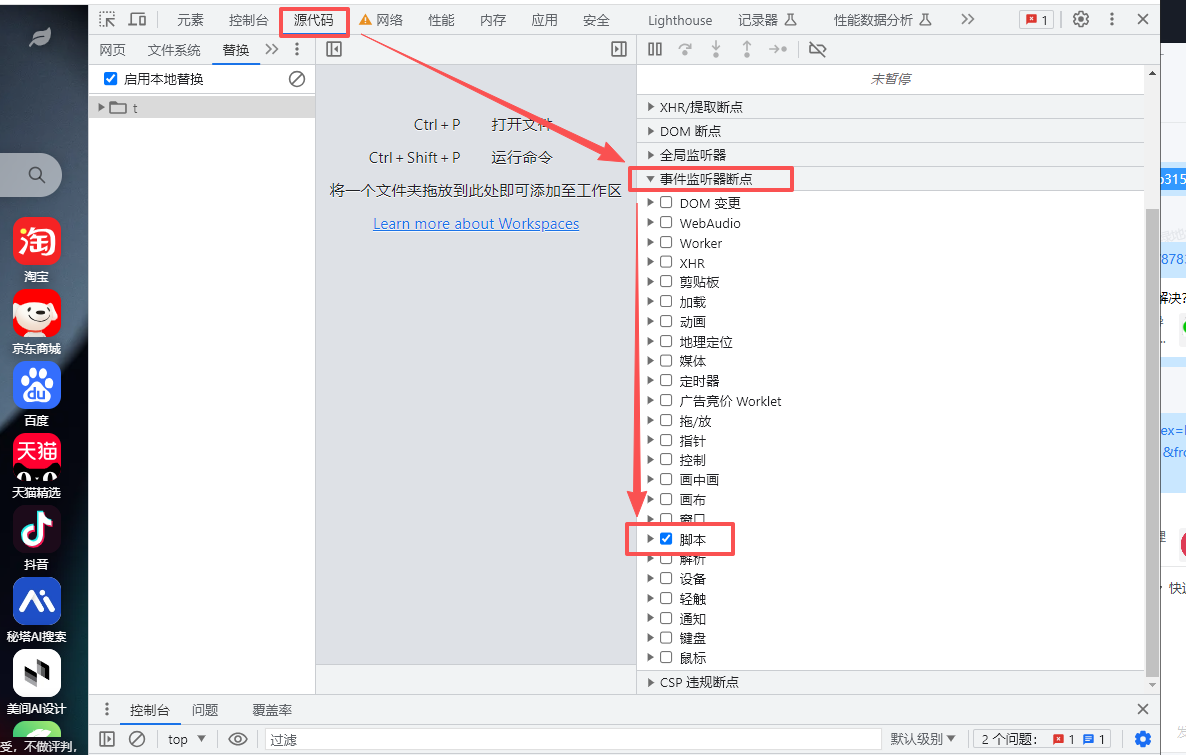
1、在任意网页打开开发者工具,找到【源代码】===>>【事件监听断点】=>> 勾选【脚本】,如图:
2、
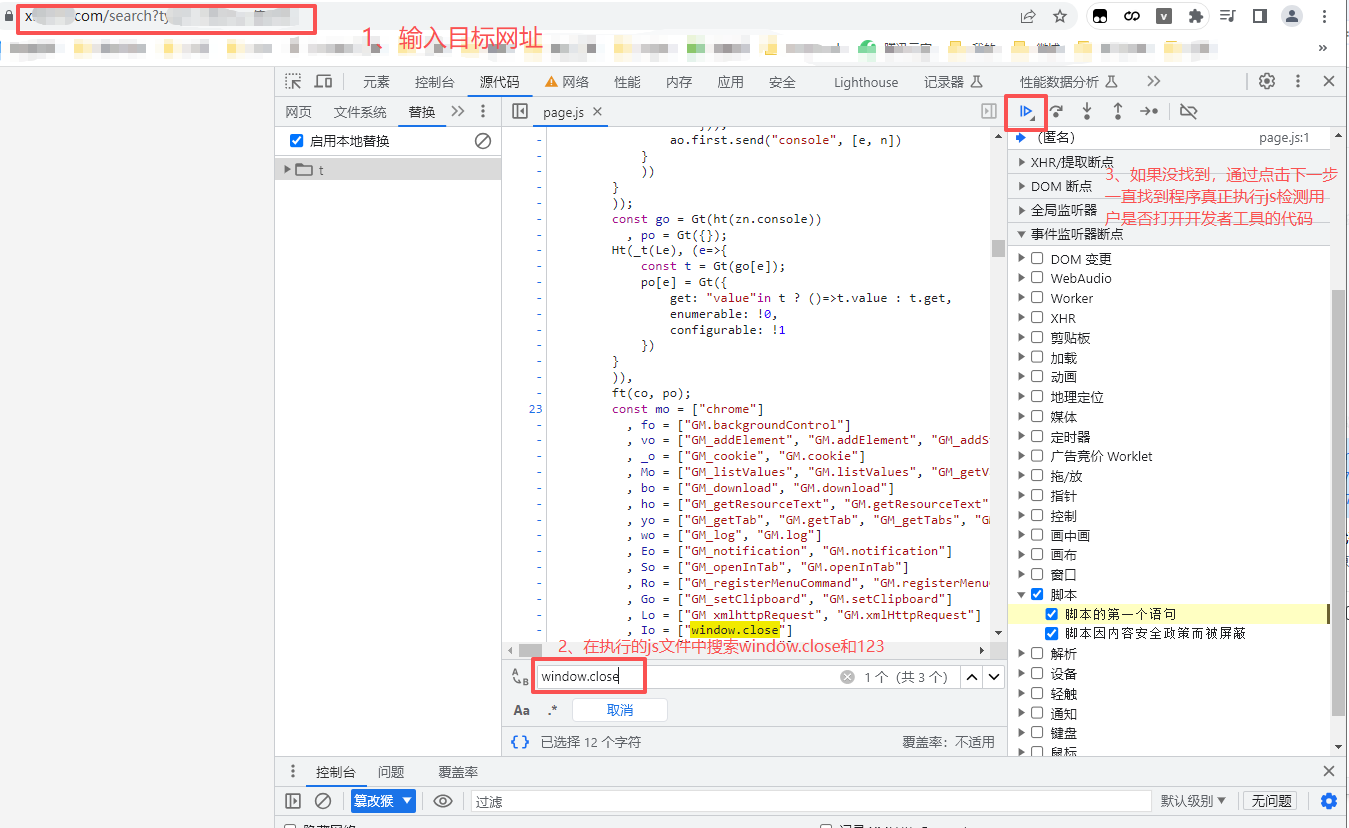
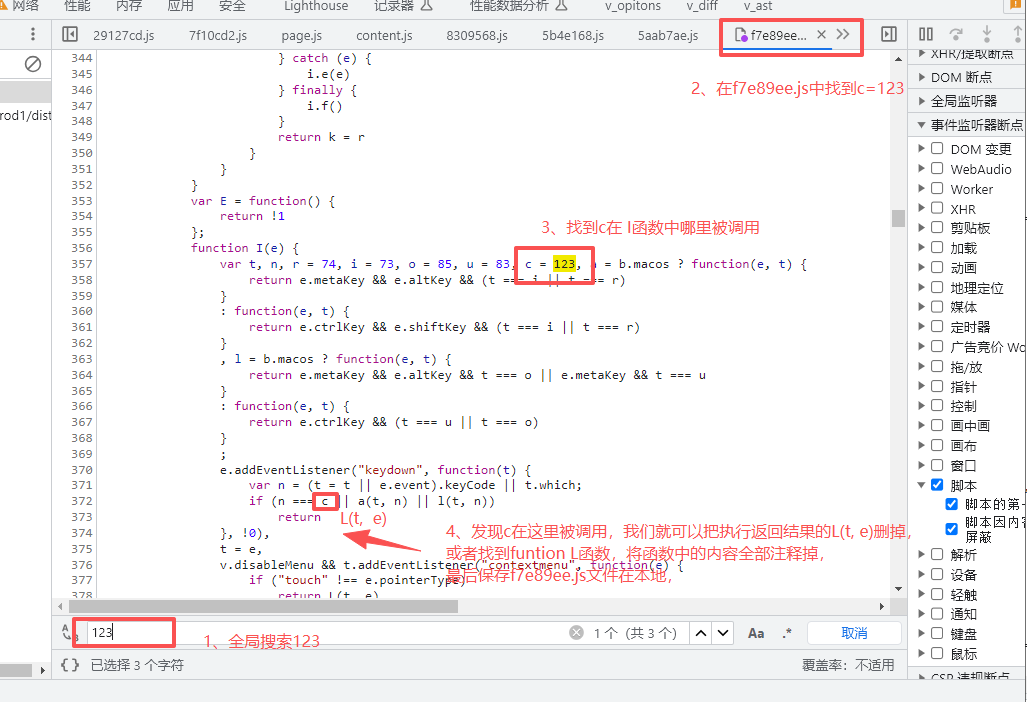
1.将目标网址放入网址框回车执行
2.通过全局搜索 window.close和123 (例如a=123,c=123)
3.这个时候开发者工具就开始对JavaScript进行断点执行, 耐心点,可能要点击十几二十个js文件才执行到真正检测代码的文件
操作如图:
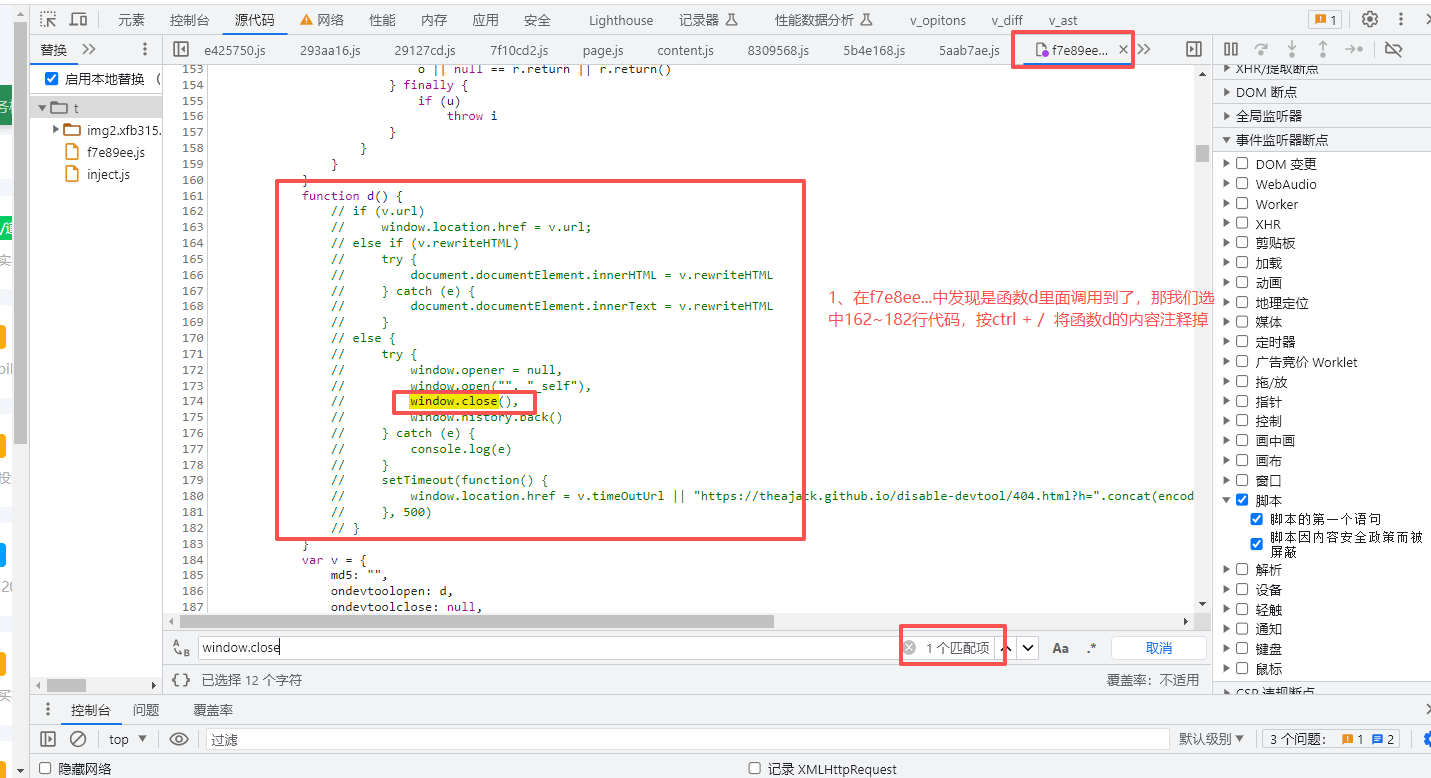
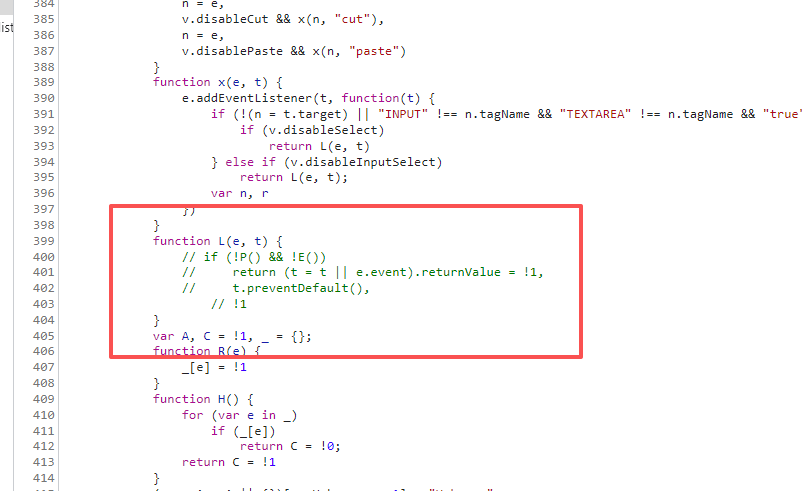
3、找到js目标文件,选中执行的函数,ctrl+/ 注释掉执行内容,如图
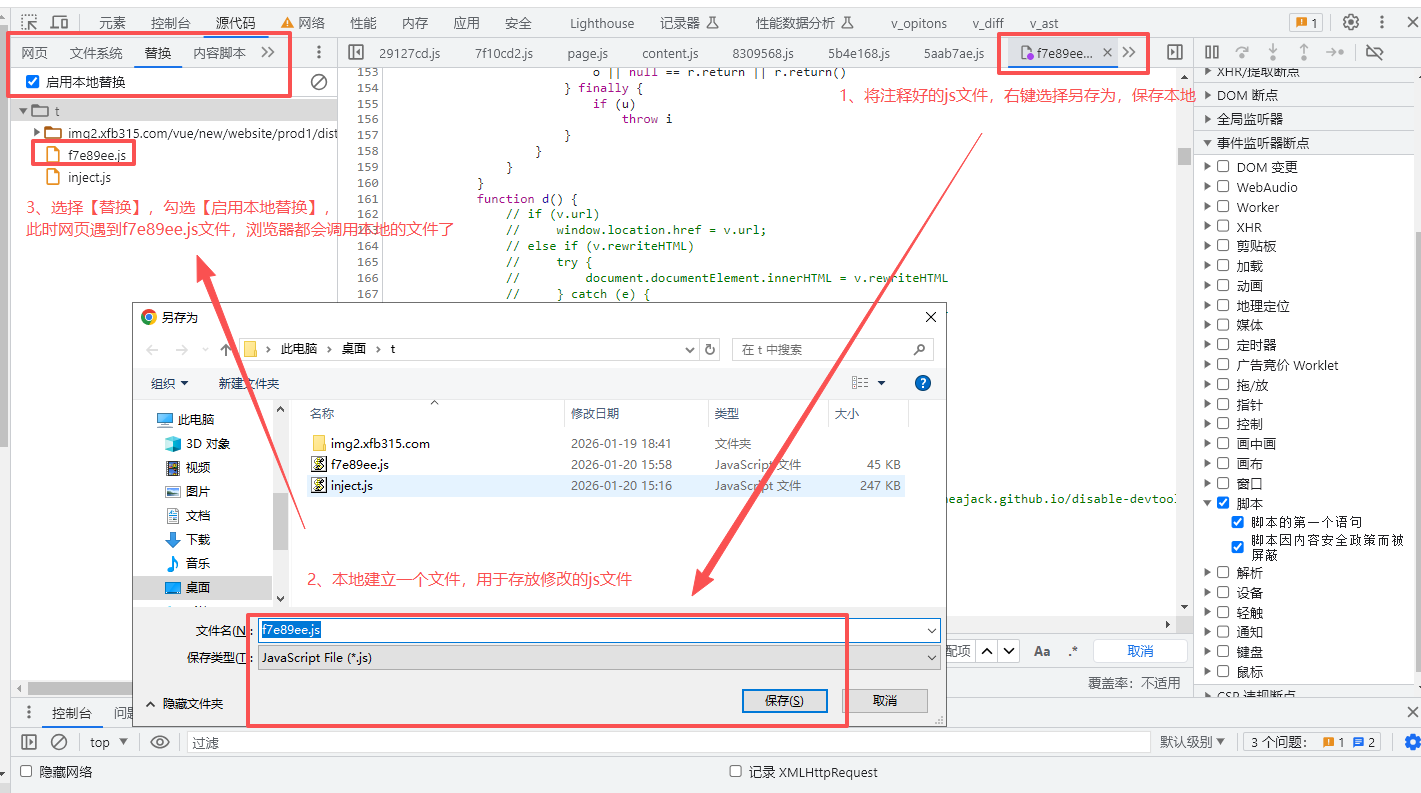
4、js文件另存为本地,使用替换-【启用本地替换】
让浏览器调用被修改的js本地文件,如图:
5、全局搜索123(例如a=123,c=123)
原因 :123代表的是键盘F12的键码,而F12是浏览器打开开发者工具的快捷键
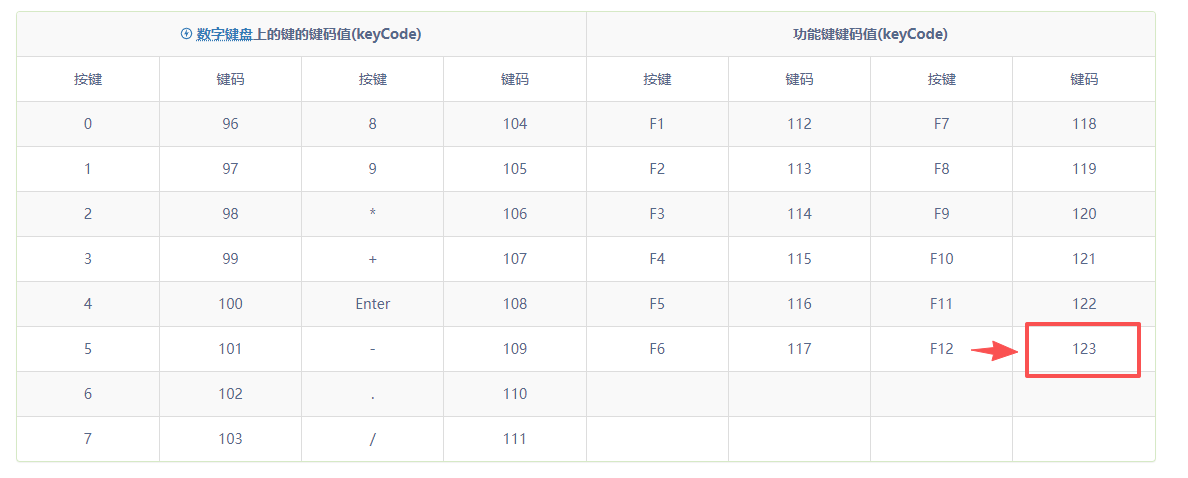
查找方法同上,如图:
6、保存文件,启用【本地文件替换】,找到【源代码】===>>【事件监听断点】=>> 关闭【脚本】,刷新网页就可以正常访问啦!!