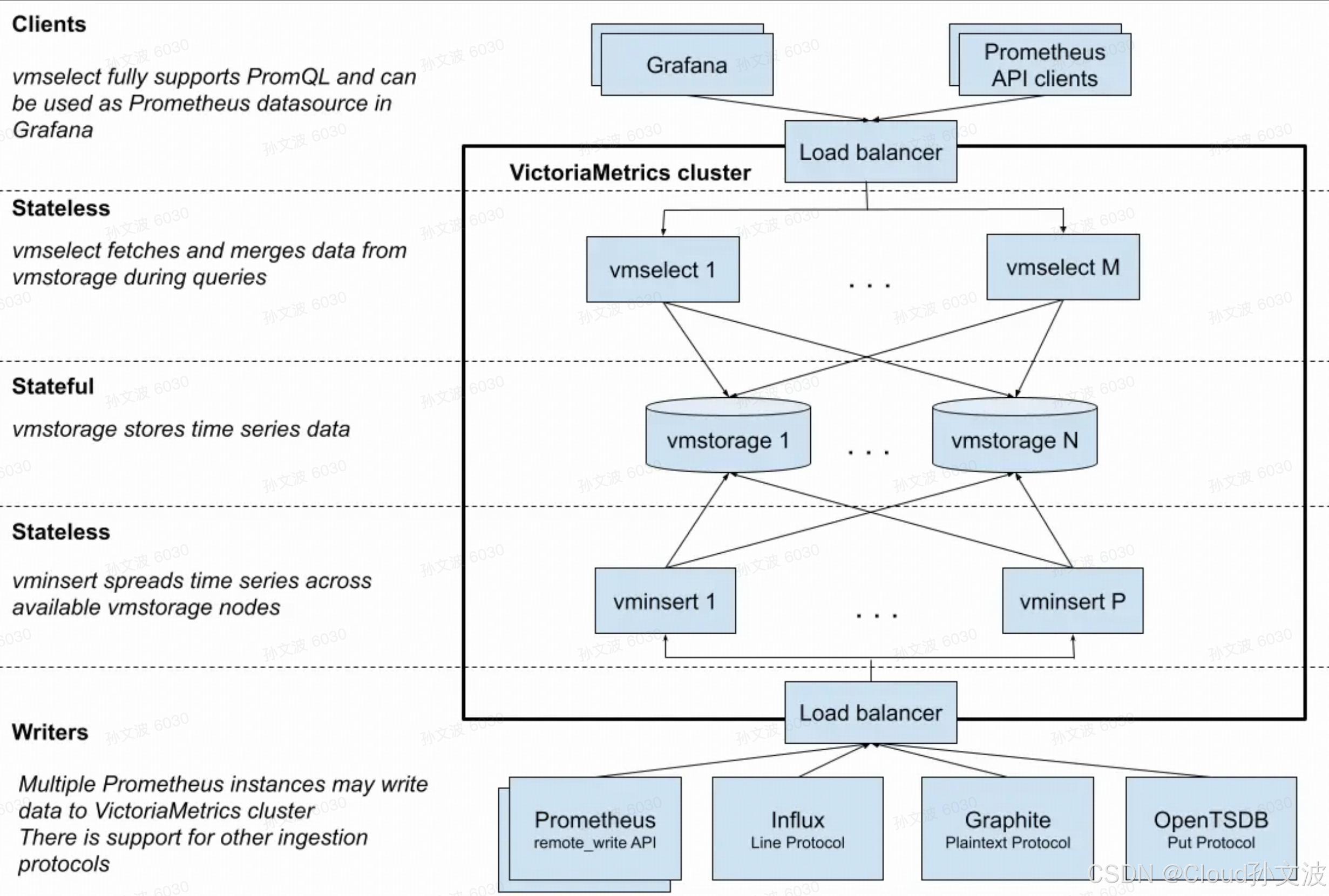
一、VictoriaMetrics 组件总体架构图
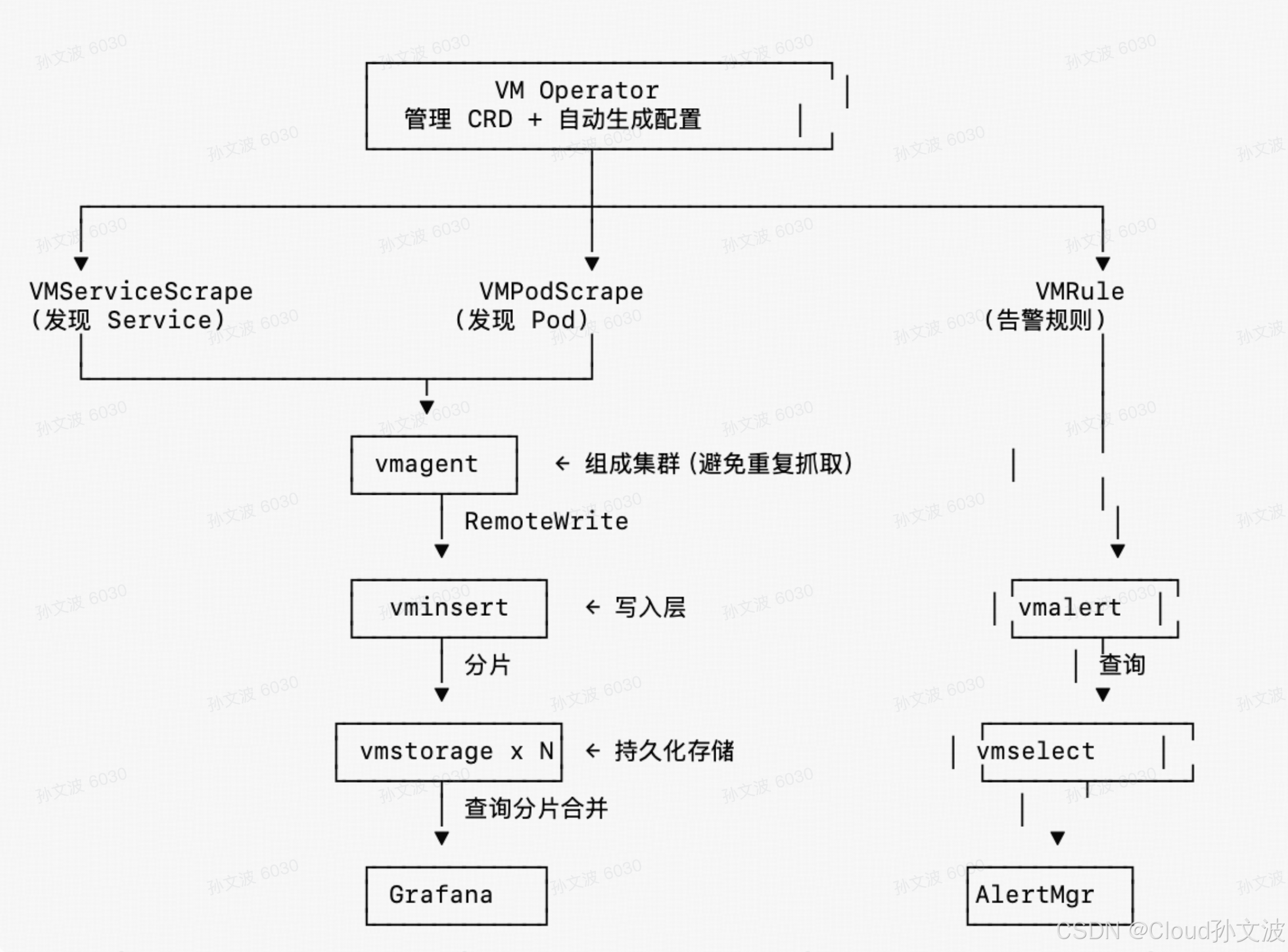
Operator 工作流程图
二、它们是如何协同工作的(工作流)
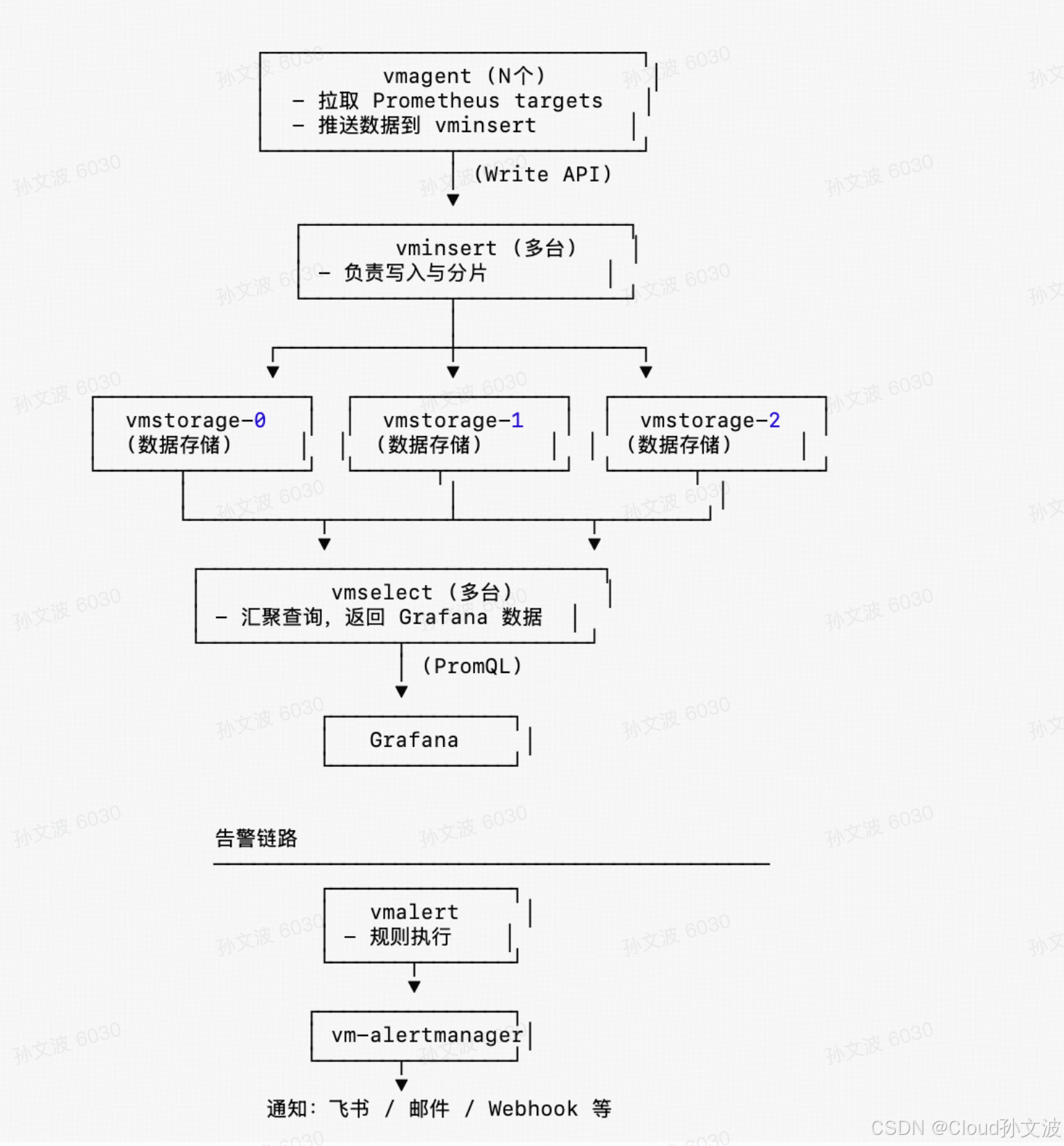
1. 数据采集链路
vmagent
-
发现 targets → 拉取 metrics → 本地缓存/限流
-
发送给 vminsert
vminsert
-
接收数据 → 校验 → 压缩 → 根据租户/seriesID 分片
-
写入对应 vmstorage
vmstorage
-
落盘、索引、合并
-
提供给 vmselect 查询
2. 查询链路(Grafana / API)
-
Grafana/API 发送 promQL 查询 → vmselect
-
vmselect 分解查询,分发到所有 vmstorage
-
vmstorage 返回局部结果
-
vmselect 聚合并优化后返回最终数据
-
Grafana 展示图表
3. 告警链路
-
vmalert 定时执行规则:
-
从 vmselect/Prometheus 读取指标
-
检查阈值
-
-
告警触发 → vmalert 发送给 vm-alertmanager
-
Alertmanager(vm-alertmanager)
-
分组、抑制、路由
-
发送到通知渠道(Webhook、飞书、钉钉、邮件等)
-
三、组件介绍
| 组件 | 作用 |
|---|---|
| vmagent | 高性能抓取器,拉 metrics 并写入 vminsert |
| vminsert | 写入入口,将数据分片写到 vmstorage |
| vmstorage | 时序数据库后端,存储压缩索引数据 |
| vmselect | 查询入口,从 vmstorage 聚合结果 |
| vmalert | 执行告警规则与 recording rules |
| vm-alertmanager | 告警路由、通知、分组、抑制 |
| victoriaMetrics Cluster | vminsert + vmstorage + vmselect 组成的高性能可扩展 TSDB |
| operator | 简化部署和管理。Operator 会自动生成配置、管理集群拓扑、滚动升级等。 |
1. VictoriaMetrics (VM Cluster)
完整的分布式版本,由以下核心组件组成(vmselect、vminsert、vmstorage)。
用于 大规模、高性能、可横向扩容的时序数据库集群。
2. vminsert
写入入口
-
接收 Prometheus、VMAgent、其他客户端的写入请求
-
负责数据校验、压缩、分片
-
将数据分发到多个 vmstorage 节点
-
支持批量写入、反压、限速
3. vmstorage
数据持久化层
-
负责存储时序数据(TSDB),包含内存 + 磁盘分段文件
-
处理数据压缩、倒排索引、合并、长期存储
-
集群中可水平扩展多个节点
-
不对外暴露查询接口,只服务 vminsert / vmselect
4. vmselect
查询入口
-
接收 PromQL 或 MetricsQL 查询
-
将查询分发到各 vmstorage 节点
-
聚合处理结果并返回给客户端(Grafana、Alerting、API)
-
负责缓存、降采样、查询优化
5. vmagent
高性能抓取组件(Prometheus scrapper 替代方案)
-
支持完整 Prometheus scrape_config
-
执行服务发现(SD)
-
拉取 metrics 并发送到 vminsert
-
可横向扩展,可使用集群分片机制避免重复抓取
6. vmalert
规则计算组件
-
执行:
-
时序规则(recording rules)
-
告警规则(alerting rules)
-
-
从 VM / Prometheus 数据源拉取指标 → 计算 → 发到 alertmanager
-
可将规则执行结果回写到 VM
7. vm-alertmanager(兼容 Alertmanager)
告警路由、分组、静默、通知组件
-
接收 vmalert 发来的告警事件
-
根据规则发送到:
-
邮件、电话、钉钉、飞书、Webhook 等
-
功能与 Prometheus Alertmanager 基本一致
8. VM Operator(CRD 管理器)
功能
-
在 Kubernetes 集群中部署和管理任意数量的 VictoriaMetrics 应用程序(例如 vmsingle/vmcluster 实例以及其他组件,如 vmauth、vmagent、vmalert 等)。
-
从 prometheus-operator无缝 迁移 ,并自动转换 prometheus 自定义资源
-
使用crd-objects实现 VictoriaMetrics 集群的简单安装、配置、升级和管理 。
-
能够将应用程序监控的配置(部分配置)委派给最终用户,并管理对不同配置或配置部分的访问权限。
-
与 VictoriaMetrics vmbackupmanager集成 - 用于创建备份的高级工具。请查看 VMSingle 的备份自动化 或 VMCluster 的备份自动化 。
-
k8s-stack helm chart 提供了开箱即用的监控所需的一切, 以及现成的用例和解决方案。
-
能够自定义部署方案模板。
它管理的 CRD 类型包括:
VMServiceScrape
-
类似于 Prometheus Operator 的 ServiceMonitor
-
指定基于 Service 自动发现 targets
VMPodScrape
-
类似于 PodMonitor
-
指定基于 Pod selector 自动发现 targets
VMRule
-
统一管理 vmalert 的规则
-
自动下发到 vmalert
VMAlertmanager
- 声明 Alertmanager 集群资源
VMCluster / VMSingle / VMInsert / VMSelect / VMStorage
- 统一声明 VM 集群拓扑,由 Operator 自动创建对应 StatefulSet/Deployments
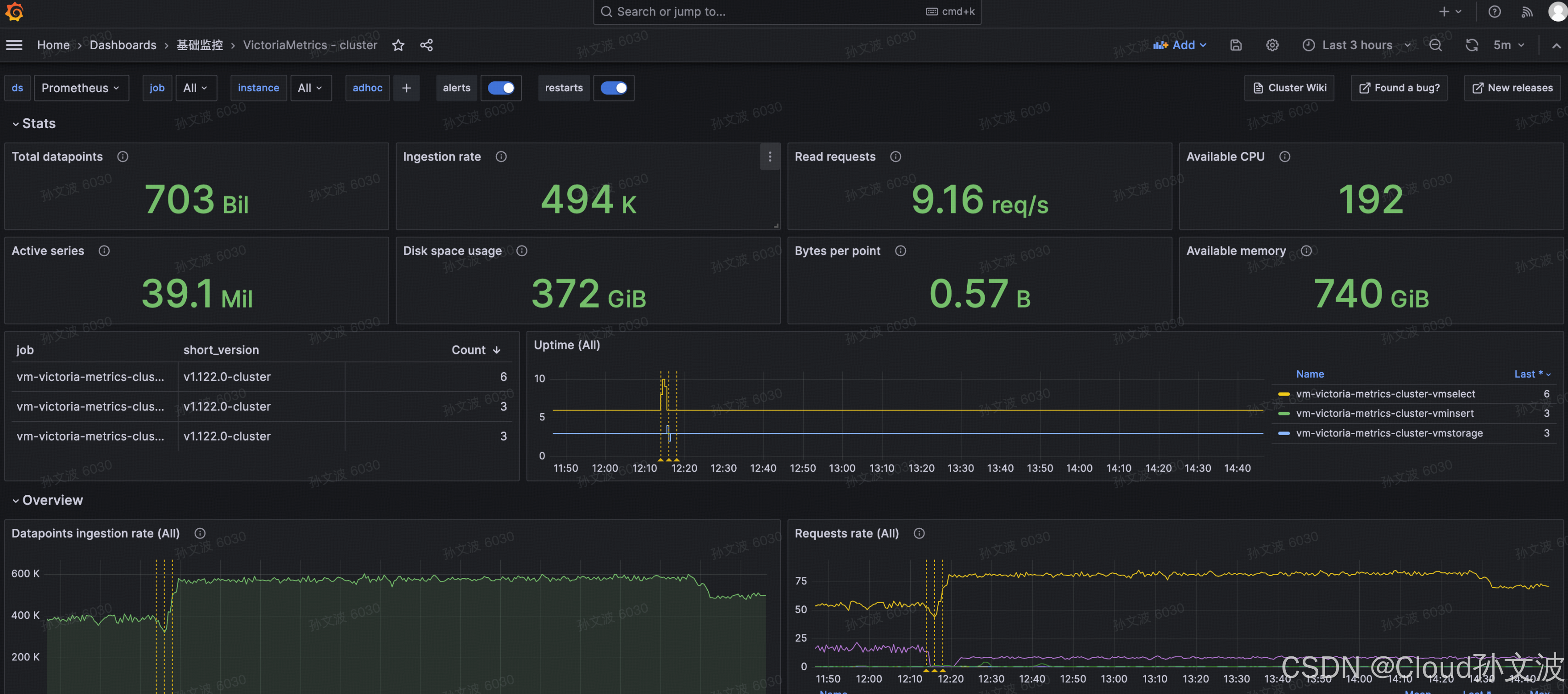
四、监控看板
vm-cluster
https://grafana.com/grafana/dashboards/11176-victoriametrics-cluster/
vm-operator
https://grafana.com/grafana/dashboards/17869-victoriametrics-operator/
五、参数优化
下面配置基于helm chart values.yaml 文件格式
1. Vmstorage
bash
extraArgs:
envflag.enable: true
envflag.prefix: VM_
loggerFormat: json
httpListenAddr: :8482
dedup.minScrapeInterval: "15s" # ha vmagent场景下数据去重。 15 秒内的重复采样数据会被认为是同一份,只存一份 2. Vmselect
bash
extraArgs:
envflag.enable: true
envflag.prefix: VM_
loggerFormat: json
httpListenAddr: :8481
search.maxQueryDuration: 10m # 查询超时 10m
search.latencyOffset: "30s" # 默认值
dedup.minScrapeInterval: "15s" # ha vmagent场景下数据去重。 15 秒内的重复采样数据会被认为是同一份,只存一份
# vmstorage 和vmselect 都需要配置并且必须配置成一致
env:
- name: TZ
value: Asia/Shanghai3. Vmagent
bash
secrets:
- etcd-client-cert
scrapeInterval: 30s
vmAgentExternalLabelName: vmagent_ha
statefulMode: true
#daemonSetMode: true
replicaCount: 2
#relabelConfig:
# name: "vmagent-relabel"
# key: "relabel.yaml"
#inlineRelabelConfig:
# - target_label: bar1
# - source_labels: [aa]
additionalScrapeConfigs:
name: additional-scrape-configs
key: prometheus-additional.yaml
# Sharding
#shardCount: 2
# remote write 目标(你的 vmselect/vminsert 地址) 支持写入kafka
remoteWrite:
- url: "http://vm-victoria-metrics-cluster-vminsert:8480/insert/0/prometheus"
#vmagent_remotewrite_pending_data_bytes > 0 持续上升 , 应增加队列数 用于快速写数据
queues: "100"
maxBlockSize: "67108864"
maxRowsPerBlock: "20000"
# 查看真实 remoteWrite URL(调试时用)
showURL: "true"
extraArgs:
envflag.enable: "true"
envflag.prefix: "VM_"
loggerFormat: "json"
httpListenAddr: ":8429"
promscrape.dropOriginalLabels: "false"
# 关键:添加 cluster sharding 参数
promscrape.cluster.membersCount: "2"
# 关键:给每条 metric 打上 agent 编号
promscrape.cluster.memberLabel: "vmagent_instance"
# 关键:设置 memberNum = podName,VM 会自动从名字提取数字
promscrape.cluster.memberNum: "$(POD_NAME)"
# 去重功能
streamAggr.dedupInterval: "15s"
streamAggr.dropInputLabels: "replica"
# 启用后:页面仍会显示每个 target 最近一次 error, 日志不再被刷爆
promscrape.suppressScrapeErrors: "true"
promscrape.cluster.memberURLTemplate: "http://vmagent-custom-agent-%d.monitoring.svc.cluster.local:8429/targets"
# 接收多大的数据
promscrape.maxScrapeSize: "128MB"
extraEnvs:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
---
apiVersion: v1
kind: Secret
metadata:
name: additional-scrape-configs
namespace: monitoring
stringData:
prometheus-additional.yaml: |
- job_name: 'cadvisor'
kubernetes_sd_configs:
- role: node
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- action: labeldrop
regex: "(id|container_id|image|image_id|container_hash|pod_uid|uid|node_name|name|device|interface|mountpoint|endpoint)"
- action: drop
source_labels: [container]
regex: "POD|pause"
- action: drop
source_labels: [mountpoint]
regex: "/var/lib/kubelet/pods/.+|/var/lib/docker/.+|/run/containerd/.+"
- action: drop
source_labels: [device]
regex: "veth.*|cni.*|docker.*|tun.*"
- action: drop
source_labels: [name]
regex: ".+_[0-9a-f]{8,}$"
- action: drop
source_labels: [__name__]
regex: "container_fs_.*"
- source_labels: [__name__]
regex: ".*_bucket"
action: drop
- source_labels: [__name__]
regex: "container_cpu_cfs_.*|container_blkio_.*|container_tasks_.*|container_hugetlb_.*"
action: drop
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- target_label: __address__
replacement: kubernetes.default.svc:443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor4. Vmalert
bash
datasource:
url: "http://vm-victoria-metrics-cluster-vmselect.monitoring:8481/select/0/prometheus"
remoteWrite:
url: "http://vm-victoria-metrics-cluster-vminsert.monitoring:8480/insert/0/prometheus"
remoteRead:
url: "http://vm-victoria-metrics-cluster-vmselect.monitoring:8481/select/0/prometheus"
maxConnections: 4
notifier:
url: "http://vmalertmanager-custom-alertmanager.monitoring.svc:9093"
timeout: 10s
maxConnections: 5
extraArgs:
loggerLevel: INFO
rule.evalDelay: "30s" #默认值需要和search.latencyOffset 设置为一致 数据有延迟的时候需要配置
external.url: "https://victoria-alert.xxx.cn"
selectAllByDefault: true
evaluationInterval: "30s"
scrapeConfigSelector: {}
serviceScrapeSelector: {}
ruleNamespaceSelector: {}
podScrapeSelector: {}
nodeScrapeSelector: {}
staticScrapeSelector: {}
probeSelector: {}
ruleSelector: {}5. Vmalertmanager
bash
# 持久化存储
storage:
volumeClaimTemplate:
metadata:
name: alertmanager-data
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
storageClassName: ssd-csi-udisk