C语言实战:手搓高并发异步日志库(基于 Ring Buffer + 生产者消费者模型)
1. 为什么 printf 不够用?
在实际项目中,尤其是嵌入式设备、实时系统或高并发服务端程序里,很多人一开始都习惯直接用 printf、fprintf 或 write 把日志打到串口、文件、Flash。这种做法在demo阶段没什么问题,但一旦上了生产环境才发现这玩意儿是个隐形的性能杀手。
我下面列举一下常见的几个致命问题(本人也不幸踩到过):
-
同步阻塞:像
write这样的底层接口是阻塞的,而磁盘 / Flash / 串口通常是比较慢的(Flash 擦除甚至能到几百毫秒),业务线程就只能干等着。我之前写了个demo实测了一下,直接写入 2000 条日志耗时 7秒 ,而使用异步日志仅需 0.02秒 ,性能差距达 300倍。
-
线程中断问题:多任务或中断里同时 printf,没有锁的话日志立刻花屏(A线程打印一半,B线程插进来了),导致日志没法看,而加锁又会带来新的性能和死锁风险。
-
缓存刷新策略失控:
printf默认行缓存 (遇到 \n 或缓冲区满才刷),在嵌入式里经常忘记fflush,在嵌入式系统崩溃或断电的瞬间,缓冲区里重要的数据往往还没来得及刷入磁盘就丢失了导致日志丢失都不知道。 -
CPU 占用率爆炸:高频率打日志时,CPU 大部分时间都在等 I/O,而不是干正事。
那么正确的操作应该是怎样的呢?
我们要把记录日志和写入磁盘彻底解耦。业务线程 只负责把日志扔进一个内存缓冲区(大概几微秒),然后立刻返回继续干活。 由一个独立的后台线程慢慢把缓冲区内容刷到磁盘/Flash/串口去。这就是经典的 " 生产者消费者模型 " 和环形缓冲区的组合。这也是很多工业级日志库的底层原理。
2. 生产者-消费者模型
为了解决上面提到的同步阻塞问题,我们不能让业务线程直接去"碰"磁盘。我们需要引入一个中间层,将产生日志 和写入磁盘 这两个动作彻底剥离。这正是计算机科学中经典的生产者-消费者模型的最佳应用场景。
2.1 系统架构
下面要介绍的这个架构也就是生产者-消费者模型这个名字的由来。
我们可以把整个日志系统看成一个繁忙的餐厅的厨房。可能有人会想"那生产者就是厨师,消费者就是顾客呗",我认为这个想法既合理又不合理,合理是因为这个想法是符合我们的常识的,不合理是因为在日志系统这个环境下,是有特殊情况存在的,后面会解释。在这里,其实生产者相当于服务员,消费者相当于厨师,而他们之间有一个窗口,就是缓冲区(放菜单)。所以整个过程其实就是服务员去给大量的客人点菜,然后把菜单放在窗口,厨师从窗口拿菜单,然后做饭,做饭可以类比为写磁盘。到这里就结束,至少在生产者-消费者模型下,这个场景已经很完善了。所以前面那个把顾客当成消费者的想法有点不太合适,如果这样理解就相当于一个顾客坐那一直吃吃吃......(胃口大的话其实也不是不行🌞)
可能有的朋友还是觉得不够形象,下面我放一张图大家可以参考一下:(纯手画的,感觉画的不错的朋友点赞加关注,不想的话就算了😊)
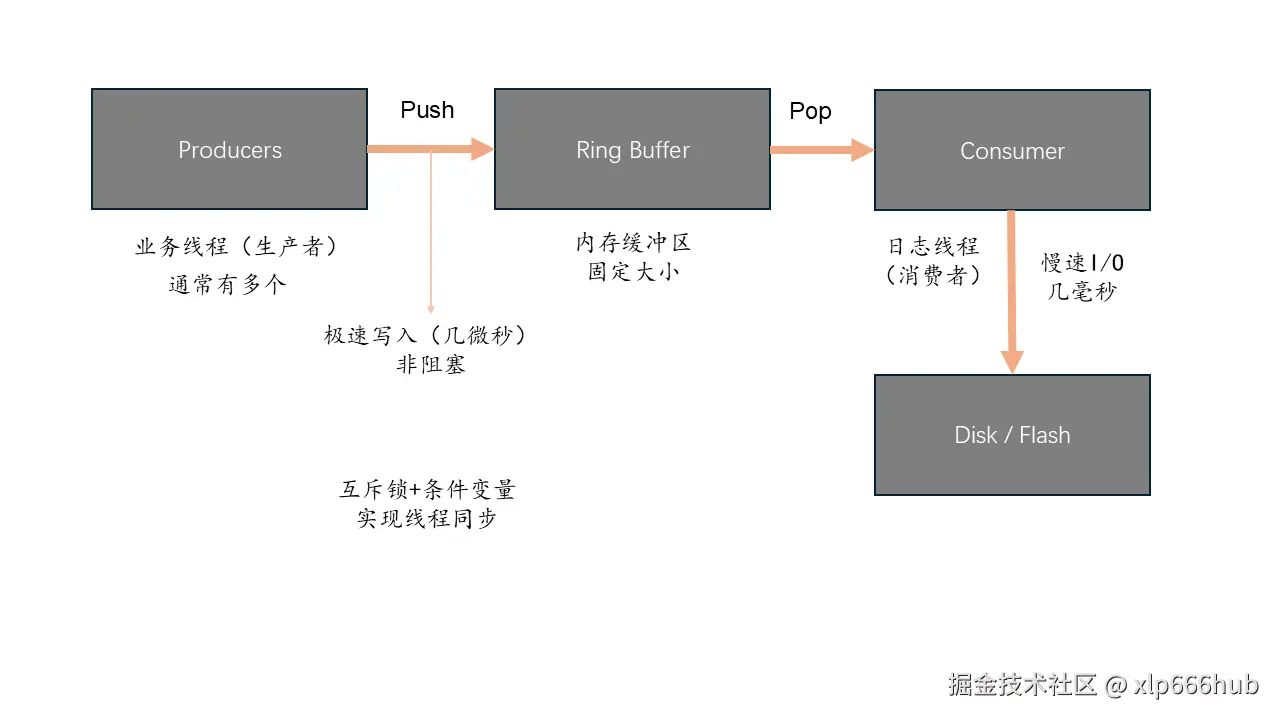
可能有细心的朋友注意到了,我在图片中生产者用的Producers,而消费者却用的Consumer,他们一个是复数,一个是单数,意思是有多个生产者而只有一个消费者吗?答案是肯定的。这个模型的名称是MPSC (Multi-Producer Single-Consumer) ,这是高性能日志系统的标准架构。
为什么消费者只有一个呢?多个消费者会怎么样呢?
- 日志文件通常是一个文本文件(log.txt)。如果你搞了 5 个消费者线程同时往一个文件里写,你需要加很重的锁来防止数据错乱(比如线程 A 写了一半"Error...",线程 B 插进来写了"Warning...")。既然最终都要加锁排队写文件 ,那多搞几个消费者线程不仅没变快,反而增加了上下文切换的开销,还不如就一个线程专门排队写。
- 对于机械硬盘或嵌入式 Flash,顺序写入是最快的。如果有多个消费者并发写,磁头(或 Flash 主控)可能需要跳来跳去,性能反而会下降。
- 一个消费者线程维护一个文件句柄,逻辑清晰,不容易出 Bug。
因此,对于日志落盘这种I/O密集型的任务,单消费者是最高效的选择。
还有的朋友可能会问,你第一章明明写了异步日志快,同步阻塞是致命问题,怎么上面的架构图又说实现了线程同步呢?这不是左脑攻击右脑吗?啊,这里确实比较绕,我有时也得想好久才能想通。下面我们详细拆解一下:
-
在宏观层面:业务流程是异步的
这里的异步描述的是生产者和消费者之间的协作关系。
同步日志(存在缺陷):业务线程说:"我要写日志",然后就在那死等,直到磁盘写完才走。这叫"同步阻塞"。
异步日志:业务线程说:"我要写日志",把数据扔进缓冲区,转身就走,去干别的事了。写磁盘的事留给后台慢慢做。这叫"异步非阻塞"。
因为业务线程不需要等 I/O,所以我们称之为异步日志系统。这是性能大幅度提升的原因。
-
在微观层面:内存访问是需要同步的
这里的同步描述的是两个线程同时访问同一块内存时的安全规则。
如果业务线程正在往
Buffer[0]写数据,还没写完,后台线程突然跑过来要把Buffer[5]读走。这就乱套了。我们需要一种机制,让他们协调一下:"我要写了,你先别动"(互斥锁),"我写完了,该你读了"(条件变量)。
这种为了保证数据安全、不打架的协调机制,在操作系统里叫线程同步。
举一个生活中的例子来比喻一下:
我们把业务线程看作服务员,把Ring buffer看作窗口的菜单钉(固定菜单),把日志线程看作厨师。这里先简单提一下,为什么把Ring Buffer看作菜单钉,因为我们的环形缓冲区Ring Buffer正是一个malloc得来的巨大数组,这个数组大小是固定的,正如菜单钉只有一个,菜单只能按顺序一个一个插,能插的菜单数量也是有限的,这个后面还会详细介绍,先回归主题。
在这个场景下理解就容易多了。
异步:服务员写好菜单,往吧台上一插,转身就去招呼下一桌客人了 (异步) ,他不需要站在厨房门口等着厨师把菜炒好(同步)。这就是效率高的原因。
线程同步:吧台只有一个,菜单钉只有一个。如果服务员正在往上插菜单,厨师正好伸手去拔菜单,两人的手就会撞在一起(疼)。所以我们需要一个规则(互斥锁):当一个人手在接触菜单钉时,另一个人必须在旁边等着。 这就是线程同步 ,并不是说我们要一起动作,而是我们要协调好顺序,不要打架。
2.2 核心角色定义
在这个模型中,每个角色都有自己的职责:
-
生产者:
系统中的业务逻辑线程(如传感器信息采集),它调用
log_push接口,将格式化好的日志字符串写入缓冲区。如果缓冲区没满,写入动作几乎是瞬时的,如果满了,可以选择丢弃或短暂等待(这取决于策略)。 -
环形缓冲区:
一段固定大小的内存空间。作为"蓄水池",平滑业务线程的流量波峰。使用数组模拟环形队列,避免频繁的内存申请与释放。
-
消费者:
一个独立的后台守护线程。死循环检查缓冲区。有数据就取出,写入文件
write,没数据就挂起wait,节省 CPU 资源。虽然它写磁盘慢,但它一直在后台默默工作,不影响前台业务。
2.3 为什么这样设计?
解耦:这样设计可以让业务逻辑不再依赖磁盘 I/O 的速度。哪怕磁盘突然卡顿了 1 秒,业务线程依然可以流畅运行,只要缓冲区没满。
削峰填谷:在某一瞬间,日志量可能瞬间爆发 。缓冲区可以暂时兜住这些数据,后台线程再慢慢消化。如果没有缓冲区,这种瞬间的大量 I/O 请求可能会直接把系统拖垮。
批量写入:这里要先提一嘴,本项目演示的是基础异步写入,没有采用批量写入。如果在生产环境中配合批量写入 (攒够 4KB 再落盘),性能还能进一步压榨,这也是 300 倍差距的来源之一。感兴趣的朋友可以自己实现一下批量写入,看看性能差距相比每条日志写一次有多大。在进阶优化中,消费者可以一次积攒 4KB 数据再一次性写入磁盘,进一步减少系统调用次数,延长 Flash 寿命。
3. 数据结构选型:为何抛弃链表?
在设计日志缓冲区的存储结构时,有两种数据结构可以供我们挑选:
- 链表:动态增长,理论上无限大。
- 环形缓冲区:基于定长数组,循环使用。
初学者往往喜欢用链表 ,因为简单且不需要考虑内存占满的情况。但在高性能、高并发、长期运行的嵌入式/服务端场景下,链表有着致命的缺陷。
3.1 链表的三大缺陷
日志系统一般是要长期运行的,采用链表的日志系统在压测和长期运行下通常会暴露下面几个问题:
3.1.1 内存碎片化
每当有新日志产生,都需要调用 malloc 分配一个小节点,消费后调用 free释放内存。但在高频日志场景下(如每秒 1000 次),频繁的申请释放会将堆内存碎片化 。在嵌入式设备长期运行的条件下(7x24小时),极易导致 OOM (Out Of Memory) ,即使剩余总内存足够,却申请不到连续的大块内存。

这张图片应该是比较形象的,大家看到这张图片应该能够明白内存碎片化大概是什么意思了。
3.1.2 内存分配的性能开销
malloc 和 free 并不是简单的 C 语句,它们是系统库函数 。它们内部维护着复杂的内存链表,并且为了线程安全 ,malloc 内部通常也有锁。
并且在内存碎片化后,malloc调用产生的开销会越来越大 ,因为内存上的孔洞越来越多,这使得寻找一块合适大小的内存越来越困难。高频调用 malloc 本身就会消耗大量的 CPU 时间,这已经违背了我们极速写入的初衷。
3.1.3 CPU 缓存对链表不友好
有朋友就想问了:"为什么CPU缓存对链表不友好呢?难道它对数组就很友好吗?"。是的,他对数组确实友好,但这并不是它歧视链表,而是由CPU本身的特性决定的。
众所周知,数组的内存是连续的,而链表的节点在堆内存中分散分布着,遍历链表需要随机跳跃访问内存,导致 Cache Miss(缓存未命中) 率极高,严重拖慢 CPU 效率。
并且CPU读取内存时,会利用 空间局部性 将相邻的数据预取到 L1/L2 Cache 中,因此数组就占据了天然的优势。
这里有必要拓展一下 Cache Miss ,用一句通俗点的话来讲:现代 CPU 性能的极大程度上取决于数据离核心有多近,而 Cache Miss 正是由于要访问的数据太远所导致的。
下面要聊的是计算机体系结构中比较经典的内容,可能会比较枯燥,但我会尽力把它描述的形象一点:
3.1.3.1 Cache的层级结构
通常我们说L1,L2,L3三层缓存。
L1 Cache(一级缓存) :离 CPU 核心最近,就在核心内部。速度最快,但内存最小,大小为32或64KB,速度约1纳秒。
L2 Cache(二级缓存) :稍微远一点,通常 也是每个核心独享。比 L1 慢一点,但内存更大,256KB 或 512KB。速度约 3-10 纳秒。
L3 Cache(三级缓存) :所有 CPU 核心共享 的。更大,但更慢,几 MB 到几十 MB,速度约 10-20 纳秒。
内存 :主板上的内存条。巨大但极慢,速度约 60-100 纳秒。

这张图是我电脑的配置,可以看到它是16核的。L1缓存为1MB,平摊到每个核上面就是64KB/核。L2缓存平摊到每个核上面是1MB/核。L3缓存的64MB是所有16个核心共享的。
这个配置看起来比上面介绍的参数要大一点(实际上大差不差),但是做嵌入式开发时,面对的板子可能根本就没有L2和L3缓存。Cache Miss 的代价会直接反应在设备卡顿上。
3.1.3.2 什么是 Cache Miss
先介绍一下什么是 Cache Line(缓存行) ,如果CPU要访问一个字节,系统不会只给它这一个字节,而是把这个字节所在的 Cache Line 全部给它,这个 Cache Line 通常是64字节。这意味着,当读取内存地址 0x1000 时,CPU 会自动把 0x1000 到 0x103F 的 64 字节全部加载到 Cache 中。
每一次查找失败,都叫一次 Miss。
当CPU要读取一个变量时,它会先查L1,如果L1命中就直接使用,耗时1ns。如果L1未命中就查L2。
如果L2命中,把数据搬到L1再给CPU,耗时5ns。如果L2未命中就查L3。
如果L3命中,把数据搬到L2,再搬到L1再给CPU,耗时15ns。如果L3也查不到,那就悲剧了。
此时,CPU只能挂起等待,让内存控制器去RAM里面找这一等可能就是上百纳秒。对于 2GHz 的 CPU 来说,100ns 意味着它可以空转 200 个周期。这段时间 CPU 什么都干不了,纯浪费。
对于数组:数组在内存里是连续存放 的。当CPU要访问数组第一个元素 ,大概率是不在三层缓存的,他可能要等很久数据才能被拿过来,速度当然就比较慢了,这叫 Cache Miss 。但它拿回来的是数组第一个元素所在的 Cache Line ,共64个字节。当他处理完第一个元素,要处理第二个时,哎,它发现第二个元素就在他手边,它可以很快的处理完第二个元素,这叫 Cache Hit(缓存命中) 。并且后面它要处理的元素可能全都在它手边,也就是说后面可能全部 Cache Hit ,这样效率是极高的。
对于链表:链表的结点是malloc出来的,在堆内存里面的分布是没有规矩可言的。这时CPU要访问每一个结点,而这些结点存在于三层缓存的概率很小,并且链表没有像数组那样,一次访问慢但对后面多次访问效率提升具有促进作用的机制。因此,如果使用链表,Cache Miss 的概率极高。
3.1.3.3 一点小补充
在高端嵌入式 SoC(如树莓派、手机 Cortex-A)中,通常有 L1/L2/L3 三级缓存。但在低端单片机(如 STM32 Cortex-M3/M4)中,通常没有 Cache 或者只有简单的 指令/数据缓存 。 尽管如此,RAM 的突发读取(Burst Read) 特性依然使得顺序访问(数组)比随机访问(链表)快得多。
现代 RAM 的 Burst Read 特性让顺序读写 64 字节和随机读 1 字节的硬件成本几乎一样。 配合 CPU 硬件预取器和多级缓存,真正连续、64 字节对齐的顺序访问(Ring Buffer)可以比随机跳跃的链表快 10~50 倍,而且这不是软件优化,是物理底层的硬加速,没得选。
所以: Ring Buffer 快不是因为代码写得好,而是因为它吃到了 CPU + Cache + DRAM 三者联合的红利。 链表再优雅,也打不过物理定律。
3.2 环形缓冲区设计原理
环形缓冲区本质上是一个固定大小的数组 ,通过维护 head(读指针)和 tail(写指针)两个索引,和取模运算来实现首尾相接的循环的效果。
下面介绍一下实现的核心逻辑:
-
初始化:申请一块大内存(例如 1MB),这显然不会造成内存碎片化。给
head和tail赋0 。 -
写入 (Push):数据存入
buffer[tail],然后tail向后移动。然后
tail = (tail + 1) % capacity -
读取 (Pop):从
buffer[head]取出数据,然后head向后移动。然后
head = (head + 1) % capacity -
判断是否空或者满:通过一个
count计数器,或者通过head和tail的相对位置来判断。
在本项目中,为了简化多线程下的状态判断,我引入了一个count计数器配合互斥锁来精确控制。
小知识:在极度追求性能的场景下(如 Linux 内核 kfifo),通常会将缓冲区大小设置为 2 的幂次方 (如 1024, 4096)。这样可以用 位运算 (&) 代替 取模运算 (%) :
取模:tail = (tail + 1) % 1024
对应的位运算:tail = (tail + 1) & (1024 - 1)
3.3 核心数据结构定义
为了实现通用性与封装性,我定义了下面结构体:
arduino
// 单条日志的最大长度
#define LOG_MSG_SIZE 128
// 日志
typedef struct {
char data[LOG_MSG_SIZE];
} Log;
// 环形缓冲区管理
typedef struct {
Log *entries; // 指向 malloc 的大数组
int capacity; // 缓冲区总容量
int count; // 当前已存储的日志数量
int head; // 读索引 (Consumer 用)
int tail; // 写索引 (Producer 用)
// 用于优雅退出
int is_running; // 1: 正常运行 0: 停止
// 线程同步工具
pthread_mutex_t mutex;
pthread_cond_t cond_producer; // 若缓冲区满 生产者睡觉
pthread_cond_t cond_consumer; // 若缓冲区空 消费者睡觉
//存放日志内容的文件的文件描述符
int file_fd;
} RingBuffer;这种设计即保证了内存的连续性 ,又通过互斥锁和条件变量保证了线程安全 。在程序启动时 rb_init 一次性分配内存,运行过程中再无内存申请操作,极其稳定。
这里的文件描述符需要再提一嘴,初始化的时候我会把它置为1,代表stdout,也就是说默认的日志输出位置是终端。后面如果要打开文件时那就给他再次赋值。如果只是用来测试,查看终端内容,因而不进行对文件描述符重新赋值的操作,那就要在close之前进行判断,如果文件描述符的值为1,就不进行close操作。但是为了保险起见,我建议不论会不会对文件描述符重新赋值,在关闭文件描述符之前都检查一下它的值。
4. 核心代码实现
为了保证代码的健壮性 与可维护性,我将核心逻辑封装在 ring_buffer.c 中,对外提供简洁的 API。以下是几个最关键的实现细节。
4.1 初始化 ------ 一切的起点
在初始化阶段,我们需要申请内存池,并初始化所有的同步工具(锁与条件变量)。这里有一个设计细节,也就是上文提到的:我们将 file_fd 默认初始化为 STDOUT_FILENO (1),这意味着默认情况下日志会输出到终端,方便调试。
ini
void rb_init(RingBuffer *rb, int capacity) {
//一次性申请堆内存
rb->entries = (Log *)malloc(sizeof(Log) * capacity);
if (rb->entries == NULL) {
perror("malloc failed");
exit(1);
}
//初始化状态
rb->capacity = capacity;
rb->head = 0;
rb->tail = 0;
rb->count = 0;
rb->is_running = 1; //标记系统运行中
//默认输出到终端
rb->file_fd = STDOUT_FILENO;
//初始化互斥锁和条件变量
pthread_mutex_init(&(rb->mutex), NULL);
pthread_cond_init(&(rb->cond_producer), NULL);
pthread_cond_init(&(rb->cond_consumer), NULL);
}这个初始化函数的内存分配正是结合了我们前面一次性申请一大块连续内存的思路,在加快访问速度的基础上还一定程度上保护了Flash。
默认情况下is_running是为1的,从这个成员的名字很容易就能看出它为1是是正常工作的。后面在main函数成功回收全部生产者时将这个值置为0,在消费者中检测这个值为0后执行相应的退出程序,防止生产者已经全部退出了消费者还在苦苦等待日志作无用功这种情况发生。
日志内容的默认输出位置就没必要再讲了,这里只是用宏代替了1,直接用1也是可以的,除了可读性下降没有什么坏处。
最后就是初始化锁和条件变量了,这里我设计了两个条件变量,从名字来看一个是属于生产者的,另一个是属于消费者的。若缓冲区为空,则消费者睡觉,直到生产者生产出日志内容,会用 cond_consumer 来叫醒消费者。若缓冲区已满,则生产者睡觉,当消费者消费日志内容使得缓冲区空间空出来时,他会使用 cond_producer 叫醒生产者。这在后面的具体代码实现中会直观的看到。
4.2 生产者 (Push)拒绝虚假唤醒
这是高并发写的核心逻辑。为了防止"惊群效应"和"虚假唤醒",必须严格遵守 POSIX 多线程编程规范。
scss
void rb_push(RingBuffer *rb, const Log *entry) {
pthread_mutex_lock(&(rb->mutex));
while (rb->count == rb->capacity) {
pthread_cond_wait(&(rb->cond_producer), &(rb->mutex));
}
// 直接 memcpy 到数组对应位置
memcpy(&(rb->entries[rb->tail]), entry, sizeof(Log));
// 更新索引
rb->tail = (rb->tail + 1) % rb->capacity;
rb->count++;
// 唤醒消费者
pthread_cond_signal(&(rb->cond_consumer));
pthread_mutex_unlock(&(rb->mutex));
}Push这个单词很形象,我相信不解释大家也能知道这里在干什么,这个函数就是用来把日志内容Push进RingBuffer的。
这里的判断为什么要使用while呢,可能会有些喜欢思考的朋友认真看了之后发现,这里只是判断一下缓冲区内的日志数量是否等于缓冲区最大容量,也就是判断缓冲区满了没有。如果满了那就等呗,没满那就继续生产日志呗。那按道理来说用if来判断也行啊?其实是不行的,这里存在一个虚假唤醒的情况。
虚假唤醒 是指,线程在调用 pthread_cond_wait() 开始睡觉之后,即使没有任何人调用 pthread_cond_signal() 或者 pthread_cond_broadcast() ,线程也有可能莫名其妙的醒来。但这个看似存在漏洞的行为其实是 POSIX 标准明确允许的行为。导致虚假唤醒比较常见的原因有:操作系统调度器的内部优化,内存伪共享,信号中断等。所以说醒来并不一定是被 signal 或者 broadcast 唤醒的,意思就是条件不一定能满足。
大家现在来想象一下这个场景,假如线程由于虚假唤醒醒来 了,但实际上这时缓冲区还是满的,它应该睡觉,不应该醒着。如果使用了 if 来判断,它会什么都不管,直接继续往下执行,先把 entry 的内容拷贝到 RingBuffer ,然后更新索引和日志条数,然后就完蛋了(╯°□°)╯︵ ┻━┻。因为缓冲区已经溢出了。
但是如果这里使用while进行判断,在触发虚假唤醒后,他会重新检查缓冲区是否满了 ,如果没满就跳出 while ,继续往下执行。如果满了那就在执行 pthread_cond_wait(&(rb->cond_producer), &(rb->mutex)); 进入睡眠。不会发生像if那样的可怕场景。
4.3 消费者 (Pop) 与优雅退出
消费者不仅要处理数据,还要负责监听停机指令 。如果只是一个 demo ,那让消费者直接无限循环就完事了,后面直接 Ctrl+C 暴力终止。但是如果想真正应用到工程上,那就要实现优雅退出。
scss
// 函数返回值:1 表示成功拿到数据,0 表示系统关闭且无数据
int rb_pop(RingBuffer *rb, Log *entry) {
pthread_mutex_lock(&(rb->mutex));
// 只有当缓冲区为空,且系统还在运行时,才选择等待
while (rb->count == 0 && rb->is_running) {
pthread_cond_wait(&(rb->cond_consumer), &(rb->mutex));
}
// 如果醒来发现没数据了,而且系统标志位已关闭,那就解锁后退出
if (rb->count == 0 && !rb->is_running) {
pthread_mutex_unlock(&(rb->mutex));
return 0;
}
// 正常消费
memcpy(entry, &(rb->entries[rb->head]), sizeof(Log));
rb->head = (rb->head + 1) % rb->capacity;
rb->count--;
// 唤醒生产者
pthread_cond_signal(&(rb->cond_producer));
pthread_mutex_unlock(&(rb->mutex));
return 1;
}代码中已经有了比较详细的注释,但为了内容的全面性,我还是简单介绍一下这个函数。
先来看 while 循环,只有当缓冲区为空,而且系统还在运行时,才等待。
如果缓冲区为空,但 is_running 被置为0了,那就跳出循环,往下执行到 if ,条件满足,解锁后直接返回0,后面在消费者线程中会检查这个返回值,这个到后面再说吧。
如果缓冲区不为空,且 is_running 为1,正常运行,那就是正常消费后唤醒生产者,函数返回1。
如果缓冲区不为空,且 is_running 为0,也就是说,生产者已经全部退出了,但缓冲区还有些日志内容没有被消费。那我们的逻辑就是消费完这些日志再退出 。来看代码,这种情况依然会跳出 while 循环,在 if 判断是,是不满足条件的,所以不会在 if 里面退出,而是继续往下执行,正常消费日志,完了返回1,到后面大家会知道,消费者线程是在循环调用 这个函数的,所以会一直重复上面描述的过程,直到日志全部被消费完,缓冲区空了,这时满足 if 的条件了,返回0。消费者线程检测到0后优雅退出。
这里我还想提一点,我在 4.2 和 本节4.3 里都用了 memcpy。在这里使用 memcpy 是安全的,因为我们在 log_push 里已经用 snprintf 保证了源数据长度不会超过 LOG_MSG_SIZE,所以不会发生越界拷贝。
优雅退出的代码没什么深度,我就不解释了,直接放在下面:
scss
//优雅退出
void rb_stop(RingBuffer *rb)
{
pthread_mutex_lock(&(rb->mutex));
rb->is_running = false;
pthread_cond_broadcast(&(rb->cond_consumer));//唤醒消费者
pthread_mutex_unlock(&(rb->mutex));
}4.4 安全性封装拒绝缓冲区溢出
在 C 语言中,strncpy 和 sprintf 都是缓冲区溢出的重灾区。为了保证日志内容的安全,我在业务封装层使用了 snprintf。
snprintf 是 C 语言中最重要,最安全的字符串格式化函数之一,它几乎完全取代了老的 sprintf,也是现代 C 代码中唯一推荐使用的格式化输出到字符串的函数。
MISRA C 2012(汽车嵌入式规范):禁止 使用库函数sprintf,vsprintf ,必须使用带长度限制的替代函数,如snprintf、vsnprintf。
Linux 内核、GNU、LLVM、Chrome、Firefox 等大型项目:全部禁止 sprintf,强制 snprintf。
除了一些大型项目可能还存在历史遗留的sprintf()调用问题。在现在的新项目中,绝对应该使用snprintf而不是sprintf ,这是工业界的共识,不是可有可无的风格问题,而是安全问题。
arduino
void log_push(RingBuffer *rb, const char *msg) {
Log log_entry = {0};
// 可以自动处理 \0 结尾,防止 msg 过长导致的越界访问
snprintf(log_entry.data, LOG_MSG_SIZE, "%s", msg);
rb_push(rb, &log_entry);
}5. 性能压测与总结
为了验证这个异步日志库的健壮性,我设计了一个高并发 + 极小缓冲区的测试场景。
5.1 压测场景设计
为了模拟最恶劣的竞争环境,我特意将缓冲区容量设置得极小,强迫线程频繁发生阻塞和唤醒。
生产者:2个线程(Producer1,Producer2),每个狂发1000条日志。
消费者:1个后台线程。
缓冲区容量:设为10,这意味着生产者每生产几条日志就要被迫睡觉,锁竞争将会非常激烈。
预期结果:日志文件应该包含整整2000条数据,无丢失,无乱序(线程内部有序),并且程序可以优雅退出。
这是 main.c 的内容,大家可以照着我上面的解释梳理一下逻辑:
c
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <pthread.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include "ring_buffer.h"
#define FILE_NAME "log.txt"
void log_push(RingBuffer *rb,const char *msg)
{
Log log_entry = {0};
snprintf(log_entry.data,LOG_MSG_SIZE,"%s",msg);//最推荐的函数
rb_push(rb,&log_entry);
}
void *pthread_producer1(void *arg)
{
RingBuffer *rb = (RingBuffer *)arg;
for(int i=0;i<1000;i++)
{
char buf[64];
snprintf(buf, sizeof(buf), "Producer1 code:%d\n", i);
printf("Producer1 pushing:%s\n",buf);
log_push(rb,buf);
usleep(100);
}
return NULL;
}
void *pthread_producer2(void *arg)
{
RingBuffer *rb = (RingBuffer *)arg;
for(int i=0;i<1000;i++)
{
char buf[64];
snprintf(buf, sizeof(buf), "Producer2 code:%d\n", i);
printf("Producer2 pushing:%s\n",buf);
log_push(rb,buf);
usleep(100);
}
return NULL;
}
void *pthread_consumer(void *arg)
{
RingBuffer *rb = (RingBuffer *)arg;
Log entry;
while(rb_pop(rb,&entry))//循环检测返回值,看看是不是要退出
{
write(rb->file_fd,entry.data,strlen(entry.data));
}
printf("消费者线程:优雅退出\n");
return NULL;
}
int main()
{
RingBuffer rb;
rb_init(&rb,10);
rb.file_fd = open(FILE_NAME,O_RDWR|O_CREAT|O_APPEND,0644);
if(rb.file_fd == -1)
{
perror("文件打开失败");
return -1;
}
pthread_t consumer,producer1,producer2;
pthread_create(&consumer,NULL,pthread_consumer,(void *)&rb);
pthread_create(&producer1,NULL,pthread_producer1,(void *)&rb);
pthread_create(&producer2,NULL,pthread_producer2,(void *)&rb);
pthread_join(producer1,NULL);
pthread_join(producer2,NULL);
printf("所有生产者已经结束任务\n");
rb_stop(&rb);
pthread_join(consumer,NULL);
printf("消费者已经退出\n");
close(rb.file_fd);
rb_destroy(&rb);
return 0;
}由于篇幅已经比较长了,下面我直接贴出 Makefile :
makefile
CC = gcc
CFLAGS = -Wall -g -pthread
TARGET = app
SRCS = main.c ring_buffer.c
OBJS = $(SRCS:.c=.o)
all: $(TARGET)
$(TARGET): $(OBJS)
$(CC) $(CFLAGS) -o $(TARGET) $(OBJS)
%.o: %.c ring_buffer.h
$(CC) $(CFLAGS) -c $< -o $@
.PHONY: clean test
clean:
rm -f $(OBJS) $(TARGET) log.txt
test: $(TARGET)
./$(TARGET)
简单介绍一下怎么使用,首先命令行输入make进行编译,然后输入./app运行程序。或者嫌麻烦的可以直接命令行输入make test,这会直接编译并且运行程序。运行完成后可以使用make clean清除程序运行产生的文件。
5.2 测试结果验证
运行之后终端输出如下:
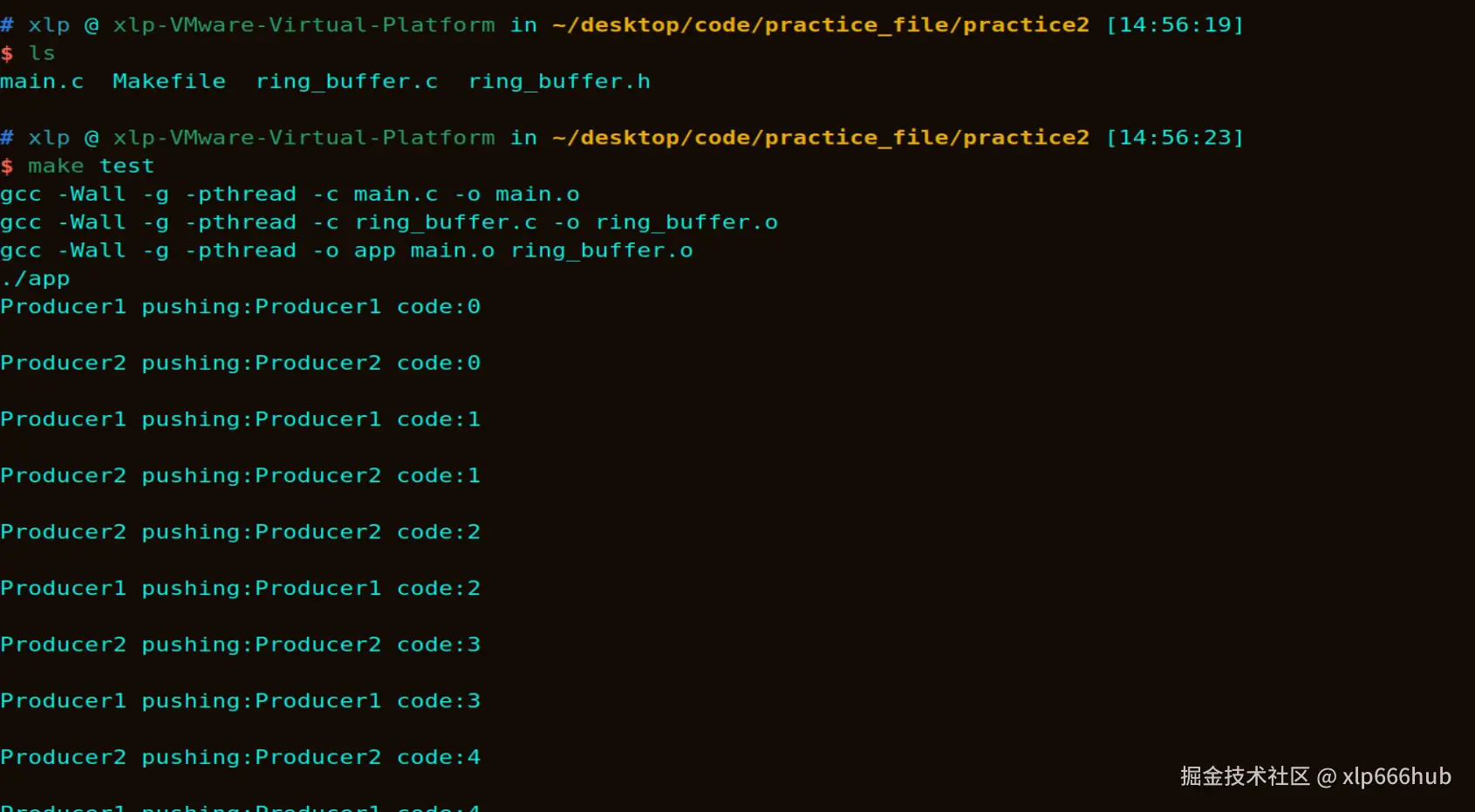
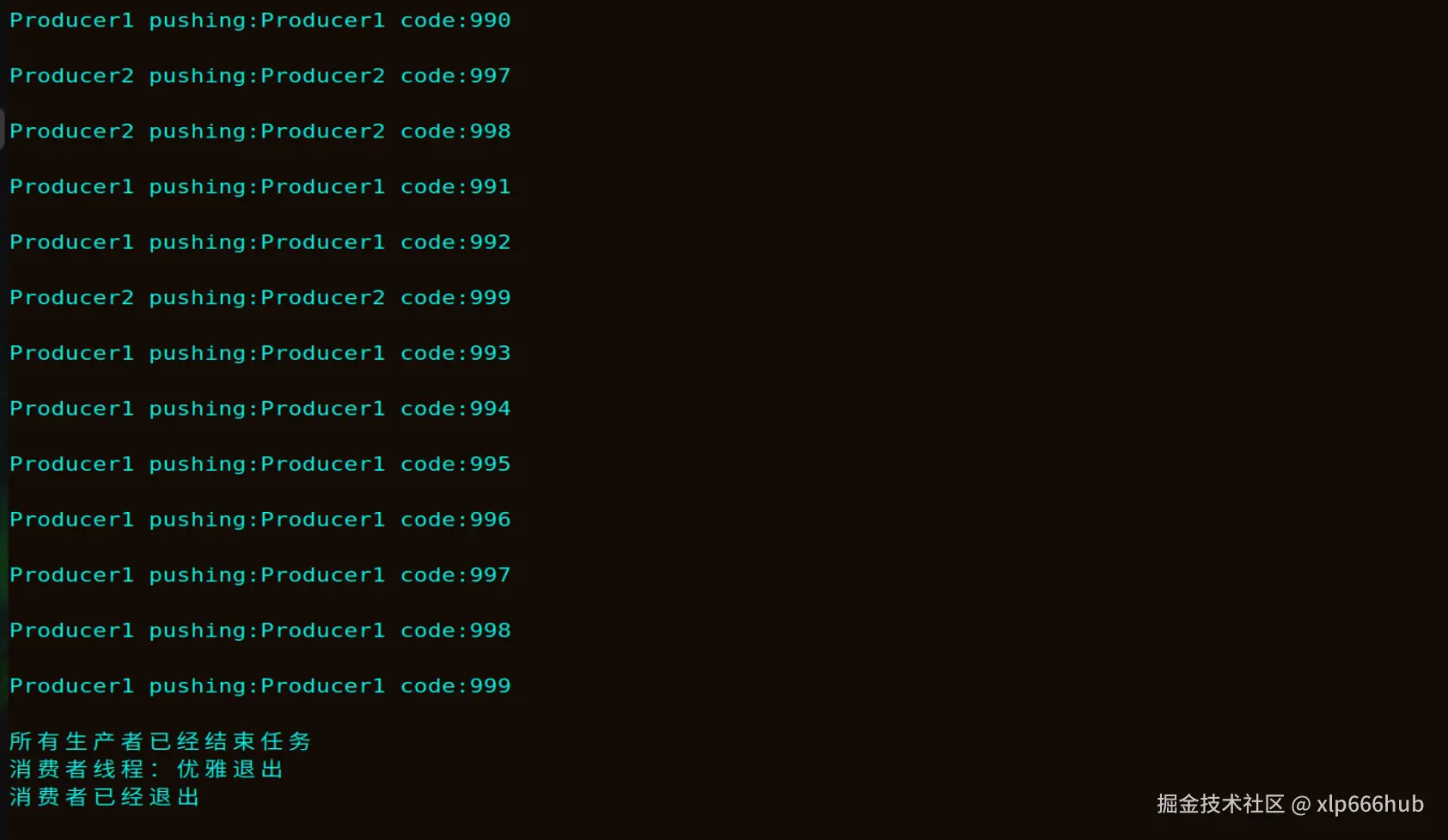
由于我在两个生产者中都添加了printf函数,所以在终端会看到他们打印出来的内容,总共2000条,我只截图了最前面和最后面的部分,可以看到已经实现了优雅退出(生产者全部退出后,消费者自动退出)。
然后我们再来查看一下日志内容是否存放到了 log.txt 里面:


我们同样只截去最前面和最后面的部分,两个生产者线程产生的日志内容都是从0-999,也就是各1000个,总共2000个。

再来查看 log.txt 文件的行数,发现也是2000行。这足以说明一条日志都没有丢失。
结果分析:在容量仅为 10 的情况下,2000 条日志全部落盘,证明条件变量的 wait & signal 逻辑 很严密。主线程成功等待所有子线程结束,证明优雅退出 机制生效,没有线程卡在 wait 状态。从终端输出可以看到,两个生产者交替抢占 时间片,证明互斥锁有效保护了临界区。
5.3 项目总结与思考
从最开始简单的每产生一条日志就用 write 直接写盘,到最终完成这个异步日志库 ,这个过程不仅仅是代码量的增加,更是工程思维的提升。下面是我在整个过程中的一些思考:
5.3.1 向硬件物理特性妥协
有人可能更关注算法的时间复杂度,但在嵌入式底层开发中,硬件特性才是性能的天花板。
放弃链表选择 Ring Buffer ,不仅仅是为了管理方便,更是为了确定性 。在长期运行的嵌入式系统中,避免频繁 malloc/free 造成的堆内存碎片是系统稳定的基石。
利用数组的空间局部性 ,大幅减少 Cache Miss,让 CPU 流水线跑得更顺畅。
5.3.2 解耦与削峰填谷
利用 生产者-消费者模型 ,将业务逻辑(快)与磁盘 I/O(慢)彻底分离。
Ring Buffer 在这里扮演了"蓄水池"的角色。面对突发流量,缓冲区能起到削峰填谷的作用,防止瞬间的高频 I/O 请求将系统拖垮。
虽然使用了互斥锁,但配合条件变量 避免了忙等待,在保证数据安全的同时,最大程度降低了 CPU 占用率。
5.3.3 防御性编程与生命周期
全面禁用 strcpy/sprintf,严格使用 snprintf 防止缓冲区溢出。
实现了优雅退出 机制。通过 is_running 标志位和广播唤醒,确保程序退出时,缓冲区内残留的日志能被全部消费,做到数据零丢失。
通过结构体封装文件描述符与互斥锁和条件变量,实现了高内聚低耦合,拒绝全局变量的污染。
5.4 进阶优化方向
虽然目前的版本已经是一个稳定、高效的异步日志库,但在面对更苛刻的工业级场景(如车规级嵌入式、高频交易系统)时,我们还可以从以下几个维度进行深度优化:
5.4.1 批量写入与页缓存对齐
前面已经提到批量写入的内容,如果采用批量写入,还能在本项目的基础上把性能进一步压榨 。而目前的实现是消费者每次 Pop 一条日志就调用一次 write 。
而 write 是系统调用,涉及用户态到内核态的上下文切换,存在着巨大的开销。
优化思路:在消费者线程内部维护一个 4KB(一页内存) 的中间缓冲区。当积攒的数据达到 4KB 或者超时(可以自己设定一个时间)时,再一次性调用 write 落盘。这能将系统调用的频率降低一个数量级,并更好地利用文件系统的 Page Cache。
5.4.2 存储管理
嵌入式设备的存储空间(Flash/SD卡)是有限的,我们不能让 log.txt 无限增长。
优化思路:当 log.txt 达到 10MB 时,自动将其重命名为 log.txt.1,并创建新的 log.txt。可以保留最近 N 个备份,自动删除最旧的日志,防止磁盘写满导致系统崩溃。
5.4.3 无锁队列
目前的实现使用了 Mutex + Cond。在极高并发(几十个线程同时写入)下,锁竞争会导致 CPU 上下文切换开销增大。
优化思路:参考 Linux 内核 kfifo 的实现,利用 原子操作 和 内存屏障 来管理 head 和 tail 指针。最终目标是实现单生产者-单消费者 模式下的完全无锁,或多生产者模式下的无锁入队,将性能压榨到物理极限。
5.4.4 零拷贝
当前的 log_push 涉及两次拷贝(snprintf 到栈,memcpy 到 RingBuffer)。
优化思路:设计函数接口允许业务线程直接在 RingBuffer 的内存区域内进行格式化写入(通过返回写指针),省去中间的栈内存拷贝过程,进一步降低内存带宽占用。