京东手机评论爬取经验总结
目录
- 一、项目概述
- 二、遇到的主要问题
- [1. 403 Forbidden错误:反爬机制拦截](#1. 403 Forbidden错误:反爬机制拦截)
- [2. 评论动态加载:无法直接从HTML提取](#2. 评论动态加载:无法直接从HTML提取)
- [3. 反爬机制:自动化工具检测](#3. 反爬机制:自动化工具检测)
- [4. Cookie管理:登录状态维护](#4. Cookie管理:登录状态维护)
- 三、成功的实践经验
- [1. Cookie复用策略](#1. Cookie复用策略)
- [2. 模拟浏览器请求](#2. 模拟浏览器请求)
- [3. 会话管理](#3. 会话管理)
- [4. 分析动态加载:API接口调用](#4. 分析动态加载:API接口调用)
- [5. 随机等待与请求控制](#5. 随机等待与请求控制)
- [6. 页面状态检查](#6. 页面状态检查)
- 四、失败的实践经验
- [1. 直接分析Minified JavaScript](#1. 直接分析Minified JavaScript)
- [2. 未正确设置请求头](#2. 未正确设置请求头)
- [3. 未管理Cookie](#3. 未管理Cookie)
- 五、完整代码实现与分享
京东手机评论爬取经验总结
一、项目概述
本次爬取目标是京东平台上特定手机商品的用户评论数据。由于京东网站采用了严格的反爬机制,且评论数据是通过JavaScript动态加载 的,爬取过程中遇到了多个技术挑战。最终通过合理的策略和技术手段(成功实践Cookie复用策略:Selenium登录 + Requests爬取),成功实现了商品评论的爬取。
二、遇到的主要问题
1. 403 Forbidden错误:反爬机制拦截
- 问题描述:访问京东商品页面时,频繁收到403 Forbidden响应,页面被重定向到京东首页。
- 原因:京东的反爬机制检测到自动化请求行为,包括缺少登录状态、异常的请求头、频繁的请求等。
- 影响:无法获取商品详情页面和评论数据。
2. 评论动态加载:无法直接从HTML提取
- 问题描述:商品页面的评论数据是通过JavaScript动态加载的,直接从HTML源代码中无法获取到完整的评论内容。
- 影响:需要额外的技术手段来获取动态加载的评论数据。
3. 反爬机制:自动化工具检测
- 问题描述 :京东的反爬机制能够检测到Selenium等自动化工具的使用,通过
navigator.webdriver等特征识别自动化脚本。 - 影响:即使使用浏览器自动化工具,也可能被拦截,无法获取正常页面。
4. Cookie管理:登录状态维护
- 问题描述:京东的部分页面和API需要登录状态才能访问,需要正确获取和管理登录Cookie。
- 影响:没有有效的登录Cookie,无法访问商品详情和评论API。
三、成功的实践经验
1. Cookie复用策略
-
实施方式:使用Selenium模拟登录获取Cookie,保存到本地JSON文件,然后使用requests库加载Cookie进行后续爬取。
-
优势:避免频繁登录,提高爬取效率;利用浏览器环境通过登录验证,减少被反爬的风险。
-
关键代码 :
pythondef load_cookies_from_file(cookie_file="jd_cookies.json"): # 从文件中加载cookie并验证有效性 if not file_exists(cookie_file): print(f"[调试] Cookie文件 {cookie_file} 不存在") return None try: with open(cookie_file, "r", encoding="utf-8") as f: cookie_dict = json.load(f) # 验证cookie是否包含必要的登录字段 jd_login_flags = ['pin', 'unick', 'pinId'] has_login_cookie = all(flag in cookie_dict for flag in jd_login_flags) if has_login_cookie: return cookie_dict else: return None except Exception as e: print(f"[错误] 加载cookie文件时出错: {e}") return None
2. 模拟浏览器请求
- 实施方式:设置真实的浏览器请求头,包括User-Agent、Accept、Accept-Language等字段,模拟人类浏览行为。
- 优势:减少被反爬机制识别的风险,提高请求成功率。
3. 会话管理
- 实施方式:使用requests.Session对象管理会话,先访问京东首页建立会话,然后再访问商品页面和评论API。
- 优势:保持会话状态,减少重复的认证过程,提高请求效率。
4. 分析动态加载:API接口调用
-
实施方式:通过浏览器开发者工具分析网络请求,找到评论API接口,直接调用API获取评论数据。
-
优势:绕过复杂的JavaScript分析,直接获取结构化的JSON数据,提高数据获取效率。
-
关键代码 :
pythondef get_product_comments(session, headers, product_id, page=0, page_size=10): # 京东评论API接口(JSON格式) comment_api = f"https://club.jd.com/comment/productPageComments.action?productId={product_id}&score=0&sortType=5&page={page}&pageSize={page_size}" try: response = session.get(comment_api, headers=headers) data = response.json() return data except Exception as e: print(f"[错误] 评论API请求失败: {e}") return None
5. 随机等待与请求控制
- 实施方式:在请求之间添加随机等待时间,控制请求频率,模拟人类浏览行为。
- 优势:避免因请求过于频繁而触发反爬机制,提高爬取稳定性。
6. 页面状态检查
- 实施方式:在获取Cookie和访问页面后,检查页面状态是否正常,避免在异常状态下继续爬取。
- 优势:及时发现问题,减少无效请求,提高爬取效率。
四、失败的实践经验
1. 直接分析Minified JavaScript
- 尝试方式:下载并分析评论相关的JavaScript文件,试图从中找到评论加载的逻辑和API接口。
- 失败原因:JavaScript文件被压缩和混淆,难以直接找到API接口和关键逻辑。
- 教训:对于动态加载的数据,优先通过浏览器开发者工具分析网络请求,而不是直接分析JavaScript代码。
2. 未正确设置请求头
- 尝试方式:最初未设置真实的浏览器请求头,使用默认的requests请求头。
- 失败原因:京东的反爬机制检测到异常的请求头,直接拦截请求。
- 教训:必须设置真实的浏览器请求头,模拟人类浏览行为。
3. 未管理Cookie
- 尝试方式:最初未使用登录Cookie,直接访问商品页面和评论API。
- 失败原因:京东的部分页面和API需要登录状态才能访问,导致403错误。
- 教训:必须正确获取和管理登录Cookie,维护登录状态。
五、完整代码实现与分享
1.首先最好下载一个浏览器驱动(通过python自动下载的驱动不稳定)

这里我使用的是edge浏览器的驱动(一定注意驱动版本和浏览器版本对应,和Selenium库版本兼容)
2.结果展示
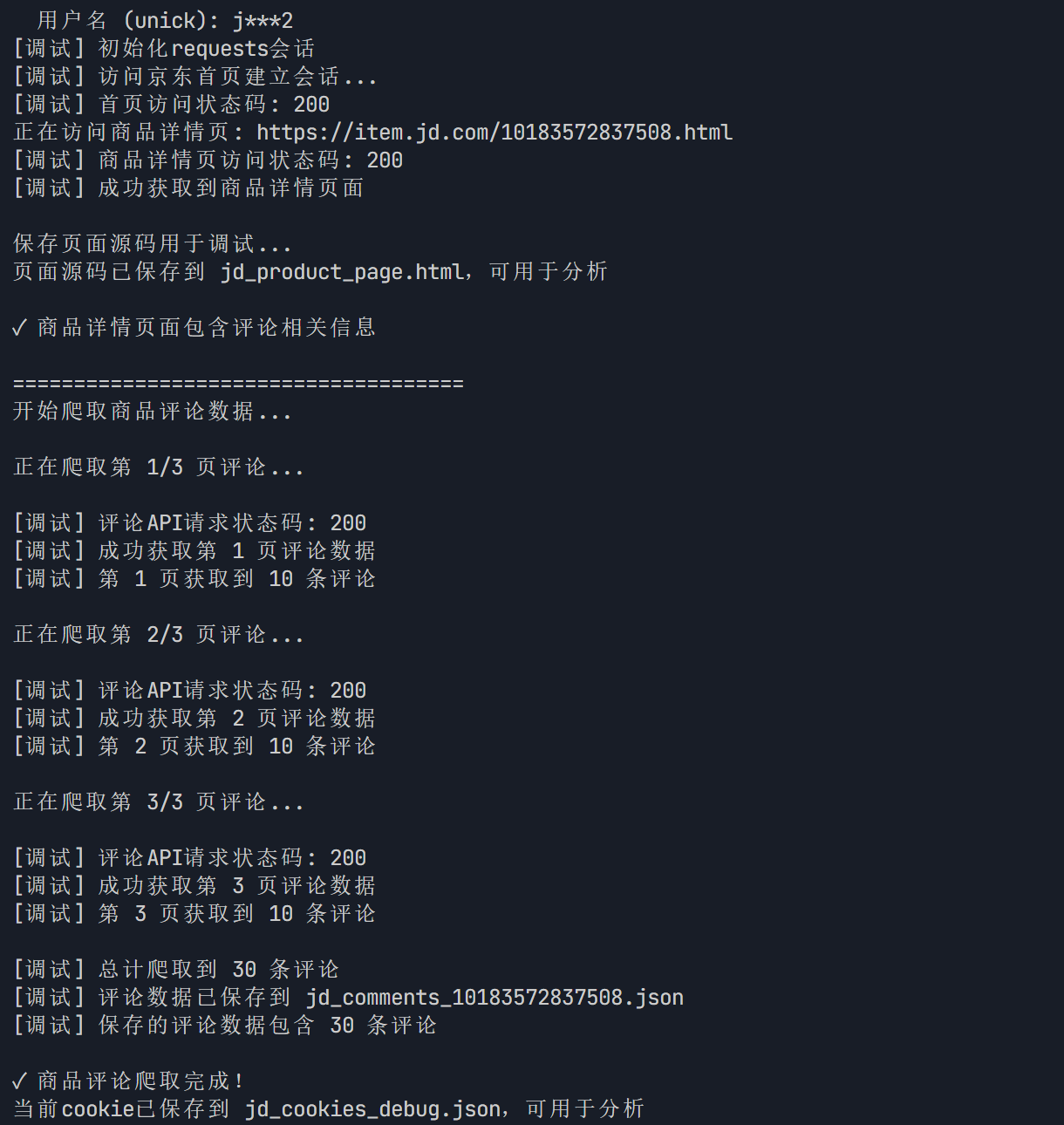
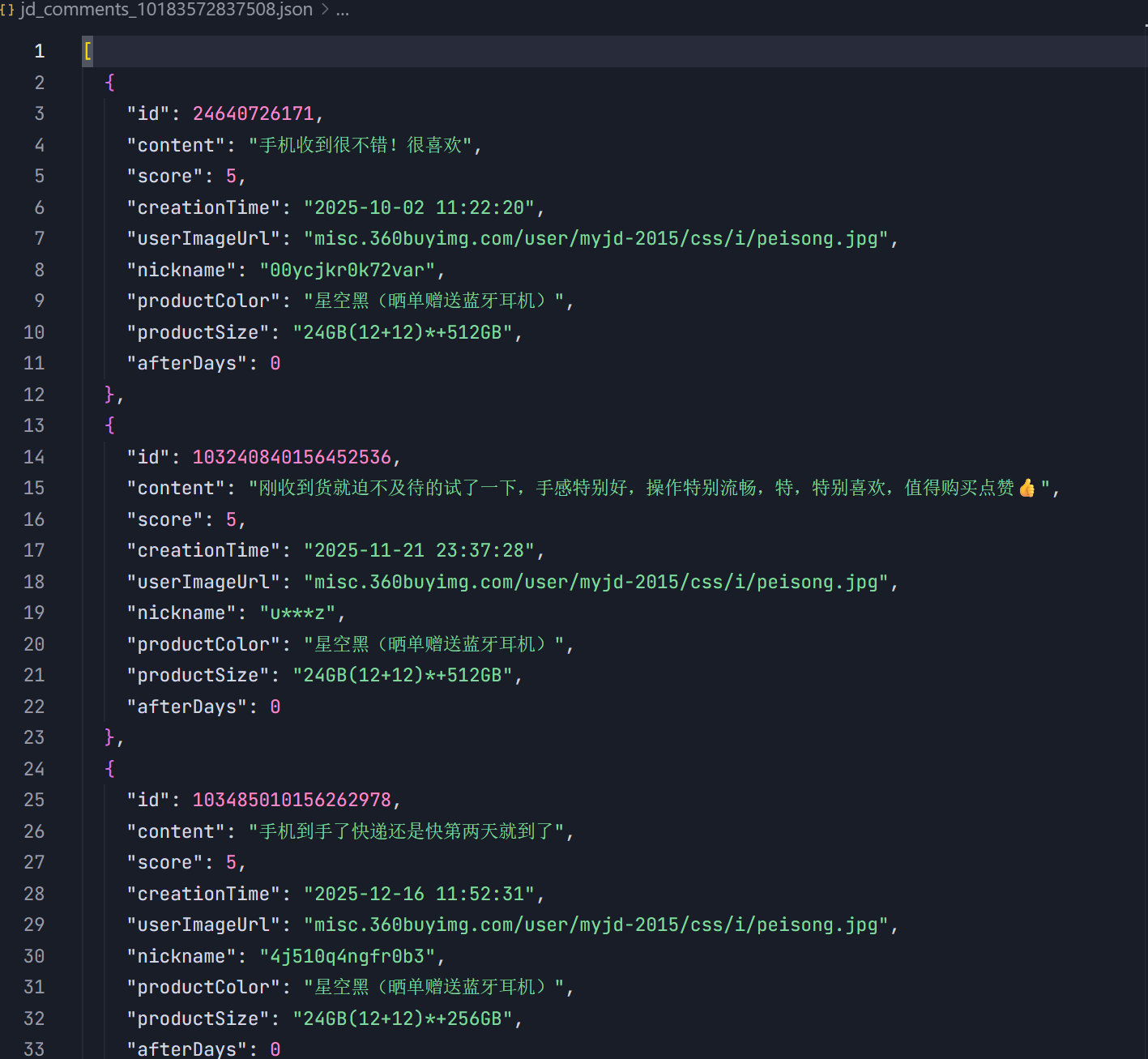
3.源代码
python
from selenium import webdriver
from selenium.webdriver.edge.service import Service
from selenium.webdriver.edge.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import time
import random
import requests
import json
# 检查文件是否存在的函数
import os
def file_exists(file_path):
"""检查文件是否存在"""
return os.path.exists(file_path)
# 加载cookie的函数
def load_cookies_from_file(cookie_file="jd_cookies.json"):
"""从文件中加载cookie并验证有效性"""
if not file_exists(cookie_file):
print(f"[调试] Cookie文件 {cookie_file} 不存在")
return None
try:
with open(cookie_file, "r", encoding="utf-8") as f:
cookie_dict = json.load(f)
print(f"[调试] 从 {cookie_file} 加载了 {len(cookie_dict)} 个cookie")
# 验证cookie是否包含必要的登录字段
jd_login_flags = ['pin', 'unick', 'pinId']
has_login_cookie = all(flag in cookie_dict for flag in jd_login_flags)
if has_login_cookie:
print("[调试] 加载的cookie包含完整登录信息")
# 打印脱敏的登录信息
pin_value = cookie_dict.get('pin', '')
unick_value = cookie_dict.get('unick', '')
print(f" 用户ID (pin): {pin_value[:2]}***{pin_value[-2:] if len(pin_value) > 4 else ''}")
print(f" 用户名 (unick): {unick_value[:1]}***{unick_value[-1:] if len(unick_value) > 2 else ''}")
return cookie_dict
else:
# 检查缺失的字段
missing_cookies = [flag for flag in jd_login_flags if flag not in cookie_dict]
print(f"[警告] 加载的cookie不完整,缺少字段: {missing_cookies}")
return None
except Exception as e:
print(f"[错误] 加载cookie文件时出错: {e}")
return None
# 页面状态检查函数
def check_page_status(driver, max_retries=3):
"""检查页面状态并处理403等异常页面"""
retry_count = 0
while retry_count < max_retries:
current_url = driver.current_url
# 检查是否是403页面
if "403" in current_url or "forbidden" in current_url.lower():
retry_count += 1
print(f"[调试] 第 {retry_count} 次检测到403页面: {current_url}")
if retry_count < max_retries:
print(f"[调试] 尝试重新访问京东首页 ({retry_count}/{max_retries-1})...")
driver.get("https://www.jd.com")
time.sleep(5)
continue
else:
print(f"[调试] 已尝试 {max_retries} 次,仍然是403页面,请手动处理。")
return False
# 检查是否是京东正常页面
elif "jd.com" in current_url:
# 检查页面标题
page_title = driver.title
if "京东" in page_title:
print(f"[调试] 页面状态正常,当前URL: {current_url}")
print(f"[调试] 页面标题: {page_title}")
return True
else:
retry_count += 1
print(f"[调试] 第 {retry_count} 次检测到异常页面标题: {page_title}")
print(f"[调试] 当前URL: {current_url}")
if retry_count < max_retries:
print(f"[调试] 尝试重新访问京东首页 ({retry_count}/{max_retries-1})...")
driver.get("https://www.jd.com")
time.sleep(5)
continue
else:
print(f"[调试] 已尝试 {max_retries} 次,页面标题仍异常,请手动处理。")
return False
else:
retry_count += 1
print(f"[调试] 第 {retry_count} 次检测到非京东页面: {current_url}")
if retry_count < max_retries:
print(f"[调试] 尝试重新访问京东首页 ({retry_count}/{max_retries-1})...")
driver.get("https://www.jd.com")
time.sleep(5)
continue
else:
print(f"[调试] 已尝试 {max_retries} 次,仍在非京东页面,请手动处理。")
return False
return False
# 配置Edge浏览器,添加更多反反爬虫设置
edge_options = Options()
edge_options.add_argument("--disable-gpu")
edge_options.add_argument("--no-sandbox")
# 模拟真实浏览器,减少自动化特征
edge_options.add_argument("--disable-blink-features=AutomationControlled")
edge_options.add_argument("--disable-extensions")
edge_options.add_argument("--start-maximized")
# 设置用户代理
edge_options.add_argument("user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Safari/537.36 Edg/143.0.0.0")
# 禁用自动化扩展
edge_options.add_experimental_option("excludeSwitches", ["enable-automation"])
edge_options.add_experimental_option('useAutomationExtension', False)
# 首先尝试加载已保存的cookie
cookie_dict = load_cookies_from_file()
# 如果没有有效的cookie,则使用Selenium登录获取新的cookie
if not cookie_dict:
print("[调试] 没有有效cookie,将启动浏览器获取新的登录cookie...")
# 初始化WebDriver
driver_path = "d:\developcode\pythonCode\paQuJD\msedgedriver.exe"
service = Service(driver_path)
driver = webdriver.Edge(service=service, options=edge_options)
try:
# 打开京东首页
driver.get("https://www.jd.com")
# 添加提示信息,让用户在浏览器中完成登录
print("请在打开的浏览器中完成京东账号登录操作...")
print("登录完成后,请手动刷新页面或保持在京东页面上")
print("注意:如果登录后跳转到403页面,这是京东的反爬机制,请尝试手动重新访问京东首页")
# 添加较长的等待时间(60秒),让用户有足够时间登录
login_wait_time = 60
print(f"等待 {login_wait_time} 秒供您完成登录...")
time.sleep(login_wait_time)
# 检查当前页面状态,确保在获取cookie前页面正常
if not check_page_status(driver):
print("页面状态异常,无法获取有效cookie")
exit(1)
# 手动刷新页面,确保获取最新的cookie
print("刷新页面以获取最新的cookie...")
driver.refresh()
time.sleep(3)
# 再次检查页面状态
if not check_page_status(driver):
print("刷新页面后状态异常,无法获取有效cookie")
exit(1)
# 获取cookie
cookies = driver.get_cookies()
# 转换cookie为requests可用的格式
cookie_dict = {cookie['name']: cookie['value'] for cookie in cookies}
# 打印当前页面URL,方便调试
print(f"[调试] 登录后当前页面URL: {driver.current_url}")
print(f"[调试] 成功获取 {len(cookies)} 个cookie")
# 打印所有获取到的cookie名称,用于调试
cookie_names = [cookie['name'] for cookie in cookies]
print(f"[调试] 获取到的cookie名称: {cookie_names}")
# 检测是否为登录态cookie(根据京东cookie特征判断)
# 从实际获取的cookie来看,京东登录态必须包含pin, unick, pinId等字段
# 只检查京东登录后特有的cookie字段,避免误判
jd_login_flags = ['pin', 'unick', 'pinId']
has_login_cookie = all(flag in cookie_dict for flag in jd_login_flags)
# 检查是否有部分登录字段
has_partial_login = any(flag in cookie_dict for flag in jd_login_flags)
print(f"[调试] 登录态检查: pin={'pin' in cookie_dict}, unick={'unick' in cookie_dict}, pinId={'pinId' in cookie_dict}")
if has_login_cookie:
print("[调试] 成功获取完整登录态cookie")
# 打印登录相关cookie信息(脱敏显示)
print("[调试] 登录用户信息:")
pin_value = cookie_dict.get('pin', '')
unick_value = cookie_dict.get('unick', '')
print(f" 用户ID (pin): {pin_value[:2]}***{pin_value[-2:] if len(pin_value) > 4 else ''}")
print(f" 用户名 (unick): {unick_value[:1]}***{unick_value[-1:] if len(unick_value) > 2 else ''}")
# 保存cookie到文件
cookie_file = "jd_cookies.json"
with open(cookie_file, "w", encoding="utf-8") as f:
json.dump(cookie_dict, f, ensure_ascii=False, indent=2)
print(f"[调试] Cookie已成功保存到 {cookie_file} 文件")
else:
# 显示缺少的登录cookie字段
missing_cookies = [flag for flag in jd_login_flags if flag not in cookie_dict]
print(f"[警告] 未获取到完整登录态cookie,缺少以下必要字段:{missing_cookies}")
if has_partial_login:
print("[调试] 获取到部分登录字段:")
for flag in jd_login_flags:
if flag in cookie_dict:
value = cookie_dict[flag]
# 脱敏显示
masked_value = value[:2] + "***" + (value[-2:] if len(value) > 4 else '')
print(f" {flag}: {masked_value}")
print("[提示] 请确保已在浏览器中完成完整登录操作!")
print("[提示] 可能的原因:")
print("[提示] 1. 登录过程中跳转到了403页面")
print("[提示] 2. 登录后没有保持在京东页面上")
print("[提示] 3. 京东的反爬机制限制了cookie获取")
print("[提示] 脚本将终止执行")
exit(1)
# 关闭Selenium浏览器,因为我们已经获取到了有效的cookie
driver.quit()
except Exception as e:
print(f"[错误] 在获取cookie过程中发生异常: {e}")
import traceback
traceback.print_exc()
if 'driver' in locals():
driver.quit()
exit(1)
# 初始化requests会话
print("[调试] 初始化requests会话")
session = requests.Session()
# 设置请求头
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8",
"Accept-Encoding": "gzip, deflate, br",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1",
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "none",
"Sec-Fetch-User": "?1",
}
# 设置cookie到session
for name, value in cookie_dict.items():
session.cookies.set(name, value)
product_id = "10183572837508"
product_url = f"https://item.jd.com/{product_id}.html"
# 先访问京东首页建立会话
print("[调试] 访问京东首页建立会话...")
home_response = session.get("https://www.jd.com", headers=headers)
print(f"[调试] 首页访问状态码: {home_response.status_code}")
time.sleep(2)
# 访问商品详情页
print(f"正在访问商品详情页: {product_url}")
response = session.get(product_url, headers=headers)
print(f"[调试] 商品详情页访问状态码: {response.status_code}")
# 检查是否是403页面
if response.status_code == 403:
print("[错误] 商品详情页访问被403禁止,可能是cookie失效或被检测到爬虫行为")
print("[提示] 建议删除jd_cookies.json文件并重新运行脚本获取新的cookie")
exit(1)
# 检查页面是否包含商品信息
if "商品详情" in response.text or "商品介绍" in response.text:
print("[调试] 成功获取到商品详情页面")
else:
print("[警告] 商品详情页面可能不完整,建议检查")
# 随机等待,模拟人工行为
time.sleep(random.randint(2, 5))
# 保存页面源码用于调试
print("\n保存页面源码用于调试...")
with open("jd_product_page.html", "w", encoding="utf-8") as f:
f.write(response.text)
print("页面源码已保存到 jd_product_page.html,可用于分析")
# 检查页面是否包含评论相关信息
if "商品评价" in response.text or "comment" in response.text.lower():
print("\n✓ 商品详情页面包含评论相关信息")
else:
print("\n✗ 商品详情页面可能不包含评论相关信息,或格式已变化")
# 定义评论API请求和解析函数
def get_product_comments(session, headers, product_id, page=0, page_size=10):
"""
获取商品评论数据
:param session: requests会话对象
:param headers: 请求头
:param product_id: 商品ID
:param page: 页码(从0开始)
:param page_size: 每页评论数
:return: 评论数据字典
"""
# 京东评论API接口(JSON格式)
comment_api = f"https://club.jd.com/comment/productPageComments.action?productId={product_id}&score=0&sortType=5&page={page}&pageSize={page_size}"
try:
response = session.get(comment_api, headers=headers)
print(f"\n[调试] 评论API请求状态码: {response.status_code}")
# 尝试解析JSON
data = response.json()
print(f"[调试] 成功获取第 {page+1} 页评论数据")
return data
except json.JSONDecodeError as e:
print(f"[错误] 评论数据JSON解析失败: {e}")
return None
except Exception as e:
print(f"[错误] 评论API请求失败: {e}")
return None
# 爬取商品评论
def crawl_product_comments(session, headers, product_id, max_pages=5):
"""
爬取商品的多页评论
:param session: requests会话对象
:param headers: 请求头
:param product_id: 商品ID
:param max_pages: 最大爬取页数
:return: 所有评论数据列表
"""
all_comments = []
for page in range(max_pages):
print(f"\n正在爬取第 {page+1}/{max_pages} 页评论...")
# 获取当前页评论
comment_data = get_product_comments(session, headers, product_id, page=page)
if not comment_data:
print(f"[警告] 无法获取第 {page+1} 页评论数据")
continue
# 检查是否有评论数据
if "comments" in comment_data and comment_data["comments"]:
comments = comment_data["comments"]
print(f"[调试] 第 {page+1} 页获取到 {len(comments)} 条评论")
# 将当前页评论添加到总列表
all_comments.extend(comments)
# 随机等待,避免触发反爬
time.sleep(random.randint(2, 5))
else:
print(f"[调试] 第 {page+1} 页没有评论数据或已达到评论末尾")
break
print(f"\n[调试] 总计爬取到 {len(all_comments)} 条评论")
return all_comments
# 保存评论数据到JSON文件
def save_comments_to_file(comments, product_id, filename=None):
"""
保存评论数据到JSON文件
:param comments: 评论数据列表
:param product_id: 商品ID
:param filename: 保存文件名,默认自动生成
"""
if not filename:
filename = f"jd_comments_{product_id}.json"
# 简化评论数据,只保存关键信息
simplified_comments = []
for comment in comments:
simplified_comment = {
"id": comment.get("id"),
"content": comment.get("content"),
"score": comment.get("score"),
"creationTime": comment.get("creationTime"),
"userImageUrl": comment.get("userImageUrl"),
"nickname": comment.get("nickname"),
"productColor": comment.get("productColor"),
"productSize": comment.get("productSize"),
"afterDays": comment.get("afterDays")
}
simplified_comments.append(simplified_comment)
try:
with open(filename, "w", encoding="utf-8") as f:
json.dump(simplified_comments, f, ensure_ascii=False, indent=2)
print(f"[调试] 评论数据已保存到 {filename}")
print(f"[调试] 保存的评论数据包含 {len(simplified_comments)} 条评论")
except Exception as e:
print(f"[错误] 保存评论数据失败: {e}")
# 执行评论爬取
print("\n=====================================")
print("开始爬取商品评论数据...")
# 爬取评论
comments = crawl_product_comments(session, headers, product_id, max_pages=3) # 爬取前3页评论
# 保存评论数据
if comments:
save_comments_to_file(comments, product_id)
print("\n✓ 商品评论爬取完成!")
else:
print("\n✗ 未获取到任何评论数据!")
# 保存当前所有cookie用于调试(可选)
with open("jd_cookies_debug.json", "w", encoding="utf-8") as f:
json.dump(cookie_dict, f, ensure_ascii=False, indent=2)
print("当前cookie已保存到 jd_cookies_debug.json,可用分析")初此实现python爬虫,有不足之处还望各位多多指点。