论文:Learning Transferable Visual Models From Natural Language Supervision
CLIP 的全称是 Contrastive Language-Image Pre-training (对比语言-图像预训练)。它是由 OpenAI 在 2021 年提出的一个多模态 人工智能模型。其核心思想是通过学习大量图像及其对应文本描述 之间的关系,来理解和连接视觉(图像)与语言(文本)这两个不同的模态。该模型直接使用大量的互联网数据进行预训练,在很多任务表现上达到了SOTA 。

1. CLIP模型概述
传统的监督模型会存在以下的这些缺点:
-
模型需要用到大量的标注数据,这些标注数据获取通常成本高昂
-
模型在当前数据集的效果比较好,但对于其他类似的数据集效果并不是很好,即泛化能力较差,
-
传统的图像分类模型无法进行类别拓展,想要保证准确率只能从头开始训练
分类模型是预测图像是否属于某个类别,CLIP采用了完全不同的分类方法:通过对比学习来学习图像与其注释之间的关联。
CLIP 的做法是使用从互联网上抓取的带字幕的图像来创建一个模型,该模型可以预测文本是否与图像匹配。如下图所示:
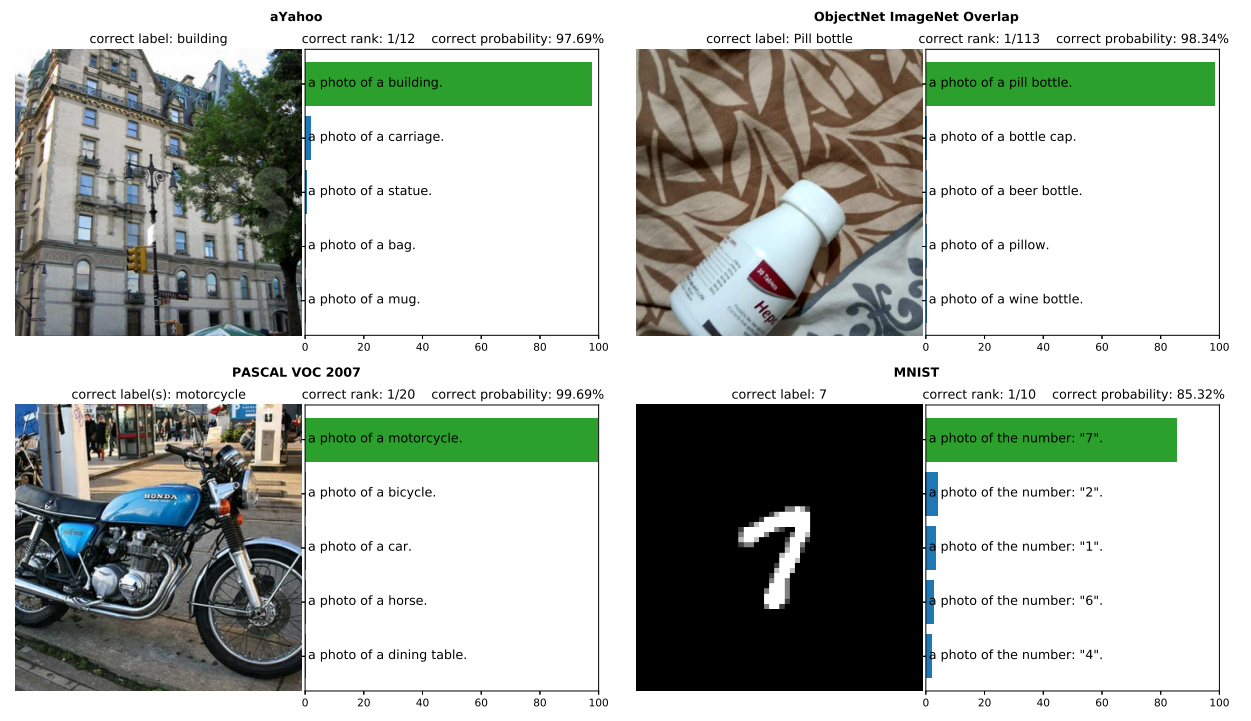
本质上,CLIP模型通过编码器将图像和文本映射到同一个Embedding空间中,使得匹配的图和文Embedding彼此靠近,而不匹配的图和文Embedding彼此相距较远 。这种学习预测事物是否属于同一类或不属于同一类的策略通常被称为"对比学习" (contrastive Learning)
2. 模型训练和使用
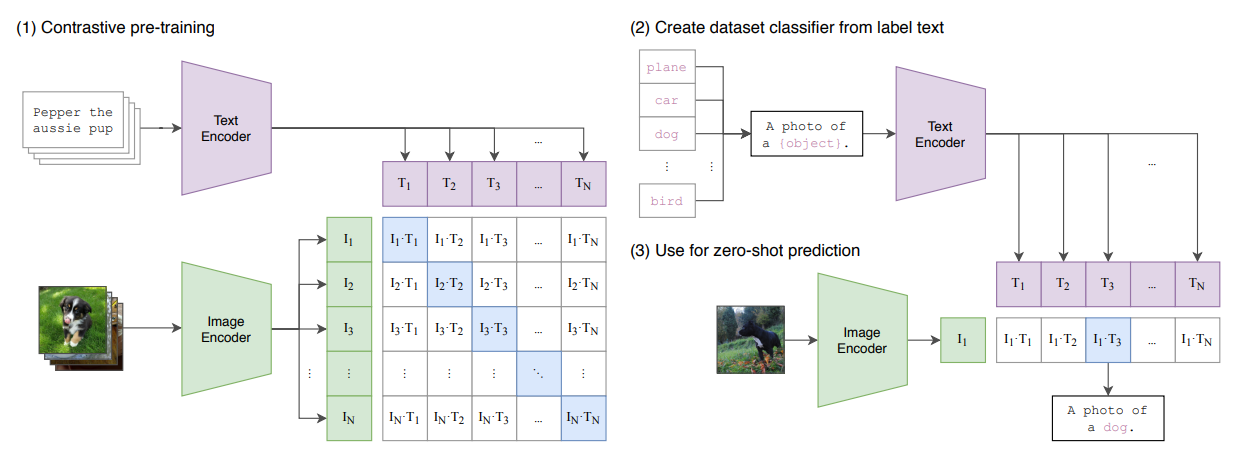
如图(1)所示,模型训练:
- 输入图片->图像编码器(vision transformer)->图片特征向量
- 输入文字->文本编码器(text )->文本特征向量
- 对两个特征进行线性投射,得到相同维度的特征,并进行L2归一化
- 通过余弦相似度计算两个特征向量的相似度
- 计算图像预测文本的损失和文本预测图像的损失,最终取平均作为总损失
如图 (2)、(3) 所示,模型推理:
- 给出一些文本提示词,同时要保证正确
- 计算每一个文本提示词 和图片特征 的相似度
- 相似度最高的即为正确答案
CLIP训练的伪代码如下图所示:

步骤如下:
- 提取图像、文本特征
- 将图像、文本特征与投影矩阵相乘,并进行L2归一化,映射到共享嵌入空间
- 计算图像和文本之间的缩放余弦相似度
- 在列方向(axis=0)以及行方向(axis=1)计算交叉熵损失并求平均
3. 应用场景
这里给出一些应用场景,例如
1. 文搜图/图搜文
- 实现方式:将文本/图像编码为CLIP嵌入向量,通过余弦相似度计算匹配度
- 应用案例 :
- 电商平台:输入"北欧风格沙发"自动展示相关商品图
- 医疗影像库:用自然语言描述(如"肺部结节CT影像")检索匹配病例
2. 视觉问答(VQA)
- 系统架构:CLIP提取图像和问题特征,结合语言模型(如GPT-4)生成答案
- 示例:输入"图中人物在做什么?",CLIP匹配图像动作与文本描述生成回答。