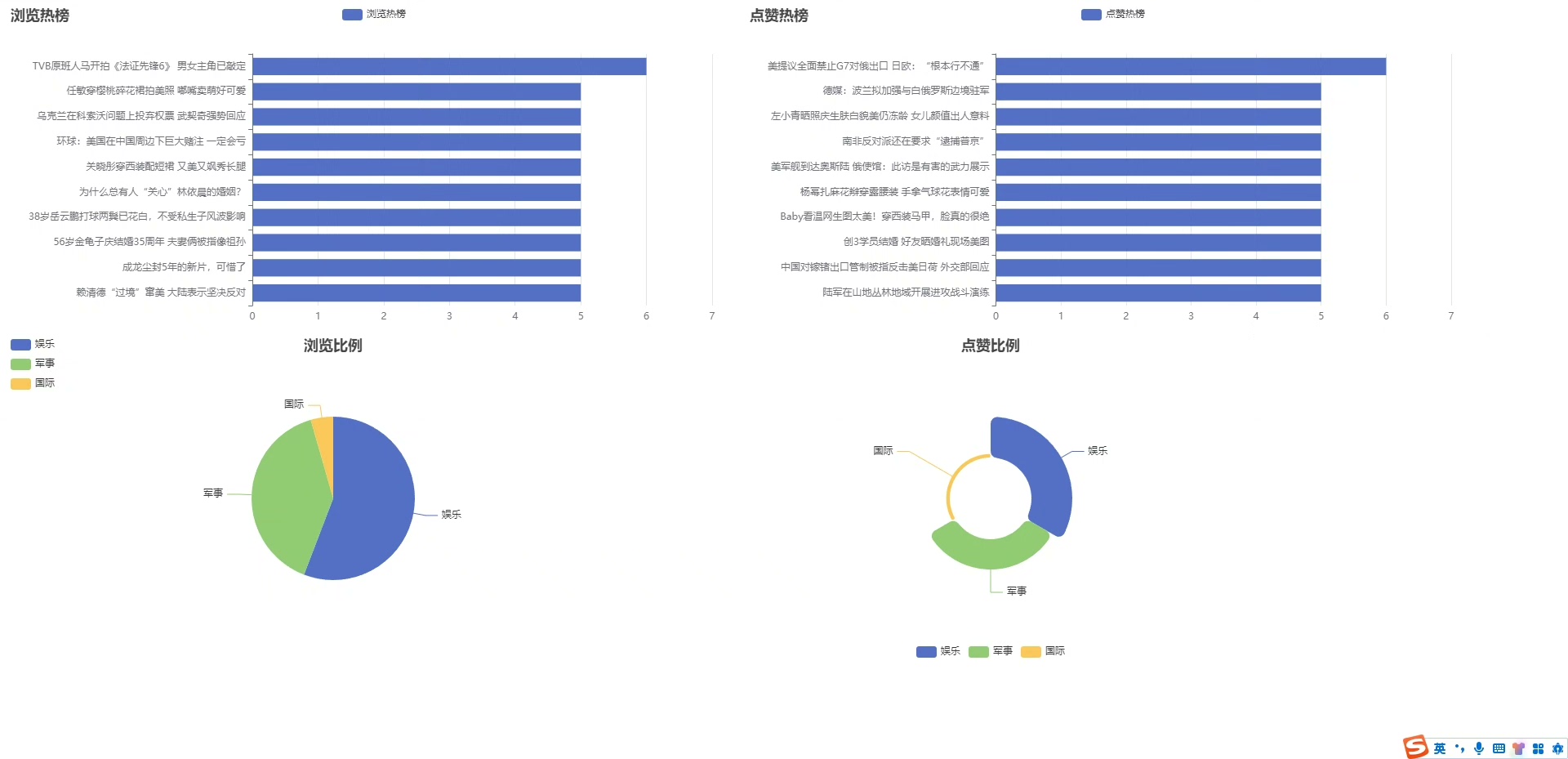
基于flume kafka hdfs hive日志采集与数据分析系统
日志数据像洪水一样涌来的时候,传统做法是把服务器当移动硬盘用,scp拷来拷去迟早翻车。搞实时分析更别想了,Excel都能给你卡成PPT。今天咱们直接上硬菜,手撸一套能扛百万级日志的生产级方案。
日志收集:Flume的骚操作

Flume配置的核心就三块:从哪里吃、怎么咽、往哪吐。给个实战配置片段:
properties
# agent取名要有逼格,比如用星座命名
agent_z.sources = tail_source
agent_z.channels = mem_chan
agent_z.sinks = kafka_sink
# 监控追加文件(重点!)
agent_z.sources.tail_source.type = exec
agent_z.sources.tail_source.command = tail -F /var/log/app/access.log
agent_z.sources.tail_source.fileHeader = true
# 内存通道别浪,超过5000条就溢血
agent_z.channels.mem_chan.type = memory
agent_z.channels.mem_chan.capacity = 10000
agent_z.channels.mem_chan.transactionCapacity = 500
# 往Kafka的topic里怼数据
agent_z.sinks.kafka_sink.type = org.apache.flume.sink.kafka.KafkaSink
agent_z.sinks.kafka_sink.kafka.bootstrap.servers = kfk1:9092,kfk2:9092
agent_z.sinks.kafka_sink.kafka.topic = app_logs
agent_z.sinks.kafka_sink.flumeBatchSize = 200关键点在于tail -F实时追踪日志变化,比inotify靠谱。Kafka的batch size别设太大,200条刚好避免网络抖动。
数据缓冲:Kafka的保命设计
生产端搞个Java示例(别用原生API,low爆了):
java
Properties props = new Properties();
props.put("bootstrap.servers", "kfk1:9092");
props.put("acks", "1"); // 平衡可靠性和性能
props.put("linger.ms", 50); // 攒够50ms就发车
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.ByteArraySerializer");
Producer<String, byte[]> producer = new KafkaProducer<>(props);
producer.send(new ProducerRecord<>("app_logs", logData.getBytes()));这里用byte数组直接传原始日志,避免JSON序列化的性能损耗。acks设为1保证至少leader确认,不像0那样可能丢数据。
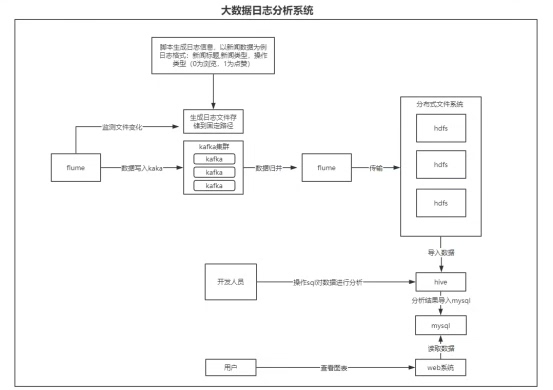
持久化存储:HDFS的正确姿势
HDFS不是无脑存,得考虑分区。用时间戳做目录结构:
bash
hdfs dfs -mkdir -p /logs/app_logs/dt=20230801/hour=14用Spark消费Kafka写入HDFS时,注意小文件合并:
scala
df.write
.option("maxRecordsPerFile", 100000) // 10万条一个文件
.partitionBy("dt", "hour")
.parquet("hdfs://nn:8020/logs/app_logs")数据分析:Hive的魔法时刻
建表语句暗藏玄机:
sql
CREATE EXTERNAL TABLE app_logs (
ip STRING,
method STRING,
path STRING,
status INT
) PARTITIONED BY (dt STRING, hour STRING)
STORED AS PARQUET
LOCATION '/logs/app_logs'
TBLPROPERTIES ("parquet.compression"="SNAPPY");重点在外部表和分区设置,用Parquet格式存储比纯文本省60%空间。动态分区配置要开:
sql
SET hive.exec.dynamic.partition=true;
SET hive.exec.dynamic.partition.mode=nonstrict;查数据时活用分区剪裁:
sql
SELECT count(*)
FROM app_logs
WHERE dt='20230801' AND hour BETWEEN '14' AND '16'
AND status=500; -- 快速定位故障时段避坑指南:
- Flume内存通道监控必须做,用JMX配报警
- Kafka消费者组偏移量监控用Burrow
- HDFS小文件用定期合并任务处理
- Hive元数据存MySQL别用derby,死得快
这套组合拳打下来,日均TB级日志处理毫无压力。不过别照搬配置,根据自己业务量调整参数,比如Kafka分区数至少是消费者数量的两倍,Hive的tez容器内存按数据量来调。搞大数据就像吃川菜,火候和配料得自己把握。