背景
某企业经常遇到应用性能问题,对于应用性能的监测缺少基本的手段,这无疑对故障的排查增加了难度,而且对于产品大促期间,这无疑会影响用户的体验以及最终的交易,本文主要通过介绍某出海企业用户在使用观测云应用性能监测分析时的故障场景分析实践。
应用性能监测
观测云拥有应用性能监测的能力,支持各种主流语言的技术栈,并兼容 OpenTelemetry,Skywalking,Jaeger,DDTrace 等等开源的 Agent,最佳部署方案是将 DataKit 部署在每一台应用服务器中,通过服务所在主机的 DataKit 后将数据打到观测云中心,能更好地对应用服务的服务器主机指标、应用日志、系统日志、应用服务链路数据等统一汇聚,进行各项数据的关联分析,而观测云应用性能监测主要功能包含服务,概览,链路,错误追踪,Profiling,应用性能指标检测等功能,本文主要基于观测云的应用监测能力,对用户故障场景进行分析实践。
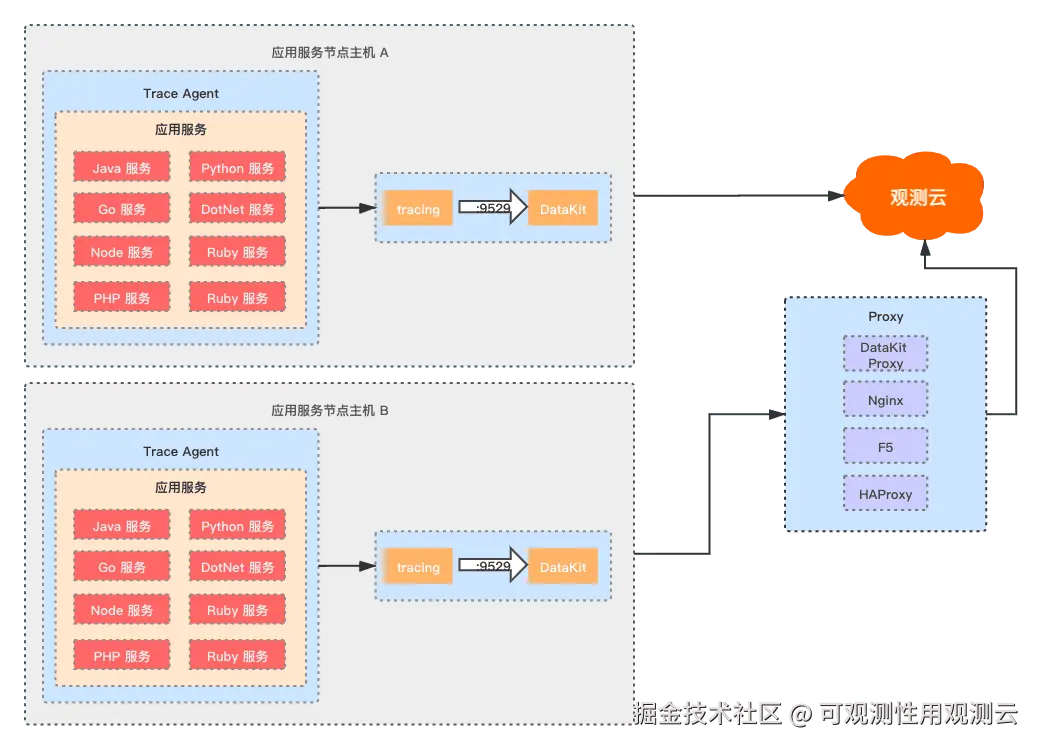
应用性能故障场景分析
故障概述:用户反馈在 17:00 前后发生应用性能访问的故障,页面卡顿,数据加载不出,基于此进行了以下场景的分析。
某服务故障场景分析实践-Read time out
- 如图,通过观测云查看到,请求量增加,从 1 万 3 的请求量级增加到,20 万左右量级,并出现大量报错,请求超时,建议平时做好压测
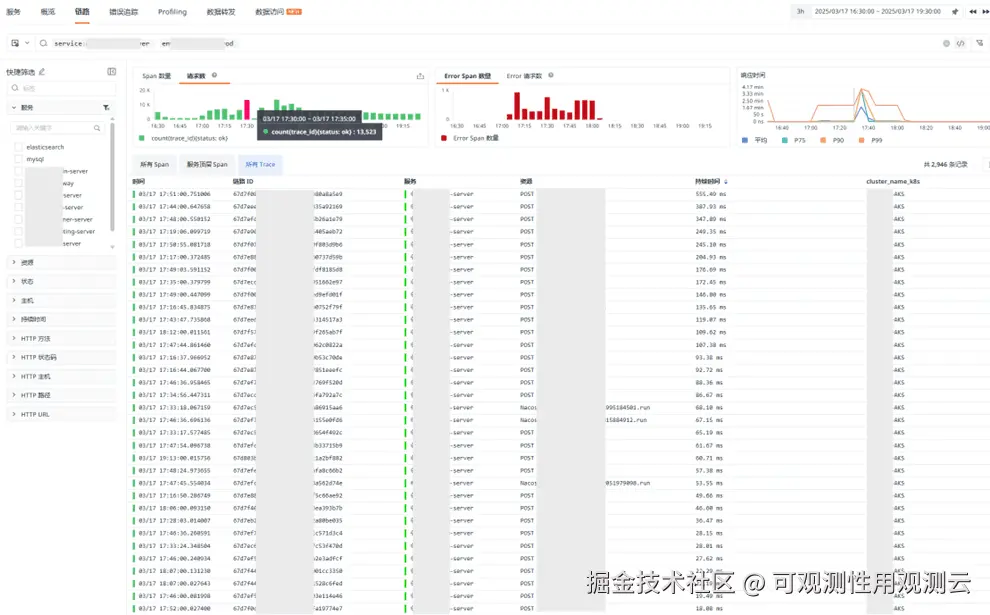
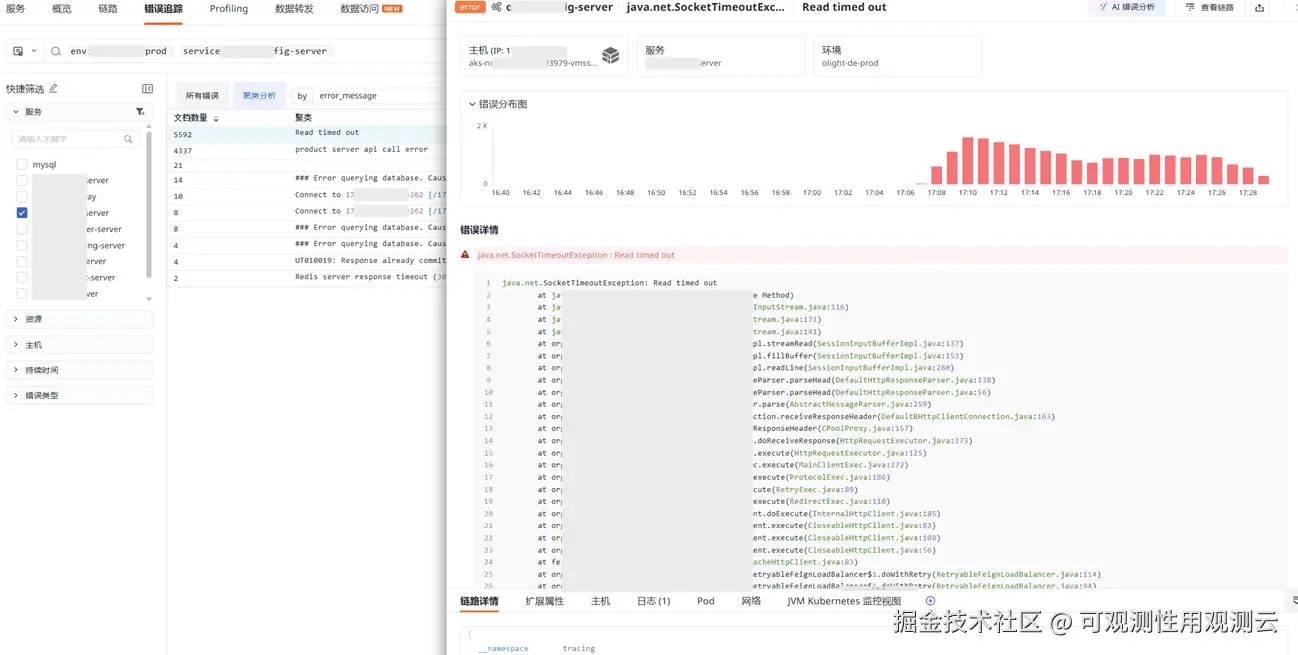
- 查看报错聚类分析,服务报错在该段时间,Read time out 报错最多
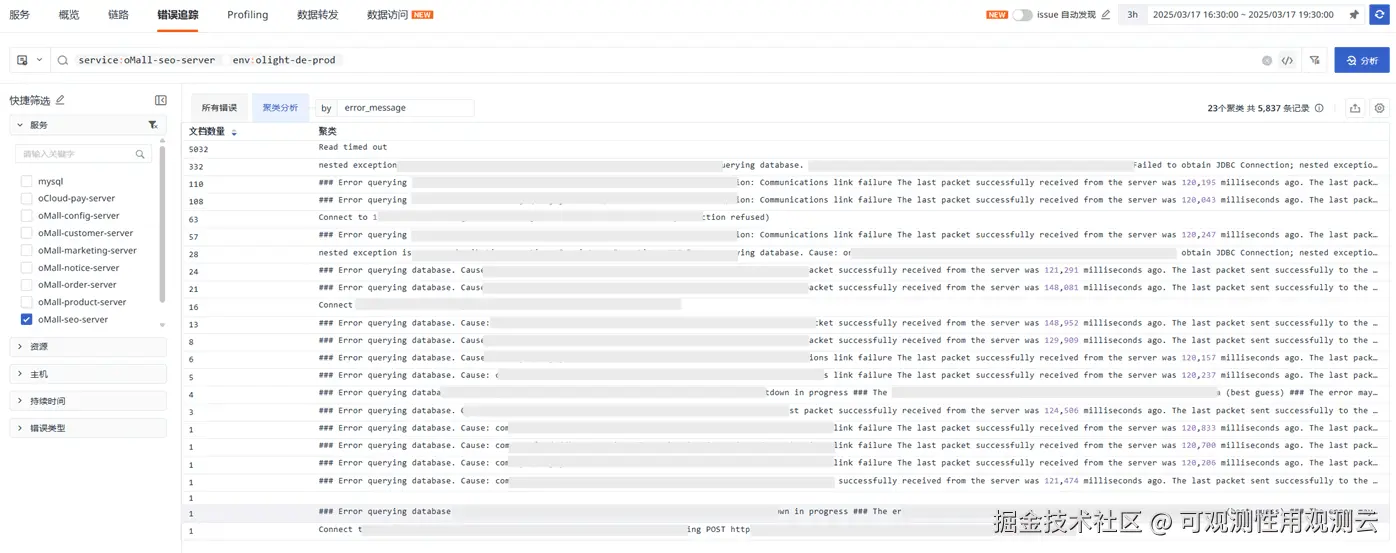
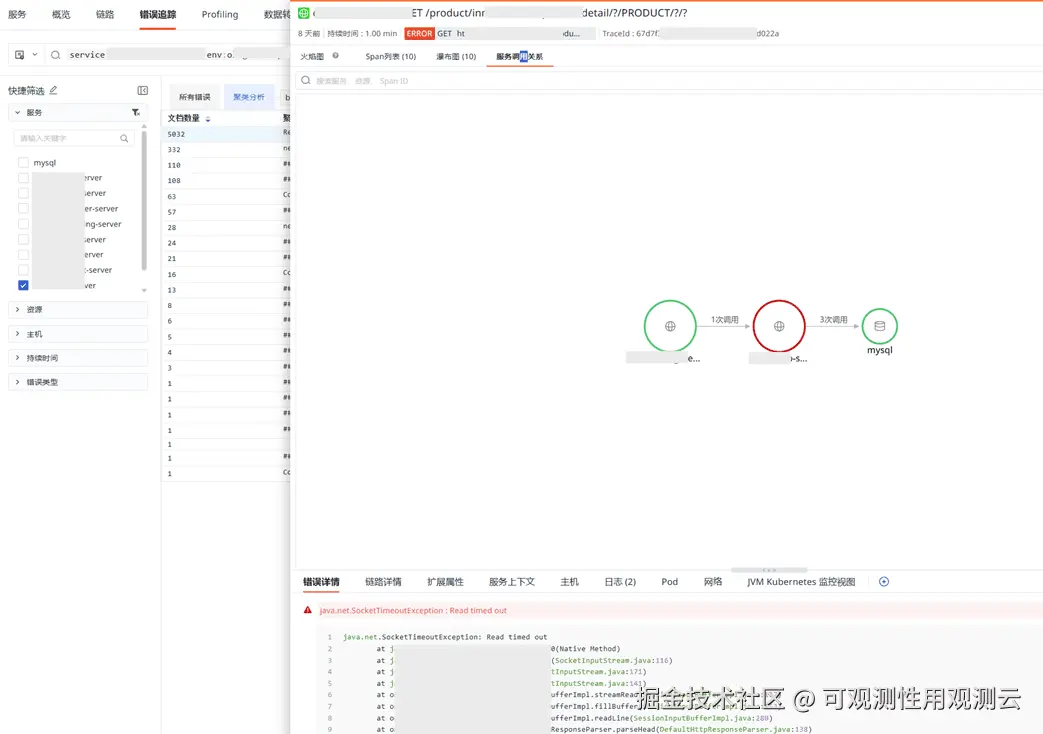
- 分析 timeout 详细,超时底层栈在 SocketInputStream.socketRead,该底层方法即发起请求后在读数据的返回

- 查看链路的瀑布图,有 1 分钟超时报错,建议检查超时设置
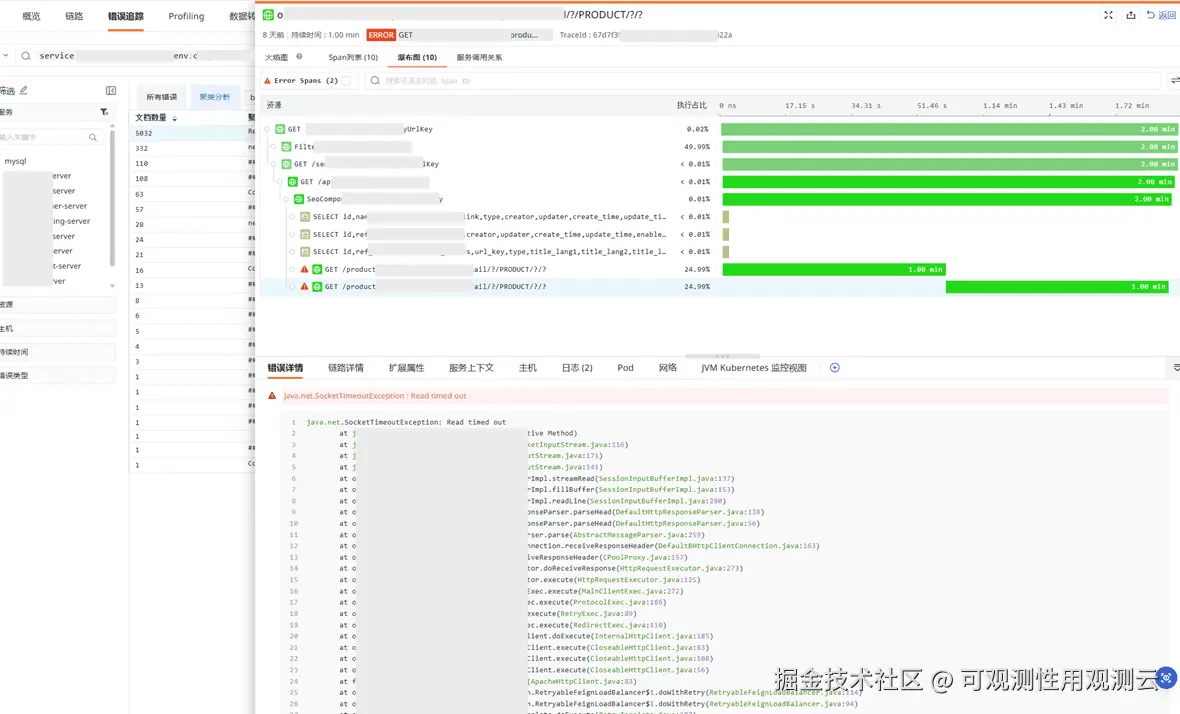
- 查看链路调用超时的拓扑图,有调 MySQL 数据库,在应用侧超时报错
MySQL 故障场景分析实践-JDBC连接通信异常
- 对 MySQL 请求量分析,发现在 17:00 左右,MySQL 请求量级也增加至少不低于 10 倍,并出现了大量报错
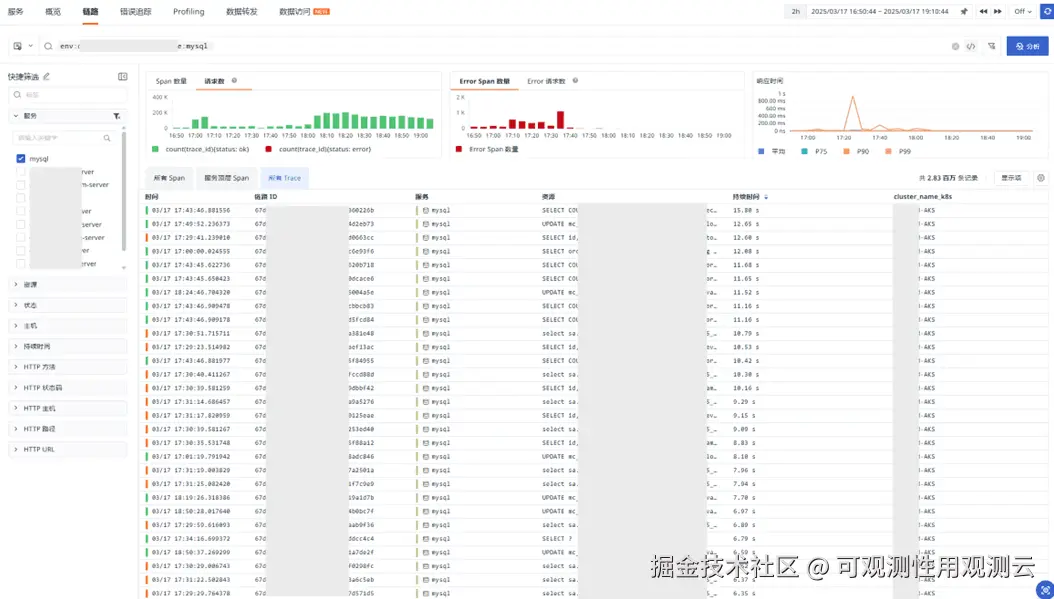
- 报错如下,主要是数据包发送接收超时,通信失败以及服务 shutdown 的情况
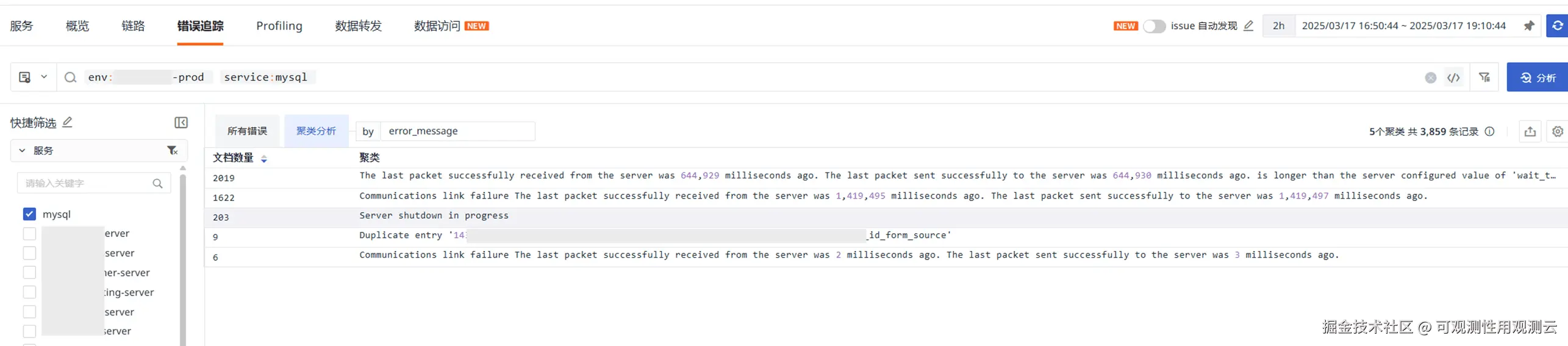
- 以上时间段可能有 MySQL 重启,筛选 17:00 左右数据,没有 server shutdown 的报错,但依然是通信超时异常
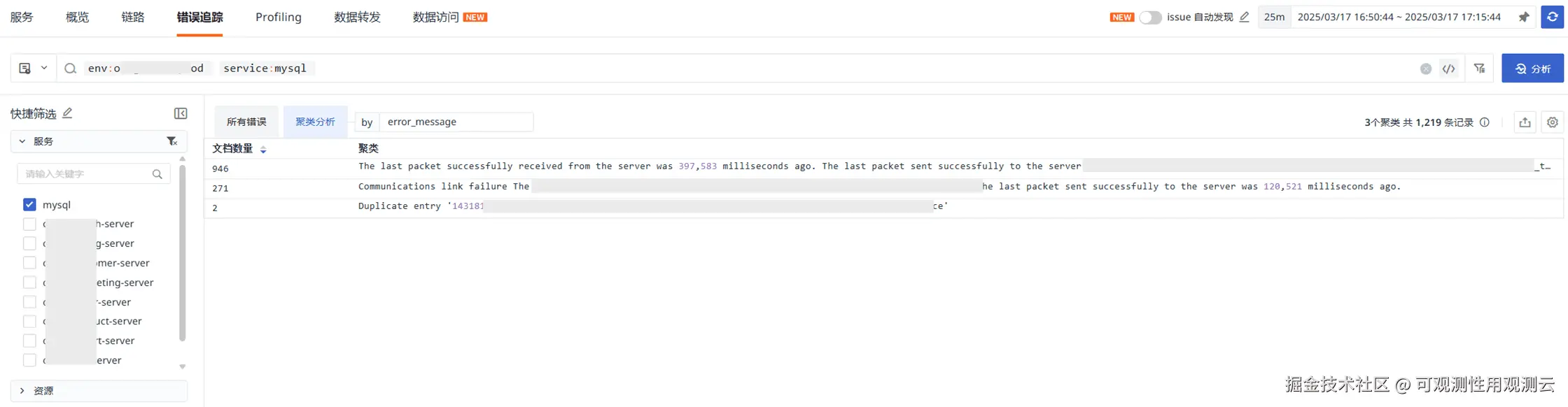
- 报错详细堆栈显示 Druid 数据库连接产生的 jdbc 异常,建议用户检查数据库连接池连接与配置情况

MySQL 故障场景分析实践-MySQL 请求调用分析
- 分析 MySQL 的请求与调用,很多服务都会调用 MySQL,每秒 5 万多请求调用
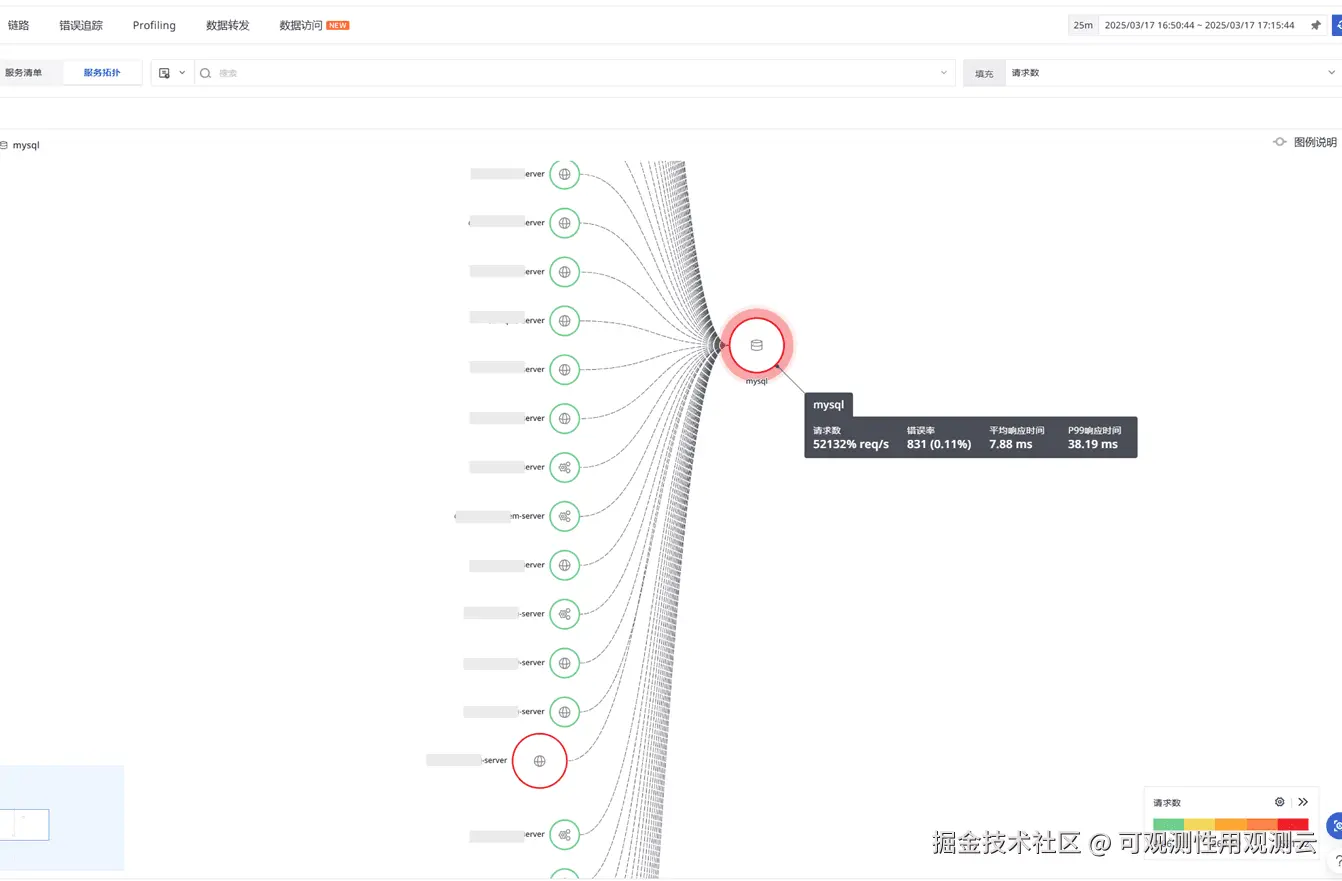
- 其中调用 MySQL 调用最多的为该服务,每秒 4 万多请求

- 其次调用 MySQL 调用最多的为 xxxxx-product-server 服务,每秒 9 千多请求

- 对 MySQL 调用最多的服务分析上下游调用情况,发现很多服务都会通过该配置服务调用 MySQL,建议考虑是否可以增加 MySQL 缓存优化
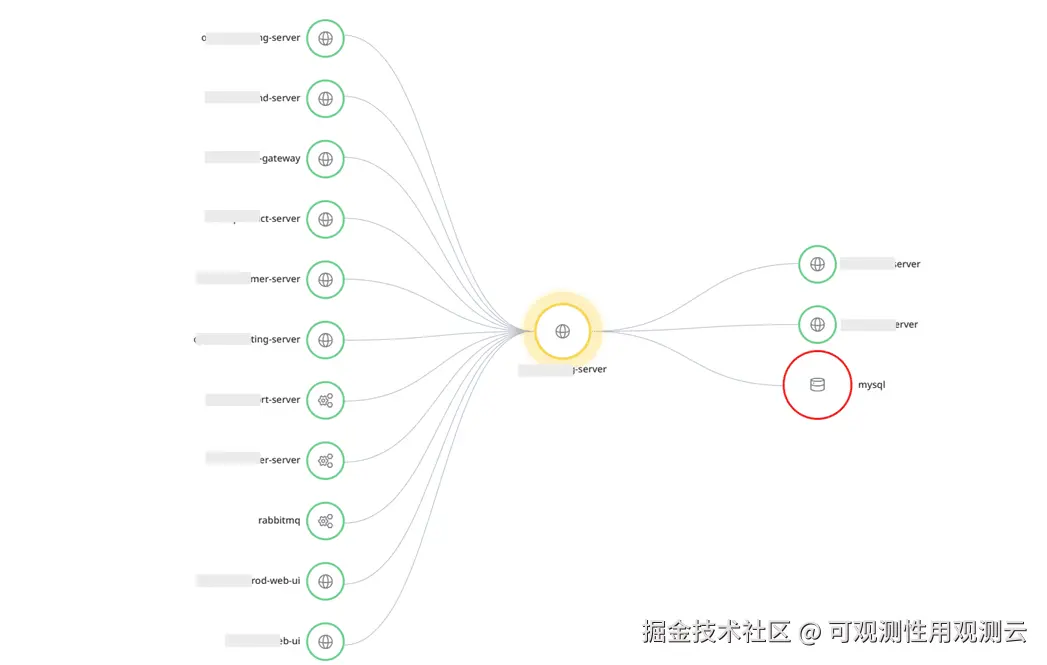
- 而且服务之间很多相互调用,服务之间也会直接或者间接的调用调数据库,只要有一个服务有问题,就可能引起连锁性能问题
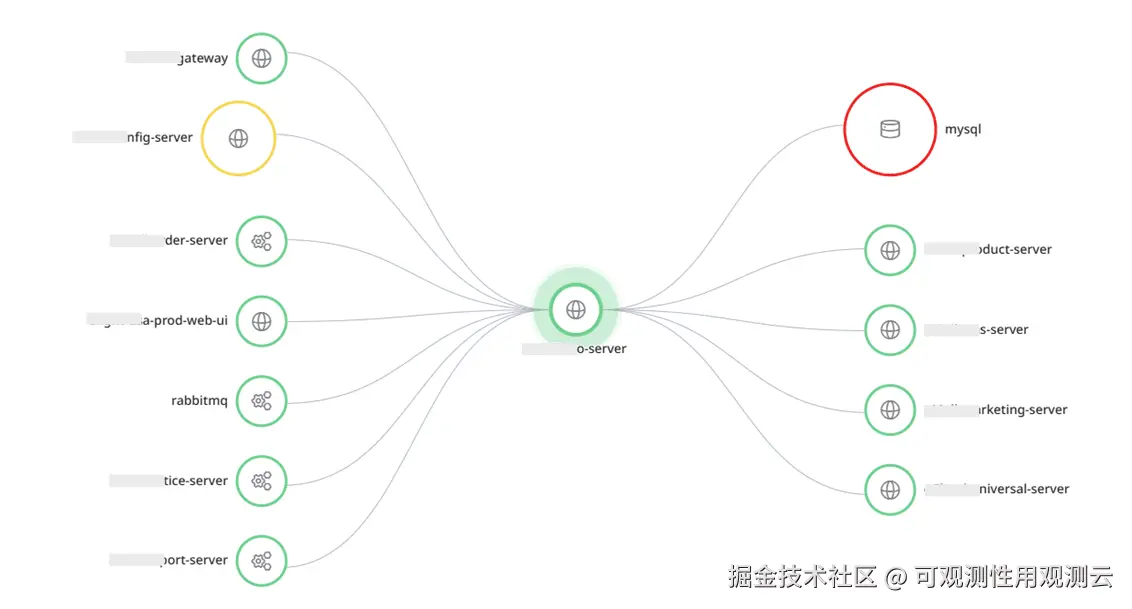
调用数据库较多的配置服务-量能分析实践
- 分析配置服务请求,发现请求量从 5 万级别到 50 万级别
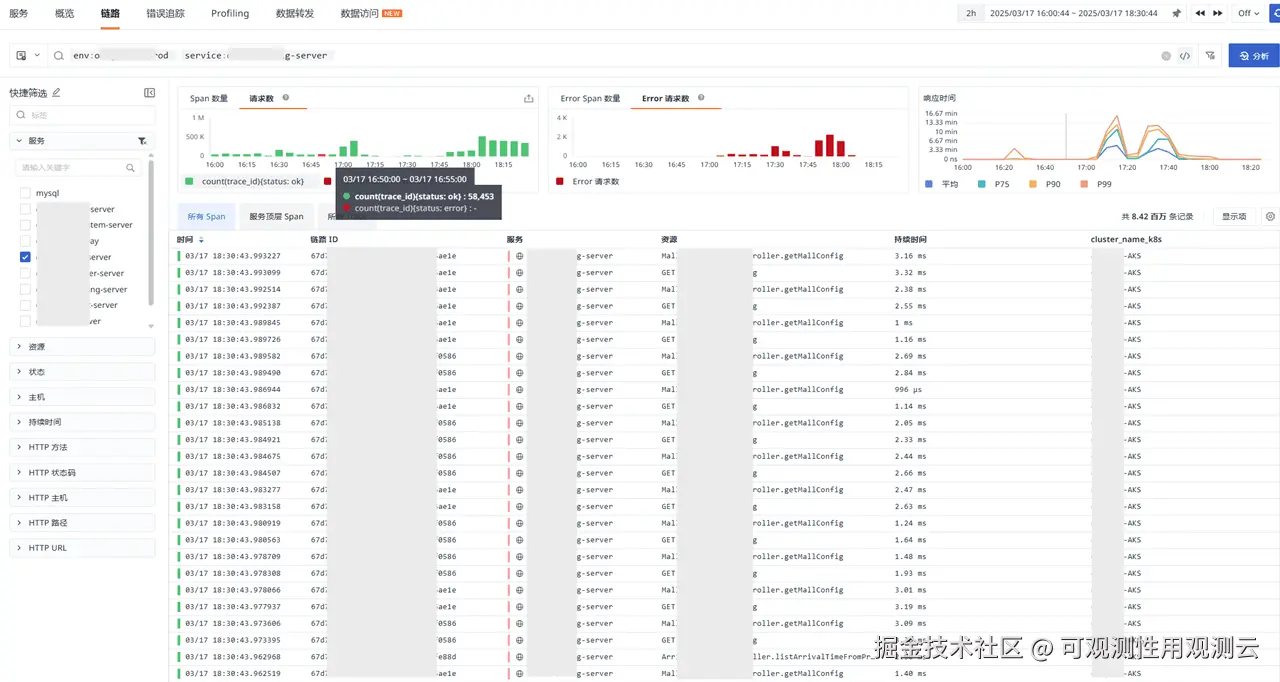
- 大量请求错误,并呈现几分钟的严重超时
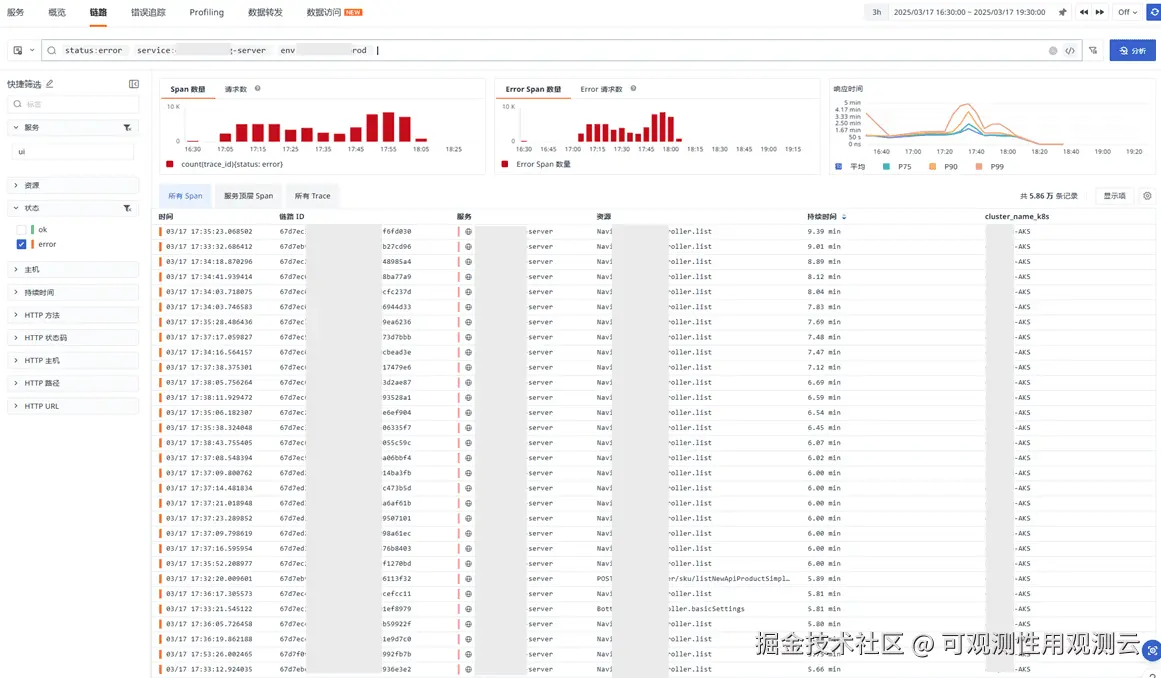
- 超时也是从 17:00 左右发生,等待数据返回
观测云应用性能分析总结
综上场景分析实践,基于观测云的应用性能监测分析得出结论与建议:
- MySQL 数据库连接问题导致本次故障,建议检查数据库连接配置,确认为连接池数不够用,连接超时,可以基于观测云增加基于连接池指标的监控
- 业务请求并发量较高,导致 MySQL 数据库请求连接数量过高
- 对调用 MySQL 较多的 xxxxx-config-server 服务,后续可以考虑采用 redis 缓存方式,减少对 MySQL 的调用
- 当有高并发活动大促时,为避免高并发导致一系列的故障采用秒级可以拉起的高性能数据库厂商
- 对于高并发的场景,提前做好性能压测,确保对应的资源能满足对应活动的并发量请求