小米破局开源大模型:150亿参数如何与千亿级模型比肩
这一次,小米的AI野心超乎想象。

就在上周,小米正式发布并开源了MiMo-V2-Flash------参数量超300亿,但实际运算只用150亿参数的混合专家模型。更关键的是,这个"少数派"的性能却能与DeepSeek-V3.2、Kimi-K2等主流模型相近。这不是简单的追赶故事,而是重新考量了大模型必须堆砌海量参数的路线,为大模型效率提供了新视角。
这背后的技术逻辑,值得拆开来看。
架构如何打破效率天花板
传统大模型的低效已是众所周知的问题。推理慢、显存占用高、成本让人咋舌------这道难题横亘在每个开发者面前。MiMo-V2-Flash从架构层面动了真格。
小米采用了MoE(混合专家)结构,但玩法不同。超300亿参数中,每次推理只激活150亿。这等于什么?用一个"有选择性的大脑"------模型不铺张浪费地激活所有参数,而是聪慧地选中最相关的专家来处理任务。结果是计算成本直降,性能毫无妥协。
推理加速靠两项关键技术------混合滑动窗口注意力(SWA)和多Token预测(MTP)。传统模型处理长文本时,计算开销会飙升。小米的思路是:只看最近的128个token(滑动窗口),加上定期的全局扫描。这个激进的5:1配置听起来有风险,实验却证明,128这个数字恰好踩对了节点------不多不少。同时MTP让模型能一次预测多个token,就像人脑思考不是逐字蹦出,而是短句长段涌现。测试结果是推理速度提升2到2.6倍,达到每秒一百五十多个token。
训练效率上的创新更猛。MOPD(多教师在线策略蒸馏)技术打破了传统RL训练的束缚。以往的RL既不稳定又烧算力。新方法让学生模型自主采样,多个教师在token粒度上实时打分,而非等完整文本生成才评估。效率提升有多大?仅需传统方案1/50的算力,学生模型就能逼近教师性能。换个角度说------小米用50天做完的事,竞争对手要花2500多天。
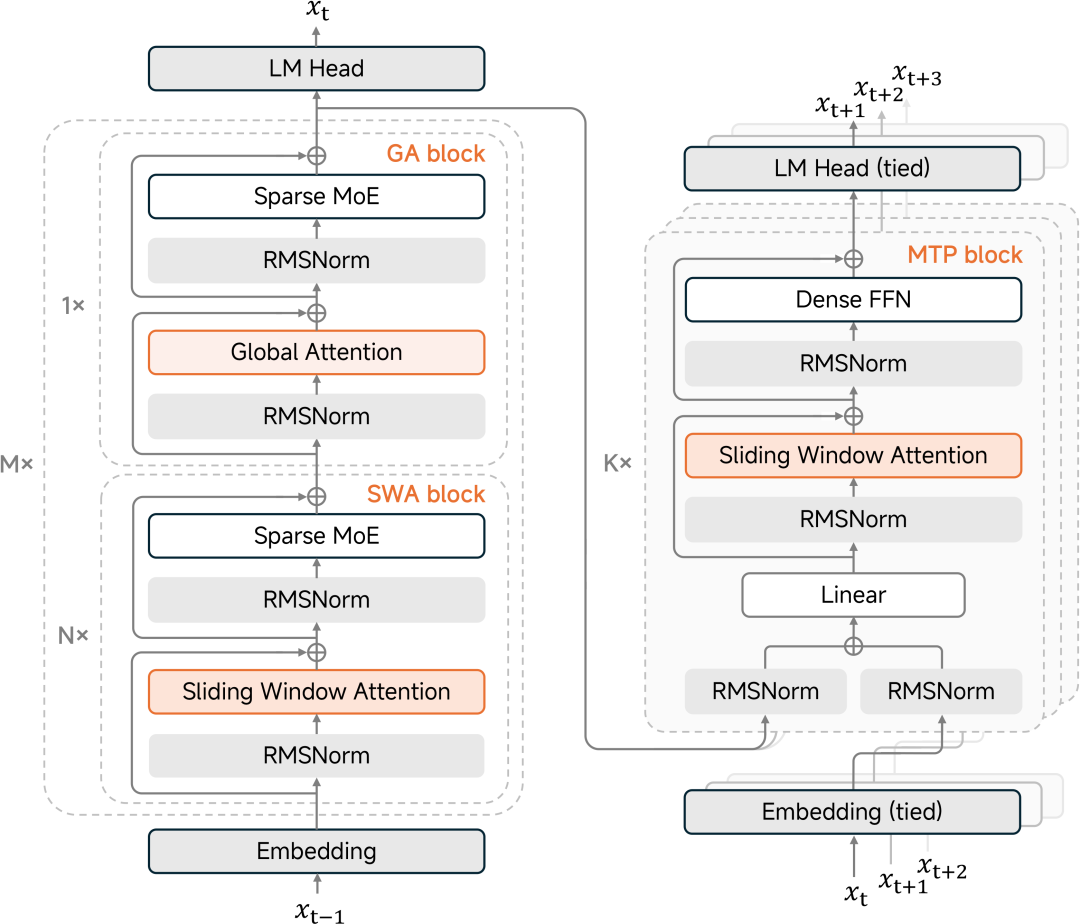
性能对标:数据怎么说
说再多也得看数据。
代码能力上,它在SWE-Bench Verified中超七成得分,在开源模型中表现突出,接近闭源顶稚水平。这不是让AI写"Hello World",而是修复真实软件bug的真刀真枪考试。七成多的成功率意味着生产环境多数问题都能自动解决。SWE-Bench Multilingual那边的七成左右得分也足够亮眼,说明对不同编程语言的理解已达到可优先水准。
数学推理方面,AIME 2025和GPQA-Diamond评测中,MiMo-V2-Flash都排在开源模型前两位。这类测试考的不是参数数量,而是真正的推理能力------能否从零开始逐步推导复杂问题。
Agent任务那块更有看头------需要模型在工具调用、上下文切换、多轮互动中保持连贯。MiMo-V2-Flash在τ²-Bench的通信类得分较高,零售类也超七成,展现出在复杂真实场景中的驾驭能力。
性能没打折,成本大幅下降。
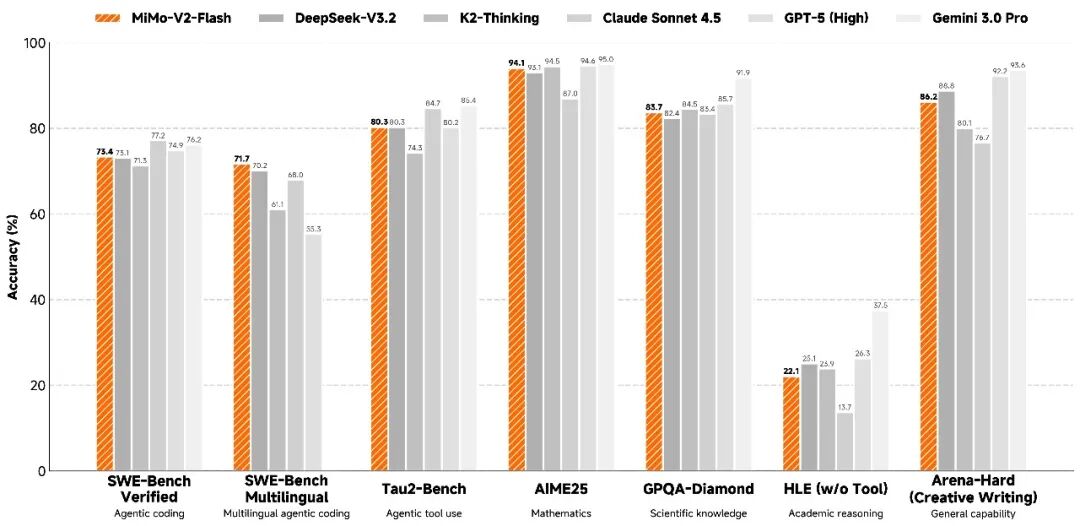
Alt text: 性能基准对比图,展示MiMo-V2-Flash与DeepSeek-V3.2、Claude Sonnet 4.5、GPT-5、Gemini 3.0 Pro等模型在SWE-Bench、数学、科学知识、Agent任务等多项基准上的表现。图源:小米官方GitHub仓库
成本如何控制得这么低
全部优势背后,其实是一套精心的成本控制体系。
推理成本的症结在KV缓存------模型得存储历史token信息来处理长文本。常规方案下缓存随序列长度线性增长,MiMo-V2-Flash的滑动窗口方案把这需求从O(N)降到O(w),w只有128。结果是什么?缓存存储量少了近六倍,即便在二十五万多token超长上下文情境下,性能也没衰减。关键卡点是"sink values"这个设计------没它性能会崩,加上它就像推开了秘密门。
多Token预测那块同样精妙。传统生成文本是逐个token蹦出来,GPU大量时间在空转。MiMo-V2-Flash能一次预测接近四个token左右,速度平均提升两倍多。妙的是推理加速之外,训练采样阶段也能减少GPU闲置,两个好处一起拿。
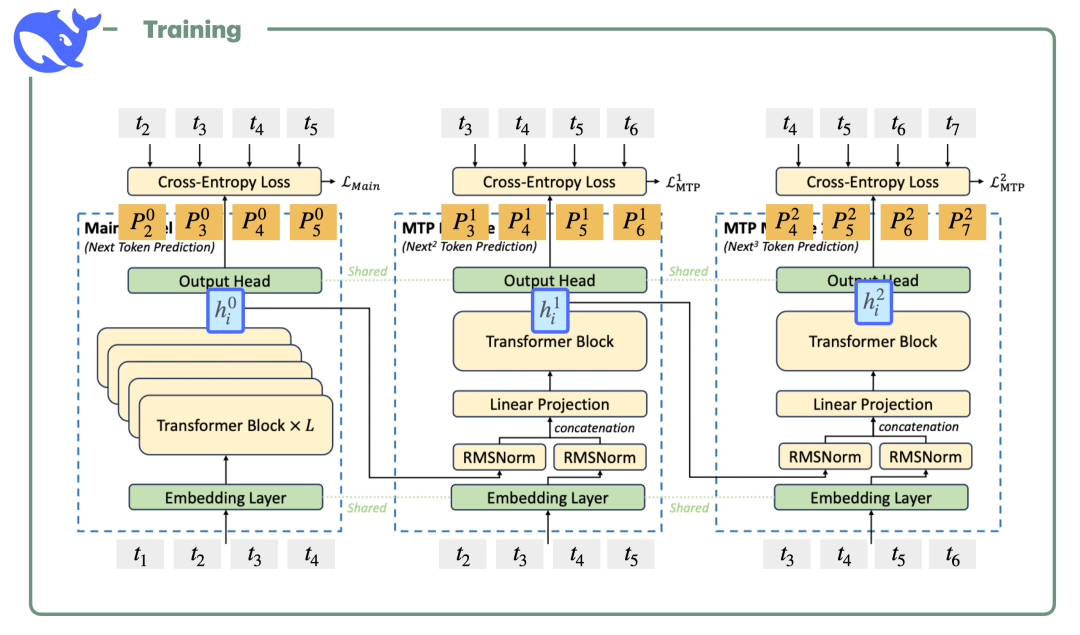
训练效率那块,MOPD威力更显著。它建构了教与学的循环:学生模型在自己策略分布上采样,多教师在token层面密集打分。对比传统SFT加RL的流程,这套思路不仅训练更稳,算力消耗也天差地别------花1/50的成本就能获得同等性能。学生模型后来变强了,还能反过来当教师,形成螺旋式进化。
具体数字呢?输入成本不到一毛钱每百万token,输出成本约3、毛钱每百万token。这价格比同级别商业模型水滘较低,推理速度比主流方案提升了一倍。从经济账看,这就叫成本下降。
对开发者和产业的实际意义
对开发者而言,二十五万多token超长上下文是什么概念?约等于一部中等长度小说,或几十页的技术文档。足够让开发者在单次请求里塞下整个代码库、完整项目背景、数百轮聊天历史。与Claude Code、Cursor、Cline这些主流工具无缝协作,开发工作流从此改变。
对产业而言,MiMo-V2-Flash代表AI能力去中心化的一阶段。曾经高端模型是少数大厂独占。现在任何有GPU的团队都能本地部署一个与业界顾閱商业模型相孔的版本。小米还把全部推理代码贡献给了SGLang社区,技术报告完全开放,模型权重用MIT协议免费发行。这股彻底的开放姿态,为开源社区提供了新的参考范式。
深层看,这是小米对自身AI基础设施策略的一次深层投注。手机、IoT、汽车------小米硬件生态需要强劲的AI引擎。MiMo-V2-Flash就是那块基石。现在的开源模型,改日可能成为小米全生态的核心引擎。
十四年前,小米用一千九百九十九块钱重新定义旗舰手机价格。今天,MiMo-V2-Flash用性价比的创新、用效率的拓展,为开源大模型的成本与能力标准提供了新的参考。这一次,小米的节奏真的变了。
社区地址
OpenCSG社区:https://opencsg.com/models/XiaomiMiMo/MiMo-V2-Flash
hf社区:https://huggingface.co/XiaomiMiMo/MiMo-V2-Flash
关于 OpenCSG
OpenCSG 是全球领先的开源大模型社区平台,致力于打造开放、协同、可持续生态,AgenticOps是人工智能领域的一种AI原生方法论, 由OpenCSG(开放传神)提出。AgenticOps是Agentic AI的最佳落地实践也是方法论。核心产品 CSGHub 提供模型、数据集、代码与 AI 应用的 一站式托管、协作与共享服务,具备业界领先的模型资产管理能力,支持多角色协同和高效复用。
更多推荐
