核心流程:
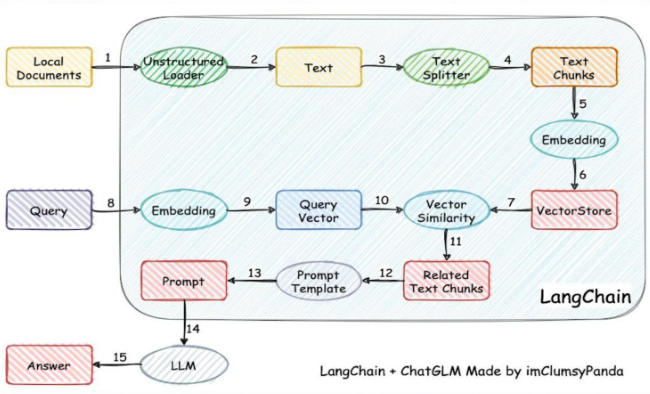
- 知识更新阶段:从非结构化数据(PDF/Excel/HTML等)获取原始数据→文档解析→文本分割(Chunk)→向量化→存入向量数据库
- 知识检索阶段:用户查询向量化→向量相似度检索(余弦相似度算法)→相关文档筛选→Prompt拼接→大模型生成答案
RAG流程的关键点:
- 文档解析难点: 处理多格式混合文档(如PDF包含图片、表格、文字等)是RAG流程中的首要难点,需要将非结构化数据转换为标准文档对象
- 文本切割策略: 大文档需切割为chunk(类似分页),切割效果直接影响最终结果,需根据业务场景反复试验优化,无固定方法论
- 向量化模型选择: 向量化模型的质量会显著影响效果,是第三个关键环节,需要谨慎选择适合的嵌入模型
- 向量数据库考量: 虽然现代向量数据库能力普遍较强,但仍需作为关键环节关注,选择不当仍会影响整体效果
- 检索算法关键性: 使用何种相似度检索算法(如余弦相似度)是第五个关键点,直接影响相关文档的召回质量
- 结果精筛机制: 检索出的文档(如10个)需通过rerank算法筛选最相关的部分(如前3个),避免噪声干扰大模型生成
- 效果评估闭环: 必须建立效果评估体系定位问题环节(文档解析/检索/rerank等),通过迭代优化提升整体效果
RAG流程包含7个关键环节,任一环节处理不当都会导致整体效果骤降,这是落地的核心难点,
首次实现的效果通常不理想,需要通过评估-定位-优化的闭环持续改进各环节。
核心难点:
- 数据工程:将原始数据转化为有效知识的过程,质量直接影响知识库准确率
- 效果评估:自研评估框架实现准确率从70%到95%的优化迭代
- 模型管理:保障数据安全前提下的高效模型维护
- 代码设计:开发稳定高效的生产环境级代码
落地场景:
- 基础问答:直接回答问题的简单场景
- 知识库问答:限制回答范围的专业场景
- 联网问答:实时搜索整合信息的复杂场景(类似Kimi)
- 问答推荐:结合用户画像的智能推荐
- Agent问答:任务拆解+分步解决的复合架构