文章目录
开始
在深入理解Groovy已经介绍了一下Groovy最重要的内容。
本来不打算单独写Groovy基本内容的,但是写Jmeter脚本的内容补充说明Groovy的东西,发现东西还比较多,就单独拿出来讲讲。
这里只是选择了最常用的内容简单说明,主要就是为了快速上手,能编写简单的脚本,想要深入理解,请看:官方文档
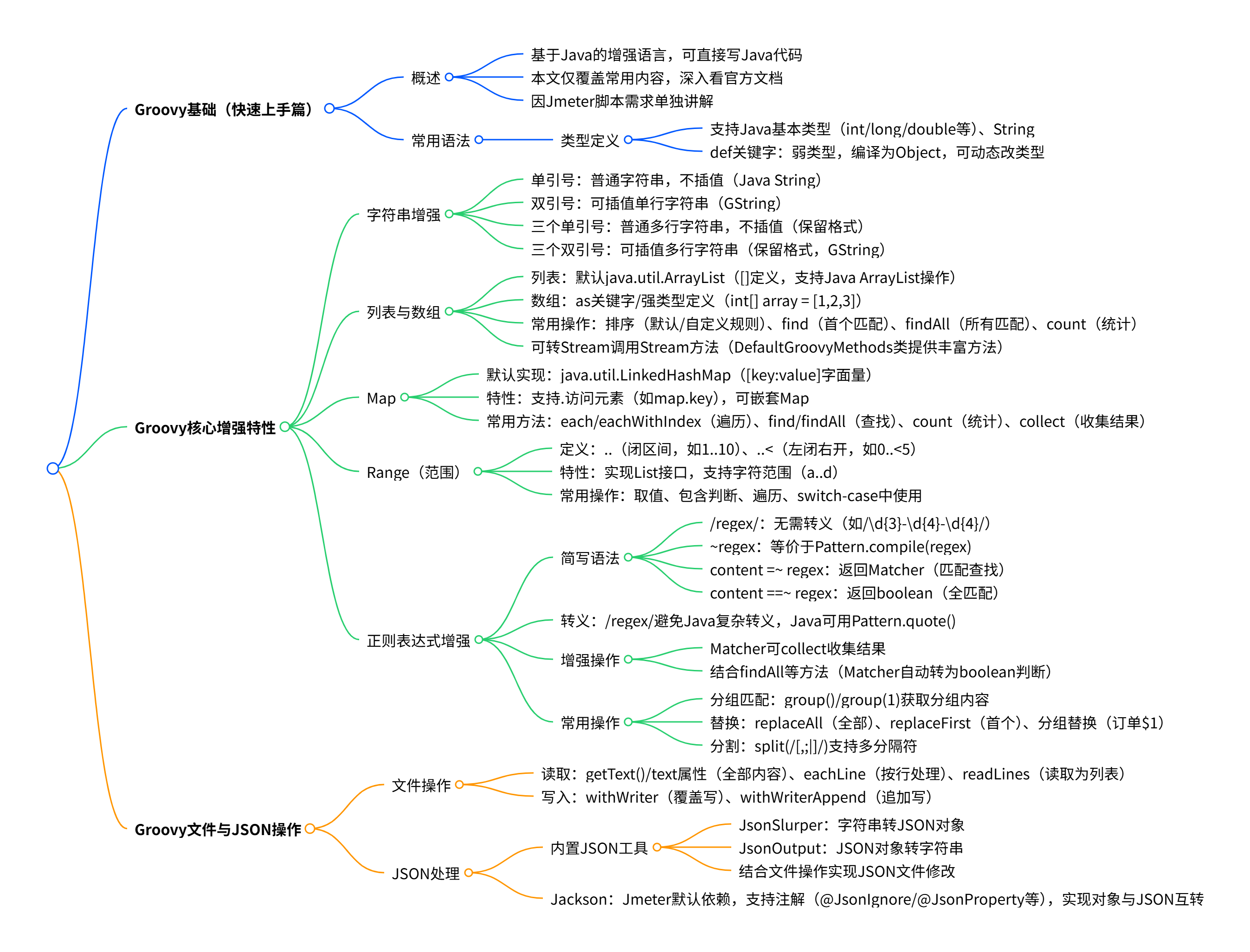
常用语法
Groovy只是对Java的增强,当Java代码来写就可以。
增强了什么呢?
答案是脚本化,例如,可以像java一样指定类型,例如:
- int
- long
- double
- float
- boolean
- byte
- char
- String
也可以使用通通使用def关键字。
groovy
// 指定类型
int a = 10
println a
// 弱类型定义,使用def关键字,自动判断b是什么类型
def b = 5
println b
// b变成了字符串类型
b = 'abc'
println(b)
// a就不能改变类型
// a = 'abc'为什么def类型可以改变类型呢?
因为Groovy将他们通通编译为Object类型了。
字符串增强
Groovy中的字符串有下面几种:
- 单引号:普通字符串,不插值,对应java中的String类型。
- 双引号:可插值字符串,单行,GString类型,Groovy自己实现的org.codehaus.groovy.runtime.GStringImpl
- 三个单引号:普通多行字符串,不插值,对应java中的String类型,多行,保留字符串中的格式:换行和缩进
- 三个双引号:可插值多行字符串,插值,GString类型,多行,保留字符串中的格式:包括换行和缩进
Groovy
def name = 'tim'
println("单引号-----")
println(name)
// hello tim
def hello = "hello $name"
println("双引号-----")
println(hello)
// $name会原样输出
def content = '''
line one
\n
line two
$name
'''
println("3个单引号-----")
println(content)
// 会计算${name.toUpperCase()}!表达式
def lines = """
line one
\n
line two
${name.toUpperCase()}!
"""
println("3个双引号-----")
println(lines)列表与数组
class java.util.ArrayList
Groovy
// Java的定义方式
def listA = new ArrayList()
println listA.class
//定义一个空的列表,直接可以当Java的ArrayList用
def listB = []
println listB.class
//定义一个非空的列表
def listC = [1,2,3,4]
println listC.class注意上面的不是数组,数组是下面这样的:
Groovy
// 使用as关键字定义数组
def arrayA = [1,2,3,4] as int[]
println arrayA.class
// 使用强类型的定义方式
int[] arrayB = [1,2,3]
println arrayB.class对于列表和数组的操作,你能想到的基本都能直接用,Groovy基本都实现了,都在DefaultGroovyMethods类中。
如果觉得Groovy给的不够,还可以通过stream方法转为Stream,然后调用stream的各种方法。
groovy
def lista = [-7,5,-3,9,4,0]
// 排序
lista.sort()
println lista
def listb = [-7,5,-3,9,4,0]
// 自定义排序规则,按绝对值大小排序
listb.sort {
a,b -> a == b ? 0 : Math.abs(a) < Math.abs(b) ? 1 : -1
}
println list
def stringList = ['a','abc','hello','groovy']
// 按照字符串的长度大小排序
stringList.sort {
it -> return it.size()
}
println stringList
// 使用find查找列表中的第一个偶数
def list = [-7,5,-3,9,4,0,6]
int result = list.find {
temp -> return temp % 2 == 0
}
println result
// 使用findAll查找列表中所有小于0的数
def list = [-7,5,-3,9,4,0,6]
def result = list.findAll {
temp -> return temp < 0
}
println result
// 使用count统计列表中偶数的个数
def list = [-7,5,-3,9,4,0,6]
int number = list.count {
return it % 2 == 0
}
println numberMap
Groovy的Map字面量比较奇怪,看起来是数组,但是是列表,使用的是java.util.Map,实现类默认使用的是java.util.LinkedHashMap
但是Groovy提供了一个像JavaScript的操作,可以直接点(.)来访问Map的元素。
groovy
def persons = [tom: '北京', tim: '上海', allen: '成都']
//class java.util.LinkedHashMap
println(persons.getClass())
// 北京
println persons['tom']
//上海
println persons.get('tim')
//null
println persons.wendy
// 成都
println persons.allen
// 添加元素
persons.bob = '重庆'
//[tom:北京, tim:上海, allen:成都, bob:重庆]
println persons
persons.complex = [a: 1, b: 2]
//[tom:北京, tim:上海, allen:成都, bob:重庆, complex:[a:1, b:2]]
println personsMap的方法:
groovy
def students = ['tom':20,'tim':25,'allen':60,'bob':30]
// 使用对象
students.each {
def student -> println "key is:" + student.key + " value is:" + student.value
}
// 带索引
students.eachWithIndex { def student, int index ->
println "key=${student.key} value=${student.value} index=${index}"
}
// 使用key value参数
students.each {
key, value -> println "key=${key},value=${value}"
}
// 查找第一个
def result = students.find {
student -> return student.value > 60
}
// 查找所有
def result = students.findAll {
student -> return student.value > 60
}
// 统计
def number = students.count {
student -> student.value > 60
}
// 查找名字
def names = students.findAll {
student -> student.value > 60
}.collect {
return it.key
}range
Groovy提供了一个像Python一样的range操作(...)
groovy
// 范围的定义[0,10]
def range = 1..10
//第一个元素的值
println range[0]
//是否包含7
println range.contains(7)
//范围的起始值
println range.from
//范围的结束值
println range.to
println (0..5).collect() == [0, 1, 2, 3, 4, 5]
// 相当于左闭右开区间[0,5)
println (0..<5).collect() == [0, 1, 2, 3, 4]
// Range实际上是List接口的实现
println (0..5) instanceof List
println (0..5).size() == 6
//也可以是字符类型
println ('a'..'d').collect() == ['a','b','c','d']
for (x in 1..10) {
println x
}
('a'..'z').each {
println it
}
def age = 25;
switch (age) {
case 0..17:
println '未成年'
break
case 18..30:
println '青年'
break
case 31..50:
println '中年'
break
default:
println '老年'
}正则表达式增强
Groovy的正则简写
groovy添加了对正则表达式的快捷操作:
- //类似于JavaScript的正则方式,/正则表达式/可以不用转义
- ~regexString:等价于Pattern.compile(regexString)
- content =~ regexString : 等价于Pattern pattern = Pattern.compile(regexString);Matcher matcher = pattern.matcher(content);
- content ==~ regexString : 等价于Pattern pattern = Pattern.compile(regexString);Matcher matcher = pattern.matcher(content);boolean matches = matcher.matches();
groovy
// regexString只是一个普通字符串,使用//是可以不用转义
def regexString = /\d{3}-\d{4}-\d{4}/
//class java.lang.String
println(regexString.getClass())
// 使用~相当于对字符串执行了Pattern.compile()操作,返回的是一个Pattern对象
def p2 = ~'he*llo'
// 相当于Java中执行了:Pattern.compile("he*llo")
//class java.util.regex.Pattern
println(p2.getClass())
def str = "手机号是:138-1234-5678"
// str =~ regexString 相当于 pattern.matcher(str)
def matcher = str =~ /\d{3}-\d{4}-\d{4}/
// 相当于Java中执行了下面2步
//Pattern pattern = Pattern.compile("\\d{3}-\\d{4}-\\d{4}");
//Matcher matcher = pattern.matcher("手机号是:138-1234-5678");
//class java.util.regex.Matcher
println(matcher.getClass())
def result = "hello" ==~ "he*llo"
// 相当于Java中执行了下面3步
//Pattern pattern = Pattern.compile("he*llo");
//Matcher matcher = pattern.matcher("hello");
//boolean matches = matcher.matches();
//class java.lang.Boolean
println result.getClass()
print result正则转义
/regex/是一个很棒的设计,可以避免转义的问题,转义问题很常见,但是有一些会比较隐蔽。
例如,按|分割字符串:"007|13746|2050|2107N|0|01000111000";
很容易就写成了下面这样:
java
@Test
public void split(){
String originalString = "007|13746|2050|2107N|0|01000111000";
String[] parts = originalString.split("|");
// [0, 0, 7, |, 1, 3, 7, 4, 6, |, 2, 0, 5, 0, |, 2, 1, 0, 7, N, |, 0, |, 0, 1, 0, 0, 0, 1, 1, 1, 0, 0, 0]
System.out.println(Arrays.toString(parts));
}但实际输出和预期结果不一样,因为|是元字符,表示或的意思,所以需要转义。
java
@Test
public void split(){
String originalString = "007|13746|2050|2107N|0|01000111000";
String[] parts = originalString.split("\\|");
// [007, 13746, 2050, 2107N, 0, 01000111000]
System.out.println(Arrays.toString(parts));
}下面是一些需要转义的元字符:
| 字符 | 名称 | 正则含义 | 转义写法 |
|---|---|---|---|
\ |
反斜杠 | 转义字符本身 | \\\\ |
| ` | ` | 竖线 | 逻辑"或" |
. |
点号 | 匹配任意字符 | \\. |
* |
星号 | 前一个字符0次或多次 | \\* |
+ |
加号 | 前一个字符1次或多次 | \\+ |
? |
问号 | 前一个字符0次或1次 | \\? |
^ |
插入符 | 字符串开始位置 | \\^ |
$ |
美元符 | 字符串结束位置 | \\$ |
() |
圆括号 | 分组捕获 | \\(\\) |
[] |
方括号 | 字符类 | \\[\\] |
{} |
花括号 | 量词范围 | \\{\\} |
我们可以看到,Java中的正则转义非常麻烦,一个\本身,需要4个\。
Java的Pattern提供了一个quote方法,帮我自动转义:
java
@Test
public void split(){
String originalString = "007|13746|2050|2107N|0|01000111000";
String quote = Pattern.quote("|");
// \Q|\E
System.out.println(quote);
String[] parts = originalString.split(quote);
// [007, 13746, 2050, 2107N, 0, 01000111000]
System.out.println(Arrays.toString(parts));
}Groovy正则增强
有了Matcher,就可以使用Java的方式操作了,当然,Groovy还有很多语法糖和增强:
例如,可以直接收集到列表中:
groovy
def str = "张三:13812345678,李四:13987654321,王五:13711112222"
def matcher = str =~ /\d{11}/
def phones = matcher.collect()
//[13812345678, 13987654321, 13711112222]
println phones结合findAll之类的方法:
groovy
def list = ["abc123", "def456", "ghi", "jdk789"]
def filtered = list.findAll { it =~ /\d/ }
//[abc123, def456, jdk789]
println filtered很神奇是吧,it=~/\d/明明是个Matcher,findAll需要一个bool值,怎么就没有报错呢。
因为闭包被包装成了BooleanClosureWrapper test = new BooleanClosureWrapper(closure);
最终调用了StringGroovyMethods的asBoolean方法:
Groovy
public static boolean asBoolean(final Matcher matcher) {
if (matcher != null) {
RegexSupport.setLastMatcher(matcher);
return matcher.find(0); //GROOVY-8855
}
return false;
}常用正则操作
分组匹配获取
groovy
def str = "订单号:ORDER_12345,金额:99元,订单号:ORDER_8888,金额:88元"
def matcher = str =~ /ORDER_(\d+)/
while (matcher.find()) {
println "匹配的订单号:${matcher.group()}"
println "订单号数字:${matcher.group(1)}"
println "-" * 20
}
// 匹配的订单号:ORDER_12345
// 订单号数字:12345
// --------------------
// 匹配的订单号:ORDER_8888
// 订单号数字:8888
// --------------------替换第1个、全部、匹配
Groovy
def str = "张三123,李四456,王五789"
//替换所有
// 张三,李四,王五
def result = str.replaceAll(/\d+/, "")
println result
// 替换第一个
// 张三***,李四456,王五789
result = str.replaceFirst(/\d+/, "***")
println result
// 替换匹配,注意单引号,Groovy中的双引号中的$有特殊作用
str = "ORDER_12345, ORDER_67890"
result = str.replaceAll(/ORDER_(\d+)/, '订单$1')
// 如果要使用双引号,要转义
//result = str.replaceAll(/ORDER_(\d+)/, "订单\$1")
// 订单12345, 订单67890,引用了替换都的数字分组
println result字符串分割
groovy
def str = "张三,李四;王五|赵六"
def arr = str.split(/[,;|]/)
//[张三, 李四, 王五, 赵六]
println arr文件
读取所有内容
groovy
def readFile = new File("F:\\tmp.json");
// 使用getText()方法读取文件内容
println readFile.getText();
// 使用text属性读取文件内容
println(readFile.text)按行处理
groovy
new File('F:\\Test.java').eachLine { line ->
println line
}
println("----------------------------")
def lines = new File('F:\\Test.java').readLines()
lines.each { line ->
println line
}写文件
groovy
def file = new File("F://tmp//example.txt")
file.withWriter { writer ->
writer.writeLine("Hello, Groovy!")
writer.writeLine("这是第二行文本。")
}追加
groovy
def file = new File("F://tmp//example.txt")
file.withWriterAppend { writer ->
writer.writeLine("追加的文本内容")
}json
groovy
import groovy.json.JsonSlurper
import groovy.json.JsonOutput
def updateTestJson(){
def jsonFile=new File("src/main/resources/test.json")
def jsonStr=jsonFile.text
def slurper = new JsonSlurper()
def jsonOutput=new JsonOutput()
//字符串转json对象
def jsonObj=slurper.parseText(jsonStr)
jsonObj.name="tim"
//对象转字符串
def finalJsonStr=jsonOutput.toJson(jsonObj)
jsonFile.withWriter ('utf-8'){writer->
writer.write finalJsonStr
}
}jackson
不习惯Groovy的自带的json,可以使用jackson,Jmeter默认就添加Jackson依赖:
Groovy
import com.fasterxml.jackson.annotation.JsonFormat
import com.fasterxml.jackson.annotation.JsonIgnore
import com.fasterxml.jackson.annotation.JsonProperty
import com.fasterxml.jackson.databind.ObjectMapper
import com.fasterxml.jackson.databind.type.CollectionType
class User {
/**
* id
* 不JSON序列化id
*/
@JsonIgnore
private Integer id;
/**
* 昵称
*/
private String name;
/**
* 密码
* 序列化testPwd属性为pwd
*/
@JsonProperty("pwd")
private String testPwd;
/**
* 注册时间
* 格式化日期属性
*/
@JsonFormat(pattern = "yyyy-MM-dd")
private Date time;
Integer getId() {
return id
}
void setId(Integer id) {
this.id = id
}
String getName() {
return name
}
void setName(String name) {
this.name = name
}
String getTestPwd() {
return testPwd
}
void setTestPwd(String testPwd) {
this.testPwd = testPwd
}
Date getTime() {
return time
}
void setTime(Date time) {
this.time = time
}
}
def filename = "F:\\tmp\\ok-user.json";
static def write(String name) throws IOException {
LinkedList<User> users = new LinkedList<>();
for (int i = 0; i < 20; i++) {
User user = new User();
user.setId(i);
user.setName("测试" + i);
user.setTestPwd("123456_" + i);
user.setTime(new Date());
users.add(user);
}
ObjectMapper objectMapper = new ObjectMapper();
File resultFile = new File(name);
objectMapper.writeValue(resultFile, users);
}
static def read(String name) {
ObjectMapper objectMapper = new ObjectMapper();
CollectionType collectionType = objectMapper.getTypeFactory()
.constructCollectionType(List.class, User.class);
File file = new File(name);
List<User> users = objectMapper.readValue(file, collectionType);
for (User user : users) {
System.out.println("Name: " + user.getName() + ", Id: " + user.getId()
+ ", Pwd: " + user.getTestPwd() + ", Time: " + user.getTime());
}
}
write(filename)
read(filename)