SHAP值的解读
对于信贷问题,我们除了希望知道是否存在风险,还希望知道每个特征贡献了多少,比如年收入+0.15,收入高,加分;负债率-0.30负债太高,减分;工作年限+0.05工作稳定,小加分;信用评分-0.25 信用不好,减分;年龄+0.02影响很小,把模型的决策分解到每个特征上
到这里你可能心想,这样是不是很类似于线性回归的特征前的系数 y=ax1+bx2+cx3,那既然如此,我直接选择用线性回归的系数作解释,那岂不是更好?
线性回归的系数:y=0.15x收入 +(-0.30)x负债率 +0.05x工作年限 +(-0.25)x信用评分+0.02x年龄
- 系数是固定的:不管是谁,"收入"的系数永远是 0.15
- 全局解释:一个系数解释所有样本
- 简单,但假设特征和目标是线性关系
比如线性回归会说收入每增加1万,贡献固定增加 x。但现实中:收入从 5万→30万,影响很大,收入从 100 万→500 万,影响就没那么大了(边际效应递减),SHAP能捕捉这种非线性关系
核心差异就在于SHAP值是因人而异的:张三的"收入"贡献可能是+0.15,李四的可能是+0.08
- 局部解释:每个样本有自己的一组SHAP值
- 复杂,但能捕捉非线性关系,同一个特征,不同样本贡献不同
这种非线性如何呈现:
- 特征本身的非线性关系:比如边际效应
- 特征之间存在交互效应:男性(性别)+年龄(25)发生质变
Shapley 值的核心就是当特征之间有交互作用时,如何公平地把"功劳"分给每个特征
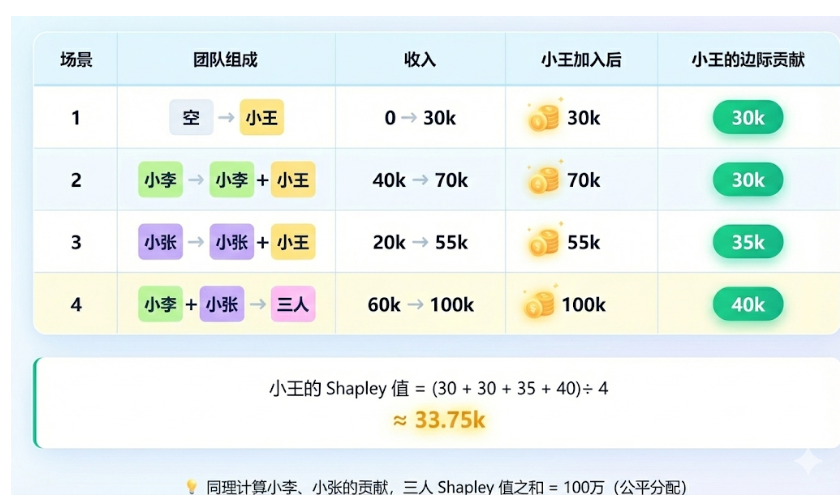
SHAP 的原理来自博弈论,但我们用一个更简单的例子来理解:想象三个人合伙开了一家奶茶店,年底赚了 100 万。问题来了:这 100 万怎么分?
小王负责研发配方、小李负责营销推广、小张负责店面运营
直接三等分?不公平!因为每个人的贡献不一样。经济学家 Shapley 提出了一个方法:
数学家 做了数学假设:
博弈论基础上有4条规则,满足这4个客观规则的只有 shap 值,很自洽
一般来说基准值不是-500 +500
100 个样本,对这个样本的预测取平均(训练)=基准值
shap 值 本质上是解释模型在训练集学习的东西 加入什么都没学 直接取平均 最好的
SHAP 在机器学习中的应用
开店=机器学习
合伙人 = 特征
总收入 = 预测值 - 基准值
每人贡献 = 每个特征的 SHAP 值
基准值(Base Value):模型在所有样本上的平均预测值
三人合伙前,收入是 0,三人合伙后,收入是 100万,要分配的"蛋糕"就是 100万-0=100 万
基准值 = 没有任何特征信息时的"默认"预测(相当于"0"的起点),这个值一般就是平均值,把训练集的所有样本都输入模型,得到所有预测值取平均值,在没有关于这个特定样本的区分性信息时,最合理的猜测就是平均值
预测值 = 加入所有特征后的预测(相当于"100 万"的终点)
要分配的"蛋糕"=预测值 -基准值
核心公式:
模型预测值 = 基准值+SHAP(特征 1)+SHAP(特征 2)+..+SHAP(特征 N)
SHAP 值加起来 =预测值与基准值的差!
那么如何实现 shaply 值动态变化呢?上面说的是平均这一家店是一个样本,对于多家店每个店都是样本,所以特征贡献不同那么对于一个样本,如果控制变量计算特征贡献呢?真实在做的时候肯定是没法实现控制其他特征不动,检测单个特征的贡献,其实还是多样本比对了,shap 值本质上也是一个近似值。
虽然不完美,但 SHAP 是目前理论最完善、应用最广泛的解释方法
SHAP 值的计算用训练还是测试集?
先说结论,两者均可,但是为了图好看一般都是选择训练集。
- 做机器学习的专业大多都是交叉学科,本身你的研究多是针对私有数据集,别人不会关注你的泛化性。所以不必因为这个纠结。
- shap 值是每个样本的每个特征都会得到对应类别的值,所以如果你的数据量本身就不大,用训练集来绘制,点多会让图美观很多,或者也可以对测试集插值也可以起到一样的效果
- 补充一个 shap图美观的小技巧,可以绘制出每一个类别 shap 曲线的置信区间,因为机器学习多是点估计,而区间估计会让你的结果更加具有信服力,利用bootstrap 重采样思想可以绘制出置信区间,自己写一下 shap 图函数,不用借助 shap 库的接口。
python
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import load_diabetes
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score, mean_absolute_error
import warnings
warnings.filterwarnings('ignore')
# --- 1. 全局设置 ---
plt.rcParams['font.sans-serif'] = ['SimHei'] # 中文字体
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号
sns.set(style="whitegrid", font='SimHei')
# ==========================================
# 2. 加载糖尿病数据集
# ==========================================
print("正在加载糖尿病数据集...")
# 加载数据
diabetes = load_diabetes()
X, y = diabetes.data, diabetes.target
# 转换为DataFrame以便更好地显示
df = pd.DataFrame(X, columns=diabetes.feature_names)
df['target'] = y
print("="*30 + " 数据集概览 " + "="*30)
print(f"数据形状: {df.shape}")
print(f"特征数量: {len(diabetes.feature_names)}")
print(f"目标变量: 一年后疾病进展的定量测量")
print("\n特征说明:")
for i, (name, desc) in enumerate(zip(diabetes.feature_names, diabetes.DESCR.split('\n')[10:20])):
print(f"{i+1:2d}. {name:15s} - {desc.strip()}")
print("\n前5行数据:")
print(df.head())
# ==========================================
# 3. 数据探索性分析
# ==========================================
print("\n" + "="*30 + " 数据探索分析 " + "="*30)
# 创建可视化
fig, axes = plt.subplots(2, 3, figsize=(15, 10))
axes = axes.flatten()
# 1. 目标变量分布
axes[0].hist(y, bins=30, color='skyblue', edgecolor='black', alpha=0.7)
axes[0].set_title('目标变量分布', fontsize=12, fontweight='bold')
axes[0].set_xlabel('疾病进展')
axes[0].set_ylabel('频数')
axes[0].grid(True, alpha=0.3)
# 2. 特征相关性热图
corr_matrix = df.corr()
sns.heatmap(corr_matrix, annot=False, cmap='coolwarm', center=0,
ax=axes[1], cbar_kws={'shrink': 0.8})
axes[1].set_title('特征相关性热图', fontsize=12, fontweight='bold')
# 3. 目标变量与重要特征的关系
important_features = ['bmi', 's5', 'bp', 's3']
for i, feature in enumerate(important_features[:3]):
axes[i+2].scatter(df[feature], y, alpha=0.5, s=20)
axes[i+2].set_title(f'目标 vs {feature}', fontsize=12)
axes[i+2].set_xlabel(feature)
axes[i+2].set_ylabel('疾病进展')
axes[i+2].grid(True, alpha=0.3)
plt.suptitle('糖尿病数据集探索性分析', fontsize=14, fontweight='bold', y=1.02)
plt.tight_layout()
plt.show()
# 数据统计
print("\n数据统计信息:")
print(df.describe().round(3))
# ==========================================
# 4. 训练随机森林模型
# ==========================================
print("\n" + "="*30 + " 模型训练 " + "="*30)
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
print(f"训练集形状: {X_train.shape}")
print(f"测试集形状: {X_test.shape}")
# 训练随机森林模型
rf_model = RandomForestRegressor(
n_estimators=100,
max_depth=10,
random_state=42,
n_jobs=-1
)
rf_model.fit(X_train, y_train)
y_pred = rf_model.predict(X_test)
# 评估模型
mse = mean_squared_error(y_test, y_pred)
rmse = np.sqrt(mse)
mae = mean_absolute_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print("\n模型性能评估:")
print(f"均方误差 (MSE): {mse:.3f}")
print(f"均方根误差 (RMSE): {rmse:.3f}")
print(f"平均绝对误差 (MAE): {mae:.3f}")
print(f"决定系数 (R²): {r2:.3f}")
# 预测结果可视化
plt.figure(figsize=(8, 6))
plt.scatter(y_test, y_pred, alpha=0.5, color='blue')
plt.plot([y.min(), y.max()], [y.min(), y.max()], 'r--', lw=2)
plt.xlabel('真实值')
plt.ylabel('预测值')
plt.title('随机森林模型预测结果', fontsize=14, fontweight='bold')
plt.grid(True, alpha=0.3)
plt.show()
# ==========================================
# 5. SHAP可解释性分析
# ==========================================
print("\n" + "="*30 + " SHAP可解释性分析 " + "="*30)
# 安装shap库(如果未安装)
try:
import shap
print("SHAP库已安装,开始分析...")
except ImportError:
print("正在安装SHAP库...")
import subprocess
import sys
subprocess.check_call([sys.executable, "-m", "pip", "install", "shap"])
import shap
# 初始化SHAP解释器
explainer = shap.TreeExplainer(rf_model)
shap_values = explainer.shap_values(X_test)
# 转换为DataFrame以便更好地处理
shap_df = pd.DataFrame(shap_values, columns=diabetes.feature_names)
print("\nSHAP分析完成!")
print(f"SHAP值形状: {shap_df.shape}")
# ==========================================
# 6. SHAP可视化分析
# ==========================================
print("\n" + "="*30 + " SHAP可视化分析 " + "="*30)
# 创建可视化图表
fig, axes = plt.subplots(2, 2, figsize=(16, 12))
# 1. 特征重要性总结图
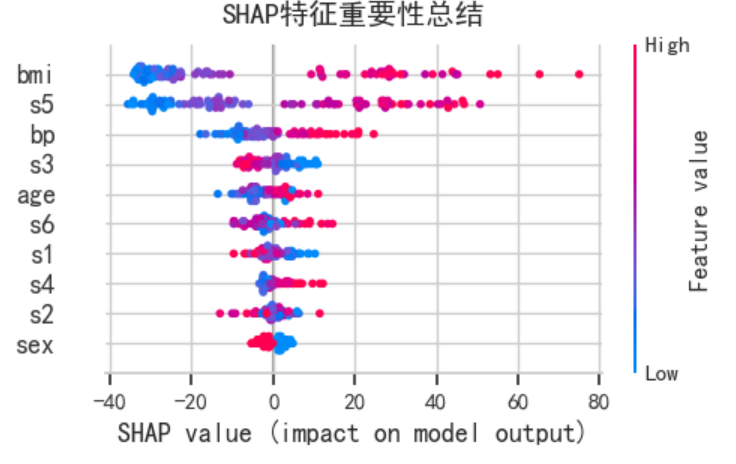
shap.summary_plot(shap_values, X_test, feature_names=diabetes.feature_names,
show=False, plot_size=None, max_display=10)
plt.title('SHAP特征重要性总结', fontsize=14, fontweight='bold', y=1.02)
fig1 = plt.gcf()
fig1.set_size_inches(10, 6)
plt.tight_layout()
plt.show()
# 2. 特征重要性条形图
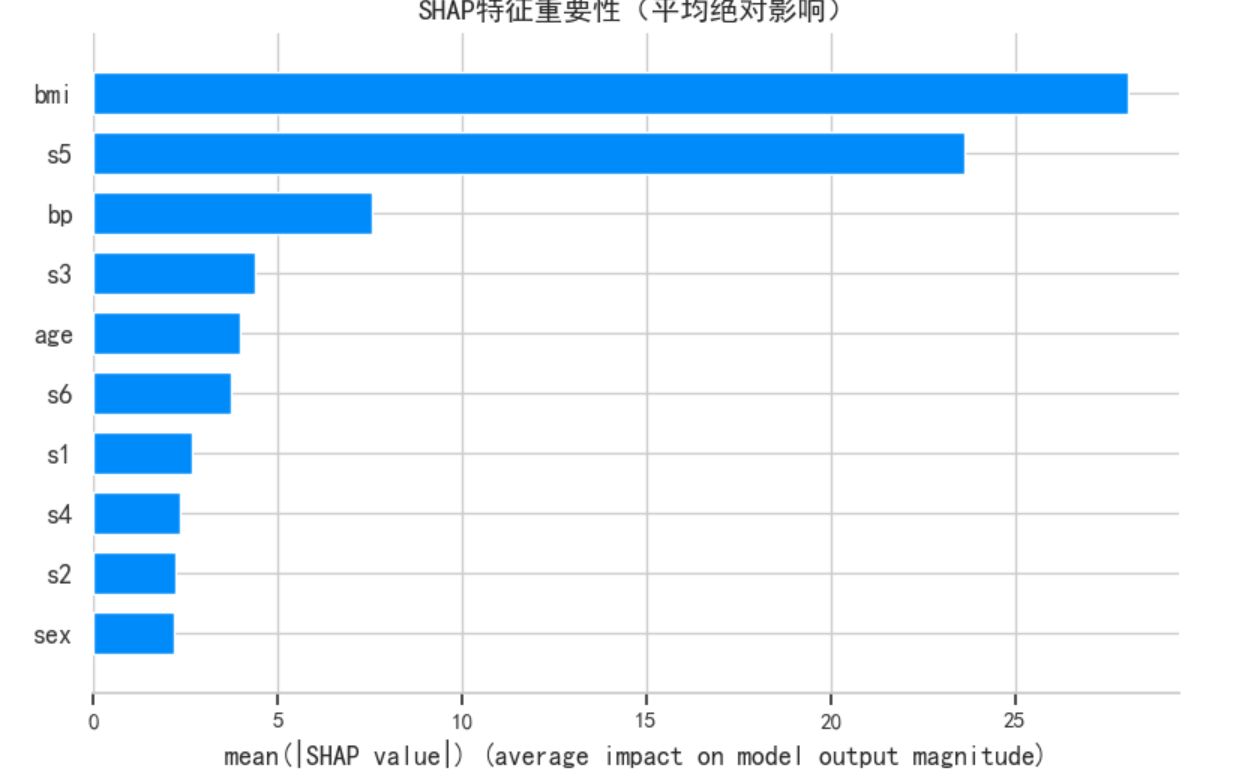
plt.figure(figsize=(10, 6))
shap.summary_plot(shap_values, X_test, feature_names=diabetes.feature_names,
plot_type="bar", show=False, max_display=10)
plt.title('SHAP特征重要性(平均绝对影响)', fontsize=14, fontweight='bold')
plt.tight_layout()
plt.show()
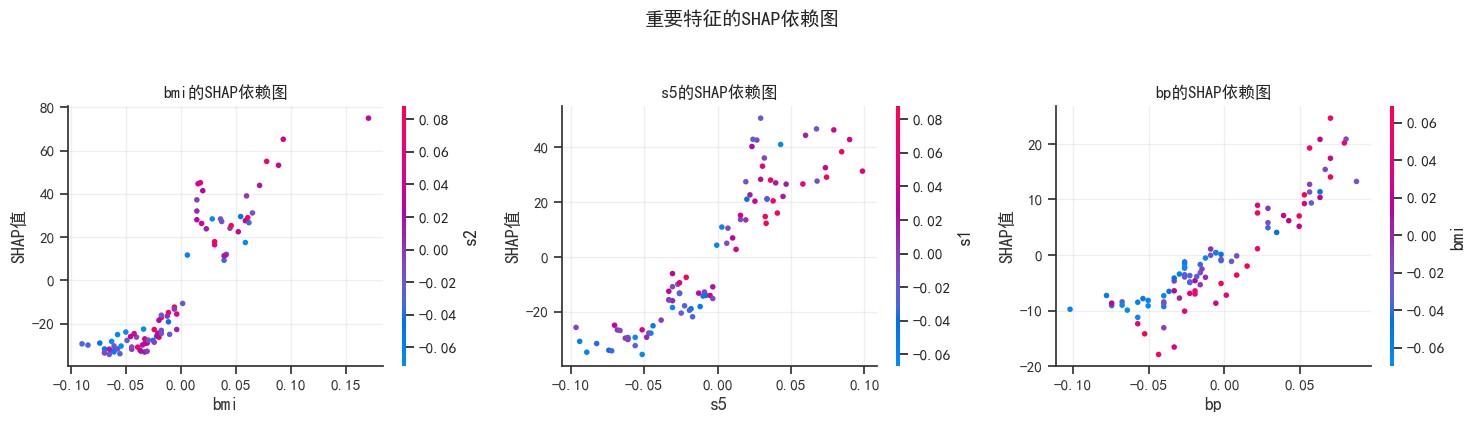
# 3. 单个特征的SHAP依赖图(选择最重要的3个特征)
important_indices = np.argsort(np.abs(shap_values).mean(0))[-3:][::-1]
important_features = [diabetes.feature_names[i] for i in important_indices]
print(f"\n最重要的3个特征:")
for i, feature in enumerate(important_features, 1):
shap_mean_abs = np.abs(shap_df[feature]).mean()
print(f"{i}. {feature}: 平均绝对SHAP值 = {shap_mean_abs:.3f}")
fig, axes = plt.subplots(1, 3, figsize=(15, 4))
for idx, (ax, feature) in enumerate(zip(axes, important_features)):
feature_idx = list(diabetes.feature_names).index(feature)
# 使用shap的partial_dependence_plot
shap.dependence_plot(
feature_idx, shap_values, X_test,
feature_names=diabetes.feature_names,
ax=ax, show=False
)
ax.set_title(f'{feature}的SHAP依赖图', fontsize=12, fontweight='bold')
ax.set_xlabel(feature)
ax.set_ylabel('SHAP值')
ax.grid(True, alpha=0.3)
plt.suptitle('重要特征的SHAP依赖图', fontsize=14, fontweight='bold', y=1.05)
plt.tight_layout()
plt.show()
# 4. 单个样本的SHAP解释(选择3个样本)
print("\n" + "="*30 + " 单样本解释 " + "="*30)
# 选择3个有代表性的样本
sample_indices = [0, 50, 100] # 可以根据需要调整
fig, axes = plt.subplots(1, 3, figsize=(15, 5))
for i, (ax, sample_idx) in enumerate(zip(axes, sample_indices)):
# 创建force plot(瀑布图)
shap.force_plot(
explainer.expected_value,
shap_values[sample_idx, :],
X_test[sample_idx, :],
feature_names=diabetes.feature_names,
matplotlib=True,
show=False,
text_rotation=30
)
# 获取当前图形
temp_fig = plt.gcf()
# 手动设置标题和标签
ax.set_title(f'样本 {sample_idx} 的SHAP解释', fontsize=12, fontweight='bold')
ax.set_xlabel('特征')
ax.set_ylabel('SHAP贡献')
# 清理并显示
plt.close(temp_fig)
plt.suptitle('单个样本的SHAP解释(Force Plot)', fontsize=14, fontweight='bold', y=1.05)
plt.tight_layout()
plt.show()
# 显示样本的具体数值
for i, sample_idx in enumerate(sample_indices):
print(f"\n样本 {sample_idx} 详情:")
print(f"真实值: {y_test[sample_idx]:.2f}")
print(f"预测值: {y_pred[sample_idx]:.2f}")
print(f"预测偏差: {y_pred[sample_idx] - y_test[sample_idx]:.2f}")
# 显示特征值和SHAP值
sample_shap = shap_values[sample_idx, :]
important_features_idx = np.argsort(np.abs(sample_shap))[-5:][::-1]
print("最重要的5个特征贡献:")
for j, feat_idx in enumerate(important_features_idx):
feat_name = diabetes.feature_names[feat_idx]
feat_value = X_test[sample_idx, feat_idx]
shap_value = sample_shap[feat_idx]
print(f" {feat_name:10s}: 值={feat_value:6.3f}, SHAP={shap_value:7.3f}")
# 5. 特征交互分析
print("\n" + "="*30 + " 特征交互分析 " + "="*30)
# 寻找最重要的交互特征
interaction_feature = 'bmi' # 选择一个重要特征
feature_idx = list(diabetes.feature_names).index(interaction_feature)
plt.figure(figsize=(10, 6))
shap.dependence_plot(
feature_idx, shap_values, X_test,
feature_names=diabetes.feature_names,
interaction_index='auto', # 自动检测交互特征
show=False
)
plt.title(f'{interaction_feature}的特征交互分析', fontsize=14, fontweight='bold')
plt.xlabel(interaction_feature)
plt.ylabel('SHAP值')
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
# ==========================================
# 7. 与传统特征重要性对比
# ==========================================
print("\n" + "="*30 + " 特征重要性对比 " + "="*30)
# 传统特征重要性(基于基尼不纯度)
traditional_importance = pd.DataFrame({
'特征': diabetes.feature_names,
'传统重要性': rf_model.feature_importances_
}).sort_values('传统重要性', ascending=False)
# SHAP特征重要性(基于平均绝对SHAP值)
shap_importance = pd.DataFrame({
'特征': diabetes.feature_names,
'SHAP重要性': np.abs(shap_values).mean(0)
}).sort_values('SHAP重要性', ascending=False)
print("\n传统特征重要性(基尼不纯度):")
print(traditional_importance.head(10))
print("\nSHAP特征重要性(平均绝对SHAP值):")
print(shap_importance.head(10))
# 可视化对比
fig, axes = plt.subplots(1, 2, figsize=(14, 6))
# 传统特征重要性
axes[0].barh(range(10), traditional_importance['传统重要性'].head(10)[::-1],
color='skyblue', alpha=0.7)
axes[0].set_yticks(range(10))
axes[0].set_yticklabels(traditional_importance['特征'].head(10)[::-1])
axes[0].set_xlabel('重要性得分')
axes[0].set_title('传统特征重要性', fontsize=12, fontweight='bold')
axes[0].grid(True, alpha=0.3, axis='x')
# SHAP特征重要性
axes[1].barh(range(10), shap_importance['SHAP重要性'].head(10)[::-1],
color='lightcoral', alpha=0.7)
axes[1].set_yticks(range(10))
axes[1].set_yticklabels(shap_importance['特征'].head(10)[::-1])
axes[1].set_xlabel('平均绝对SHAP值')
axes[1].set_title('SHAP特征重要性', fontsize=12, fontweight='bold')
axes[1].grid(True, alpha=0.3, axis='x')
plt.suptitle('特征重要性方法对比', fontsize=14, fontweight='bold', y=1.02)
plt.tight_layout()
plt.show()
# ==========================================
# 8. 模型对比分析
# ==========================================
print("\n" + "="*30 + " 模型对比分析 " + "="*30)
# 训练线性回归模型进行对比
lr_model = LinearRegression()
lr_model.fit(X_train, y_train)
y_pred_lr = lr_model.predict(X_test)
# 计算线性回归的SHAP值(使用KernelExplainer)
lr_explainer = shap.KernelExplainer(lr_model.predict, X_train[:100]) # 使用子集提高速度
lr_shap_values = lr_explainer.shap_values(X_test[:100]) # 使用子集
print("\n模型性能对比:")
print(f"随机森林 R²: {r2_score(y_test, y_pred):.3f}")
print(f"线性回归 R²: {r2_score(y_test[:100], y_pred_lr[:100]):.3f}")
# 对比特征重要性
if lr_shap_values is not None:
lr_shap_importance = pd.DataFrame({
'特征': diabetes.feature_names,
'线性回归SHAP': np.abs(lr_shap_values).mean(0)
}).sort_values('线性回归SHAP', ascending=False)
print("\n线性回归SHAP重要性:")
print(lr_shap_importance.head(10))
# ==========================================
# 9. 总结报告
# ==========================================
print("\n" + "="*30 + " SHAP分析总结 " + "="*30)
print("\n关键发现:")
print("1. 最重要的预测特征:")
for i, row in shap_importance.head(3).iterrows():
print(f" {row['特征']}: 平均绝对SHAP值 = {row['SHAP重要性']:.3f}")
print("\n2. 模型解释性:")
print(" • SHAP提供了局部和全局的解释")
print(" • 可以理解每个特征对单个预测的贡献")
print(" • 揭示了特征之间的相互作用")
print("\n3. 临床应用建议:")
print(" • 重点关注BMI、s5和血压等关键指标")
print(" • 这些特征对疾病进展预测有最大影响")
print(" • 可以为个性化医疗提供数据支持")
print("\n4. 技术要点:")
print(" • 随机森林模型表现良好 (R² = {:.3f})".format(r2))
print(" • SHAP分析揭示了特征的非线性关系")
print(" • 与传统特征重要性方法相比,SHAP更准确")
# 保存结果
results = {
'模型性能': {
'R2': r2,
'RMSE': rmse,
'MAE': mae
},
'特征重要性': shap_importance.to_dict('records')[:5]
}
import json
with open('diabetes_shap_results.json', 'w', encoding='utf-8') as f:
json.dump(results, f, ensure_ascii=False, indent=2)
print(f"\n分析结果已保存到: diabetes_shap_results.json")
print("\n" + "="*30 + " 分析完成 " + "="*30)