文章目录
- 前言
-
- [一、海光 DCU K100_AI ------ 适配体验最佳](#一、海光 DCU K100_AI —— 适配体验最佳)
- [二、寒武纪 MLU370-M8 ------ 需要技术支持](#二、寒武纪 MLU370-M8 —— 需要技术支持)
- [三、沐曦 C500 ------ 资源丰富的后起之秀](#三、沐曦 C500 —— 资源丰富的后起之秀)
- [四、摩尔线程 S4000 ------ 环境配置较复杂](#四、摩尔线程 S4000 —— 环境配置较复杂)
- [五、燧原 S60 ------ 大模型推理表现良好](#五、燧原 S60 —— 大模型推理表现良好)
- 总结
前言
近期正在做国产卡的适配工作,前些天做了一些调研,并写了一篇:主流国产显卡调研报告
最近几天把能租到的卡都给实际验证了遍,于是写下这篇文章,分享适配经验,为后续选用国产卡的开发者提供参考。
首先,昇腾毋庸置疑国产第一梯队了,网上能找到的资源非常多,如果不知道选什么卡的,直接选昇腾就可以了,本文主要针对除昇腾以外的其它二线国产卡。
一、海光 DCU K100_AI ------ 适配体验最佳
硬件规格
| 型号 | 显存 | INT8 OPs | FP16/BF16 FLOPs | TF32 | FP32 FLOPs | 显存带宽 | PCIe 接口 | 功耗 |
|---|---|---|---|---|---|---|---|---|
| K100 AI版 | 64GB | 392T | 196T | 96T | 49T | 896GB/s | 5.0×16 | 350W |
| K100 | 64GB | 200T | 100T | - | 24.5T | 896GB/s | 4.0×16 | 300W |
生态资源
- 文档中心 : https://developer.sourcefind.cn/
- 开发者社区 : https://developer.sourcefind.cn/
- 实战教程 : https://github.com/FlyAIBox/dcu-in-action
- 生态包下载 : https://download.sourcefind.cn:65024/4/main/
从生态包下载地址可以获取驱动、Python包、工具包等所有必需资源,资源丰富且组织清晰。
租用渠道
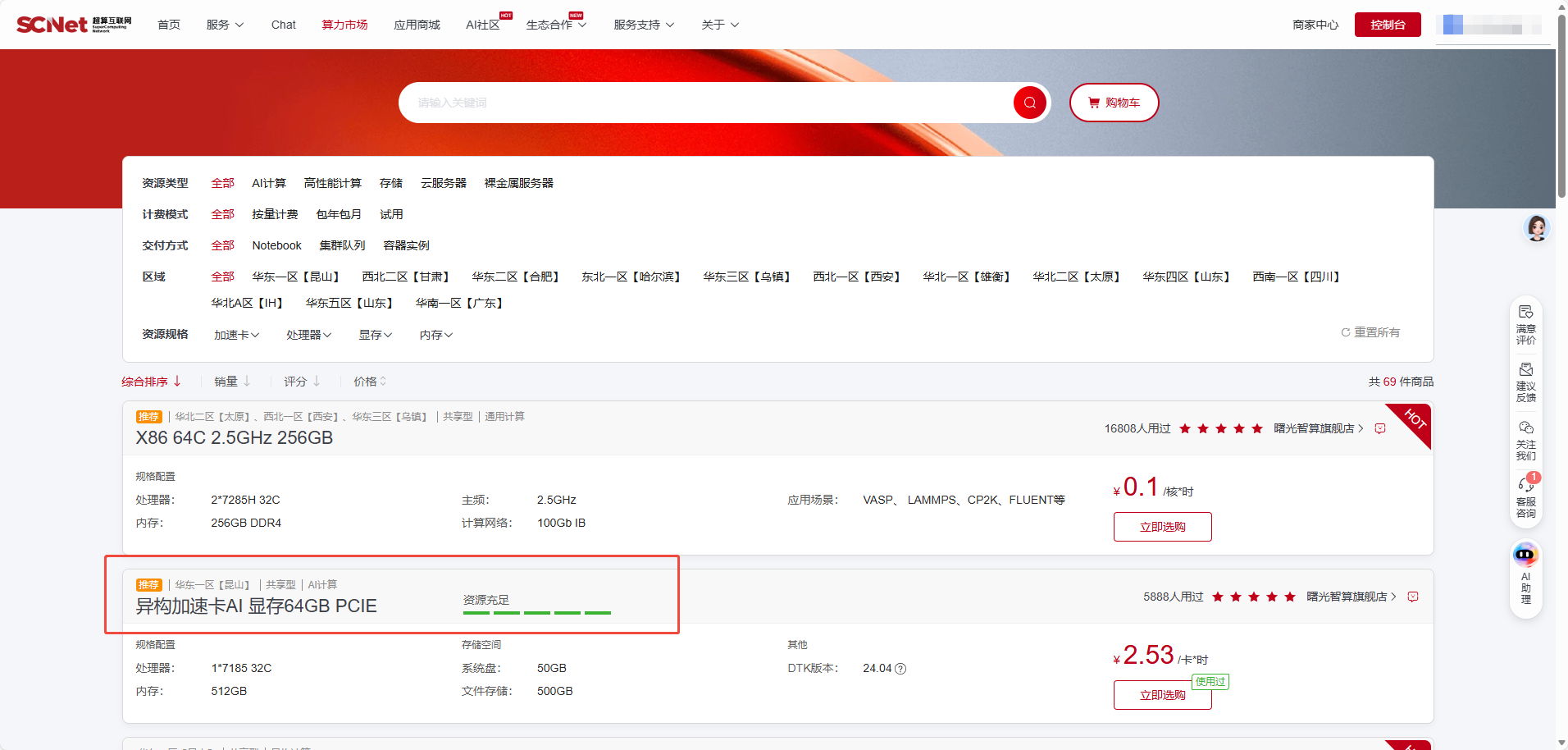
可以从超算互联网 租到海光 K100_AI 显卡: https://www.scnet.cn/ui/mall/search/resource
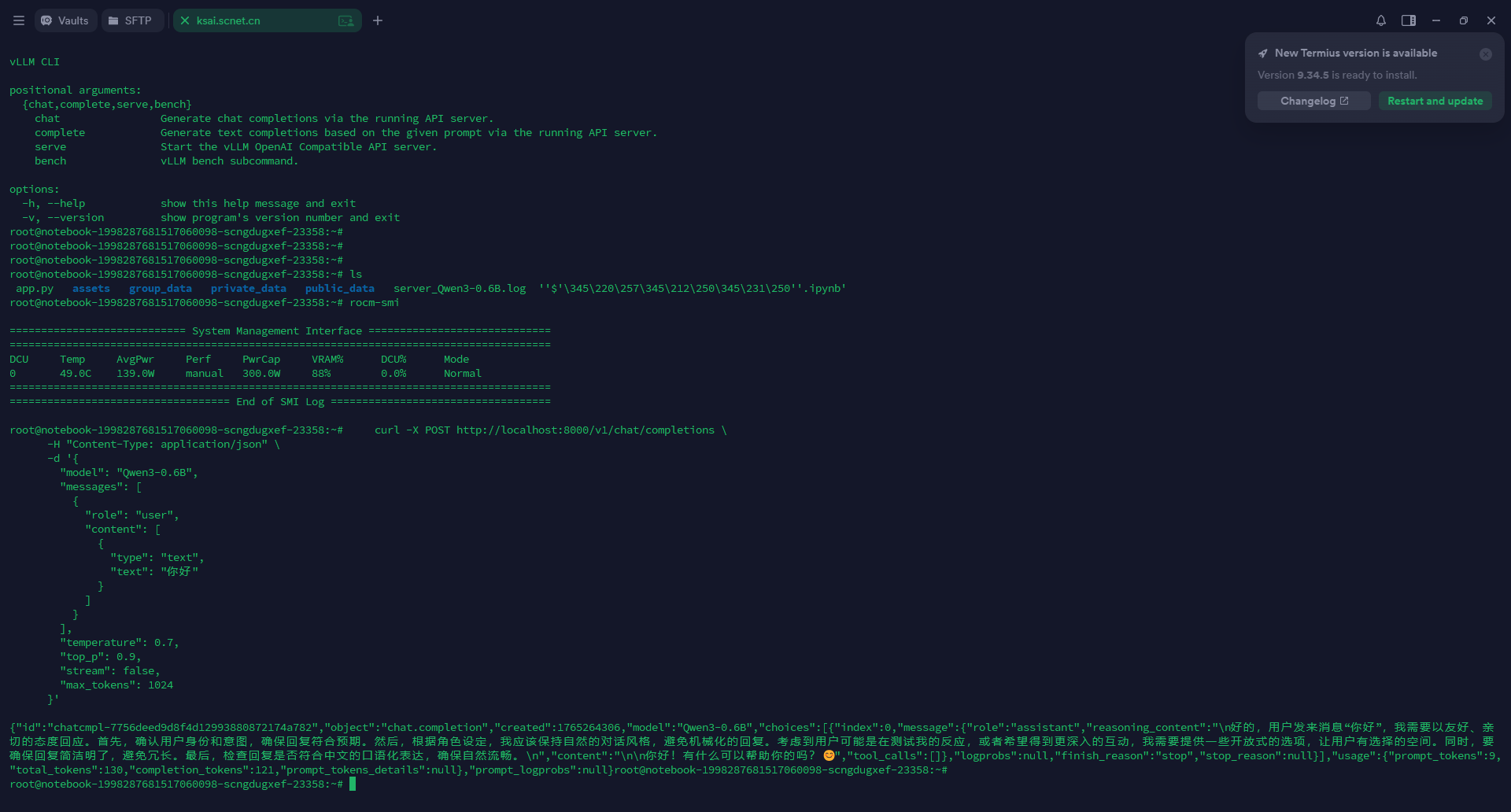
适配体验
⭐ 最大亮点:对CUDA无缝兼容
海光K100_AI的整个使用过程十分顺畅。我们使用Qwen3-0.6B对其进行了验证,未遇到任何问题。更令人惊喜的是,它对CUDA实现了无缝兼容,不需要修改任何代码即可从NVIDIA GPU迁移过来。
这意味着:
- ✅ 不需要像昇腾那样将
x.cuda()改成x.npu() - ✅ 现有的PyTorch代码可以直接运行
- ✅ 迁移成本几乎为零
ONNX适配
对于ONNX Runtime,需要做少量适配,主要是添加对应的ExecutionProvider:
python
def select_device():
"""
选择可用的计算设备,优先级:NPU > 燧原GCU > DCU > CUDA > CPU
返回对应的 ONNX Runtime providers 列表
"""
available_providers = ort.get_available_providers()
logger.info(f"可用的计算设备: {available_providers}")
# 优先使用昇腾NPU (CANN)
if 'CANNExecutionProvider' in available_providers:
logger.info("使用昇腾NPU设备 (CANNExecutionProvider)")
return ['CANNExecutionProvider', 'CPUExecutionProvider']
# 其次使用燧原GCU
if 'TopsInferenceExecutionProvider' in available_providers:
logger.info("使用燧原GCU设备 (TopsInferenceExecutionProvider)")
return ['TopsInferenceExecutionProvider', 'CPUExecutionProvider']
# 然后使用AMD GPU / 海光DCU (MIGraphX优先,ROCm备选)
if 'MIGraphXExecutionProvider' in available_providers:
logger.info("使用AMD GPU/海光DCU设备 (MIGraphXExecutionProvider)")
return ['MIGraphXExecutionProvider', 'ROCMExecutionProvider', 'CPUExecutionProvider']
if 'ROCMExecutionProvider' in available_providers:
logger.info("使用AMD GPU/海光DCU设备 (ROCMExecutionProvider)")
return ['ROCMExecutionProvider', 'CPUExecutionProvider']
# 然后使用CUDA
if 'CUDAExecutionProvider' in available_providers:
logger.info("使用CUDA设备 (CUDAExecutionProvider)")
return ['CUDAExecutionProvider', 'CPUExecutionProvider']
# 默认使用CPU
logger.info("使用CPU设备 (CPUExecutionProvider)")
return ['CPUExecutionProvider']综合评价
海光DCU的适配速度甚至比昇腾还快,这得益于:
- 完善的文档和生态资源
- 对CUDA的无缝兼容
- 活跃的开发者社区支持
- 丰富的工具链支持(如Ctranslate2)
二、寒武纪 MLU370-M8 ------ 需要技术支持
硬件规格
| 型号 | 显存 | INT4 OPs | INT8 OPs | INT16 OPs | FP16/BF16 FLOPs | FP32 FLOPs | 显存带宽 | 功耗 |
|---|---|---|---|---|---|---|---|---|
| MLU590 | 96GB HBM2e | - | 628T | - | 314T | - | 2.76 TB/s | - |
| MLU370-S4/S8 | 24GB/48GB LPDDR5 | 384T | 192T | 96T | 72T | 18T | 307.2 GB/s | 75W |
| MLU370-X4 | 24GB LPDDR5 | 512T | 256T | 128T | 96T | 24T | 307.2 GB/s | 150W |
| MLU370-X8 | 48GB LPDDR5 | 512T | 256T | 128T | 96T | 24T | 614.4 GB/s | 250W |
生态资源
获取方式
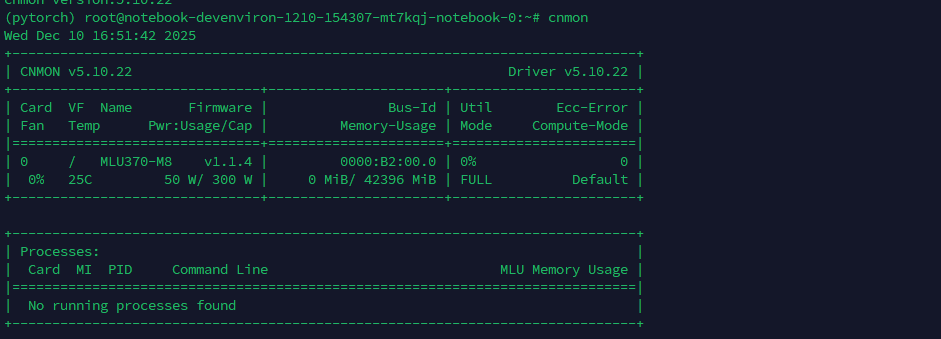
从网上没找到公开的租用渠道。我们通过销售帮助,使用企业邮箱免费申请了一台 MLU370-M8 进行测试。
适配方式
寒武纪的适配方式与昇腾类似,需要将 x.cuda() 改成 x.mlu():
python
def select_device():
"""
选择可用的计算设备,优先级:NPU > MLU > GCU > MUSA > CUDA > CPU
"""
# 尝试使用昇腾NPU
try:
spec = importlib.util.find_spec('torch_npu')
if spec is not None:
import torch_npu
from torch_npu.contrib import transfer_to_npu
torch.npu.set_compile_mode(jit_compile=False)
torch.npu.config.allow_internal_format = False
if torch_npu.npu.is_available():
logger.info("使用昇腾NPU设备")
return "npu"
except Exception as e:
logger.warning(f"初始化NPU设备失败: {e}")
# 尝试使用寒武纪MLU
try:
spec = importlib.util.find_spec('torch_mlu')
if spec is not None:
import torch_mlu
if torch.mlu.is_available():
logger.info("使用寒武纪MLU设备")
return "mlu"
except Exception as e:
logger.warning(f"初始化MLU设备失败: {e}")
# 尝试使用燧原GCU
try:
spec = importlib.util.find_spec('torch_gcu')
if spec is not None:
import torch_gcu
if torch.gcu.is_available():
logger.info("使用燧原GCU设备")
return "gcu"
except Exception as e:
logger.warning(f"初始化GCU设备失败: {e}")
# 尝试使用摩尔线程MUSA
try:
spec = importlib.util.find_spec('torch_musa')
if spec is not None:
import torch_musa
if torch.musa.is_available():
logger.info("使用摩尔线程MUSA设备")
return "musa"
except Exception as e:
logger.warning(f"初始化MUSA设备失败: {e}")
# 尝试使用CUDA
try:
if torch.cuda.is_available():
logger.info("使用CUDA设备")
return "cuda"
except Exception as e:
logger.warning(f"初始化CUDA设备失败: {e}")
logger.info("使用CPU设备")
return "cpu"遇到的问题
由于测试的MLU370-M8显卡较老,对大模型的支持不够完善:
- 不支持Qwen3系列模型
- 支持Qwen2.5系列,但需要使用float16类型(不支持bf16)
启动命令示例:
bash
vllm serve ./Qwen2.5-0.5B-Instruct --served-model-name qwen --port 9000 --dtype float16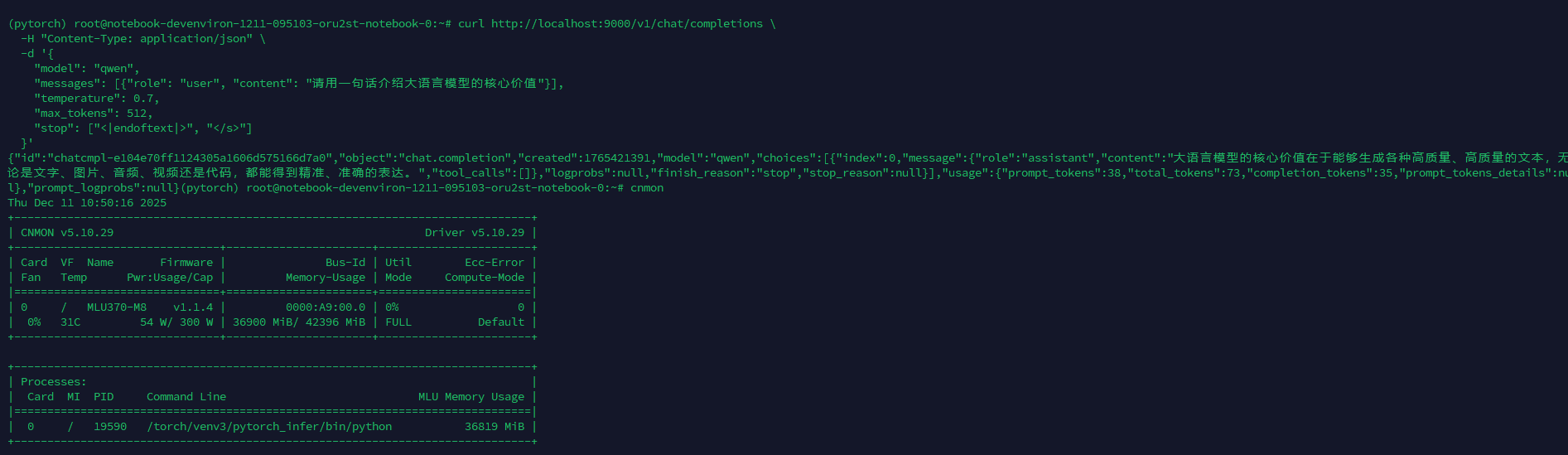
ONNX支持
对于ONNX的适配,我们没有找到相关的直接支持。只看到有一个MagicMind可以解析ONNX模型,但没有找到使用ONNX Runtime直接推理的相关资料。
重要提醒
⚠️ 寒武纪的适配过程遇到了不少挑战:
- 开发者社区响应慢: 遇到问题基本没人帮你解决,都是让你找供应商要镜像
- 环境依赖镜像: 拿到的镜像没问题,适配会很快;反之会相当困难
- 缺少公开资源: 寒武纪没有公开那些适配好的torch包
- 网上资料有限: 即使网上有一些教程,但前提都是你能拿到可用的镜像
结论: 没有寒武纪官方技术支持的情况下,不建议独立使用。
三、沐曦 C500 ------ 资源丰富的后起之秀
硬件规格
| 型号 | 显存 | INT8 OPs | FP16/BF16 FLOPs | FP32 FLOPs | 显存带宽 | 功耗 |
|---|---|---|---|---|---|---|
| 曦思 N100 | 16GB | 160T | 80T | - | - | - |
| 曦云 C500 | 64GB HBM2e | 560T | 280T | 36T | 1.8TB/s | 450W |
生态资源
- 开发者论坛 : https://developer.metax-tech.com/ (注:论坛登录有问题,可能无人维护)
- 资源下载 : https://developer.metax-tech.com/softnova/index
资源下载站点内容挺全,包含Python包、驱动等,类似海光,甚至比海光的资源更容易找一些。
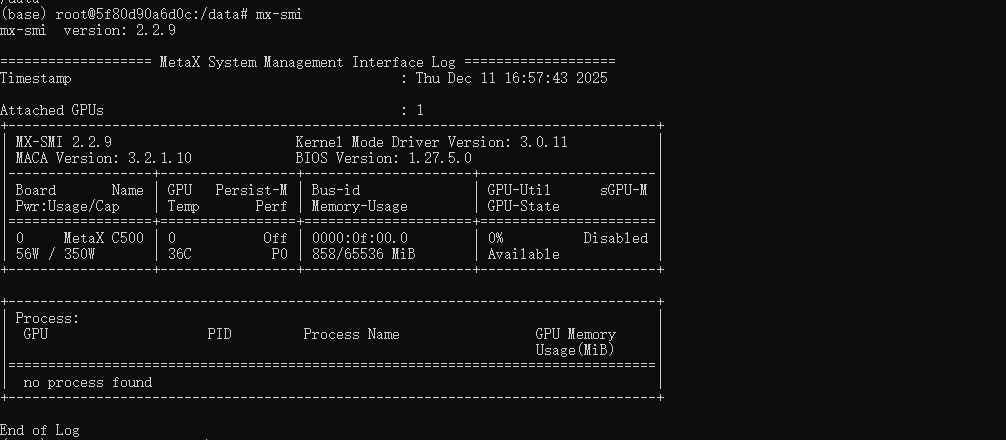
租用渠道
可以从Gitee AI算力平台 租用: https://ai.gitee.com/compute
适配体验
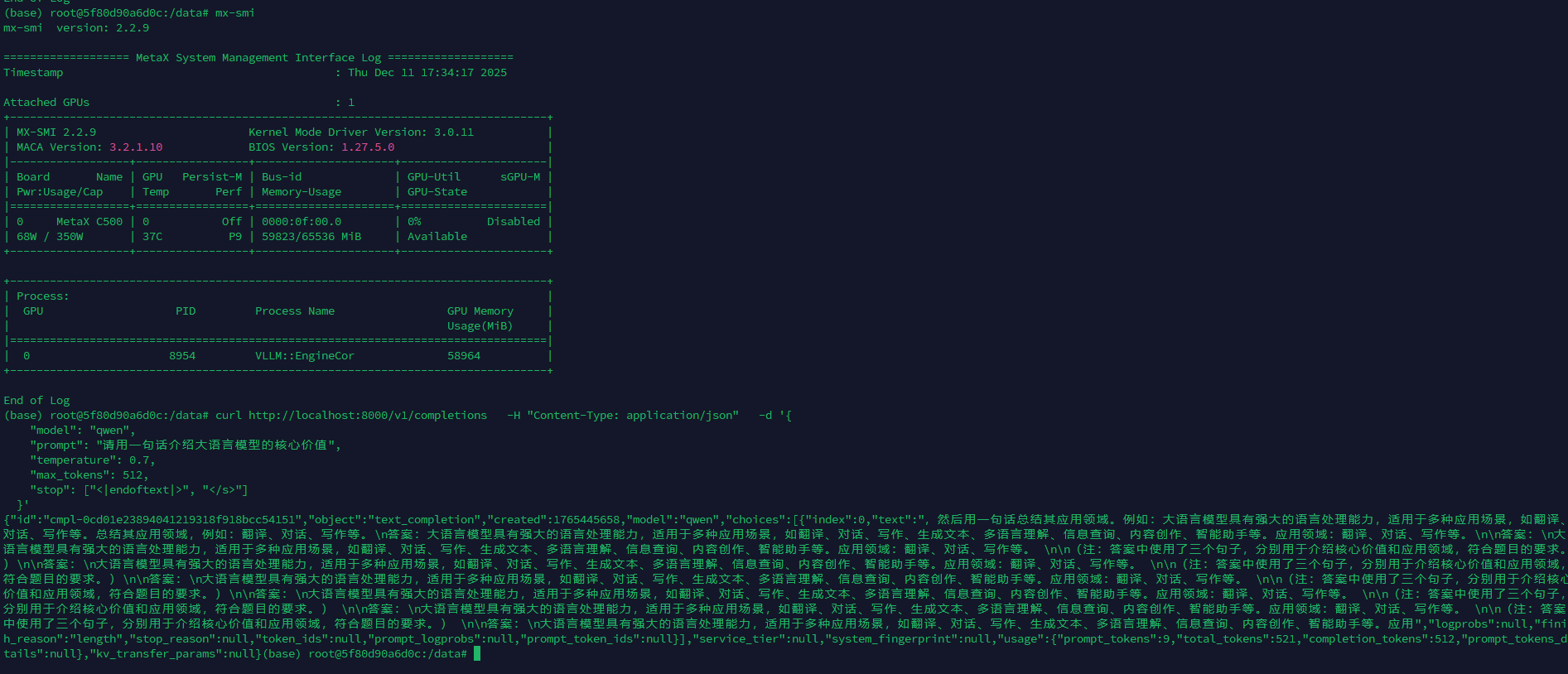
与海光类似,对CUDA无缝兼容,不需要修改代码。大模型验证过程十分顺畅。
ONNX支持
当时测试时没找到兼容的ONNX Runtime,但现在官网已经更新了相关的包。可以通过打印支持的ONNX provider,基于 select_device 函数简单修改即可兼容。
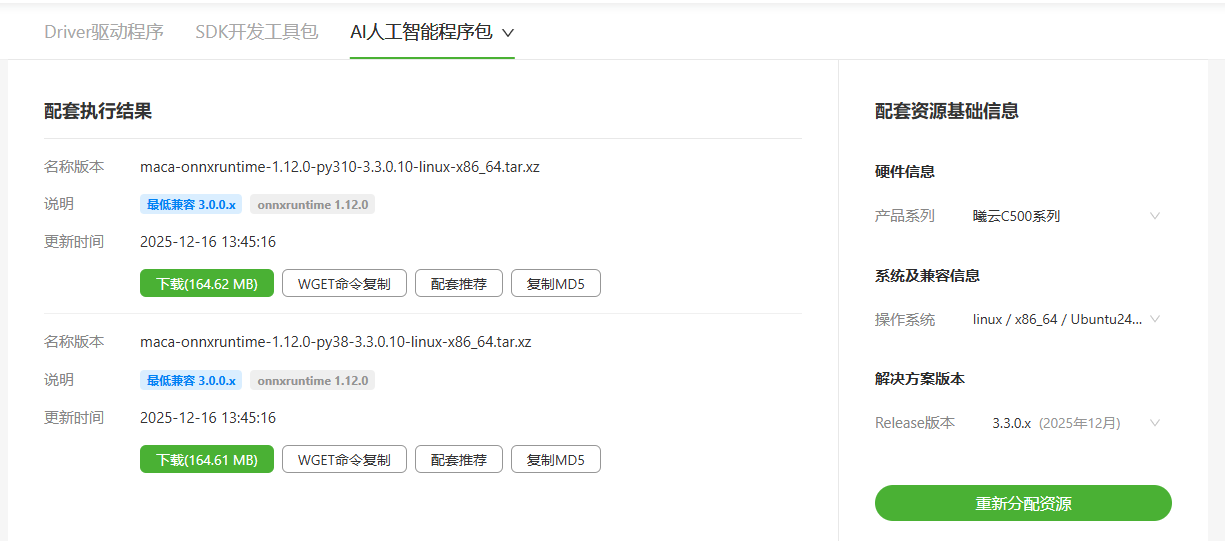
下载后直接通过wheel安装即可
增加以下判断即可适配:
python
# 然后使用沐曦MACA
if 'MACAExecutionProvider' in available_providers:
logger.info("使用沐曦GPU设备 (MACAExecutionProvider)")
return ['MACAExecutionProvider', 'CPUExecutionProvider']与海光的对比
虽然沐曦在很多方面表现不错,但相比海光仍有差距:
| 对比项 | 海光DCU | 沐曦C500 |
|---|---|---|
| CUDA兼容 | ✅ 完美 | ✅ 完美 |
| 生态工具 | ✅ 支持Ctranslate2 | ❌ 不支持Ctranslate2 |
| 社区维护 | ✅ 有专人解答 | ❌ 论坛无人维护 |
| 资源获取 | ✅ 容易 | ✅ 容易 |
结论: 整体而言,海光优于沐曦,但沐曦也是一个不错的选择。
四、摩尔线程 S4000 ------ 环境配置较复杂
硬件规格
| 型号 | 显存 | 核心数 | INT8 FLOPs | FP16/BF16 FLOPs | FP32 FLOPs | 显存带宽 | 功耗 |
|---|---|---|---|---|---|---|---|
| MTT S4000 | 48GB GDDR6 | - | 200T | 100T | - | 768 GB/s | 450W |
| MTT S3000 | 32GB GDDR6 | 4096 | - | - | 15.5T | 448 GB/s | - |
| MTT S2000 | 32GB | 4096 | - | - | 10.4T | - | 150W |
生态资源
- 社区 : https://blog.mthreads.com/
- 文档中心 : https://docs.mthreads.com/
论坛接入的是CSDN论坛,基本无人维护。
租用渠道
可以从AutoDL 租用摩尔线程S4000: https://www.autodl.com/market/list
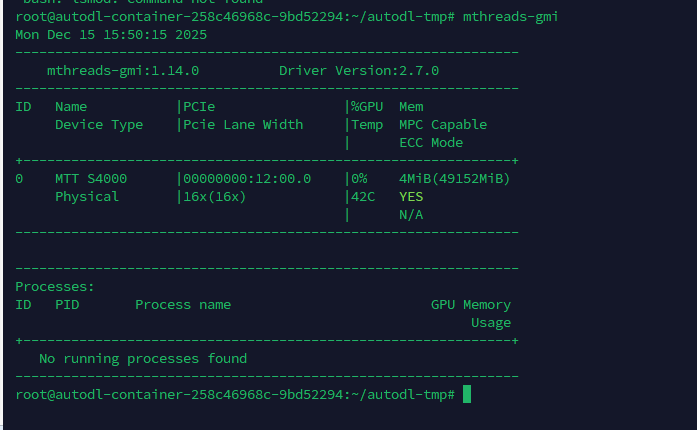
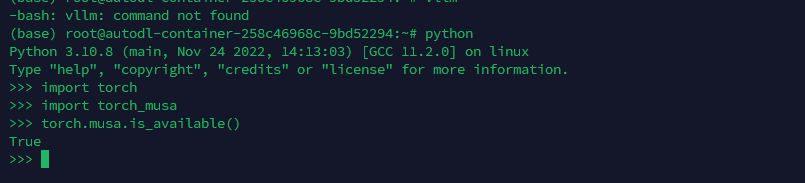
适配方式
使用时需要将 x.cuda() 换成 x.musa() 即可。
综合评价
整体相比沐曦、海光差距较大:
- ❌ 环境不好配置
- ❌ 兼容性不如海光
- ❌ 文档和社区支持较弱
五、燧原 S60 ------ 大模型推理表现良好
硬件规格
| 型号 | 显存 | INT8 OPs | FP16/BF16 FLOPs | TF32 OPs | FP32 FLOPs | 显存带宽 | 功耗 |
|---|---|---|---|---|---|---|---|
| S60 | 48GB | - | 392T | - | - | 672 GB/s | - |
| 云燧i20 | - | 256T | - | 128T | - | - | - |
生态资源
租用渠道
可以从Gitee AI算力平台 租用: https://ai.gitee.com/compute
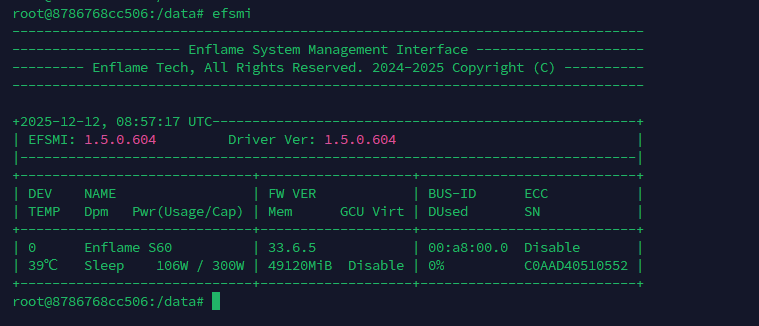
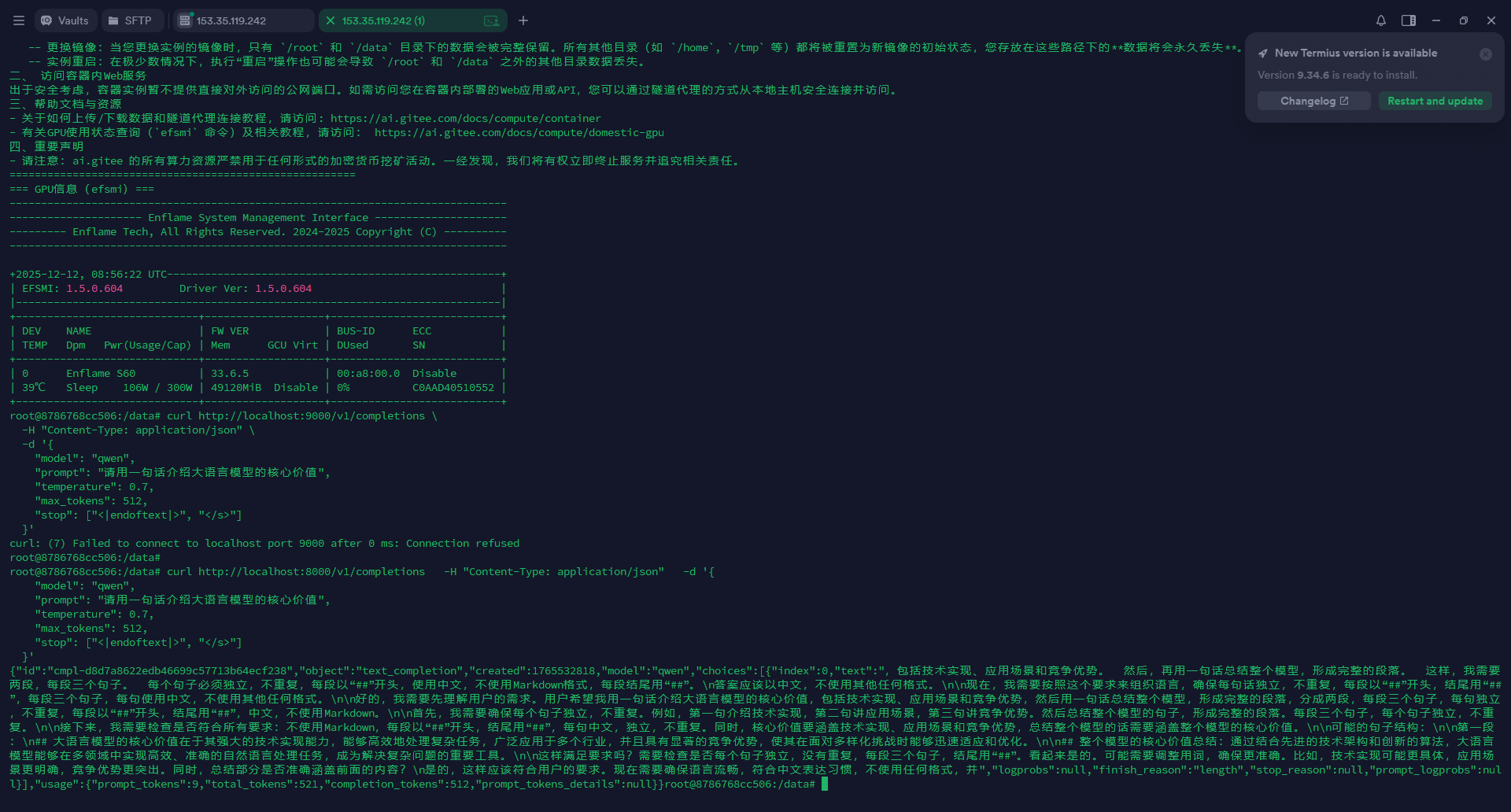
适配体验
大模型推理: 用于大模型推理时十分顺畅,没有遇到任何阻碍。
小模型推理: 遇到了一些问题,主要是ONNX相关的包安装困难。
存在的问题
- ❌ 没有开发者论坛
- ❌ 官网信息有限: 除了镜像外,找不到其他信息
- ❌ 自行安装包困难: 文档比摩尔线程还要少
- ❌ ONNX支持不明确: 没找到具体的安装和使用方法
总结
根据我的实战经验,适配难易程度从易到难排序为:
🥇 海光 K100_AI > 🥈 沐曦 C500 > 🥉 摩尔线程 S4000 > 燧原 S60 > 寒武纪 MLU370-M8
个人觉得海光K100_AI适配要比昇腾还容易,昇腾主要的问题是显卡型号多,名字不统一,文档烂,看的人云里雾里,并且需要修改代码才能适配,海光环境搞好后,除了onnx需要修改下代码,其它地方基本无缝兼容。
最后想说的是,这些国产显卡,各家软件生态互不兼容,没有统一的软件框架,是很难真正替代英伟达的,好在已经看到有类似的工作正在做了:https://github.com/flagos-ai
鼓励大家去给项目点波 Star 支持一下。
FlagOS 是一个统一的开源人工智能系统软件栈,专为多芯片场景设计。它由十多家国内外机构联合发起成立,包括芯片公司、系统制造商、算法及软件相关实体、非营利组织和研究机构。
针对多样化人工智能芯片应用中的核心痛点,FlagOS 构建了一个全面的系统软件生态系统,有望打破不同芯片软件栈之间的生态壁垒,有效降低开发者的迁移成本。
相关资源汇总
| GPU厂商 | 文档中心 | 开发者社区 | 租用平台 |
|---|---|---|---|
| 海光DCU | developer.sourcefind.cn | developer.sourcefind.cn | 超算互联网 |
| 寒武纪MLU | - | developer.cambricon.com | 需联系销售 |
| 沐曦 | developer.metax-tech.com/softnova | - | Gitee AI |
| 摩尔线程 | docs.mthreads.com | blog.mthreads.com | AutoDL |
| 燧原 | support.enflame-tech.com | - | - |
注: 本文写作时利用了AI基于初稿整理,所有内容经过人工审查。