"这是 GPT-5 以来 agentic coding 最大的跃升,版本号的小幅升级低估了智能的大幅提升。"
------ Windsurf CEO,看到 SWE-Bench Pro 结果后如是说
就在 Altman 内部拉响 Code Red 一周后,OpenAI 果断交卷------GPT-5.2 三剑齐发:
gpt-5.2-instant:对话快如闪电 ⚡gpt-5.2-thinking:深度推理引擎 🧠gpt-5.2-pro:顶级攻坚专家 💎
🔥 一、为什么叫「5.2」?因为------它本该叫「GPT-6」
先看一组震撼数据👇
| Benchmark | GPT-5.1 | GPT-5.2 Thinking | 提升 |
|---|---|---|---|
| AIME 2025(数学奥赛) | --- | ✅ 100% 满分(无工具) | --- |
| ARC-AGI-2(抽象推理) | 17.6% | 52.9% | ↑ 200%+ |
| SWE-Bench Pro(真实代码) | 50.8% | 55.6% | ↑ 4.8 pts |
| GDPval(知识工作胜率) | --- | 70.9% vs 人类专家 | --- |
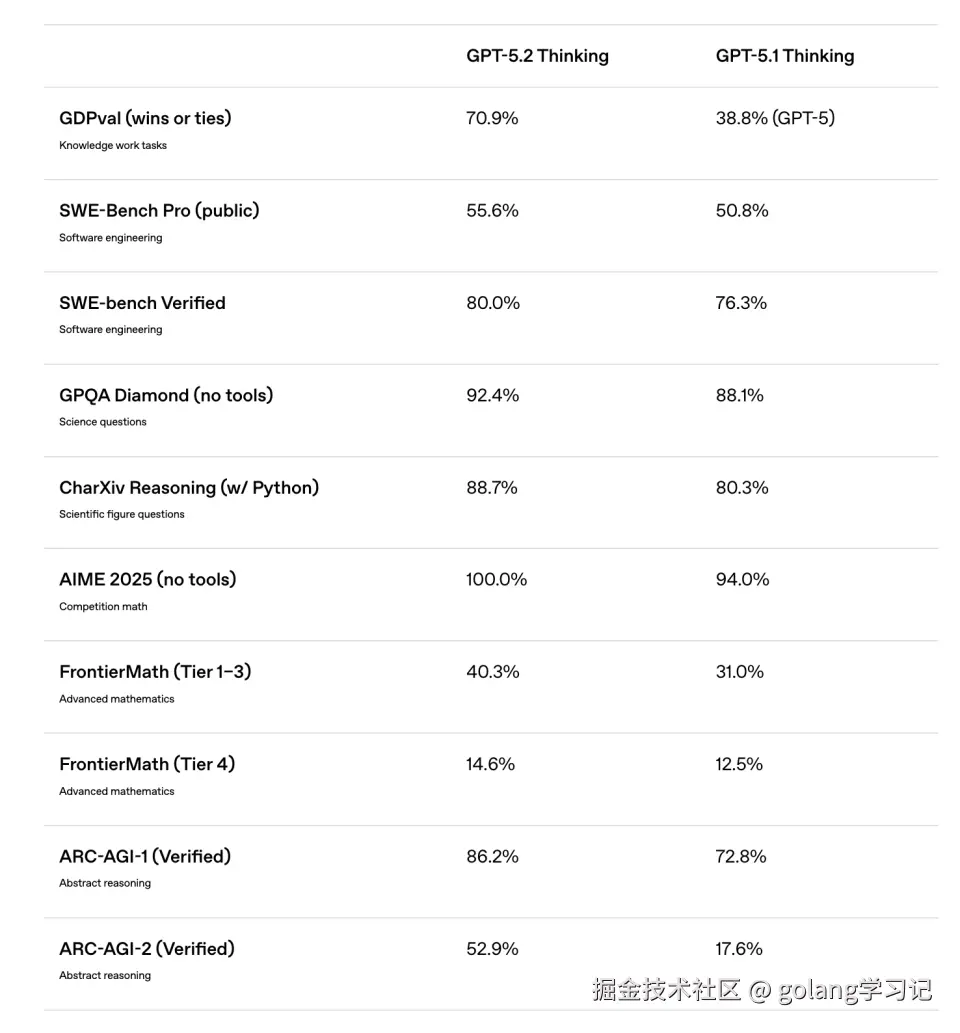
📌 关键洞察:
ARC-AGI-2 从 17.6% → 52.9% 是质变------此前所有模型在此任务上长期卡在 20% 以下,GPT-5.2 是首个突破「常识性抽象推理」门槛的模型。
🧩 二、三大版本,精准分工
| 模型 | 定位 | 适用场景 | 推理耗时 | API 名称 |
|---|---|---|---|---|
| GPT-5.2 Instant | 日常对话快枪手 | 聊天、翻译、简单问答 | <1s | gpt-5.2-chat-latest |
| GPT-5.2 Thinking | 深度任务主力 | 编码、长文分析、数学、规划 | 数秒~数分钟 | gpt-5.2 |
| GPT-5.2 Pro | 专家级攻坚 | 科研级推理、复杂建模、极限精度 | 分钟级(可选 xhigh effort) |
gpt-5.2-pro |
💡 类比:
- Instant = 智能手机快应用
- Thinking = 笔记本主力机
- Pro = 工作站 + GPU 集群
🌟 三、七大能力跃升,附官方实测图
1️⃣ 🧮 数学与科学:拿下 AIME 满分!
- AIME 2025 :✅ 100% 满分(无工具调用)------史上首次
- HMMT 2025 :99.4% → Pro 版 100%
- GPQA Diamond :92.4% → Pro 版 93.2%
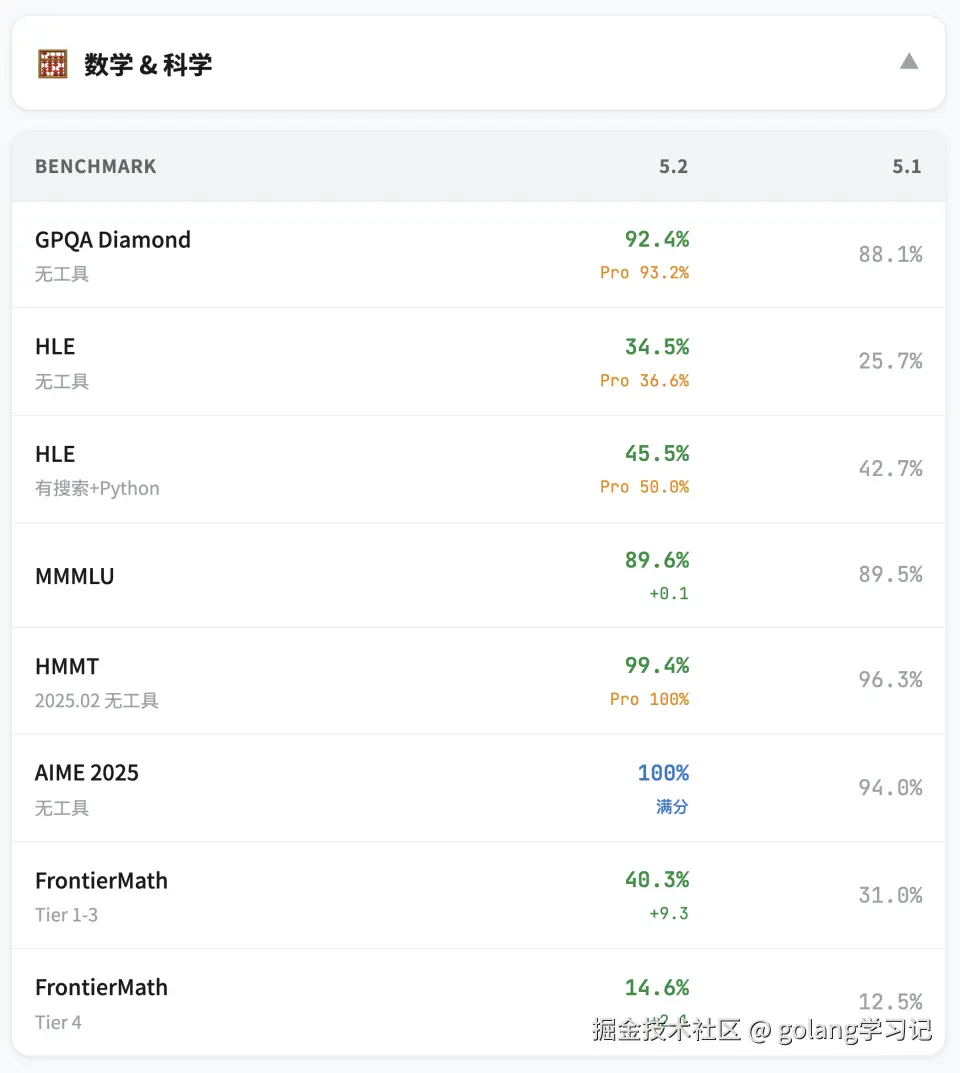
🔍 亮点:不仅能解题,还能生成严谨证明过程,错误率大幅下降。
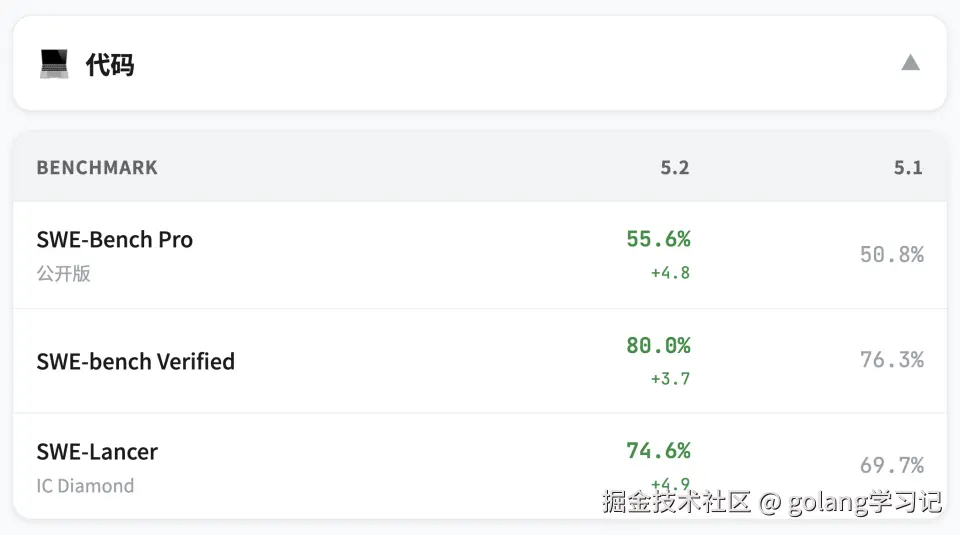
2️⃣ 💻 写代码:SWE-Bench Pro 首超 55%
新 benchmark SWE-Bench Pro 更贴近工业界:
- 支持 Python/Java/TS/Go 四语言
- 要求理解 issue → 修改代码 → 通过测试 → 写注释
| 模型 | SWE-Bench Pro |
|---|---|
| GPT-5.1 | 50.8% |
| GPT-5.2 Thinking | 55.6% |
| Claude 3.5 Sonnet | ~53%*(估算) |
🎯 前端能力飞跃:单 prompt 生成 3D 海浪模拟 (WebGL + 物理参数)👇
cursor虽然推出了最新的visual editor ,但是3D能力还不行
3️⃣ 👁️ 视觉理解:错误率减半,空间感知开挂
- CharXiv Reasoning (论文图表问答):80.3% → 88.7%
- ScreenSpot-Pro (GUI 理解):64.2% → 86.3%
主板识别实测:从「认不全」到「精准标注」
| GPT-5.1 | GPT-5.2 |
|---|---|
 |
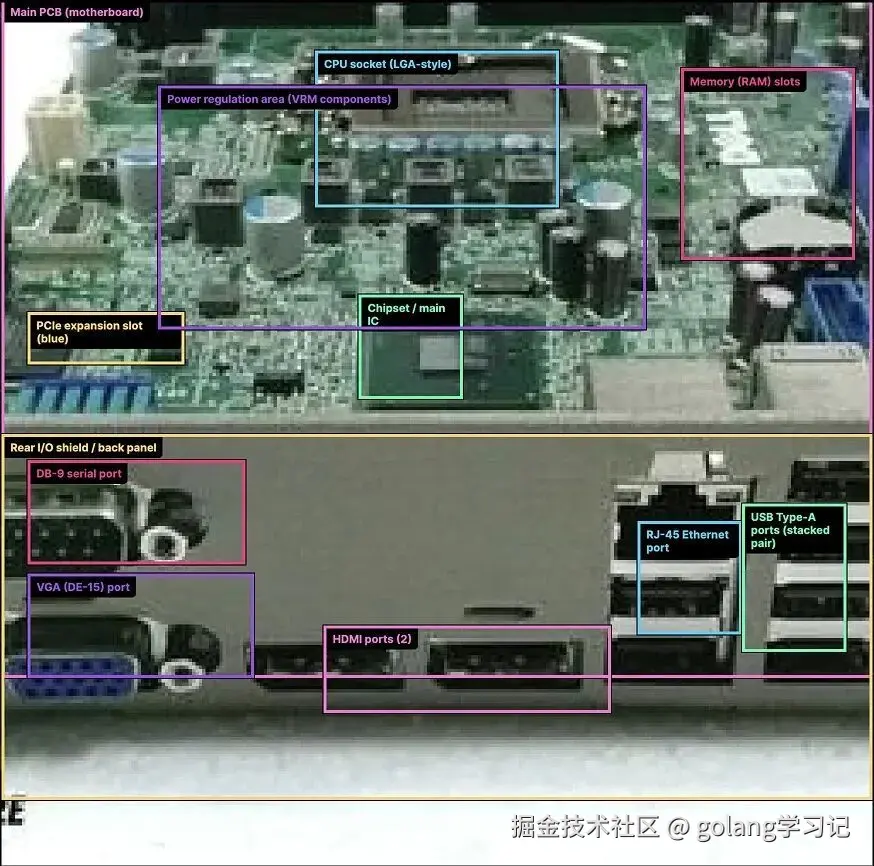 |
✅ 空间推理能力大幅提升:能理解「左上角的 PCIe 插槽」「CPU 下方的 VRM 模块」
4️⃣ 📜 长文档:4-Needle 任务 256K 上接近 100%
OpenAI MRCRv2 测试:在超长文档中找第 N 个「needle」。
| 模型 | 4-Needle @256K |
|---|---|
| GPT-5.1 | ~30% |
| GPT-5.2 Thinking | ~100% ✅ |
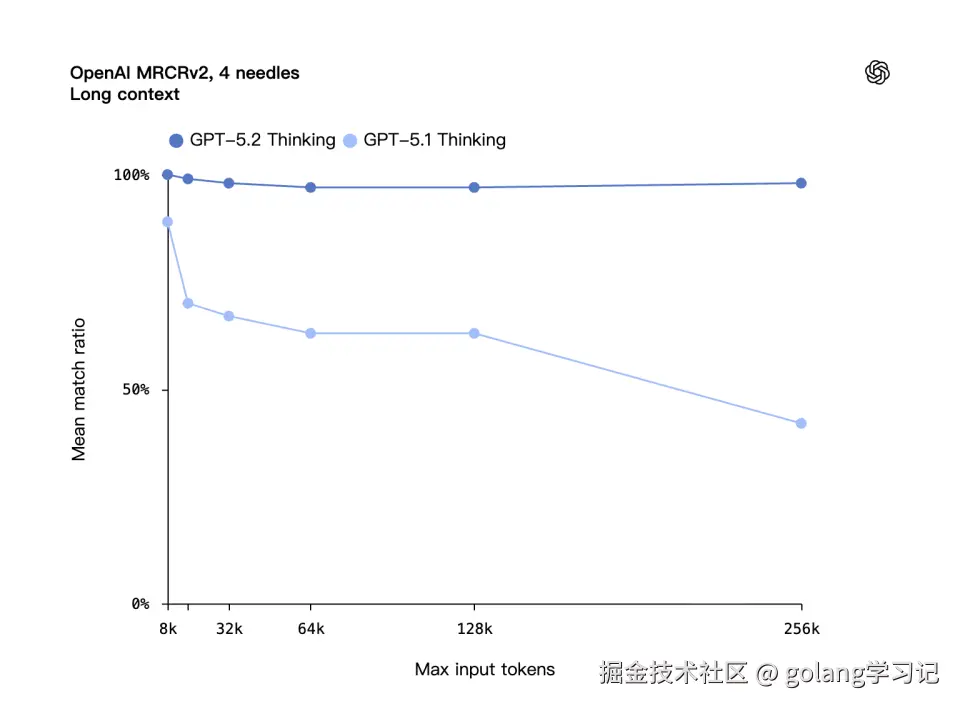
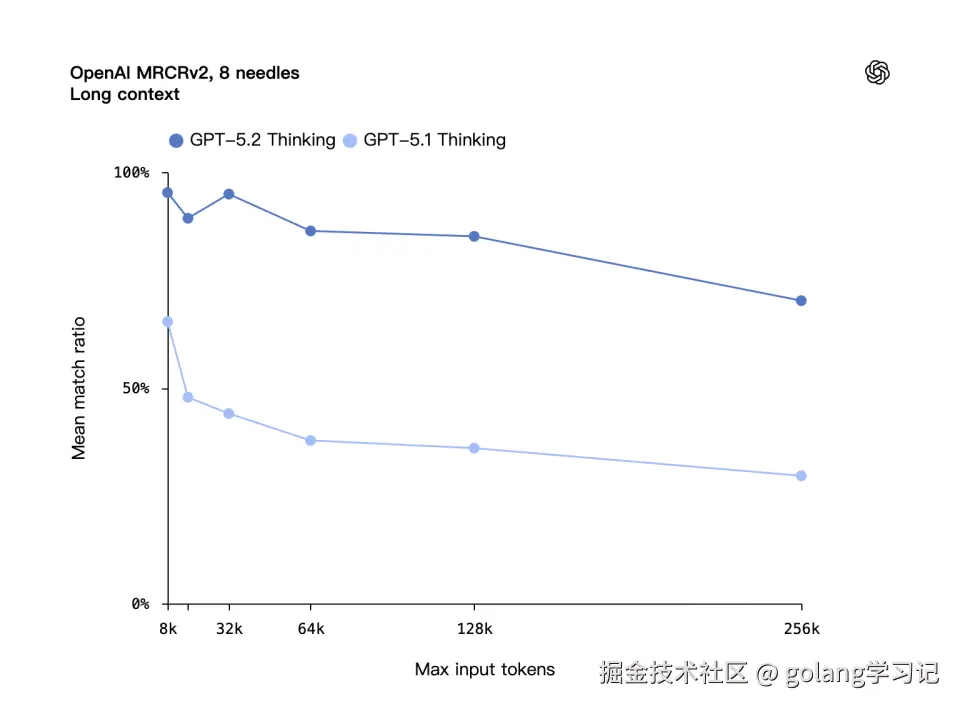
⚙️ 新增
/compactAPI 端点:可动态压缩上下文,支持超长工具链任务。
5️⃣ 🛠️ 工具调用:多轮任务「一步到位」
Tau2-bench(客服场景):
- Telecom 领域:95.6% → 98.7%
- Retail 领域:77.9% → 82.0%
用户需求:「航班延误 + 错过转机 + 行李丢失 + 医疗需求 + 过夜安排」
| GPT-5.1 | GPT-5.2 |
|---|---|
 |
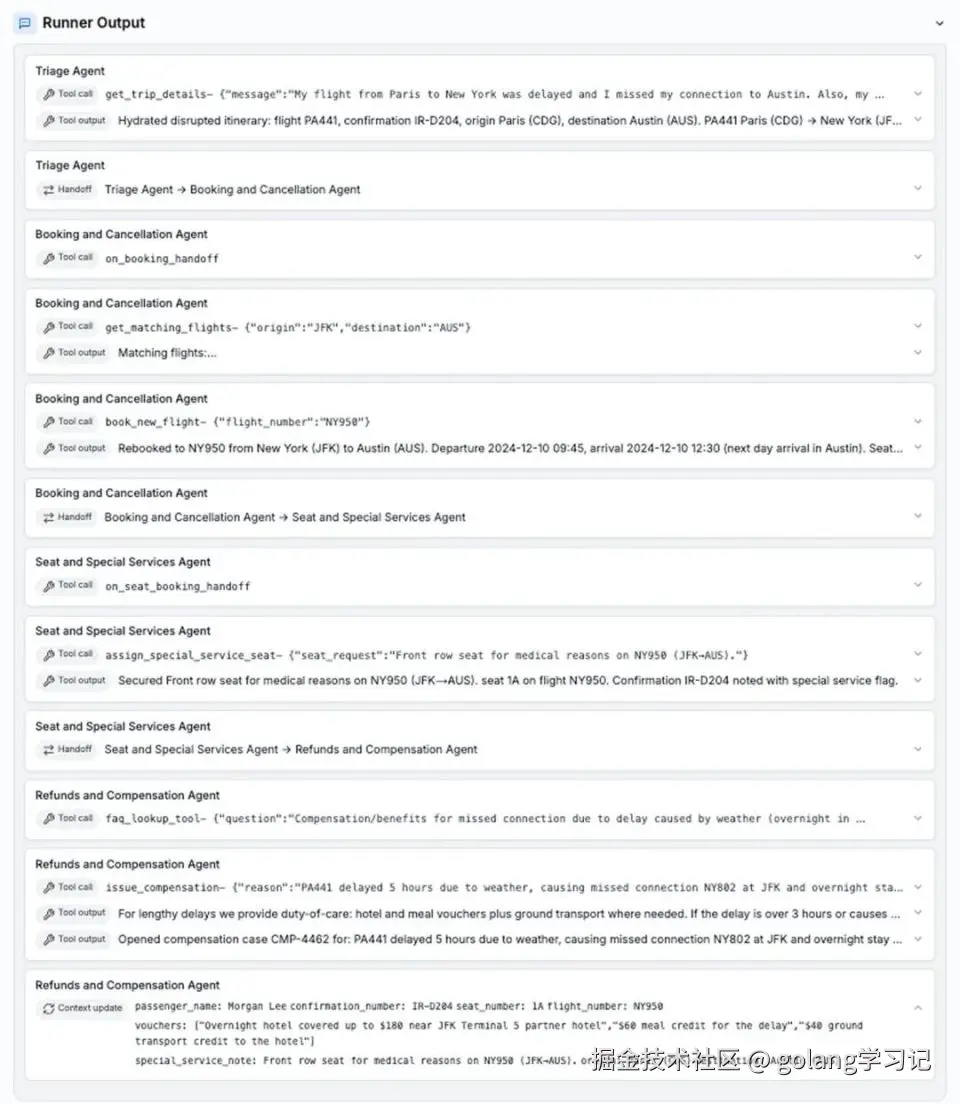 |
✅ Pro 版可串联多个工具调用,实现端到端自动化工作流。
6️⃣ 📊 真实知识工作:70.9% 任务胜过人类专家
新 benchmark GDPval 测 44 个职业任务:
- 做 PPT、建财务模型、写行业报告......
| 模型 | 胜过人类专家比例 |
|---|---|
| GPT-5.2 Thinking | 70.9% |
| GPT-5.2 Pro | 74.1% |
📌 评审员评价:
「看起来像是一个有员工的专业公司做的,布局和建议都很专业」
💰 效率:速度是人类 11 倍,成本 <1%
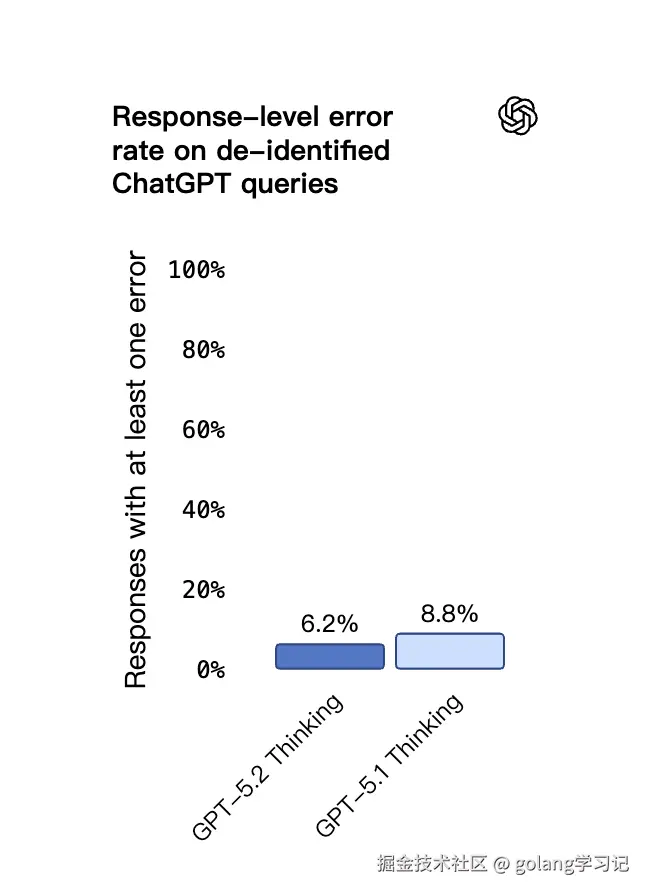
7️⃣ 🎯 幻觉 & 安全:错误回复 ↓30%,儿童保护上线
- 有错误回复率:8.8% → 6.2%(↓30%)
- 新增 年龄预测模型:自动识别 18 岁以下用户,限制敏感内容
- 心理健康对话安全性提升(延续 GPT-5 Safe Completion)

💰 四、价格与性价比:贵了 40%,但可能更省钱?
| 模型 | 价格(vs GPT-5.1) | 每百万 token(输入+输出) |
|---|---|---|
| GPT-5.2 | +40% | $5.00 |
| GPT-5.2 Pro | +150%+ | $20.00+ |
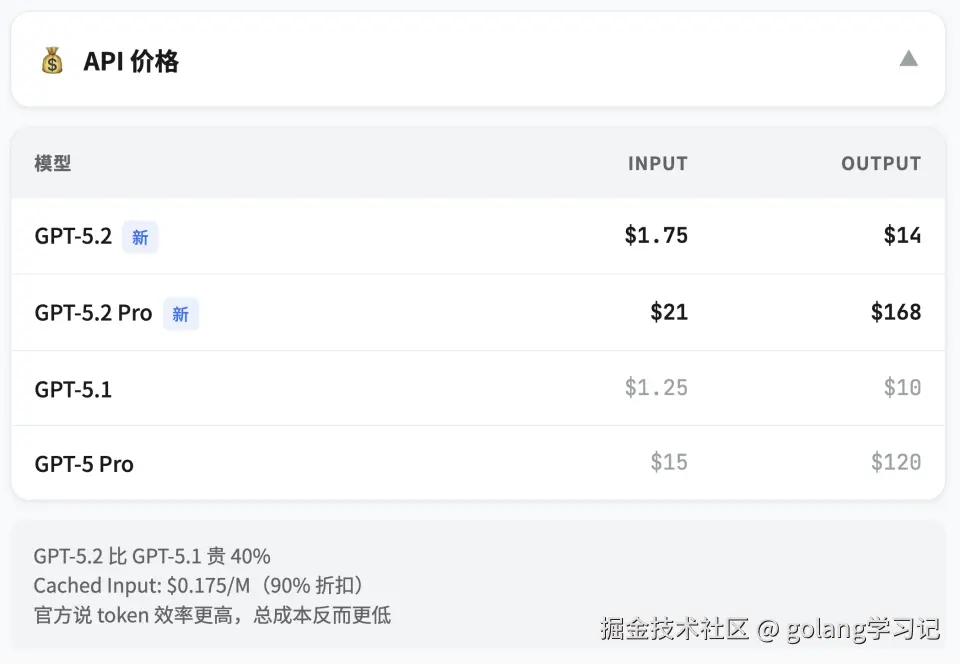
🔁 OpenAI 解释:
「单价更高,但 token 效率提升,达到同样效果的总成本反而更低」例:生成一份专业报告,GPT-5.1 需 3 轮迭代(300K token),GPT-5.2 1 轮搞定(80K token)→ 反降 40% 成本
📌 订阅用户注意:
- ChatGPT Plus / Pro / Business / Enterprise 今日起推送
- GPT-5.1 将保留 3 个月后下线
- Playground 新增
xhighreasoning effort(质量优先模式)
🧭 五、开发者行动建议
| 你的角色 | 推荐动作 |
|---|---|
| 普通用户 | 在 ChatGPT 设置中切换至 GPT-5.2 Thinking,体验「一次生成即达标」 |
| 工程师 | 升级 API → 用 gpt-5.2 替代 gpt-5.1;复杂任务试 gpt-5.2-pro + xhigh |
| 企业用户 | 评估 GDPval 场景(PPT/报表/建模)------人力成本可降 90%+ |
| 研究者 | 关注 ARC-AGI-2 / AIME / HLE 突破,重审「AI 抽象推理」上限 |
🚀 额外彩蛋:
Codex 优化版即将推出------结合 Skills + GPT-5.2,或将诞生「领域专家级编程助手」。
✅ 结语:GPT-5.2 不是升级,是「拐点」
它证明了一件事:
当模型在抽象推理(ARC-AGI)、数学证明(AIME)、真实编码(SWE-Bench Pro)三大「硬骨头」上同时突破,AGI 的路径就不再是哲学问题,而是工程问题。
Code Red 的警报解除了------但真正的竞赛,才刚刚开始。