现在AI开发圈里,"Trae + Spec"这对CP火到出圈!说白了就是字节跳动的AI开发神器Trae,配上清晰的需求规范(Spec),直接把软件开发的效率拉满。以前写代码熬到凌晨的苦日子,现在可能一杯咖啡的功夫就搞定,尤其适合快速出活的项目和不想被代码虐的小伙伴。下面就用大白话拆解这对"神仙组合",新手也能秒懂!
一、先搞懂俩主角:Trae不是英文词,Spec也不是暗号
想把这对组合用明白,得先摸清楚它俩各自的"技能点"------一个是AI界的"全能码农",一个是需求界的"定海神针",天生就该搭伙干活。
1. Trae:字节亲儿子,AI界的"真·代码搭子"
别费劲查词典了,Trae不是普通英文词,是字节跳动专门搞的AI开发工具,全称"The Real AI Engineer",翻译过来就是"真·AI工程师",听着就很靠谱。它就像个有多年经验的老码农,双引擎加持,能把复杂需求拆成一个个小任务,代码补全、优化、解释、甚至把你的口头需求直接转成代码,还能联网查资料补全信息,简直是"行走的代码库"。
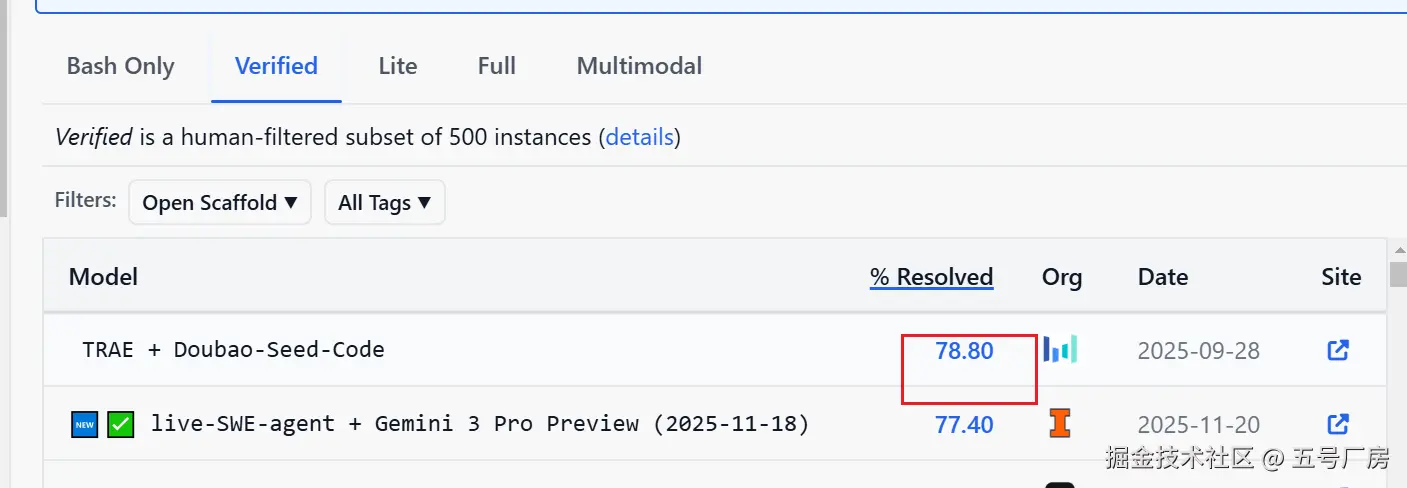
在行业测试SWE-bench verified里,它曾创下78.80%的好成绩,直接刷新纪录,实力是被盖章认证的。现在分国内和海外版,就像手机的国行和港行,核心功能没差,放心用。不管你是写前端还是后端,它都能帮上忙,再也不用喊"我太难了"。
2. Spec:需求"说明书",别写得像"谜之暗号"
Spec是Specification的缩写,说白了就是"需求规范",但不是"做个好用的APP"这种模糊话,得是"接口响应不能超过100毫秒""能同时扛住1000人访问"这种能落地、能验证的硬指标。你把它喂给Trae,就像给导航输了精准地址,AI才不会跑偏。
对Trae来说,Spec就是"指令密码本",AI全靠它拆任务、写代码、做测试。所以Spec写得越细,Trae干活越准,千万别玩"你猜我要啥"的游戏。哦对了,Spec在其他领域还有别的意思,但跟Trae搭伙时,就认准"需求规范"这个意思准没错。
二、实战开整:两种模式,新手也能当"造物主"
Trae和Spec凑一起,不是简单的1+1,而是直接把"提需求---写代码---做测试"的流程翻新了。不管你是产品经理想自己搞个原型,还是码农想省力气,都有对应的玩法。
1. SOLO模式:非技术党也能"手搓"应用,太香了
这是最火的玩法,相当于把Trae当成你的"专属码农"------你只需要把写清楚的Spec丢给它,剩下的需求文档、设计方案、任务拆分、代码编写,它全给你包圆了,最后还会帮你初步调试好。
这模式直接把开发门槛干到地板价,产品经理、设计师不用再求着码农改需求,自己写好Spec就能搞出最小可用产品(MVP);码农也能省力气,AI把框架搭好,你只管做优化,简直是"摸鱼神器"。下面拿电商常用的"商品列表查询接口"举例,一步一步看它俩怎么配合干活。
第一步:写Spec别"画大饼",越具体越好
产品经理按业务需求,把Spec写得明明白白,别搞模糊表述,比如:
- 要做啥:搞个RESTful接口,通过商品分类ID查商品列表,得显示商品信息和有没有货;
- 传啥参数:分类ID(必填,得是正整数)、页码(默认第1页)、每页条数(默认20条,最多50条);
- 返回啥:商品ID、名字、售价(保留2位小数)、库存数、上架状态(0=下架/1=上架)、封面图链接;
- 性能要求:接口响应别超100毫秒,同时1000人访问也不能崩;
- 出错咋整:没传分类ID就提示"分类ID不能为空",传了字母就提示"格式错了",数据库挂了就提示"服务暂时歇菜";
- 用啥工具做:Python 3.9以上、Flask 2.0以上、MySQL 8.0,数据库操作要用SQLAlchemy。
第二步:把Spec丢给Trae,坐等AI干活
把上面的Spec复制粘贴到Trae的SOLO模式里,它立马开启"自动打工"模式,全程不用你催:

- 拆任务:自动列出干活清单,从定义数据模型到性能优化,7个步骤写得清清楚楚,还标了先做啥后做啥;
- 写代码:按清单把代码写好,连注释都给你标清楚,直接能用,核心代码长这样:
python
from flask import Flask, request, jsonify
from flask_sqlalchemy import SQLAlchemy
from decimal import Decimal
import time
app = Flask(__name__)
# 数据库配置(Trae会提示用户替换实际连接信息)
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql+pymysql://user:password@localhost:3306/ecommerce'
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
db = SQLAlchemy(app)
# 1. 定义数据模型(对应商品表)
class Product(db.Model):
__tablename__ = 'products'
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(255), nullable=False)
price = db.Column(db.Numeric(10, 2), nullable=False) # 保留2位小数
stock = db.Column(db.Integer, nullable=False, default=0)
status = db.Column(db.SmallInteger, nullable=False, default=0) # 0下架,1上架
cover_url = db.Column(db.String(512))
category_id = db.Column(db.Integer, nullable=False)
# 2. 商品列表查询接口
@app.route('/api/products', methods=['GET'])
def get_product_list():
start_time = time.time()
# 3. 请求参数校验(符合Spec要求)
category_id = request.args.get('category_id')
page = int(request.args.get('page', 1))
page_size = int(request.args.get('page_size', 20))
# 异常处理逻辑
if not category_id:
return jsonify({"code": 400, "msg": "分类ID不能为空", "data": None}), 400
try:
category_id = int(category_id)
if category_id <= 0:
raise ValueError
except ValueError:
return jsonify({"code": 400, "msg": "分类ID格式错误", "data": None}), 400
# 限制page_size最大值
if page_size > 50:
page_size = 50
# 4. 数据库查询(ORM操作,分页处理)
try:
pagination = Product.query.filter_by(
category_id=category_id, status=1 # 只查询上架商品
).paginate(page=page, per_page=page_size, error_out=False)
products = pagination.items
# 5. 响应格式封装
result = []
for p in products:
result.append({
"id": p.id,
"name": p.name,
"price": float(p.price), # 转为float便于前端处理
"stock": p.stock,
"status": p.status,
"cover_url": p.cover_url or ""
})
# 性能监控(确保响应时间符合要求)
response_time = (time.time() - start_time) * 1000
if response_time > 100:
app.logger.warning(f"接口响应超时,耗时:{response_time:.2f}ms")
return jsonify({
"code": 200,
"msg": "success",
"data": {
"total": pagination.total,
"page": page,
"page_size": page_size,
"list": result
}
})
except Exception as e:
app.logger.error(f"数据库查询异常:{str(e)}")
return jsonify({"code": 500, "msg": "服务暂不可用", "data": None}), 500
if __name__ == '__main__':
app.run(debug=True)- 出文档 :自动生成接口说明,连请求示例(比如
/api/products?category_id=1&page=1&page_size=10)、返回结果都给你整理好,直接丢给前端同学; 4. 帮调试:提醒你改数据库连接信息,还自带简单测试工具,点一下就能测接口好不好使。
第三步:人类收尾,简单优化就行
AI把框架搭好,剩下的细活交给人类就行。比如加个数据库索引优化性能,确保多人访问也不卡;再用Trae生成的测试用例测测极端情况,比如传个超大数字当页码,看看会不会崩。搞定这些,接口就能上线了。
你看,Spec写得清楚,Trae就不会瞎干活,原本要两三个小时的活,20分钟就搞定了,代码还符合规范,这波协作简直"赢麻了"。
2. Vibe模式:AI当"监工",写代码不踩坑
如果你想自己写代码,Trae也能当"智能监工"------这就是它的Vibe模式。你写代码的时候,它会盯着Spec实时"找茬",比如你忘了加密数据,它立马弹提示;测试的时候,还会按Spec自动生成测试用例,确保你写的代码没跑偏。
字节内部就这么玩过:做用户登录模块时,Spec里写了"密码要用BCrypt加密,长度至少8位"。有个开发者顺手用了MD5加密,Trae立马弹出红色提示:"跟Spec 3.2条对不上哦,建议换成BCrypt,给你个示例代码:bcrypt.hashpw(password.encode('utf-8'), bcrypt.gensalt())";后来忘了加密码长度校验,Trae直接把代码片段补好了,还标了对应的Spec条款。这么一来,代码返工率直接降了30%以上,再也不用因为需求理解错熬夜改代码了。
三、为啥说这对组合"香到爆"?三大优势直击痛点
不管是新手还是老码农,用一次就知道这组合有多香,比单独写代码、单独用AI工具靠谱多了,核心优势就三个:
- 效率飞起:Spec把"模糊需求"变成AI能懂的"干活指令",避免AI瞎猜;Trae把"需求转代码"的时间从天缩短到小时,赶项目时再也不用996了。
- 门槛超低:产品、设计不用学编程,只要会写清楚Spec,就能自己"手搓"应用,真正实现"人人都能当造物主"。
- 质量靠谱:Spec全程当"裁判",Trae实时"纠错",从需求到代码形成闭环,再也不用怕"写出来的跟要的不一样"。
四、避坑指南:这俩"雷区"千万别踩
想把这组合用明白,别犯这两个错,不然再好的工具也白搭:第一,Spec别写"做个好用的APP"这种空话,越具体越精准;第二,别完全依赖AI,复杂业务逻辑和涉及安全的代码,一定要自己再检查一遍,AI靠谱但不是万能的。
核心总结:Trae + Spec,本质是"AI造物搭子"遇上"清晰需求说明书"。你负责把要啥说清楚,AI负责把活干出来,以前复杂的开发流程,现在变得简单又高效。这波AI开发的红利,不管是打工人还是创业者,都可以赶紧盘起来!