原文:Goroutine + Channel 高效在哪?一文吃透 Go 并发底层 G-M-P 调度与实现
为什么Go的并发如此高效?
在现代软件开发中,"并发"(Concurrency)已成为衡量一门编程语言或技术框架性能的关键指标。Go 语言,以其在服务端和云计算领域的出色表现,迅速赢得了"高并发、低开销"的盛誉。
但 Go 究竟是如何做到这一点的?
它的秘诀并非来自传统操作系统线程的简单堆叠,而是源于一种更优雅、更安全的并发哲学。
Go 语言在设计之初,就推崇一条核心的并发准则:
"Do not communicate by sharing memory; instead, share memory by communicating"
通过通信来共享内存,而非通过共享内存来通信
这条准则正是对计算机科学中通信顺序进程(Communicating Sequential Processes,CSP) 范式的实践。
传统的并发模型往往依赖于 互斥锁(Mutex) 来保护共享内存,这带来了复杂的锁竞争、死锁风险和性能瓶颈。而 CSP 则将并发实体(进程或线程)视为独立的个体,它们之间通过显式的通信来同步数据和状态。
Go 语言通过原生支持两个核心构建,将这一哲学落地:
- Goroutine:轻量级的、由Go运行时管理的执行单元。
- Channel:类型安全的、用于在 Goroutine 之间传递数据的通信管道。
本文将深入 Go 语言的内部,从其并发哲学的基石 CSP 范式出发,层层拆解 Goroutine 背后的 G-M-P 调度机制 ,以及 Channel 的 hchan 结构与工作原理,最终为您呈现 Go 并发高效、安全的实现全貌。
一、CSP范式
在深入 Go 语言的并发实现之前,我们必须理解它选择抛弃的传统模型,以及它所拥抱的 CSP 范式为何能带来更清晰、更安全的并发编程体验。
1.1 传统并发模型:共享内存与"锁"的困境
在 Java、C++ 等主流编程语言的传统多线程模型中,并发的实现核心是:共享内存。
多个线程访问和修改同一个共享的数据结构(如全局变量、对象属性)。为了保证数据在并发环境下的正确性,避免数据竞态(Data Race) ,开发者必须依赖于各种同步原语,最常见的就是互斥锁(Mutex)。
这种"通过共享内存来通信"的方式,虽然能够完成任务,但存在固有的缺陷:
- 复杂性高:开发者需要时刻警惕哪些数据是共享的、何时需要加锁、何时需要解锁。
- 死锁风险:当两个或多个线程互相持有对方所需的锁时,程序将陷入僵局。
- 性能瓶颈 :高频度的锁竞争会将并行操作串行化,严重限制程序的扩展性和吞吐量。
- 调试困难:并发 Bug 往往难以复现,且与锁相关的 Bug 涉及时间敏感性,是公认的噩梦。
1.2 CSP:通信即同步
与传统模型形成鲜明对比的是 通信顺序进程(Communicating Sequential Processes,CSP) 范式。
CSP 并非一种编程语言,而是一种由计算机科学家 Tony Hoare 在 1978 年提出的用于描述并发系统的数学理论。
CSP 的核心理念可以概括为:
- 顺序进程(Sequential Processes) :并发系统由许多独立的、按顺序执行的实体组成(在 Go 中即是 Goroutine)。
- 通信(Communicating) :这些实体之间不共享内存,而是通过消息传递(在 Go 中即是 Channel)进行协作和同步。
在 CSP 范式下,通信本身就是同步的方式。当一个 Goroutine 通过 Channel 发送数据时,它不必关心数据如何被存储,只需关心接收方是否准备就绪。数据的所有权从发送方转移到接收方。
这种机制抽象了复杂的底层同步细节,让并发编程回归到对业务逻辑流的清晰描述。
Hoare 曾强调,这种并发风格的优势,更重要的原因在于清晰性,而非仅仅是效率。
1.3 Go的选择:原生支持与高效实现
Go 语言将 CSP 范式作为其核心的并发模型,是其设计哲学的一次大胆而成功的选择。
通过原生提供 Goroutine 和 Channel,Go 成功地将 CSP 理论从学术殿堂带入了工业级应用:
- Goroutine 作为轻量级的顺序进程,解决了传统 OS 线程开销大的问题。
- Channel 作为消息传递的媒介,提供了一种类型安全、内置 FIFO 队列结构的通信机制,让开发者得以实践"通过通信来共享内存"的理念。
二、Go并发模型的M:N架构
Go 的并发能力建立在一个高效的运行时调度器之上,采用 M:N 调度模型。这意味着数量众多的应用程序级并发单元(N,即Goroutines)被多路复用到数量有限的操作系统线程(M,即Machine/M)上执行 。
这种解耦是 Go 实现高可扩展性的关键,因为它避免了操作系统线程(内核级线程)的巨大资源开销和上下文切换成本 。Go 的调度器在用户空间管理这些 Goroutines,保证了并发任务能够高效地利用多核CPU资源 。
M:N 调度与传统模型的差异及优势
| 特性 | Go M:N 模型(Goroutine) | 传统 1:1 模型(OS 线程/进程) | 优势 |
|---|---|---|---|
| 并发单元 | Goroutine (G) | 操作系统线程 (OS Thread) | Goroutine数量主要受内存大小限制。 |
| 启动/栈大小 | 极小(起始2KB)且动态增长 | 较大(Linux通常10MB)且固定 | 极大地节省虚拟内存和物理内存开销 。 |
| 调度管理 | Go 运行时(用户空间) | 操作系统内核(内核空间) | Goroutine切换是用户空间操作,开销极低,避免昂贵的内核上下文切换。 |
| 阻塞处理 | 非侵入式:I/O阻塞时,自动解耦OS线程 (M) 和逻辑处理器 (P),不影响其他并发任务。 | 侵入式:I/O阻塞会暂停整个线程,影响该线程上的所有任务(除非使用异步I/O。 | 开发者可编写同步代码风格,由运行时自动实现高效的并发I/O处理。 |
2.1 Goroutine的生命周期与栈管理
Goroutine的效率源于其极低的资源开销。
2.1.1 分段栈与初始分配
每个Goroutine启动时仅分配一个极小的栈空间,通常只有2KB左右 。这个栈是动态可增长的,根据需要由Go运行时自动扩展和收缩。
这与操作系统线程默认分配的较大固定栈空间形成了鲜明对比(例如,Linux通常为10MB,Windows为1MB) 。
这种低初始栈分配的优势并不仅仅体现在物理内存的节省上,也极大地降低了虚拟内存开销,从而使得在实际应用中启动数十万甚至数百万个并发 Goroutine 成为可能。
因此,Goroutine的低内存占用是实现大规模并发的前提 ,而M:N调度模型和高效上下文切换则是保证性能的关键。
PS: 虽然操作系统线程通常也采用延迟分配物理内存页的方式(初始可能只分配8KB的物理内存) ,但内核线程在虚拟内存中保留了巨大的栈空间(如10MB),这极大地限制了系统能够创建的线程总数 。
2.1.2 上下文切换效率
Goroutine之间的切换是一种快速的用户空间操作,完全由Go 运行时 管理,无需涉及操作系统的内核上下文切换 。
内核线程的上下文切换涉及用户空间到内核空间的昂贵转换。
相比之下,Goroutine 切换只需保存和恢复少数关键寄存器,这些寄存器信息的存储和恢复完全由 Go 运行时负责完成 。
这种极简的切换操作大幅降低了调度延迟,提供了巨大的性能优势。
2.2 Goroutine 的调度机制
2.2.1 M:N调度模型:G、M 和 P组件
Go调度器使用G-M-P模型来高效地将Goroutines(G)调度到OS线程(M)上,通过逻辑处理器(P)进行协调 。
| 组件 | 描述 | 调度中的作用 |
|---|---|---|
| Goroutine (G) | 轻量级应用层线程;包含栈和上下文。 | 实际的执行单元,排队等待运行。 |
| Processor (P) | 逻辑处理器;调度队列机制。 | 持有本地运行队列(LRQ);是执行G所需的资源;促进工作窃取。 |
| Machine (M) | 操作系统(OS)线程。 | 运行附加到P的G;处理阻塞的系统调用。 |
P(Processor)是执行 Go 代码所必需的资源,每个 P 都维护一个本地运行队列(LRQ)来存储可运行的 G。
可以通过GOMAXPROCS环境变量或函数控制着可用P的数量,决定Go程序能够同时并行执行的OS线程的最大数量 。
需要注意的是,P 的数量通常于 M 的数量不一致 ------ P 的数量是固定的(由GOMAXPROCS控制),而M的数量是动态的,Go 运行时会根据 I/O 阻塞情况增加 M 的数量,以保证 P 始终有 M 可用,但会严格控制处于 Spinning(正在执行或等待执行)状态的 M 的数量 ,确保其不超过 GOMAXPROCS。
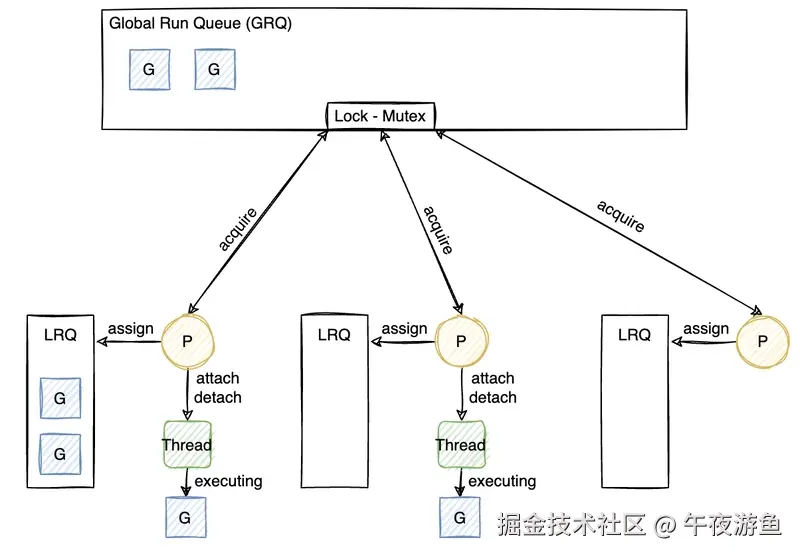 上图清晰地展示了 G-M-P 模型中 P 的核心作用:它维护 LRQ,并从 GRQ 中获取任务(需要
上图清晰地展示了 G-M-P 模型中 P 的核心作用:它维护 LRQ,并从 GRQ 中获取任务(需要 Lock-Mutex 保护),以及 M 如何在 P 上执行 G。
2.2.2 动态负载均衡
如上所述,每个 P 都维护一个本地运行队列(LRQ)。
当一个新的 Goroutine 被创建或被唤醒时,它通常会被推送到当前正在执行它的 P 的 本地运行队列 (LRQ) 的末尾。如果 LRQ 已满,任务可能会被推送到全局运行队列 (GRQ),所有 P 都会周期性地检查 GRQ 以获取任务。
关键在于工作窃取(Work Stealing):当一个 P 完成了其 LRQ 中的所有任务而变为空闲时,会主动尝试从其他随机选中的 P 的 LRQ 中**"窃取"一半**的可运行 Goroutine。
这种去中心化的工作窃取策略确保了CPU资源的高效利用,有效避免了某些核心空闲而其他核心任务饱和的情况 。
2.2.3 抢占机制
Go 调度器在以下两种情况下决定切换执行中的 Goroutine (G) :
- 协作式让步(Voluntary Yield) :G 在执行特定操作时自愿放弃控制权。这些操作包括:通道操作、网络I/O操作、显式调用
runtime.Gosched()、以及启动新的 Goroutine(使用go关键字)。 - 强制(异步)抢占(Forced/Asynchronous Preemption):针对长时间运行的计算密集型或没有 I/O/Channel 操作的紧密循环 。(Go 1.14 引入)
运行时通过异步信号和编译器在循环中插入的抢占检查来工作。当运行时检测到一个Goroutine运行时间过长时,它会设置该Goroutine的抢占标志位(g.preempt),使得该Goroutine能够在安全点被中断 。
2.2.4 阻塞系统调用(Syscall)处理
Go 运行时对阻塞性系统调用(如文件 I/O)的处理机制,是保证高并发性能的另一关键。它确保了 "I/O 阻塞不影响并发任务的执行"。
当一个 Goroutine 执行一个阻塞性的系统调用时(Go 运行时判断耗时超过 20 微秒即为阻塞):
- 执行该 G 的 M 会自动与当前的 P 分离(解耦)。
- Go 运行时会从线程缓存中获取一个空闲的 M ,或者创建一个新的 M 来接管该 P,继续执行 P 本地队列中的其他 Goroutines。
当 M 完成阻塞的系统调用返回后,它会尝试重新获取一个 P 。如果找不到 P,该 M 不会被立即销毁,而是进入一个线程缓存,以避免频繁创建和销毁 OS 线程带来的系统资源开销 。
这种机制有效地平衡了 I/O 密集型任务对线程数量的需求与 CPU 密集型任务对有限线程切换开销的追求,确保了即使开发者编写了标准的阻塞式I/O代码,底层的P也不会被长时间占用而导致其他Goroutines 饥饿
因此,Go 开发者可以像编写同步代码一样编写并发代码,而由运行时在底层负责管理线程池和I/O阻塞问题,避免了手动使用复杂异步I/O框架的需要 。
三、Channel 的设计与实现
Channel是Go语言实现CSP哲学,进行Goroutine间同步和通信的主要手段,是类型安全、内置的FIFO队列结构,是 Go 并发模型安全性的核心保障。
3.1 channel 类型
根据 channel 的容量,可分为无缓冲 channel 和有缓冲 channel
3.1.1 无缓冲 channel
无缓冲 channel 可通过make(chan int)创建,容量为零。
无缓冲 channel 实现了 Goroutine 之间的强同步(Rendezvous),要求发送方和接收方必须同时准备就绪才能完成数据传输。
常用于需要严格控制操作顺序或等待事件发生的场景。
3.1.2 有缓冲 channel
可通过make(chan int, N)创建指定缓存大小 N 的缓冲 channel,在缓冲区满之前,发送方可以发送数据而不阻塞,实现了 Goroutine 之间的一步通讯。
发送方只有在缓冲区满时才会阻塞,接收方只有在缓冲区空时才会阻塞,常用于实现生产者-消费者模型或进行任务缓冲。
3.2 内部结构:hchan
Go的 Channel在运行时内部由hchan结构体表示 。所有对 Channel 的操作,无论是发送、接收还是关闭,都通过hchan中包含的单个互斥锁(hchan.lock)来保护,从而确保并发安全 。
该结构体定义位于 Go 运行时源代码的 src/runtime/chan.go 文件中 。
go
type hchan struct {
qcount uint // total data in the queue
dataqsiz uint // size of the circular queue
buf unsafe.Pointer // points to an array of dataqsiz elements
elemsize uint16
synctest bool // true if created in a synctest bubble
closed uint32
timer *timer // timer feeding this chan
elemtype *_type // element type
sendx uint // send index
recvx uint // receive index
recvq waitq // list of recv waiters
sendq waitq // list of send waiters
// lock protects all fields in hchan, as well as several
// fields in sudogs blocked on this channel.
//
// Do not change another G's status while holding this lock
// (in particular, do not ready a G), as this can deadlock
// with stack shrinking.
lock mutex
}重要属性说明:
| 类别 | 属性 | 功能与实现 |
|---|---|---|
| 同步 | lock |
runtime.mutex,用于确保Channel操作期间的并发安全。 |
| 缓冲控制 | dataqsiz |
用户定义的Channel缓冲区容量。 |
| 缓冲内容 | buf, qcount |
指向环形缓冲区的指针,以及当前缓冲区中元素的数量。 |
| 缓冲索引 | sendx, recvx |
跟踪环形缓冲区中可写(发送)和可读(接收)位置的索引。 |
| 等待队列 | sendq, recvq |
sudog对象(包含被阻塞的Goroutine)组成的双向链表。 |
3.2.1 环形缓冲区
缓冲Channel使用环形缓冲区(Ring Buffer)作为数据缓存 。
数据的写入位置由sendx索引控制,读取位置由recvx索引控制。当任一索引到达缓冲区末尾时,它会回绕到 0,实现了高效的FIFO队列管理 。

Linux 新增的异步 I/O 模型 io_uring 也采用了类似的环形缓冲区结构,以追求极致的 I/O 性能,该结构在高并发场景下具有很多优势:
- O(1) 性能:入队(enqueue)和出队(dequeue)操作的平均时间复杂度为 O(1),性能稳定。
- 高效内存利用:内存是预先分配好的,无需在运行时进行昂贵的重新分配或调整大小。
- 高并发/无锁潜力 :它天然适用于生产者-消费者模型。虽然 Go 官方的
hchan实现依赖互斥锁来保证状态一致性,但在其他并发队列设计中,环形缓冲区可通过原子操作实现无锁或接近无锁的并发访问。
3.2.2 sudog对象与等待队列
当一个Goroutine由于Channel操作而必须阻塞时,它和相关的操作数据(如要发送的数据地址)会被封装成一个sudog对象 。
这些sudog对象被放入hchan中的两个等待队列之一:recvq(等待接收数据的Goroutine)或sendq(等待发送数据的Goroutine),这两个队列都是通过双向链表实现的标准FIFO队列 。
在hchan的结构中可以看到recvq和sendq的类型都是waitq
go
type waitq struct {
first *sudog
last *sudog
}而sudog的结构为:
go
// sudog (pseudo-g) represents a g in a wait list, such as for sending/receiving
// on a channel.
//
// sudog is necessary because the g ↔ synchronization object relation
// is many-to-many. A g can be on many wait lists, so there may be
// many sudogs for one g; and many gs may be waiting on the same
// synchronization object, so there may be many sudogs for one object.
//
// sudogs are allocated from a special pool. Use acquireSudog and
// releaseSudog to allocate and free them.
type sudog struct {
// The following fields are protected by the hchan.lock of the
// channel this sudog is blocking on. shrinkstack depends on
// this for sudogs involved in channel ops.
g *g
next *sudog
prev *sudog
elem unsafe.Pointer // data element (may point to stack)
...
}3.3 阻塞与唤醒机制
无缓冲 Channel 和 有缓冲 Channel 的阻塞和唤醒机制存在一定的差异。
3.3.1 无缓冲 Channel 的直接复制
对于无缓冲 Channel,数据传输跳过任何内部缓冲区 。
简单的流程描述如下:
- 假设一个发送方 GS 尝试发送数据,且
recvq上已经有一个等待的接收方 GR。 - 此时,数据不会经过任何缓冲区,Go 运行时会直接将 GS 要发送的数据复制到 GR 的接收变量地址中。
- 完成复制后,Go 运行时会直接唤醒 GR 和 GS,两者继续执行。
这种 Rendezvous 机制保证了极小的延迟和强同步性。
3.3.2 缓冲 Channel 的复杂流转
缓冲 Channel 的流程相对会复杂一点,在缓冲Channel中,如果缓冲区已满,发送方会阻塞并进入sendq。当接收方从这个已满的缓冲区中取走数据时,Channel 的内部逻辑会执行一个精妙的"双重复制"和"唤醒"操作 :
- 考虑一个已满 的缓冲 Channel。发送方 GS 尝试发送数据,它会被封装成
sudog并进入sendq阻塞。 - 当一个接收方 GR 成功从这个已满的缓冲区中取走数据时,Channel 的内部逻辑会执行一个"双重复制"操作:
2.1. 第一步复制:将环形缓冲区当前可读位置的数据复制到 GR 的接收变量地址中。
2.2. 第二步复制:紧接着,Go 运行时会取出sendq队列头部等待发送的 GS 所携带的数据,并将其复制到刚被接收操作腾出的缓冲区空位中。 - 完成数据接力后,Go 运行时会唤醒被阻塞的发送方 Goroutine。 GS 醒来后,它认为自己的发送操作已经完成,但数据实际上已经由 Channel 内部转移到缓冲区,确保了数据流的持续性。
这种设计保证了数据流的持续性,即使缓冲区被填满,接收操作也能无缝地将等待发送的数据管道化到缓冲区中,最大限度地减少了等待时间。
然而,需要注意的是,所有这些内部操作都依赖于hchan.lock的互斥保护 。
尽管这保证了通道状态的顺序一致性,但如果一个通道被成千上万个 Goroutine 高频访问,这个锁可能会成为一个并发瓶颈,导致操作被串行化 。
通过 Goroutine 和 Channel,Go 成功地将 CSP 范式从理论带入实践,实现了高效、简洁且安全的并发编程模式。
四、并发的取舍与最佳实践
经过前文对 Go 并发哲学、G-M-P 调度器和 Channel 内部实现的深入剖析,我们理解了 Go 高效并发的原理。
然而,在实际开发中,开发者仍需面对一个核心问题:何时使用 Go 提倡的 Channel(CSP 范式),何时使用传统的锁(共享内存范式)?
Channel vs. Lock
| 特性 | Channel (CSP 范式) | 锁 (共享内存范式) |
|---|---|---|
| 编程哲学 | 通过通信来共享内存 | 通过共享内存来通信 |
| 核心目的 | 数据所有权转移、任务流程协调 | 局部共享状态的保护 |
| 安全性 | 抽象同步逻辑,自然避免数据竞态 | 依赖开发者手动加锁/解锁,易引入死锁 |
| 性能 | 涉及 hchan.lock 的互斥保护,可能导致操作串行化 |
竞争较低时,对局部数据保护的性能更极致 |
Go 鼓励使用Channel进行通信和协调,因为这天然地避免了数据竞争,使得并发代码"更容易写对" 。
但实际的性能测试表明,对于简单、高频的共享状态修改(例如更新一个缓存Map),由sync.Mutex保护的直接状态变异往往比通过 Channel 与管理 Goroutine 进行请求-响应通信要快得多 。
这是因为 Mutex 的加锁和解锁操作通常是通过高效的原子操作实现的,开销极低;而Channel 操作则涉及内存分配、调度等待 Goroutine,以及潜在的上下文切换,开销相对较大 。
因此,最佳实践要求根据场景选择工具 :
- 共享状态保护(如缓存读写) :如果目标只是保护共享数据结构不被同时访问,应优先使用
sync.Mutex或sync.RWMutex,以获得极致的局部性能 。 - 任务分发与协调:如果问题是工作任务的分配、协调复杂的流程或确保数据所有权的转移,Channel 是更自然且更安全的解决方案,因为它抽象了复杂的协调逻辑(例如生产者-消费者模型) 。
简而言之:用 Channel 解决并发设计问题;用 Lock 解决局部数据保护问题。
参考资料:
- Share Memory By Communicating
- Communicating Sequential Processes CSP
- Bell Labs and CSP Threads
- Go's work-stealing scheduler
- Go Channels Unlocked: How They Work
个人公众号:午夜游鱼 个人博客:muzhy.top/