1. 大模型概述
1.1 大模型基本原理
① 核心本质:大模型是一个"超级函数"
传统函数与大模型的本质对比:
-
普通函数: f(x) = y (给定输入 x,通过固定数学规则,算出确定的输出 y)
-
大模型函数: f(Prompt) = Next Token 概率分布(输入提示词,通过海量参数矩阵,算出下一个词的概率)
大模型不是一个拥有人类意识的"智脑",而是一个规模极其庞大、包含了千亿级浮点数参数的数学函数。
② 运作流水线:单字续写的"无限循环"
大模型生成回答并不是"一蹴而就"的,而是像"成语接龙"一样,严格遵循以下四步循环:
[ 用户输入 Prompt ]
│
▼
1. 切割 Token ──> 将文本切成字、词或词根(Token)
│
▼
2. 内部矩阵运算 ──> 经过千亿参数计算
│
▼
3. 概率分布输出 ──> 算出词表中每个词出现的概率
│
▼
4. 摇号采样 (Sample) ──> 决定吐出"下一个 Token"
│
└─────── 拼接到原输入后面 ───────> (回到步骤1,循环往复)核心特点: 自回归(Autoregressive)。模型每次只预测一个 Token,然后把新词当成前文,吐出下下个词,直到拼出完整段落。
总结:
通过在大规模语料上进行这种训练,模型能够学习到语言的语法结构、表达方式、知识关联以及一定的推理模式。因此,虽然它的底层训练目标看起来只是"预测下一个 token",但当模型规模、训练数据和训练方法达到一定程度后,模型就能够表现出问答、摘要、翻译、信息抽取、代码生成等多种能力。
-
底层目标的极简性: 模型的底层驱动力极其单纯,不为了理解,不为了思考,只为了"预测下一个 Token 猜得更准"。
-
量变引起质变(Scale Law): 当模型参数规模 变大、训练数据 变多、方法变对之后,原本只学会了"接龙"的模型,突然就具有了智能。
-
能力的"自动涌现": 为了把下一个词猜得更准,模型被迫在海量语料中顺便学会了:人类的语法结构、逻辑推理、代码编写、翻译和摘要等高级智力能力。
1.2 大模型结构
基本信息:
-
技术底座: 基于 Transformer 架构 的 Decoder-only(仅解码器) 结构(代表:GPT、DeepSeek、Qwen)。
-
物理本质: 大模型从外面看是一个黑盒,内部其实就是输入层 + 几十层 Transformer Block + 输出层的纵向堆叠。
-
参数的真面目: 模型内部充斥着庞大的矩阵 ,矩阵里密密麻麻的浮点数值,就是常说的"千亿参数"。
Token 的"加工流水线"
数据进入模型后,会严格经历以下三个部门的清洗和改造:
[用户输入文本]
│
▼
┌──────────────┐
│ 1. 输入层 │ ──> 【切分 Token】 + 【查表向量化 (Embedding)】
└──────┬───────┘ (把不能计算的"文字",变成带有初始语义的"数字向量")
│
▼
┌──────────────┐
│ 2. 堆叠层 │ ──> 【注意力机制 (Attention)】 + 【前馈神经网络 (FFN)】
└──────┬───────┘ (让 Token 回头看上下文,更新表示,融入语境的恩怨情仇)
│
▼
┌──────────────┐
│ 3. 输出层 │ ──> 【LM Head 矩阵映射】 ──> 【得到全局词表概率分布】
└──────────────┘ (利用最后一个位置的向量,预测下一个词的概率,摇号输出)总结:
-
输入层: 负责化整为零,字变数字(初始语义)。
-
Transformer Block: 负责前后勾连,注入语境(上下文语义)。
-
输出层: 负责以终为始,概率摇号(预测未来)。
这个"自回归"的无限循环(预测 --> 拼接 --> 再预测),就是大模型能够输出千言万语的唯一底层真相。
1.3 大模型发展历程
自 2018 年 GPT-1 发布以来,到如今的GPT-5.x,GPT 系列的发展推动了现代大语言模型训练范式的逐步成熟,形成了以 "预训练---监督微调---对齐" 为核心的三阶段开发框架:
- 预训练(Pre-training )
基于超大规模无标注语料进行自监督学习,使模型获得通用语言建模能力、广泛的世界知识以及基本的推理与泛化能力。
- 监督微调(Supervised Fine-tuning, SFT )
利用人工构建的指令---响应示例或高质量对话数据对模型进行进一步训练,使其能够更好地理解指令,并输出更加规范、稳定且贴合任务需求的内容。
- 对齐(Alignment )
通过引入人类偏好、行为规范、安全约束与价值观等因素,使模型的行为更符合用户期望。对齐方式包括RLHF(奖励模型 + 强化学习)以及DPO、ORPO、KTO 等无需强化学习的偏好优化方法。对齐阶段的目标是让模型在真实应用场景中表现得更有帮助、更安全、更可靠。
这一"三阶段"开发范式在实践中得到广泛验证,已成为业界主流的大语言模型训练框架。
2. 大模型适配方法
在企业级大语言模型(LLM)落地实践中,通用模型的静态泛化能力与特定行业、私域专业任务的高精度需求之间存在天然鸿沟。为了在特定业务场景中提升模型的适用性、稳定性、事实准确性与输出质量,必须通过针对性的技术手段进行增强与适配。
在实践中常见且具有代表性的适配方法包括:提示词工程( Prompt Engineering )、微调(Fine-tuning )、检索增强生成(Retrieval Augmented Generation ,RAG **)。**这些方法从不同层面优化模型,各有其适用场景与优势。
2.1 提示词工程 (Prompt Engineering)
-
核心机制: 属于推理期(Inference-time)外围引导技术。在不改变大模型内部参数矩阵的前提下,通过设计高度结构化的输入指令、上下文锚定、多样本示例(Few-shot)和输出格式强制约束,激活并引导模型的内在生成概率。
-
核心优势: 零参数训练成本、即时迭代生效、灵活性与可扩展性极强,是所有应用场景下的首选渐进式适配方案。
-
技术瓶颈: 效能完全受限于大模型本身的基座能力上限(Upper Bound)、受制于上下文窗口长度限制(Context Window Constraint),且无法根本消除复杂长尾任务中的行为非一致性。
2.2 微调 (Fine-tuning)
-
核心机制: 属于训练期(Training-time)内在参数调整技术 。通过在特定分布的标注数据集上进行梯度下降,调整模型的权重参数,改变其内在概率分布。**微调主要用于让模型更稳定地学习特定任务、格式、语气或业务风格。**使其输出更贴合任务需求或更符合人类偏好。
-
核心范式分类:
-
监督微调 (SFT): 运用高质、规范的"指令---响应"对进行强监督学习,强制模型内化特定的输出格式、专业语调、业务风格及固定标签分类逻辑。
-
偏好对齐 (Preference Alignment): 基于对比偏好数据,缩减有害输出空间,使其在安全性、价值观及综合交互质量上收敛于人类期望。
-
-
关键决定因素: 微调效能高度依赖于标注数据集的纯净度、覆盖广度、一致性与任务定义的清晰度。
2.3 检索增强生成 (RAG)
-
核心机制: 属于推理期动态知识注入技术 。将信息检索(IR)与自回归生成(Generation)耦合,在推理阶段实时从外部异构知识源(如向量数据库、图数据库)中召回与输入高度相关的文本切片(Chunks),作为真实性上下文(Context)注入提示词。RAG 主要用于让模型在回答时检索并参考外部知识,以提升事实准确性和知识时效性。
-
核心优势: 无需变更模型参数,专门用于抹平事实性幻觉,极度适用于知识时效性要求高、私域敏感数据多、动态更新频繁的企业文档智能与专业咨询场景。
-
关键决定因素: 依赖于外部知识库的数据治理质量、检索算力的召回率(Recall)与精确率(Precision)以及 Chunk 段落的相关度。
总结:适配方法选择策略
在实际系统架构设计中,为实现投入产出比(ROI)的最大化,开发者应遵循"从外围到内部、从低算力到高算力"的渐进式路径进行适配决策:
[ 业务适配需求明确 ]
│
▼
[ 步骤 1: 提示词工程 ] ──(满足业务要求)──> [ 上线部署 ]
│
(效果不达标)
│
▼
是否需要大量私域、高动态知识?
├───> [是] ───> [ 步骤 2: 构建 RAG 系统 ] ──(满足要求)─> [ 上线部署 ]
└───> [否] ──────────┐
│
▼
是否需要严格的格式、品牌风格、或行为高度一致性?
└───> [是] ───> [ 步骤 3: 启动模型微调(SFT/对齐) ] ─> [ 上线部署 ]-
第一阶段: 优先实施提示词工程,快速试探模型的能力边界,定义任务并固化初步输出。
-
第二阶段: 若任务涉及海量外部动态知识、长尾事实查询,引入 RAG 架构 补充模型的外部检索回路。
-
第三阶段: 若 RAG 阶段模型的格式依然泛化较差,或者需要极高的领域风格、行业术语规范和分类稳定性,则收集高质量标注数据启动监督微调与偏好对齐。
-
终极形态: 在复杂的垂直产业落地中,业界通常采用 "微调基座(定风格/定格式) + RAG(喂数据/给事实) + 提示词工程(作调度/严约束)" 的复合链路架构。
3. 微调整体流程
现代大语言模型(LLM)的监督微调(SFT)是一项系统性的工程流水线。其标准生命周期严格遵循"模型选择 --> 数据准备 --> 微调训练 --> 模型验证"四个核心物理环节。
3.1 模型选择 (Model Selection)
模型选型是微调工程的起点,需从模型类型(基座偏好)与参数规模(算力边界)两个维度进行联合决策。
1. 范式选型:Base Model vs Instruct Model
-
Instruct Model(指令/对话对齐模型): * 技术现状: 已经在基座模型之上历经了标准 SFT 和人类偏好对齐(RLHF/DPO)。
- 工程建议: 绝大多数业务场景的首选起点。由于其天然具备成熟的指令遵循和多轮对话解构能力,能显著降低数据构建与收敛难度,极其适用于客服、生成、结构化输出等场景。
-
Base Model(基础/预训练基座模型): * 技术现状: 仅具备基于概率续写文本的通用表征能力。
- 工程建议: 仅适用于边缘高度定制化任务,或企业拥有海量私域高质数据、希望从零固化底层领域泛化能力的深度适配场景。
2. 规模选型(Scale Selection)与业务场景映射
模型规模的选择需要在任务复杂度、显存开销(VRAM)、推理时延(Latency)与部署成本之间取得平衡。工业界渐进式选型基准如下:
| 目标业务场景 | 推荐模型类型 | 推荐参数规模 | 选型考量与逻辑 |
|---|---|---|---|
| 端侧轻量部署/边缘设备 | Instruct Model | 0.5B - 4B | 受限于硬件算力与功耗限制,牺牲部分泛化性能换取极致吞吐。 |
| 意图识别 / 文本分类 | Instruct Model | 1B - 7B | 属于判别式任务,语义空间相对收敛,小规模模型足以稳定提取特征。 |
| 智能客服 FAQ / 工单辅助 | Instruct Model | 7B - 14B | 兼顾多轮对话的上下文控制力与线上高并发低时延要求。 |
| 企业知识库问答 / RAG | Instruct Model | 核心 7B - 14B 复杂场景 14B - 32B | 需要较强的上下文窗口(Context Window)注意力保持能力,避免长文本导致的知识漂移。 |
| NL2SQL (自然语言转 SQL) | Instruct Model | 简单 7B - 14B 复杂场景 14B - 32B | 属于高密度结构化逻辑推理,较大规模(如 32B)能显著提升语法树(AST)生成的稳定性。 |
3.2 数据准备 (Data Preparation)
数据治理是决定微调成败的底层基石(Data-centric AI)。
-
数据来源: 公共数据源: 来源于 HuggingFace、ModelScope 等开源社区,用于补充通用指令遵循能力。(https://huggingface.co/ 、 ModelScope 魔搭社区)
- 私有数据源: 来源于企业私域文档、业务数据库、客户真实历史交互,是构建差异化竞争力的核心。
-
数据清洗管线(Pipeline): 原始数据必须经历 "筛选 --> 清洗 --> 结构化抽稀 --> 人工/AI 标注 --> 格式转换",最终转化为标准的 Prompt-Response 对。
-
**数据集格式:**在大型语言模型的监督微调中,数据集的构建格式至关重要,常见的格式可分为两类:指令式 与 对话式。
bash
指令式:指令式数据集用于训练模型执行明确的单轮任务,如翻译、摘要或问答。其典型格式源自斯坦福大学的 Alpaca 项目,结构简洁、易于使用。
每条样本包含三个字段:
instruction:描述模型需要执行的任务;
input:任务所需的上下文或附加信息;
output:模型应生成的正确回答。
{
"instruction": "将以下英文翻译成中文",
"input": "Large language models are transforming AI.",
"output": "大语言模型正在改变人工智能。"
}
训练时,这些字段通常会通过一个提示模板(prompt template)组合成结构统一的输入字符串,以帮助模型更好的学习任务指令。
### 指令:
{instruction}
### 输入:
{input}
### 回复:
{output}
bash
对话式数据集用于训练模型进行多轮对话,例如聊天机器人、虚拟助手等。这类数据通常以消息序列的形式组织,强调发言者角色与对话流程。目前广泛采用的格式主要有 ShareGPT 格式 和 OpenAI 格式。
1)ShareGPT 格式
ShareGPT 格式源于用户在社区中分享的与 ChatGPT 的真实对话记录,常用于保存多轮对话数据集。
每条数据样本由一个名为 conversations 的列表构成,列表中的每个元素代表一次发言,包含两个关键字段:
from:标识发言者的角色,通常取值为 "human"(表示用户)或 "gpt"(表示模型助手);
value:该轮对话的具体文本内容。
如:
{
"conversations": [
{
"from": "human",
"value": "你能解释一下什么是机器学习吗?"
},
{
"from": "gpt",
"value": "机器学习是人工智能的一个分支,它允许计算机系统通过数据和经验自动改进其性能。"
},
{
"from": "human",
"value": "它主要有哪些类型?"
},
{
"from": "gpt",
"value": "主要类型包括监督学习、无监督学习、半监督学习和强化学习等。"
}
]
}
2)OpenAI 格式
OpenAI 格式是 OpenAI 官方在其 API 微调功能中推广的一种通用消息列表格式,兼具灵活性与表达力,可同时支持单轮和多轮对话。
每个训练样本是一个包含 messages 字段的字典,其中 messages 是一个有序列表,每条消息包含以下字段:
role:发言者角色,常见值包括:system、user和assistant。
content:消息的具体文本内容。
如:
{
"messages": [
{
"role": "system",
"content": "你是一名专业的营养师。你的回答应基于科学知识,提供务实、健康的建议,并避免提供任何医疗诊断。"
},
{
"role": "user",
"content": "我最近感觉下午很疲惫,有什么健康的零食推荐吗?"
},
{
"role": "assistant",
"content": "下午感到疲惫是常见的现象,选择正确的零食可以帮助稳定能量水平。以下是一些推荐:\n1. **一把坚果和干果**:提供健康的脂肪、蛋白质和天然糖分,能快速补充能量。\n2. **希腊酸奶**:富含蛋白质,能提供持久的饱腹感。\n3. **一个苹果或一根香蕉**:富含维生素和膳食纤维,是方便的天然能量来源。\n请记得结合充足的水分摄入,因为脱水也会导致疲劳。"
}
]
}3.3 微调训练 (Fine-tuning Training)
训练阶段是模型更新权重参数、内化下游任务特征的计算密集型阶段。
-
计算原理: 将训练集输入模型计算前向传播,对比输出与目标答案的损失(Loss),通过反向传播算法更新矩阵参数。
-
工程优化策略: 针对大模型显存占用高、训练成本昂贵的痛点,业界分化出不同的策略:
-
全参数微调 (Full Fine-tuning): 更新模型所有权重。能力提升最彻底,但算力成本最高,且易引发"灾难性遗忘(Catastrophic Forgetting)"。
-
LoRA / QLoRA (参数高效微调): 冻结原模型参数,通过引入低秩分解矩阵(Low-Rank Adaptation)进行增量训练。QLoRA 进一步引入 4-bit 量化。这是当前工业界兼顾显存性价比与模型性能的主流方案。
-
3.4 模型验证 (Model Validation)
模型验证是防止模型过拟合(Overfitting)、评估商用可用性的最后闭环。
-
多维评估指标: *量化指标: 监控训练集与验证集的损失收敛曲线(Loss Curve)。
-
标准基准: 在验证集上运行自动化评测指标(如 ROUGE、BLEU,或特定分类的 Accuracy)。
-
人类/大模型评测: 运行典型盲测样例(Golden Test Cases),通过人工或高阶模型(如 GPT-4)扮演裁判(LLM-as-a-Judge)对输出质量、格式、拒绝回复边界进行综合泛化评估。
-
总结:
微调工程是一个典型的"试错迭代(Trial and Error)"流程。在工程落地时,应秉持"先小后大、数据先行"的原则:首先选用 7B/8B 级别的 Instruct 模型作为 Baseline 基线,将核心精力投入在构建高纯度、无噪声的训练数据集上;在训练方式上优先选用 LoRA/QLoRA 快速验证;最后通过模型验证的反馈,逆向指导数据的迭代优化或模型规模的扩容。
4. 微调方法选择
在现代大语言模型(LLM)的监督微调(SFT)工程中,微调方法的选型直接决定了算力资源的消耗上限与下游任务的性能表现。根据是否更新全局参数 ,微调技术路线清晰地分化为全参数微调(Full Fine-tuning)与参数高效微调(PEFT)两大范式。
4.1 全参数微调 vs 参数高效微调(PEFT)
1. 全参数微调 (Full Fine-tuning)
-
核心机制: 在反向传播中释放全部网络层,对模型内部所有的权重矩阵进行梯度更新。
-
技术痛点: 显存与算力开销极度高昂。由于需要存储模型权重、激活值(Activations)以及数倍于权重体积的优化器状态(Optimizer States,如 Adam 的一阶/二阶动量),单卡通常无法承载,强依赖于 ZeRO、Tensor Parallelism 等复杂的分布式训练并行策略。
-
适用场景: 资源极度充裕、对长尾复杂任务有极致性能追求、且拥有百万级海量高质标注数据的严肃工业场景。
2. 参数高效微调 (PEFT)
-
核心机制: 冻结原始预训练模型的大部分或全部参数,仅通过更新极少量的自定义可训练模块(或新增外部参数),实现下游任务的适配。
-
历史演进: 自 2019 年(BERT/GPT-2 时代)起,历经了 Prompt Tuning、Prefix Tuning、P-Tuning、Adapter 等阶段。目前,LoRA 及其变体已成为绝对的工业界事实标准,其余技术路线在通用性与稳定性上已被逐步边缘化。
4.2 主流 PEFT 技术核心机理深度拆解
1. LoRA(低秩适应,Low-Rank Adaptation)
-
提出背景与核心假设: 微软研究院(2021年)发现,大模型在过渡到下游任务时,其内在权重更新矩阵 △W 具有极低的"内在秩(Intrinsic Rank)",即其有效自由度远低于矩阵表面维度。
-
数学机理: 设原始预训练冻结矩阵为 W_0 \\in \\mathbb{R}\^{d \\times k},LoRA 将需要学习的完整增量矩阵 △W 近似分解为两个低秩矩阵 A 和 B 的乘积:
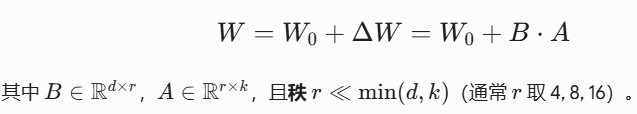
-
工程优势:
-
训练期轻量化: 完美冻结 W_0,仅对 A(高斯初始化)和 B(零初始化) 进行梯度更新。参数量通常可压缩至原始权重的 0.4% 左右。
-
推理期零开销(参数重参数化): 在部署阶段,可通过矩阵加法直接将 B \\cdot A 的乘积无缝熔断/合并(Merge)回原始权重 W_0 中,不引入任何额外的推理时延与计算复杂度。支持针对不同下游任务切换不同的轻量适配器(Adapters)。
-
2. QLoRA(量化低秩适应)
-
提出背景: 华盛顿大学(2023年)提出,旨在将大模型微调的硬件门槛彻底下放至消费级 GPU(如单张 RTX 3090/4090)。
-
三大核心技术组件(显存极致压缩):
(1)4-bit NormalFloat(NF4)量化
针对大模型权重在统计上近似服从标准正态分布 的特点,放弃了传统的等距均匀量化(Absmax Quantization),发明了 NF4 数据类型。它通过分位数近似,将标准正态分布转化为 16 个等概率区间的非均匀格点(0附近密集,两端稀疏)。在 4-bit 极低精度下,实现了相比于传统 INT4 显著更低的量化信息失真。
(2)双重量化(Double Quantization, DQ)
在常规量化中,每 64 个权重引入一个 32-bit 的常数缩放因子(Quantization Constants)。为了压榨这部分辅助显存,QLoRA 对缩放因子本身实施了二次量化:将缩放因子以 256 个为一组,采用 8-bit FP 再次压缩,使量化因子带来的显存开销从人均 0.5 bit/weight 骤降至 0.127 bit/weight。
(3)分页优化器(Paged Optimizers)
针对 Adam 优化器状态引发的显存偶发性峰值(OOM 隐患),利用了类似操作系统虚拟内存的页表技术(依托 CUDA Unified Memory)。将优化器状态切分为小块(Pages),非激活层对应的优化器状态被动态换出(Evict)至系统内存(RAM)中,仅在当前层发生反向传播梯度更新时,才按需换入(Fetch)显存。彻底平滑了训练期间的显存尖峰,保障了低显存环境下的极限训练稳定性。
4.3 微调方法多维度矩阵横向对比
| 评估维度 | 全参数微调 (Full FT) | LoRA | QLoRA |
|---|---|---|---|
| 可训练参数量 | 100% | ~0.4% \\sim 1% | ~0.4% \\sim 1% |
| 基本数据精度 | FP16 / BF16 | FP16 / BF16 | 4-bit NF4 (基座解压后计算) |
| 推理额外时延 | 0 | 0 (支持矩阵无缝合并) | 0 (若推理前合并且反量化) |
| 优化器状态显存 | 极高 (2-3倍模型体积) | 极低 (仅针对低秩矩阵) | 极致低 (LoRA参数量 + 分页置换机制) |
| 单卡 24G 适配极限 | 无法运行 7B 级别模型 | 可微调 7B 级别模型 | 可稳定微调 13B/33B/70B 级别模型 |
| 硬件设备要求 | 多卡 A100 / H100 集群 | 企业级单卡/双卡 (如 A10) | 消费级显卡 (如 RTX 3090/4090) |
| 综合任务性能 | 理论上限最高 (最优) | 几乎无损 (持平全参数) | 极其微弱的精度损失 (基本持平全参数) |
4.4 工业级工程选型策略
-
预算与硬件本位制:
-
若拥有集群算力(A100/H100 级别),且追求极致的任务精度,或涉及底层语言、代码等极其硬核的领域能力迁移,评估采用全参数微调。
-
若处于标准企业云端环境,推荐以 LoRA 作为首选黄金 Baseline。
-
若受限于预算,需在消费级 GPU 或边缘工作站上做技术验证,无脑选择 QLoRA。
-
-
多任务并行部署视角:
-
如果线上业务需要同时承载"客服、摘要、分类、续写"等多个异构子任务,全参数微调意味着需要部署多个庞大的独立模型(高昂的冷启动与显存开销)。
-
采用 LoRA/QLoRA 方案,线上只需常驻一个冻结的通用基座模型(Base Model),针对不同任务通过动态挂载/卸载几兆大小的 LoRA Adapter 权重包,即可完美实现低成本、高并发的多任务动态路由切换。
-
5. 微调实操
LLaMA Factory 是一个简单易用且高效的大型语言模型(Large Language Model)训练与微调平台。通过 LLaMA Factory,可以在无需编写任何代码的前提下,在本地完成上百种预训练模型的微调
5.2 安装LLaMA-Factory
源码下载:
使用git下载:
git clone https://github.com/hiyouga/LLaMA-Factory.git
autodl内置代理加速:AutoDL帮助文档
配置代理加速:
source /etc/network_turbo
取消代理加速:
unset http_proxy && unset https_proxy
依赖安装:
使用UV,创建一个python 3.12环境:
uv venv --python 3.12
激活环境:
source .venv/bin/activate
安装依赖:
uv pip install -e . -i https://pypi.tuna.tsinghua.edu.cn/simple
验证安装成功:
llamafactory-cli version
5.2 启动LLaMA-Factory
启动webui:
llamafactory-cli webui
不占用前台的方式启动:
nohup llamafactory-cli webui >llama_factory.log 2>&1 &
看到"Running on local URL: http://0.0.0.0:7860"即启动成功。
如果使用autodl服务器启动,本地电脑访问需开启SSH隧道,在本地电脑执行:
ssh -CNg -L 7860:127.0.0.1:7860 root@connect.nmb2.seetacloud.com -p 16652
也可以使用AutoDL提供的图形化界面工具配置代理隧道
5.3 准备模型
在使用LLaMA-Factory进行微调时,可以通过LLaMA-Factory在训练时下载模型,也可以提前将模型下载好之后,配置本地路径,直接使用本地的模型。
通过ModelScope下载Qwen3-0.6B模型至model/Qwen3-0.6B路径下,命令如下:
modelscope download --model Qwen/Qwen3-0.6B --local_dir model/Qwen3-0.6B
5.4 准备数据集
LLaMA-Factory目前支持 Alpaca 格式和 ShareGPT 格式的数据集。我们自己整理好格式的数据需要添加到数据集信息中。
处理数据格式:
数据上传至LLaMa-Factory目录中。
在LLaMa-Factory目录下,使用以下脚本,将数据整理成LLaMa-Factory所需要的格式,并保存至data/keywords_data_sharegpt.jsonl中。
python
from datasets import load_dataset
def convert_to_qwen_format(examples):
conversations = []
# 遍历每个对话样本,注意开启batch时,会自动套一层list
for conv_list in examples["conversation"]:
# 重建符合Qwen3标准的消息结构
for conv in conv_list:
conversations.append([
{"role": "user", "content": conv['human'].strip()},
{"role": "assistant", "content": conv['assistant'].strip()}
])
return {"messages": conversations}
if __name__ == '__main__':
dataset = load_dataset("json", data_files="data/keywords_data_train.jsonl", split="train")
# 格式化数据为 Chatgpt 格式
dataset = dataset.map(
convert_to_qwen_format,
batched=True,
remove_columns=dataset.column_names
)
dataset.to_json("data/keywords_data_sharegpt.jsonl",force_ascii=False)添加数据集:
修改dataset_info.json文件,添加数据集信息
python
"keywords_extract": {
"file_name": "keywords_data_sharegpt.jsonl",
"formatting": "sharegpt",
"columns": {
"messages": "messages"
},
"tags": {
"role_tag": "role",
"content_tag": "content",
"user_tag": "user",
"assistant_tag": "assistant"
}
},在web ui上就可以看到数据集,选中后,可以在页面预览数据。
5.5 使用LoRA进行微调:
配置模型&使用LoRA:
配置前面已经下载好的模型,模型名称选择Custom,模型路径配置本地路径即可:
在微调方法栏,配置使用lora,即可启用LoRA微调
配置训练轮数和最大样本数:
配置训练总轮数以及每个数据集最多使用的样本数。
在不设置最大样本数时,每个 epoch 会遍历完整训练集,因此理论训练样本量约为训练集样本数 × 训练轮数。
在设置最大样本数后,训练前会先将可用训练样本限制到该数量以内,因此理论训练样本量约为 min(训练集样本数, 最大样本数) × 训练轮数。

配置保存位置
设置输出目录,后续训练过程中的检查点以及其他相关数据,都会保存至该目录当中去。
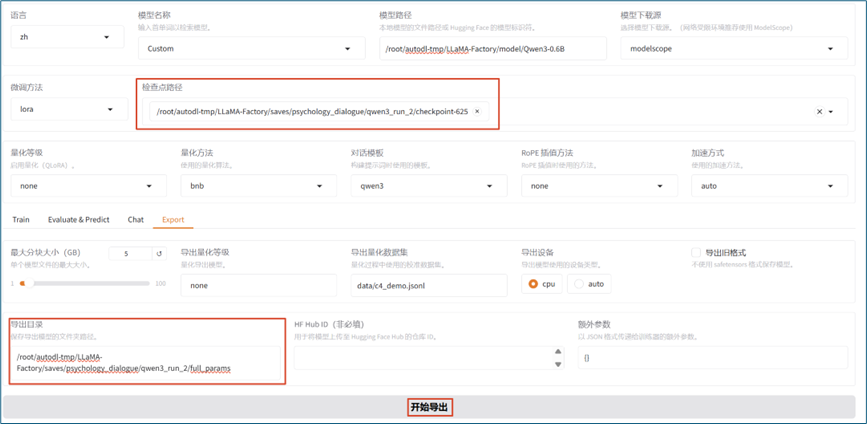
5.6 模型权重导出
通过LLaMA-Factory,可将训练好后得到的LoRA适配器参数和基座模型参数进行合并导出:
其他参考:炼石成丹:大语言模型微调实战系列(二)模型微调篇 | 亚马逊AWS官方博客