在大数据领域,查询引擎层出不穷。今天我们来聊聊 Trino(原 PrestoSQL),带你用最快的方式在本地跑起来,并使用 DBeaver 进行可视化连接。
一、 什么是 Trino?
Trino 的前身是 Facebook 在 2012 年开源的 Presto,一个 不存数据,只负责统一查询的 SQL 引擎,2018年,Presto 的三位核心创始人离开 Facebook,成立了 Presto Software Foundation,并维护了一个分支叫 PrestoSQL。Facebook 继续维护原版,称为 PrestoDB。2020年12月,由于商标争议,PrestoSQL 正式更名为 Trino。
1. 它是干嘛的?
想象一下,你们公司的数据可能散落在各个地方:
- 用户表 存放在 MySQL 里。
- 日志文件 存放在 S3 或 HDFS 里。
- 实时订单 存放在 Kafka 或 Redis 里。
如果你老板让你:"查一下过去一周,买东西最多的用户都在哪个城市?"
- 没有 Trino 时:你得先去 MySQL 导数据,再去 S3 导日志,写个脚本把它们拼在一起,累死人还慢。
- 有了 Trino 时 :你只需要写一句 标准的 SQL,Trino 就会同时去连 MySQL、S3 和 Redis,把数据"抓"过来,在内存里拼好,直接给你结果。
2. 核心特点
- 联邦查询:一条 SQL 关联不同数据源(比如 MySQL Join PostgreSQL)。
- 速度快:全内存计算,专为交互式分析设计。
- 不存数据:它只是计算引擎,数据还在原来的地方。
二、 Docker 极速安装
使用 Docker 是体验 Trino 最快的方式。官方镜像已经内置了 tpch(测试用)数据源,开箱即用。
1. 启动容器
在终端执行以下命令:
bash
docker run --name trino -d -p 8080:8080 trinodb/trino2. 验证安装
等待镜像下载并启动后,我们可以进入容器内部使用命令行工具(CLI)简单测试一下。
终端执行记录:
bash
[root@vm ~]# docker exec -it trino trino
trino> select count(*) from tpch.sf1.nation;
_col0
-------
25
(1 row)
Query 20251218_064225_00000_n3t98, FINISHED, 1 node
Splits: 9 total, 9 done (100.00%)
1.80 [25 rows, 172B] [13 rows/s, 96B/s]
trino> 看到 _col0 返回了数据,说明 Trino 服务已经正常运行在 8080 端口了。
三、 DBeaver 可视化连接
命令行虽然酷,但在日常开发中,使用 DBeaver 连接查看数据更加直观。
连接配置步骤
- 新建连接 :在 DBeaver 中选择 Trino 驱动。
- 主机 (Host):填写服务器 IP。
- 端口 (Port) :
8080。 - 数据库 (Database/Schema) :
tpch(请填tpch这个内置测试库)。 - 用户名 (Username) :
admin(或者任意非空字符串)。 - 密码 (Password) :留空 (默认容器未配置密码验证,所以不要填)。
配置截图参考:
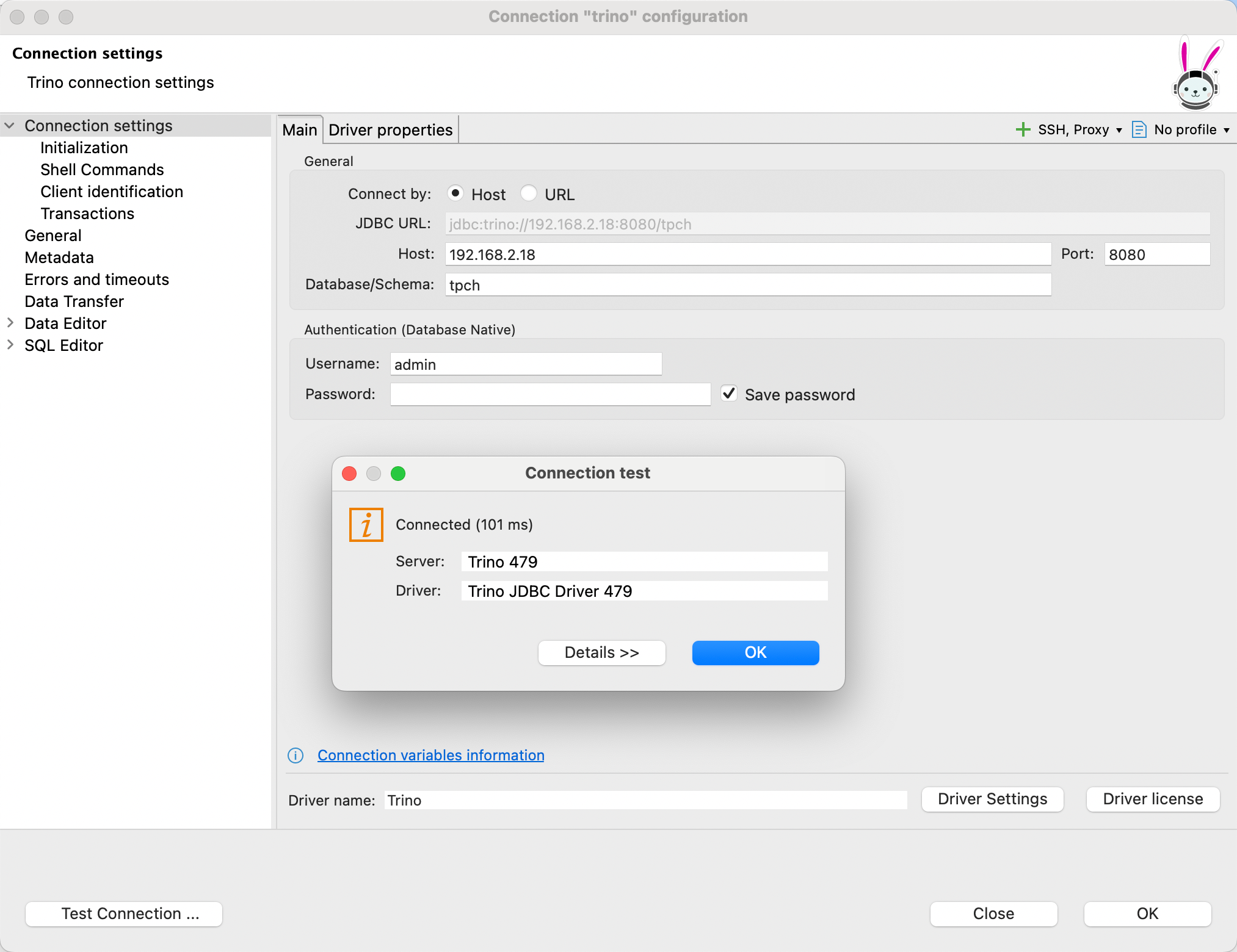
点击 Test Connection,如果配置正确,你会看到连接成功的提示。
四、 常用查询实战
连接成功后,我们可以使用以下 SQL 语句来探索 Trino 的数据结构。Trino 的层级结构为:Catalog (数据源) -> Schema (模式) -> Table (表)。
1. 查看所有数据源 (Catalog)
查看当前 Trino 连接了哪些外部数据源(如 system, memory, tpch 等)。
sql
SHOW CATALOGS;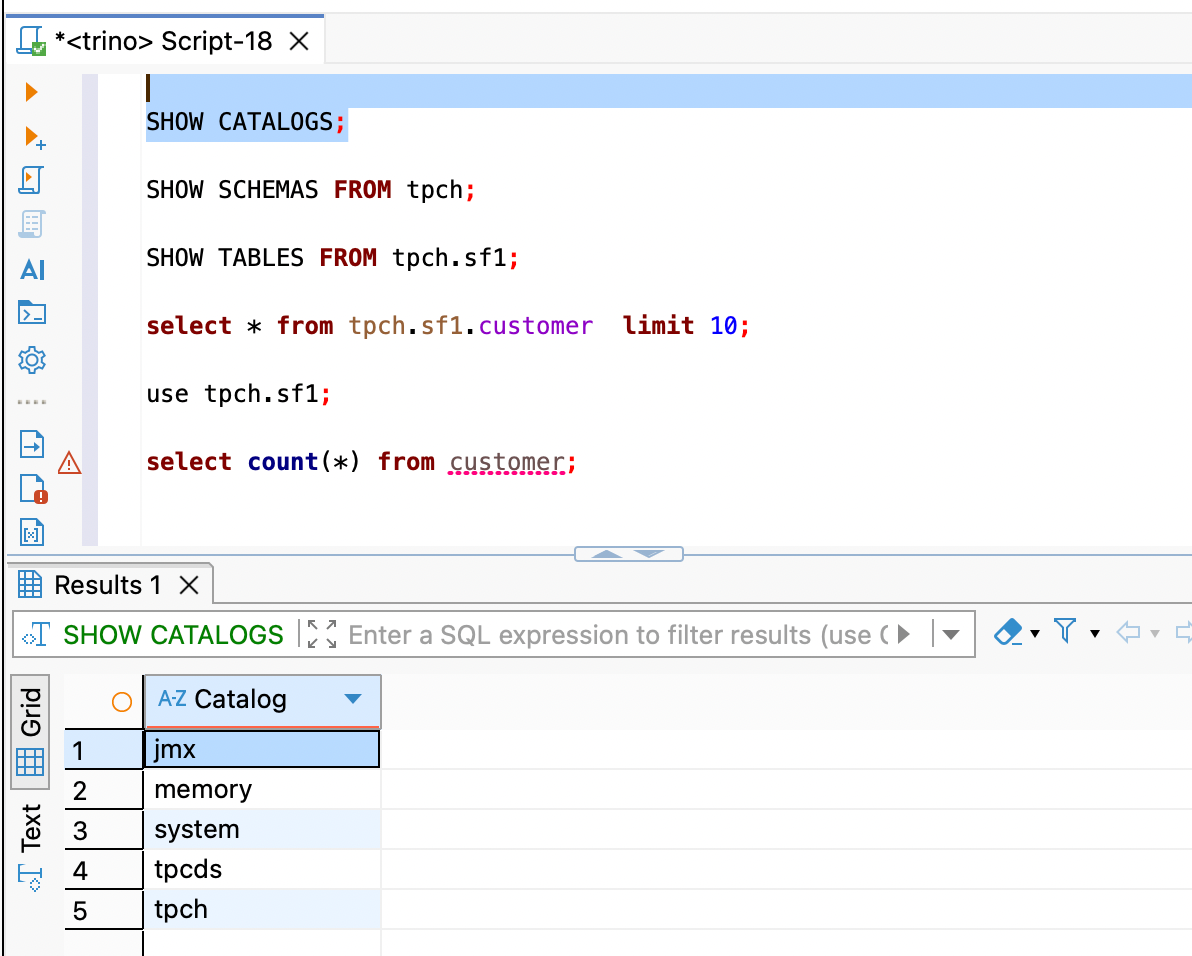
2. 查看模式 (Schema)
查看 tpch 数据源下有哪些模式(通常 sf1 代表 scale factor 1,即小规模测试集)。
sql
SHOW SCHEMAS FROM tpch;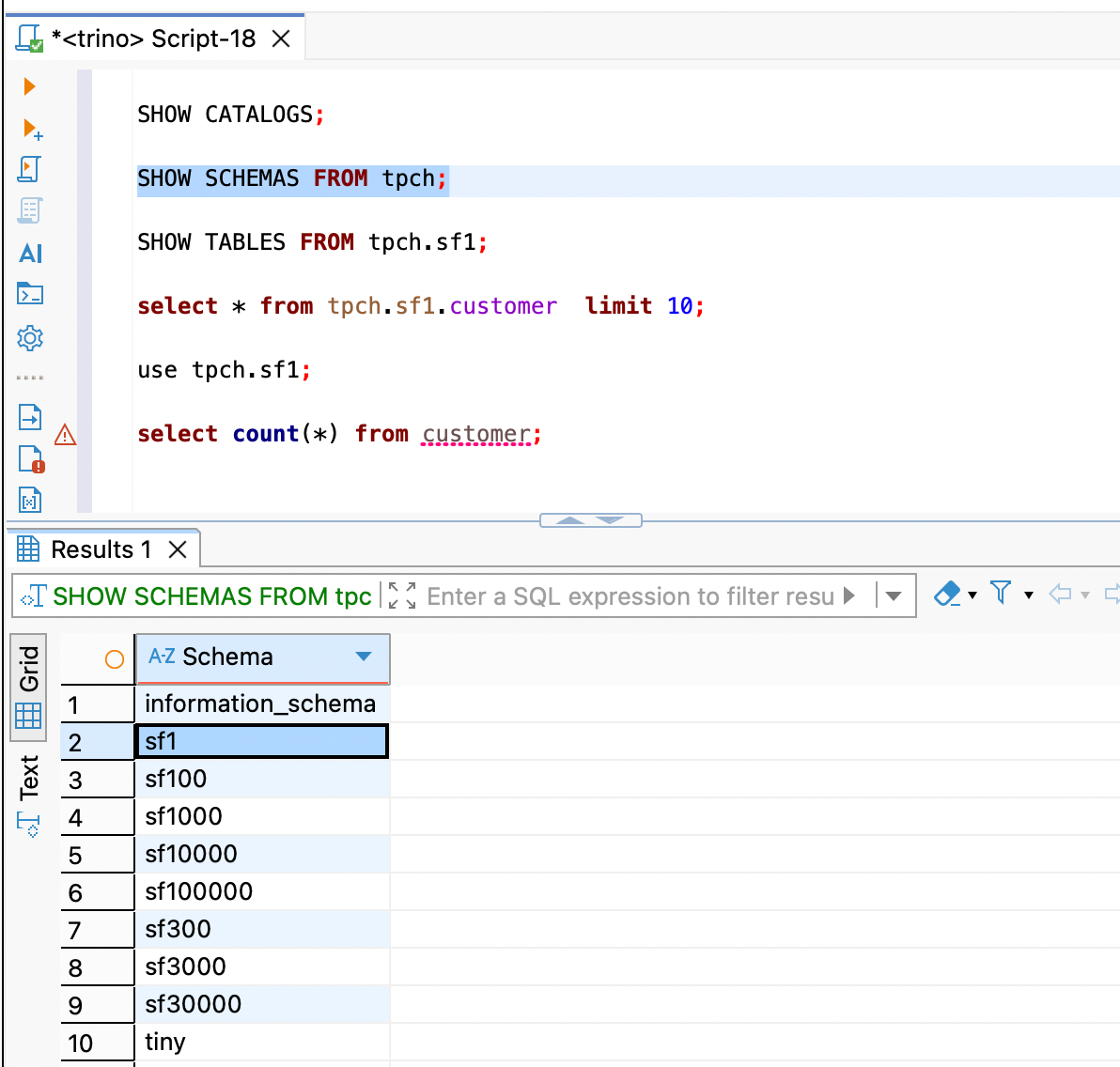
4. 查看表 (Table)
查看 tpch 数据源 sf1 模式下具体有哪些表。
sql
SHOW TABLES FROM tpch.sf1;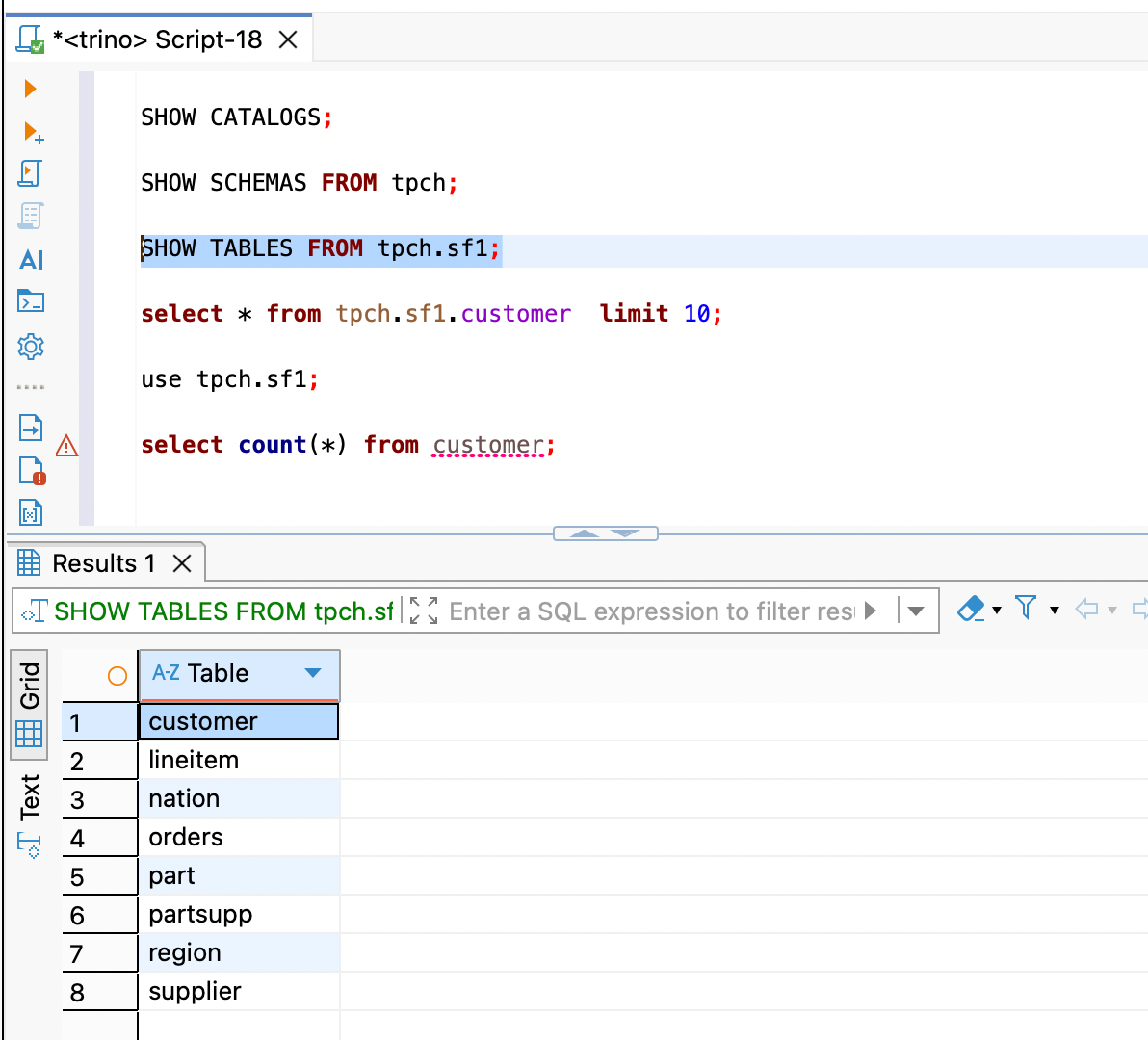
5. 预览数据
查询 customer 表的前 10 条数据。
sql
select * from tpch.sf1.customer limit 10;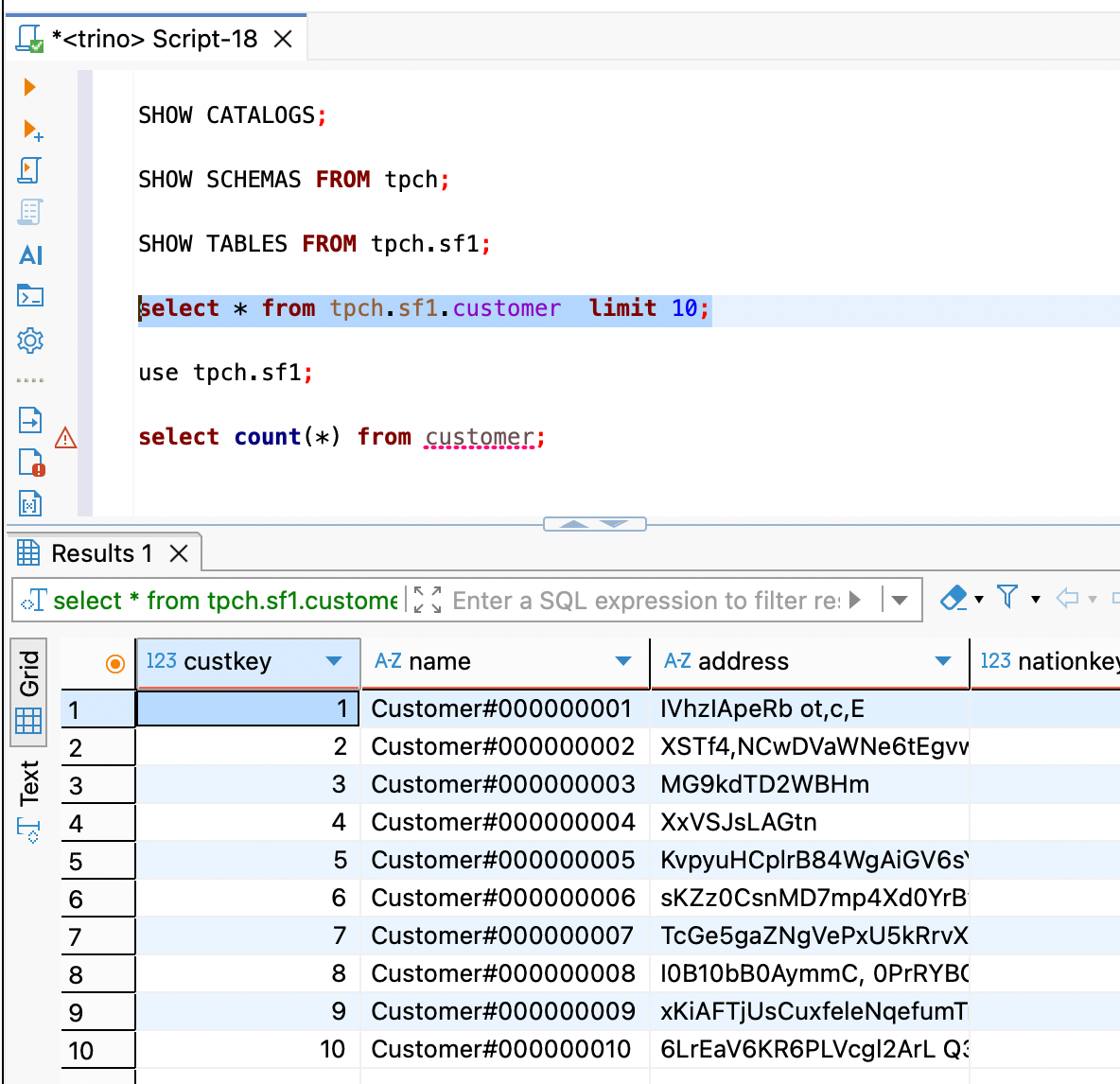
6. 切换当前上下文
如果你不想每次都写 tpch.sf1.xxx 这么长的前缀,可以使用 USE 命令切换当前环境。
sql
use tpch.sf1;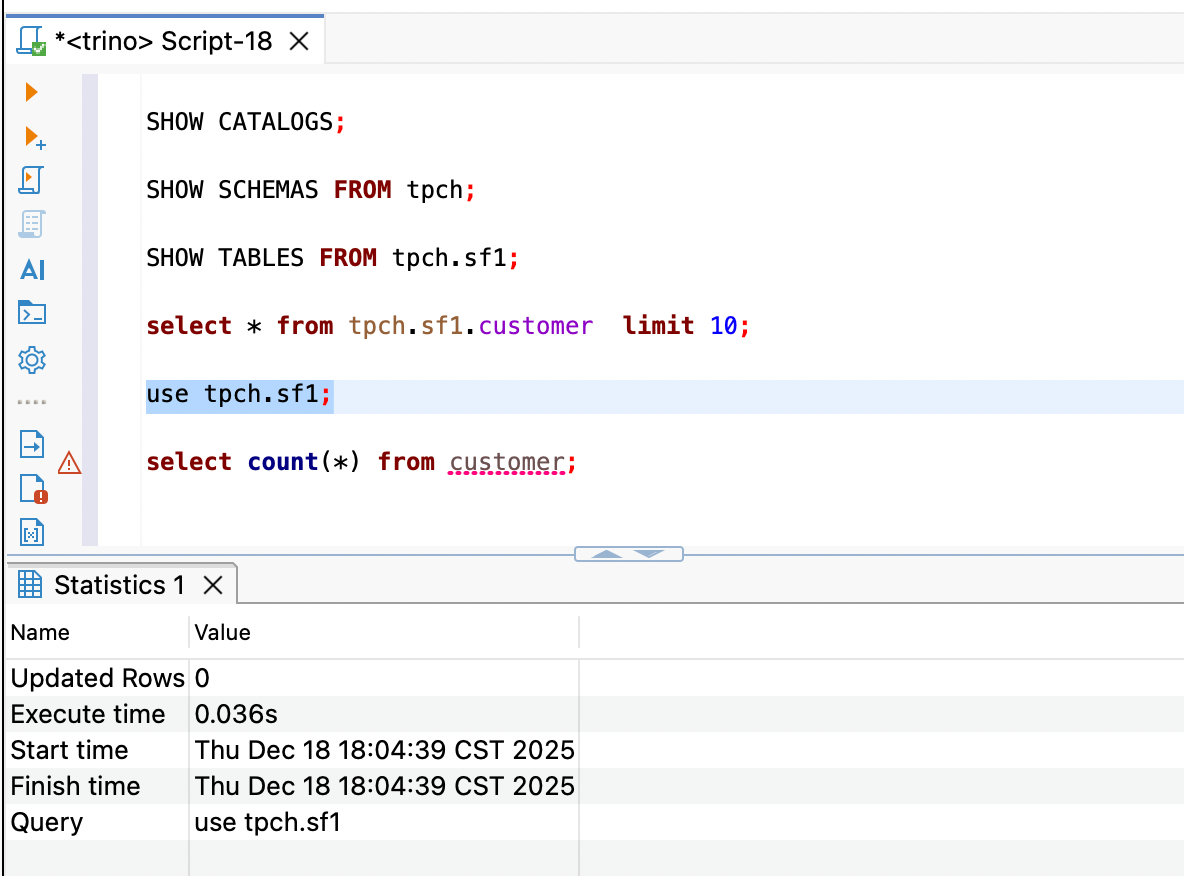
7. 简化查询
切换上下文后,直接查询表名即可。
sql
-- 切换后不再需要写 catalog 和 schema 前缀
select count(*) from customer;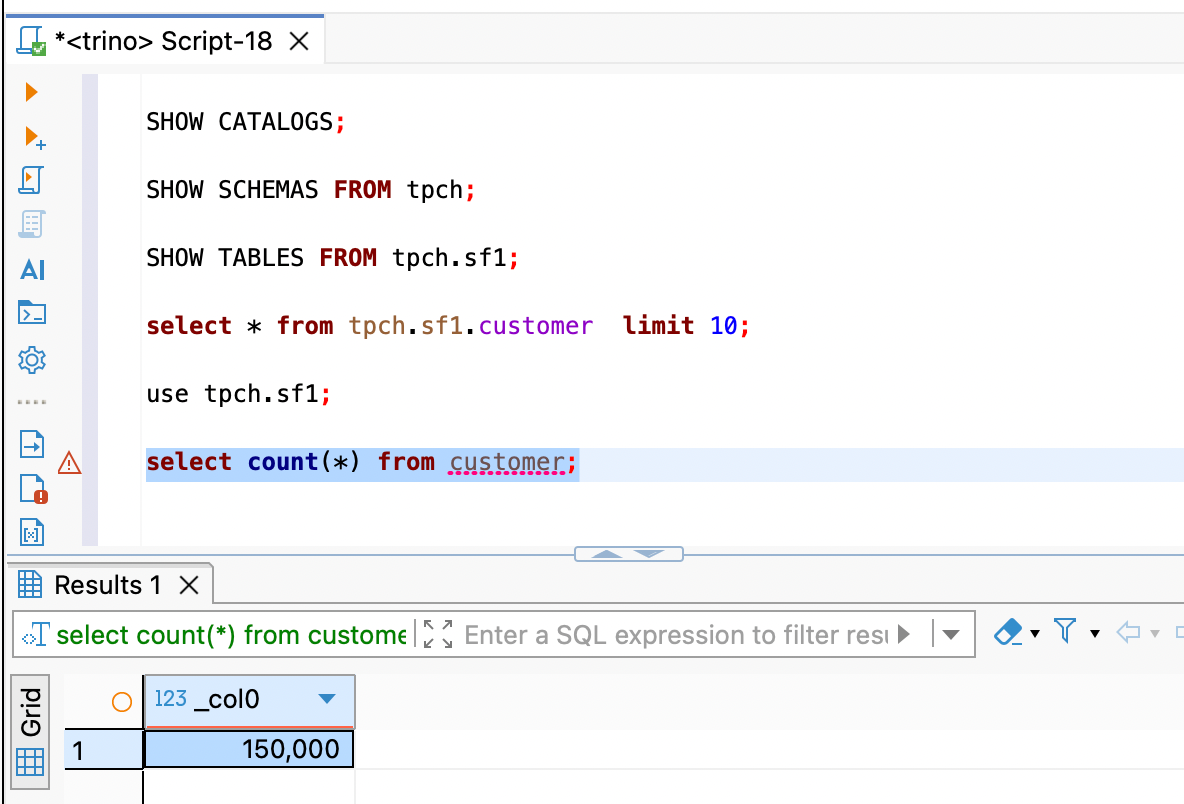
总结
至此,你已经成功运行了 Trino 并通过图形化界面进行了操作。下一步,你可以尝试挂载自定义的配置文件来连接真实的 MySQL 或 Hive 数据源,体验真正的"联邦查询"威力。