
♥♥♥~~~~~~欢迎光临知星小度博客空间~~~~~~♥♥♥
♥♥♥零星地变得优秀~也能拼凑出星河~♥♥♥
♥♥♥我们一起努力成为更好的自己~♥♥♥
♥♥♥如果这一篇博客对你有帮助~别忘了点赞分享哦~♥♥♥
♥♥♥如果有什么问题可以评论区留言或者私信我哦~♥♥♥
✨✨✨✨✨✨ 个人主页✨✨✨✨✨✨
这一篇博客,我们继续来学习Linux~准备好了吗~我们发车去探索Linux的奥秘啦~🚗🚗🚗🚗🚗🚗
目录
[1.1 机械磁盘的精妙设计](#1.1 机械磁盘的精妙设计)
[1.2 磁盘存储的层次结构](#1.2 磁盘存储的层次结构)
[第二章 数据寻址:从三维坐标到一维地址😋](#第二章 数据寻址:从三维坐标到一维地址😋)
[2.1 CHS寻址:传统三维坐标定位](#2.1 CHS寻址:传统三维坐标定位)
[2.2 LBA寻址:现代一维线性地址](#2.2 LBA寻址:现代一维线性地址)
[第三章 文件系统核心概念😁](#第三章 文件系统核心概念😁)
[3.1 块(Block):提升效率的存储单元](#3.1 块(Block):提升效率的存储单元)
[3.2 分区(Partition):磁盘的逻辑划分](#3.2 分区(Partition):磁盘的逻辑划分)
[3.3 inode:文件的身份证](#3.3 inode:文件的身份证)
[第四章 Ext2文件系统深度解析🙃](#第四章 Ext2文件系统深度解析🙃)
[4.1 整体架构:分而治之的设计哲学](#4.1 整体架构:分而治之的设计哲学)
[4.2 超级块(Super Block):文件系统的大脑](#4.2 超级块(Super Block):文件系统的大脑)
[数据块(Data Blocks)------内容存储实体](#数据块(Data Blocks)——内容存储实体)
[4.4 数据存储的多级索引机制](#4.4 数据存储的多级索引机制)
[第五章 文件访问全流程解析😄](#第五章 文件访问全流程解析😄)
[5.1 文件创建的四步曲](#5.1 文件创建的四步曲)
[5.2 路径解析:从根目录到目标文件](#5.2 路径解析:从根目录到目标文件)
[5.3 目录的本质:文件名到inode的映射](#5.3 目录的本质:文件名到inode的映射)
[第六章 挂载机制:连接文件系统与目录树😀](#第六章 挂载机制:连接文件系统与目录树😀)
[6.1 挂载的实际操作演示](#6.1 挂载的实际操作演示)
[6.2 挂载的技术原理](#6.2 挂载的技术原理)
[第七章 软硬链接:文件的多个入口🐷](#第七章 软硬链接:文件的多个入口🐷)
[7.1 硬链接:同一文件的多个名称](#7.1 硬链接:同一文件的多个名称)
[7.2 软链接:文件的快捷方式](#7.2 软链接:文件的快捷方式)
引言:从物理磁盘到逻辑文件的魔法之旅😊
在我们日常使用计算机时,很少会思考这样一个问题:当我们点击一个文件时,计算机是如何在复杂的硬件结构中精确找到并打开这个文件的?这背后隐藏着一套精密的文件系统机制。在Linux世界中,Ext系列文件系统(Ext2、Ext3、Ext4)扮演着至关重要的角色。今天,让我们一同揭开这个神秘面纱,从磁盘的物理结构开始,逐步探索文件系统的完整运作机制。
第一章:磁盘物理结构:数据存储的基石😍
1.1 机械磁盘的精妙设计
机械磁盘是计算机中唯一的机械设备,这个特点决定了它的工作方式和性能特征~磁盘作为外设,读取速度慢,但是容量大、价格便宜~
接下来我们来看看磁盘的样子:

核心组件解析:
盘片(Platter):表面光滑的圆形金属或玻璃盘片,覆盖着磁性材料
磁头(Header):悬浮在盘片上方纳米级别的读写头
主轴 (Spindle):高速旋转的马达,让所有盘片同步旋转
磁臂(Actuator Arm):承载磁头在盘片半径方向移动的机械臂
实际场景比喻:
把磁盘想象成一个多层旋转餐厅,每层楼面(盘片)都有餐桌(数据),服务员(磁头)沿着半径方向移动,为不同位置的客人提供服务。
1.2 磁盘存储的层次结构
磁盘的数据组织采用分层结构,理解这个结构是理解文件系统的前提:
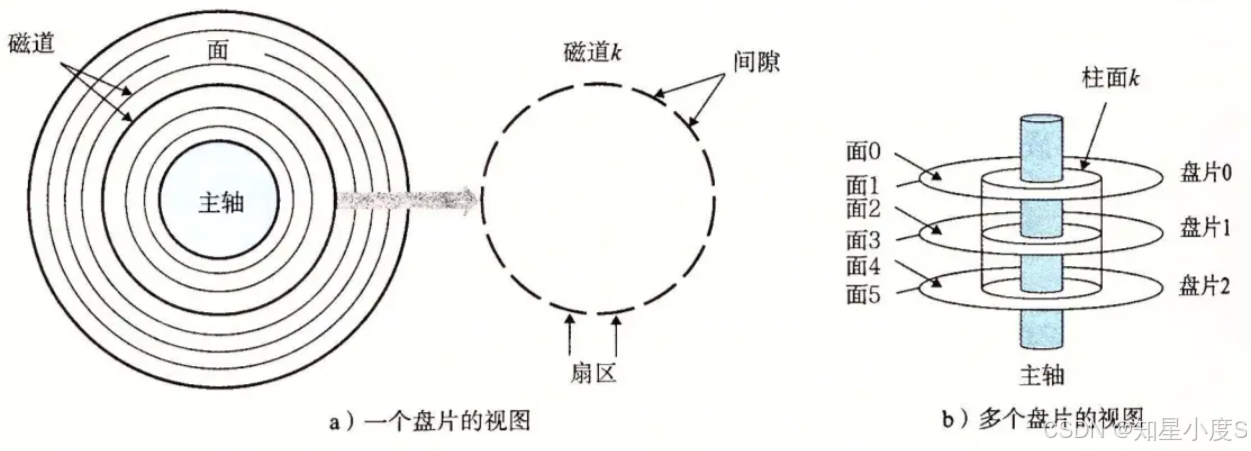
磁盘 (Disk)
↓
盘片 (Platter) × N↓
盘面 (Surface) × 2 (每个盘片有两个面)↓
磁道 (Track) (同心圆)↓
扇区 (Sector) (512字节基本单元)
关键概念:
磁道 :盘面上的同心圆轨迹,就像田径场的跑道
扇区 :磁道上等分的弧段,每个512字节,是磁盘最小存储单元,也是操作系统访问磁盘设备的基本单位
柱面 :所有盘面相同半径的磁道组成的立体结构(也就是类似于圆柱面)
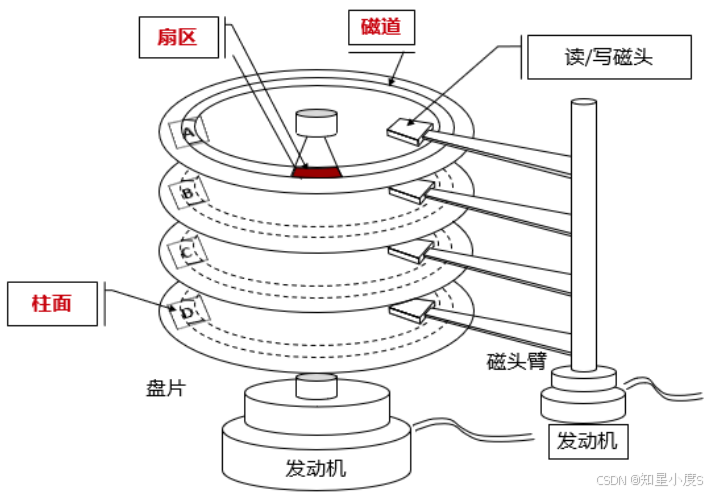
所有磁头是"机械联动"的,当0号磁头移动到第100个磁道时,其他所有磁头也都移动到各自盘面的第100个磁道【磁头共进退】。这种设计简化了机械控制,但也在一定程度上影响了性能。
磁头左右摆动 本质上是确定在哪一个磁道(柱面), 盘片旋转 本质上是定位该磁道(柱面上)的哪一个扇区。这样我们就可以对磁盘的特定位置进行寻址~
第二章 数据寻址:从三维坐标到一维地址😋
2.1 CHS寻址:传统三维坐标定位
在早期磁盘中,采用CHS(Cylinder-Header-Sector)三维坐标来定位数据:
查看磁盘信息------命令行输入【fdisk -l】(注意:需要root账号或者给普通账号提升权限)
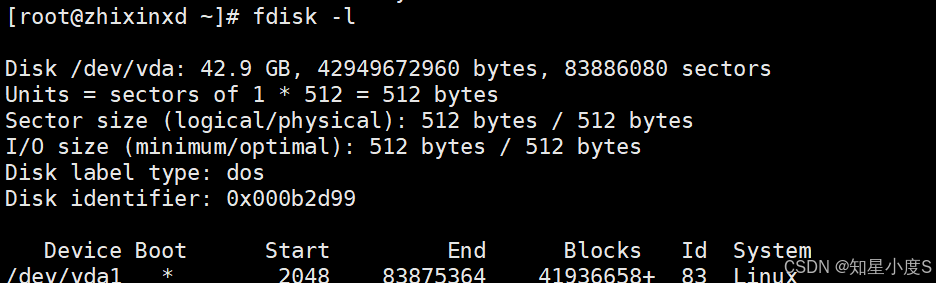
包含了我们整体磁盘信息:
-
磁盘设备 :
/dev/vda -
磁盘容量: 42.9 GB (42,949,672,960 字节)
-
扇区总数: 83,886,080 个
-
扇区大小: 逻辑和物理大小都是 512 字节
-
I/O 大小: 最小/最优也是 512 字节
-
分区表类型 :
dos(也就是传统的 MBR 分区表) -
磁盘标识符 :
0x000b2d99
CHS寻址原理:
Cylinder(柱面):确定在哪一个柱面(所有盘面的同一磁道)
Header(磁头):确定使用哪个磁头(哪个盘面)
Sector(扇区):确定该磁道上的具体扇区
注意:
在物理现实 上,扇区个数与半径 有直接关系; CHS模型为了简化计算和接口设计,强行做了一个假设 :假设所有磁道(无论内外圈)的扇区数量都是完全相同的。
在这个模型里:
磁盘被想象成一个规整的"圆柱体"。
每个"柱面"都由相同数量的磁道组成。
每个磁道都由相同数量的扇区组成。
现代硬盘的工作流程:
物理磁盘(扇区数不等) → 磁盘控制器(进行转换) → 呈现给操作系统(扇区数固定的CHS或直接的LBA)
CHS的局限性 :
由于使用8bit存储磁头地址、10bit存储柱面地址、6bit存储扇区地址,CHS模式最大只能支持:256 × 1024 × 63 × 512B = 8064 MB
2.2 LBA寻址:现代一维线性地址
为了解决CHS的局限性,现代磁盘采用LBA(Logical Block Address)逻辑块地址【也就是我们把磁盘结构想象成一个线性结构,我们可以把磁盘当作一个以Sector(扇区)为单位的一维数组】,
转换公式:
CHS转成LBA:
磁头数*每磁道扇区数 = 单个柱面的扇区总数
LBA = 柱面号C**单个柱面的扇区总数 + 磁头号H**每磁道扇区数 + 扇区号S - 1
即:LBA = 柱面号C*(磁头数* 每磁道扇区数) + 磁头号H*每磁道扇区数 + 扇区号S - 1
扇区号通常是从1开始的,而在LBA中,地址是从0开始的
柱面和磁道都是从0开始编号的
总柱面,磁道个数,扇区总数等信息在磁盘内部会自动维护,上层开机的时候,会获取到这些参数。
LBA转成CHS
柱面号C = LBA // (磁头数*每磁道扇区数) 就是单个柱面的扇区总数
磁头号H = (LBA % (磁头数*每磁道扇区数)) // 每磁道扇区数
扇区号S = (LBA % 每磁道扇区数) + 1
"// ": 表示除取整
所以:从此往后,在磁盘使用者看来,根本就不关心CHS地址,而是直接使用LBA地址,磁盘内部自己转换。所以:从现在开始,磁盘就是一个元素为扇区的一维数组,数组的下标就是每一个扇区的LBA地址,把磁盘当作一个块设备。OS使用磁盘,就可以用一个数字访问磁盘扇区了。
生动比喻:
CHS:像在大型图书馆说"去3号楼2层第5个书架"
LBA:像直接说"去第301号位置"
CHS是描述磁盘物理结构的旧方法,而LBA是线性逻辑地址。现代磁盘内部物理结构复杂(如区域位记录),不再与标准CHS对应。转换工作交给了磁盘固件这个"黑盒子",操作系统只需发送LBA地址,磁盘自行将其映射到真实的物理位置,从而简化了操作,并突破了寻址限制。也就是说:CHS和LBA地址的相互转换是由磁盘自己的控制器来做的。
第三章 文件系统核心概念😁
3.1 块(Block):提升效率的存储单元
事实上,操作系统不会以单个扇区(512B)为单位进行读写,而是以"块"为单位:
cpp
// 典型的块大小
#define BLOCK_SIZE 4096 // 8个扇区我们来看看Linux 2.6.0版本中块大小是多少?
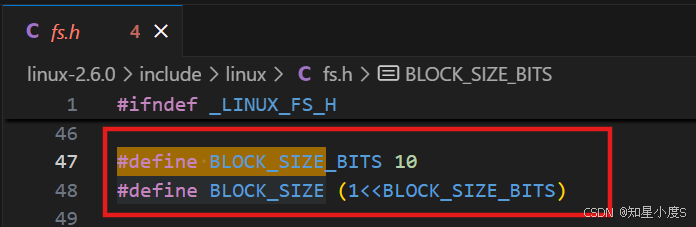
这并不是直接定义了块大小,Linux内核2.6.0的fs.h文件中,BLOCK_SIZE_BITS定义为10,通过位运算1<<10计算出BLOCK_SIZE为1024字节(1KB)。这确定了文件系统的基本I/O块大小,是所有磁盘读写操作的最小单位~最常见的应该是4KB(4096字节) ,即连续8个扇区(512B)组成一个块~
块设备的优势:
减少寻道时间:一次读取连续多个扇区
提高吞吐量:减少IO操作次数
优化缓存:更有效地利用页面缓存
3.2 分区(Partition):磁盘的逻辑划分
分区就像把大仓库划分成不同的功能区,命令行输入【df -h】可以查看系统分区情况~
df -h = 显示磁盘文件系统使用情况,-h 参数表示以人类可读的格式(GB/MB)显示
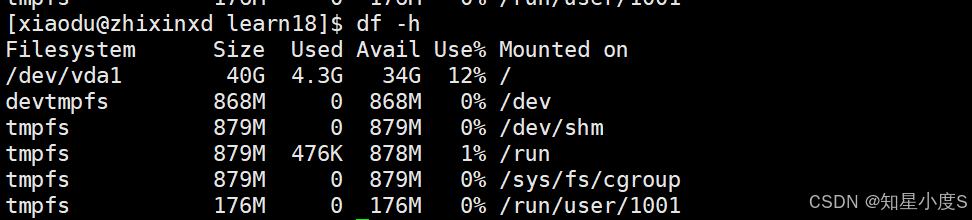
输出结果包含:
系统主要磁盘:
/dev/vda1- 根分区,总大小40G,已用4.3G,可用34G,使用率12%
临时文件系统(内存中):
-
devtmpfs- 设备文件系统,868MB -
tmpfs- 临时文件系统,多个实例用于:-
/dev/shm- 共享内存 -
/run- 运行时数据 -
/sys/fs/cgroup- 控制组文件系统 -
/run/user/1001- 用户级运行时目录
-
因为小编使用的是云服务器,所以我们看到的40G磁盘是云服务商为我分配的虚拟磁盘空间,不是物理独立的硬盘~
分区的好处:
①隔离系统文件和用户文件
②不同的分区可以使用不同的文件系统
③提高系统安全性和维护性
3.3 inode:文件的身份证
每个文件都有唯一的inode,记录文件的元信息【属性】 :
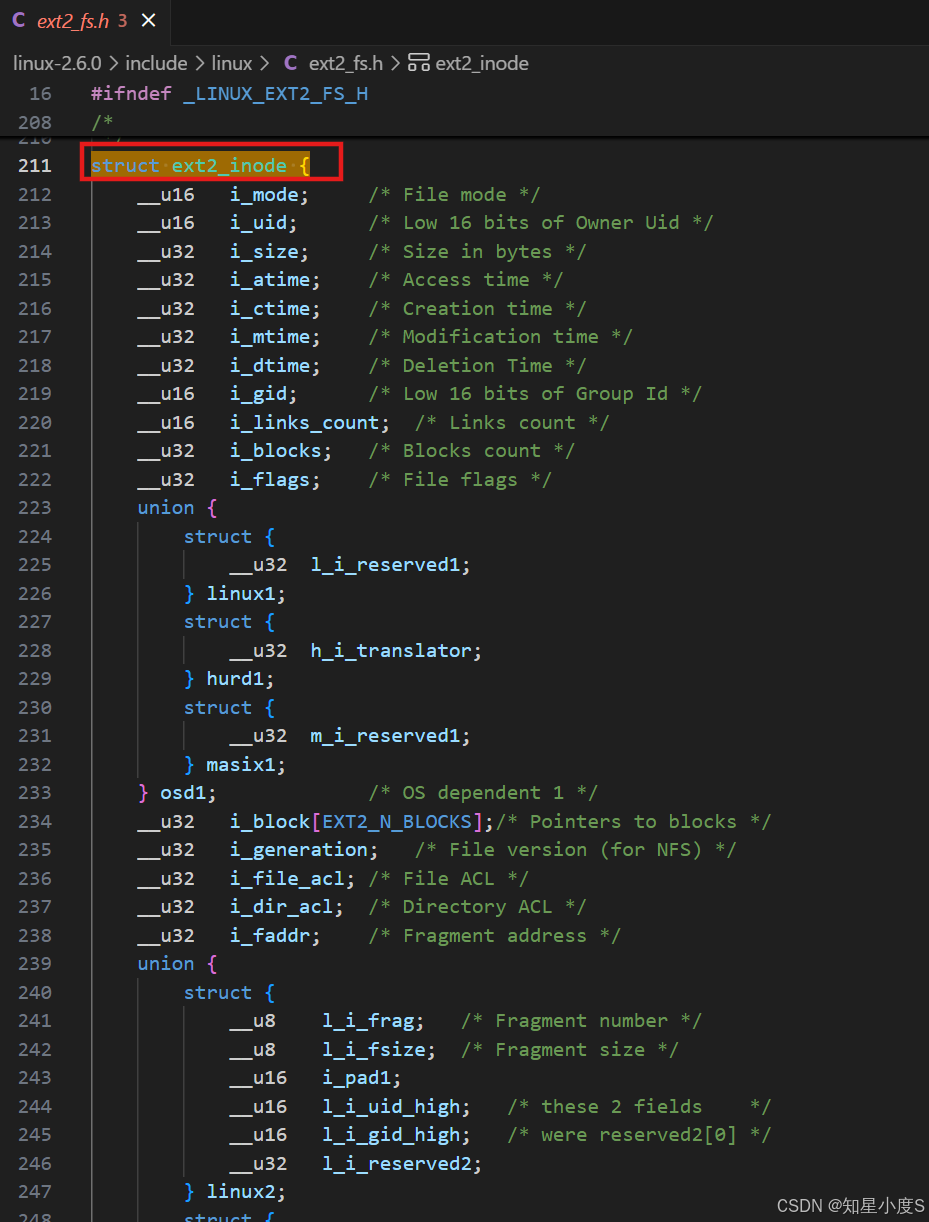
这里我们进行简单的说明:
cpp
/*
* ext2 文件系统 inode 结构体定义
* 位于:linux-2.6.0/include/linux/ext2_fs.h
* 这是磁盘上 inode 的存储格式
*/
struct ext2_inode {
/* 文件基本属性 */
__u16 i_mode; /* 文件类型和权限位 */
__u16 i_uid; /* 文件所有者用户ID(低16位) */
__u32 i_size; /* 文件大小(字节) */
/* 时间戳(32位Unix时间戳) */
__u32 i_atime; /* 最后访问时间 */
__u32 i_ctime; /* inode状态改变时间 */
__u32 i_mtime; /* 最后修改时间 */
__u32 i_dtime; /* 文件删除时间 */
/* 所有权和链接信息 */
__u16 i_gid; /* 文件所属组ID(低16位) */
__u16 i_links_count; /* 硬链接计数 */
__u32 i_blocks; /* 文件占用的512字节块数 */
__u32 i_flags; /* 文件标志(如immutable、append-only等) */
/* 操作系统依赖字段 - 联合体用于不同OS兼容 */
union {
struct {
__u32 l_i_reserved1; /* Linux系统保留字段 */
} linux1;
struct {
__u32 h_i_translator; /* HURD系统翻译器字段 */
} hurd1;
struct {
__u32 m_i_reserved1; /* Masix系统保留字段 */
} masix1;
} osd1; /* 操作系统相关字段1 */
/* 数据块指针数组 - 文件系统的核心 */
__u32 i_block[EXT2_N_BLOCKS]; /* 指向文件数据块的指针数组 */
/* 包含:12个直接指针 + 1个一级间接 + 1个二级间接 + 1个三级间接 */
/* 扩展属性 */
__u32 i_generation; /* 文件版本号(用于NFS) */
__u32 i_file_acl; /* 文件访问控制列表 */
__u32 i_dir_acl; /* 目录访问控制列表 */
__u32 i_faddr; /* 片段地址 */
/* Linux特定扩展字段 */
union {
struct {
__u8 l_i_frag; /* 片段编号 */
__u8 l_i_fsize; /* 片段大小 */
__u16 i_pad1; /* 填充对齐 */
__u16 l_i_uid_high; /* 用户ID高16位(扩展UID支持) */
__u16 l_i_gid_high; /* 组ID高16位(扩展GID支持) */
__u32 l_i_reserved2; /* Linux保留字段 */
} linux2;
/* 其他操作系统的扩展字段可以在此添加 */
} osd2; /* 操作系统相关字段2 */
};关键特性:
①inode中不包含文件名属性,文件名属性存储在目录文件中
②每个inode大小通常为128或256字节
③通过inode号唯一标识文件,inode在是全分区统一分配,不仅仅是分组内有效【inode不能跨分区,一个分区,一个文件系统相互独立】
④任何文件的内容大小可以不同,但是属性大小一定是相同的
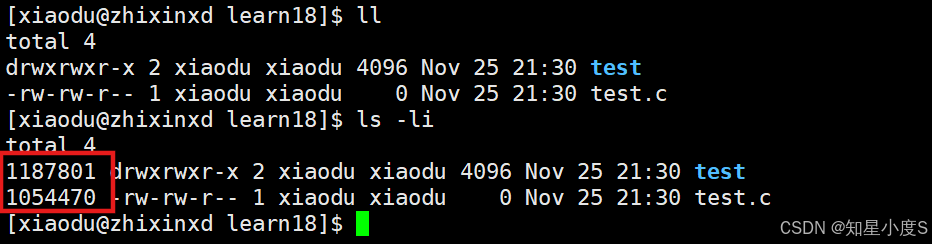
命令行输入【ls -li】,我们可以实际查看inode:
第四章 Ext2文件系统深度解析🙃
4.1 整体架构:分而治之的设计哲学
Ext2系列文件系统采用"块组"管理策略,将大分区划分为多个管理单元。
EXT2文件系统将磁盘分区划分为多个相同大小的块组进行管理,每个块组包含超级块、组描述符表、块位图、inode位图、inode表和数据块。分区起始处有1KB的启动扇区存储引导信息,不可更改。inode表记录文件元数据,包括类型、权限、链接数、属主、大小及数据块指针。这种分层块组设计实现了高效的磁盘空间管理,具有良好的可靠性和性能,为后续ext3/ext4的发展奠定基础,是Linux文件系统的经典架构。
我们一起来看看下面的图片:
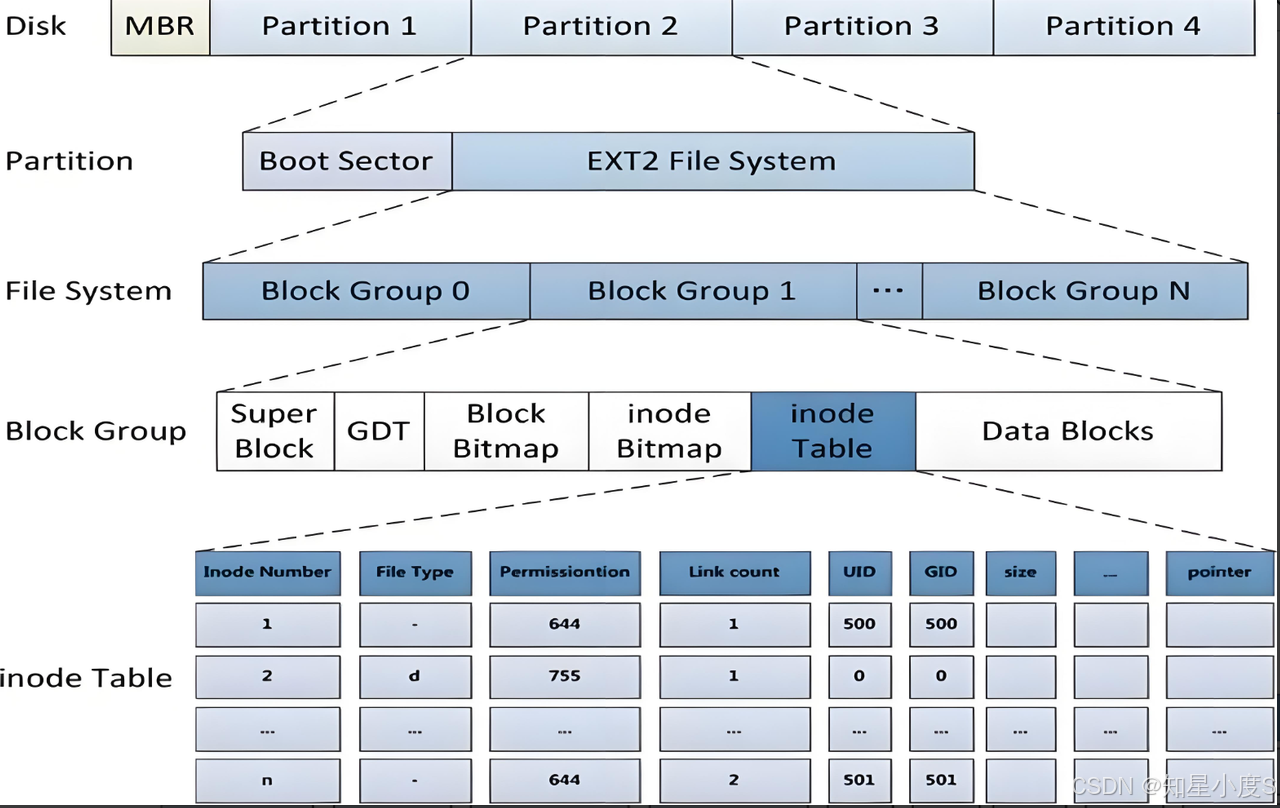
结合图片,我们可以看到每个块组的内部结构 :
{
SuperBlock // 超级块(文件系统元数据)
GroupDescriptor // 块组描述符
BlockBitmap // 块位图(数据块使用情况)
InodeBitmap // inode位图(inode使用情况)
InodeTable // inode表(所有inode集合)
DataBlocks // 数据块(实际文件内容)
};
4.2 超级块(Super Block):文件系统的大脑
超级块记录着整个文件系统的关键信息,比如:文件系统的全局配置和状态信息,指导文件系统如何分配和管理磁盘空间
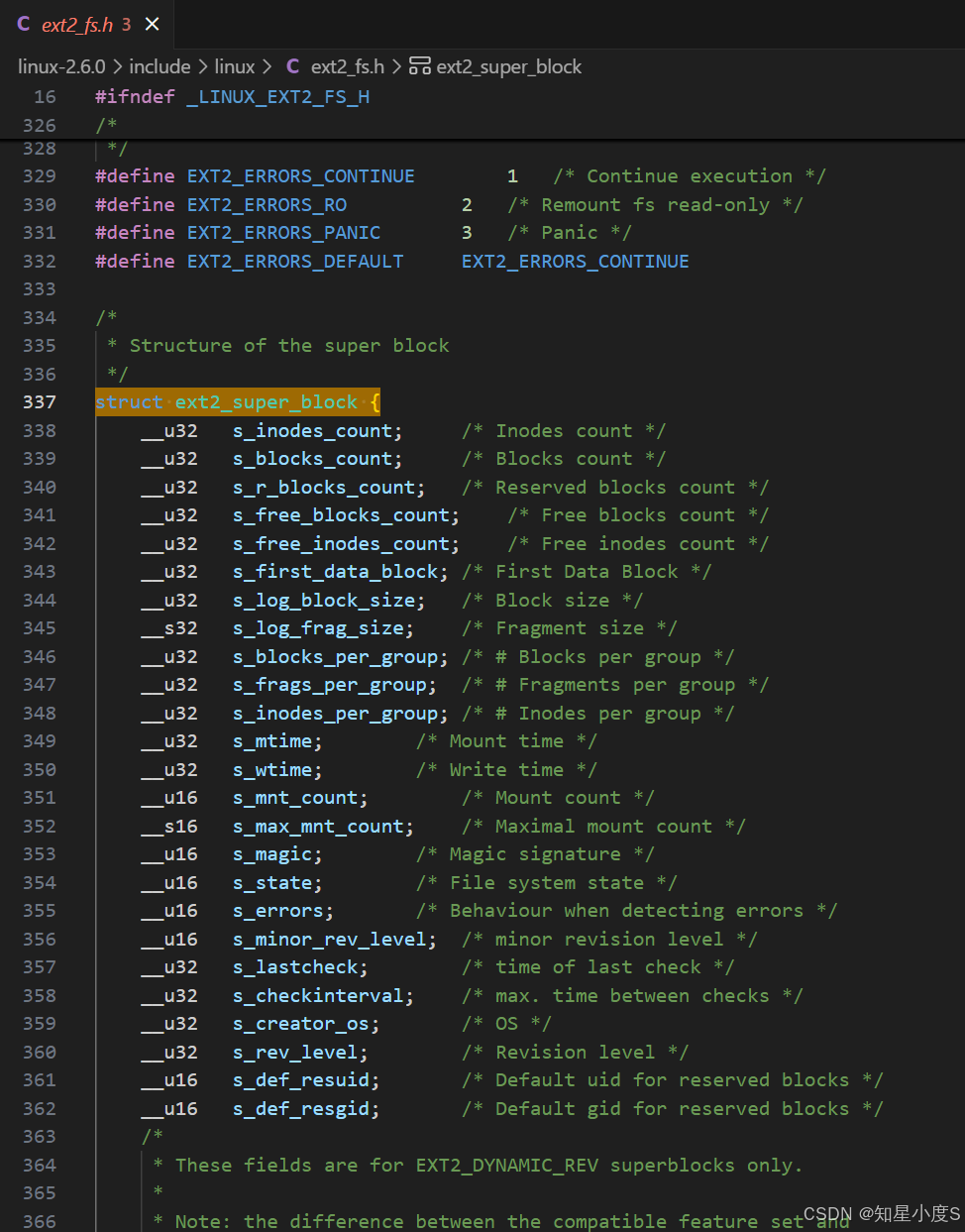
cpp
/*
* EXT2 文件系统超级块结构体定义
* 位于:linux-2.6.0/include/linux/ext2_fs.h
* 超级块存储文件系统的全局元数据信息
*/
struct ext2_super_block {
/* 文件系统容量统计 */
__le32 s_inodes_count; /* 文件系统中inode的总数 */
__le32 s_blocks_count; /* 文件系统中块的总数 */
__le32 s_r_blocks_count; /* 保留块数(供root用户使用) */
__le32 s_free_blocks_count; /* 空闲块数 */
__le32 s_free_inodes_count; /* 空闲inode数 */
__le32 s_first_data_block; /* 第一个数据块的位置(通常是0或1) */
/* 块和片段大小设置 */
__le32 s_log_block_size; /* 块大小的对数表示(用于计算实际块大小) */
__le32 s_log_frag_size; /* 片段大小的对数表示 */
/* 块组布局参数 */
__le32 s_blocks_per_group; /* 每个块组包含的块数 */
__le32 s_frags_per_group; /* 每个块组包含的片段数 */
__le32 s_inodes_per_group; /* 每个块组包含的inode数 */
/* 文件系统状态和时间戳 */
__le32 s_mtime; /* 最后挂载时间 */
__le32 s_wtime; /* 最后写入时间 */
__le16 s_mnt_count; /* 挂载次数计数 */
__le16 s_max_mnt_count; /* 最大允许挂载次数(超过需fsck检查) */
/* 文件系统标识和状态 */
__le16 s_magic; /* 魔数标识(0xEF53,用于识别ext2文件系统) */
__le16 s_state; /* 文件系统状态(干净/错误等) */
__le16 s_errors; /* 错误处理行为(继续/只读/panic) */
__le16 s_minor_rev_level; /* 次修订版本号 */
/* 文件系统检查和维护 */
__le32 s_lastcheck; /* 最后一次检查的时间戳 */
__le32 s_checkinterval; /* 两次检查之间的最大时间间隔 */
/* 系统信息 */
__le32 s_creator_os; /* 创建该文件系统的操作系统 */
__le32 s_rev_level; /* 主修订版本号 */
/* 默认权限设置 */
__le16 s_def_resuid; /* 保留块的默认用户ID */
__le16 s_def_resgid; /* 保留块的默认组ID */
/*
其他字段...
*/
};
/* 错误处理行为定义 */
#define EXT2_ERRORS_CONTINUE 1 /* 检测到错误时继续执行 */
#define EXT2_ERRORS_RO 2 /* 重新以只读方式挂载文件系统 */
#define EXT2_ERRORS_PANIC 3 /* 触发内核panic */
#define EXT2_ERRORS_DEFAULT EXT2_ERRORS_CONTINUE /* 默认错误处理行为 */
/*
* 关键字段计算说明:
*
* 实际块大小 = 1024 << s_log_block_size
* 例如:s_log_block_size=0 -> 1024字节块
* s_log_block_size=1 -> 2048字节块
* s_log_block_size=2 -> 4096字节块
*
* 块组数 = (s_blocks_count + s_blocks_per_group - 1) / s_blocks_per_group
*
* 魔数验证:s_magic必须等于0xEF53才能确认为ext2文件系统
*/备份策略: 超级块在多个块组中都有备份,确保即使部分扇区损坏,文件系统仍能恢复。
4.3其他结构
块组描述符表(GDT)------区域协调中心
GDT作为块组级别的管理结构,承担着承上启下的关键作用 :
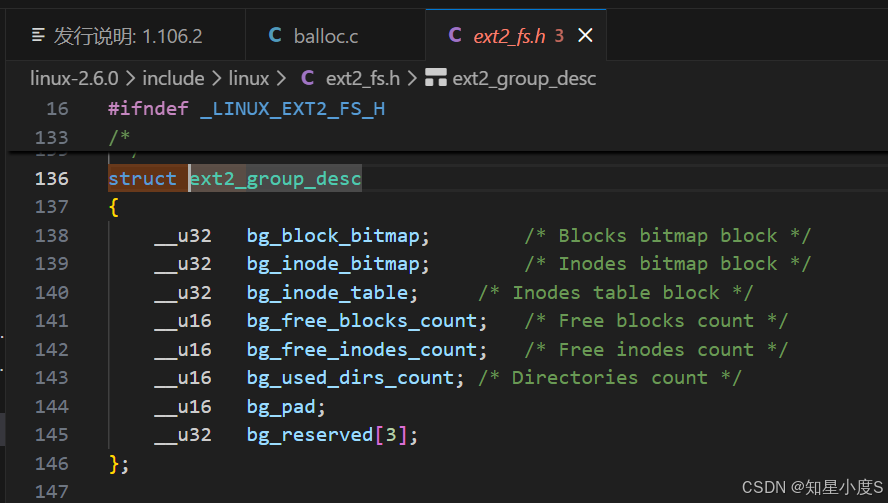
cpp
/*
* EXT2 文件系统 - 块组描述符结构体定义
* 文件位置:linux-2.6.0/include/linux/ext2_fs.h
* 作用:描述单个块组的属性和资源分配信息
*/
#ifndef _LINUX_EXT2_FS_H
#define _LINUX_EXT2_FS_H
/* 其他头文件内容... */
/*
* 块组描述符结构体
* 每个块组都有一个对应的描述符,记录该块组的资源分配状态
*/
struct ext2_group_desc
{
/* 关键指针字段 - 记录重要数据结构的物理位置 */
__le32 bg_block_bitmap; /* 块位图所在的块号
* 指向记录数据块使用情况的位图块
* 系统通过此位置快速定位块分配状态 */
__le32 bg_inode_bitmap; /* inode位图所在的块号
* 指向记录inode使用情况的位图块
* 用于快速查找可用inode */
__le32 bg_inode_table; /* inode表起始块号
* 指向该块组inode表的起始位置
* inode表存储所有文件的元数据信息 */
/* 资源统计字段 - 实时跟踪块组资源使用情况 */
__le16 bg_free_blocks_count; /* 当前空闲块数量
* 动态更新的计数器,反映可用数据块数
* 文件创建时递减,删除时递增 */
__le16 bg_free_inodes_count; /* 当前空闲inode数量
* 记录可用的inode数量
* 新文件创建时需要消耗一个inode */
__le16 bg_used_dirs_count; /* 目录文件数量
* 统计本块组中包含的目录数
* 用于负载均衡,避免目录过于集中 */
/* 对齐和预留字段 */
__le16 bg_pad; /* 填充字段,用于结构体对齐
* 确保后续字段正确对齐 */
__le32 bg_reserved[3]; /* 预留字段,为未来扩展保留
* 在早期EXT2版本中未使用 */
};
#endif /* _LINUX_EXT2_FS_H */管理职责:
资源定位:精确指向块组内各个关键组件的物理位置
状态统计:实时维护本块组的资源使用情况
负载均衡:通过目录计数等信息辅助文件分配决策
位图系统------资源分配的精确导航
块位图(Block Bitmap)
采用位级管理,每个比特对应一个数据块的使用状态;0表示空闲,1表示已占用;实现快速空间分配和回收,避免线性扫描整个磁盘
inode位图(Inode Bitmap)跟踪inode资源的分配状态;为新文件创建提供可用的inode编号;支持高效的inode资源回收和再利用
inode表------文件的元数据仓库
inode表集中存储文件的所有属性信息,形成完整的文件身份档案~
核心元数据包括:
文件类型和权限模式
所有者UID和GID
文件大小和时间戳(创建、修改、访问时间)
链接计数和块占用统计
数据块指针数组(直接、间接指针)
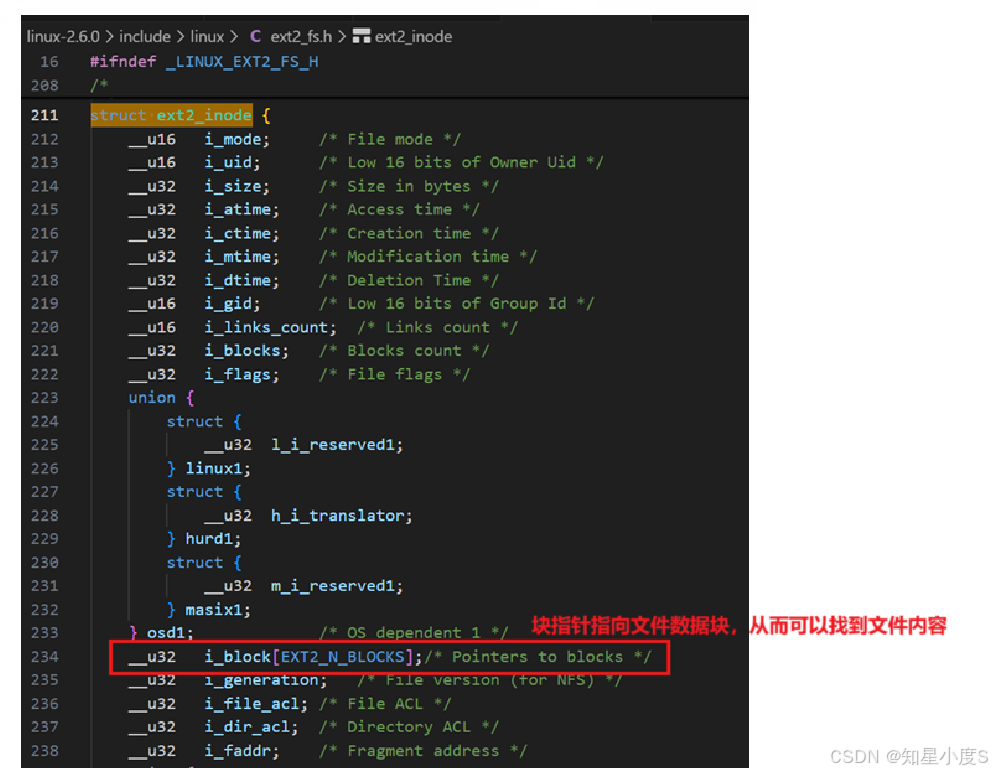
每个inode在分区内拥有唯一编号,通过精巧的指针系统建立文件内容与磁盘块的映射关系 。我们通过inode号找到inode结构;inode结构中包含一个块映射关系表(即块指针数组);这些块指针指向文件数据块,从而可以找到文件内容。所以整个文件访问过程:文件名 → 目录项 → inode编号 → inode结构 → 数据块指针 → 文件内容
数据块(Data Blocks)------内容存储实体
数据块是文件系统的最终存储载体,根据文件类型承担不同角色~
普通文件 :存储实际的文件内容数据
目录文件 :存储目录项列表,包含文件名到inode编号的映射【这也就是inode中不包含文件名属性,文件名属性存储在目录文件中】
特殊文件:设备文件、符号链接等有特殊的处理方式
数据块按照固定大小(通常为1KB、2KB或4KB)进行管理,确保存储效率和管理便利性。
整个EXT2文件系统通过这些组件的紧密配合实现高效运作:
文件查找:通过目录数据块找到文件名对应的inode编号
元数据读取:在inode表中定位并读取文件属性信息
内容定位:解析inode中的数据块指针,确定文件内容位置
空间管理:通过位图快速分配和回收存储资源
全局协调:超级块和GDT确保整个系统的稳定运行
关键点总结
同一个目录下,文件名不能重复。
在指定目录下新建文件的本质:将文件名到inode的映射写入当前目录的data block中。
对目录设置rw权限的本质:允许用户访问(读/写)目录的data block。
要查看目录下的文件列表(即读取目录的data block),需要该目录的读权限。
根目录是确定的,每个目录和文件都有唯一的inode编号。
Linux下通过文件路径定位文件的根本原因:目录的data block中存储了文件名到inode的映射。
Linux下访问文件都必须带路径(显式或隐式),打开文件时需要对路径进行解析。
进程的当前工作目录(cwd)的作用:提供隐式路径解析的起点。
4.4 数据存储的多级索引机制
inode通过15个指针管理文件数据,采用多级索引策略 ~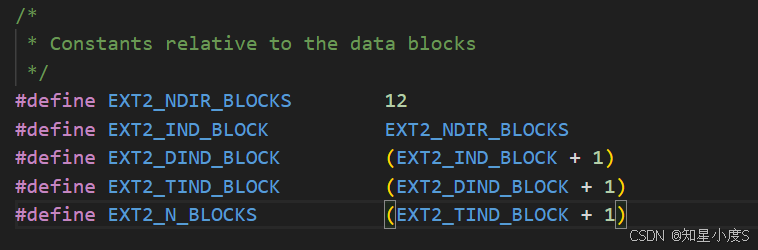
cpp
#define EXT2_NDIR_BLOCKS 12 /* 直接数据块数量:12个 */
#define EXT2_IND_BLOCK EXT2_NDIR_BLOCKS /* 一级间接块索引:12 */
#define EXT2_DIND_BLOCK (EXT2_IND_BLOCK + 1) /* 二级间接块索引:13 */
#define EXT2_TIND_BLOCK (EXT2_DIND_BLOCK + 1) /* 三级间接块索引:14 */
#define EXT2_N_BLOCKS (EXT2_TIND_BLOCK + 1) /* 总块指针数:15 */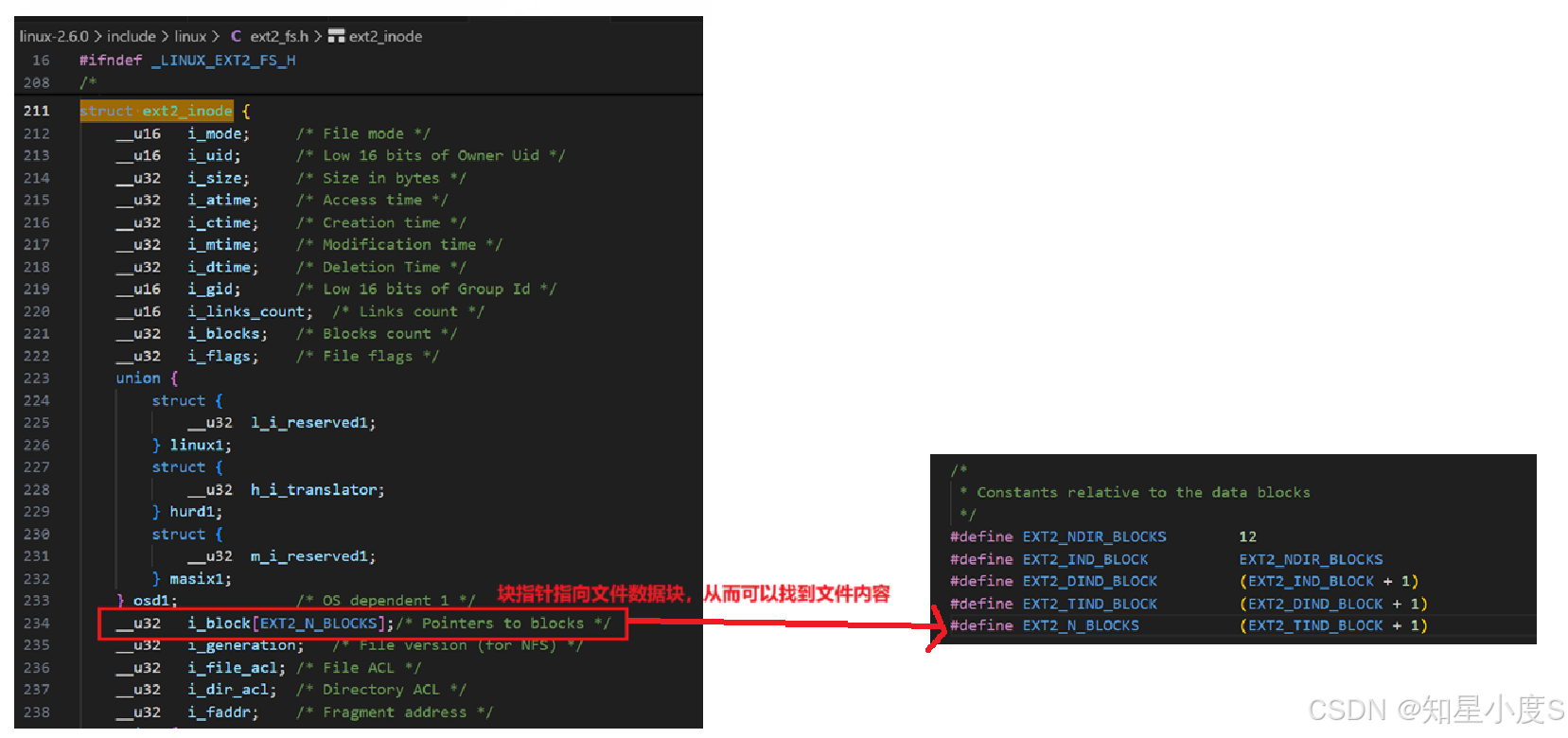
存储容量计算(假设块大小4KB):
| 索引级别 | 指针数量 | 存储容量 | 适用场景 |
|---|---|---|---|
| 直接指针 | 12个 | 48KB | 小文件 |
| 一级间接 | 1×1024 | 4MB | 中等文件 |
| 二级间接 | 1024×1024 | 4GB | 大文件 |
| 三级间接 | 1024³ | 4TB | 超大文件 |
实际应用比喻:
直接指针:像办公室抽屉,直接存放常用文件
一级间接:像办公室文件柜,通过目录查找文件
二级间接:像楼层档案室,需要两级查找
三级间接:像公司中央档案馆,支持海量存储
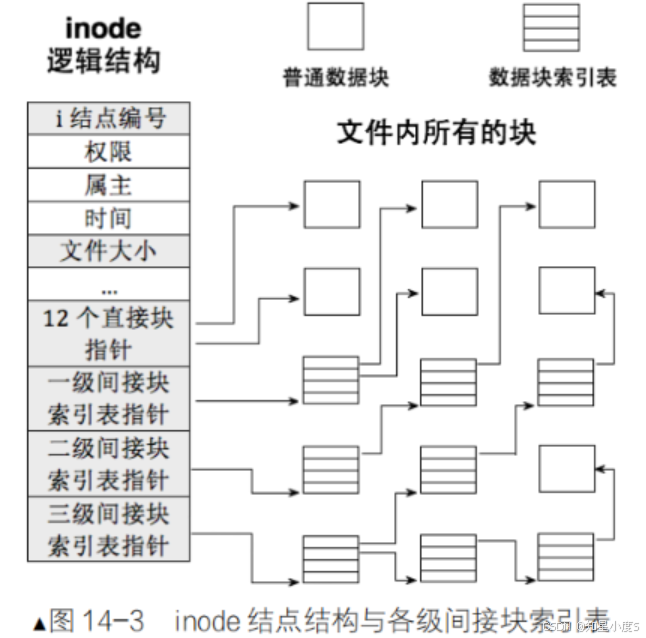
这样一个索引机制就可以满足我们不同文件大小的需要~
第五章 文件访问全流程解析😄
5.1 文件创建的四步曲
以touch test命令为例,深入分析文件创建过程:
1. 创建文件
$ touch test
2. 查看inode号
$ ls -i test

详细创建步骤:
步骤1:存储属性
内核在inode位图中查找空闲位
找到空闲inode(如1054467)
将文件元信息写入inode
步骤2:存储数据
内核在块位图中查找空闲数据块
分配数据块(如300、500、800)
将数据写入对应块
步骤3:记录分配情况
在inode的i_block数组中记录块分配情况
更新inode中的块计数和时间戳
步骤4:添加文件名到目录
在目录文件中添加(1054467, test)条目
更新目录文件的mtime
5.2 路径解析:从根目录到目标文件
想象一下你要去一个陌生地方【"请带我去 /home/xiaodu/GLearn/Linux_L/Learn/learn18"】
路径解析过程:
cpp
// 就像问路的过程
// 路径解析的伪代码
inode_t *resolve_path(const char *path) {
inode_t *current = root_inode; // 从根目录开始
foreach (component in path_components) {
if (!S_ISDIR(current->i_mode))
return ERROR_NOT_DIRECTORY;
// 读取目录内容,查找对应条目
directory_entry *entry = find_entry(current, component);
if (!entry)
return ERROR_NOT_FOUND;
// 切换到下一级目录的inode
current = get_inode(entry->inode);
}
return current;
}实际问路过程:
-
从"城市中心"(/)出发
-
找"home区"的路牌 → 进入home区
-
在home区找"xiaodu街道"的路牌 → 进入xiaodu街道
-
在xiaodu街道找"GLearn大楼"的路牌 → 进入GLearn大楼
-
在GLearn大楼找"Linux_L楼层"的路牌 → 进入Linux_L楼层
-
在Linux_L楼层找"Learn房间"的门牌 → 进入Learn房间
-
在Learn房间找到"learn18"这个位置
这样就会很麻烦,如果每次问路都要从城市中心开始,太慢了!所以就需要优化!
路径解析优化:dentry缓存
Linux通过dentry(目录项)缓存 来加速路径查找,每个文件其实都要有对应的dentry结构,包括普通文件。这样所有被打开的文件,就可以在内存中形成整个树形结构。
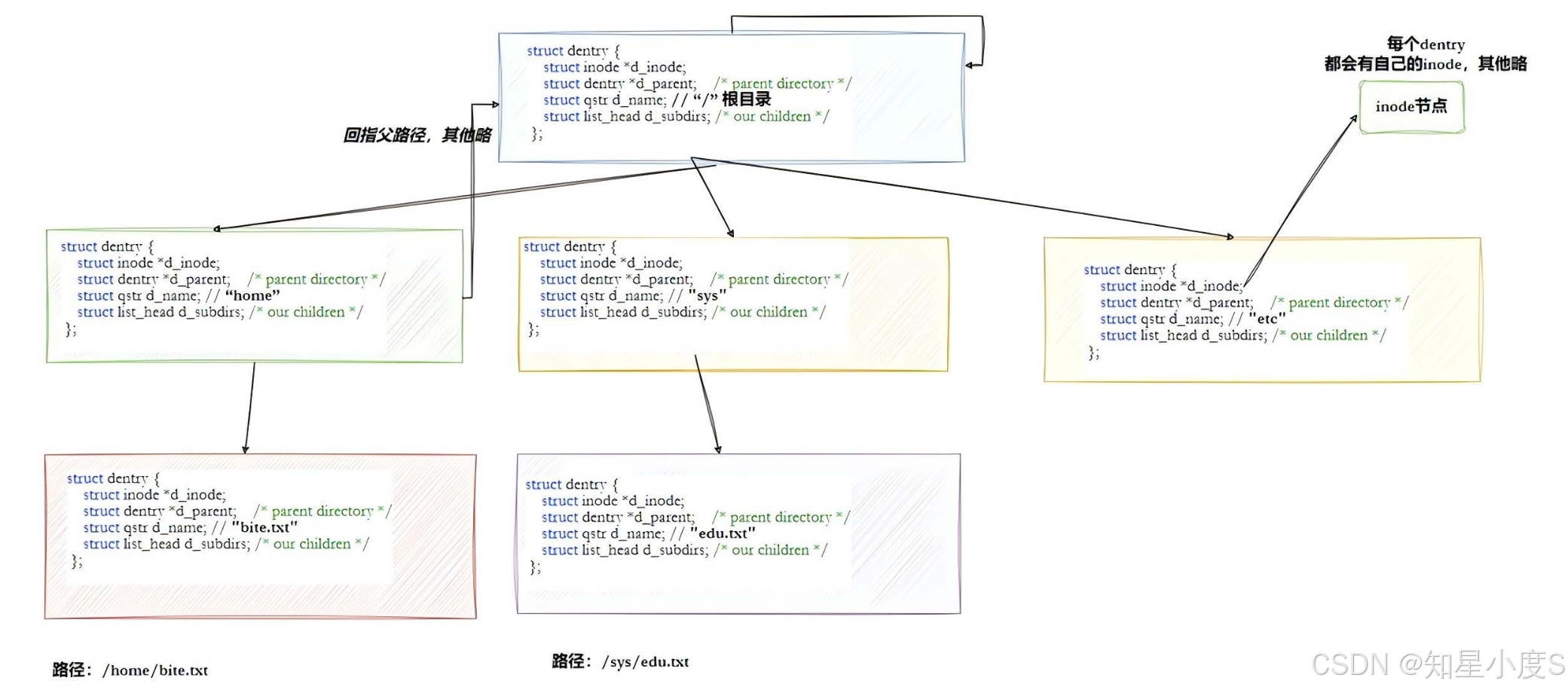
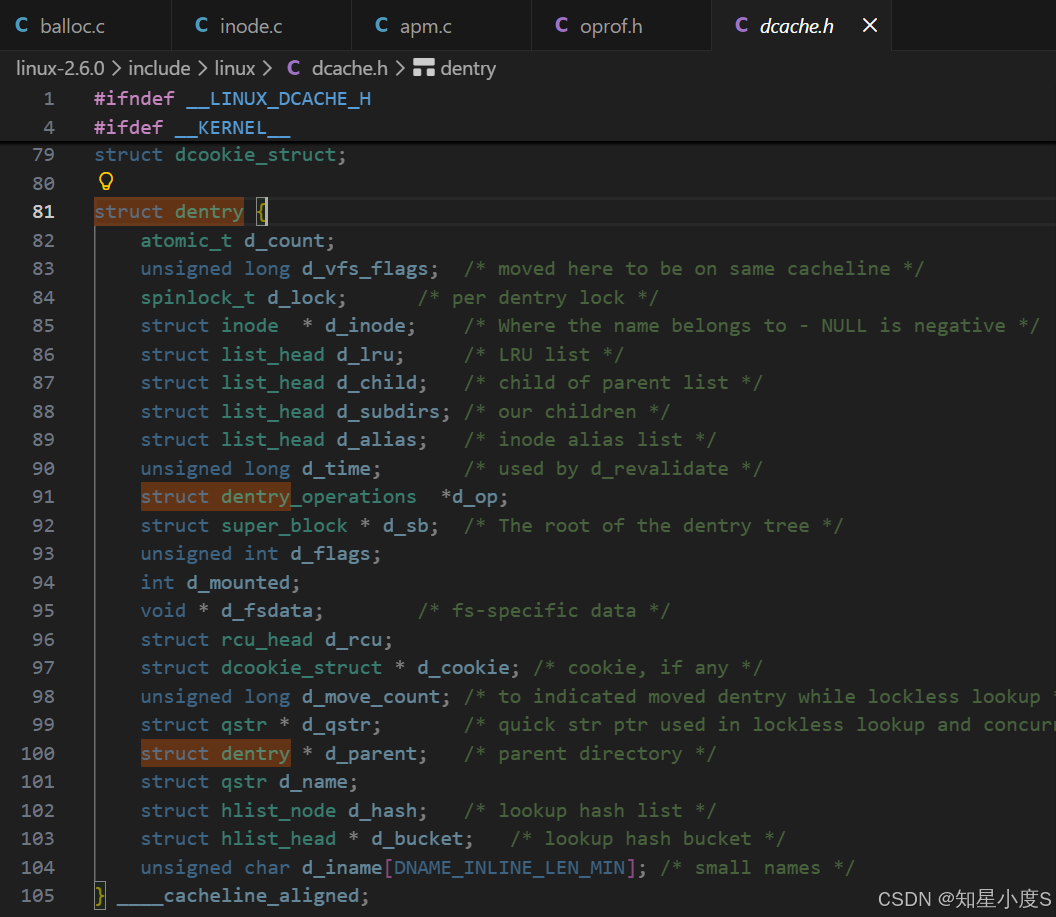
cpp
/*
* Linux内核dentry结构体定义
* 文件位置:linux-2.6.0/include/linux/dcache.h
*/
#ifndef __LINUX_DCACHE_H
#define __LINUX_DCACHE_H
#ifdef __KERNEL__
// ... 其他代码 ...
struct dentry {
/* === 基础管理字段 === */
atomic_t d_count; // 引用计数:跟踪有多少进程正在使用这个dentry
unsigned long d_vfs_flags; // VFS标志位:dentry的状态标志(特意放在同一缓存行优化性能)
spinlock_t d_lock; // 自旋锁:保护dentry结构的并发访问
/* === 核心关联字段 === */
struct inode * d_inode; // 指向对应的inode:NULL表示负dentry(文件不存在)
/* === 链表管理字段 === */
struct list_head d_lru; // LRU链表:用于最近最少使用算法的内存回收
struct list_head d_child; // 兄弟链表:链接到父目录的d_subdirs链表
struct list_head d_subdirs; // 子目录链表:这个目录的所有子dentry
struct list_head d_alias; // 别名链表:硬链接的dentry链表(多个文件名指向同一inode)
/* === 时间和操作字段 === */
unsigned long d_time; // 时间戳:用于dentry验证,检查是否过期需要重新验证
struct dentry_operations *d_op; // 操作函数表:dentry相关的操作函数指针
/* === 文件系统关联字段 === */
struct super_block * d_sb; // 超级块指针:指向所属文件系统的超级块
unsigned int d_flags; // 标志位:dentry的各种状态标志
int d_mounted; // 挂载计数:记录是否在此dentry上挂载了文件系统
void * d_fsdata; // 文件系统私有数据:特定文件系统可以存储额外信息
/* === 高级特性字段 === */
struct rcu_head d_rcu; // RCU回调头:用于RCU机制的安全释放
struct dcookie_struct * d_cookie; // 调试cookie:用于调试和性能分析
/* === 并发和移动管理 === */
unsigned long d_move_count; // 移动计数:在无锁查找期间指示dentry是否被移动
/* === 快速字符串访问 === */
struct qstr * d_qstr; // 快速字符串指针:用于无锁查找和并发操作
/* === 树形结构字段 === */
struct dentry * d_parent; // 父目录指针:指向父目录的dentry,形成目录树
struct qstr d_name; // 文件名结构:存储文件名和哈希值
/* === 哈希表管理 === */
struct hlist_node d_hash; // 哈希链表节点:用于dentry哈希表,快速查找
struct hlist_head * d_bucket; // 哈希桶指针:指向这个dentry所在的哈希桶
/* === 小文件名优化 === */
unsigned char d_iname[DNAME_INLINE_LEN_MIN]; // 内联文件名:短文件名直接存储,避免内存分配
} __cacheline_aligned; // 缓存行对齐:优化CPU缓存性能
#endif /* __KERNEL__ */
#endif /* __LINUX_DCACHE_H */dentry缓存的好处:
-
快速导航:记住常用路径,不用重复问路
-
路线共享:多个人可以记住同一条路线
-
智能更新:如果道路改建(文件删除),自动更新记忆
5.3 目录的本质:文件名到inode的映射
目录也是文件,其内容存储文件名到inode的映射~
目录就是一本"地址簿":
-
每个条目包含:名字 + 门牌号(inode)
-
通过名字查门牌号,通过门牌号找到实际房屋
这样就可以解决核心问题:
-
文件系统只知道:"这个inode里存着什么"
-
用户只知道:"我要找叫learn18的目录"
-
目录就是连接两者的桥梁
我们来写一个程序验证目录内容结构~
cpp
#include <dirent.h>
#include <stdio.h>
int main(int argc, char *argv[])
{
DIR *dir = opendir(argv[1]);
struct dirent *entry;
while ((entry = readdir(dir)) != NULL)
{
printf("filename: %s, Inode: %lu\n",
entry->d_name,
(unsigned long)entry->d_ino);
}
closedir(dir);
return 0;
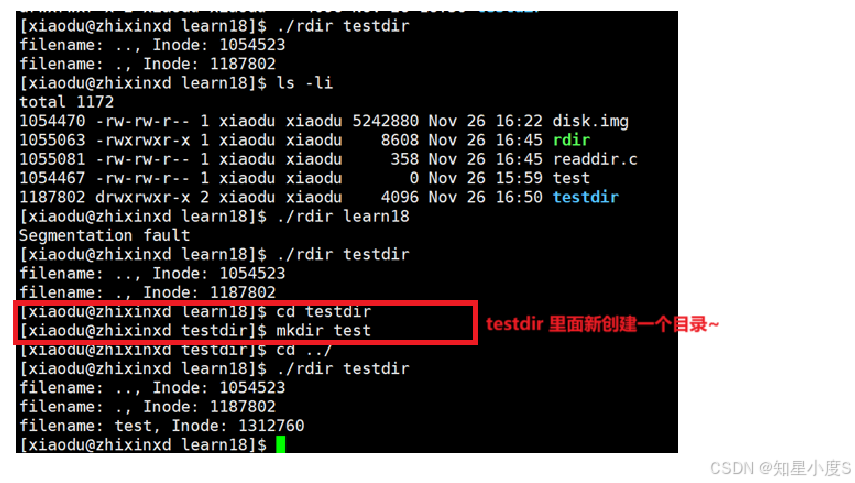
}我们通过opendir打开命令行参数指定的目录,然后使用readdir循环读取目录中的每个条目。对于每个目录项,程序打印出文件名和对应的inode号码。最后使用closedir关闭目录流。
运行结果:
现实世界的类比
| 计算机概念 | 现实世界类比 | 作用 |
|---|---|---|
| inode | 房屋的实际结构 | 存储文件的元信息 |
| 目录 | 地址簿/路牌 | 名字到房屋的映射 |
| dentry | 记住的路线 | 加速查找的缓存 |
| 路径解析 | 按地址导航 | 一步步找到目的地 |
第六章 挂载机制:连接文件系统与目录树😀
6.1 挂载的实际操作演示
- 创建磁盘镜像文件(模拟分区)
$ dd if=/dev/zero of=./disk.img bs=1M count=5
-
dd: 数据复制工具
-
if=/dev/zero: 输入文件,提供无限个零字节
-
of=./disk.img: 输出文件,创建名为disk.img的镜像文件
-
bs=1M: 块大小为1MB
-
count=5: 复制5个块,总共5MB
作用: 创建一个5MB的全零文件,模拟空磁盘

- 格式化为ext4文件系统
$ mkfs.ext4 disk.img
【将disk.img文件格式化为ext4文件系统】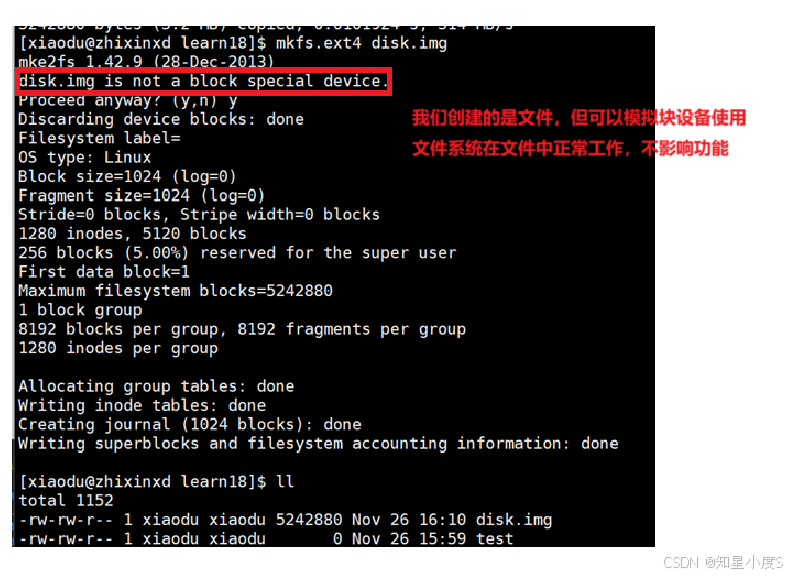
- 创建挂载点目录
$ mkdir /mnt/mydisk
- 挂载文件系统
$ sudo mount -t ext4 ./disk.img /mnt/mydisk/
-
mount: 挂载命令
-
-t ext4: 指定文件系统类型
-
./disk.img: 要挂载的设备/文件
-
/mnt/mydisk/: 挂载点目录

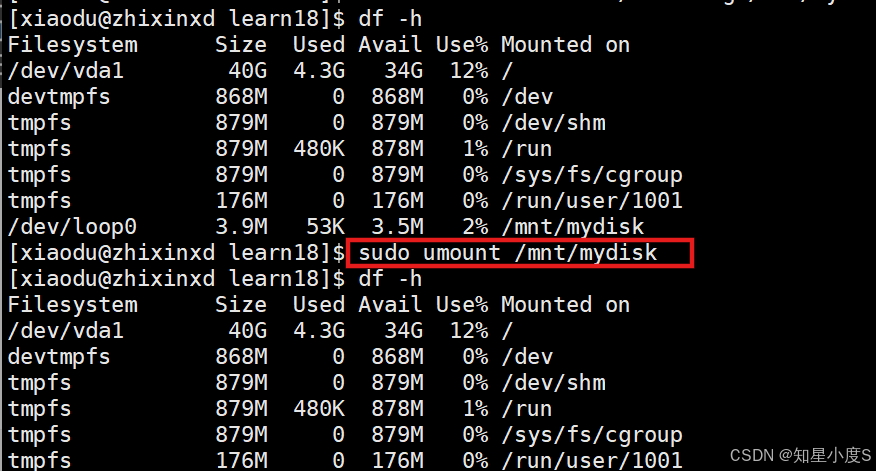
- 验证挂载结果
$ df -h
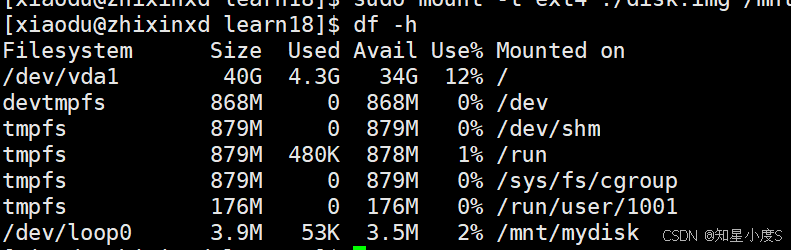
可以看到/dev/loop0设备已挂载到/mnt/mydisk,系统自动创建了loop设备来映射镜像文件~
loop设备说明 :
/dev/loop0是Linux的循环设备,允许将普通文件作为块设备使用,非常适合测试和学习。
- 使用后卸载
$ sudo umount /mnt/mydisk
6.2 挂载的技术原理
挂载的本质 :
将文件系统连接到Linux统一的目录树中,使得用户可以通过指定路径访问不同物理设备上的文件系统~
分区被写入文件系统后,需要挂载到某个目录才能使用;而当我们访问一个文件时,可以通过文件的路径前缀(即挂载点)来确定该文件位于哪个分区。
第七章 软硬链接:文件的多个入口🐷
7.1 硬链接:同一文件的多个名称
创建硬链接示例
$ touch test1
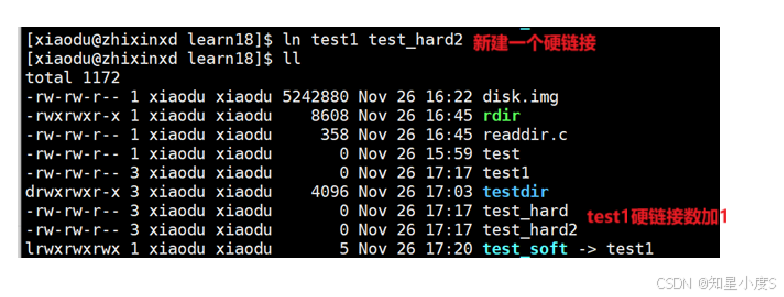
$ ln test1 test_hard # 创建硬链接
$ ls -li test1 test_hard
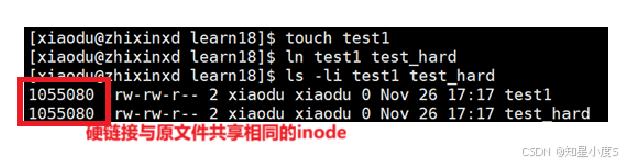
硬链接特性:
①与原文件共享相同的inode【不是独立的文件】本质是在;指定目录下,建立新的文件名和目标inode的映射关系并没有在系统层面创建新的文件
②不能跨文件系统创建
③ 删除一个名称不影响其他名称
④硬链接计数在inode中维护
硬链接的应用:文件备份:创建重要文件的硬链接作为备份
目录结构:.和..就是特殊的硬链接
版本管理:多个名称指向同一文件内容
硬链接就像给同一个文件起了多个别名,这些别名都指向磁盘上的同一份数据内容,共享同一个inode编号。
硬链接的限制:
- 在用户层面,系统不允许对目录创建硬链接,这是Linux/Unix系统的一个设计限制
原因:
防止目录树中出现循环引用,避免文件系统遍历陷入无限循环【路径环路问题】
保持目录树结构的完整性和一致性
只有内核才有权限创建目录硬链接(用于
.和..条目)

7.2 软链接:文件的快捷方式
创建软链接示例
$ ln -s test test_soft # 创建软链接
$ ls -li
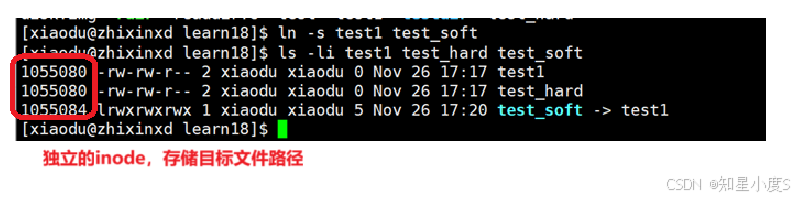
软链接特性:
①独立的inode【是独立的文件】,存储目标文件路径
②可以跨文件系统创建
③源文件删除后软链接失效
④文件类型为符号链接(l)
软链接的应用:快捷方式:为深层路径文件创建桌面快捷方式
版本切换:java -> java8,python -> python3
动态路径:指向配置文件的符号链接
硬链接数
接下来,我们来看看我们经常使用的【ls -l】第二列数字就是表示文件的硬链接数~
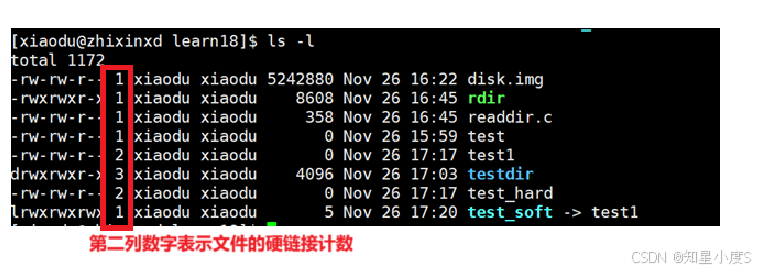
不同文件类型的硬链接计数规则不同,比如在当前目录下:
| 文件类型 | 硬链接数 | 说明 |
|---|---|---|
disk.img |
1 | 普通文件,只有一个文件名指向该inode |
rdir |
1 | 可执行文件,只有一个硬链接 |
readdir.c |
1 | 源代码文件,只有一个硬链接 |
test |
1 | 普通文件,只有一个硬链接 |
test1 |
2 | 硬链接文件,有两个文件名指向同一个inode |
testdir |
3 | 目录文件 ,包含: 1. 目录本身 2. 目录内的. 3. 子目录中的..指向它 |
test_hard |
2 | 硬链接文件 ,与test1指向同一个inode |
test_soft |
1 | 软链接文件,软链接本身是一个独立文件 |
关键区别:
-
硬链接:多个文件名指向同一个inode,硬链接计数增加
-
软链接:独立的文件,内容存储目标路径,硬链接计数始终为1
-
目录 :硬链接计数至少为2(自身 +
.),有子目录时会更多【子目录里面有..】
结语:文件系统的设计哲学
通过深入分析Ext系列文件系统,我们可以看到优秀系统设计的几个关键原则:
分层抽象:从物理CHS到逻辑LBA,再到文件系统抽象
空间效率:通过多级索引平衡小文件和大文件的存储效率
时间性能:通过缓存、预读等技术优化访问性能
可靠性:通过备份、日志等机制保证数据安全
扩展性:支持从KB到TB级别的文件存储
理解文件系统的工作原理,不仅有助于我们更好地使用和管理系统,更能启发我们在设计复杂系统时的思考方式。从磁盘的物理旋转到文件的逻辑访问,这中间的每一层抽象都体现了计算机科学的精妙之处。
♥♥♥本篇博客内容结束,期待与各位优秀程序员交流,有什么问题请私信♥♥♥
♥♥♥如果这一篇博客对你有帮助~别忘了点赞分享哦~♥♥♥
✨✨✨✨✨✨个人主页✨✨✨✨✨✨