当时序数据不再"只是时间":金仓数据库如何在复杂场景中拉开与 InfluxDB 的差距
一、时序数据库的"第二阶段"已经到来
在很长一段时间里,时序数据库的核心问题只有一个:
如何高效存储按时间不断增长的数据点?
InfluxDB 正是在这一阶段脱颖而出的代表产品。其专门为时间序列设计的存储模型、简洁的写入接口以及良好的初期性能,使其在监控和物联网领域被大量采用。
但随着业务系统逐渐成熟,企业对时序数据的诉求正在发生变化:
- 数据量不再是百万、千万,而是持续增长的百亿级
- 查询不再只是画图,而是实时分析、异常定位、智能决策
- 时序数据不再独立存在,而是要与业务数据、设备数据、空间信息结合
这意味着,时序数据库正在进入一个新的阶段------
从"专用存储工具"向"核心数据能力"的转变。
也正是在这一阶段,金仓数据库(KingbaseES)与 InfluxDB 的差距开始被不断放大。
二、写入不是终点:高并发之下的可持续能力
写入性能,往往是评价时序数据库的第一指标。但真正重要的,并不是"单次跑分有多高",而是:
在设备规模不断扩大、写入长期持续的情况下,系统是否还能稳定、高效地运行?
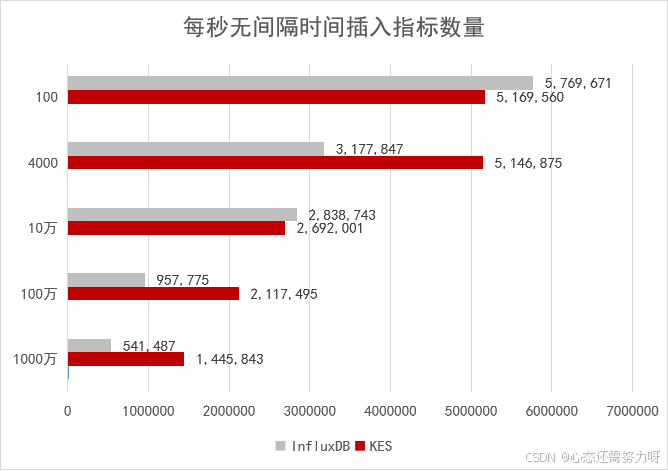
在基于 TSBS 的测试中,模拟了从小规模设备到千万级设备的持续写入压力。测试结果呈现出一个非常清晰的趋势:
- 在小规模写入场景下,两者性能接近
- 随着设备数量和指标数量增长,金仓的写入吞吐优势逐步显现
- 在千万级设备压力下,金仓的写入性能达到 InfluxDB 的 2 倍以上
这背后反映的,并不是简单的"写得快",而是:
- 并发调度能力
- 存储结构对高基数数据的适应性
- 分区与索引策略的可扩展性
在真实生产系统中,这些因素往往比单次写入延迟更重要。
三、真正决定上限的,是复杂查询能力
如果说写入能力决定系统能否"活下来",那么查询能力决定的,就是系统是否"有价值"。
在大量企业实践中,时序查询往往会经历三个阶段:
- 基础查询:单指标、短时间窗口
- 分析查询:多设备、多指标、分组聚合
- 业务查询:最新状态、异常筛选、跨维度分析
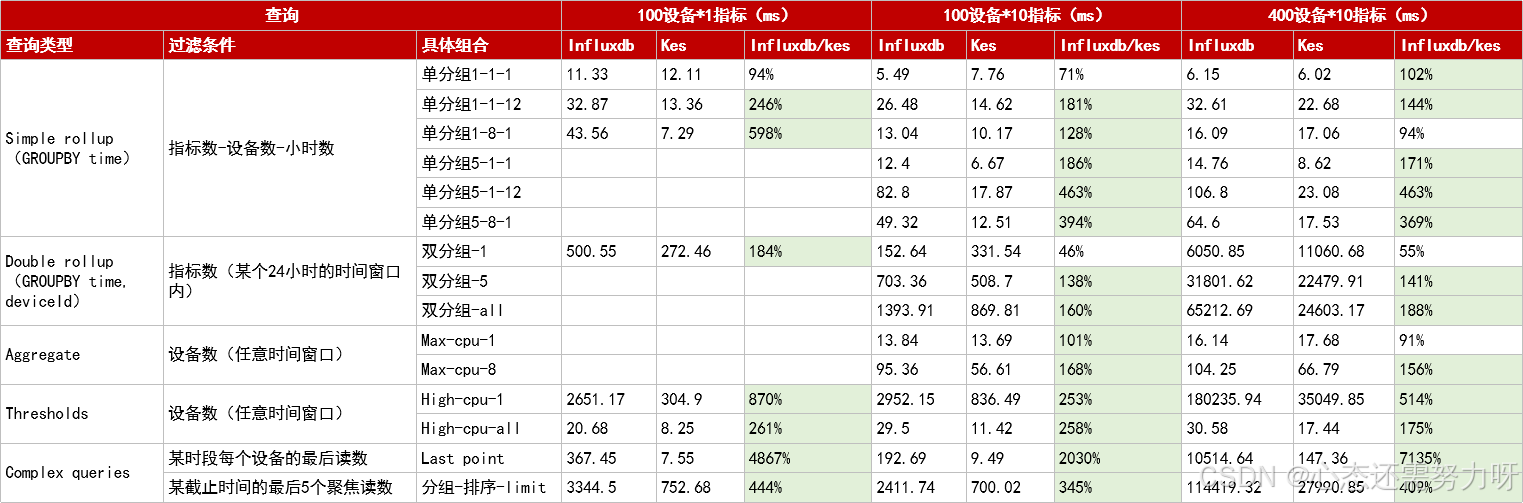
1. 简单查询阶段:差距不明显
在单设备、单指标的聚合查询中,金仓与 InfluxDB 的性能都能保持在毫秒级,整体体验差距有限。
这也是很多团队在早期使用 InfluxDB 时感觉"性能很好"的原因。
2. 分析查询阶段:优势开始显现
当查询涉及多设备、多指标,并且需要进行分组统计时,金仓的优势逐步体现。
在典型的"多设备多指标一小时统计"测试中:
- 金仓的响应速度通常为 InfluxDB 的 3~4 倍
- 随着时间窗口拉长,这一差距仍能保持稳定
这说明,在数据量和计算复杂度同时增长的情况下,金仓的执行计划和资源调度更加高效。
3. 业务级查询:数量级差距的出现
在最接近真实业务的查询场景中,两者的性能差距呈现出数量级放大。
例如:
- Last Point 查询(获取每个设备的最新数据)
- 阈值筛选查询(找出某时间段内超限的设备)
- 状态统计查询(按设备维度汇总运行状态)
在测试中,面对数百台设备的数据:
- 金仓的查询耗时维持在百毫秒级
- InfluxDB 的查询耗时则可能达到数秒甚至十秒以上
在部分场景下,性能差距超过 70 倍。
对于实时告警、智能调度和自动控制系统而言,这种差距直接决定了系统是否"可用"。
四、架构差异:为什么 InfluxDB 会在复杂场景中"吃力"
从根本上看,这种性能差距并非偶然,而是架构设计目标不同所导致的必然结果。
1. 专用模型 vs 通用执行引擎
InfluxDB 的设计初衷是围绕时间序列进行高度优化,适合指标型数据的快速写入与简单聚合。
而金仓的时序能力,构建在成熟的关系型数据库内核之上,具备:
- 完整的查询优化器
- 多种索引与执行策略
- 成熟的并发控制与事务机制
当查询逻辑变复杂时,这种通用能力反而成为优势。
2. SQL 生态带来的长期收益
金仓原生支持标准 SQL,这一点在企业级场景中意义重大:
- 可直接复用 BI、报表、分析工具
- 支持复杂关联查询与子查询
- 统一技术栈,降低学习和维护成本
相比之下,InfluxDB 的专用查询语言在简单场景下足够高效,但在复杂分析和系统集成中,往往需要额外的适配和开发工作。
五、存储与成本:被忽视但极其关键的维度
在海量时序数据场景中,存储成本往往是长期运营中最大的隐性支出。
金仓在数据生命周期管理方面提供了:
- 自动时间分区
- 灵活的数据保留策略
- 高压缩比的历史数据存储
- 冷热数据分级管理
在实际测试中,针对工业传感器类数据,金仓可实现 1:4 左右的压缩比,在数据规模持续增长的情况下,这种优势会被不断放大。
六、从"时序"到"融合":业务价值的真正释放
企业真正关心的,并不是"时序数据本身",而是它所承载的业务含义。
金仓支持在同一数据库内,对以下数据进行统一分析:
- 时序数据
- 设备与业务主数据
- JSON 文档型信息
- 空间地理数据
这使得许多复杂分析场景得以简化,例如:
"统计过去一周内,某区域内运行异常的设备数量及分布情况"
在 InfluxDB 中,这通常需要多系统协作完成;而在金仓中,一条 SQL 即可完成。
七、结语:时序数据库竞争的真正分水岭
InfluxDB 在时序数据库发展早期,起到了重要推动作用。但随着业务复杂度和数据规模的持续提升,企业对数据库的期待已经发生根本变化。
金仓数据库所展现的优势,并不仅是"跑得更快",而是:
- 在复杂查询下依然可控、稳定
- 在企业生态中易于融合
- 在长期运营中成本可预期
当时序数据从"记录状态"走向"驱动决策",数据库的角色也必须随之进化。
而这,正是金仓在复杂时序场景中逐步领先的根本原因。