文章目录
- 第01章:LangChain使用概述
-
- [1、介绍 LangChain](#1、介绍 LangChain)
-
- [1.1 什么是 LangChain](#1.1 什么是 LangChain)
- [1.2 有哪些大模型应用开发框架呢?](#1.2 有哪些大模型应用开发框架呢?)
- [1.3 为什么需要 LangChain?](#1.3 为什么需要 LangChain?)
- [1.4 LangChain的使用场景](#1.4 LangChain的使用场景)
- [1.5 LangChain资料介绍](#1.5 LangChain资料介绍)
- [1.6 架构设计](#1.6 架构设计)
- 2、开发前的准备工作
-
- [2.1 前置知识](#2.1 前置知识)
- [2.2 相关环境安装](#2.2 相关环境安装)
- 3、大模型应用开发
-
- [3.1 基于RAG架构的开发](#3.1 基于RAG架构的开发)
- [3.2 基于Agent架构的开发](#3.2 基于Agent架构的开发)
- [3.3 大模型应用开发的4个场景](#3.3 大模型应用开发的4个场景)
- 4、LangChain的核心组件
-
- [4.1 一个问题引发的思考](#4.1 一个问题引发的思考)
- [4.2 核心组件的概述](#4.2 核心组件的概述)
- [4.3 核心组件的说明](#4.3 核心组件的说明)
-
- [**核心组件1:Model I/O**](#核心组件1:Model I/O)
- **核心组件2:Chains**
- **核心组件3:Memory**
- **核心组件4:Agents**
- **核心组件5:Retrieval**
- **核心组件6:Callbacks**
- [4.4 小结](#4.4 小结)
- 5、LangChain的helloworld
-
- [5.1 获取大模型](#5.1 获取大模型)
- [5.2 使用提示词模板](#5.2 使用提示词模板)
- [5.3 使用输出解析器](#5.3 使用输出解析器)
- [5.4 使用向量存储](#5.4 使用向量存储)
- [5.5 RAG(检索增强生成)](#5.5 RAG(检索增强生成))
- [5.6 使用Agent](#5.6 使用Agent)
- [第02章:LangChain使用之Model I/O](#第02章:LangChain使用之Model I/O)
-
- [1、Model I/O介绍](#1、Model I/O介绍)
- [2、Model I/O之调用模型1](#2、Model I/O之调用模型1)
-
- [2.1 模型的不同分类方式](#2.1 模型的不同分类方式)
- [2.2 角度1出发:按照功能不同举例](#2.2 角度1出发:按照功能不同举例)
-
- 类型1:LLMs (非对话模型)
- [类型2:Chat Models (对话模型)](#类型2:Chat Models (对话模型))
- [类型3:Embedding Model (嵌入模型)](#类型3:Embedding Model (嵌入模型))
- [2.3 角度2出发:参数位置不同举例](#2.3 角度2出发:参数位置不同举例)
-
- [2.3.1 模型调用的主要方法及参数](#2.3.1 模型调用的主要方法及参数)
- [2.3.2 模型调用推荐平台:closeai](#2.3.2 模型调用推荐平台:closeai)
- [2.3.3 方式1:硬编码](#2.3.3 方式1:硬编码)
- [2.3.4 方式2:配置环境变量](#2.3.4 方式2:配置环境变量)
- [2.3.5 方式3:使用.env配置文件 (推荐)](#2.3.5 方式3:使用.env配置文件 (推荐))
- [2.4 角度3出发:各平台API的调用举例(了解)](#2.4 角度3出发:各平台API的调用举例(了解))
-
- [2.4.1 OpenAI 官方API](#2.4.1 OpenAI 官方API)
- [2.4.2 百度千帆平台](#2.4.2 百度千帆平台)
- [2.4.3 阿里云百炼平台](#2.4.3 阿里云百炼平台)
- [2.4.4 智谱的GLM](#2.4.4 智谱的GLM)
- [2.4.5 硅基流动平台](#2.4.5 硅基流动平台)
- [2.5 如何选择合适的大模型](#2.5 如何选择合适的大模型)
-
- [2.5.1 有没有最好的大模型](#2.5.1 有没有最好的大模型)
- [2.5.2 小结:获取大模型的标准方式](#2.5.2 小结:获取大模型的标准方式)
- [3、Model I/O之调用模型2](#3、Model I/O之调用模型2)
-
- [3.1 关于对话模型的Message(消息)](#3.1 关于对话模型的Message(消息))
- [3.2 关于多轮对话与上下文记忆](#3.2 关于多轮对话与上下文记忆)
- [3.3 关于模型调用的方法](#3.3 关于模型调用的方法)
-
- [3.3.1 流式输出与非流式输出](#3.3.1 流式输出与非流式输出)
- [3.3.2 批量调用](#3.3.2 批量调用)
- [3.3.3 同步调用与异步调用 (了解)](#3.3.3 同步调用与异步调用 (了解))
- [4、Model I/O之Prompt Template](#4、Model I/O之Prompt Template)
-
- [4.1 介绍与分类](#4.1 介绍与分类)
- [4.2 复习:str.format()](#4.2 复习:str.format())
- [4.3 具体使用:PromptTemplate](#4.3 具体使用:PromptTemplate)
-
- [4.3.1 使用说明](#4.3.1 使用说明)
- [4.3.2 两种实例化方式](#4.3.2 两种实例化方式)
- [4.3.3 两种新的结构形式](#4.3.3 两种新的结构形式)
- [4.3.4 format()与invoke()](#4.3.4 format()与invoke())
- [4.3.5 结合LLM调用](#4.3.5 结合LLM调用)
- [4.4 具体使用:ChatPromptTemplate](#4.4 具体使用:ChatPromptTemplate)
-
- [4.4.1 使用说明](#4.4.1 使用说明)
- [4.4.2 两种实例化方式](#4.4.2 两种实例化方式)
- [4.4.3 模板调用的几种方式对比](#4.4.3 模板调用的几种方式对比)
- [4.4.4 更丰富的实例化参数类型](#4.4.4 更丰富的实例化参数类型)
- [4.4.5 结合LLM](#4.4.5 结合LLM)
- [4.4.6 插入消息列表:MessagesPlaceholder](#4.4.6 插入消息列表:MessagesPlaceholder)
- [4.5 具体使用:少量样本示例的提示词模板 (Few-Shot)](#4.5 具体使用:少量样本示例的提示词模板 (Few-Shot))
-
- [4.5.1 使用说明](#4.5.1 使用说明)
- [4.5.2 FewShotPromptTemplate的使用](#4.5.2 FewShotPromptTemplate的使用)
- [4.5.3 FewShotChatMessagePromptTemplate的使用](#4.5.3 FewShotChatMessagePromptTemplate的使用)
- [4.5.4 Example selectors (示例选择器)](#4.5.4 Example selectors (示例选择器))
- [4.6 具体使用:PipelinePromptTemplate(了解)](#4.6 具体使用:PipelinePromptTemplate(了解))
- [4.7 具体使用:自定义提示词模版(了解)](#4.7 具体使用:自定义提示词模版(了解))
- [4.8 从文档中加载Prompt(了解)](#4.8 从文档中加载Prompt(了解))
-
- [4.8.1 yaml格式提示词](#4.8.1 yaml格式提示词)
- [4.8.2 json格式提示词](#4.8.2 json格式提示词)
- [5、Model I/O之Output Parsers](#5、Model I/O之Output Parsers)
-
- [5.1 输出解析器的分类](#5.1 输出解析器的分类)
- [5.2 具体解析器的使用](#5.2 具体解析器的使用)
-
- [① 字符串解析器 StrOutputParser](#① 字符串解析器 StrOutputParser)
- [② JSON解析器 JsonOutputParser](#② JSON解析器 JsonOutputParser)
- [③ XML解析器 XMLOutputParser](#③ XML解析器 XMLOutputParser)
- [④ 列表解析器 CommaSeparatedListOutputParser](#④ 列表解析器 CommaSeparatedListOutputParser)
- [⑤ 日期解析器 DatetimeOutputParser (了解)](#⑤ 日期解析器 DatetimeOutputParser (了解))
- 6、LangChain调用本地模型
-
- [6.1 Ollama的介绍](#6.1 Ollama的介绍)
- [6.2 Ollama的下载-安装](#6.2 Ollama的下载-安装)
- [6.3 模型的下载-安装](#6.3 模型的下载-安装)
- [6.4 调用本地私有模型](#6.4 调用本地私有模型)
- 第03章:LangChain使用之Chains
-
- 1、Chains的基本使用
-
- [1.1 Chain的基本概念](#1.1 Chain的基本概念)
- [1.2 LCEL及其基本构成](#1.2 LCEL及其基本构成)
- [1.3 Runnable](#1.3 Runnable)
- [1.4 使用举例](#1.4 使用举例)
- 2、传统Chain的使用
-
- [2.1 基础链:LLMChain](#2.1 基础链:LLMChain)
-
- [2.1.1 使用说明](#2.1.1 使用说明)
- [2.1.2 主要步骤](#2.1.2 主要步骤)
- [2.1.3 参数说明](#2.1.3 参数说明)
- [2.2 顺序链之 SimpleSequentialChain](#2.2 顺序链之 SimpleSequentialChain)
-
- [2.2.1 说明](#2.2.1 说明)
- [2.2.2 使用举例](#2.2.2 使用举例)
- [2.3 顺序链之 SequentialChain](#2.3 顺序链之 SequentialChain)
-
- [2.3.1 说明](#2.3.1 说明)
- [2.3.2 使用举例](#2.3.2 使用举例)
- 第04章:LangChain使用之Memory
-
- 1、Memory概述
-
- [1.1 为什么需要Memory](#1.1 为什么需要Memory)
- [1.2 什么是Memory](#1.2 什么是Memory)
- [1.3 Memory的设计理念](#1.3 Memory的设计理念)
- [1.4 不使用Memory模块,如何拥有记忆?](#1.4 不使用Memory模块,如何拥有记忆?)
- 2、基础Memory模块的使用
-
- [2.1 Memory模块的设计思路](#2.1 Memory模块的设计思路)
- [2.2 ChatMessageHistory(基础)](#2.2 ChatMessageHistory(基础))
- [2.3 ConversationBufferMemory](#2.3 ConversationBufferMemory)
- [2.4 ConversationChain](#2.4 ConversationChain)
- [2.5 ConversationBufferWindowMemory](#2.5 ConversationBufferWindowMemory)
- 3、其他Memory模块
-
- [3.1 ConversationTokenBufferMemory](#3.1 ConversationTokenBufferMemory)
- [3.2 ConversationSummaryMemory](#3.2 ConversationSummaryMemory)
- [3.3 ConversationSummaryBufferMemory](#3.3 ConversationSummaryBufferMemory)
- [3.4 ConversationEntityMemory(了解)](#3.4 ConversationEntityMemory(了解))
- [3.5 ConversationKGMemory(了解)](#3.5 ConversationKGMemory(了解))
- [3.6 VectorStoreRetrieverMemory(了解)](#3.6 VectorStoreRetrieverMemory(了解))
- 第05章:LangChain使用之Tools
- 第06章:LangChain使用之Agents
-
- 1、理解Agents
-
- [1.1 Agent与Chain的区别](#1.1 Agent与Chain的区别)
- [1.2 什么是Agent](#1.2 什么是Agent)
- [1.3 Agent的核心能力/组件](#1.3 Agent的核心能力/组件)
- [1.4 举例](#1.4 举例)
- [1.5 明确几个组件](#1.5 明确几个组件)
- 2、Agent入门使用
-
- [2.1 Agent、AgentExecutor的创建](#2.1 Agent、AgentExecutor的创建)
- [2.2 Agent的类型](#2.2 Agent的类型)
-
- [2.2.1 FUNCATION_CALL模式](#2.2.1 FUNCATION_CALL模式)
- [2.2.2 ReAct模式](#2.2.2 ReAct模式)
- [Agent 两种典型类型对比表](#Agent 两种典型类型对比表)
- [2.3 AgentExecutor创建方式](#2.3 AgentExecutor创建方式)
- [2.4 小结](#2.4 小结)
- 3、Agent中工具的使用
-
- [3.1 传统方式](#3.1 传统方式)
- [3.2 通用方式](#3.2 通用方式)
- 4、Agent嵌入记忆组件
-
- [4.1 传统方式](#4.1 传统方式)
- [4.2 通用方式](#4.2 通用方式)
第01章:LangChain使用概述

1、介绍 LangChain
1.1 什么是 LangChain
LangChain 是 2022年10月,由哈佛大学的 Harrison Chase (哈里森·蔡斯)发起研发的一个开源框架,用于开发由大语言模型(LLMs)驱动的应用程序。比如,搭建"智能体"(Agent)、问答系统(QA)、对话机器人、文档搜索系统、企业私有知识库等。
LangChain在Github上的热度变化
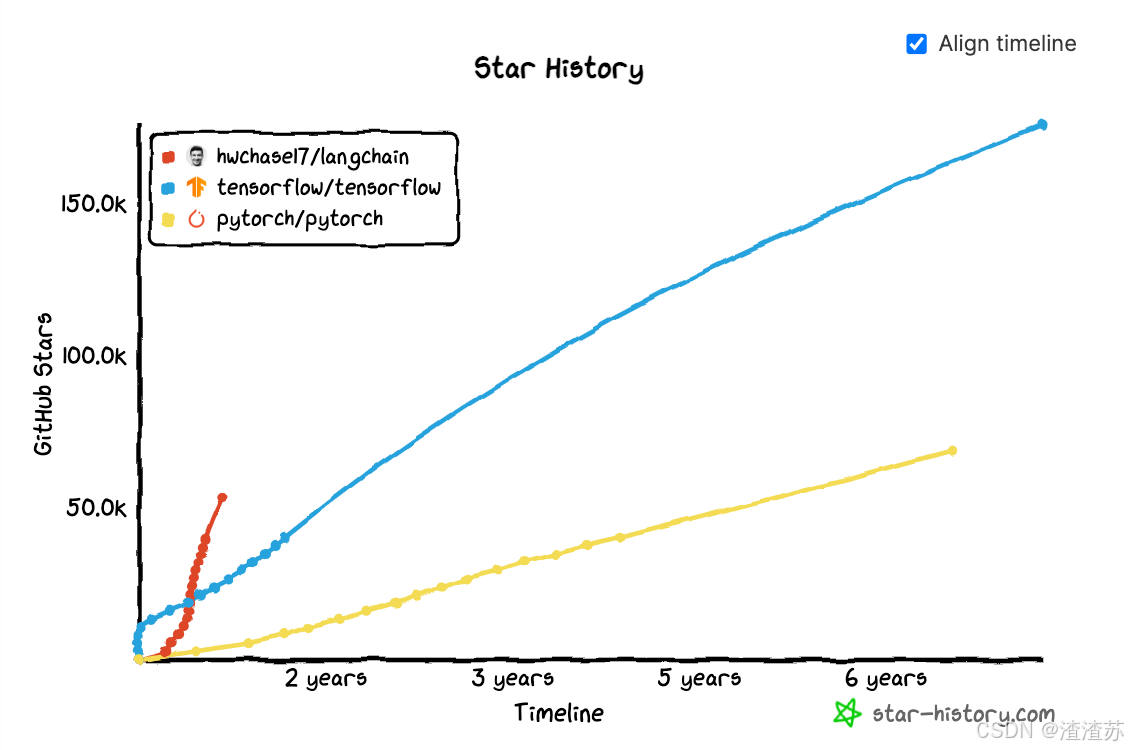
LangChain在Github上的star

https://github.com/langchain-ai/langchain
简单概括:
- LangChain ≠ LLMs
- LangChain之于 LLMs,类似 Spring之于 Java。
- LangChain之于 LLMs,类似 Django、Flask之于 Python。
顾名思义,LangChain中的"Lang"是指 language,即大语言模型,"Chain"即"链",也就是将大模型与外部数据&各种组件连接成链,以此构建AI应用程序。
大模型相关的岗位
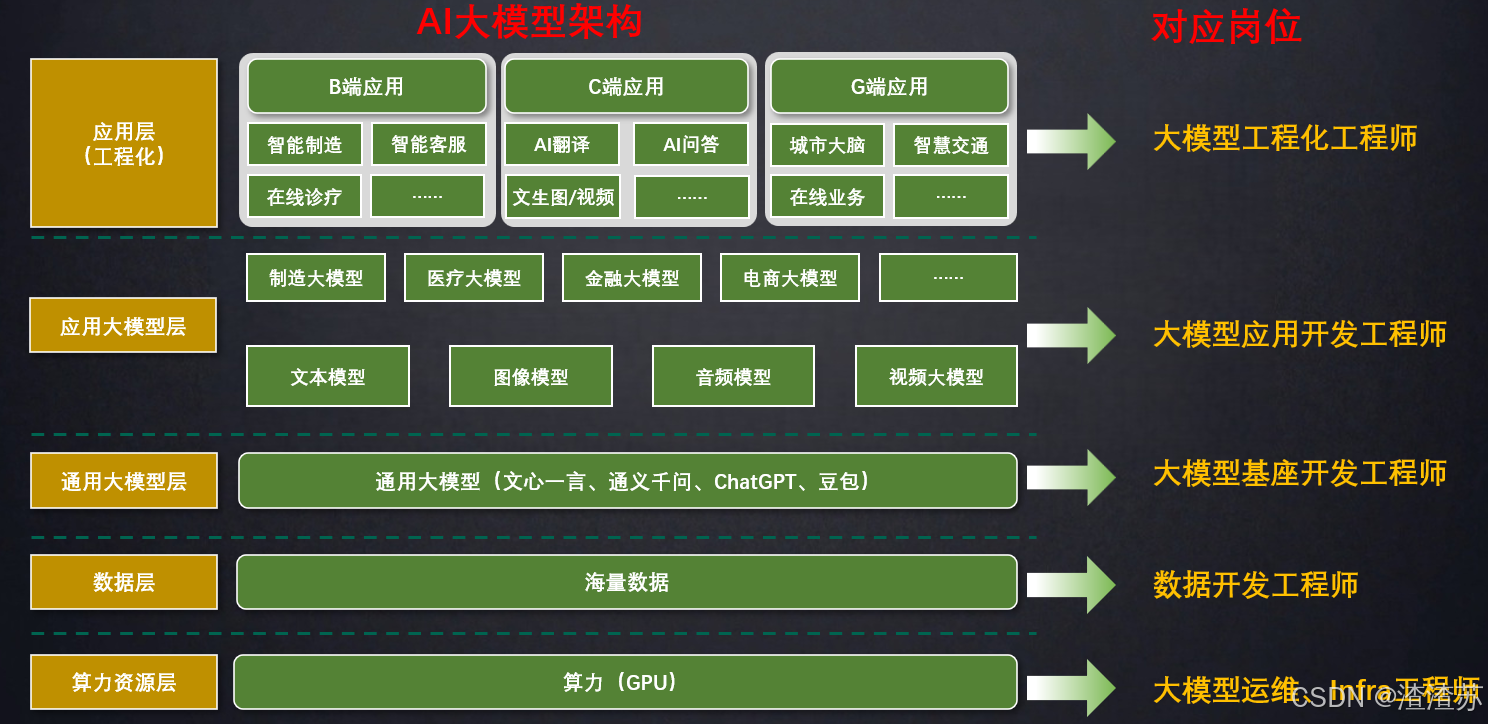
应用开发是大模型最值得关注的方向:应用为王! 学习LangChain框架,高效开发大模型应用。
1.2 有哪些大模型应用开发框架呢?
截止到2025年7月26日,GitHub统计数据:
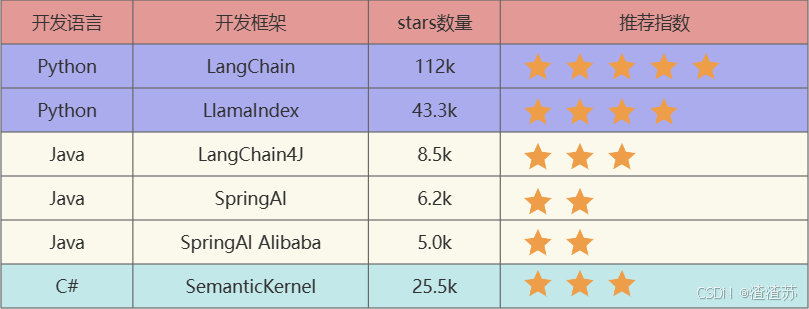
- LangChain:这些工具里出现最早、最成熟的,适合复杂任务分解和单智能体应用。
- LlamaIndex:专注于高效的索引和检索,适合 RAG场景。(注意不是Meta开发的)
- LangChain4J:LangChain还出了Java、JavaScript(LangChain.js)两个语言的版本,LangChain4j的功能略少于LangChain,但是主要的核心功能都是有的。
- SpringAI/SpringAI Alibaba:有待进一步成熟,此外只是简单的对于一些接口进行了封装。
- SemanticKernel:也称为sk,微软推出的,对于C#同学来说,那就是5颗星。
1.3 为什么需要 LangChain?
问题1:LLMs用的好好的,干嘛还需要LangChain?
在大语言模型(LLM)如 ChatGPT、Claude、DeepSeek等快速发展的今天,开发者不仅希望能"使用"这些模型,还希望能将它们灵活集成到自己的应用中,实现更强大的对话能力、检索增强生成(RAG)、工具调用(Tool Calling)、多轮推理等功能。

LangChain为更方便解决这些问题,而生的。比如:大模型默认不能联网,如果需要联网,用langchain。
问题2:我们可以使用GPT或GLM4等模型的API进行开发,为何需要LangChain这样的框架?
不使用LangChain,确实可以使用GPT或GLM4等模型的API进行开发。比如,搭建"智能体"(Agent)、问答系统、对话机器人等复杂的 LLM应用。但使用LangChain的好处:
- 简化开发难度:更简单、更高效、效果更好。
- 学习成本更低:不同模型的API不同,调用方式也有区别,切换模型时学习成本高。使用LangChain,可以以统一、规范的方式进行调用,有更好的移植性。
- 现成的链式组装 :LangChain提供了一些现成的链式组装,用于完成特定的高级任务。让复杂的逻辑变得结构化、易组合、易扩展。
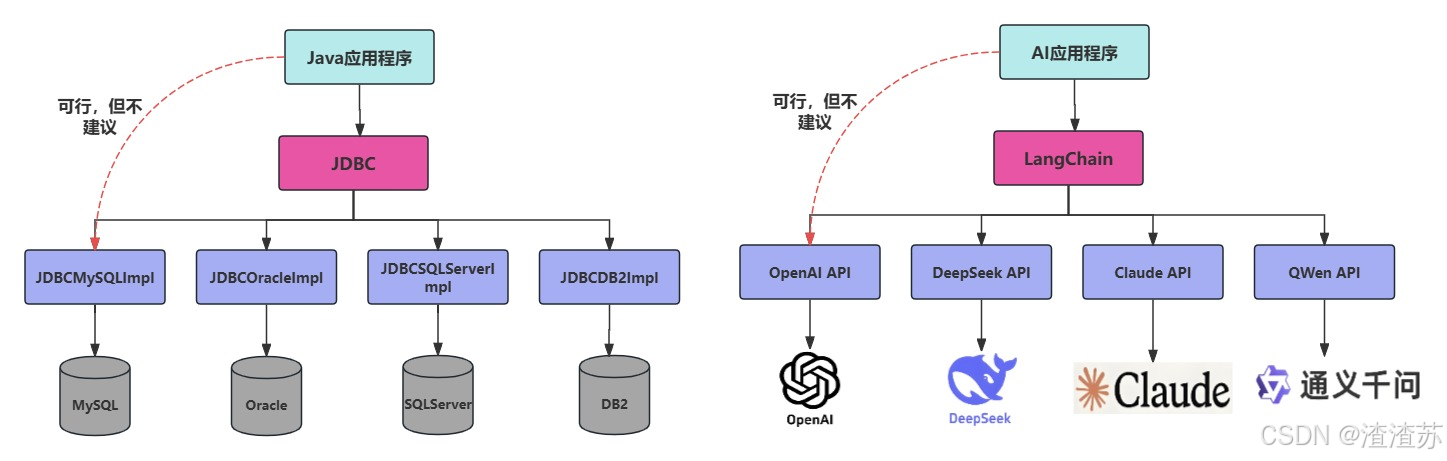
问题3:LangChain提供了哪些功能呢?
LangChain是一个帮助你构建 LLM应用的全套工具集。这里涉及到prompt构建、LLM接入、记忆管理、工具调用、RAG、智能体开发等模块。
学习 LangChain最好的方式就是做项目。
1.4 LangChain的使用场景
学完LangChain,如下类型的项目,大家都可以实现:
| 项目名称 | 技术点 | 难度 |
|---|---|---|
| 文档问答助手 | Prompt+ Embedding+ RetrievalQA | ⭐⭐ |
| 智能日程规划助手 | Agent+ Tool+ Memory | ⭐⭐⭐ |
| LLM+数据库问答 | SQLDatabaseToolkit+ Agent | ⭐⭐⭐⭐ |
| 多模型路由对话系统 | RouterChain+多 LLM | ⭐⭐⭐⭐ |
| 互联网智能客服 | ConversationChain+ RAG+Agent | ⭐⭐⭐⭐⭐ |
| 企业知识库助手(RAG+本地模型) | VectorDB+ LLM+ Streamlit | ⭐⭐⭐⭐⭐ |
-
比如:医院智能助手
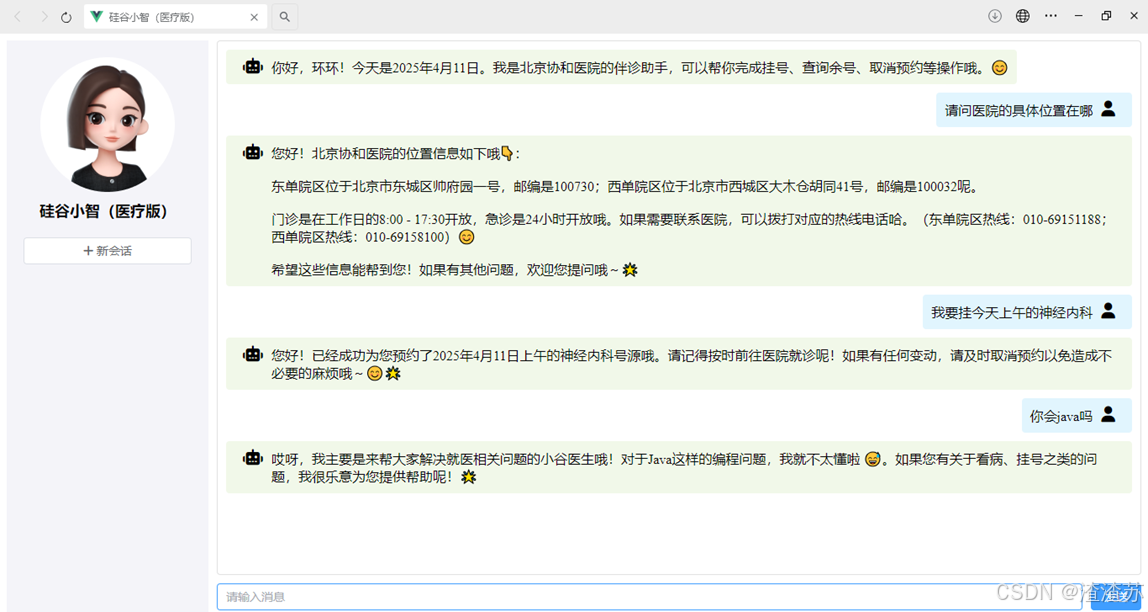
-
比如:万象知识库
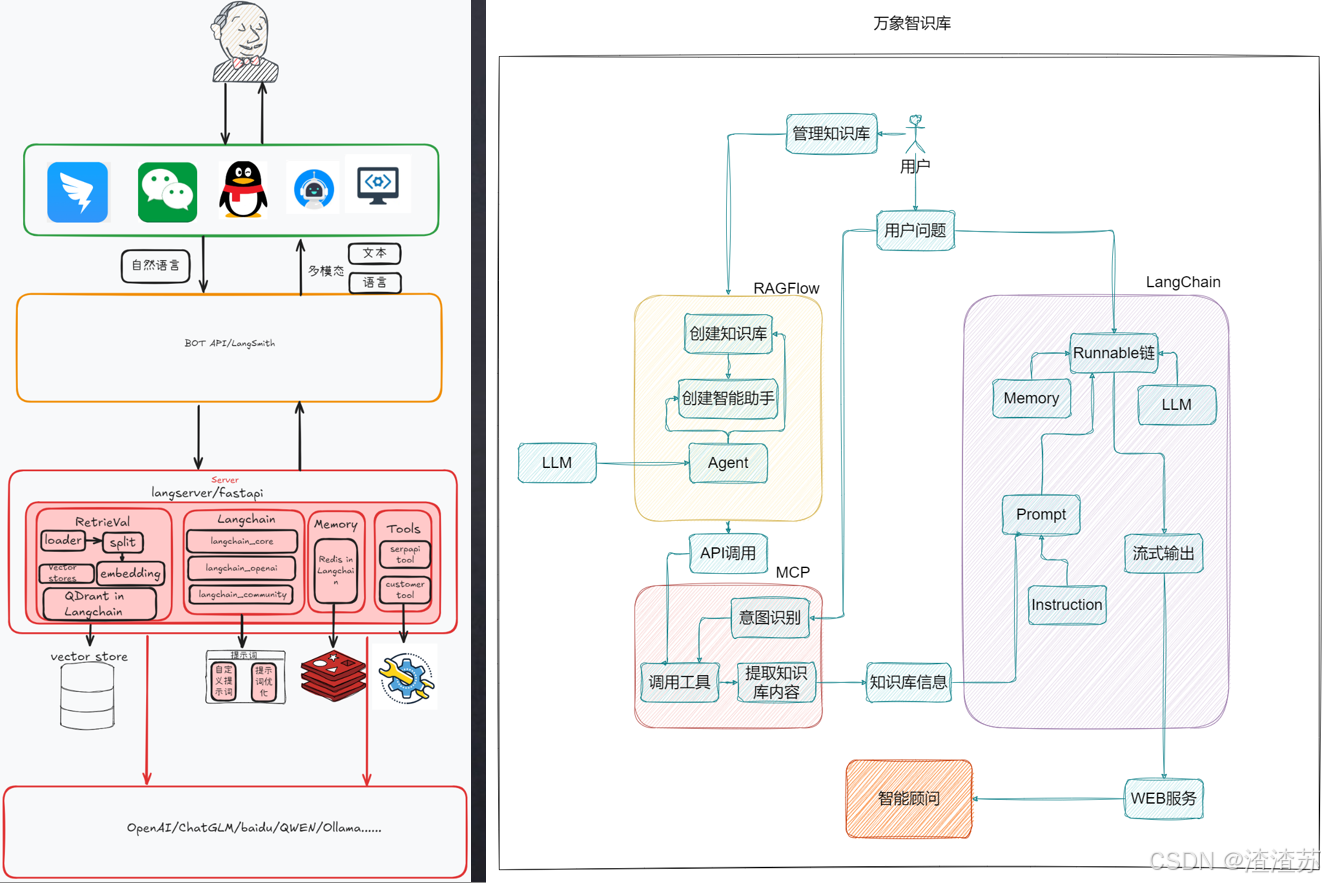
-
比如:京东助手
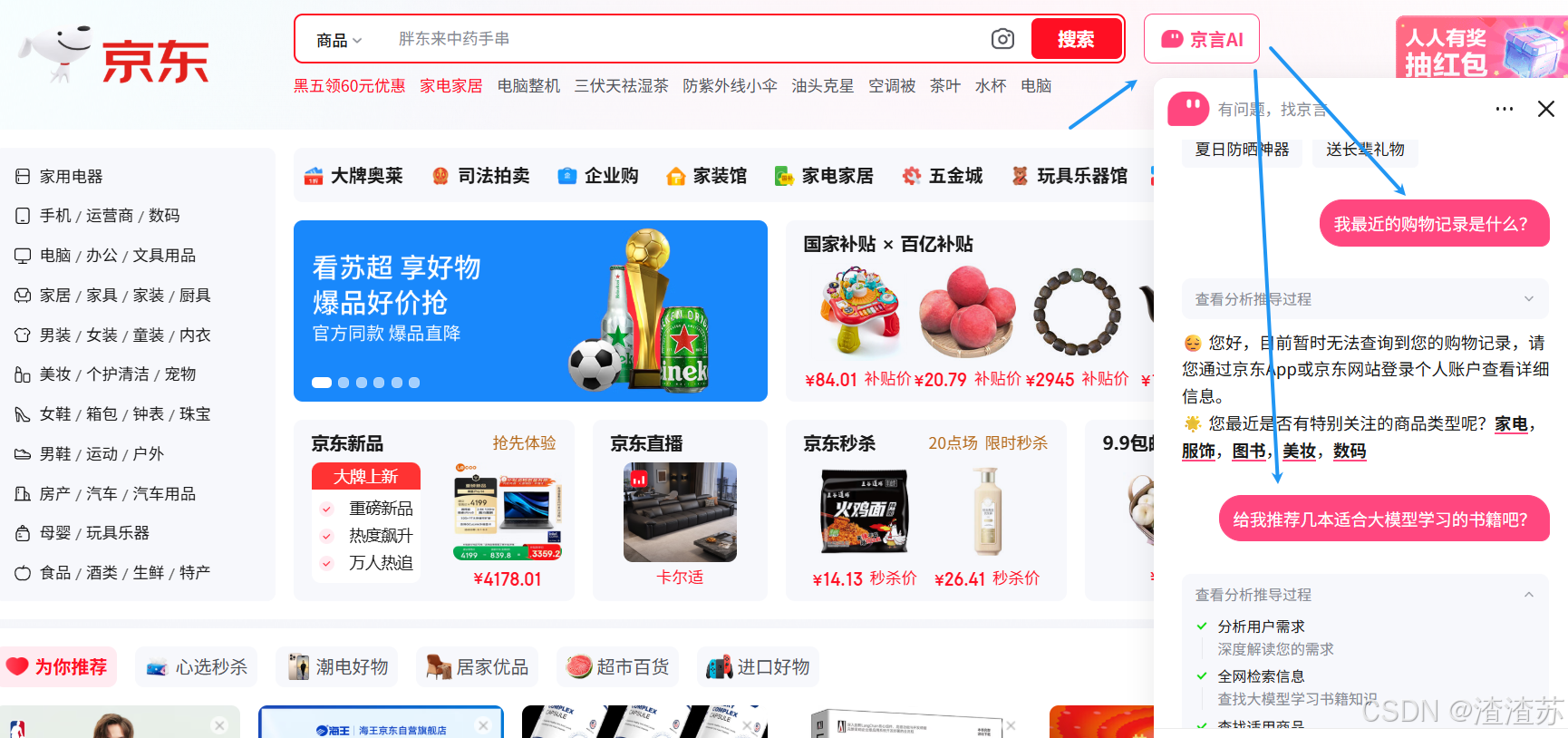
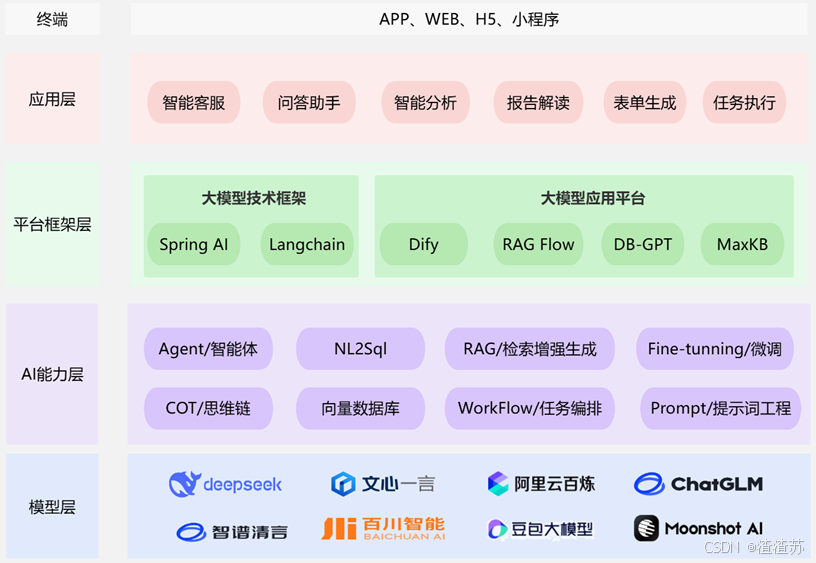
LangChain的位置:
1.5 LangChain资料介绍
- 官网地址:https://www.langchain.com/langchain
- 官网文档:https://python.langchain.com/docs/introduction/
- API文档:https://python.langchain.com/api_reference/
- github地址:https://github.com/langchain-ai/langchain
1.6 架构设计
1.6.1 总体架构图
-
V0.1版本
-
V0.2/ V0.3版本
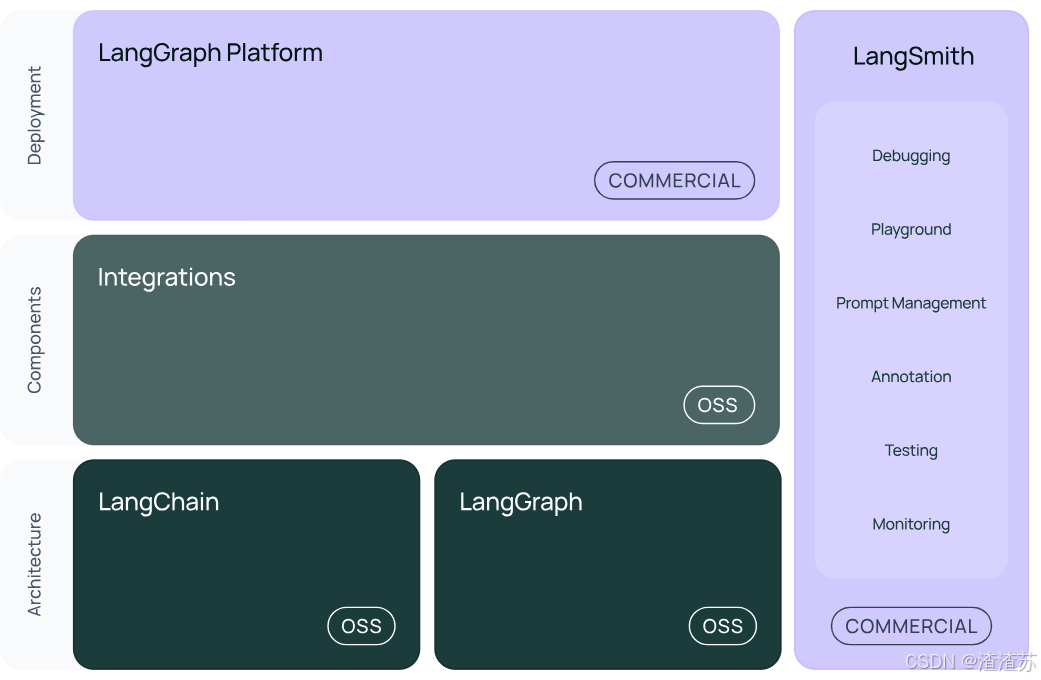
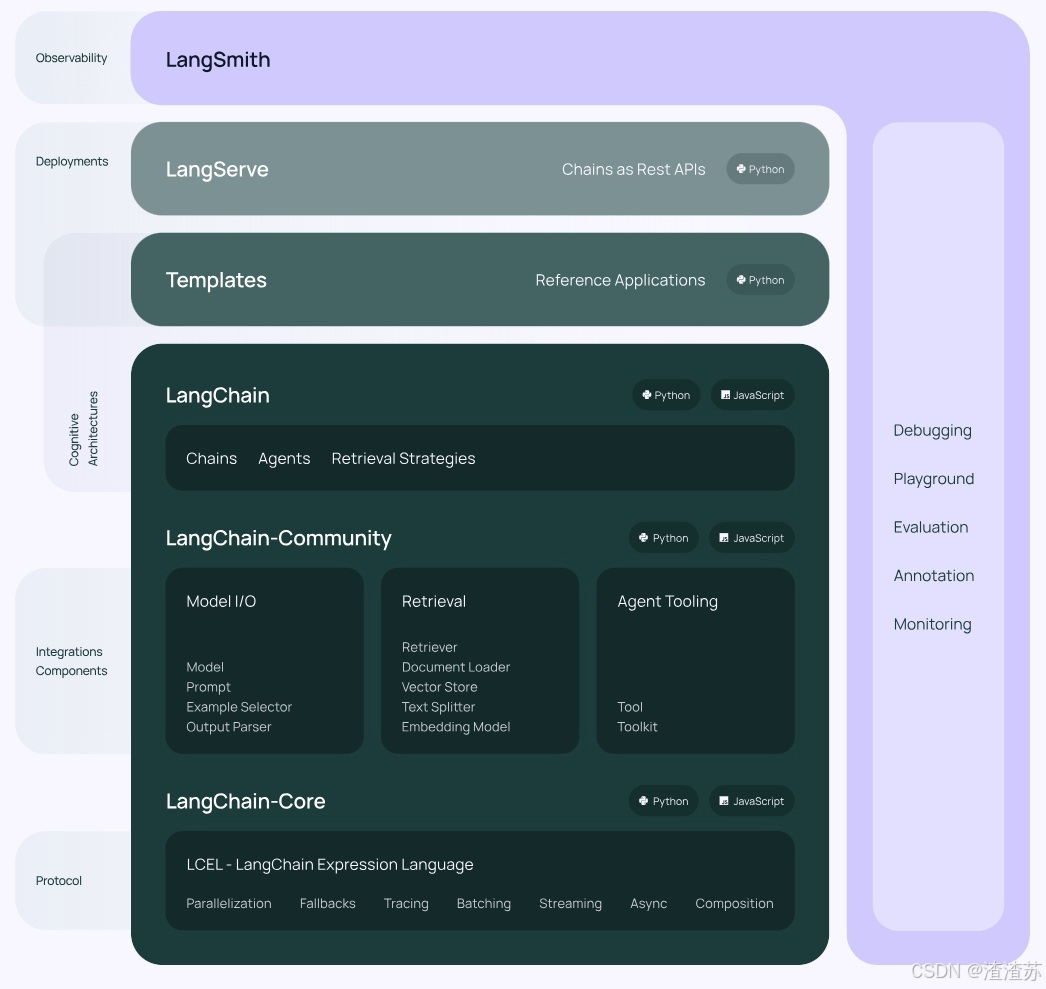
图中展示了LangChain生态系统的主要组件及其分类,分为三个层次:架构(Architecture)、组件(Components)和部署(Deployment)。
版本的升级,v0.2相较于v0.1,修改了大概10%-15%。功能性上差不多,主要是往稳定性(或兼容性)、安全性上使劲了,支持更多的大模型,更安全。
1.6.2 内部架构详情
结构1:LangChain
-
langchain:构成应用程序认知架构的Chains,Agents,Retrieval strategies等构成应用程序的链、智能体、RAG。
-
langchain-community:第三方集成,比如:Model I/O、Retrieval、Tool& Toolkit;合作伙伴包 langchain-openai,langchain-anthropic等。
-
langchain-Core:基础抽象和LangChain表达式语言(LCEL)
小结:LangChain,就是AI应用组装套件,封装了一堆的API。langchain框架不大,但是里面琐碎的知识点特别多。就像玩乐高,提供了很多标准化的乐高零件(比如,连接器、轮子等)
结构2:LangGraph
LangGraph可以看做基于LangChain的api的进一步封装,能够协调多个Chain、Agent、Tools完成更复杂的任务,实现更高级的功能。
结构3:LangSmith
官网:https://docs.smith.langchain.com/
链路追踪。提供了6大功能,涉及Debugging(调试)、Playground(沙盒)、Prompt Management(提示管理)、Annotation(注释)、Testing(测试)、Monitoring(监控)等。与LangChain无缝集成,帮助你从原型阶段过渡到生产阶段。
正是因为LangSmith这样的工具出现,才使得LangChain意义更大,要不仅靠⼀些API(当然也可以不⽤,⽤原⽣的API),⽀持不住LangChain的热度。
结构4:LangServe
将LangChain的可运行项和链部署为REST API,使得它们可以通过网络进行调用。
Java怎么调用langchain呢?就通过这个langserve。将langchain应用包装成一个rest api,对外暴露服务。同时,支持更高的并发,稳定性更好。
总结:
LangChain当中,最有前途的两个模块就是:LangGraph ,LangSmith。
- LangChain能做RAG,其它的一些框架也能做,而且做的也不错,比如LlamaIndex。所以这时候LangChain要在Agent这块发力,那就需要LangGraph。
- 而LangSmith,做运维、监控。故,二者是LangChain里最有前途的。
2、开发前的准备工作
2.1 前置知识
- Python基础语法
- 变量、函数、类、装饰器、上下文管理器
- 模块导入、包管理(推荐用 pip 或 conda )
- 大语言模型基础
- 了解什么是 LLM、Token、Prompt、Embedding
- OpenAI API或其他模型提供商,如 Anthropic、阿里云百炼、DeepSeek等
- 通过浏览器或app使用过大模型(比如:豆包、DeepSeek等)
2.2 相关环境安装
-
安装Python或Anaconda
LangChain基于Python开发,因此需确保系统中安装了Python。
- 方式1:直接下载Python安装包。推荐版本为Python 3.10及以上。
- 方式2:使用包管理工具(如Anaconda)进行安装。通过Anaconda可以轻松创建和管理虚拟环境。
-
创建虚拟环境
- 为了保持项目的独立性与环境的干净,建议使用虚拟环境。
-
如何下载安装包
-
方式1:使用pip指令
基础指令
bash# 安装包(默认最新版) pip install langchain # 指定版本 pip install langchain==0.3.7 # 批量安装(空格分隔) pip install langchain requests numpy # 升级包 pip install --upgrade langchain # 卸载包 pip uninstall langchain # 查看已安装包 pip list高级操作
bash# 国内镜像加速 (解决下载慢) -i:指定镜像源 pip install -i https://mirrors.aliyun.com/pypi/simple/ langchain # 从本地/URL安装: pip install ./local_package.whl pip install https://github.com/user/repo/archive/main.zip -
方式2:使用conda指令
bash# 安装包(默认仓库) conda install langchain # 指定频道(如 conda-forge) # -c:是--channel的缩写,conda用于指定包的安装来源渠道。 # conda-forge:该源比官方默认渠道更新更快、包更全 conda install -c conda-forge langchain==0.3.7 # 更新包 conda update langchain # 卸载包 conda uninstall langchain # 查看已安装包 conda list -c :是 --channel 的缩写,conda⽤于指定包的安装来源渠道。 conda-forge :该源⽐官⽅默认渠道更新更快、包更全 -
建议:二者最好不要混用,推荐先conda装基础包,后 pip补充的顺序。
bash# 检查包来源 conda list # conda安装的包显示频道,pip安装的显示 pypi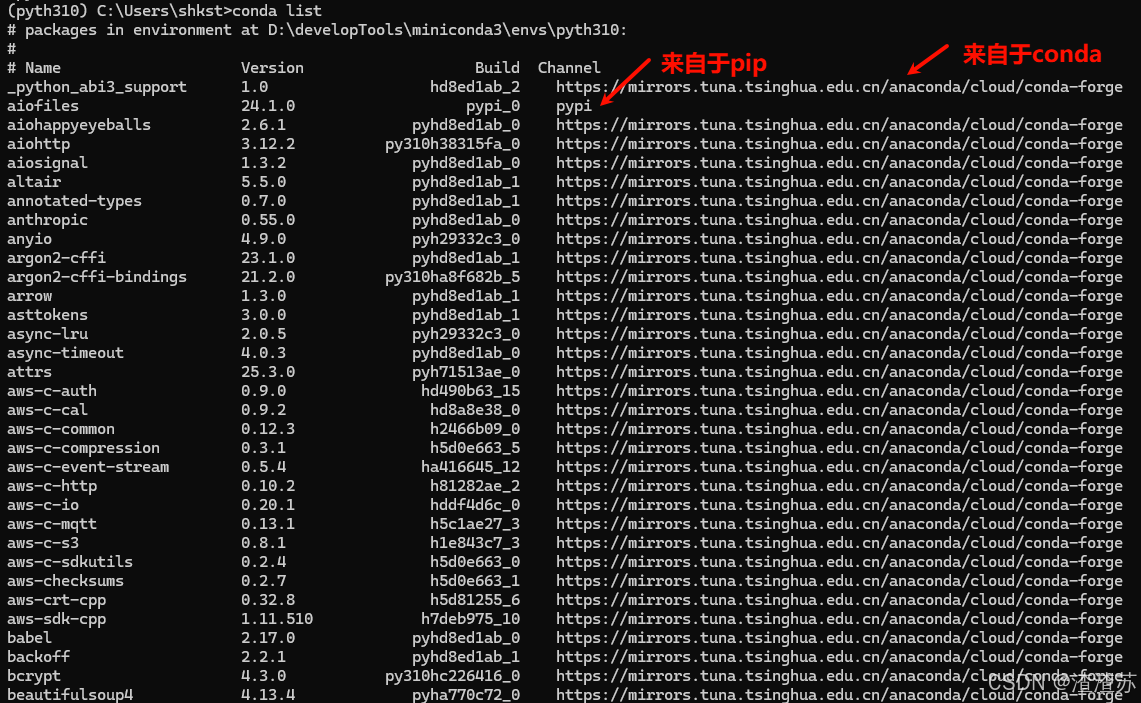
-
-
PyCharm开发环境
-
PyCharm作为专业的Python IDE,具有强大的代码编辑、调试和版本控制功能。

-
创建新的工程,并设置Python解释器(选择Anaconda环境)。
-
bash
import langchain
print(langchain.__version__) # 0.3.25
import openai
print(openai.__version__) # 1.81.0
import sys
#查看python的版本
print(sys.version) # 3.10.17 | packaged by conda-forge | (main, Apr 10 2025, 22:06:35) [MSC
v.1943 64 bit (AMD64)]3、大模型应用开发
大模型应用技术特点:门槛低,天花板高。
3.1 基于RAG架构的开发
背景:
- 大模型的知识冻结
- 大模型幻觉。
而RAG就可以非常精准地解决这两个问题。
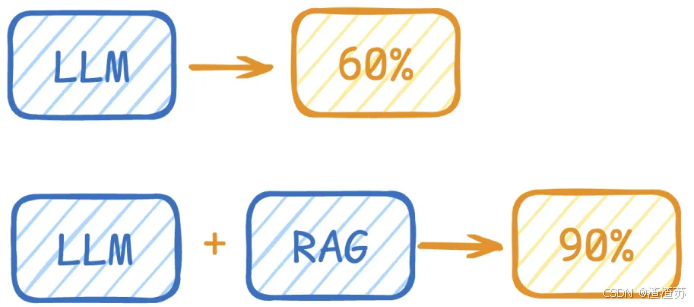
举例:
LLM在考试的时候面对陌生的领域,答复能力有限,然后就准备放飞自我了。而此时RAG给了一些提示和思路,让LLM懂了开始往这个提示的方向做,最终考试的正确率从60%到了90%!
何为RAG?
Retrieval-Augmented Generation(检索增强生成)
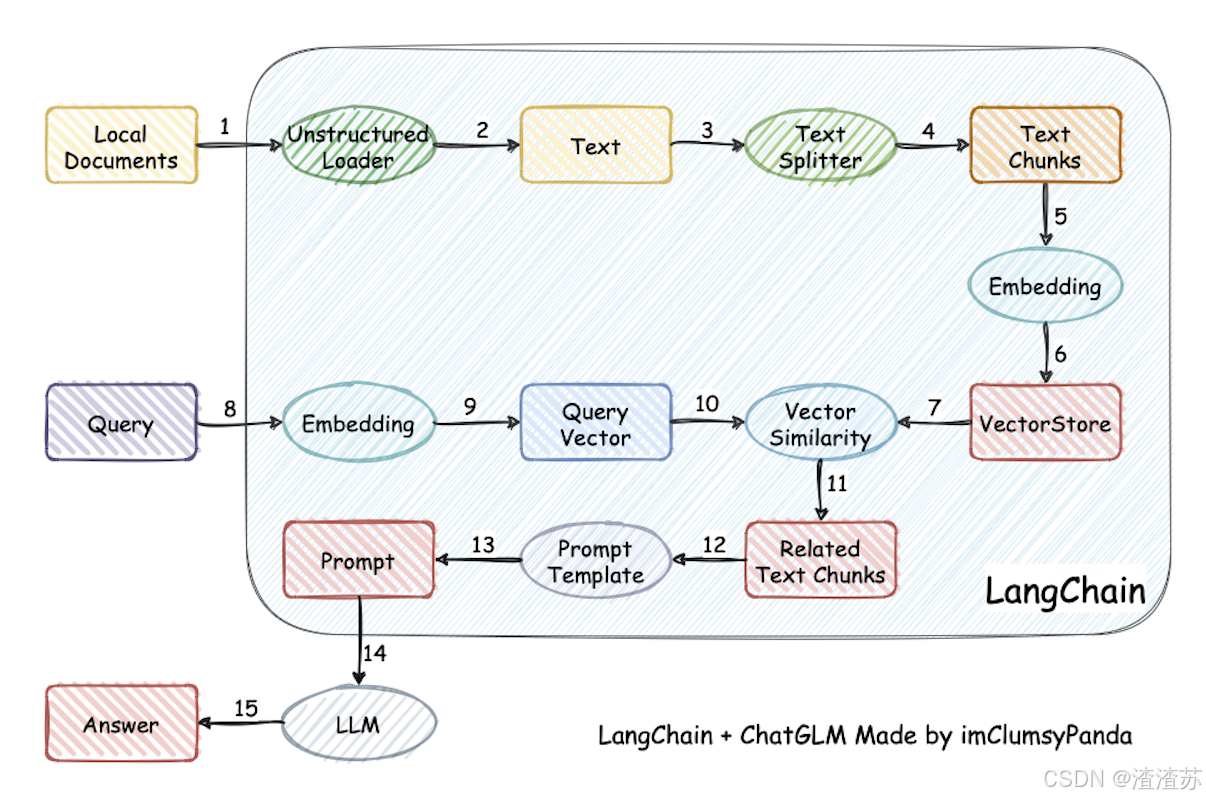
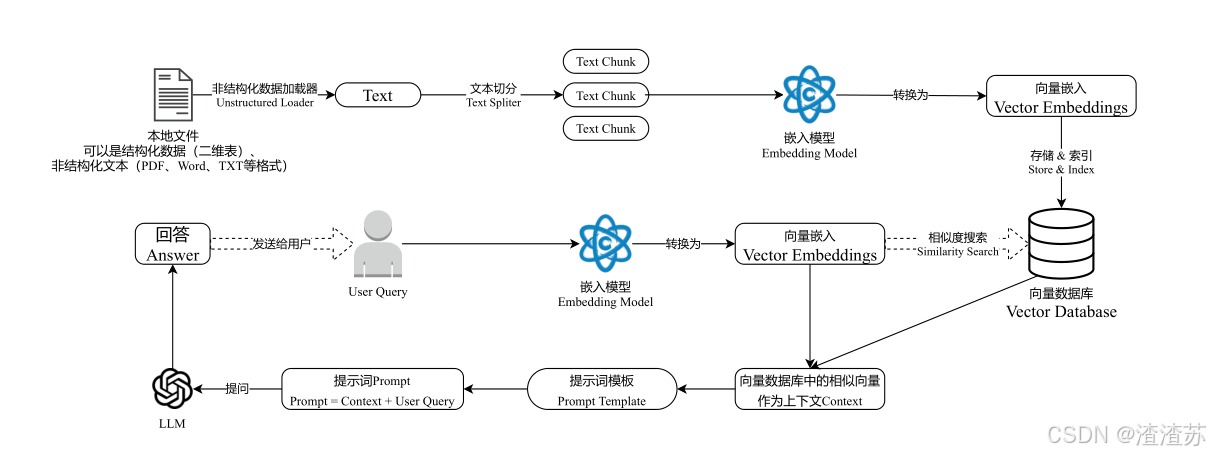
检索-增强-⽣成过程:检索可以理解为第10步,增强理解为第12步(这⾥的提⽰词包含检索到的数据),⽣成理解为第15步。
类似的细节图:
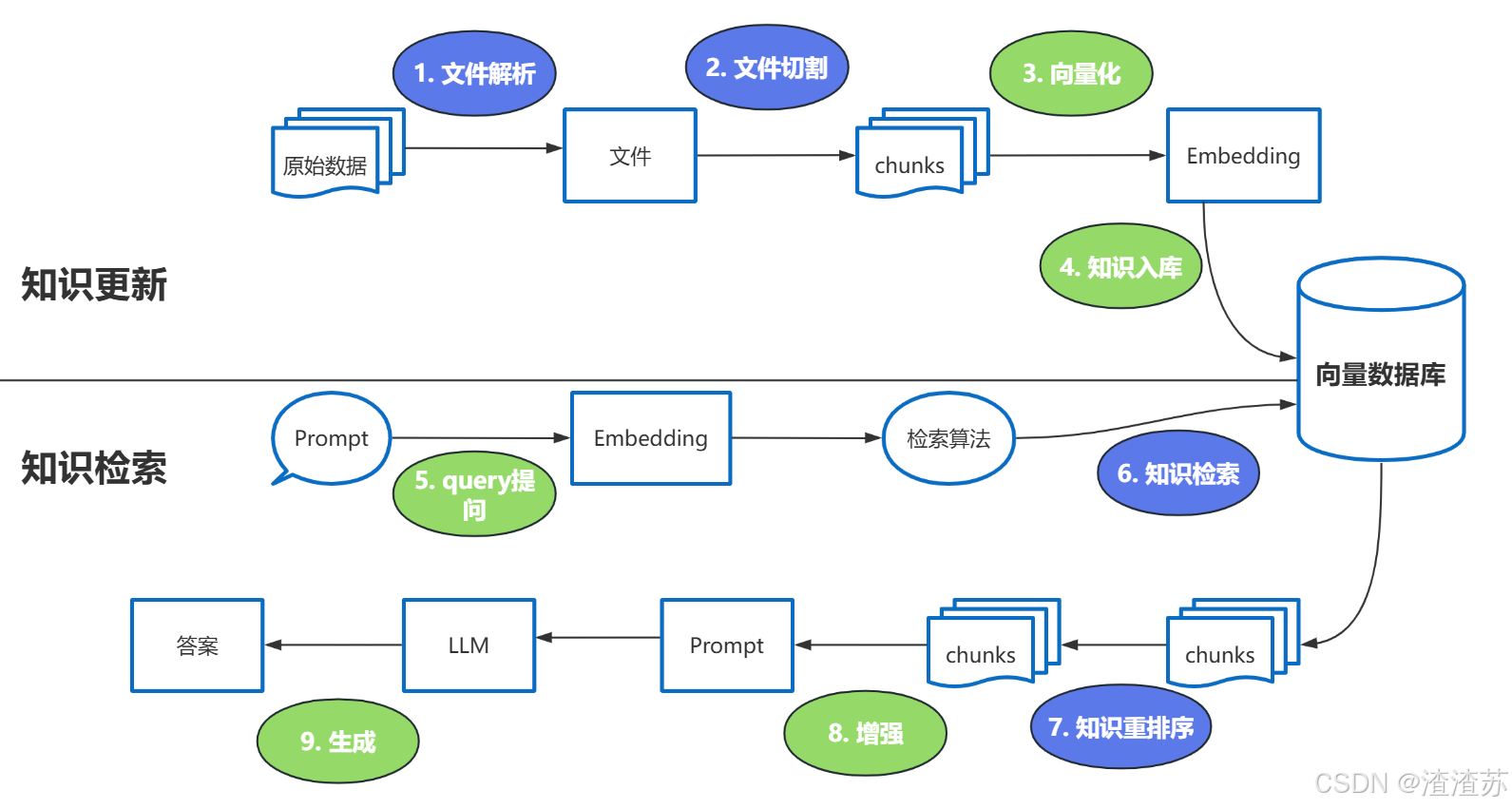
强调一下难点的步骤:
Reranker的使用场景:
- 适合:追求回答高精度和高相关性的场景中特别适合使用 Reranker,例如专业知识库或者客服系统等应用。
- 不适合:引入reranker会增加召回时间,增加检索延迟。服务对响应时间要求高时,使用reranker可能不合适。
这里有三个位置涉及到大模型的使用:
- 第3步向量化时,需要使用EmbeddingModels。
- 第7步重排序时,需要使用RerankModels。
- 第9步生成答案时,需要使用LLM。
3.2 基于Agent架构的开发
充分利用 LLM的推理决策能力,通过增加规划、记忆和工具调用的能力,构造一个能够独立思考、逐步完成给定目标的智能体。
举例:传统的程序 vs Agent(智能体)
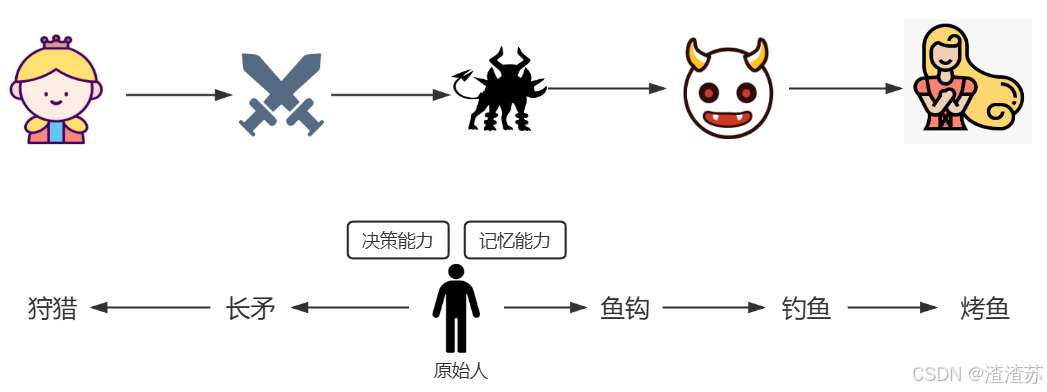 OpenAI的元老翁丽莲(Lilian Weng)于2023年6月在个人博客首次提出了现代AI Agent架构。
OpenAI的元老翁丽莲(Lilian Weng)于2023年6月在个人博客首次提出了现代AI Agent架构。
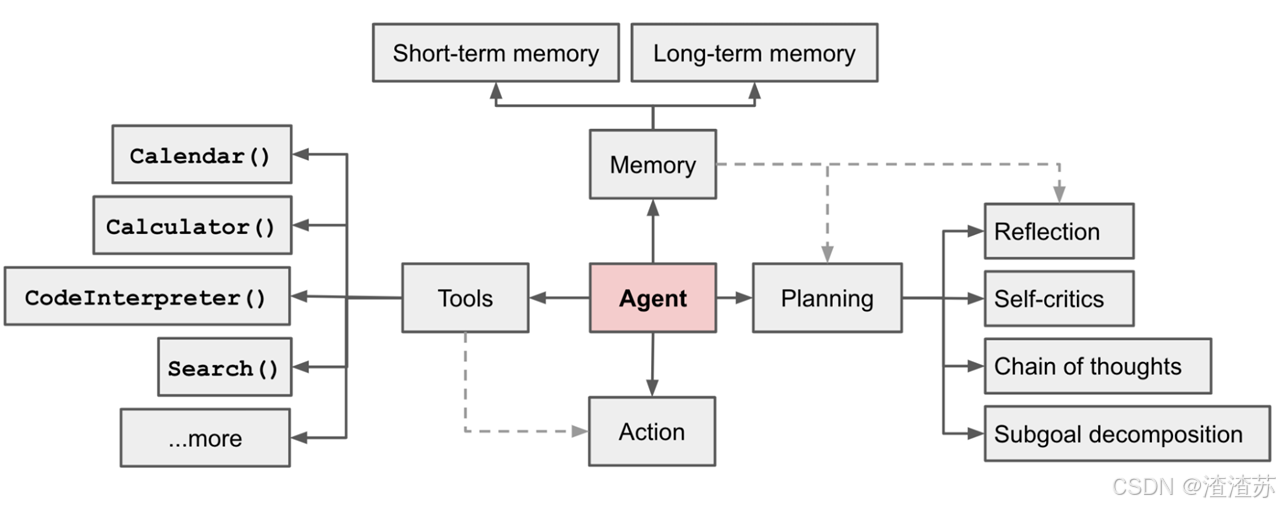
一个数学公式来表示 :
Agent = LLM + Memory + Tools + Planning + Action
⽐如,打⻋到西藏玩。
1. ⼤脑中枢:规划⾏程的你
2. 规划:步骤1:规划打⻋路线,步骤2:定饭店、酒店,。。。
3. 调⽤⼯具:调⽤MCP或FunctionCalling等API,滴滴打⻋、携程、美团订酒店饭店
4. 记忆能⼒:沟通时,要知道上下⽂。⽐如定酒店得知道是西藏路上的酒店,不能聊着聊着忘了最初的⽬的。
5. 能够执⾏上述操作。说走就走,不能纸上谈兵。智能体核心要素被细化为以下模块:
- 大模型(LLM)作为"大脑":提供推理、规划和知识理解能力,是AI Agent的决策中枢。
⼤脑主要由⼀个⼤型语⾔模型 LLM 组成,承担着信息处理和决策等功能, 并可以呈现推理和规划的过程,能很好地应对未知任务。
-
记忆(Memory):
记忆机制能让智能体在处理重复⼯作时调⽤以前的经验,从而避免⽤⼾进⾏⼤量重复交互。
-
短期记忆:存储单次对话周期的上下文信息,属于临时信息存储机制。受限于模型的上下文窗口长度。
ChatGPT:⽀持约8k token的上下⽂
GPT4:⽀持约32k token的上下⽂
最新的很多⼤模型:都⽀持100万、1000万 token的上下⽂ (相当于2000万字⽂本或20小时视频)
⼀般情况下模型中 token 和字数的换算⽐例⼤致如下:
- 1 个英⽂字符 ≈ 0.3 个 token。
- 1 个中⽂字符 ≈ 0.6 个 token。
-
长期记忆:可以横跨多个任务或时间周期,可存储并调用核心知识,非即时任务。
- 长期记忆,可以通过模型参数微调(固化知识)、知识图谱(结构化语义网络)或向量数据库(相似性检索)方式实现。
-
-
工具使用(Tool Use):调用外部工具(如API、数据库)扩展能力边界。
-
规划决策(Planning):通过任务分解、反思与自省框架实现复杂任务处理。例如,利用思维链(Chain of Thought)将目标拆解为子任务,并通过反馈优化策略。
-
行动(Action):实际执行决策的模块,涵盖软件接口操作(如自动订票)和物理交互(如机器人执行搬运)。比如:检索、推理、编程等。
智能体会形成完整的计划流程。例如先读取以前⼯作的经验和记忆,之后规划⼦⽬标并使⽤相应⼯具去处理问题,最后输出给⽤⼾并完成反思。
3.3 大模型应用开发的4个场景
-
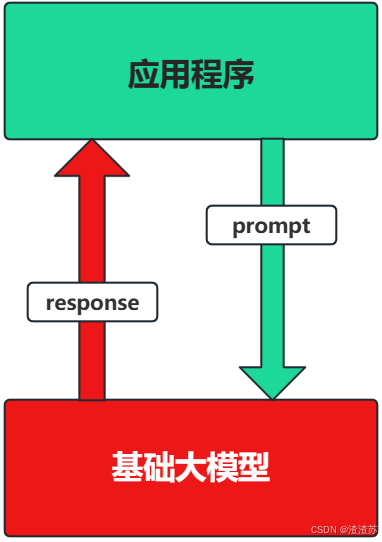
场景1:纯 Prompt
-
Prompt是操作大模型的唯一接口。
-
当人看:你说一句,ta回一句,你再说一句,ta再回一句...
-
-
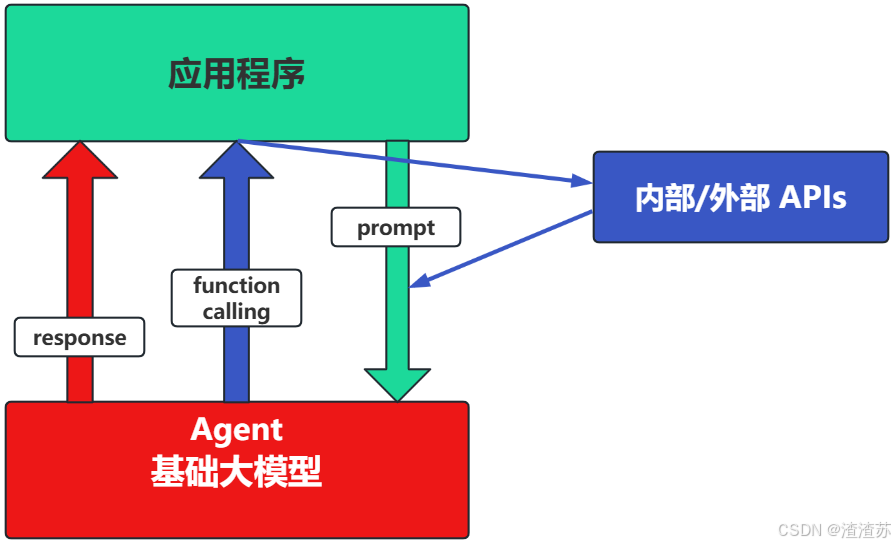
场景2:Agent+ Function Calling
-
Agent:AI主动提要求。
-
Function Calling:需要对接外部系统时,AI要求执行某个函数。
-
当人看:你问 ta「我明天去杭州出差,要带伞吗?」,ta 让你先看天气预报,你看了告诉ta,ta再告诉你要不要带伞
-
-
场景3:RAG(Retrieval-Augmented Generation)
RAG:需要补充领域知识时使用。
- Embeddings:把文字转换为更易于相似度计算的编码。这种编码叫向量。
- 向量数据库:把向量存起来,方便查找。
- 向量搜索:根据输入向量,找到最相似的向量。
举例:考试答题时,到书上找相关内容,再结合题目组成答案
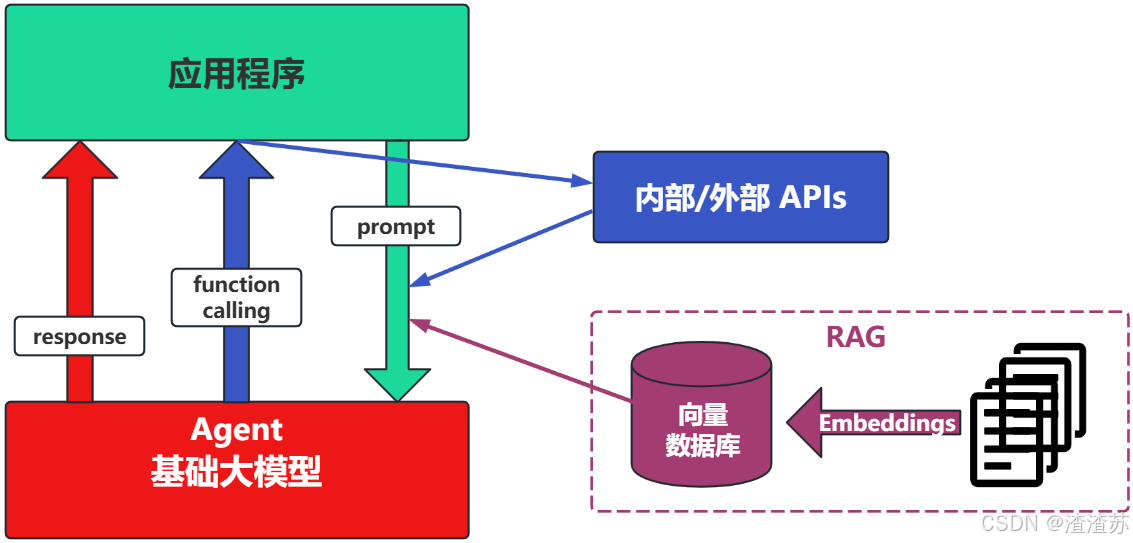
-
场景4:Fine-tuning(精调/微调)
-
举例:努力学习考试内容,长期记住,活学活用。
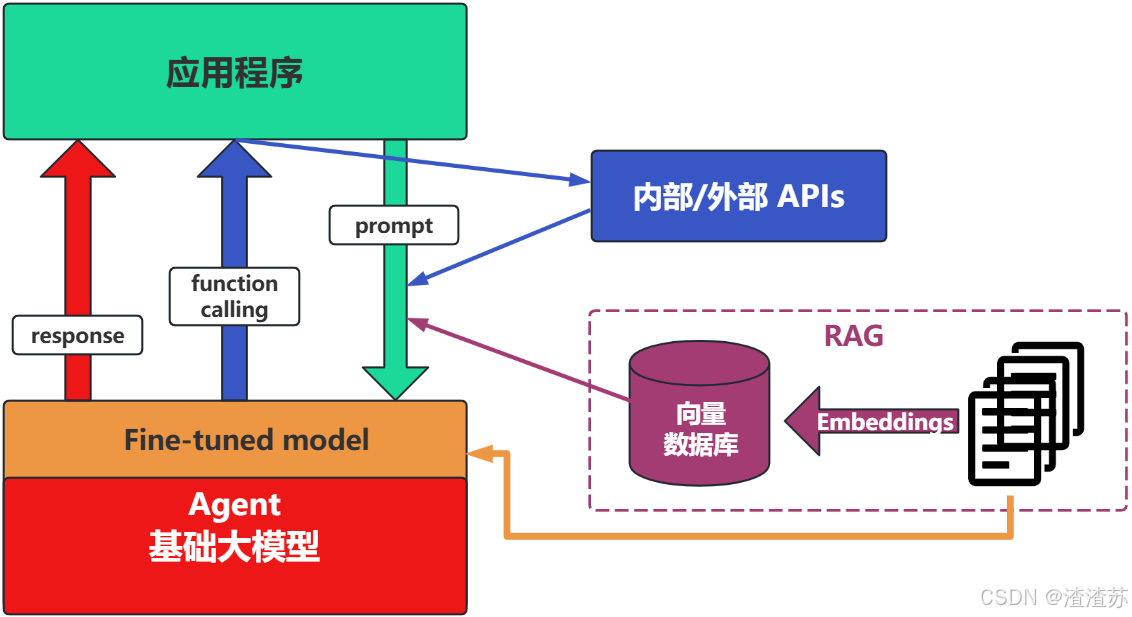
-
特点:成本最高;在前面的方式解决不了问题的情况下,再使用。
-
如何选择
面对一个需求,如何开始,如何选择技术方案?下面是个常用思路:
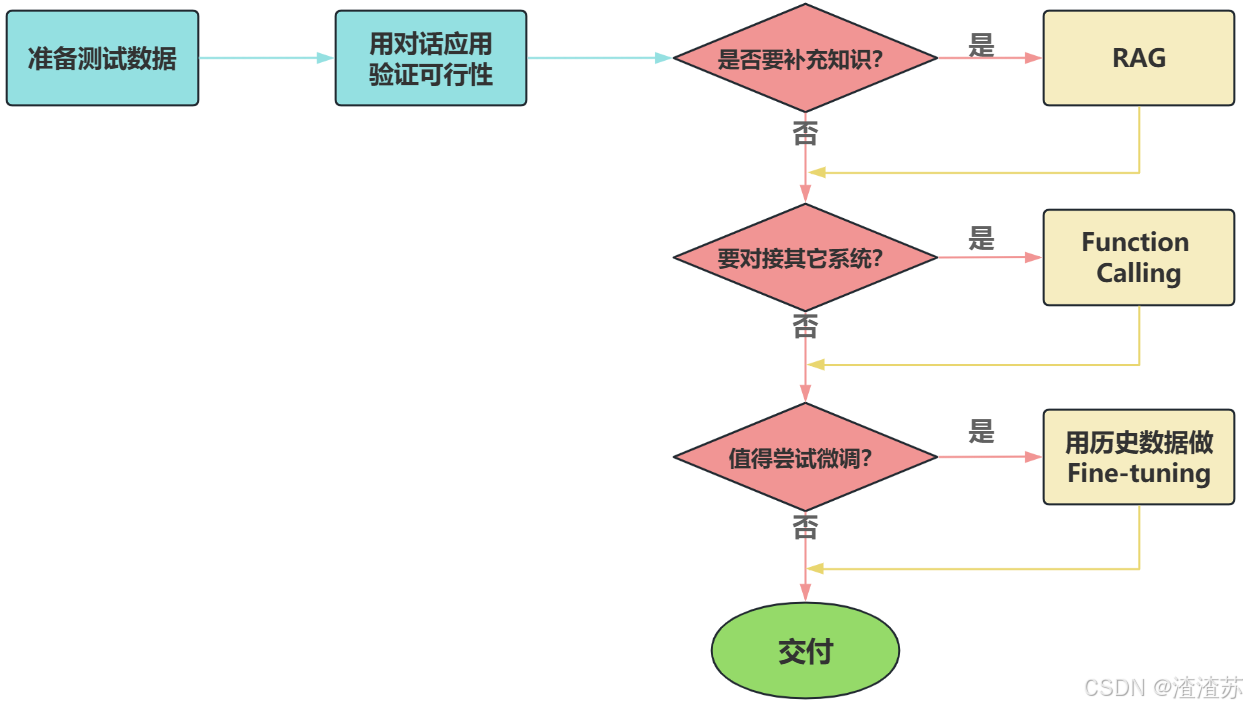
- 注意:其中最容易被忽略的,是准备测试数据。
下面,我们重点介绍下大模型应用的开发两类:基于RAG的架构,基于Agent的架构。
4、LangChain的核心组件
学习Langchain最简单直接的方法就是阅读官方文档。
https://python.langchain.com/v0.1/docs/modules/
通过文档目录我们可以看到,Langchain构成的核心组件。
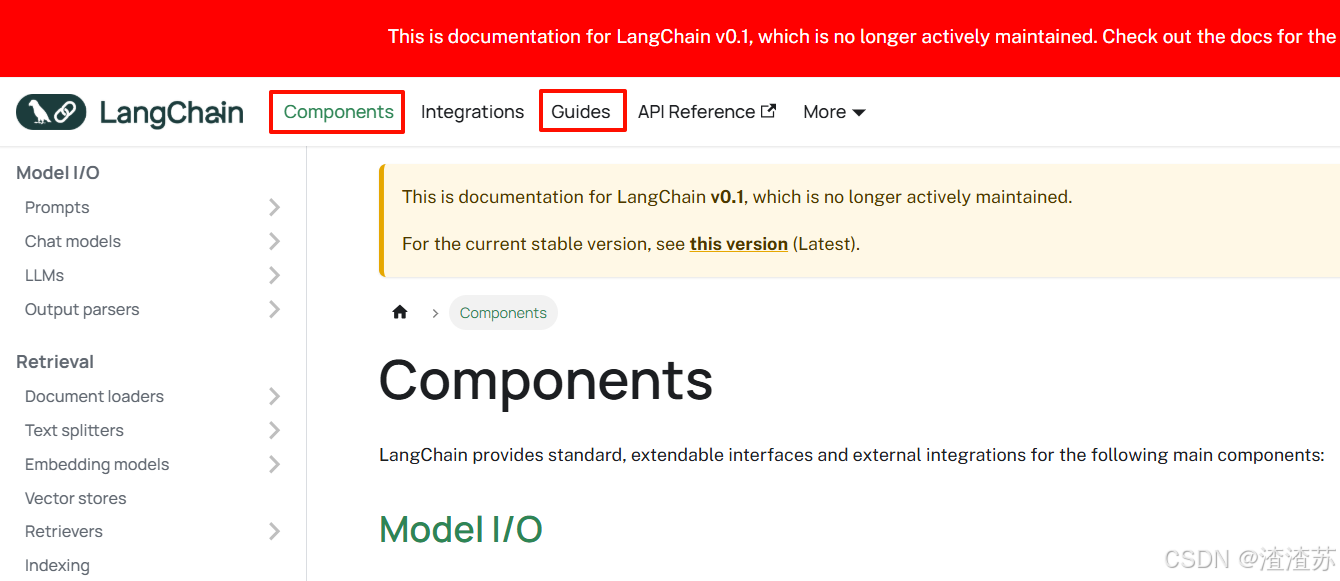
两个红框内容是核心。中间的Integrations:集成各种工具或云平台。
4.1 一个问题引发的思考
如果要组织一个AI应用,开发者一般需要什么?
- 提示词模板的构建,不仅仅只包含用户输入。
- 模型调用与返回,参数设置,返回内容的格式化输出。
- 知识库查询,这里会包含文档加载,切割,以及转化为词嵌入(Embedding)向量。
- 其他第三方工具调用,一般包含天气查询、Google搜索、一些自定义的接口能力调用。
- 记忆获取,每一个对话都有上下文,在开启对话之前总得获取到之前的上下文吧?
4.2 核心组件的概述
LangChain的核心组件涉及六大模块,这六大模块提供了一个全面且强大的框架,使开发者能够创建复杂、高效且用户友好的基于大模型的应用。
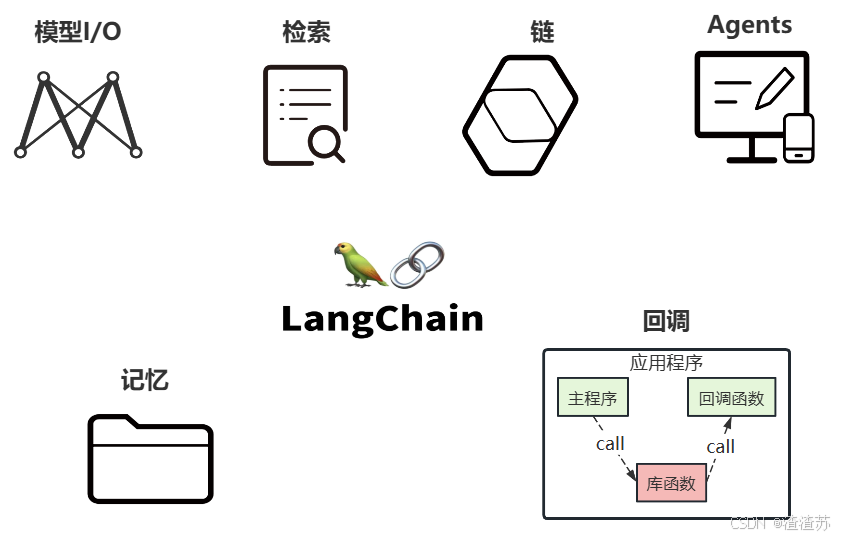
4.3 核心组件的说明
核心组件1:Model I/O
这个模块使用最多,也最简单。
Model I/O:标准化各个大模型的输入和输出,包含输入模版,模型本身和格式化输出。
以下是使用语言模型从输入到输出的基本流程。
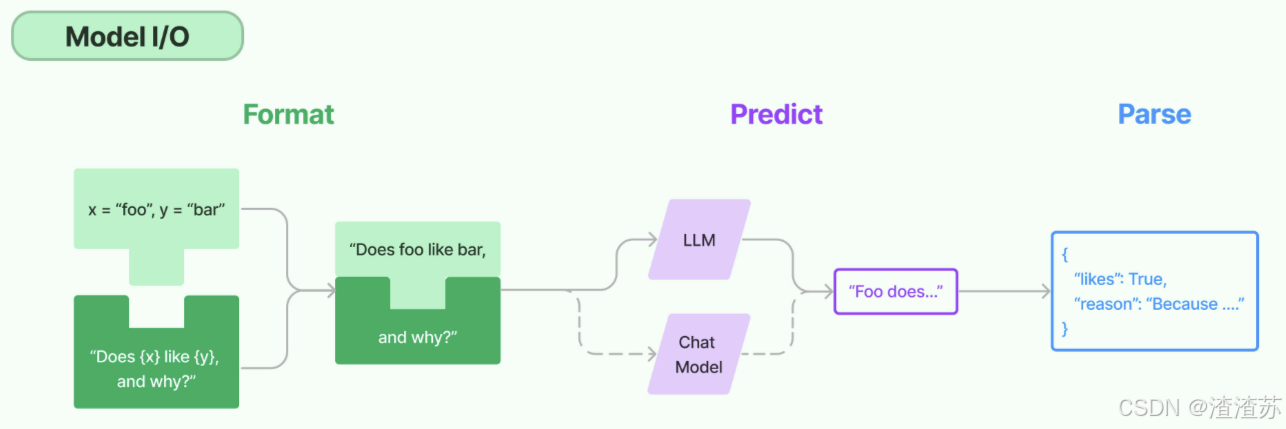
以下是对每一块的总结:
- Format(格式化):即指代Prompts Template,通过模板管理大模型的输入。将原始数据格式化成模型可以处理的形式,插入到一个模板问题中,然后送入模型进行处理。
- Predict(预测):即指代Models,使用通用接口调用不同的大语言模型。接受被送进来的问题,然后基于这个问题进行预测或生成回答。
- Parse(生成):即指代Output Parser部分,用来从模型的推理中提取信息,并按照预先设定好的模版来规范化输出。比如,格式化成一个结构化的JSON对象。
核心组件2:Chains
Chain:"链条",用于将多个模块串联起来组成一个完整的流程,是 LangChain框架中最重要的模块。
例如,一个 Chain 可能包括一个 Prompt 模板、一个语言模型和一个输出解析器,它们一起工作以处理用户输入、生成响应并处理输出。
- 常见的Chain类型 :
LLMChain:最基础的模型调用链SequentialChain:多个链串联执行RouterChain:自动分析用户的需求,引导到最适合的链RetrievalQA:结合向量数据库进行问答的链
核心组件3:Memory
Memory:记忆模块,用于保存对话历史或上下文信息,以便在后续对话中使用。
- 常见的 Memory类型 :
ConversationBufferMemory:保存完整的对话历史ConversationSummaryMemory:保存对话内容的精简摘要(适合长对话)ConversationSummaryBufferMemory:混合型记忆机制VectorStoreRetrieverMemory:保存对话历史存储在向量数据库中
核心组件4:Agents
Agents,对应着智能体,是 LangChain的高阶能力,它可以自主选择工具并规划执行步骤。
- Agent的关键组成 :
AgentType:定义决策逻辑的工作流模式Tool:是一些内置的功能模块,如API调用、搜索引擎、文本处理、数据查询等工具。Agents通过这些工具来执行特定的功能。AgentExecutor:用来运行智能体并执行其决策的工具,负责协调智能体的决策和实际的工具执行。
⽬前最热⻔的智能体开发实践,未来能够真正实现通⽤⼈⼯智能的落地⽅案。
这⾥的Agent,就会涉及到前⾯讲的memory,以及tools。
核心组件5:Retrieval
Retrieval:对应着RAG,检索外部数据,然后在执行生成步骤时将其传递到 LLM。步骤包括文档加载、切割、Embedding等
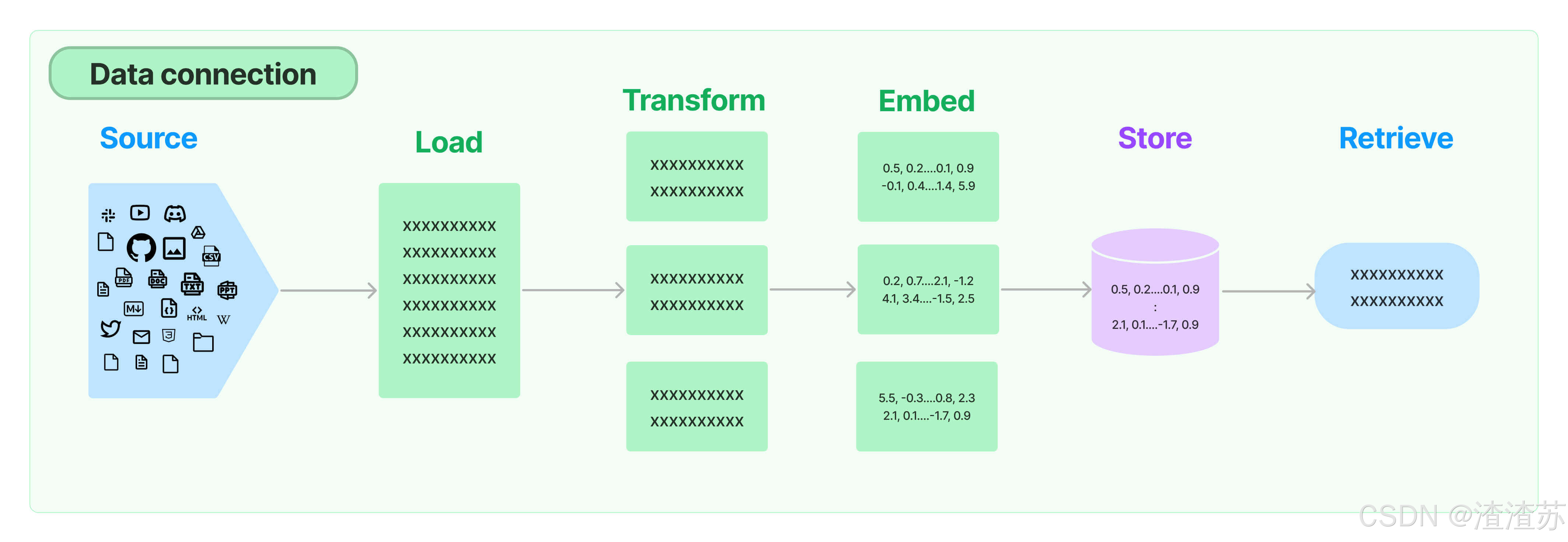
- Source:数据源,即大模型可以识别的多种类型的数据:视频、图片、文本、代码、文档等。
- Load:负责将来自不同数据源的非结构化数据,加载为文档(Document)对象
- Transform:负责对加载的文档进行转换和处理,比如将文本拆分为具有语义意义的小块。
- Embed:将文本编码为向量的能力。一种用于嵌入文档,另一种用于嵌入查询
- Store:将向量化后的数据进行存储
- Retrieve:从大规模文本库中检索和查询相关的文本段落
绿⾊的是⼊库存储前的操作。
核心组件6:Callbacks
Callbacks:回调机制,允许连接到 LLM应用程序的各个阶段,可以监控和分析LangChain的运行情况,比如日志记录、监控、流传输等,以优化性能。
回调函数,对于程序员们应该都不陌⽣。这个函数允许我们在LLM的各个阶段使⽤各种各样的"钩⼦",从而达实现⽇志的记录、监控以及流式传输等功能。
4.4 小结
- Model I/O模块:使用最多,也最简单
- Chains模块:最重要的模块
- Retrieval模块、Agents模块:大模型的主要落地场景
在这个基础上,其它组件要么是它们的辅助,要么只是完成常规应用程序的任务。
- 辅助:比如,向量数据库的分块和嵌入,用于追踪、观测的Callbacks
- 任务:比如,Tools,Memory
我们要做的就是一个一个module去攻破,最后将他们融会贯通,也就成为一名合格的LangChain学习者了。
5、LangChain的helloworld
注意:大家如果想演示如下代码的话,需要准备两个前提:
① 安装必要的库和插件
② 参考后续《02-LangChain使用之Model IO》的2.3.2小结,配置好.env配置文件
建议:如下的helloworld大家看看即可,从下一章开始展开讲解
5.1 获取大模型
python
# 导入 dotenv库的 load_dotenv函数,用于加载环境变量文件(.env)中的配置
import dotenv
from langchain_openai import ChatOpenAI
import os
dotenv.load_dotenv() # 加载当前目录下的.env文件
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY1")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")
# 创建大模型实例
llm = ChatOpenAI(model="gpt-4o-mini") # 默认使用 gpt-3.5-turbo
# 直接提供问题,并调用llm
response = llm.invoke("什么是大模型?")
print(response)其中,需要在当前工程下提供 .env 文件,文件中提供如下信息:
OPENAI_API_KEY1="sk-cvUm8OddQbly.............AGgIHTm9kMH7Bf226G2" # 你自己的密钥
OPENAI_BASE_URL="https://api.openai-proxy.org/v1" # url是固定值,统一写成这样密钥来自于:https://www.closeai-asia.com/
5.2 使用提示词模板
python
from langchain_core.prompts import ChatPromptTemplate
# 需要注意的一点是,这里需要指明具体的role,在这里是system和用户
prompt = ChatPromptTemplate.from_messages([
("system", "你是世界级的技术文档编写者"),
("user", "{input}") # {input}为变量
])
# 我们可以把prompt和具体llm的调用和在一起。
chain = prompt | llm
message = chain.invoke({"input": "大模型中的LangChain是什么?"})
print(message)5.3 使用输出解析器
python
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser, JsonOutputParser
# 初始化模型
llm = ChatOpenAI(model="gpt-4o-mini")
# 创建提示模板
prompt = ChatPromptTemplate.from_messages([
("system", "你是世界级的技术文档编写者。"),
("user", "{input}")
])
# 使用输出解析器
# output_parser = StrOutputParser()
output_parser = JsonOutputParser()
# 将其添加到上一个链中
# chain = prompt | llm
chain = prompt | llm | output_parser
# 调用它并提出同样的问题。答案是一个字符串,而不是ChatMessage
# chain.invoke({"input":"LangChain是什么?"})
chain.invoke({"input": "LangChain是什么?用JSON格式回复,问题用question,回答用answer"})或者
python
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser, JsonOutputParser
# 初始化模型
llm = ChatOpenAI(model="gpt-4o-mini")
# 创建提示模板
prompt = ChatPromptTemplate.from_messages([
("system", "你是世界级的技术文档编写者。输出格式要求:{format_instructions}"),
("user", "{input}")
])
# 使用输出解析器
# output_parser = StrOutputParser()
output_parser = JsonOutputParser()
# 将其添加到上一个链中
# chain = prompt | llm
chain = prompt | llm | output_parser
# 调用它并提出同样的问题。答案是一个字符串,而不是ChatMessage
# chain.invoke({"input":"LangChain是什么?"})
chain.invoke({"input": "LangChain是什么?", "format_instructions": output_parser.get_format_instructions()})5.4 使用向量存储
使用一个简单的本地向量存储 FAISS,首先需要安装它
bash
pip install faiss-cpu
# 或者
conda install faiss-cpu
pip install langchain_community==0.3.7
# 或者
conda install langchain_community==0.3.7
python
# 导入和使用 WebBaseLoader
from langchain_community.document_loaders import WebBaseLoader
import bs4
loader = WebBaseLoader(
web_path="https://www.gov.cn/xinwen/2020-06/01/content_5516649.htm",
bs_kwargs=dict(parse_only=bs4.SoupStrainer(id="UCAP-CONTENT"))
)
docs = loader.load()
# print(docs)
# 对于嵌入模型,这里通过 API调用
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(model="text-embedding-ada-002")
from langchain_community.vectorstores import FAISS
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 使用分割器分割文档
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
documents = text_splitter.split_documents(docs)
print(len(documents))
# 向量存储 embeddings会将 documents中的每个文本片段转换为向量,并将这些向量存储在 FAISS 向量数据库中
vector = FAISS.from_documents(documents, embeddings)5.5 RAG(检索增强生成)
基于外部知识,增强大模型回复
python
from langchain_core.prompts import PromptTemplate
retriever = vector.as_retriever()
retriever.search_kwargs = {"k": 3}
docs = retriever.invoke("建设用地使用权是什么?")
# for i,doc in enumerate(docs):
# print(f"⭐第{i+1}条规定:")
# print(doc)
# 6. 定义提示词模版
prompt_template = """
你是一个问答机器人。你的任务是根据下述给定的已知信息回答用户问题。确保你的回复完全依据下述已知信息。不要编造答案。如果下述已知信息不足以回答用户的问题,请直接回复"我无法回答您的问题"。
已知信息:
{info}
用户问:
{question}
请用中文回答用户问题。
"""
# 7. 得到提示词模版对象
template = PromptTemplate.from_template(prompt_template)
# 8. 得到提示词对象
prompt = template.format(info=docs, question='建设用地使用权是什么?')
# 9. 调用LLM
response = llm.invoke(prompt)
print(response.content)5.6 使用Agent
python
from langchain.tools.retriever import create_retriever_tool
# 检索器工具
retriever_tool = create_retriever_tool(
retriever,
"CivilCodeRetriever",
"搜索有关中华人民共和国民法典的信息。关于中华人民共和国民法典的任何问题,您必须使用此工具!",
)
tools = [retriever_tool]
from langchain import hub
from langchain.agents import create_openai_functions_agent
from langchain.agents import AgentExecutor
# https://smith.langchain.com/hub
prompt = hub.pull("hwchase17/openai-functions-agent")
agent = create_openai_functions_agent(llm, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
# 运行代理
agent_executor.invoke({"input": "建设用地使用权是什么"})第02章:LangChain使用之Model I/O
1、Model I/O介绍
Model I/O 模块是与语言模型(LLMs)进行交互的 核心组件 ,在整个框架中有着很重要的地位。
所谓的Model I/O,包括输入提示(Format)、调用模型(Predict)、输出解析(Parse)。分别对应着Prompt Template , Model 和 Output Parser 。
简单来说,就是输⼊、模型处理、输出这三个步骤
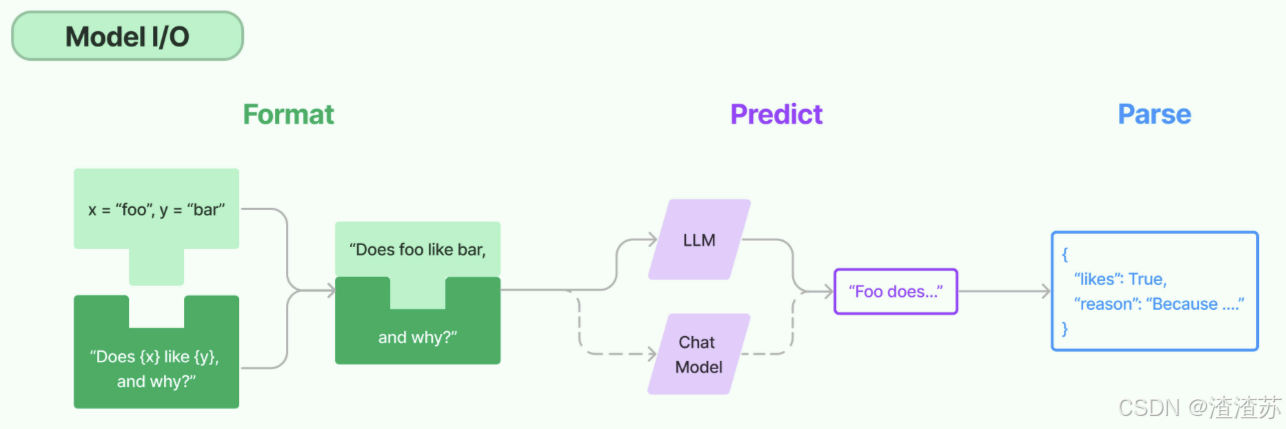
针对每个环节,LangChain都提供了模板和工具,可以快捷的调用各种语言模型的接口。
2、Model I/O之调用模型1
LangChain作为一个"工具",不提供任何 LLMs,而是依赖于第三方集成各种大模型。比如,将OpenAI、Anthropic、Hugging Face 、LlaMA、阿里Qwen、ChatGLM等平台的模型无缝接入到你的应用。
2.1 模型的不同分类方式
简单来说,就是⽤谁家的API以什么⽅式调⽤哪种类型的⼤模型:
角度1:按照模型功能的不同
- 非对话模型 (LLMs/Text Model)
- 对话模型 (Chat Models) (推荐)
- 嵌入模型 (Embedding Models)
角度2:模型调用时,几个重要参数的书写位置的不同
- 硬编码: 写在代码文件中(仅用于临时测试,有密钥泄露风险)。
- 使用环境变量: 密钥与代码分离,适合单机开发。
- 使用配置文件 (推荐): 安全性高,适合生产环境和团队协作。
角度3:具体调用的API
- OpenAI提供的API
- 其它大模型自家提供的API
- LangChain的统一方式调用API (推荐)
背景小知识: OpenAI的GPT系列模型影响了⼤模型技术发展的开发范式和标准。所以⽆论是Qwen、ChatGLM等模型,它们的使⽤⽅法和函数调⽤逻辑基本 遵循OpenAI定义的规范 ,没有太⼤差异。这就使得⼤部分的开源项⽬能够通过⼀个较为通⽤的接口来接⼊和使⽤不同的模型。
2.2 角度1出发:按照功能不同举例
类型1:LLMs (非对话模型)
LLMs,也叫Text Model、非对话模型,是许多语言模型应用程序的支柱。主要特点如下:
- 输入:接受 文本字符串 或 PromptValue 对象
- 输出:总是返回 文本字符串
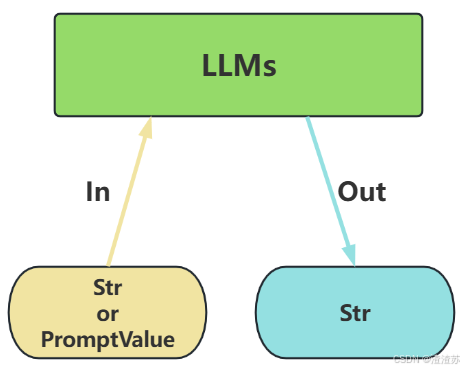
- 适用场景:仅需单次文本生成任务(如摘要生成、翻译、代码生成、单次问答)或对接不支持消息结构的旧模型(如部分本地部署模型)( 言外之意,优先推荐ChatModel )
- 不支持多轮对话上下文。每次调用独立处理输入,无法自动关联历史对话(需手动拼接历史文本)。
- 局限性:无法处理角色分工或复杂对话逻辑。
python
import os
import dotenv
from langchain_openai import OpenAI
dotenv.load_dotenv()
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY1")
os.environ["OPENAI_BASE_URL"] = os.getenv("OPENAI_BASE_URL")
###########核心代码############
llm = OpenAI()
str = llm.invoke("写一首关于春天的诗") # 直接输入字符串
print(str)类型2:Chat Models (对话模型)
ChatModels,也叫聊天模型、对话模型,底层使用LLMs。
大语言模型调用,以 ChatModel 为主!
主要特点如下:
- 输入:接收消息列表 ListBaseMessage 或 PromptValue ,每条消息需指定角色(如SystemMessage、HumanMessage、AIMessage)
- 输出:总是返回带角色的 消息对象 ( BaseMessage 子类),通常是 AIMessage
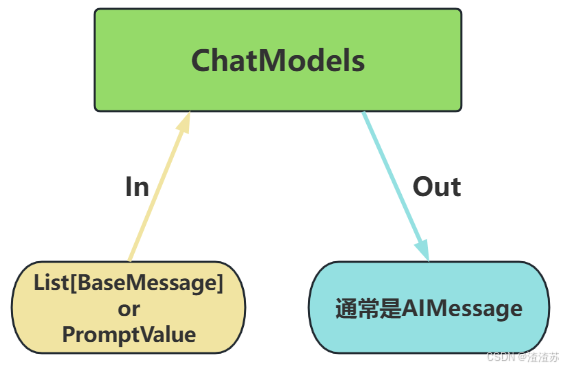
- 原生支持多轮对话。通过消息列表维护上下文(例如: SystemMessage, HumanMessage,AIMessage, ... ),模型可基于完整对话历史生成回复。
- 适用场景:对话系统(如客服机器人、长期交互的AI助手)
python
from langchain_openai import ChatOpenAI
from langchain_core.messages import SystemMessage, HumanMessage
import os
import dotenv
dotenv.load_dotenv()
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY1")
os.environ["OPENAI_BASE_URL"] = os.getenv("OPENAI_BASE_URL")
########核心代码############
chat_model = ChatOpenAI(model="gpt-4o-mini")
messages = [
SystemMessage(content="我是人工智能助手,我叫小智"),
HumanMessage(content="你好,我是小明,很高兴认识你")
]
response = chat_model.invoke(messages)
print(type(response)) # <class 'langchain_core.messages.ai.AIMessage'>
print(response.content)类型3:Embedding Model (嵌入模型)
Embedding Model:也叫文本嵌入模型,这些模型将 文本 作为输入并返回 浮点数列表 ,也就是Embedding。(后面章节《07-LangChain使用之Retrieval》重点讲)
python
from langchain_openai import OpenAIEmbeddings
import os
import dotenv
dotenv.load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY1")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")
embeddings_model = OpenAIEmbeddings(model="text-embedding-ada-002")
res1 = embeddings_model.embed_query('我是文档中的数据')
print(res1)
# 打印结果:[-0.004306625574827194, 0.003083756659179926, -0.013916781172156334, ...., ]2.3 角度2出发:参数位置不同举例
这里以 LangChain 的API为准,使用对话模型,进行测试。
2.3.1 模型调用的主要方法及参数
- 相关方法及属性:
- OpenAI(...) / ChatOpenAI(...) :创建一个模型对象(非对话类/对话类)
- model.invoke(xxx) :执行调用,将用户输入发送给模型
- .content :提取模型返回的实际文本内容
模型调用函数使用时需初始化模型,并设置必要的参数。
-
必须设置的参数:
base_url: API服务的根地址。api_key: 用于身份验证的密钥,由大模型服务商(如 OpenAI、百度千帆)提供model/model_name: 指定要调用的具体大模型名称。
-
其它参数:
-
temperature :温度,控制生成文本的"随机性",取值范围为0~1。
- 值越低 → 输出越确定、保守(适合事实回答)
- 值越高 → 输出越多样、有创意(适合创意写作)
通常,根据需要设置如下:
- 精确模式(0.5或更低):生成的文本更加安全可靠,但可能缺乏创意和多样性。
- 平衡模式(通常是0.8):生成的文本通常既有一定的多样性,又能保持较好的连贯性和准确性。
- 创意模式(通常是1):生成的文本更有创意,但也更容易出现语法错误或不合逻辑的内容。
-
max_tokens: 限制生成文本的最大长度,防止输出过长。Token是什么?
基本单位 : 大模型处理文本的最小单位是token(相当于自然语言中的词或字),输出时逐个token依次生成。
收费依据 :大语言模型(LLM)通常也是以token的数量作为其计量(或收费)的依据。
- 1个Token≈1-1.8个汉字,1个Token≈3-4个英文字母
- Token与字符转化的可视化工具:
max_tokens设置建议:
- 客服短回复:128-256。比如:生成一句客服回复(如"订单已发货,预计明天送达")
- 常规对话、多轮对话:512-1024
- 长内容生成:1024-4096。比如:生成一篇产品说明书(包含功能、使用方法等结构)
-
2.3.2 模型调用推荐平台:closeai
这里推荐使用的平台:
考虑到OpenAI等模型在国内访问及充值的不便,大家可以使用CloseAI网站注册和充值, 具体费用自
理 。
2.3.3 方式1:硬编码
直接将 API Key 和模型参数写入代码,仅适用于临时测试,存在密钥泄露风险,在 生产环境不推荐 。
python
from langchain_openai import ChatOpenAI
# 硬编码 API Key 和模型参数
llm = ChatOpenAI(
api_key="sk-xxxxxxxxx", # 明文暴露密钥
base_url="https://api.openai-proxy.org/v1",
model="gpt-3.5-turbo",
)
# 调用示例
response = llm.invoke("解释神经网络原理")
print(response.content)2.3.4 方式2:配置环境变量
通过系统环境变量存储密钥,避免代码明文暴露。
方式1:终端设置环境变量(临时生效):
bash
export OPENAI_API_KEY="sk-xxxxxxxxxxxxxxxxxxxx" # Linux/Mac
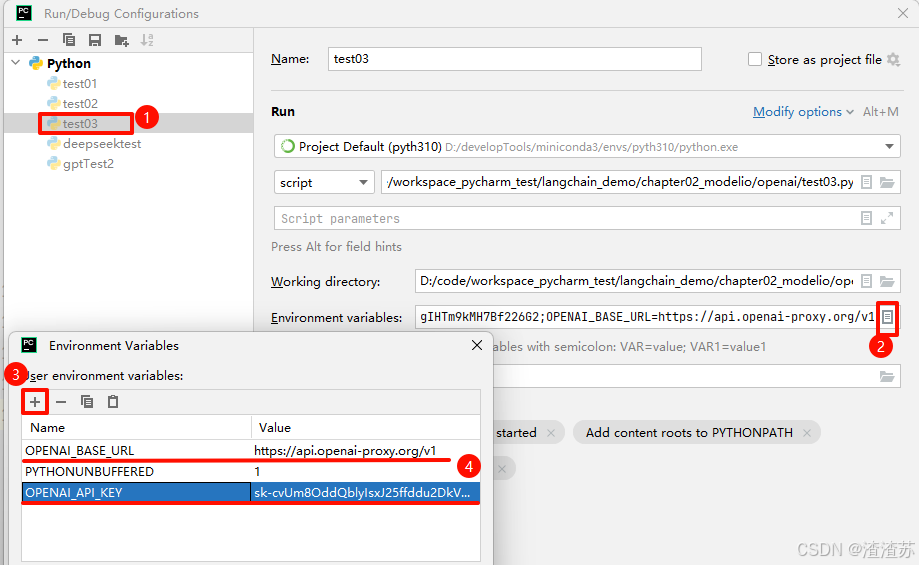
set OPENAI_API_KEY="sk-xxxxxxxxxxxxxxxxxxxx" # Windows方式2:从PyCharm设置
举例:
python
import os
from langchain_openai import ChatOpenAI
# 从环境变量读取密钥
llm = ChatOpenAI(
api_key=os.environ["OPENAI_API_KEY"], # 动态获取
base_url=os.environ["OPENAI_BASE_URL"],
model="gpt-4o-mini",
)
response = llm.invoke("LangChain 是什么?")
print(response.content)优点:密钥与代码分离,适合单机开发
缺点 :切换终端或文件后,变量失效,需重新设置。
2.3.5 方式3:使用.env配置文件 (推荐)
使用 python-dotenv 加载本地配置文件,支持多环境管理。
-
安装依赖:
bashpip install python-dotenv #或者 conda install python-dotenv -
创建
.env文件 (项目根目录):iniOPENAI_API_KEY="sk-xxxxxxxxx" OPENAI_BASE_URL="https://api.openai-proxy.org/v1" -
举例:
pythonfrom dotenv import load_dotenv from langchain_openai import ChatOpenAI import os load_dotenv() # 自动加载 .env 文件 # print(os.getenv("OPENAI_API_KEY")) # print(os.getenv("OPENAI_BASE_URL")) llm = ChatOpenAI( api_key=os.getenv("OPENAI_API_KEY"), # 安全读取 base_url=os.getenv("OPENAI_BASE_URL"), model="gpt-4o-mini", temperature=0.7, ) response = llm.invoke("RAG 技术的核心流程") print(response.content)方式2:给os内部的环境变量赋值
pythonfrom langchain_openai import ChatOpenAI import dotenv dotenv.load_dotenv() import os os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY1") os.environ["OPENAI_API_BASE"] = os.getenv("OPENAI_BASE_URL") text = "猫王是猫吗?" chat_model = ChatOpenAI( model="gpt-4o-mini", temperature=0.7, max_tokens=300, ) response = chat_model.invoke(text) print(type(response)) print(response.content)核心优势:
- 配置文件可加入 .gitignore 避免泄露
- 结合 LangChain 可扩展其它模型(如 DeepSeek、阿里云)
- 生产环境推荐
小结:
| 方式 | 安全性 | 持久性 | 适用场景 |
|---|---|---|---|
| 硬编码 | ⚠低 | ❌临时 | 本地快速测试 |
| 环境变量 | ✅中 | ⚠会话级 | 短期开发调试 |
| .env 配置文件 | ✅✅高 | ✅永久 | 生产环境、团队协作 |
2.4 角度3出发:各平台API的调用举例(了解)
2.4.1 OpenAI 官方API
考虑到OpenAI在国内访问及充值的不便,我们仍然使用CloseAI网站(https://www.closeai-asia.com)注册和充值, 具体费用自理 。
调用非对话模型:
python
from openai import OpenAI
# 从环境变量读取API密钥(推荐安全存储)
client = OpenAI(api_key="sk-zD4CB2Qe7G2Dp6veCfPRSxeDx9fQPxCUIfOFAk20ETV5B2VA", #
填写自己的api-key
base_url="https://api.openai-proxy.org/v1") #通过代码示例获取
# 调用Completion接口
response = client.completions.create(
model="gpt-3.5-turbo-instruct", # 非对话模型
prompt="请将以下英文翻译成中文:\n'Artificial intelligence will reshape the future.'",
max_tokens=100, # 生成文本最大长度
temperature=0.7, # 控制随机性
)
# 提取结果
print(response.choices[0].text.strip())调用对话模型:
写法1:
python
from openai import OpenAI
client = OpenAI(api_key="sk-zD4CB2Qe7G2Dp6veCfPRSxeDx9fQPxCUIfOFAk20ETV5B2VA", #填
写自己的api-key
base_url="https://api.openai-proxy.org/v1")
completion = client.chat.completions.create(
model="gpt-3.5-turbo", # 对话模型
messages=[
{"role": "system", "content": "你是一个乐于助人的智能AI小助手"},
{"role": "user", "content": "你好,请你介绍一下你自己"}
],
max_tokens=150,
temperature=0.5
)
print(completion.choices[0].message)写法2:
python
from openai import OpenAI
import os
import dotenv
dotenv.load_dotenv()
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY1")
os.environ["OPENAI_BASE_URL"] = os.getenv("OPENAI_BASE_URL")
client = OpenAI()
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "我是一位乐于助人的AI智能小助手"},
{"role": "user", "content": "你好,请你介绍一下你自己。"}
]
)
print(response.choices[0])2.4.2 百度千帆平台
开发参考文档:
https://cloud.baidu.com/doc/qianfan-docs/s/Mm8r1mejk
获取API Key和App ID:
创建API Key:https://console.bce.baidu.com/qianfan/ais/console/apiKey
创建App ID:https://console.bce.baidu.com/qianfan/ais/console/applicationConsole/application/v2
代码举例:
python
from openai import OpenAI
client = OpenAI(
api_key="bce-v3/ALTAK-KZke********/f1d6ee*************", # 千帆bearer token
base_url="https://qianfan.baidubce.com/v2", # 千帆域名
default_headers={"appid": "app-MuYR79q6"} # 用户在千帆上的appid,非必传
)
completion = client.chat.completions.create(
model="ernie-4.0-turbo-8k", # 预置服务请查看模型列表,定制服务请填入API地址
messages=[{'role': 'system', 'content': 'You are a helpful assistant.'},
{'role': 'user', 'content': 'Hello!'}]
)
print(completion.choices[0].message)2.4.3 阿里云百炼平台
注册与key的获取:
提前开通百炼平台账号并申请API KEY:https://bailian.console.aliyun.com/#/home
对应的配置文件:
properties
DASHSCOPE_API_KEY="sk-f1a87324#####e6a819a482" #使用自己的api key
DASHSCOPE_BASE_URL="https://dashscope.aliyuncs.com/compatible-mode/v1"模型的调用:
参考具体模型的代码示例。这里以DeepSeek为例:
举例1:通过OpenAI SDK
pip install openai
python
import os
from openai import OpenAI
client = OpenAI(
# 若没有配置环境变量,请用阿里云百炼API Key将下行替换为:api_key="sk-xxx",
api_key=os.getenv("DASHSCOPE_API_KEY"), # 如何获取API Key:
https://help.aliyun.com/zh/model-studio/developer-reference/get-api-key
base_url=os.getenv("DASHSCOPE_BASE_URL")
)
completion = client.chat.completions.create(
model="deepseek-r1", # 此处以 deepseek-r1 为例,可按需更换模型名称。
messages=[
{'role': 'user', 'content': '9.9和9.11谁大'}
]
)
# 通过reasoning_content字段打印思考过程
print("思考过程:")
print(completion.choices[0].message.reasoning_content)
# 通过content字段打印最终答案
print("最终答案:")
print(completion.choices[0].message.content)举例2:通过DashScope SDK
pip install dashscope
python
import os
import dashscope
messages = [
{'role': 'user', 'content': '你是谁?'}
]
response = dashscope.Generation.call(
# 若没有配置环境变量,请用阿里云百炼API Key将下行替换为:api_key="sk-xxx",
api_key=os.getenv('DASHSCOPE_API_KEY'),
model="deepseek-r1", # 此处以 deepseek-r1 为例,可按需更换模型名称。
messages=messages,
# result_format参数不可以设置为"text"。
result_format='message'
)
print("=" * 20 + "思考过程" + "=" * 20)
print(response.output.choices[0].message.reasoning_content)
print("=" * 20 + "最终答案" + "=" * 20)
print(response.output.choices[0].message.content)2.4.4 智谱的GLM
注册智谱模型并获取API Key:
https://www.bigmodel.cn/usercenter/proj-mgmt/apikeys
properties
#记录自己的api key,声明在.env文件中
ZHIPUAI_API_KEY="63a0f275b3a9###############rA4Y8daGaLydxQ"查看《开发文档》
或者选择如下《参考文档》皆可:
https://www.bigmodel.cn/dev/api/normal-model/glm-4
代码举例
举例1:使用OpenAI SDK
python
from openai import OpenAI
client = OpenAI(
api_key=os.getenv("ZHIPUAI_API_KEY"),
base_url=os.getenv("ZHIPUAI_URL")
)
completion = client.chat.completions.create(
model="glm-4-air-250414",
messages=[
{"role": "system", "content": "你是一个聪明且富有创造力的小说作家"},
{"role": "user", "content": "请你作为童话故事大王,写一篇短篇童话故事,故事的主题是要永远
保持一颗善良的心,要能够激发儿童的学习兴趣和想象力,同时也能够帮助儿童更好地理解和接受故事
中所蕴含的道理和价值观。"}
],
top_p=0.7,
temperature=0.9
)
print(completion.choices[0].message)举例2:使用Langchain SDK
python
import os
from langchain_openai import ChatOpenAI
from langchain.prompts import (
ChatPromptTemplate,
MessagesPlaceholder,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from langchain.chains import LLMChain
from langchain.memory import ConversationBufferMemory
llm = ChatOpenAI(
temperature=0.95,
model="glm-4-air-250414",
openai_api_key= os.getenv("ZHIPUAI_API_KEY"),
openai_api_base=os.getenv("ZHIPUAI_URL"),
)
prompt = ChatPromptTemplate(
messages=[
SystemMessagePromptTemplate.from_template(
"You are a nice chatbot having a conversation with a human."
),
MessagesPlaceholder(variable_name="chat_history"),
HumanMessagePromptTemplate.from_template("{question}")
]
)
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
conversation = LLMChain(
llm=llm,
prompt=prompt,
verbose=True,
memory=memory
)
conversation.invoke({"question": "给我讲个冷笑话"})举例3:参考langchain的文档
https://imooc-langchain.shortvar.com/docs/integrations/chat/zhipuai/
安装包:
pip install langchain-community
pip install pyjwt代码示例:
python
import dotenv
from langchain_community.chat_models import ChatZhipuAI
from langchain_core.messages import AIMessage, SystemMessage, HumanMessage
#智谱大模型:参考langchain的大模型
dotenv.load_dotenv()
import os
os.environ["ZHIPUAI_API_KEY"] = os.getenv("ZHIPUAI_API_KEY")
chat = ChatZhipuAI(
model="glm-4",
temperature=0.5,
)
messages = [
AIMessage(content="哈罗~"),
SystemMessage(content="你是一个诗人"),
HumanMessage(content="写一首关于AI的七言绝句"),
]
response = chat.invoke(messages)
print(response.content) # 显示 AI 生成的诗2.4.5 硅基流动平台
官网:https://www.siliconflow.cn/
申请API Key:
python
from openai import OpenAI
client = OpenAI(api_key=os.getenv("SILICON_API_KEY"),
base_url="https://api.siliconflow.cn/v1")
response = client.chat.completions.create(
model='Pro/deepseek-ai/DeepSeek-R1',
# model="Qwen/Qwen2.5-72B-Instruct",
messages=[
{'role': 'user',
'content': "推理模型会给市场带来哪些新的机会"}
],
stream=True
)
for chunk in response:
if not chunk.choices:
continue
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
if chunk.choices[0].delta.reasoning_content:
print(chunk.choices[0].delta.reasoning_content, end="", flush=True)或者:
python
import requests
url = "https://api.siliconflow.cn/v1/chat/completions"
payload = {
"model": "deepseek-ai/DeepSeek-R1", #填写你选择的大模型
"messages": [
{
"role": "user",
"content": "1 +2 * 3 = ?"
}
]
}
headers = {
"Authorization": "Bearer sk-auciaxqpz.....zepozralhwleyrdoyjani", #填写你的api-key
"Content-Type": "application/json"
}
response = requests.post(url, json=payload, headers=headers)
print(response.json())2.5 如何选择合适的大模型
2.5.1 有没有最好的大模型
凡是问「哪个大模型最好?」的,都是不懂的。
不妨反问:「无论做什么,有都表现最好的员工吗?」
划重点:没有最好的大模型,只有最适合的大模型
基础模型选型,合规和安全是首要考量因素!
为什么不要依赖榜单?
- 没有最好的大模型,只有最适合的大模型。合规和安全是首要考量因素。
- 不要过度依赖榜单,因为榜单体现的是整体能力,不一定适用于具体任务,且未体现成本差异。
- 本课程主要以OpenAI为例,因为其流行、先进,且其他模型大多在模仿其范式。
本课程主要以OpenAI为例展开后续的课程。因为:
1、OpenAl 最流行,即便国内也是如此
2、OpenAl 最先进。别的模型有的能力,OpenAI一定都有。OpenAI有的,别的模型不一定有。
3、其它模型都在追赶和模仿OpenAl gpt-4o-mini
学会OpenAl,其它模型触类旁通。反之,不⼀定
2.5.2 小结:获取大模型的标准方式
后续课程将基于以下标准方式初始化模型:
非对话模型:
python
import os
import dotenv
from langchain_openai import OpenAI
dotenv.load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")
llm = OpenAI()对话模型:
python
import os
import dotenv
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")
chat_model = ChatOpenAI(model="gpt-4o-mini")对应的 .env 配置文件:
ini
OPENAI_API_KEY="sk-xxxxxx"
OPENAI_BASE_URL="https://api.openai-proxy.org/v1"3、Model I/O之调用模型2
3.1 关于对话模型的Message(消息)
聊天模型,出了将字符串作为输入外,还可以使用 聊天消息 作为输入,并返回 聊天消息 作为输出。
LangChain内置的消息类型:
SystemMessage: 设定AI行为规则或背景信息。HumanMessage: 表示来自用户的输入。AIMessage: 存储AI回复的内容。ChatMessage: 可以自定义角色的通用消息类型。FunctionMessage/ToolMessage: 用于函数/工具调用结果的消息类型。
注意:
FunctionMessage和ToolMessage分别是在函数调⽤和⼯具调⽤场景下才会使⽤的特殊消息类型,HumanMessage、AIMessage和SystemMessage才是最常⽤的消息类型。
举例1:
python
from langchain_core.messages import HumanMessage, SystemMessage
messages = [SystemMessage(content="你是一位乐于助人的智能小助手"),
HumanMessage(content="你好,请你介绍一下你自己"),]
print(messages)举例2:
python
from langchain_core.messages import HumanMessage, AIMessage, SystemMessage
messages = [
SystemMessage(content=["你是一个数学家,只会回答数学问题","每次你都能给出详细的方案"]),
HumanMessage(content="1 + 2 * 3 = ?"),
AIMessage(content="1 + 2 * 3 的结果是7"),
]
print(messages)举例3:
python
#1.导入相关包
from langchain_core.messages import SystemMessage, HumanMessage, AIMessage
# 2.直接创建不同类型消息
systemMessage = SystemMessage(
content="你是一个AI开发工程师",
additional_kwargs={"tool": "invoke_tool()"}
)
humanMessage = HumanMessage(
content="你能开发哪些AI应用?"
)
aiMessage = AIMessage(
content="我能开发很多AI应用, 比如聊天机器人, 图像识别, 自然语言处理等"
)
# 3.打印消息列表
messages = [systemMessage,humanMessage,aiMessage]
print(messages)举例4:
python
from langchain_core.messages import (
AIMessage,
HumanMessage,
SystemMessage,
ChatMessage
)
# 创建不同类型的消息
system_message = SystemMessage(content="你是一个专业的数据科学家")
human_message = HumanMessage(content="解释一下随机森林算法")
ai_message = AIMessage(content="随机森林是一种集成学习方法...")
custom_message = ChatMessage(role="analyst", content="补充一点关于超参数调优的信息")
print(system_message.content)
print(human_message.content)
print(ai_message.content)
print(custom_message.content)举例5:结合大模型使用
python
import os
from langchain_core.messages import SystemMessage,HumanMessage
dotenv.load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")
chat_model = ChatOpenAI(
model="gpt-4o-mini",
)
# 组成消息列表
messages = [
SystemMessage(content="你是一个擅长人工智能相关学科的专家"),
HumanMessage(content="请解释一下什么是机器学习?")
]
response = chat_model.invoke(messages)
print(response.content)
print(type(response)) #<class 'langchain_core.messages.ai.AIMessage'>3.2 关于多轮对话与上下文记忆
前提:获取大模型
python
import os
import dotenv
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY1")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")
chat_model = ChatOpenAI(
model="gpt-4o-mini"
)测试1:
python
from langchain_core.messages import SystemMessage, HumanMessage
sys_message = SystemMessage(
content="我是一个人工智能的助手,我的名字叫小智",
)
human_message = HumanMessage(content="猫王是一只猫吗?")
messages = [sys_message, human_message]
#调用大模型,传入messages
response = chat_model.invoke(messages)
print(response.content)
response1 = chat_model.invoke("你叫什么名字?")
print(response1.content)测试2:
python
from langchain_core.messages import SystemMessage, HumanMessage
sys_message = SystemMessage(
content="我是一个人工智能的助手,我的名字叫小智",
)
human_message = HumanMessage(content="猫王是一只猫吗?")
human_message1 = HumanMessage(content="你叫什么名字?")
messages = [sys_message, human_message,human_message1]
#调用大模型,传入messages
response = chat_model.invoke(messages)
print(response.content)测试3:
python
from langchain_core.messages import SystemMessage, HumanMessage
sys_message = SystemMessage(
content="我是一个人工智能的助手,我的名字叫小智",
)
human_message = HumanMessage(content="猫王是一只猫吗?")
sys_message1 = SystemMessage(
content="我可以做很多事情,有需要就找我吧",
)
human_message1 = HumanMessage(content="你叫什么名字?")
messages = [sys_message, human_message,sys_message1,human_message1]
#调用大模型,传入messages
response = chat_model.invoke(messages)
print(response.content)测试4:
python
from langchain_core.messages import SystemMessage, HumanMessage
# 第1组
sys_message = SystemMessage(
content="我是一个人工智能的助手,我的名字叫小智",
)
human_message = HumanMessage(content="猫王是一只猫吗?")
messages = [sys_message, human_message]
# 第2组
sys_message1 = SystemMessage(
content="我可以做很多事情,有需要就找我吧",
)
human_message1 = HumanMessage(content="你叫什么名字?")
messages1 = [sys_message1,human_message1]
#调用大模型,传入messages
response = chat_model.invoke(messages)
print(response.content)
response = chat_model.invoke(messages1)
print(response.content)测试5:
python
from langchain_core.messages import SystemMessage, HumanMessage, AIMessage
messages = [
SystemMessage(content="我是一个人工智能助手,我的名字叫小智"),
HumanMessage(content="人工智能英文怎么说?"),
AIMessage(content="AI"),
HumanMessage(content="你叫什么名字"),
]
messages1 = [
SystemMessage(content="我是一个人工智能助手,我的名字叫小智"),
HumanMessage(content="很高兴认识你"),
AIMessage(content="我也很高兴认识你"),
HumanMessage(content="你叫什么名字"),
]
messages2 = [
SystemMessage(content="我是一个人工智能助手,我的名字叫小智"),
HumanMessage(content="人工智能英文怎么说?"),
AIMessage(content="AI"),
HumanMessage(content="你叫什么名字"),
]
chat_model.invoke(messages2)3.3 关于模型调用的方法
为了尽可能简化自定义链的创建,我们实现了一个"Runnable"协议。许多LangChain组件实现了Runnable 协议,包括聊天模型、提示词模板、输出解析器、检索器、代理(智能体)等。
Runnable 定义的公共的调用方法如下:
invoke: 处理单条输入,等待LLM完全推理完成后再返回调用结果。stream: 流式响应,逐字输出LLM的响应结果batch: 处理批量输入。
还有对应的异步方法,应该与 asyncio 的 await 语法一起使用以实现并发:
- astream : 异步流式响应
- ainvoke : 异步处理单条输入
- abatch : 异步处理批量输入
- astream_log : 异步流式返回中间步骤,以及最终响应
- astream_events : (测试版)异步流式返回链中发生的事件(在 langchain-core 0.1.14 中引入)
3.3.1 流式输出与非流式输出
在Langchain中,语言模型的输出分为了两种主要的模式:流式输出与非流式输出。
下面是两个场景:
-
非流式输出:这是Langchain与LLM交互时的 默认行为 ,是最简单、最稳定的语言模型调用方式。
当用户发出请求后,系统在后台等待模型 生成完整响应 ,然后 一次性将全部结果返回 。
- 举例:用户提问,请编写一首诗,系统在静默数秒后 突然弹出 了完整的诗歌。(体验较单调)
- 在大多数问答、摘要、信息抽取类任务中,非流式输出提供了结构清晰、逻辑完整的结果,适合快速集成和部署。
-
流式输出:一种 更具交互感 的模型输出方式,用户不再需要等待完整答案,而是能看到模型 逐个token 地实时返回内容。
- 举例:用户提问,请编写一首诗,当问题刚刚发送,系统就开始 一字一句 (逐个token)进行回复,感觉是一边思考一边输出。
- 更像是"实时对话",更为贴近人类交互的习惯,更有吸引力。
- 适合构建强调"实时反馈"的应用,如聊天机器人、写作助手等。
- Langchain 中通过设置 stream=True 并配合 回调机制 来启用流式输出。
-
非流式输出: 默认行为,等待模型生成完整响应后一次性返回。
pythonimport os import dotenv from langchain_core.messages import HumanMessage from langchain_openai import ChatOpenAI dotenv.load_dotenv() os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY1") os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL") #初始化大模型 chat_model = ChatOpenAI(model="gpt-4o-mini") # 创建消息 messages = [HumanMessage(content="你好,请介绍一下自己")] # 非流式调用LLM获取响应 response = chat_model.invoke(messages) # 打印响应内容 print(response)输出结果如下,是直接全部输出的。
举例2:
pythonimport os import dotenv from langchain_core.messages import HumanMessage, SystemMessage from langchain_openai import ChatOpenAI dotenv.load_dotenv() os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY1") os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL") # 初始化大模型 chat_model = ChatOpenAI(model="gpt-4o-mini") # 支持多个消息作为输入 messages = [ SystemMessage(content="你是一位乐于助人的助手。你叫于老师"), HumanMessage(content="你是谁?") ] response = chat_model.invoke(messages) print(response.content)举例3:
pythonimport os import dotenv from langchain_core.messages import HumanMessage, SystemMessage from langchain_openai import ChatOpenAI dotenv.load_dotenv() 1 os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY1") os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL") # 初始化大模型 chat_model = ChatOpenAI(model="gpt-4o-mini") # 支持多个消息作为输入 messages = [ SystemMessage(content="你是一位乐于助人的助手。你叫于老师"), HumanMessage(content="你是谁?") ] response = chat_model(messages) #特别的写法 print(response.content)第19行,底层调用 BaseChatModel.call ,内部调用的还是invoke()。后续还会有这种写法出现,了解即可。
-
流式输出:
一种更具交互感的模型输出方式,用户不再需要等待完整答案,而是能看到模型逐个 token 地实时返回内容。适合构建强调"实时反馈"的应用,如聊天机器人、写作助手等。
Langchain 中通过设置 streaming=True 并配合 回调机制 来启用流式输出。
pythonimport os import dotenv from langchain_core.messages import HumanMessage from langchain_openai import ChatOpenAI dotenv.load_dotenv() os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY") os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL") # 初始化大模型 chat_model = ChatOpenAI(model="gpt-4o-mini", streaming=True # 启用流式输出 ) # 创建消息 messages = [HumanMessage(content="你好,请介绍一下自己")] # 流式调用LLM获取响应 print("开始流式输出:") for chunk in chat_model.stream(messages): # 逐个打印内容块 print(chunk.content, end="", flush=True) # 刷新缓冲区 (无换行符,缓冲区未刷新,内容可能不会 立即显示) print("\n流式输出结束")输出结果如下(一段段文字逐个输出)
3.3.2 批量调用
python
import os
import dotenv
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")
# 初始化大模型
chat_model = ChatOpenAI(model="gpt-4o-mini")
messages1 = [SystemMessage(content="你是一位乐于助人的智能小助手"),
HumanMessage(content="请帮我介绍一下什么是机器学习"), ]
messages2 = [SystemMessage(content="你是一位乐于助人的智能小助手"),
HumanMessage(content="请帮我介绍一下什么是AIGC"), ]
messages3 = [SystemMessage(content="你是一位乐于助人的智能小助手"),
HumanMessage(content="请帮我介绍一下什么是大模型技术"), ]
messages = [messages1, messages2, messages3]
# 调用batch
response = chat_model.batch(messages)
print(response)3.3.3 同步调用与异步调用 (了解)
invoke是同步调用。
python
import time
def call_model():
# 模拟同步API调用
print("开始调用模型...")
time.sleep(5) # 模拟调用等待,单位:秒
print("模型调用完成。")
def perform_other_tasks():
# 模拟执行其他任务
for i in range(5):
print(f"执行其他任务 {i + 1}")
time.sleep(1) # 单位:秒
def main():
start_time = time.time()
call_model()
perform_other_tasks()
end_time = time.time()
total_time = end_time - start_time
return f"总共耗时:{total_time}秒"
# 运行同步任务并打印完成时间
main_time = main()
print(main_time)之前的 llm.invoke(...) 本质上是一个同步调用。每个操作依次执行,直到当前操作完成后才开始下一个操作,从而导致总的执行时间是各个操作时间的总和。
-
ainvoke是异步调用,可以使用asyncio并发执行多个请求,提高效率。异步调用,允许程序在等待某些操作完成时继续执行其他任务,而不是阻塞等待。这在处理I/O操作(如网络请求、文件读写等)时特别有用,可以显著提高程序的效率和响应性。
举例:
写法1:此写法适合Jupyter Notebook
python
import asyncio
import time
async def async_call(llm):
await asyncio.sleep(5) # 模拟异步操作
print("异步调用完成")
async def perform_other_tasks():
await asyncio.sleep(5) # 模拟异步操作
print("其他任务完成")
async def run_async_tasks():
start_time = time.time()
await asyncio.gather(
async_call(None), # 示例调用,使用None模拟LLM对象
perform_other_tasks()
)
end_time = time.time()
return f"总共耗时:{end_time - start_time}秒"
# # 正确运行异步任务的方式
# if __name__ == "__main__":
# # 使用 asyncio.run() 来启动异步程序
# result = asyncio.run(run_async_tasks())
# print(result)
# 在 Jupyter 单元格中直接调用
result = await run_async_tasks()
print(result)写法2:(此写法不适合Jupyter Notebook)
python
import asyncio
import time
async def async_call(llm):
await asyncio.sleep(5) # 模拟异步操作
print("异步调用完成")
async def perform_other_tasks():
await asyncio.sleep(5) # 模拟异步操作
print("其他任务完成")
async def run_async_tasks():
start_time = time.time()
await asyncio.gather(
async_call(None), # 示例调用,替换None为模拟的LLM对象
perform_other_tasks()
)
end_time = time.time()
return f"总共耗时:{end_time - start_time}秒"
# 正确运行异步任务的方式
if __name__ == "__main__":
# 使用 asyncio.run() 来启动异步程序
result = asyncio.run(run_async_tasks())
print(result)使用 asyncio.gather() 并行执行时,理想情况下,因为两个任务几乎同时开始,它们的执行时间将重叠。如果两个任务的执行时间相同(这里都是5秒),那么总执行时间应该接近单个任务的执行时间,而不是两者时间之和。
异步调用之ainvoke
举例1:验证ainvoke是否是异步
python
# 方式1
import inspect
print("ainvoke 是协程函数:", inspect.iscoroutinefunction(chat_model.ainvoke))
print("invoke 是协程函数:", inspect.iscoroutinefunction(chat_model.invoke))举例2:(不能在Jupyter Notebook中测试)
python
import asyncio
import os
import time
import dotenv
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY1")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")
# 初始化大模型
chat_model = ChatOpenAI(model="gpt-4o-mini")
# 同步调用(对比组)
def sync_test():
messages1 = [SystemMessage(content="你是一位乐于助人的智能小助手"),
HumanMessage(content="请帮我介绍一下什么是机器学习"), ]
start_time = time.time()
response = chat_model.invoke(messages1) # 同步调用
duration = time.time() - start_time
print(f"同步调用耗时:{duration:.2f}秒")
return response, duration
# 异步调用(实验组)
async def async_test():
messages1 = [SystemMessage(content="你是一位乐于助人的智能小助手"),
HumanMessage(content="请帮我介绍一下什么是机器学习"), ]
start_time = time.time()
response = await chat_model.ainvoke(messages1) # 异步调用
duration = time.time() - start_time
print(f"异步调用耗时:{duration:.2f}秒")
return response, duration
# 运行测试
if __name__ == "__main__":
# 运行同步测试
sync_response, sync_duration = sync_test()
print(f"同步响应内容: {sync_response.content[:100]}...\n")
# 运行异步测试
async_response, async_duration = asyncio.run(async_test())
print(f"异步响应内容: {async_response.content[:100]}...\n")
# 并发测试 - 修复版本
print("\n=== 并发测试 ===")
start_time = time.time()
async def run_concurrent_tests():
# 创建3个异步任务
tasks = [async_test() for _ in range(3)]
# 并发执行所有任务
return await asyncio.gather(*tasks)
# 执行并发测试
results = asyncio.run(run_concurrent_tests())
total_time = time.time() - start_time
print(f"\n3个并发异步调用总耗时: {total_time:.2f}秒")
print(f"平均每个调用耗时: {total_time / 3:.2f}秒")4、Model I/O之Prompt Template
Prompt Template用于通过模板管理大模型的输入,使提示词更加灵活和结构化。
4.1 介绍与分类
Prompt Template 是LangChain中的一个概念,接收用户输入,返回一个传递给LLM的信息(即提示词prompt)。
在应用开发中,固定的提示词限制了模型的灵活性和适用范围。所以,prompt template 是一个 模板化的字符串 ,你可以将 变量插入到模板 中,从而创建出不同的提示。调用时:
- 以 字典 作为输入,其中每个键代表要填充的提示模板中的变量。
- 输出一个 PromptValue 。这个 PromptValue 可以传递给 LLM 或 ChatModel,并且还可以转换为字符串或消息列表。
有几种不同类型的提示模板:
- PromptTemplate :LLM提示模板,用于生成字符串提示。它使用 Python 的字符串来模板提示。
- ChatPromptTemplate :聊天提示模板,用于组合各种角色的消息模板,传入聊天模型。
- XxxMessagePromptTemplate :消息模板词模板,包括:SystemMessagePromptTemplate、HumanMessagePromptTemplate、AIMessagePromptTemplate、ChatMessagePromptTemplate等
- FewShotPromptTemplate :样本提示词模板,通过示例来教模型如何回答
- PipelinePrompt :管道提示词模板,用于把几个提示词组合在一起使用。
- 自定义模板 :允许基于其它模板类来定制自己的提示词模板。
模版导入
python
from langchain.prompts.prompt import PromptTemplate
from langchain.prompts import ChatPromptTemplate
from langchain.prompts import FewShotPromptTemplate
from langchain.prompts.pipeline import PipelinePromptTemplate
from langchain.prompts import (
ChatMessagePromptTemplate,
SystemMessagePromptTemplate,
AIMessagePromptTemplate,
HumanMessagePromptTemplate,
)4.2 复习:str.format()
Python的 str.format() 方法是一种字符串格式化的手段,允许在 字符串中插入变量 。使用这种方法,可以创建包含 占位符 的字符串模板,占位符由花括号 {} 标识。
- 调用format()方法时,可以传入一个或多个参数,这些参数将被顺序替换进占位符中。
- str.format()提供了灵活的方式来构造字符串,支持多种格式化选项。
在LangChain的默认设置下, PromptTemplate 使用 Python 的 str.format() 方法进行模板化。这样在模型接收输入前,可以根据需要对数据进行预处理和结构化。
带有位置参数的用法
python
# 使用位置参数
info = "Name: {0}, Age: {1}".format("Jerry", 25)
print(info)带有关键字参数的用法
python
# 使用关键字参数
info = "Name: {name}, Age: {age}".format(name="Tom", age=25)
print(info)使用字典解包的方式
python
# 使用字典解包
person = {"name": "David", "age": 40}
info = "Name: {name}, Age: {age}".format(**person)
print(info)4.3 具体使用:PromptTemplate
4.3.1 使用说明
PromptTemplate类,用于快速构建 包含变量 的提示词模板,并通过 传入不同的参数值 生成自定义的提示词。
主要参数介绍:
- template:定义提示词模板的字符串,其中包含 文本 和 变量占位符(如{name}) ;
- input_variables: 列表,指定了模板中使用的变量名称,在调用模板时被替换;
- partial_variables:字典,用于定义模板中一些固定的变量名。这些值不需要再每次调用时被替换。
函数介绍:
- format():给input_variables变量赋值,并返回提示词。利用format() 进行格式化时就一定要赋值,否则会报错。当在template中未设置input_variables,则会自动忽略。
4.3.2 两种实例化方式
方式1:构造方法
python
from langchain.prompts import PromptTemplate
# 定义模板:描述主题的应用
template = PromptTemplate(template="请简要描述{topic}的应用。",
input_variables=["topic"])
print(template)
# 使用模板生成提示词
prompt_1 = template.format(topic="机器学习")
prompt_2 = template.format(topic="自然语言处理")
print("提示词1:", prompt_1)
print("提示词2:", prompt_2)可以直观的看到PromptTemplate可以将template中声明的变量topic准确提取出来,使prompt更清晰。
举例2:定义多变量模板
python
from langchain.prompts import PromptTemplate
#定义多变量模板
template = PromptTemplate(
template="请评价{product}的优缺点,包括{aspect1}和{aspect2}。",
input_variables=["product", "aspect1", "aspect2"])
#使用模板生成提示词
prompt_1 = template.format(product="智能手机", aspect1="电池续航", aspect2="拍照质量")
prompt_2 = template.format(product="笔记本电脑", aspect1="处理速度", aspect2="便携性")
print("提示词1:",prompt_1)
print("提示词2:",prompt_2)方式2:调用from_template()
举例1:
python
from langchain.prompts import PromptTemplate
prompt_template = PromptTemplate.from_template(
"请给我一个关于{topic}的{type}解释。"
)
#传入模板中的变量名
prompt = prompt_template.format(type="详细", topic="量子力学")
print(prompt)举例2:模板支持任意数量的变量,包括不含变量:
python
#1.导入相关的包
from langchain_core.prompts import PromptTemplate
# 2.定义提示词模版对象
text = """
Tell me a joke
"""
prompt_template = PromptTemplate.from_template(text)
# 3.默认使用f-string进行格式化(返回格式好的字符串)
prompt = prompt_template.format()
print(prompt)4.3.3 两种新的结构形式
- 部分提示词模板 : 使用
partial_variables或.partial()方法预填充部分变量。 - 组合提示词 : 使用
+操作符连接多个模板。
形式1:部分提示词模版
在生成prompt前就已经提前初始化部分的提示词,实际进一步导入模版的时候只导入除已初始化的变量即可。
举例1:
方式1:实例化过程中使用partial_variables变量
python
from langchain.prompts import PromptTemplate
#方式2:
template2 = PromptTemplate(
template="{foo}{bar}",
input_variables=["foo","bar"],
partial_variables={"foo": "hello"}
)
prompt2 = template2.format(bar="world")
print(prompt2)方式2:使用 PromptTemplate.partial() 方法创建部分提示模板
python
from langchain.prompts import PromptTemplate
template1 = PromptTemplate(
template="{foo}{bar}",
input_variables=["foo", "bar"]
)
#方式1:
partial_template1 = template1.partial(foo="hello")
prompt1 = partial_template1.format(bar="world")
print(prompt1)举例2:
python
from langchain_core.prompts import PromptTemplate
# 完整模板
full_template = """你是一个{role},请用{style}风格回答:
问题:{question}
答案:"""
# 预填充角色和风格
partial_template = PromptTemplate.from_template(full_template).partial(
role="资深厨师",
style="专业但幽默"
)
# 只需提供剩余变量
print(partial_template.format(question="如何煎牛排?"))举例3:
python
prompt_template = PromptTemplate.from_template(
template = "请评价{product}的优缺点,包括{aspect1}和{aspect2}。",
partial_variables= {"aspect1":"电池","aspect2":"屏幕"}
)
prompt= prompt_template.format(product="笔记本电脑")
print(prompt)形式2:组合提示词(了解)
举例:
python
from langchain_core.prompts import PromptTemplate
template = (
PromptTemplate.from_template("Tell me a joke about {topic}")
+ ", make it funny"
+ "\n\nand in {language}"
)
prompt = template.format(topic="sports", language="spanish")
print(prompt)4.3.4 format()与invoke()
只要对象是RunnableSerializable接口类型,都可以使用invoke(),替换前面使用format()的调用方式
format(),返回值为字符串类型;invoke(),返回值为PromptValue类型,接着调用to_string()返回字符串。
举例1:
python
#1.导入相关的包
from langchain_core.prompts import PromptTemplate
# 2.定义提示词模版对象
prompt_template = PromptTemplate.from_template(
"Tell me a {adjective} joke about {content}."
)
# 3.默认使用f-string进行格式化(返回格式好的字符串)
prompt_template.invoke({"adjective":"funny", "content":"chickens"})举例2:
python
#1.导入相关的包
from langchain_core.prompts import PromptTemplate
# 2.使用初始化器进行实例化
prompt = PromptTemplate(
input_variables=["adjective", "content"],
template="Tell me a {adjective} joke about {content}")
# 3. PromptTemplate底层是RunnableSerializable接口 所以可以直接使用invoke()调用
prompt.invoke({"adjective": "funny", "content": "chickens"})举例3:
python
from langchain_core.prompts import PromptTemplate
prompt_template = (
PromptTemplate.from_template("Tell me a joke about {topic}")
+ ", make it funny"
+ " and in {language}"
)
prompt = prompt_template.invoke({"topic":"sports", "language":"spanish"})
print(prompt)4.3.5 结合LLM调用
Prompt 与大模型结合。
问题:这里的大模型,是哪类呢?非对话大模型?对话大模型?
提供大模型:(非对话大模型)
python
import os
import dotenv
from langchain_openai import OpenAI
dotenv.load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY1")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")
llm = OpenAI()提供大模型:(对话大模型)
python
import os
import dotenv
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY1")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")
llm = ChatOpenAI(
model="gpt-4o-mini"
)调用过程:
python
prompt_template = PromptTemplate.from_template(
template = "请评价{product}的优缺点,包括{aspect1}和{aspect2}。"
)
prompt = prompt_template.format(product="电脑",aspect1="性能",aspect2="电池")
# prompt = prompt_template.invoke({"product":"电脑","aspect1":"性能","aspect2":"电池"})
print(type(prompt))
# llm.invoke(prompt) #使用非对话模型调用
llm1.invoke(prompt) #使用对话模型调用4.4 具体使用:ChatPromptTemplate
专为聊天模型设计,用于创建消息列表。
4.4.1 使用说明
ChatPromptTemplate是创建 聊天消息列表 的提示模板。它比普通 PromptTemplate 更适合处理多角色、多轮次的对话场景。
特点:
- 支持 System / Human / AI 等不同角色的消息模板
- 对话历史维护
参数类型:列表参数格式是tuple类型( role :str content :str 组合最常用)
元组的格式为:(role: str | type, content: str | listdict | listobject)
- 其中 role 是:字符串(如 "system" 、 "human" 、 "ai" )
4.4.2 两种实例化方式
方式1:使用构造方法
举例:
python
from langchain_core.prompts import ChatPromptTemplate
#参数类型这里使用的是tuple构成的list
prompt_template = ChatPromptTemplate([
# 字符串 role + 字符串 content
("system", "你是一个AI开发工程师. 你的名字是 {name}."),
("human", "你能开发哪些AI应用?"),
("ai", "我能开发很多AI应用, 比如聊天机器人, 图像识别, 自然语言处理等."),
("human", "{user_input}")
])
#调用format()方法,返回字符串
prompt = prompt_template.invoke(input={"name":"小谷AI","user_input":"你能帮我做什么?"})
print(type(prompt))
print(prompt)方式2:调用from_messages()
举例1:
python
# 导入相关依赖
from langchain_core.prompts import ChatPromptTemplate
# 定义聊天提示词模版
chat_template = ChatPromptTemplate.from_messages(
[
("system", "你是一个有帮助的AI机器人,你的名字是{name}。"),
("human", "你好,最近怎么样?"),
("ai", "我很好,谢谢!"),
("human", "{user_input}"),
]
)
# 格式化聊天提示词模版中的变量
messages = chat_template.invoke(input={"name":"小明", "user_input":"你叫什么名字?"})
# 打印格式化后的聊天提示词模版内容
print(messages)举例2:了解
python
# 示例 1: role 为字符串
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个{role}."),
("human", "{user_input}"),
])
# 示例 2: role 为消息类 不支持
from langchain_core.messages import SystemMessage, HumanMessage
# prompt = ChatPromptTemplate.from_messages([
# (SystemMessage, "你是一个{role}."), # 类对象 role + 字符串 content
# (HumanMessage, ["你好!", {"type": "text"}]), # 类对象 role + list[dict] content
# ])
# 修改
prompt = ChatPromptTemplate.from_messages([
("system", ["你好!", {"type": "text"}]), # 字符串 role + list[dict] content
])4.4.3 模板调用的几种方式对比
invoke(): 返回ChatPromptValue对象。format(): 返回格式化后的字符串。format_messages(): 推荐 ,返回可以直接传给聊天模型的消息列表List[BaseMessage]。format_prompt(): 返回PromptValue对象。
方式1:使用 invoke(),前面已经讲过
python
from langchain_core.prompts import ChatPromptTemplate
#参数类型这里使用的是tuple构成的list
prompt_template = ChatPromptTemplate([
# 字符串 role + 字符串 content
("system", "你是一个AI开发工程师. 你的名字是 {name}."),
("human", "你能开发哪些AI应用?"),
("ai", "我能开发很多AI应用, 比如聊天机器人, 图像识别, 自然语言处理等."),
("human", "{user_input}")
])
prompt = prompt_template.invoke({"name":"小谷AI", "user_input":"你能帮我做什么?"})
print(type(prompt))
print(prompt)
print(len(prompt.messages))方式2:使用format()
python
from langchain_core.prompts import ChatPromptTemplate
#参数类型这里使用的是tuple构成的list
prompt_template = ChatPromptTemplate([
# 字符串 role + 字符串 content
("system", "你是一个AI开发工程师. 你的名字是 {name}."),
("human", "你能开发哪些AI应用?"),
("ai", "我能开发很多AI应用, 比如聊天机器人, 图像识别, 自然语言处理等."),
("human", "{user_input}")
])
#方式1:调用format()方法,返回字符串
prompt = prompt_template.format(name="小谷AI", user_input="你能帮我做什么?")
print(type(prompt))
print(prompt)方式3:使用format_messages()
python
from langchain_core.prompts import ChatPromptTemplate
prompt_template = ChatPromptTemplate([
("system", "你是一个AI开发工程师. 你的名字是 {name}."),
("human", "你能开发哪些AI应用?"),
("ai", "我能开发很多AI应用, 比如聊天机器人, 图像识别, 自然语言处理等."),
("human", "{user_input}")
])
#调用format_messages()方法,返回消息列表
prompt2 = prompt_template.format_messages(name="小谷AI", user_input="你能帮我做什么?")
print(type(prompt2))
print(prompt2)结论:给占位符赋值,针对于ChatPromptTemplate,推荐使用 format_messages() 方法,返回消息列表。
方式4:使用format_prompt()
python
from langchain_core.prompts import ChatPromptTemplate
#参数类型这里使用的是tuple构成的list
prompt_template = ChatPromptTemplate([
# 字符串 role + 字符串 content
("system", "你是一个AI开发工程师. 你的名字是 {name}."),
("human", "你能开发哪些AI应用?"),
("ai", "我能开发很多AI应用, 比如聊天机器人, 图像识别, 自然语言处理等."),
("human", "{user_input}")
])
prompt = prompt_template.format_prompt(name="小谷AI", user_input="你能帮我做什么?")
print(prompt.to_messages())
print(type(prompt.to_messages()))
#print(prompt.to_string())
#print(type(prompt.to_string()))4.4.4 更丰富的实例化参数类型
前面讲了ChatPromptTemplate的两种创建方式。我们看到不管使用构造方法,还是使用from_messages(),参数类型都是 列表类型 。列表中的元素可以是多种类型,前面我们主要测试了元组类型。
源码:
python
def __init__(self,
messages: Sequence[BaseMessagePromptTemplate | BaseMessage |
BaseChatPromptTemplate | tuple[str | type, str | list[dict] | list[object]] | str | dict[str, Any]],
*,
template_format: Literal["f-string", "mustache", "jinja2"] = "f-string",
**kwargs: Any) -> None源码:
python
@classmethod def from_messages(cls,
messages: Sequence[BaseMessagePromptTemplate | BaseMessage |
BaseChatPromptTemplate | tuple[str | type, str | list[dict] | list[object]] | str | dict[str, Any]],
template_format: Literal["f-string", "mustache", "jinja2"] = "f-string")
-> ChatPromptTemplate结论:参数是列表类型,列表的元素可以是字符串、字典、字符串构成的元组、消息类型、提示词模板类型、消息提示词模板类型等
类型1:str类型
列表参数格式是str类型(不推荐),因为默认角色都是human
python
#1.导入相关依赖
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.messages import SystemMessage,HumanMessage, AIMessage
# 2.定义聊天提示词模版
chat_template = ChatPromptTemplate.from_messages(
[
"Hello, {name}!" # 等价于 ("human", "Hello, {name}!")
]
)
#1.导入相关依赖
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.messages import SystemMessage,HumanMessage, AIMessage
# 2.定义聊天提示词模版
chat_template = ChatPromptTemplate.from_messages(
[
"Hello, {name}!" # 等价于 ("human", "Hello, {name}!")
]
)类型2:dict类型
列表参数格式是dict类型
python
# 示例: 字典形式的消息
prompt = ChatPromptTemplate.from_messages([
{"role": "system", "content": "你是一个{role}."},
{"role": "human", "content": ["复杂内容", {"type": "text"}]},
])
print(prompt.format_messages(role="教师"))类型3:Message类型
python
from langchain_core.messages import SystemMessage,HumanMessage
chat_prompt_template = ChatPromptTemplate.from_messages([
SystemMessage(content="我是一个贴心的智能助手"),
HumanMessage(content="我的问题是:人工智能英文怎么说?")
])
messages = chat_prompt_template.format_messages()
print(messages)
print(type(messages))类型4:BaseChatPromptTemplate类型
使用 BaseChatPromptTemplate,可以理解为ChatPromptTemplate里嵌套了ChatPromptTemplate。
举例1:不带参数
python
from langchain_core.prompts import ChatPromptTemplate
# 使用 BaseChatPromptTemplate(嵌套的 ChatPromptTemplate)
nested_prompt_template1 = ChatPromptTemplate.from_messages([("system", "我是一个人工智
能助手")])
nested_prompt_template2 = ChatPromptTemplate.from_messages([("human", "很高兴认识你")])
prompt_template = ChatPromptTemplate.from_messages([
nested_prompt_template1,nested_prompt_template2
])
prompt_template.format_messages()举例2:带参数
python
from langchain_core.prompts import ChatPromptTemplate
# 使用 BaseChatPromptTemplate(嵌套的 ChatPromptTemplate)
nested_prompt_template1 = ChatPromptTemplate.from_messages([
("system", "我是一个人工智能助手,我的名字叫{name}")
])
nested_prompt_template2 = ChatPromptTemplate.from_messages([
("human", "很高兴认识你,我的问题是{question}")
])
prompt_template = ChatPromptTemplate.from_messages([
nested_prompt_template1,nested_prompt_template2
])
prompt_template.format_messages(name="小智",question="你为什么这么帅?")类型5:BaseMessagePromptTemplate类型
LangChain提供不同类型的MessagePromptTemplate。最常用的是SystemMessagePromptTemplate 、 HumanMessagePromptTemplate 和AIMessagePromptTemplate ,分别创建系统消息、人工消息和AI消息,它们是ChatMessagePromptTemplate的特定角色子类。
基本概念:
HumanMessagePromptTemplate,专用于生成 用户消息(HumanMessage) 的模板类,是ChatMessagePromptTemplate的特定角色子类。
- 本质 :预定义了 role="human" 的 MessagePromptTemplate,且无需无需手动指定角色
- 模板化 :支持使用变量占位符,可以在运行时填充具体值
- 格式化 :能够将模板与输入变量结合生成最终的聊天消息
- 输出类型 :生成 HumanMessage 对象( content + role="human" )
- 设计目的 :简化用户输入消息的模板化构造,避免重复定义角色
SystemMessagePromptTemplate、AIMessagePromptTemplate:类似于上面,不再赘述
ChatMessagePromptTemplate,用于构建聊天消息的模板。它允许你创建可重用的消息模板,这些模板可以动态地插入变量值来生成最终的聊天消息
- 角色指定 :可以为每条消息指定角色(如 "system"、"human"、"ai") 等,角色灵活。
- 模板化 :支持使用变量占位符,可以在运行时填充具体值
- 格式化 :能够将模板与输入变量结合生成最终的聊天消息
举例1:
python
# 导入聊天消息类模板
from langchain_core.prompts import ChatPromptTemplate, HumanMessagePromptTemplate,
SystemMessagePromptTemplate
# 创建消息模板
system_template = "你是一个专家{role}"
system_message_prompt = SystemMessagePromptTemplate.from_template(system_template)
human_template = "给我解释{concept},用浅显易懂的语言"
human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)
# 组合成聊天提示模板
chat_prompt = ChatPromptTemplate.from_messages([system_message_prompt,
human_message_prompt])
# 格式化提示
formatted_messages = chat_prompt.format_messages(
role="物理学家",
concept="相对论"
)
print(formatted_messages)举例2:ChatMessagePromptTemplate的理解
python
# 1.导入先关包
from langchain_core.prompts import ChatMessagePromptTemplate
# 2.定义模版
prompt = "今天我们授课的内容是{subject}"
# 3.创建自定义角色聊天消息提示词模版
chat_message_prompt = ChatMessagePromptTemplate.from_template(
role="teacher", template=prompt
)
# 4.格式聊天消息提示词
resp = chat_message_prompt.format(subject="我爱北京天安门")
print(type(resp))
print(resp)举例3:综合使用
python
from langchain_core.prompts import (
ChatPromptTemplate,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from langchain_core.messages import SystemMessage, HumanMessage
# 示例 1: 使用 BaseMessagePromptTemplate
system_prompt = SystemMessagePromptTemplate.from_template("你是一个{role}.")
human_prompt = HumanMessagePromptTemplate.from_template("{user_input}")
# 示例 2: 使用 BaseMessage(已实例化的消息)
system_msg = SystemMessage(content="你是一个AI工程师。")
human_msg = HumanMessage(content="你好!")
# 示例 3: 使用 BaseChatPromptTemplate(嵌套的 ChatPromptTemplate)
nested_prompt = ChatPromptTemplate.from_messages([("system", "嵌套提示词")])
prompt = ChatPromptTemplate.from_messages([
system_prompt, # MessageLike (BaseMessagePromptTemplate)
human_prompt, # MessageLike (BaseMessagePromptTemplate)
system_msg, # MessageLike (BaseMessage)
human_msg, # MessageLike (BaseMessage)
nested_prompt, # MessageLike (BaseChatPromptTemplate)
])
prompt.format_messages(role="人工智能专家",user_input="介绍一下大模型的应用场景")类似的:
python
from langchain_core.messages import HumanMessage, AIMessage
from langchain_core.prompts import HumanMessagePromptTemplate,
SystemMessagePromptTemplate
from langchain_core.prompts import ChatPromptTemplate
chat_template = ChatPromptTemplate.from_messages(
[
SystemMessagePromptTemplate.from_template("你是一个AI开发工程师. 你的名字是
{name}."),
HumanMessage(content=("你能开发哪些AI应用?")),
AIMessage(content=("我能开发很多AI应用, 比如聊天机器人, 图像识别, 自然语言处理等.")),
HumanMessagePromptTemplate.from_template("{input}")
]
)
messages = chat_template.format_messages(input="你能帮我做什么?", name="小谷AI")
print(messages)4.4.5 结合LLM
举例1:
python
from langchain.prompts.chat import ChatPromptTemplate
######1、提供提示词#########
chat_prompt = ChatPromptTemplate.from_messages([
("system", "你是一个数学家,你可以计算任何算式"),
("human", "我的问题:{question}"),
])
# 输入提示
messages = chat_prompt.format_messages(question="我今年18岁,我的舅舅今年38岁,我的爷爷今年72岁,我和舅舅一共多少岁了?")
#print(messages)
######2、提供大模型#########
import os
import dotenv
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY1")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")
chat_model = ChatOpenAI(model="gpt-4o-mini")
######3、结合提示词,调用大模型#########
# 得到模型的输出
output = chat_model.invoke(messages)
# 打印输出内容
print(output.content)举例2:
python
from dotenv import load_dotenv
from langchain.prompts.chat import SystemMessagePromptTemplate,
HumanMessagePromptTemplate, AIMessagePromptTemplate
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
load_dotenv()
llm = ChatOpenAI()
template = ChatPromptTemplate.from_messages(
[
SystemMessagePromptTemplate.from_template("你是{product}的客服助手。你的名字叫{name}"),
HumanMessagePromptTemplate.from_template("hello 你好吗?"),
AIMessagePromptTemplate.from_template("我很好 谢谢!"),
HumanMessagePromptTemplate.from_template("{query}"),
]
)
prompt = template.format_messages(
product="AGI课堂",
name="Bob",
query="你是谁"
)
# 提供聊天模型
import os
import dotenv
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY1")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")
chat_model = ChatOpenAI(model="gpt-4o-mini")
# 调用聊天模型
response = chat_model.invoke(prompt)
print(response.content)4.4.6 插入消息列表:MessagesPlaceholder
当你不确定消息提示模板使用什么角色,或者希望在格式化过程中 插入消息列表 时,该怎么办? 这就需要使用 MessagesPlaceholder,负责在特定位置添加消息列表。
使用场景:多轮对话系统存储历史消息以及Agent的中间步骤处理此功能非常有用。
举例1:
python
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.messages import HumanMessage
prompt_template = ChatPromptTemplate.from_messages([
("system", "You are a helpful assistant"),
MessagesPlaceholder("msgs")
])
# prompt_template.invoke({"msgs": [HumanMessage(content="hi!")]})
prompt_template.format_messages(msgs=[HumanMessage(content="hi!")])这将生成两条消息,第一条是系统消息,第二条是我们传入的 HumanMessage。 如果我们传入了 5 条消息,那么总共会生成 6 条消息(系统消息加上传入的 5 条消息)。 这对于将一系列消息插入到特定位置非常有用。
举例2:存储对话历史内容
python
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.messages import AIMessage
prompt = ChatPromptTemplate.from_messages(
[
("system", "You are a helpful assistant."),
MessagesPlaceholder("history"),
("human", "{question}")
]
)
prompt.format_messages(
history=[HumanMessage(content="1+2*3 = ?"),AIMessage(content="1+2*3=7")],
question="我刚才问题是什么?")
# prompt.invoke(
# {
# "history": [("human", "what's 5 + 2"), ("ai", "5 + 2 is 7")],
# "question": "now multiply that by 4"
# }
# )举例3:
python
#1.导入相关包
from langchain_core.prompts import (ChatPromptTemplate, HumanMessagePromptTemplate,
MessagesPlaceholder)
# 2.定义消息模板
prompt = ChatPromptTemplate.from_messages([
SystemMessagePromptTemplate.from_template("你是{role}"),
MessagesPlaceholder(variable_name="intermediate_steps"),
HumanMessagePromptTemplate.from_template("{query}")
])
# 3.定义消息对象(运行时填充中间步骤的结果)
intermediate = [
SystemMessage(name="search", content="北京: 晴, 25℃")
]
# 4.格式化聊天消息提示词模版
prompt.format_messages(
role="天气预报员",
intermediate_steps=intermediate,
query="北京天气怎么样?"
)举例4:作为拓展,课下看看即可
python
# 1.导入相关包
from langchain_core.prompts import (ChatPromptTemplate, HumanMessagePromptTemplate,
MessagesPlaceholder)
from langchain_core.messages import AIMessage, HumanMessage
# 2,定义HumanMessage对象
human_message = HumanMessage(content="学习编程的最好方法是什么?")
# 3.定义AIMessage对象
ai_message = AIMessage(
content="""\
1. 选择一门编程语言:选择一门你想学习的编程语言.
2.从基础开始:熟悉基本的编程概念,如变量、数据类型和控制结构.
3. 练习,练习,再练习:学习编程的最好方法是通过实践经验\
"""
)
# 4. 定义提示词
human_prompt = "用{word_count}个词总结我们到目前为止的对话"
# 5. 定义提示词模版
human_message_template = HumanMessagePromptTemplate.from_template(human_prompt)
chat_prompt = ChatPromptTemplate.from_messages(
[
MessagesPlaceholder(variable_name="conversation"),
human_message_template
]
)
# 6.格式化聊天消息提示词模版
messages1 = chat_prompt.format_messages(
conversation=[human_message, ai_message], word_count="10"
)
print(messages1)4.5 具体使用:少量样本示例的提示词模板 (Few-Shot)
通过提供少量示例来指导模型生成,可以显著提高模型在特定任务上的性能。
4.5.1 使用说明
在构建prompt时,可以通过构建一个 少量示例列表 去进一步格式化prompt,这是一种简单但强大的指导生成的方式,在某些情况下可以 显著提高模型性能 。
少量示例提示模板可以由 一组示例 或一个负责从定义的集合中选择 一部分示例 的示例选择器构建。
- 前者:使用 FewShotPromptTemplate 或 FewShotChatMessagePromptTemplate
- 后者:使用 Example selectors(示例选择器)
每个示例的结构都是一个 字典 ,其中 键 是输入变量, 值 是输入变量的值。
体会:zeroshot会导致低质量回答
python
from langchain_openai import ChatOpenAI
import os
import dotenv
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY1")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")
chat_model = ChatOpenAI(model="gpt-4o-mini",
temperature=0.4)
res = chat_model.invoke("2 🦜 9是多少?")
print(res.content)4.5.2 FewShotPromptTemplate的使用
举例1:
python
from langchain.prompts import PromptTemplate
from langchain.prompts.few_shot import FewShotPromptTemplate
#1、创建示例集合
examples = [
{"input": "北京天气怎么样", "output": "北京市"},
{"input": "南京下雨吗", "output": "南京市"},
{"input": "武汉热吗", "output": "武汉市"}
]
#2、创建PromptTemplate实例
example_prompt = PromptTemplate.from_template(
template="Input: {input}\nOutput: {output}"
)
#3、创建FewShotPromptTemplate实例
prompt = FewShotPromptTemplate(
examples=examples,
example_prompt=example_prompt,
suffix="Input: {input}\nOutput:", # 要放在示例后面的提示模板字符串。
input_variables=["input"] # 传入的变量
)
#4、调用
prompt = prompt.invoke({"input":"长沙多少度"})
print("===Prompt===")
print(prompt)结合大模型调用:
python
import os
import dotenv
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY1")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")
#获取大模型
chat_model = ChatOpenAI(model="gpt-4o-mini")
#调用
print("===Response===")
response = chat_model.invoke(prompt)
print(response.content)举例2:
python
#1、创建提示模板
from langchain.prompts import PromptTemplate
# 创建提示模板,配置一个提示模板,将一个示例格式化为字符串
prompt_template = "你是一个数学专家,算式: {input} 值: {output} 使用: {description} "
# 这是一个提示模板,用于设置每个示例的格式
prompt_sample = PromptTemplate.from_template(prompt_template)
#2、提供示例
examples = [
{"input": "2+2", "output": "4", "description": "加法运算"},
{"input": "5-2", "output": "3", "description": "减法运算"},
]
#3、创建一个FewShotPromptTemplate对象
from langchain.prompts.few_shot import FewShotPromptTemplate
prompt = FewShotPromptTemplate(
examples=examples,
example_prompt=prompt_sample,
suffix="你是一个数学专家,算式: {input} 值: {output}",
input_variables=["input", "output"]
)
print(prompt.invoke({"input":"2*5", "output":"10"}))
#4、初始化大模型,然后调用
import os
import dotenv
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY1")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")
chat_model = ChatOpenAI(model="gpt-4o-mini")
result = chat_model.invoke(prompt.invoke({"input":"2*5", "output":"10"}))
print(result.content) # 使用: 乘法运算4.5.3 FewShotChatMessagePromptTemplate的使用
除了FewShotPromptTemplate之外,FewShotChatMessagePromptTemplate是专门为 聊天对话场景 设计的少样本(few-shot)提示模板,它继承自 FewShotPromptTemplate ,但针对聊天消息的格式进行了优化。
特点:
- 自动将示例格式化为聊天消息( HumanMessage / AIMessage 等)
- 输出结构化聊天消息( ListBaseMessage )
- 保留对话轮次结构
举例1:基本结构
python
from langchain.prompts import (FewShotChatMessagePromptTemplate,
ChatPromptTemplate
)
# 1.示例消息格式
examples = [
{"input": "1+1等于几?", "output": "1+1等于2"},
{"input": "法国的首都是?", "output": "巴黎"}
]
# 2.定义示例的消息格式提示词模版
msg_example_prompt = ChatPromptTemplate.from_messages([
("human", "{input}"),
("ai", "{output}"),
])
# 3.定义FewShotChatMessagePromptTemplate对象
few_shot_prompt = FewShotChatMessagePromptTemplate(
example_prompt=msg_example_prompt,
examples=examples
)
# 4.输出格式化后的消息
print(few_shot_prompt.format())举例2:
使用方式:将原始输入和被选中的示例组一起加入Chat提示词模版中。
python
# 1.导入相关包
from langchain_core.prompts import (FewShotChatMessagePromptTemplate,
ChatPromptTemplate)
# 2.定义示例组
examples = [
{"input": "2🦜2", "output": "4"},
{"input": "2🦜3", "output": "8"},
]
# 3.定义示例的消息格式提示词模版
example_prompt = ChatPromptTemplate.from_messages([
('human', '{input} 是多少?'),
('ai', '{output}')
])
# 4.定义FewShotChatMessagePromptTemplate对象
few_shot_prompt = FewShotChatMessagePromptTemplate(
examples=examples, # 示例组
example_prompt=example_prompt, # 示例提示词词模版
)
# 5.输出完整提示词的消息模版
final_prompt = ChatPromptTemplate.from_messages(
[
('system', '你是一个数学奇才'),
few_shot_prompt,
('human', '{input}'),
]
)
#6.提供大模型
import os
import dotenv
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY1")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")
chat_model = ChatOpenAI(model="gpt-4o-mini",
temperature=0.4)
chat_model.invoke(final_prompt.invoke(input="2🦜4")).content举例3:与前面类似
python
# 1.导入相关包
from langchain_core.prompts import (FewShotChatMessagePromptTemplate,
ChatPromptTemplate)
# 2.定义示例组
examples = [
{"input": "2+2", "output": "4"},
{"input": "2+3", "output": "5"},
]
# 3.定义示例的消息格式提示词模版
example_prompt = ChatPromptTemplate.from_messages([('human', 'What is {input}?'), ('ai',
'{output}')])
# 4.定义FewShotChatMessagePromptTemplate对象
few_shot_prompt = FewShotChatMessagePromptTemplate(
examples=examples, # 示例组
example_prompt=example_prompt, # 示例提示词词模版
)
# 5.输出完整提示词的消息模版
final_prompt = ChatPromptTemplate.from_messages(
[
('system', 'You are a helpful AI Assistant'),
few_shot_prompt,('human', '{input}'),
]
)
# 6.格式化完整消息
#final_prompt.format(input="What is 4+4?")
# 或者
final_prompt.format_messages(input="What is 4+4?")4.5.4 Example selectors (示例选择器)
前面FewShotPromptTemplate的特点是,无论输入什么问题,都会包含全部示例。在实际开发中,我们可以根据当前输入,使用示例选择器,从大量候选示例中选取最相关的示例子集。
使用的好处:避免盲目传递所有示例,减少 token 消耗的同时,还可以提升输出效果。
示例选择策略:语义相似选择、长度选择、最大边际相关示例选择等
- 语义相似选择 :通过余弦相似度等度量方式评估语义相关性,选择与输入问题最相似的 k 个示例。
- 长度选择 :根据输入文本的长度,从候选示例中筛选出长度最匹配的示例。增强模型对文本结构的理解。比语义相似度计算更轻量,适合对响应速度要求高的场景。
- 最大边际相关示例选择 :优先选择与输入问题语义相似的示例;同时,通过惩罚机制避免返回同质化的内容
余弦相似度是通过计算两个向量的夹⻆余弦值来衡量它们的相似性。它的值范围在-1到1之间:当两个向量⽅向相同时值为1;夹⻆为90°时值为0;⽅向完全相反时为-1。
数学表达式:余弦相似度 = (A·B) / (||A|| * ||B||)。其中A·B是点积,||A||和||B||是向量的模(⻓度)。
举例1:
pip install chromadb
python
# 1.导入相关包
from langchain_community.vectorstores import Chroma
from langchain_core.example_selectors import SemanticSimilarityExampleSelector
import os
import dotenv
from langchain_openai import OpenAIEmbeddings
dotenv.load_dotenv()
# 2.定义嵌入模型
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY1")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")
embeddings_model = OpenAIEmbeddings(
model="text-embedding-ada-002"
)
# 3.定义示例组
examples = [
{
"question": "谁活得更久,穆罕默德·阿里还是艾伦·图灵?",
"answer": """
接下来还需要问什么问题吗?
追问:穆罕默德·阿里去世时多大年纪?
中间答案:穆罕默德·阿里去世时享年74岁。
""",
},
{
"question": "craigslist的创始人是什么时候出生的?",
"answer": """
接下来还需要问什么问题吗?
追问:谁是craigslist的创始人?
中级答案:Craigslist是由克雷格·纽马克创立的。
""",
},
{
"question": "谁是乔治·华盛顿的外祖父?",
"answer": """
接下来还需要问什么问题吗?
追问:谁是乔治·华盛顿的母亲?
中间答案:乔治·华盛顿的母亲是玛丽·鲍尔·华盛顿。
""",
},
{
"question": "《大白鲨》和《皇家赌场》的导演都来自同一个国家吗?",
"answer": """
接下来还需要问什么问题吗?
追问:《大白鲨》的导演是谁?
中级答案:《大白鲨》的导演是史蒂文·斯皮尔伯格。
""",
},
]
# 4.定义示例选择器
example_selector = SemanticSimilarityExampleSelector.from_examples(
# 这是可供选择的示例列表
examples,
# 这是用于生成嵌入的嵌入类,用于衡量语义相似性
embeddings_model,
# 这是用于存储嵌入并进行相似性搜索的 VectorStore 类
Chroma,
# 这是要生成的示例数量
k=1,
)
# 选择与输入最相似的示例
question = "玛丽·鲍尔·华盛顿的父亲是谁?"
selected_examples = example_selector.select_examples({"question": question})
print(f"与输入最相似的示例:{selected_examples}")
# for example in selected_examples:
# print("\n")
# for k, v in example.items():
# print(f"{k}: {v}")举例2:结合 FewShotPromptTemplate 使用
这里使用FAISS,需安装:
pip install faiss-cpu
#或
conda install faiss-cpu
python
# 1.导入相关包
from langchain_community.vectorstores import FAISS
from langchain_core.example_selectors import SemanticSimilarityExampleSelector
from langchain_core.prompts import FewShotPromptTemplate, PromptTemplate
from langchain_openai import OpenAIEmbeddings
# 2.定义示例提示词模版
example_prompt = PromptTemplate.from_template(
template="Input: {input}\nOutput: {output}",
)
# 3.创建一个示例提示词模版
examples = [
{"input": "高兴", "output": "悲伤"},
{"input": "高", "output": "矮"},
{"input": "长", "output": "短"},
{"input": "精力充沛", "output": "无精打采"},
{"input": "阳光", "output": "阴暗"},
{"input": "粗糙", "output": "光滑"},
{"input": "干燥", "output": "潮湿"},
{"input": "富裕", "output": "贫穷"},
]
# 4.定义嵌入模型
embeddings = OpenAIEmbeddings(
model="text-embedding-ada-002"
)
# 5.创建语义相似性示例选择器
xample_selector = SemanticSimilarityExampleSelector.from_examples(
examples,
embeddings,
FAISS,
k=2,
)
#或者
#example_selector = SemanticSimilarityExampleSelector(
# examples,
# embeddings,
# FAISS,
# k=2
#)
# 6.定义小样本提示词模版
similar_prompt = FewShotPromptTemplate(
example_selector=example_selector,
example_prompt=example_prompt,
prefix="给出每个词组的反义词",
suffix="Input: {word}\nOutput:",
input_variables=["word"],
)
response = similar_prompt.invoke({"word":"忧郁"})
print(response.text)4.6 具体使用:PipelinePromptTemplate(了解)
用于将多个提示模板按顺序组合成处理管道,实现分阶段、模块化的提示构建。它的核心作用类似于软件开发中的 管道模式 (Pipeline Pattern),通过串联多个提示处理步骤,实现复杂的提示生成逻辑。
特点:
- 将复杂提示拆解为多个处理阶段,每个阶段使用独立的提示模板
- 前一个模板的输出作为下一个模板的输入变量
- 使用场景:解决单一超大提示模板难以维护的问题
说明:PipelinePromptTemplate在langchain 0.3.22版本中被标记为过时,在 langchain-core==1.0之前不会删除它。
举例:
python
from langchain_core.prompts.pipeline import PipelinePromptTemplate
from langchain_core.prompts.prompt import PromptTemplate
# 阶段1:问题分析
analysis_template = PromptTemplate.from_template("""
分析这个问题:{question}
关键要素:
""")
# 阶段2:知识检索
retrieval_template = PromptTemplate.from_template("""
基于以下要素搜索资料:
{analysis_result}
搜索关键词:
""")
# 阶段3:生成最终回答
answer_template = PromptTemplate.from_template("""
综合以下信息回答问题:
{retrieval_result}
最终答案:
""")
# 构建管道
pipeline = PipelinePromptTemplate(
final_prompt=answer_template,
pipeline_prompts=[
("analysis_result", analysis_template),
("retrieval_result", retrieval_template)
]
)
print(pipeline.format(question="量子计算的优势是什么?"))上述代码执行时,提示PipelinePromptTemplate已过时,代码更新如下:
python
from langchain_core.prompts.prompt import PromptTemplate
# 阶段1:问题分析
analysis_template = PromptTemplate.from_template("""
分析这个问题:{question}
关键要素:
""")
# 阶段2:知识检索
retrieval_template = PromptTemplate.from_template("""
基于以下要素搜索资料:
{analysis_result}
搜索关键词:
""")
# 阶段3:生成最终回答
answer_template = PromptTemplate.from_template("""
综合以下信息回答问题:
{retrieval_result}
最终答案:
""")
# 逐步执行管道提示
pipeline_prompts = [
("analysis_result", analysis_template),
("retrieval_result", retrieval_template)
]
my_input = {"question": "量子计算的优势是什么?"}
# print(pipeline_prompts)
# [('analysis_result', PromptTemplate(input_variables=['question'], input_types={},partial_variables={}, template='\n分析这个问题:{question}\n关键要素:\n')), ('retrieval_result',PromptTemplate(input_variables=['analysis_result'], input_types={}, partial_variables={},template='\n基于以下要素搜索资料:\n{analysis_result}\n搜索关键词:\n'))]
for name, prompt in pipeline_prompts:
# 调用当前提示模板并获取字符串结果
result = prompt.invoke(my_input).to_string()
# 将结果添加到输入字典中供下一步使用
my_input[name] = result
# 生成最终答案
my_output = answer_template.invoke(my_input).to_string()
print(my_output)4.7 具体使用:自定义提示词模版(了解)
在创建prompt时,我们也可以按照自己的需求去创建自定义的提示模版。
步骤:
- 自定义类继承提示词基类模版BasePromptTemplate
- 重写format、format_prompt、from_template方法
举例
python
# 1.导入相关包
from typing import List, Dict, Any
from langchain.prompts import BasePromptTemplate
from langchain.prompts import PromptTemplate
from langchain.schema import PromptValue
# 2.自定义提示词模版
class SimpleCustomPrompt(BasePromptTemplate):
"""简单自定义提示词模板"""
template: str
def __init__(self, template: str, **kwargs):
# 使用PromptTemplate解析输入变量
prompt = PromptTemplate.from_template(template)
super().__init__(
input_variables=prompt.input_variables,
template=template,
**kwargs
)
def format(self, **kwargs: Any) -> str:
"""格式化提示词"""
# print("kwargs:", kwargs)
# print("self.template:", self.template)
return self.template.format(**kwargs)
def format_prompt(self, **kwargs: Any) -> PromptValue:
"""实现抽象方法"""
return PromptValue(text=self.format(**kwargs))
@classmethod
def from_template(cls, template: str, **kwargs) -> "SimpleCustomPrompt":
"""从模板创建实例"""
return cls(template=template, **kwargs)
# 3.使用自定义提示词模版
custom_prompt = SimpleCustomPrompt.from_template(
template="请回答关于{subject}的问题:{question}"
)
# 4.格式化提示词
formatted = custom_prompt.format(
subject="人工智能",
question="什么是LLM?"
)
print(formatted)4.8 从文档中加载Prompt(了解)
一方面,将想要设定prompt所支持的格式保存为JSON或者YAML格式文件。
另一方面,通过读取指定路径的格式化文件,获取相应的prompt。
目的与使用场景:
- 为了便于共享、存储和加强对prompt的版本控制。
- 当我们的prompt模板数据较大时,我们可以使用外部导入的方式进行管理和维护。
4.8.1 yaml格式提示词
asset下创建yaml文件:prompt.yaml
yaml
_type:
"prompt"
input_variables:
["name","what"]
template:
"请给{name}讲一个关于{what}的故事"
python
from langchain_core.prompts import load_prompt
from dotenv import load_dotenv
load_dotenv()
prompt = load_prompt("asset/prompt.yaml", encoding="utf-8")
# print(prompt)
print(prompt.format(name="年轻人", what="滑稽"))4.8.2 json格式提示词
asset下创建json文件:prompt.json
json
{
"_type": "prompt",
"input_variables": ["name", "what"],
"template": "请{name}讲一个{what}的故事。"
}
python
from langchain_core.prompts import load_prompt
from dotenv import load_dotenv
load_dotenv()
prompt = load_prompt("asset/prompt.json",encoding="utf-8")
print(prompt.format(name="张三",what="搞笑的"))5、Model I/O之Output Parsers
语言模型返回的内容通常都是字符串的格式(文本格式),但在实际AI应用开发过程中,往往希望model可以返回更直观、更格式化的内容,以确保应用能够顺利进行后续的逻辑处理。此时,LangChain提供的 输出解析器 就派上用场了。
输出解析器(Output Parser)负责获取 LLM 的输出并将其转换为更合适的格式。这在应用开发中及其重要。
5.1 输出解析器的分类
LangChain有许多不同类型的输出解析器
- StrOutputParser :字符串解析器
- JsonOutputParser :JSON解析器,确保输出符合特定JSON对象格式
- XMLOutputParser :XML解析器,允许以流行的XML格式从LLM获取结果
- CommaSeparatedListOutputParser :CSV解析器,模型的输出以逗号分隔,以列表形式返回输出
- DatetimeOutputParser :日期时间解析器,可用于将 LLM 输出解析为日期时间格式
除了上述常用的输出解析器之外,还有:
- EnumOutputParser :枚举解析器,将LLM的输出,解析为预定义的枚举值
- StructuredOutputParser :将非结构化文本转换为预定义格式的结构化数据(如字典)
- OutputFixingParser :输出修复解析器,用于自动修复格式错误的解析器,比如将返回的不符合预期格式的输出,尝试修正为正确的结构化数据(如 JSON)
- RetryOutputParser :重试解析器,当主解析器(如 JSONOutputParser)因格式错误无法解析LLM 的输出时,通过调用另一个 LLM 自动修正错误,并重新尝试解析
5.2 具体解析器的使用
① 字符串解析器 StrOutputParser
StrOutputParser 简单地将 任何输入 转换为 字符串 。它是一个简单的解析器,从结果中提取content字段
举例:将一个对话模型的输出结果,解析为字符串输出
python
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_core.output_parsers import StrOutputParser
import os
import dotenv
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY1")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")
chat_model = ChatOpenAI(model="gpt-4o-mini")
messages = [
SystemMessage(content="将以下内容从英语翻译成中文"),
HumanMessage(content="It's a nice day today"),
]
result = chat_model.invoke(messages)
print(type(result))
print(result)
parser = StrOutputParser()
#使用parser处理model返回的结果
response = parser.invoke(result)
print(type(response))
print(response)② JSON解析器 JsonOutputParser
JsonOutputParser,即JSON输出解析器,是一种用于将大模型的 自由文本输出 转换为 结构化JSON数据 的工具。
适合场景:特别适用于需要严格结构化输出的场景,比如 API 调用、数据存储或下游任务处理。
实现方式
- 方式1:用户自己通过提示词指明返回Json格式
- 方式2:借助JsonOutputParser的 get_format_instructions() ,生成格式说明,指导模型输出JSON 结构
举例1:
python
from langchain_core.output_parsers import JsonOutputParser
from langchain_core.prompts import ChatPromptTemplate
chat_model = ChatOpenAI(model="gpt-4o-mini")
chat_prompt_template = ChatPromptTemplate.from_messages([
("system","你是一个靠谱的{role}"),
("human","{question}")
])
parser = JsonOutputParser()
# 方式1:
result = chat_model.invoke(chat_prompt_template.format_messages(role="人工智能专家",question="人工智能用英文怎么说?问题用q表示,答案用a表示,返回一个JSON格式"))
print(result)
print(type(result))
parser.invoke(result)
# 方式2:
# chain = chat_prompt_template | chat_model | parser
# chain.invoke({"role":"人工智能专家","question" : "人工智能用英文怎么说?问题用q表示,答案用a
表示,返回一个JSON格式"})举例2:使用指定的JSON格式
python
from langchain_core.output_parsers import JsonOutputParser
output_parser = JsonOutputParser()
# 返回一些指令或模板,这些指令告诉系统如何解析或格式化输出数据
format_instructions = output_parser.get_format_instructions()
print(format_instructions)基于此:
python
# 引入依赖包
from langchain_core.output_parsers import JsonOutputParser
from langchain_core.prompts import PromptTemplate
# 初始化语言模型
chat_model = ChatOpenAI(model="gpt-4o-mini")
joke_query = "告诉我一个笑话。"
# 定义Json解析器
parser = JsonOutputParser()
# 定义提示词模版
# 注意,提示词模板中需要部分格式化解析器的格式要求format_instructions
prompt = PromptTemplate(
template="回答用户的查询.\n{format_instructions}\n{query}\n",
input_variables=["query"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
# 5.使用LCEL语法组合一个简单的链
chain = prompt | chat_model | parser
# 6.执行链
output = chain.invoke({"query": "给我讲一个笑话"})
print(output)③ XML解析器 XMLOutputParser
XMLOutputParser,将模型的自由文本输出转换为可编程处理的 XML 数据。
如何实现:在 PromptTemplate 中指定 XML 格式要求,让模型返回 content 形式的数据。
注意:XMLOutputParser 不会直接将模型的输出保持为原始XML字符串,而是会解析XML并转换成Python字典 (或类似结构化的数据)。目的是为了方便程序后续处理数据,而不是单纯保留XML格式。
举例1:不使用XMLOutputParser,通过大模型的能力,返回xml格式数据
python
# 初始化语言模型
chat_model = ChatOpenAI(model="gpt-4o-mini")
# 测试模型的xml解析效果
actor_query = "生成汤姆·汉克斯的简短电影记录"
output = chat_model.invoke(f"""{actor_query}请将影片附在<movie></movie>标签中"""
)
print(type(output)) # <class 'langchain_core.messages.ai.AIMessage'>
print(output.content)举例2:体会XMLOutputParser的格式
python
from langchain_core.output_parsers import XMLOutputParser
output_parser = XMLOutputParser()
# 返回一些指令或模板,这些指令告诉系统如何解析或格式化输出数据
format_instructions = output_parser.get_format_instructions()
print(format_instructions)举例3:XMLOutputParser 的使用
python
# 1.导入相关包
from langchain_core.output_parsers import XMLOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
# 2. 初始化语言模型
chat_model = ChatOpenAI(model="gpt-4o-mini")
# 3.测试模型的xml解析效果
actor_query = "生成汤姆·汉克斯的简短电影记录,使用中文回复"
# 4.定义XMLOutputParser对象
parser = XMLOutputParser()
# 5.定义提示词模版对象
# prompt = PromptTemplate(
# template="{query}\n{format_instructions}",
# input_variables=["query","format_instructions"],
# partial_variables={"format_instructions": parser.get_format_instructions()},
#)
prompt_template = PromptTemplate.from_template("{query}\n{format_instructions}")
prompt_template1 =
prompt_template.partial(format_instructions=parser.get_format_instructions())
response = chat_model.invoke(prompt_template1.format(query=actor_query))
print(response.content)继续:
python
# 方式1
response = chat_model.invoke(prompt_template1.format(query=actor_query))
result = parser.invoke(response)
print(result)
print(type(result))
# 方式2
# chain = prompt_template1 | chat_model | parser
# result = chain.invoke({"query":actor_query})
# print(result)
# print(type(result))举例4:与前例类似
python
from langchain_openai import ChatOpenAI
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import XMLOutputParser
model = ChatOpenAI(model="gpt-4o-mini")
actor_query = "生成周星驰的简化电影作品列表,按照最新的时间降序,必要时使用中文"
# 设置解析器 + 将指令注入提示模板。
parser = XMLOutputParser()
prompt = PromptTemplate(
template="回答用户的查询。\n{format_instructions}\n{query}\n",
input_variables=["query"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
chain = prompt | model | parser
output = chain.invoke({"query": actor_query})
print(output)④ 列表解析器 CommaSeparatedListOutputParser
列表解析器:利用此解析器可以将模型的文本响应转换为一个用 逗号分隔的列表(Liststr) 。
举例1:
python
from langchain_core.output_parsers import CommaSeparatedListOutputParser
output_parser = CommaSeparatedListOutputParser()
# 返回一些指令或模板,这些指令告诉系统如何解析或格式化输出数据
format_instructions = output_parser.get_format_instructions()
print(format_instructions)
messages = "大象,猩猩,狮子"
result = output_parser.parse(messages)
print(result)
print(type(result))举例2:
python
from langchain_core.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
from langchain.output_parsers import CommaSeparatedListOutputParser
# 初始化语言模型
chat_model = ChatOpenAI(model="gpt-4o-mini")
# 创建解析器
output_parser = CommaSeparatedListOutputParser()
# 创建LangChain提示模板
chat_prompt = PromptTemplate.from_template(
"生成5个关于{text}的列表.\n\n{format_instructions}",partial_variables={
"format_instructions": output_parser.get_format_instructions()
})
# 提示模板与输出解析器传递输出
# chat_prompt =
chat_prompt.partial(format_instructions=output_parser.get_format_instructions())
# 将提示和模型合并以进行调用
chain = chat_prompt | chat_model | output_parser
res = chain.invoke({"text": "电影"})
print(res)
print(type(res))举例3:
python
from langchain.prompts.chat import HumanMessagePromptTemplate
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain.output_parsers import CommaSeparatedListOutputParser
# 初始化语言模型
chat_model = ChatOpenAI(model="gpt-4o-mini")
output_parser = CommaSeparatedListOutputParser()
chat_prompt = ChatPromptTemplate.from_messages([
("human", "{request}\n{format_instructions}")
# HumanMessagePromptTemplate.from_template("{request}\n{format_instructions}"),
])
# model_request = chat_prompt.format_messages(
# request="给我5个心情",
# format_instructions=output_parser.get_format_instructions()
# )
#方式1:
# result = chat_model.invoke(model_request)
#
# resp = output_parser.parse(result.content)
# print(resp)
# print(type(resp))
# 方式2:
# result = chat_model.invoke(model_request)
# resp = output_parser.invoke(result)
# print(resp)
# print(type(resp))
# 方式3:
chain = chat_prompt | chat_model | output_parser
resp = chain.invoke({"request": "给我5个心情", "format_instructions":
output_parser.get_format_instructions()})
print(resp)
print(type(resp))⑤ 日期解析器 DatetimeOutputParser (了解)
利用此解析器可以直接将LLM输出解析为日期时间格式。
- get_format_instructions(): 获取日期解析的格式化指令,指令为:"Write a datetime stringthat matches the following pattern: '%Y-%m-%dT%H:%M:%S.%fZ'。
- 举例:1206-08-16T17:39:06.176399Z
举例1:
python
from langchain.output_parsers import DatetimeOutputParser
output_parser = DatetimeOutputParser()
format_instructions = output_parser.get_format_instructions()
print(format_instructions)举例2:
python
from langchain_openai import ChatOpenAI
from langchain.prompts.chat import HumanMessagePromptTemplate
from langchain_core.prompts import ChatPromptTemplate
from langchain.output_parsers import DatetimeOutputParser
chat_model = ChatOpenAI(model="gpt-4o-mini")
chat_prompt = ChatPromptTemplate.from_messages([
("system","{format_instructions}"),
("human", "{request}")
])
output_parser = DatetimeOutputParser()
# 方式1:
# model_request = chat_prompt.format_messages(
# request="中华人民共和国是什么时候成立的",
# format_instructions=output_parser.get_format_instructions()
# )
# response = chat_model.invoke(model_request)
# result = output_parser.invoke(response)
# print(result)
# print(type(result))
# 方式2:
chain = chat_prompt | chat_model | output_parser
resp = chain.invoke({"request":"中华人民共和国是什么时候成立的",
"format_instructions":output_parser.get_format_instructions()})
print(resp)
print(type(resp))6、LangChain调用本地模型
6.1 Ollama的介绍
Ollama是在Github上的一个开源项目,其项目定位是:一个本地运行大模型的集成框架。目前主要针对主流的LlaMA架构的开源大模型设计,可以实现如 Qwen、Deepseek 等主流大模型的下载、启动和本地运行的自动化部署及推理流程。
目前作为一个非常热门的大模型托管平台,已被包括LangChain、Taskweaver等在内的多个热门项目高度集成。
Ollama官方地址:https://ollama.com
6.2 Ollama的下载-安装
Ollama项目支持跨平台部署,目前已兼容Mac、Linux和Windows操作系统。特别地对于Windows用户提供了非常直观的预览版。
无论使用哪个操作系统,Ollama项目的安装过程都设计得非常简单。
访问 https://ollama.com/download 下载对应系统的安装文件。
-
Windows 系统执行 .exe 文件安装(大概671M大小)
-
Linux 系统执行以下命令安装:
curl -fsSL https://ollama.com/install.sh | sh -
这行命令的目的是从 https://ollama.com/ 网站读取 install.sh 脚本,并立即通过 sh 执行该脚本,在安装过程中会包含以下几个主要的操作:
- 检查当前服务器的基础环境,如系统版本等;
- 下载Ollama的二进制文件;
- 配置系统服务,包括创建用户和用户组,添加Ollama的配置信息;
- 启动Ollama服务;
6.3 模型的下载-安装
访问 https://ollama.com/search 可以查看 Ollama 支持的模型。使用命令行可以下载并运行模型,例如运行 deepseek-r1:7b 模型:
ollama run deepseek-r1:7b6.4 调用本地私有模型
举例1:
python
from langchain_community.chat_models import ChatOllama
#from langchain_ollama import ChatOllama
ollama_llm = ChatOllama(model="deepseek-r1:7b")
python
from langchain_core.messages import HumanMessage
messages = [
HumanMessage(content="你好,请介绍一下你自己")
]
chat_model_response = ollama_llm.invoke(messages)
print(chat_model_response.content)若 Ollama 不在本地默认端口运行,需指定 base_url ,即:
python
ollama_llm = ChatOllama(
model="deepseek-r1:7b",
base_url="http://your-ip:port" # 自定义地址
)
print(chat_model_response.content)举例2:
python
from langchain.prompts.chat import ChatPromptTemplate
from langchain_community.chat_models import ChatOllama
# 生成对话形式的聊天信息格式
chat_prompt = ChatPromptTemplate.from_messages([
("system","你是一个有用的助手,可以将{input_language}翻译成{output_language}。"),
("human", "{text}"),
])
# 格式化变量输入
messages = chat_prompt.format_messages(input_language="中文", output_language="英语",
text="我爱编程")
# 实例化Ollama启动的模型
ollama_llm = ChatOllama(model="deepseek-r1:7b")
# 执行推理
result = ollama_llm.invoke(messages)
print(result.content)第03章:LangChain使用之Chains
1、Chains的基本使用
1.1 Chain的基本概念
Chain:链,用于将多个组件(提示模板、LLM模型、记忆、工具等)连接起来,形成可复用的工作流 ,完成复杂的任务。
Chain的核心思想是通过组合不同的模块化单元,实现比单一组件更强大的功能。比如:
- 将 LLM与 Prompt Template (提示模板)结合
- 将 LLM与输出解析器结合
- 将 LLM与外部数据结合,例如用于问答
- 将 LLM与长期记忆结合,例如用于聊天历史记录
- 通过将第一个LLM的输出作为第二个LLM的输入,...,将多个LLM按顺序结合在一起
1.2 LCEL及其基本构成
使用LCEL,可以构造出结构最简单的Chain。
LangChain表达式语言(LCEL,LangChain Expression Language)是一种声明式方法,可以轻松地将多个组件链接成 AI工作流。它通过Python原生操作符(如管道符 | )将组件连接成可执行流程,显著简化了AI应用的开发。
LCEL的基本构成:提示(Prompt)+模型(Model)+输出解析器(OutputParser)
即:
python
#在这个链条中,用户输入被传递给提示模板,然后提示模板的输出被传递给模型,然后模型的输出被传递给输出解析器。
chain = prompt | model | output_parser
chain.invoke({"input":"What's your name?"})-
Prompt :Prompt 是一个
BasePromptTemplate,这意味着它接受一个模板变量的字典并生成一个PromptValue。PromptValue可以传递给 LLM(它以字符串作为输入)或 ChatModel(它以消息序列作为输入)。 -
Model :将
PromptValue传递给 model。如果我们的 model是一个 ChatModel,这意味着它将输出一个BaseMessage。 -
OutputParser :将 model的输出传递给
output_parser,它是一个BaseOutputParser,意味着它可以接受字符串或BaseMessage作为输入。 -
chain:我们可以使用 | 运算符轻松创建这个Chain。 | 运算符在 LangChain 中用于将两个元素组合在一起。
-
invoke:所有LCEL对象都实现了 Runnable协议,保证一致的调用方式 ( invoke/ batch/ stream )
|符号类似于 shell里面管道操作符,它将不同的组件链接在一起,将前一个组件的输出作为下一个组件的输入,这就形成了一个 AI工作流。
1.3 Runnable
Runnable是LangChain定义的一个抽象接口(Protocol),它强制要求所有LCEL组件实现一组标准方法:
python
class Runnable(Protocol):
def invoke(self, input: Any) -> Any: ... # 单输入单输出
def batch(self, inputs: List[Any]) -> List[Any]: ... # 批量处理
def stream(self, input: Any) -> Iterator[Any]: ... # 流式输出
# 还有其他方法如 ainvoke(异步)等...任何实现了这些方法的对象都被视为LCEL兼容组件。比如:聊天模型、提示词模板、输出解析器、检索器、代理(智能体)等。
每个 LCEL对象都实现了 Runnable接口,该接口定义了一组公共的调用方法。这使得 LCEL对象链也自动支持这些调用成为可能。
2、为什么需要统一调用方式?
传统问题
假设没有统一协议:
- 提示词渲染用 .format()
- 模型调用用 .generate()
- 解析器解析用 .parse()
- 工具调用用 .run()
代码会变成:
python
prompt_text = prompt.format(topic="猫") # 方法1
model_out = model.generate(prompt_text) # 方法2
result = parser.parse(model_out) # 方法3痛点:每个组件调用方式不同,组合时需要手动适配。
3、LCEL解决方案
通过 Runnable 协议统一:
python
#(分步调用)
prompt_text = prompt.invoke({"topic": "猫"}) # 方法1
model_out = model.invoke(prompt_text) # 方法2
result = parser.invoke(model_out) # 方法3
#(LCEL管道式)
chain = prompt | model | parser # 用管道符组合
result = chain.invoke({"topic": "猫"}) # 所有组件统一用invoke- 一致性:无论组件的功能多复杂(模型/提示词/工具),调用方式完全相同
- 组合性:管道操作符 | 背后自动处理类型匹配和中间结果传递
1.4 使用举例
举例1:
情况1:没有使用chain
python
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
from langchain.prompts import PromptTemplate
import os
import dotenv
dotenv.load_dotenv()
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY1")
os.environ["OPENAI_BASE_URL"] = os.getenv("OPENAI_BASE_URL")
chat_model = ChatOpenAI(
model="gpt-4o-mini"
)
prompt_template = PromptTemplate.from_template(
template="给我讲一个关于{topic}话题的简短笑话"
)
parser = StrOutputParser()
prompt_value = prompt_template.invoke({"topic":"冰淇淋"})
result = chat_model.invoke(prompt_value)
out_put = parser.invoke(result)
print(out_put)
print(type(out_put))情况2:使用 chain:将提示模板、模型、解析器链接在一起。使用LCEL将不同的组件组合成一个单一的链条
python
from dotenv import load_dotenv
from langchain_core.output_parsers import StrOutputParser
load_dotenv()
chat_model = ChatOpenAI(model="gpt-4o-mini")
prompt_template = PromptTemplate.from_template(
template = "给我讲一个关于{topic}话题的简短笑话"
)
parser = StrOutputParser()
# 构建链式调用(LCEL语法)
chain = prompt_template | chat_model | parser
out_put = chain.invoke({"topic": "ice cream"})
print(out_put)
print(type(out_put))
2、传统Chain的使用
2.1 基础链:LLMChain
2.1.1 使用说明
LCEL之前,最基础也最常见的链类型是LLMChain。
这个链至少包括一个提示词模板(PromptTemplate),一个语言模型(LLM或聊天模型)。
注意:LLMChain was deprecated in LangChain 0.1.17 and will be removed in 1.0. Use prompt | llm instead。
特点:
- 用于单次问答,输入一个 Prompt,输出 LLM的响应。
- 适合无上下文的简单任务(如翻译、摘要、分类等)。
- 无记忆:无法自动维护聊天历史
2.1.2 主要步骤
-
配置任务链:使用LLMChain类将任务与提示词结合,形成完整的任务链。
pythonchain = LLMChain(llm = llm, prompt = prompt_template) -
执行任务链:使用
invoke()等方法执行任务链,并获取生成结果。可以根据需要对输出进行处理和展示。
python
result = chain.invoke(...)
print(result)2.1.3 参数说明
这里我们可以整理如下:
| 参数名 | 类型 | 默认值 | 必填 | 说明 |
|---|---|---|---|---|
| llm | UnionRunnable\[LanguageModelInput, str, RunnableLanguageModelInput, BaseMessage] | - | 是 | 要调用的语言模型 |
| prompt | BasePromptTemplate | - | 是 | 要使用的提示对象 |
| verbose | bool | False | 否 | 是否以详细模式运行。在详细模式下,一些中间日志将被打印到控制台。默认使用全局详细设置,可通过 langchain.globals.get_verbose() 访问 |
| callback_manager | OptionalBaseCallbackManager | None | 否 | 【已弃用】请改用callbacks。 |
| callbacks | Callbacks | None | 否 | 可选的回调处理器列表或回调管理器。在调用链的生命周期中的不同阶段被调用,从on_chain_start开始,到on_chain_end或 on_chain_error结束。自定义链可以选择调用额外的回调方法。详见回调文档 |
| llm_kwargs | dict | - | 否 | 语言模型的关键字参数字典 |
| memory | OptionalBaseMemory | None | 否 | 可选的记忆对象。默认为None。记忆是一个在每个链的开始和结束时被调用的类。开始时,记忆加载变量并在链中传递。结束时,它保存任何返回的变量。有许多不同类型的记忆,请查看内存文档获取完整目录 |
| metadata | OptionalDict\[str, Any] | None | 否 | 与链相关联的可选元数据。默认为 None。这些元数据将与调用此链的每次调用相关联,并作为参数传递给callbacks中定义的处理程序。您可以使用这些来识别链的特定实例及其用例 |
| output_parser | BaseLLMOutputParser | - | 否 | 要使用的输出解析器。默认为 StrOutputParser |
| return_final_only | bool | True | 否 | 是否只返回最终解析结果。默认为 True。如果为False,将返回关于生成的额外信息。 |
| tags | OptionalList\[str] | None | 否 | 与链相关联的可选标签列表。默认为None。这些标签将与调用此链的每次调用相关联,并作为参数传递给callbacks中定义的处理程序。您可以使用这些来识别链的特定实例及其用例 |
举例1:
python
from langchain.chains.llm import LLMChain
from langchain_core.prompts import PromptTemplate
import os
import dotenv
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY1")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")
# 1、创建大模型实例
chat_model = ChatOpenAI(model="gpt-4o-mini")
# 2、原始字符串模板
template = "桌上有{number}个苹果,四个桃子和 3 本书,一共有几个水果?"
prompt = PromptTemplate.from_template(template)
# 3、创建LLMChain
llm_chain = LLMChain(
llm=chat_model,
prompt=prompt
)
# 4、调用LLMChain,返回结果
result = llm_chain.invoke({"number": 2})
print(result)举例2:verbose参数,使用使用ChatPromptTemplate。
python
# 1.导入相关包
from langchain.chains.llm import LLMChain
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
# 2.定义提示词模版对象
chat_template = ChatPromptTemplate.from_messages(
[
("system","你是一位{area}领域具备丰富经验的高端技术人才"),
("human", "给我讲一个 {adjective} 笑话"),
]
)
# 3.定义模型
llm = ChatOpenAI(model="gpt-4o-mini")
# 4.定义LLMChain
llm_chain = LLMChain(llm=llm, prompt=chat_template, verbose=True)
# 5.调用LLMChain
response = llm_chain.invoke({"area":"互联网","adjective":"上班的"})
print(response)2.2 顺序链之 SimpleSequentialChain
顺序链(SequentialChain)允许将多个链顺序连接起来,每个Chain的输出作为下一个Chain的输入,形成特定场景的流水线(Pipeline)。
顺序链有两种类型:
- 单个输入/输出:对应着 SimpleSequentialChain
- 多个输入/输出:对应着:SequentialChain
2.2.1 说明
SimpleSequentialChain:最简单的顺序链,多个链串联执行 ,每个步骤都有单一的输入和输出,一个步骤的输出就是下一个步骤的输入,无需手动映射。
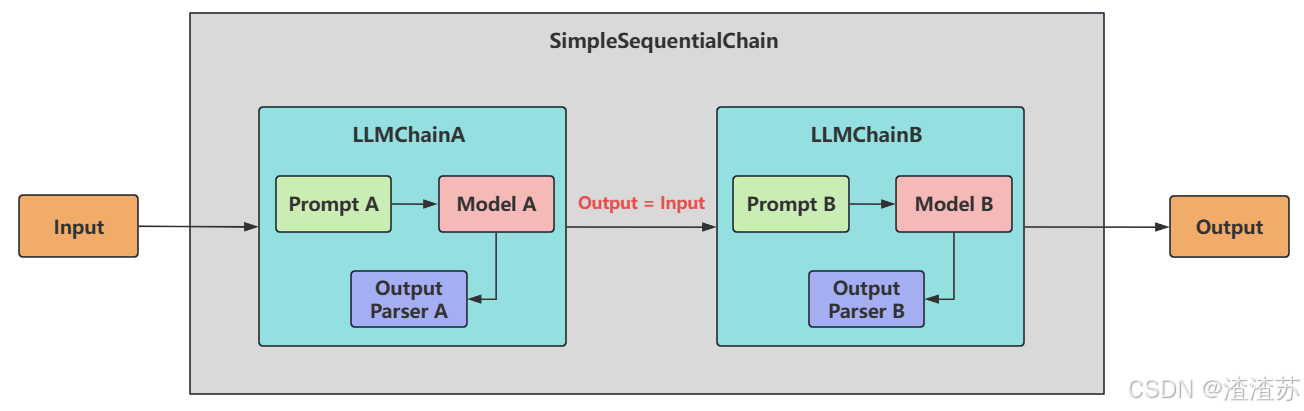
2.2.2 使用举例
举例1:
python
from langchain_core.prompts import ChatPromptTemplate
from langchain.chains import LLMChain
chainA_template = ChatPromptTemplate.from_messages(
[
("system", "你是一位精通各领域知识的知名教授"),
("human", "请你尽可能详细的解释一下:{knowledge}"),
]
)
chainA_chains = LLMChain(llm=llm, prompt=chainA_template, verbose=True )
chainA_chains.invoke({"knowledge":"什么是LangChain?"})继续:
python
from langchain_core.prompts import ChatPromptTemplate
chainB_template = ChatPromptTemplate.from_messages(
[
("system", "你非常善于提取文本中的重要信息,并做出简短的总结"),
("human", "这是针对一个提问的完整的解释说明内容:{description}"),
("human", "请你根据上述说明,尽可能简短的输出重要的结论,请控制在20个字以内"),
]
)
chainB_chains = LLMChain(llm=llm,
prompt=chainB_template,
verbose=True
)
python
#导入SimpleSequentialChain
from langchain.chains import SimpleSequentialChain
#在chains参数中,按顺序传入LLMChain A和LLMChain B
full_chain = SimpleSequentialChain(chains=[chainA_chains, chainB_chains], verbose=True)
full_chain.invoke({"input":"什么是langChain?"})在这个过程中,因为 SimpleSequentialChain定义的是顺序链,所以在 chains参数中传递的列表要按照顺序来进行传入,即LLMChain A要在LLMChain B之前。同时,在调用时,不再使用LLMChain A中定义的{knowledge}参数,也不是LLMChainB中定义的{description}参数,而是要使用 input进行变量的传递。
源码:
python
class SimpleSequentialChain(Chain):
"""Simple chain where the outputs of one step feed directly into next."""
chains: List[Chain]
strip_outputs: bool = False
input_key: str = "input" #::meta private:
output_key: str = "output" #::meta private:举例2:创建了两条chain,并且让第一条chain给剧名写大纲,输出该剧名大纲,作为第二条chain的输入,然后生成一个剧本的大纲评论。最后利用 SimpleSequentialChain即可将两个 chain直接串联起来。
python
# 1.导入相关包
from langchain.chains import LLMChain
from langchain_core.prompts import PromptTemplate
from langchain.chains import SimpleSequentialChain
# 2.创建大模型实例
llm = ChatOpenAI(model="gpt-4o-mini")
# 3.定义一个给剧名写大纲的LLMChain
template1 = """你是个剧作家。给定剧本的标题,你的工作就是为这个标题写一个大纲。
Title: {title}
"""
prompt_template1 = PromptTemplate(input_variables=["title"], template=template1)
synopsis_chain = LLMChain(llm=llm, prompt=prompt_template1)
# 4.定义给一个剧本大纲写一篇评论的LLMChain
template2 = """你是《纽约时报》的剧评家。有了剧本的大纲,你的工作就是为剧本写一篇评论
剧情大纲: {synopsis}
"""
prompt_template2 = PromptTemplate(input_variables=["synopsis"], template=template2)
review_chain = LLMChain(llm=llm, prompt=prompt_template2)
# 5.定义一个完整的链按顺序运行这两条链
# (verbose=True:打印链的执行过程)
overall_chain = SimpleSequentialChain(
chains=[synopsis_chain, review_chain],
verbose=True
)
# 6.调用完整链顺序执行这两个链
review = overall_chain.invoke("日落海滩上的悲剧")
# 7.打印结果
print(review)2.3 顺序链之 SequentialChain
2.3.1 说明
SequentialChain:更通用的顺序链,具体来说:
- 多变量支持 :允许不同子链有独立的输入/输出变量。
- 灵活映射 :需显式定义变量如何从一个链传递到下一个链。即精准地命名输入关键字和输出关键字,来明确链之间的关系。
- 复杂流程控制 :支持分支、条件逻辑(分别通过
input_variables和output_variables配置输入和输出)。
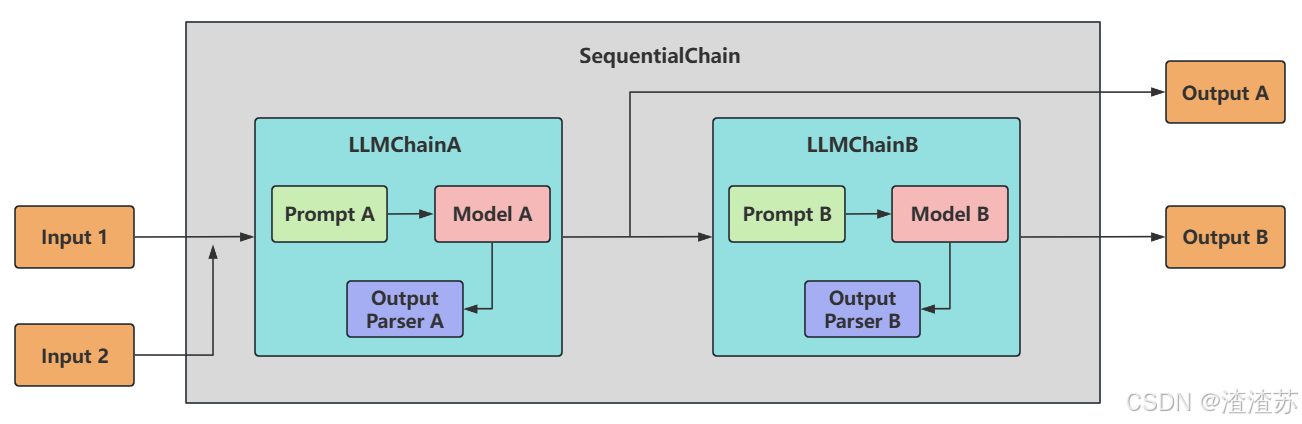
2.3.2 使用举例
举例1:
python
from langchain_core.prompts import ChatPromptTemplate
from langchain.chains import SequentialChain
from langchain_openai import ChatOpenAI
from langchain.chains import LLMChain
from openai import OpenAI
import os
#创建大模型实例
llm = ChatOpenAI(model="gpt-4o-mini")
schainA_template = ChatPromptTemplate.from_messages(
[
("system", "你是一位精通各领域知识的知名教授"),
("human", "请你先尽可能详细的解释一下:{knowledge},并且{action}")
]
)
schainA_chains = LLMChain(llm=llm, prompt=schainA_template, verbose=True, output_key="schainA_chains_key" )
# schainA_chains.invoke({
# "knowledge":"中国的篮球怎么样?",
# "action":"举一个实际的例子"
# } #)
schainB_template = ChatPromptTemplate.from_messages(
[
("system", "你非常善于提取文本中的重要信息,并做出简短的总结"),
("human", "这是针对一个提问完整的解释说明内容:{schainA_chains_key}"),
("human", "请你根据上述说明,尽可能简短的输出重要的结论,请控制在100个字以内"),
]
)
schainB_chains = LLMChain(llm=llm, prompt=schainB_template, verbose=True, output_key='schainB_chains_key' )
Seq_chain = SequentialChain(
chains=[schainA_chains, schainB_chains],
input_variables=["knowledge","action"],
output_variables=["schainA_chains_key","schainB_chains_key"],
verbose=True)
response = Seq_chain.invoke({
"knowledge":"中国足球为什么踢得烂",
"action":"举一个实际的例子"
} )
print(response)还可以单独输出:
python
print(response["schainA_chains_key"])
print(response["schainB_chains_key"])举例2:
python
# 1.导入相关包
from langchain.chains.llm import LLMChain
from langchain_openai import ChatOpenAI
from langchain_core.prompts import PromptTemplate
from langchain.chains import SequentialChain
#创建大模型实例
llm = ChatOpenAI(model="gpt-4o-mini")
# 2.定义任务链一
#chain 1任务:翻译成中文
first_prompt = PromptTemplate.from_template("把下面内容翻译成中文:\n\n{content}")
chain_one = LLMChain(
llm=llm,
prompt=first_prompt,
verbose=True,
output_key="Chinese_Review",
)
# 3.定义任务链二
#chain 2任务:对翻译后的中文进行总结摘要
input_key是上一个chain的output_key
second_prompt = PromptTemplate.from_template("用一句话总结下面内容:\n\n{Chinese_Review}")
chain_two = LLMChain(
llm=llm,
prompt=second_prompt,
verbose=True,
output_key="Chinese_Summary",
)
# 4.定义任务链三
# chain 3任务:识别语言
third_prompt = PromptTemplate.from_template("下面内容是什么语言:\n\n{Chinese_Summary}")
chain_three = LLMChain(
llm=llm,
prompt=third_prompt,
verbose=True,
output_key="Language",
)
# 5.定义任务链四
#chain 4任务:针对摘要使用指定语言进行评论
input_key是上一个chain的output_key
fourth_prompt = PromptTemplate.from_template("请使用指定的语言对以下内容进行评论:\n\n内容:{Chinese_Summary}\n\n语言:{Language}")
chain_four = LLMChain(
llm=llm,
prompt=fourth_prompt,
verbose=True,
output_key="Comment",
)
# 6.总链
#overall任务:翻译成中文->对翻译后的中文进行总结摘要->智能识别语言->针对摘要使用指定语言进行评论
overall_chain = SequentialChain(
chains=[chain_one, chain_two, chain_three, chain_four],
verbose=True,
input_variables=["content"],
output_variables=["Chinese_Review","Chinese_Summary","Language","Comment"],
)
#读取文件
# read file
content = "Recently, we welcomed several new team members who have made significant contributions to their respective departments. I would like to recognize Jane Smith(SSN: 049-45-5928) for her outstanding performance in customer service. Jane has consistently received positive feedback from our clients. Furthermore, please remember that the open enrollment period for our employee benefits program is fast approaching. Should you have any questions or require assistance, please contact our HR representative, Michael Johnson(phone: 418-492-3850, email: michael.johnson@example.com)."
overall_chain.invoke(content)第04章:LangChain使用之Memory
1、Memory概述
1.1 为什么需要Memory
大多数的大模型应用程序都会有一个会话接口,允许我们进行多轮的对话,并有一定的上下文记忆能力。
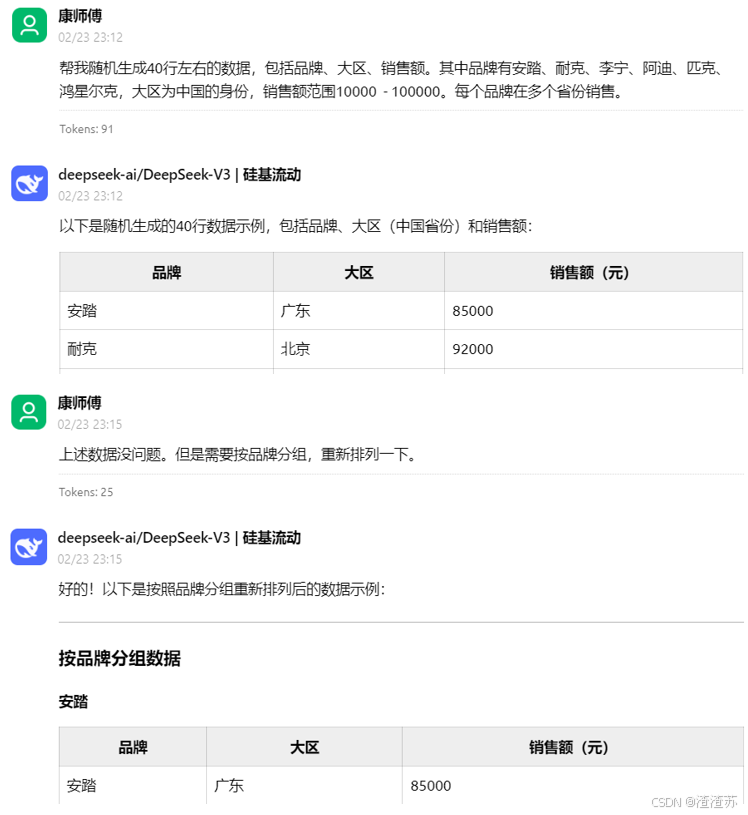
但实际上,模型本身是 不会记忆 任何上下文的,只能依靠用户本身的输入去产生输出。
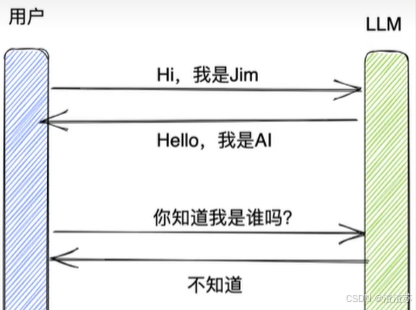
如何实现记忆功能呢?
实现这个记忆功能,就需要额外的模块去保存我们和模型对话的上下文信息,然后在下一次请求时,把 所有的历史信息都输入给模型,让模型输出最终结果。
而在 LangChain中,提供这个功能的模块就称为 Memory(记忆) ,用于存储用户和模型交互的历史信息。
1.2 什么是Memory
Memory ,是LangChain中用于多轮对话中保存和管理上下文信息(比如文本、图像、音频等)的组件。它让应用能够记住用户之前说了什么,从而实现对话的上下文感知能力 ,为构建真正智能和上下文感知的链式对话系统提供了基础。
1.3 Memory的设计理念
- 输入问题:(
{"question":...}) - 读取历史消息:从Memory中READ历史消息(
{"past_messages":[...]}) - 构建提示(Prompt) :读取到的历史消息和当前问题会被合并,构建一个新的Prompt
- 模型处理:构建好的提示会被传递给语言模型进行处理。语言模型根据提示生成一个输出。
- 解析输出:输出解析器通过正则表达式 regex(
"Answer:(.*)")来解析,返回一个回答({"answer":...})给用户 - 得到回复并写入Memory:新生成的回答会与当前的问题一起写入Memory,更新对话历史。Memory会存储最新的对话内容,为后续的对话提供上下文支持。
问题:一个链如果接入了 Memory模块,其会与Memory模块交互几次呢?
链内部会与 Memory模块进行两次交互:读取和写入:
1、收到用户输入时,从记忆组件中查询相关历史信息,拼接历史信息和用户的输入到提示词中传给LLM。
2、返回响应之前,自动把LLM返回的内容写入到记忆组件,用于下次查询。
1.4 不使用Memory模块,如何拥有记忆?
不借助LangChain情况下,我们如何实现大模型的记忆能力?
思考 :通过 messages变量,不断地将历史的对话信息追加到对话列表中,以此让大模型具备上下文记忆能力。
python
import os
import dotenv
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY1")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")
# 创建大模型实例
llm = ChatOpenAI(model="gpt-4o-mini")
from langchain.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.messages import SystemMessage, HumanMessage, AIMessage
llm = ChatOpenAI(model="gpt-4o-mini")
def chat_with_model(question):
# 步骤一:初始化消息
chat_prompt_template = ChatPromptTemplate.from_messages([
("system", "你是一位人工智能小助手"),
("human", "{question}")
])
# 步骤二:定义一个循环体:
while True:
# 步骤三:调用模型
chain = chat_prompt_template | llm
response = chain.invoke({"question": question})
# 步骤四:获取模型回答
print(f"模型回答: {response.content}")
# 询问用户是否还有其他问题
user_input = input("您还有其他问题想问嘛?(输入'退出'结束对话)")
# 设置结束循环的条件
if (user_input == "退出"):
break
# 步骤五:记录用户回答
chat_prompt_template.messages.append(AIMessage(content=response.content))
chat_prompt_template.messages.append(HumanMessage(content=user_input))
chat_with_model("你好")这种形式是最简单的一种让大模型具备上下文知识的存储方式,任何记忆的基础都是所有聊天交互的历史记录。即使这些不全部直接使用,也需要以某种形式存储。
2、基础Memory模块的使用
2.1 Memory模块的设计思路
如何设计Memory模块?
- 层次1(最直接的方式):保留一个聊天消息列表
- 层次2(简单的新思路):只返回最近交互的k条消息
- 层次3(稍微复杂一点):返回过去k条消息的简洁摘要
- 层次4(更复杂):从存储的消息中提取实体,并且仅返回有关当前运行中引用的实体的信息
LangChain的设计:针对上述情况,LangChain构建了一些可以直接使用的 Memory工具,用于存储聊天消息的一系列集成。

2.2 ChatMessageHistory(基础)
ChatMessageHistory 是一个用于存储和管理对话消息的基础类,它直接操作消息对象(如 HumanMessage, AIMessage 等),是其它记忆组件的底层存储工具。
在API文档中, ChatMessageHistory 还有一个别名类:InMemoryChatMessageHistory;导包时,需使用:from langchain.memory import ChatMessageHistory
特点:
- 纯粹是消息对象的"存储器",与记忆策略(如缓冲、窗口、摘要等)无关。
- 不涉及消息的格式化(如转成文本字符串)
场景1:记忆存储
ChatMessageHistory是用于管理和存储对话历史的具体实现。
python
# 1.导入相关包
from langchain.memory import ChatMessageHistory
# 2.实例化ChatMessageHistory对象
history = ChatMessageHistory()
# 3.添加UserMessage
history.add_user_message("hi!")
# 4.添加AIMessage
history.add_ai_message("whats up?")
# 5.返回存储的所有消息列表
print(history.messages)场景2:对接LLM
python
from langchain.memory import ChatMessageHistory
history = ChatMessageHistory()
history.add_ai_message("我是一个无所不能的小智")
history.add_user_message("你好,我叫小明,请介绍一下你自己")
history.add_user_message("我是谁呢?")
print(history.messages) # 返回List[BaseMessage]类型
python
# 创建LLM
llm = ChatOpenAI(model_name='gpt-4o-mini')
llm.invoke(history.messages)
AIMessage(content='你好,小明!我是一个人工智能助手,旨在为你提供信息、回答问题,以及帮助你解决各种问题。你可以问我任何事情,无论是关于知识、学习还是生活中的实际问题,我都会尽力帮助你!你今天想聊些什么呢?', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 59, 'prompt_tokens': 36, 'total_tokens': 95, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_efad92c60b', 'id': 'chatcmpl-BpnIMSTuLSRcmpJJlIfVmPWB8hGhW', 'service_tier': None, 'finish_reason': 'stop', 'logprobs': None}, id='run--cd9b5546-0799-47d2-9c0f-ac35aa78e9b1-0', usage_metadata={'input_tokens': 36, 'output_tokens': 59, 'total_tokens': 95, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}})2.3 ConversationBufferMemory
ConversationBufferMemory是一个基础的对话记忆(Memory)组件 ,专门用于按原始顺序存储完整的对话历史。
适用场景:对话轮次较少、依赖完整上下文的场景(如简单的聊天机器)
特点:
- 完整存储对话历史
- 简单 、无裁剪 、无压缩
- 与 Chains/Models无缝集成
- 支持两种返回格式(通过
return_messages参数控制输出格式)return_messages=True返回消息对象列表(List[BaseMessage]return_messages=False(默认)返回拼接的纯文本字符串
场景1:入门使用
举例1:
python
# 1.导入相关包
from langchain.memory import ConversationBufferMemory
# 2.实例化ConversationBufferMemory对象
memory = ConversationBufferMemory()
# 3.保存消息到内存中
memory.save_context(inputs={"input": "你好,我是人类"}, outputs={"output": "你好,我是AI助手"})
memory.save_context(inputs={"input": "很开心认识你"}, outputs={"output": "我也是"})
# 4.读取内存中消息(返回消息内容的纯文本)
print(memory.load_memory_variables({}))
python
{'history': 'Human: 你好,我是人类\nAI: 你好,我是AI助手\nHuman: 很开心认识你\nAI: 我也是'}注意:
- 不管inputs、outputs的key用什么名字,都认为inputs的key是human,outputs的key是AI。
- 打印的结果的json数据的key,默认是"history"。可以通过
ConversationBufferMemory的memory_key属性修改。
举例2:
python
# 1.导入相关包
from langchain.memory import ConversationBufferMemory
# 2.实例化ConversationBufferMemory对象
memory = ConversationBufferMemory(return_messages=True)
# 3.保存消息到内存中
memory.save_context({"input": "hi"}, {"output": "whats up"})
# 4.读取内存中消息(返回消息)
print(memory.load_memory_variables({}))
# 5.读取内存中消息(访问原始消息列表)
print(memory.chat_memory.messages)场景2:结合chain
举例1:使用PromptTemplate
python
from langchain_openai import OpenAI
from langchain.memory import ConversationBufferMemory
from langchain.chains.llm import LLMChain
from langchain_core.prompts import PromptTemplate
# 初始化大模型
llm = OpenAI(model="gpt-4o-mini", temperature=0)
# 创建提示
# 有两个输入键:实际输入与来自记忆类的输入
# 需确保PromptTemplate和 ConversationBufferMemory中的键匹配
template = """你可以与人类对话。
当前对话: {history}
人类问题: {question}
回复: """
prompt = PromptTemplate.from_template(template)
# 创建ConversationBufferMemory
memory = ConversationBufferMemory()
# 初始化链
chain = LLMChain(llm=llm, prompt=prompt, memory=memory)
# 提问
res1 = chain.invoke({"question": "我的名字叫Tom"})
print(res1)
python
{'question': '我的名字叫Tom', 'history': '', 'text': '你好,Tom!很高兴认识你。你今天过得怎么样?有什么我可以帮助你的吗?'}
python
res = chain.invoke({"question": "我的名字是什么?"})
print(res)
python
{'question': '我的名字是什么?', 'history': 'Human: 我的名字叫Tom\nAI: 你好,Tom!很高兴认识你。你今天过得怎么样?有什么我可以帮助你的吗?', 'text': '你的名字是Tom。你今天过得怎么样?有什么我可以帮助你的吗?'}举例2 :可以通过memory_key 修改memory数据的变量名
python
from langchain_openai import OpenAI
from langchain.memory import ConversationBufferMemory
from langchain.chains.llm import LLMChain
from langchain_core.prompts import PromptTemplate
# 初始化大模型
llm = OpenAI(model="gpt-4o-mini", temperature=0)
# 创建提示
# 有两个输入键:实际输入与来自记忆类的输入
# 需确保PromptTemplate和 ConversationBufferMemory中的键匹配
template = """你可以与人类对话。
当前对话: {chat_history}
人类问题: {question}
回复: """
prompt = PromptTemplate.from_template(template)
# 创建ConversationBufferMemory
memory = ConversationBufferMemory(memory_key="chat_history")
# 初始化链
chain = LLMChain(llm=llm, prompt=prompt, memory=memory)
# 提问
res1 = chain.invoke({"question": "我的名字叫Tom"})
print(str(res1) + "\n")
res = chain.invoke({"question": "我的名字是什么?"})
print(res)
python
{'question': '我的名字叫Tom', 'chat_history': '', 'text': '你好,Tom!很高兴认识你。有什么我可以帮助你的吗?'}
{'question': '我的名字是什么?', 'chat_history': 'Human: 我的名字叫Tom\nAI: 你好,Tom!很高兴认识你。有什么我可以帮助你的吗?', 'text': '你的名字是Tom。很高兴再次见到你!有什么我可以帮助你的吗?'}说明 :创建带Memory功能的Chain,并不能使用统一的LCEL语法。同样地, LLMChain也不能使用管道运算符接 StrOutputParser 。这些设计上的问题,个人推测也是目前Memory模块还是Beta版本的原因之一吧。
举例3:使用ChatPromptTemplate和 return_messages
python
# 1.导入相关包
from langchain_core.messages import SystemMessage
from langchain.chains.llm import LLMChain
from langchain.memory import ConversationBufferMemory
from langchain_core.prompts import MessagesPlaceholder, ChatPromptTemplate, HumanMessagePromptTemplate
from langchain_openai import ChatOpenAI
# 2.创建LLM
llm = ChatOpenAI(model_name='gpt-4o-mini')
# 3.创建Prompt
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个与人类对话的机器人。"),
MessagesPlaceholder(variable_name='history'),
("human", "问题:{question}")
])
# 4.创建Memory
memory = ConversationBufferMemory(return_messages=True)
# 5.创建LLMChain
llm_chain = LLMChain(prompt=prompt, llm=llm, memory=memory)
# 6.调用LLMChain
res1 = llm_chain.invoke({"question": "中国首都在哪里?"})
print(res1, end="\n\n")
python
{'question': '中国首都在哪里?', 'history': [HumanMessage(content='中国首都在哪里?', additional_kwargs={}, response_metadata={}), AIMessage(content='中国的首都是北京市。', additional_kwargs={}, response_metadata={})], 'text': '中国的首都是北京市。'}
python
res2 = llm_chain.invoke({"question": "我刚刚问了什么"})
print(res2)
python
{'question': '我刚刚问了什么', 'history': [HumanMessage(content='中国首都在哪里?', additional_kwargs={}, response_metadata={}), AIMessage(content='中国的首都是北京市。', additional_kwargs={}, response_metadata={}), HumanMessage(content='我刚刚问了什么', additional_kwargs={}, response_metadata={}), AIMessage(content='你刚刚问了中国的首都在哪里。', additional_kwargs={}, response_metadata={})], 'text': '你刚刚问了中国的首都在哪里。'}二者对比
| 特性 | 普通 PromptTemplate | ChatPromptTemplate |
|---|---|---|
| 历史存储时机 | 仅执行后存储 | 执行前存储用户输入+执行后存储输出 |
| 首次调用显示 | 仅显示问题(历史仍为空字符串) | 显示完整问答对 |
| 内部消息类型 | 拼接字符串 | ListBaseMessage |
注意:我们观察到的现象不是 bug ,而是 LangChain为保障对话一致性所做的刻意设计:
- 用户提问后,系统应立即"记住"该问题
- AI回答后,该响应应即刻加入对话上下文
- 返回给客户端的结果应反映最新状态
2.4 ConversationChain
ConversationChain实际上是就是对 ConversationBufferMemory和 LLMChain进行了封装,并且提供一个默认格式的提示词模版(我们也可以不用),从而简化了初始化ConversationBufferMemory 的步骤。
举例1:使用PromptTemplate
python
from langchain.chains.conversation.base import ConversationChain
from langchain_core.prompts.prompt import PromptTemplate
from langchain.chains import LLMChain
# 初始化大模型
llm = ChatOpenAI(model="gpt-4o-mini")
template = """以下是人类与AI之间的友好对话描述。AI表现得很健谈,并提供了大量来自其上下文的具体细节。如果AI不知道问题的答案,它会真诚地表示不知道。
当前对话:
{history}
Human: {input}
AI:"""
prompt = PromptTemplate.from_template(template)
# memory = ConversationBufferMemory()
#
# conversation = LLMChain(
# llm=llm,
# prompt=prompt,
# memory=memory,
# verbose=True,
# )
chain = ConversationChain(llm=llm, prompt=prompt, verbose=True)
chain.invoke({"input": "你好,你的名字叫小智"}) # 注意,chain中的key必须是input,否则会报错
python
{'input': '你好,你的名字叫小智', 'history': '', 'response': '你好!是的,我叫小智。很高兴和你聊聊!你想讨论些什么呢?'}
python
chain.invoke({"input": "你好,你叫什么名字?"})
python
{'input': '你好,你叫什么名字?', 'history': 'Human: 你好,你的名字叫小智\nAI: 你好!是的,我叫小智。很高兴和你聊聊!你想讨论些什么呢?', 'response': '你好!我叫小智。很高兴见到你!有什么想聊的话题吗?'}举例2:使用内置默认格式的提示词模版(内部包含input、history 变量)
python
# 1.导入所需的库
from langchain_openai import ChatOpenAI
from langchain.chains.conversation.base import ConversationChain
# 2.初始化大语言模型
llm = ChatOpenAI(model="gpt-4o-mini")
# 3.初始化对话链
conv_chain = ConversationChain(llm=llm)
# 4.进行对话
resut1 = conv_chain.invoke(input="小明有1只猫")
# print(resut1)
resut2 = conv_chain.invoke(input="小刚有2只狗")
# print(resut2)
resut3 = conv_chain.invoke(input="小明和小刚一共有几只宠物?")
print(resut3)
python
小明有一只猫,小刚有两只狗,所以他们一共有三只宠物。真是热闹的一家人!你喜欢猫还是狗呢?每种宠物都有它们独特的魅力和性格。2.5 ConversationBufferWindowMemory
在了解了ConversationBufferMemory记忆类后,我们知道了它能够无限的将历史对话信息填充到History中,从而给大模型提供上下文的背景。但这会导致内存量十分大 ,并且消耗的token是非常多的,此外,每个大模型都存在最大输入的Token限制。
我们发现,过久远的对话数据往往并不能对当前轮次的问答提供有效的信息,LangChain给出的解决方式是: ConversationBufferWindowMemory模块。
该记忆类会保存一段时间内对话交互的列表,仅使用最近 K个交互 。这样就使缓存区不会变得太大。
特点:
- 适合长对话场景。
- 与 Chains/Models无缝集成
- 支持两种返回格式(通过
return_messages参数控制输出格式)return_messages=True返回消息对象列表(List[BaseMessage]return_messages=False(默认)返回拼接的纯文本字符串
场景1:入门使用
通过内置在LangChain中的缓存窗口(BufferWindow)可以将meomory "记忆"下来。
举例1:
python
# 1.导入相关包
from langchain.memory import ConversationBufferWindowMemory
# 2.实例化ConversationBufferWindowMemory对象,设定窗口阈值
memory = ConversationBufferWindowMemory(k=2)
# 3.保存消息
memory.save_context({"input": "你好"}, {"output": "怎么了"})
memory.save_context({"input": "你是谁"}, {"output": "我是AI助手"})
memory.save_context({"input": "你的生日是哪天?"}, {"output": "我不清楚"})
# 4.读取内存中消息(返回消息内容的纯文本)
print(memory.load_memory_variables({}))
python
{'history': 'Human: 你是谁\nAI: 我是AI助手\nHuman: 你的生日是哪天?\nAI: 我不清楚'}举例2:
ConversationBufferWindowMemory 也支持使用聊天模型( ChatModel)的情况,同样可以通过return_messages=True 参数,将对话转化为消息列表形式。
python
# 1.导入相关包
from langchain.memory import ConversationBufferWindowMemory
# 2.实例化ConversationBufferWindowMemory对象,设定窗口阈值
memory = ConversationBufferWindowMemory(k=2, return_messages=True)
# 3.保存消息
memory.save_context({"input": "你好"}, {"output": "怎么了"})
memory.save_context({"input": "你是谁"}, {"output": "我是AI助手小智"})
memory.save_context({"input": "初次对话,你能介绍一下你自己吗?"}, {"output": "当然可以了。我是一个无所不能的小智。"})
# 4.读取内存中消息(返回消息内容的纯文本)
print(memory.load_memory_variables({}))
python
{'history': [HumanMessage(content='你是谁', additional_kwargs={}, response_metadata={}),
AIMessage(content='我是AI助手小智', additional_kwargs={}, response_metadata={}),
HumanMessage(content='初次对话,你能介绍一下你自己吗?', additional_kwargs={}, response_metadata={}),
AIMessage(content='当然可以了。我是一个无所不能的小智。', additional_kwargs={}, response_metadata={})]}场景2:结合chain
借助提示词模版去构建LangChain
python
from langchain.memory import ConversationBufferWindowMemory
# 1.导入相关包
from langchain_core.prompts.prompt import PromptTemplate
from langchain.chains.llm import LLMChain
# 2.定义模版
template = """以下是人类与AI之间的友好对话描述。AI表现得很健谈,并提供了大量来自其上下文的具体细节。如果AI不知道问题的答案,它会表示不知道。
当前对话:
{history}
Human: {question}
AI:"""
# 3.定义提示词模版
prompt_template = PromptTemplate.from_template(template)
# 4.创建大模型
llm = ChatOpenAI(model="gpt-4o-mini")
# 5.实例化ConversationBufferWindowMemory对象,设定窗口阈值
memory = ConversationBufferWindowMemory(k=1)
# 6.定义LLMChain
conversation_with_summary = LLMChain(
llm=llm,
prompt=prompt_template,
memory=memory,
verbose=True,
)
# 7.执行链(第一次提问)
respon1 = conversation_with_summary.invoke({"question": "你好,我是孙小空"})
# print(respon1)
# 8.执行链(第二次提问)
respon2 = conversation_with_summary.invoke({"question": "我还有两个师弟,一个是猪小戒,一个是沙小僧"})
# print(respon2)
# 9.执行链(第三次提问)
respon3 = conversation_with_summary.invoke({"question": "我今年高考,竟然考上了1本"})
# print(respon3)
# 10.执行链(第四次提问)
respon4 = conversation_with_summary.invoke({"question": "我叫什么?"})
print(respon4)> Entering new LLMChain chain...
Prompt after formatting:
以下是人类与AI之间的友好对话描述。AI表现得很健谈,并提供了大量来自其上下文的具体细节。如果AI不知道问题的答案,它会表示不知道。
当前对话:
Human: 你好,我是孙小空
AI:
> Finished chain.
> Entering new LLMChain chain...
Prompt after formatting:
以下是人类与AI之间的友好对话描述。AI表现得很健谈,并提供了大量来自其上下文的具体细节。如果AI不知道问题的答案,它会表示不知道。
当前对话:
Human: 你好,我是孙小空
AI: 你好,孙小空!很高兴和你聊天。你今天过得怎么样?有什么想聊的话题吗?
Human: 我还有两个师弟,一个是猪小戒,一个是沙小僧
AI:
> Finished chain.
> Entering new LLMChain chain...
Prompt after formatting:
以下是人类与AI之间的友好对话描述。AI表现得很健谈,并提供了大量来自其上下文的具体细节。如果AI不知道问题的答案,它会表示不知道。
当前对话:
Human: 我还有两个师弟,一个是猪小戒,一个是沙小僧
AI: 哦,听起来你们都是有趣的人物!猪小戒和沙小僧的名字真特别,他们是不是有一些有趣的特长或者爱好呢?如果你们在一起会做些什么呢?
Human: 我今年高考,竟然考上了1本
AI:
> Finished chain.
> Entering new LLMChain chain...
Prompt after formatting:
以下是人类与AI之间的友好对话描述。AI表现得很健谈,并提供了大量来自其上下文的具体细节。如果AI不知道问题的答案,它会表示不知道。
当前对话:
Human: 我今年高考,竟然考上了1本
AI: 太棒了!恭喜你考上了1本,这真是一个了不起的成就!高考是一个重要的里程碑,你一定为了这个目标付出了很多努力。你打算选择什么专业呢?或者你对未来的大学生活有什么期待吗?
Human: 我叫什么?
AI:
> Finished chain.
python
{'input': '我叫什么?', 'history': 'Human: 我今年高考,竟然考上了1本\nAI: 太棒了!恭喜你考上了1本,这真是一个了不起的成就!高考是一个重要的里程碑,你一定为了这个目标付出了很多努力。你打算选择什么专业呢?或者你对未来的大学生活有什么期待吗?', 'text': '抱歉,我不知道你的名字。不过,我很高兴能与您进行交流!如果你愿意分享更多关于你的事情,比如你的兴趣或未来的计划,我会很乐意听!'}思考 :将参考 k=1替换成 k=3,会怎样呢?
python
{'input': '我叫什么?', 'history': 'Human: 你好,我是孙小空\nAI: 你好,孙小空!很高兴和你交流。有什么我可以帮助你的吗?\nHuman: 我还有两个师弟,一个是猪小戒,一个是沙小僧\nAI: 你们的名字听起来很有趣,似乎有点像《西游记》中的角色!猪小戒和沙小僧一定也很特别。你们平时一起做些什么呢?\nHuman: 我今年高考,竟然考上了1本\nAI: 太棒了,恭喜你考上了本科!这是一个重要的里程碑,你一定为自己感到骄傲。你打算大学学什么专业呢?或者有什么特别的目标和期待吗?', 'text': '你叫孙小空!如果我没记错的话,这个名字很有个性。你喜欢这个名字吗?'}3、其他Memory模块
3.1 ConversationTokenBufferMemory
ConversationTokenBufferMemory是 LangChain中一种基于 Token数量控制的对话记忆机制。如果字符数量超出指定数目,它会切掉这个对话的早期部分,以保留与最近的交流相对应的字符数量。
特点:
- Token精准控制
- 原始对话保留
原理:
举例 : 情况1:
python
# 1.导入相关包
from langchain.memory import ConversationTokenBufferMemory
from langchain_openai import ChatOpenAI
# 2.创建大模型
llm = ChatOpenAI(model="gpt-4o-mini")
# 3.定义ConversationTokenBufferMemory对象
memory = ConversationTokenBufferMemory(
llm=llm,
max_token_limit=10 # 设置token上限
)
# 添加对话
memory.save_context({"input": "你好吗?"}, {"output": "我很好,谢谢!"})
memory.save_context({"input": "今天天气如何?"}, {"output": "晴天,25度"})
# 查看当前记忆
print(memory.load_memory_variables({}))
python
{'history': ''}情况2:
python
# 1.导入相关包
from langchain.memory import ConversationTokenBufferMemory
from langchain_openai import ChatOpenAI
# 2.创建大模型
llm = ChatOpenAI(model="gpt-4o-mini")
# 3.定义ConversationTokenBufferMemory对象
memory = ConversationTokenBufferMemory(
llm=llm,
max_token_limit=50 # 设置token上限
)
# 添加对话
memory.save_context({"input": "你好吗?"}, {"output": "我很好,谢谢!"})
memory.save_context({"input": "今天天气如何?"}, {"output": "晴天,25度"})
# 查看当前记忆
print(memory.load_memory_variables({}))
python
{'history': 'Human: 你好吗?\nAI: 我很好,谢谢!\nHuman: 今天天气如何?\nAI: 晴天,25度'}3.2 ConversationSummaryMemory
前面的方式发现,如果全部保存下来太过浪费,截断时无论是按照对话条数还是 token都是无法保证既节省内存又保证对话质量的,所以推出ConversationSummaryMemory、 ConversationSummaryBufferMemory
ConversationSummaryMemory 是 LangChain中一种智能压缩对话历史的记忆机制,它通过大语言模型(LLM)自动生成对话内容的精简摘要 ,而不是存储原始对话文本。这种记忆方式特别适合长对话和需要保留核心信息的场景。
特点:
- 摘要生成
- 动态更新
- 上下文优化
原理:
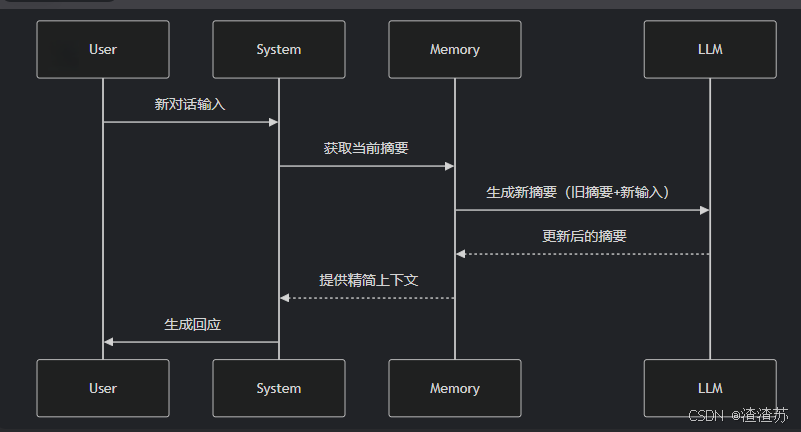
场景1:如果实例化ConversationSummaryMemory前,没有历史消息,可以使用构造方法实例化
python
# 1.导入相关包
from langchain.memory import ConversationSummaryMemory, ChatMessageHistory
from langchain_openai import ChatOpenAI
# 2.创建大模型
llm = ChatOpenAI(model="gpt-4o-mini")
# 3.定义ConversationSummaryMemory对象
memory = ConversationSummaryMemory(llm=llm)
# 4.存储消息
memory.save_context({"input": "你好"}, {"output": "怎么了"})
memory.save_context({"input": "你是谁"}, {"output": "我是AI助手小智"})
memory.save_context({"input": "初次对话,你能介绍一下你自己吗?"}, {"output": "当然可以了。我是一个无所不能的小智。"})
# 5.读取消息(总结后的)
print(memory.load_memory_variables({}))
python
{'history': 'The human greets the AI in Chinese by saying hello, and the AI responds by asking, What\'s wrong? The human then asks, Who are you? and the AI replies, I am AI assistant Xiao Zhi. Additionally, the human asks for a self-introduction, and the AI describes itself as an all-capable assistant named Xiao Zhi.'}场景2:如果实例化 ConversationSummaryMemory 前,已经有历史消息,可以调用from_messages()实例化
python
# 1.导入相关包
from langchain.memory import ConversationSummaryMemory, ChatMessageHistory
from langchain_openai import ChatOpenAI
# 2.定义ChatMessageHistory对象
llm = ChatOpenAI(model="gpt-4o-mini")
# 3.假设原始消息
history = ChatMessageHistory()
history.add_user_message("你好,你是谁?")
history.add_ai_message("我是AI助手小智")
# 4.初始化ConversationSummaryMemory实例
memory = ConversationSummaryMemory.from_messages(
llm=llm, # 是生成摘要的原材料
chat_memory=history,
)
print(memory.load_memory_variables({}))
memory.save_context(inputs={"human": "我的名字叫小明"}, outputs={"AI": "很高兴认识你"})
print(memory.load_memory_variables({}))
print(memory.chat_memory.messages)
python
{'history': 'The human greets the AI and asks who it is. The AI responds that it is an AI assistant named Xiao Zhi.'}
{'history': 'The human greets the AI and asks who it is. The AI responds that it is an AI assistant named Xiao Zhi. The human introduces themselves as Xiao Ming, and the AI expresses pleasure in meeting them.'}
[HumanMessage(content='你好,你是谁?', additional_kwargs={}, response_metadata={}),
AIMessage(content='我是AI助手小智', additional_kwargs={}, response_metadata={}),
HumanMessage(content='我的名字叫小明', additional_kwargs={}, response_metadata={}),
AIMessage(content='很高兴认识你', additional_kwargs={}, response_metadata={})]3.3 ConversationSummaryBufferMemory
ConversationSummaryBufferMemory 是 LangChain中一种混合型记忆机制,它结合了ConversationBufferMemory (完整对话记录)和 ConversationSummaryMemory (摘要记忆)的优点,在保留最近对话原始记录的同时,对较早的对话内容进行智能摘要 。
特点:
- 保留最近N条原始对话:确保最新交互的完整上下文
- 摘要较早历史:对超出缓冲区的旧对话进行压缩,避免信息过载
- 平衡细节与效率:既不会丢失关键细节,又能处理长对话
原理:
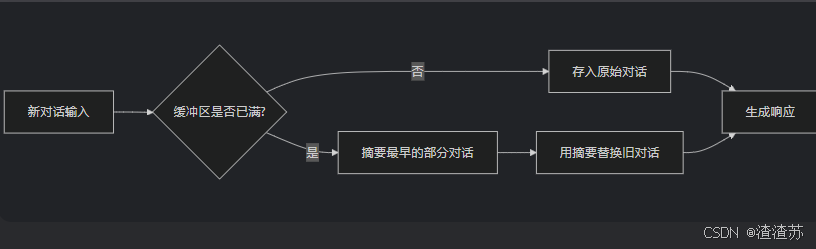
场景1:入门使用
情况1:构造方法实例化,并设置max_token_limit
python
# 1.导入相关的包
from langchain.memory import ConversationSummaryBufferMemory
from langchain_openai import ChatOpenAI
# 2.定义模型
llm = ChatOpenAI(model_name="gpt-4o-mini",temperature=0)
# 3.定义ConversationSummaryBufferMemory对象
memory = ConversationSummaryBufferMemory(
llm=llm, max_token_limit=40, return_messages=True
)
# 4.保存消息
memory.save_context({"input": "你好,我的名字叫小明"}, {"output": "很高兴认识你,小明"})
memory.save_context({"input": "李白是哪个朝代的诗人"}, {"output": "李白是唐朝诗人"})
memory.save_context({"input": "唐宋八大家里有苏轼吗?"}, {"output": "有"})
# 5.读取内容
print(memory.load_memory_variables({}))
print(memory.chat_memory.messages)情况2:
python
# 1.导入相关的包
from langchain.memory import ConversationSummaryBufferMemory
from langchain_openai import ChatOpenAI
# 2.定义模型
llm = ChatOpenAI(model_name="gpt-4o-mini",temperature=0)
# 3.定义ConversationSummaryBufferMemory对象
memory = ConversationSummaryBufferMemory(
llm=llm, max_token_limit=100, return_messages=True
)
# 4.保存消息
memory.save_context({"input": "你好,我的名字叫小明"}, {"output": "很高兴认识你,小明"})
memory.save_context({"input": "李白是哪个朝代的诗人"}, {"output": "李白是唐朝诗人"})
memory.save_context({"input": "唐宋八大家里有苏轼吗?"}, {"output": "有"})
# 5.读取内容
print(memory.load_memory_variables({}))
print(memory.chat_memory.messages)场景2:客服
python
from langchain.memory import ConversationSummaryBufferMemory
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain.chains.llm import LLMChain
# 1、初始化大语言模型
llm = ChatOpenAI(
model="gpt-4o-mini",
temperature=0.5,
max_tokens=500
)
# 2、定义提示模板
prompt = ChatPromptTemplate.from_messages([
("system", "你是电商客服助手,用中文友好回复用户问题。保持专业但亲切的语气。"),
MessagesPlaceholder(variable_name="chat_history"),
("human", "{input}")
])
# 3、创建带摘要缓冲的记忆系统
memory = ConversationSummaryBufferMemory(
llm=llm,
max_token_limit=400,
memory_key="chat_history",
return_messages=True
)
# 4、创建对话链
chain = LLMChain(
llm=llm,
prompt=prompt,
memory=memory,
)
# 5、模拟多轮对话
dialogue = [
("你好,我想查询订单12345的状态", None),
("这个订单是上周五下的", None),
("我现在急着用,能加急处理吗", None),
("等等,我可能记错订单号了,应该是12346", None),
("对了,你们退货政策是怎样的", None)
]
# 6、执行对话
for user_input, _ in dialogue:
response = chain.invoke({"input": user_input})
print(f"用户: {user_input}")
print(f"客服: {response['text']}\n")
# 7、查看当前记忆状态
print("\n=== 当前记忆内容 ===")
print(memory.load_memory_variables({}))3.4 ConversationEntityMemory(了解)
ConversationEntityMemory 是一种基于实体的对话记忆机制,它能够智能地识别、存储和利用对话中出现的实体信息(如人名、地点、产品等)及其属性/关系,并结构化存储,使 AI 具备更强的上下文理解和记忆能力。
好处:解决信息过载问题
- 长对话中大量冗余信息会干扰关键事实记忆
- 通过对实体摘要,可以压缩非重要细节(如删除寒暄等,保留价格/时间等硬性事实)
应用场景:在医疗等高风险领域,必须用实体记忆确保关键信息(如过敏史)被100%准确识别和拦截。
{"input": "我头痛,血压140/90,在吃阿司匹林。"},
{"output": "建议监测血压,阿司匹林可继续服用。"}
{"input": "我对青霉素过敏。"},
{"output": "已记录您的青霉素过敏史。"}
{"input": "阿司匹林吃了三天,头痛没缓解。"},
{"output": "建议停用阿司匹林,换布洛芬试试。"}使用ConversationSummaryMemory
"患者主诉头痛和⾼⾎压(140/90),正在服⽤阿司匹林。患者对⻘霉素过敏。三天后头痛未缓解,建议更换⽌痛药。"使用ConversationEntityMemory
json
{
"症状": "头痛",
"⾎压": "140/90",
"当前⽤药": "阿司匹林(⽆效)",
"过敏药物": "⻘霉素"
}对比:ConversationSummaryMemory 和 ConversationEntityMemory
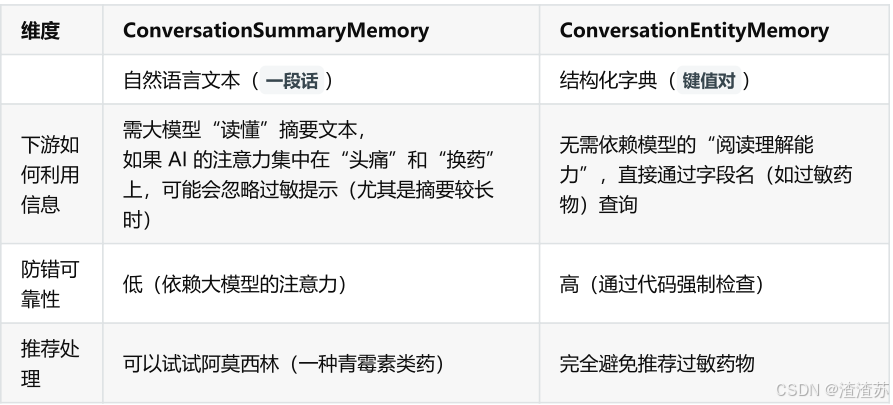
举例:
python
from langchain.chains.conversation.base import LLMChain
from langchain.memory import ConversationEntityMemory
from langchain.memory.prompt import ENTITY_MEMORY_CONVERSATION_TEMPLATE
from langchain_openai import ChatOpenAI
# 初始化大语言模型
llm = ChatOpenAI(model_name='gpt-4o-mini', temperature=0)
# 使用LangChain为实体记忆设计的预定义模板
prompt = ENTITY_MEMORY_CONVERSATION_TEMPLATE
# 初始化实体记忆
memory = ConversationEntityMemory(llm=llm)
# 提供对话链
chain = LLMChain(
llm=llm,
prompt=ENTITY_MEMORY_CONVERSATION_TEMPLATE,
memory=ConversationEntityMemory(llm=llm),
#verbose=True, # 设置为True可以看到链的详细推理过程
)
# 进行几轮对话,记忆组件会在后台自动提取和存储实体信息
chain.invoke(input="你好,我叫蜘蛛侠。我的好朋友包括钢铁侠、美国队长和绿巨人。")
chain.invoke(input="我住在纽约。")
chain.invoke(input="我使用的装备是由斯塔克工业提供的。")
# 查询记忆体中存储的实体信息
print("\n当前存储的实体信息:")
print(chain.memory.entity_store.store)
# 基于记忆进行提问
answer = chain.invoke(input="你能告诉我蜘蛛侠住在哪里以及他的好朋友有哪些吗?")
print("\nAI的回答:")
print(answer)3.5 ConversationKGMemory(了解)
ConversationKGMemory是一种基于知识图谱(Knowledge Graph)的对话记忆模块,它比ConversationEntityMemory 更进一步,不仅能识别和存储实体,还能捕捉实体之间的复杂关系,形成结构化的知识网络。
特点:
- 知识图谱结构 将对话内容转化为 (头实体, 关系, 尾实体) 的三元组形式
- 动态关系推理
举例:
pip install networkx
python
#1.导入相关包
from langchain.memory import ConversationKGMemory
from langchain.chat_models import ChatOpenAI
# 2.定义LLM
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
# 3.定义ConversationKGMemory对象
memory = ConversationKGMemory(llm=llm)
# 4.保存会话
memory.save_context({"input": "向山姆问好"}, {"output": "山姆是谁"})
memory.save_context({"input": "山姆是我的朋友"}, {"output": "好的"})
# 5.查询会话
memory.load_memory_variables({"input": "山姆是谁"})
python
memory.get_knowledge_triplets("她最喜欢的颜色是红色")3.6 VectorStoreRetrieverMemory(了解)
VectorStoreRetrieverMemory是一种基于 向量检索 的先进记忆机制,它将对话历史存储在向量数据库中,通过 语义相似度检索 相关信息,而非传统的线性记忆方式。每次调用时,就会查找与该记忆关联最高的k个文档。
适用场景:这种记忆特别适合需要长期记忆和语义理解的复杂对话系统。
原理:
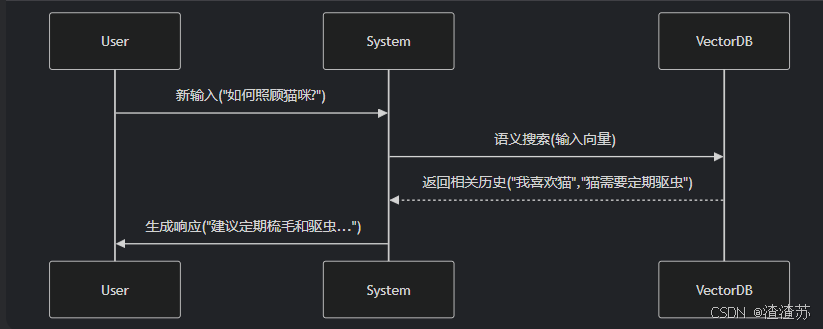
举例:
python
import os
import dotenv
from langchain_openai import OpenAIEmbeddings
dotenv.load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY1")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")
embeddings_model = OpenAIEmbeddings(
model="text-embedding-ada-002"
)
# 1.导入相关包
from langchain_openai import OpenAIEmbeddings
from langchain.memory import VectorStoreRetrieverMemory
from langchain_community.vectorstores import FAISS
from langchain.memory import ConversationBufferMemory
# 2.定义ConversationBufferMemory对象
memory = ConversationBufferMemory()
memory.save_context({"input": "我最喜欢的食物是披萨"}, {"output": "很高兴知道"})
memory.save_context({"Human": "我喜欢的运动是跑步"}, {"AI": "好的,我知道了"})
memory.save_context({"Human": "我最喜欢的运动是足球"}, {"AI": "好的,我知道了"})
# 3.定义向量嵌入模型
embeddings_model = OpenAIEmbeddings(
model="text-embedding-ada-002"
)
# 4.初始化向量数据库
vectorstore = FAISS.from_texts(memory.buffer.split("\n"), embeddings_model) # 空初始化
# 5.定义检索对象
retriever = vectorstore.as_retriever(search_kwargs=dict(k=1))
# 6.初始化VectorStoreRetrieverMemory
memory = VectorStoreRetrieverMemory(retriever=retriever)
print(memory.load_memory_variables({"prompt": "我最喜欢的食物是"}))第05章:LangChain使用之Tools
1、Tools概述
1.1 介绍
要构建更强大的AI工程应用,只有生成文本这样的"纸上谈兵 "能力自然是不够的。工具Tools不仅仅 是"肢体"的延伸,更是为"大脑"插上了想象力的"翅膀"。借助工具,才能让AI应用的能力真正具 备无限的可能,才能从"认识世界 "走向"改变世界 "。
Tools用于扩展大语言模型(LLM)的能力,使其能够与外部系统、API或自定义函数交互,从而完成仅靠文本生成无法实现的任务(如搜索、计算、数据库查询等)。
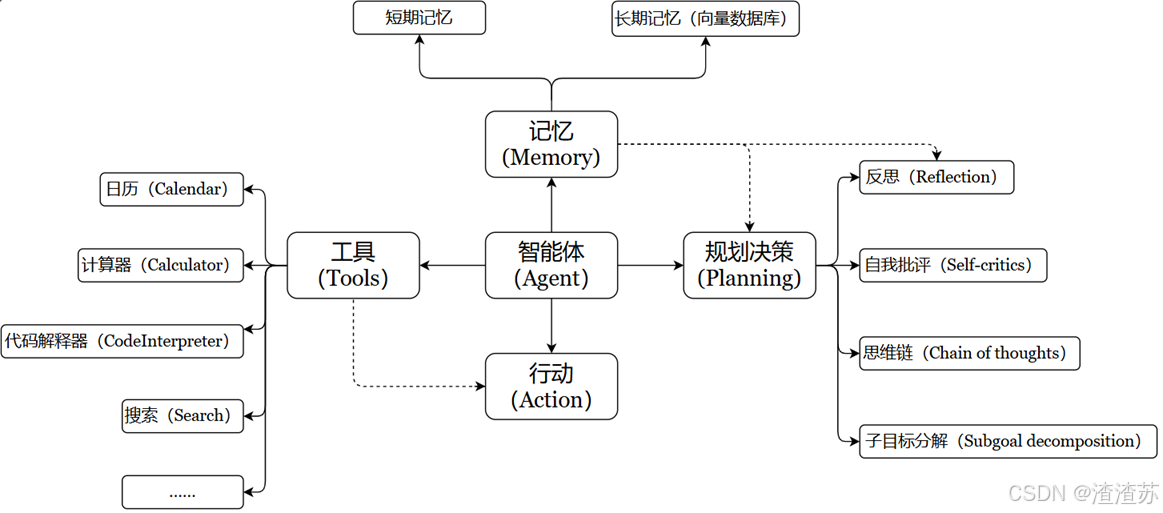
特点:
- 增强 LLM的功能 :让 LLM突破纯文本生成的限制,执行实际操作(如调用搜索引擎、查询数据 库、运行代码等)
- 支持智能决策 :在Agent工作流中,LLM根据用户输入动态选择最合适的 Tool完成任务。
- 模块化设计 :每个 Tool专注一个功能,便于复用和组合(例如:搜索工具+计算工具+天气查 询工具)
LangChain拥有大量第三方工具。请访问工具集成查看可用工具列表。
https://python.langchain.com/v0.2/docs/integrations/tools/
1.2 Tool的要素
Tools本质上是封装了特定功能的可调用模块,是Agent、Chain或LLM可以用来与世界互动的接口。Tool通常包含如下几个要素:
name:工具的名称description:工具的功能描述- 该工具输入的 JSON模式
- 要调用的函数
return_direct:是否应将工具结果直接返回给用户(仅对Agent相关)
实操步骤:
步骤1:将name、description和 JSON模式作为上下文提供给LLM
步骤2:LLM会根据提示词推断出需要调用哪些工具 ,并提供具体的调用参数信息
步骤3:用户需要根据返回的工具调用信息,自行触发相关工具的回调
注意: 如果工具具有精心选择的名称、描述和JSON模式,则模型的性能将更好。下一章内容我们可以看到工具的调用动作可以通过Agent自主接管。
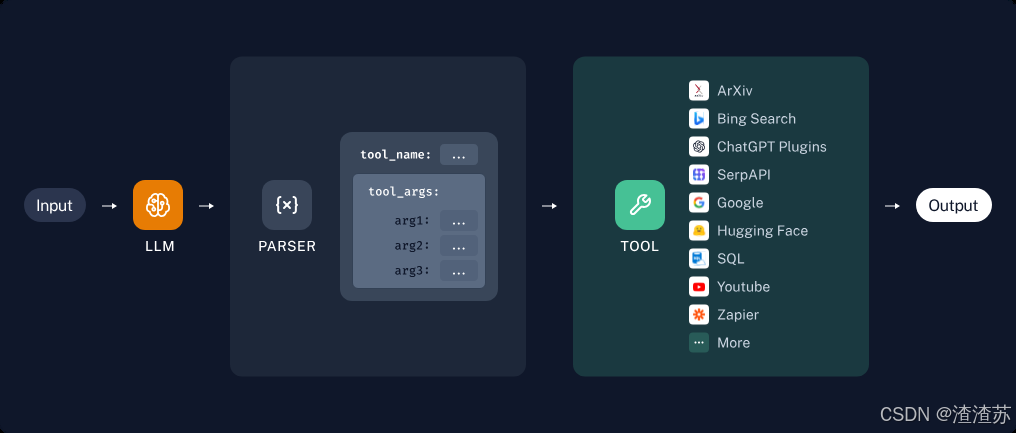
2、自定义工具
2.1 两种自定义方式
第1种:使用@tool装饰器(自定义工具的最简单方式)
装饰器默认使用函数名称作为工具名称,但可以通过参数 name_or_callable来覆盖此设置。
同时,装饰器将使用函数的文档字符串作为工具的描述 ,因此函数必须提供文档字符串。
第2种:使用StructuredTool.from_function类方法
这类似于@tool装饰器,但允许更多配置和同步/异步实现的规范。
2.2 几个常用属性
Tool由几个常用属性组成:
| 属性 | 类型 | 描述 |
|---|---|---|
name |
str |
必选的 ,在提供给LLM或Agent的工具集中必须是唯一的。 |
description |
str |
可选但建议 ,描述工具的功能。LLM或Agent将使用此描述作为上下文,使用它确定工具的使用 |
args_schema |
PydanticBaseModel |
可选但建议 ,可用于提供更多信息(例如,few-shot示例) 或验证预期参数。 |
return_direct |
boolean |
仅对Agent相关。当为True时,在调用给定工具后,Agent将停止并将结果直接返回给用户。 |
2.3 具体实现
方式1:@tool装饰器
举例1:
python
from langchain.tools import tool
@tool
def add_number(a: int, b: int) -> int:
"""两个整数相加"""
return a + b
print(f"name={add_number.name}")
print(f"args={add_number.args}")
print(f"description={add_number.description}")
print(f"return_direct={add_number.return_direct}")
res = add_number.invoke({"a": 10, "b": 20})
print(res)输出:
name= add_number
description=两个整数相加
args={ 'a':{ 'title': 'A', 'type': 'integer'}, 'b':{ 'title': 'B', 'type': 'integer'}}
return_direct= False
30说明: return_direct参数的默认值是False。当return_direct=False时,工具执行结果会返回给 Agent,让Agent决定下一步操作;而return_direct=True则会中断这个循环,直接结束流程,返回结 果给用户。
举例2:通过@tool的参数设置进行重置
python
from langchain.tools import tool
@tool(name_or_callable="add_two_number", description="two number add", return_direct=True)
def add_number(a: int, b: int) -> int:
"""两个整数相加"""
return a + b
print(f"name={add_number.name}")
print(f"description={add_number.description}")
print(f"args={add_number.args}")
print(f"return_direct={add_number.return_direct}")
res = add_number.invoke({"a": 10, "b": 20})
print(res)输出:
name= add_two_number
description= two number add
args={ 'a':{ 'title': 'A', 'type': 'integer'}, 'b':{ 'title': 'B', 'type': 'integer'}}
return_direct= True
30补充:还可以修改参数的说明
python
from langchain.tools import tool
from pydantic import BaseModel, Field
class FieldInfo(BaseModel):
a: int = Field(description="第1个参数")
b: int = Field(description="第2个参数")
@tool(name_or_callable="add_two_number", description="two number add", args_schema=FieldInfo, return_direct=True)
def add_number(a: int, b: int) -> int:
"""两个整数相加"""
return a + b输出:
name= add_two_number
description= two number add
args={ 'a':{ 'description':'第1个参数', 'title': 'A', 'type': 'integer'}, 'b':{ 'description':'第2个参数', 'title': 'B', 'type': 'integer'}}
return_direct= True
30方式2:StructuredTool的from_function()
StructuredTool.from_function类方法提供了比@tool装饰器更多的可配置性,而无需太多额外的代 码。
举例1:
python
from langchain_core.tools import StructuredTool
def search_function(query: str):
return "LangChain"
search1 = StructuredTool.from_function(
func=search_function,
name="Search",
description="useful for when you need to answer questions about current events"
)
print(f"name={search1.name}")
print(f"description={search1.description}")
print(f"args={search1.args}")
search1.invoke("hello")输出:
name= Search
description= useful for when you need to answer questions about current events
args={ 'query':{ 'title': 'Query', 'type': 'string'}}
LangChain举例2:
python
from langchain_core.tools import StructuredTool
from pydantic import Field, BaseModel
class FieldInfo(BaseModel):
query: str = Field(description="要检索的关键词")
def search_function(query: str):
return "LangChain"
search1 = StructuredTool.from_function(
func=search_function,
name="Search",
description="useful for when you need to answer questions about current events",
args_schema=FieldInfo,
return_direct=True,
)
print(f"name={search1.name}")
print(f"description={search1.description}")
print(f"args={search1.args}")
print(f"return_direct={search1.return_direct}")
search1.invoke("hello")输出:
name= Search
description= useful for when you need to answer questions about current events
args={ 'query':{ 'description':'要检索的关键词', 'title': 'Query', 'type': 'string'}}
return_direct= True
LangChain2.4 工具调用举例
我们通过大模型分析用户需求,判断是否需要调用指定工具。
举例1:大模型分析调用工具
python
# 1.导入相关依赖
from langchain_community.tools import MoveFileTool
from langchain_core.messages import HumanMessage
from langchain_core.utils.function_calling import convert_to_openai_function
import os
import dotenv
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY1")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")
# 2.定义LLM模型
chat_model = ChatOpenAI(model="gpt-4o-mini", temperature=0)
# 3.定义工具
tools = [MoveFileTool()]
# 4.这里需要将工具转换为openai函数,后续再将函数传入模型调用
functions = [convert_to_openai_function(t) for t in tools]
# print(functions[0])
# 5.提供大模型调用的消息列表
messages = [HumanMessage(content="将文件a移动到桌面")]
# 6.模型使用函数
response = chat_model.invoke(
input=messages,
functions=functions
)
print(response)输出:
作为对照,修改代码:
python
response = chat_model.invoke(
[HumanMessage(content="今天的天气怎么样?")],
functions=functions
)
print(response)输出:
调用工具说明
两种情况:
情况1:大模型决定调用工具
如果模型认为需要调用工具(如 MoveFileTool ),返回的 message会包含:
content: 通常为空(因为模型选择调用工具,而非生成自然语言回复)。additional_kwargs: 包含工具调用的详细信息:
python
AIMessage(
content='', #无自然语言回复
additional_kwargs={
'function_call':{
'name':'move_file', #工具名称
'arguments': '{"source_path":"a","destination_path":"/Users/YourUsername/Desktop/a"}' #工具参数
}
}
)情况2:大模型不调用工具
如果模型认为无需调用工具(例如用户输入与工具无关),返回的 message会是普通文本回复:
python
AIMessage(
content='我没有找到需要移动的文件。', #自然语言回复
additional_kwargs={'refusal': None} #无工具调用
)举例2:确定工具并调用
python
#定义LLM模型
chat_model = ChatOpenAI(model="gpt-4o-mini", temperature=0)
#定义工具
tools = [MoveFileTool()]
#将工具转换为openai函数
functions = [convert_to_openai_function(t) for t in tools]
#提供消息列表
messages = [HumanMessage(content="将本目录下的abc.txt文件移动到 C:\\Users\\shkst\\Desktop")]
#模型调用
response = chat_model.invoke(
input=messages,
functions=functions
)
print(response)输出:
(1) 检查是否需要调用工具
python
import json
if "function_call" in response.additional_kwargs:
tool_name = response.additional_kwargs["function_call"]["name"]
tool_args = json.loads(response.additional_kwargs["function_call"]["arguments"])
print(f"调用工具:{tool_name},参数:{tool_args}")
else:
print("模型回复:", response.content)(2) 实际执行工具调用
python
from langchain.tools import MoveFileTool
if "move_file" in response.additional_kwargs["function_call"]["name"]:
tool = MoveFileTool()
result = tool.run(tool_args) #执行工具
print("工具执行结果:", result)第06章:LangChain使用之Agents
1、理解Agents
通用人工智能(AGI)将是AI的终极形态,几乎已成为业界共识。同样,构建智能体(Agent)则是AI 工程应用当下的"终极形态"。
将 AI和人类协作的程度类比自动驾驶的不同阶段:
1.1 Agent与Chain的区别
在 Chain中行动序列是硬编码的、固定流程的 ,像是"线性流水线",而Agent 则采用语言模型作为推理引擎 ,具备一定的自主决策能力,来确定以什么样的顺序采取什么样的行动,像是"拥有大脑的机器工人"。
它可以根据任务 动态决定 :
- 如何 拆解任务
- 需要 调用哪些工具
- 以 什么顺序调用
- 如何利用好 中间结果 推进任务
1.2 什么是Agent
Agent(智能体)是一个通过动态协调大语言模型(LLM)和工具(Tools)来完成复杂任务的智能系统。它让LLM充当"决策大脑",根据用户输入自主选择和执行工具(如搜索、计算、数据库查询等),最终生成精准的响应。
1.3 Agent的核心能力/组件
作为一个智能体,需要具备以下核心能力:
1)大模型(LLM):作为大脑,提供推理、规划和知识理解能力。比如:OpenAI()、ChatOpenAI()
2)记忆(Memory):具备短期记忆(上下文)和长期记忆(向量存储),支持快速知识检索。比如:ConversationBufferMemory 、ConversationSummaryMemory 、ConversationBufferWindowMemory 等
3)工具(Tools) :调用外部工具(如API、数据库)的执行单元
比如:SearchTool、CalculatorTool
4)规划(Planning):任务分解、反思与自省框架实现复杂任务处理
5)行动(Action) :实际执行决策的能力
比如:检索、推理、编程
6)协作:通过与其他智能体交互合作,完成更复杂的任务目标。
问题:为什么要调用第三方工具(比如:搜索引擎或者数据库)或借助第三方库呢?
因为大模型虽然非常强大,但是也具备一定的局限性。比如不能回答实时信息 、处理复杂数学逻辑问题 仍然非常初级等等。因此,可以借助第三方工具来辅助大模型的应用。
以MCP工具为例说明:https://bailian.console.aliyun.com/?tab=mcp#/mcp-market
1.4 举例
举例1:扣子平台智能体演示
举例2:Manus、纳米AI使用演示
我们期待它不仅仅是执行任务的工具,而是一个能够思考、自主分析需求、拆解任务并逐步实现目标的智能实体。这种形态的智能体才更接近于人工智能的终极目标------AGI(通用人工智能),它能让类似于托尼·斯塔克的贾维斯那样的智能助手成为现实,服务于每个人。
1.5 明确几个组件
Agents模块有几个关键组件:
1、工具 Tool
LangChain提供了广泛的入门工具,但也支持自定义工具 ,包括自定义描述。在框架内,每个功能或函数被封装成一个工具 (Tools),具有自己的输入、输出及处理方法。
具体使用步骤:
① Agent接收任务后,通过大模型推理选择适合的工具处理任务。
② 一旦选定,LangChain将任务输入传递给该工具,工具处理输入生成输出。
③ 输出经过大模型推理,可用于其他工具的输入或作为最终结果返回给用户。
2、工具集 Toolkits
在构建Agent时,通常提供给LLM的工具不仅仅只有一两个,而是一组可供选择的工具集(Tool列表), 这样可以让 LLM在完成任务时有更多的选择。
3、智能体/代理 Agent
智能体/代理(agent)可以协助我们做出决策,调用相应的 API。底层的实现方式是通过 LLM来决定下一步执行什么动作。
4、代理执行器 Agent Executor
AgentExecutor本质上是代理的运行时,负责协调智能体的决策和实际的工具执行。AgentExecutor是一个很好的起点,但是当你开始拥有更多定制化的代理时,它就不够灵活了。为了解决这个问题,我们构建了LangGraph,使其成为这种灵活、高度可控的运行时。
| 环节1:创建Agent | 环节2:创建AgentExecutor | |
|---|---|---|
| 方式1:传统方式 | 使用 AgentType指定 | initialize_agent() |
| 方式2:通用方式 | create_xxx_agent()比如:create_react_agent()、create_tool_calling_agent() | 调用AgentExecutor()构造方法 |
2、Agent入门使用
2.1 Agent、AgentExecutor的创建
2.2 Agent的类型
顾名思义就是某件事可以由不同的人去完成,最终结果可能是一样的,但是做的过程可能各有千秋。比如一个公司需求,普通开发可以编写,技术经理也可以编写, CTO也可以编写。虽然都能 完成最后的需求,但是CTO做的过程可能更加直观,高效。
在LangChain中Agent的类型就是为你提供不同的"问题解决姿势"的。
API说明:https://python.langchain.com/v0.1/docs/modules/agents/agent_types/
Agents的核心类型有两种模式:
- 方式1:Funcation Call模式
- 方式2:ReAct模式
2.2.1 FUNCATION_CALL模式
基于结构化函数调用 (如 OpenAI Function Calling ) 直接生成工具调用参数( JSON格式 ) 效率更高,适合工具明确的场景
典型 AgentType:
- 第1种: AgentType.OPENAI_FUNCTIONS
- 第2种: AgentType.OPENAI_MULTI_FUNCTIONS
2.2.2 ReAct模式
基于文本推理的链式思考(Reasoning+ Acting),具备反思和自我纠错能力。
- 推理(Reasoning):分析当前状态,决定下一步行动
- 行动(Acting):调用工具并返回结果
通过自然语言描述决策过程
适合需要明确推理步骤的场景。例如智能客服、问答系统、任务执行等。
典型 AgentType:
- 第1种:零样本推理(可以在没有预先训练的情况下尝试解决新的问题) AgentType.ZERO_SHOT_REACT_DESCRIPTION
- 第2种:无记忆对话 AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION
- 第3种:带记忆对话 AgentType.CONVERSATIONAL_REACT_DESCRIPTION
问题:我想要查询xxx
思考:我需要先搜索最新信息 →
行动:调用Search工具 →
观察:获得3个结果 →
思考:需要抓取第一个链接 →
行动:调用scrape_website工具...→
观察:获得工具结果
最后:获取结果
Agent 两种典型类型对比表
| 特性 | Function Call模式 | ReAct模式 |
|---|---|---|
| 底层机制 | 结构化函数调用 | 自然语言推理 |
| 输出格式 | JSON/结构化数据 | 自由文本 |
| 适合场景 | 需要高效工具调用 | 需要解释决策过程 |
| 典型延迟 | 较低 (直接参数化调用) | 较高 (需生成完整文本) |
| LLM要求 | 需支持函数调用(如gpt-4) | 通用模型即可 |
2.3 AgentExecutor创建方式
传统方式:initialize_agent()
特点:内置一些标准化模板(如 ZERO_SHOT_REACT_DESCRIPTION )
Agent的创建:使用AgentType
优点:快速上手(3行代码完成配置)
缺点:定制化能力较弱(如提示词固定)
代码片段:
python
from langchain.agents import initialize_agent
#第1步:创建AgentExecutor
agent_executor = initialize_agent(
llm=llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
tools=[search_tool],
verbose=True
)
#第2步:执行
agent_executor.invoke({"xxxx"})通用方式:AgentExecutor构造方法
特点:
Agent 的创建:使用 create_xxx_agent
优点:可自定义提示词(如从远程hub 获取或本地自定义)
清晰分离Agent 逻辑与执行逻辑
缺点:需要更多代码
需理解底层组件关系
代码片段:
python
prompt = hub.pull("hwchase17/react")
tools = [search_tool]
#第1步:创建Agent实例
agent = create_react_agent(
llm=llm,
prompt=prompt,
tools=tools
)
#第2步:创建AgentExecutor实例
agent_executor = AgentExecutor(
agent=agent,
tools=tools
)
#第3步:执行
agent_executor.invoke({"input":"xxxxx"})| 组件 | 传统方式 | 通用方式 |
|---|---|---|
| Agent创建 | 通过 AgentType枚举选择预设 | 通过 create_xxx_agent显式构建 |
| AgentExecutor创建 | 通过 initialize_agent()创建 | 通过 AgentExecutor()创建 |
| 提示词 | 内置不可见 | 可以自定义 |
| 工具集成 | AgentExecutor中显式传入 | Agent/AgentExecutor中需显式传入 |
2.4 小结
创建方式
3、Agent中工具的使用
3.1 传统方式
案例1:单工具使用
需求:今天北京的天气怎么样?
使用Tavily 搜索工具
Tavily 的搜索API是一个专门为人工智能Agent( 或LLM)构建的搜索引擎,可以快速提供实时、 准确和真实的结果。LangChain中有一个内置工具,可以轻松使用 Tavily搜索引擎作为工具。
TAVILY_API_KEY申请:https://tavily.com/,注册账号并登录,创建 API密钥。
方式1:ReAct模式
AgentType是 ZERO_SHOT_REACT_DESCRIPTION
python
from langchain_openai import ChatOpenAI
from langchain.agents import initialize_agent, AgentType
from langchain.tools import Tool
import os
import dotenv
from langchain_openai import ChatOpenAI
from langchain_community.tools.tavily_search import TavilySearchResults
# 1.设置 API密钥
os.environ["TAVILY_API_KEY"] = "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"
# 2.初始化搜索工具
search = TavilySearchResults(max_results=3)
# 3.创建Tool的实例 (本步骤可以考虑省略,直接使用[search]替换[search_tool]。但建议加上
search_tool = Tool(
name="Search",
func=search.run,
description="用于搜索互联网上的信息"
)
# 4.初始化 LLM
dotenv.load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY1")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")
llm = ChatOpenAI(
model="gpt-4o-mini",
temperature=0,
)
# 5.创建 AgentExecutor
agent_executor = initialize_agent(
tools=[search_tool],
llm=llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True
)
# 5.测试查询
query = "今天北京的天气怎么样?"
result = agent_executor.invoke(query)
print(f"查询结果:{result}")Entering new AgentExecutor chain...
我需要查找今天北京的天气信息。
Action: Search
Action Input: '今天北京天气'
Observation: {'title': '中国气象局-天气预报-北京', 'url': 'https://weather.cma.cn/web/weather/54511.html', 'content': '...'}
Thought: 我现在知道今天北京的天气情况。
Final Answer: 今天北京的天气是晴,最高气温32°C,最低气温18°C,湿度为36%,风速为南风2级,空气质量良好。
Finished chain.
查询结果: 今天北京的天气是晴,最高气温32°C,最低气温18°C,湿度为36%,风速为南风2级,空气质量良好。
拓展:上述程序中tool的设置也可以简化为:
python
#初始化搜索工具
search = TavilySearchResults(max_results=3)
#创建 AgentExecutor
agent_executor = initialize_agent(
tools=[search],
llm=llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True
)方式2:FUNCATION_CALL模式
AgentType是 OPENAI_FUNCTIONS
提示:只需要修改前面代码中的initialize_agent中的agent参数值。
python
from langchain_openai import ChatOpenAI
from langchain.agents import initialize_agent, AgentType
from langchain.tools import Tool
import os
import dotenv
from langchain_openai import ChatOpenAI
from langchain_community.tools.tavily_search import TavilySearchResults
# 1.设置 API密钥
os.environ["TAVILY_API_KEY"] = "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"
# 2.初始化搜索工具
search = TavilySearchResults(max_results=3)
# 3.创建Tool的实例
search_tool = Tool(
name="Search",
func=search.run,
description="用于搜索互联网上的信息"
)
# 4.初始化 LLM
dotenv.load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY1")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")
llm = ChatOpenAI(
model="gpt-4o-mini",
temperature=0,
)
# 5.创建 AgentExecutor
agent_executor = initialize_agent(
tools=[search_tool],
llm=llm,
agent=AgentType.OPENAI_FUNCTIONS, #唯一变化
verbose=True
)
# 5.测试查询
query = "今天北京的天气怎么样?"
result = agent_executor.invoke(query)
print(f"查询结果:{result}")Entering new AgentExecutor chain...
Invoking:
tavily_search_results_jsonwith{'query': '北京天气'}{'title': '北京-天气预报-中央气象台', 'url': 'https://www.nmc.cn/publish/forecast/ABJ/beijing.html', 'content': '...'}
今天北京的天气情况如下:
- 当前气温:30℃
- 天气状况:多云
- 风速:西南风,约3级
- 相对湿度:43%
- 体感温度:29.9℃
- 空气质量:良
预计今天的最高气温为35℃,最低气温为23℃,降水量为0mm,整体感觉温暖且较为舒适。
如果你想查看更详细的天气预报,可以访问中央气象台。
Finished chain.
查询结果: {'input': '今天北京的天气怎么样?', 'output': '今天北京的天气情况如下:\n\n-当前气温:30℃\n-天气状况:多云\n-风速:西南风,约3级\n-相对湿度:43%\n-体感温度:29.9℃ \n-空气质量:良\n\n预计今天的最高气温为35℃,最低气温为23℃,降水量为0mm,整体感觉温暖且较为舒适。\n\n如果你想查看更详细的天气预报,可以访问中央气象台。'}
二者对比:ZERO_SHOT_REACT_DESCRIPTION和OPENAI_FUNCTIONS
| 对比维度 | ZERO_SHOT_REACT_DESCRIPTION | OPENAI_FUNCTIONS |
|---|---|---|
| 底层机制 | 模型生成文本指令,系统解析后调用工具 | 模型直接返回JSON格式工具调用 |
| 执行效率 | 🐢 较低(需多轮文本交互) | ⚡更高(单步完成) |
| 输出可读性 | 直接显示人类可读的思考过程 | 需查看结构化日志 |
| 工具参数处理 | 依赖模型文本描述准确性 | 自动匹配工具参数结构 |
| 兼容模型 | 所有文本生成模型 | 仅GPT-4/Claude 3等新模型 |
| 复杂任务表现 | 可能因文本解析失败出错 | 更可靠(结构化保证) |
案例2:多工具使用
需求:计算特斯拉当前股价是多少?比去年上涨了百分之几?(提示:调用PythonREPL实例的run方法)
多个(两个)工具的选择
方式1:ReAct模式
AgentType是 ZERO_SHOT_REACT_DESCRIPTION
python
# 1.导入相关依赖
from langchain_openai import ChatOpenAI
from langchain.agents import initialize_agent, AgentType
from langchain.tools import Tool
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain_experimental.utilities.python import PythonREPL
# 2.设置 TAVILY_API密钥
os.environ["TAVILY_API_KEY"] = "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" #需要替换为你的 Tavily API密钥
# 3.定义搜索工具
search = TavilySearchResults(max_results=3)
search_tool = Tool(
name="Search",
func=search.run,
description="用于搜索互联网上的信息,特别是股票价格和新闻"
)
# 4.定义计算工具
python_repl = PythonREPL() # LangChain封装的工具类可以进行数学计算
calc_tool = Tool(
name="Calculator",
func=python_repl.run,
description="用于执行数学计算,例如计算百分比变化"
)
# 5.定义LLM
llm = ChatOpenAI(
model="gpt-4o-mini",
temperature=0,
)
# 6.创建AgentExecutor执行器对象
agent_executor = initialize_agent(
tools=[search_tool, calc_tool],
llm=llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True
)
# 7.测试股票价格查询
query = "特斯拉当前股价是多少?比去年上涨了百分之几?"
result = agent_executor.invoke(query)
print(f"查询结果:{result}")注意:可能会失败(查询超时)。
方式2:FUNCTION_CALL模式
AgentType 是 FUNCTION_CALL
python
# 1.导入相关依赖
from langchain_openai import ChatOpenAI
from langchain.agents import initialize_agent, AgentType
from langchain.tools import Tool
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain_experimental.utilities.python import PythonREPL
# 2.设置 TAVILY_API密钥
os.environ["TAVILY_API_KEY"] = "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" #需要替换为你的 Tavily API密钥
# 3.定义搜索工具
search = TavilySearchResults(max_results=3)
search_tool = Tool(
name="Search",
func=search.run,
description="用于搜索互联网上的信息,特别是股票价格和新闻"
)
# 4.定义计算工具
python_repl = PythonREPL() # LangChain封装的工具类可以进行数学计算
calc_tool = Tool(
name="Calculator",
func=python_repl.run,
description="用于执行数学计算,例如计算百分比变化"
)
# 5.定义LLM
llm = ChatOpenAI(
model="gpt-4", # 注意这里使用gpt-4以支持function calling
temperature=0,
)
# 6.创建AgentExecutor执行器对象
agent_executor = initialize_agent(
tools=[search_tool, calc_tool],
llm=llm,
agent=AgentType.OPENAI_FUNCTIONS, #唯一变化的位置
verbose=True
)
# 7.测试股票价格查询
query = "特斯拉当前股价是多少?比去年上涨了百分之几?"
result = agent_executor.invoke(query)
print(f"查询结果:{result}")注意:也有可能输出失败,但是机会小。
案例3:自定义函数与工具
需求:计算3的平方,Agent自动调用工具完成
python
from langchain.agents import initialize_agent, AgentType, Tool
from langchain_openai import ChatOpenAI
import langchain
# 1.定义工具-计算器(要求字符串输入)
def simple_calculator(expression: str) -> str:
"""
基础数学计算工具,支持加减乘除和幂运算
参数: expression:数学表达式字符串,如"3+5"或"2**3"
返回: 计算结果字符串或错误信息
"""
print(f"\n[工具调用]计算表达式: {expression}")
print("只因为在人群中多看了你一眼,确认下你调用了我^_^")
return str(eval(expression))
# 2.创建工具对象
math_calculator_tool = Tool(
name="Math_Calculator", #工具名称(Agent将根据名称选择工具)
func=simple_calculator, #工具调用的函数
description="用于数学计算,输入必须是纯数学表达式(如'3+5'或'3**2'表示平方)。不支持字母或特殊符号" #关键:明确输入格式要求
)
# 3.初始化大模型
llm = ChatOpenAI(
model="gpt-4o-mini",
temperature=0,
)
# 4.初始化AgentExecutor(使用零样本React模式、增加超时设置)
agent_executor = initialize_agent(
tools=[math_calculator_tool], #可用的工具列表
llm=llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, #简单指令模式
verbose=True #关键参数!在控制台显示详细的推理过程
)
# 5.测试工具调用(添加异常捕获)
print("===测试:正常工具调用===")
response = agent_executor.invoke("计算3的平方") #向Agent提问
print("最终答案:", response)=测试:正常工具调用=
Entering new AgentExecutor chain...
我需要计算3的平方,这可以用数学表达式32来表示。
Action: Math_Calculator
Action Input: 3 2工具调用计算表达式: 3**2
只因为在人群中多看了你一眼,确认下你调用了我_
Observation: 9
Thought: 我现在知道最终答案
Final Answer: 9
Finished chain.
最终答案: {'input': '计算3的平方', 'output': '9'}
3.2 通用方式
需求:今天北京的天气怎么样??
方式1:FUNCATION_CALL模式
注意:agent_scratchpad 必须声明,它用于存储和传递Agent 的思考过程。比如,在调用链式工具时(如先搜索天气再推荐行程), agent_scratchpad 保留所有历史步骤,避免上下文丢失。format 方法会将intermediate_steps 转换为特定格式的字符串,并赋值给 agent_scratchpad 变量。如果不传递intermediate_steps 参数,会导致KeyError: 'intermediate_steps' 错误。
python
# 1.导入相关包
from langchain.agents import AgentExecutor, create_tool_calling_agent
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain_core.prompts import ChatPromptTemplate
# 2.定义搜索化工具
# ①设置 TAVILY_API密钥
os.environ["TAVILY_API_KEY"] = "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" #需要替换为你的 Tavily API密钥
# ②定义搜索工具
search = TavilySearchResults(max_results=1)
# 3.自定义提示词模版
prompt = ChatPromptTemplate.from_messages([
("system", "您是一位乐于助人的助手,请务必使用 tavily_search_results_json工具来获取信息。"),
("human", "{input}"),
("placeholder", "{agent_scratchpad}"),
])
# 4.定义LLM
llm = ChatOpenAI(
model="gpt-4o-mini",
temperature=0,
)
# 5.创建Agent对象
agent = create_tool_calling_agent(
llm=llm,
tools=[search],
prompt=prompt
)
# 6.创建AgentExecutor执行器
agent_executor = AgentExecutor(agent=agent, tools=[search], verbose=True)
# 7.测试
agent_executor.invoke({"input": "今天北京的天气怎么样??"})Entering new AgentExecutor chain...
Invoking:
tavily_search_results_jsonwith{'query': '北京天气'}{'title': '北京-天气预报-中央气象台', 'url': 'https://www.nmc.cn/publish/forecast/ABJ/beijing.html', 'content': '土壤水分监测\\n农业干旱综合监测\\n...北京\\n30℃\\n日落19:43\\n降水量\\n0mm\\n西南风\\n3级\\n相对湿度\\n43%\\n体感温度\\n29.9℃\\n空气质量:良\\n舒适度:温暖,较舒适...', 'score': 0.78493005}
今天北京的天气情况如下:
- 当前温度:30℃
- 天气状况:多云
- 风速:西南风,3级
- 相对湿度:43%
- 体感温度:29.9℃
- 空气质量:良
- 舒适度:温暖,较舒适
日出时间为04:45,日落时间为19:43。预计降水量为0mm。
如果需要更详细的信息,可以查看中央气象台的天气预报。
Finished chain.
{'input': '今天北京的天气怎么样??', 'output': '今天北京的天气情况如下:\n\n-当前温度:30℃\n-天气状况:多云\n-风速:西南风,3级\n-相对湿度:43%\n-体感温度:29.9℃\n-空气质量:良\n-舒适度:温暖,较舒适\n\n日出时间为04:45,日落时间为19:43。预计降水量为0mm。\n\n如果需要更详细的信息,可以查看中央气象台的天气预报。'}
方式2:ReAct模式
体会1:使用PromptTemplate提示词要体现可以使用的工具、用户输入和agent_scratchpad。
远程的提示词模版通过https://smith.langchain.com/hub/hwchase17获取
举例:https://smith.langchain.com/hub/hwchase17/react,这个模板是专为ReAct模式设计的提示模板。这个模板中已经有聊天对话键 tools 、 tool_names 、 agent_scratchpad
方式1:
python
# 1.导入相关包
from langchain.agents import AgentExecutor, create_react_agent
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain_core.prompts import PromptTemplate
# 2.定义搜索化工具
tools = [TavilySearchResults(max_results=1, tavily_api_key="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")]
# 3.自定义提示词模版
template = '''
Answer the following questions as best you can. You have access to the following tools: {tools}
Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Begin!
Question: {input}
Thought: {agent_scratchpad}
'''
prompt = PromptTemplate.from_template(template)
# 4.定义LLM
llm = ChatOpenAI(
model="gpt-4o-mini",
temperature=0,
)
# 5.创建Agent对象
agent = create_react_agent(llm, tools, prompt)
# 6.创建AgentExecutor执行器
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True, handle_parsing_errors=True)
# 7.测试
agent_executor.invoke({"input": "今天北京的天气怎么样??"})Entering new AgentExecutor chain...
我需要查找今天北京的天气情况。
Action: tavily_search_results_json
Action Input: "今天北京天气"
{'title': '中国气象局-天气预报-北京', 'url': 'https://weather.cma.cn/web/weather/54511', 'content': '\|时间\| 08:00\| 11:00\| ... \|气温\| 21.4℃\| 23.6℃\| ... \|30.8℃\| ...', 'score': 0.7859175}
我现在知道今天北京的天气情况。
Final Answer: 今天北京的天气是晴天,气温在21.4℃到30.8℃之间,全天无降水。
{'input': '今天北京的天气怎么样??', 'output': '今天北京的天气是晴天,气温在21.4℃到30.8℃之间,全天无降水。'}
方式2:
python
# 1.导入相关包
from langchain.agents import AgentExecutor, create_react_agent
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain import hub
# 2.定义搜索化工具
tools = [TavilySearchResults(max_results=1, tavily_api_key="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")]
# 3.使用LangChain Hub中的官方ReAct提示模板
prompt = hub.pull("hwchase17/react")
# 4.定义LLM
llm = ChatOpenAI(
model="gpt-4o-mini",
temperature=0,
)
# 5.创建Agent对象
agent = create_react_agent(llm, tools, prompt)
# 6.创建AgentExecutor执行器
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True, handle_parsing_errors=True)
# 7.测试
agent_executor.invoke({"input": "今天北京的天气怎么样??"})体会2:使用ChatPromptTemplate提示词中需要体现使用的工具、用户输入和agent_scratchpad。
场景 handle_parsing_errors=True handle_parsing_errors=False
解析成功 正常执行 正常执行
解析失败 自动修复或降级响应 直接抛出异常
适用场景 生产环境(保证鲁棒性) 开发调试(快速发现问题)
修改:任务不变,添加 handle_parsing_errors=True 。用于控制 Agent在解析工具调用或输出时发生错误的容错行为。
handle_parsing_errors=True的作用
- 自动捕获错误并修复:当解析失败时,Agent不会直接崩溃,而是将错误信息传递给 LLM,让 LLM自行修正并重试 。
- 降级处理:如果重试后仍失败,Agent会返回一个友好的错误消息(如 "I couldn't process that request." ),而不是抛出异常。
4、Agent嵌入记忆组件
4.1 传统方式
比如:北京明天的天气怎么样?上海呢? (通过两次对话实现)
举例:以REACT模式为例
python
# 1.导入依赖包
from langchain_openai import ChatOpenAI
from langchain.agents import initialize_agent, AgentType
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain.memory import ConversationBufferMemory
import os
import dotenv
dotenv.load_dotenv()
# 2.设置 API密钥
os.environ["TAVILY_API_KEY"] = "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"
# 3.定义搜索工具
search_tool = TavilySearchResults(max_results=2)
# 4.定义LLM
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY1")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")
llm = ChatOpenAI(
model="gpt-4o-mini",
temperature=0
)
# 5.定义记忆组件(以ConversationBufferMemory为例)
memory = ConversationBufferMemory(
memory_key="chat_history", #必须是此值,通过initialize_agent()的源码追踪得到
return_messages=True
)
# 6.创建 AgentExecutor
agent_executor = initialize_agent(
tools=[search_tool],
llm=llm,
agent=AgentType.CONVERSATIONAL_REACT_DESCRIPTION,
memory=memory, #在AgentExecutor中声明
verbose=True
)
# 7.测试对话
#第一个查询
query1 = "北京明天的天气怎么样?"
result1 = agent_executor.invoke(query1)
print(f"查询结果:{result1}")
# print("\n===继续对话===")
query2 = "上海呢"
result2 = agent_executor.invoke(query2)
print(f"分析结果:{result2}")代码修改为:
python
# 1.导入依赖包
from langchain_openai import ChatOpenAI
from langchain.agents import initialize_agent, AgentType
from langchain.tools import Tool
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain_experimental.utilities.python import PythonREPL
from langchain.memory import ConversationBufferMemory
# 2.设置 API密钥
os.environ["TAVILY_API_KEY"] = "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"
# 3.定义搜索工具
search_tool = TavilySearchResults(max_results=2)
# 5.定义LLM
llm = ChatOpenAI(
model="gpt-4",
temperature=0
)
# 6.定义记忆组件(以ConversationBufferMemory为例)
memory = ConversationBufferMemory(
memory_key="chat_history",
return_messages=True
)
# 7.创建 AgentExecutor
agent_executor = initialize_agent(
tools=[search_tool],
llm=llm,
agent=AgentType.CONVERSATIONAL_REACT_DESCRIPTION,
memory=memory,
handle_parsing_errors=True,
verbose=True
)
# 8.测试对话
#第一个查询
query1 = "北京明天的天气怎么样?"
result1 = agent_executor.invoke(query1)
print(f"查询结果:{result1}")
# print("\n===继续对话===")
query2 = "上海呢"
result2 = agent_executor.invoke(query2)
print(f"分析结果:{result2}")Entering new AgentExecutor chain...
Thought: Do I need to use a tool? Yes Action: tavily_search_results_json Action Input: 北京明天的天气Observation: {'title': '中国气象局-天气预报-北京', 'url': 'https://weather.cma.cn/web/weather/54511.html', 'content': '\|时间\| 08:00\| 11:00\| ... \|气温\| 21.4℃\| 23.6℃\| ...', 'score': 0.7859175}, ...
Thought: I now know the final answer for the current query.
Final Answer: 北京明天的天气情况...
Finished chain.
查询结果: {'input': '北京明天的天气怎么样?', 'output': '北京明天的天气情况...'}
Entering new AgentExecutor chain...
Thought: The user is asking about the weather in Shanghai after previously asking about Beijing. I need to search for Shanghai's weather. Action: tavily_search_results_json Action Input: 上海明天的天气Observation: {'title': '中国气象局-天气预报-上海', 'url': 'https://weather.cma.cn/web/weather/58362.html', 'content': '\|时间\| 08:00\| 11:00\| ... \|气温\| 25.8℃\| 28.2℃\| ...', 'score': 0.7923456}, ...
Thought: I now know the final answer for the current query.
Final Answer: 上海明天的天气情况...
Finished chain.
分析结果: {'input': '上海呢', 'output': '上海明天的天气情况...'}
4.2 通用方式
(续上一页内容)
当使用通用方式(create_react_agent + AgentExecutor 构造方法)在 Agent 中嵌入记忆组件时,需要在提示词模板中加入聊天历史记录。具体实现方式如下:
python
# 1.导入依赖包
from langchain.agents import AgentExecutor, create_react_agent
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain.memory import ConversationBufferMemory
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain import hub
# 2.设置 API密钥
os.environ["TAVILY_API_KEY"] = "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"
# 3.定义搜索工具
search_tool = TavilySearchResults(max_results=2)
# 4.定义LLM
llm = ChatOpenAI(
model="gpt-4",
temperature=0
)
# 5.定义记忆组件
memory = ConversationBufferMemory(
memory_key="chat_history",
return_messages=True
)
# 6.加载提示模板(包含聊天历史)
prompt = hub.pull("hwchase17/react-chat")
# 7.创建Agent
agent = create_react_agent(
llm=llm,
tools=[search_tool],
prompt=prompt
)
# 8.创建AgentExecutor
agent_executor = AgentExecutor(
agent=agent,
tools=[search_tool],
memory=memory,
verbose=True,
handle_parsing_errors=True
)
# 9.测试对话
query1 = "北京明天的天气怎么样?"
result1 = agent_executor.invoke({"input": query1})
print(f"查询结果: {result1}")
query2 = "上海的呢?"
result2 = agent_executor.invoke({"input": query2})
print(f"查询结果: {result2}")在通用方式中,关键点在于:
- 使用了专门为带记忆的聊天场景设计的提示模板:
hub.pull("hwchase17/react-chat") - 将memory组件直接传入AgentExecutor
- 提示模板中包含了对聊天历史的处理