本文章关注的三个问题,分别覆盖了接口设计规范 、数据同步实践 和算法逻辑实现三大开发核心场景,我会结合代码示例、最佳实践和底层逻辑,逐一拆解每个问题的关键要点,帮你不仅 "知其然",更 "知其所以然"。
一、@GetMapping ("/open/vdata/**"):带通配符接口的设计逻辑与作用
1.1 路径各部分的核心含义
先拆解这个接口路径的每一段,理解其设计意图:
| 路径段 | 含义与设计思路 |
|---|---|
/open |
开放接口标识:表明该接口是对外(或跨服务)开放的,通常无需强鉴权(或仅轻量鉴权),区别于内部接口(如/admin) |
/vdata |
模块 / 版本标识:v通常代表 version(版本),data代表数据模块,用于隔离不同版本 / 类型的开放数据接口(如后续可扩展/v2data) |
/** |
Ant 风格通配符:匹配任意层级的路径 (单层通配符是*,仅匹配当前层级),比如/open/vdata/user/1、/open/vdata/order/2025/list都能匹配 |
1.2 Ant 通配符规则(Spring MVC 核心)
Spring MVC 支持 Ant 风格的路径匹配,这是理解这类接口的基础:
| 通配符 | 作用 | 示例 | 匹配场景 |
|---|---|---|---|
? |
匹配单个任意字符(不含路径分隔符/) |
/open/vdata/? |
匹配/open/vdata/1、/open/vdata/a,不匹配/open/vdata/12 |
* |
匹配 0 个或多个任意字符(单层路径) | /open/vdata/* |
匹配/open/vdata/user、/open/vdata/order,不匹配/open/vdata/user/1 |
** |
匹配 0 个或多个任意字符(多层路径) | /open/vdata/** |
匹配所有以/open/vdata开头的路径,包括单层 / 多层 |
1.3 这类接口的核心作用
(1)开放数据统一入口
/open前缀明确了接口的 "开放属性",通常用于对外提供数据服务(如开放平台、跨系统数据共享),比如:
- 给合作伙伴提供用户行为数据:
/open/vdata/behavior/user/1001 - 对外暴露订单统计数据:
/open/vdata/order/stat/2025
通过/**通配符,可将所有开放数据请求收敛到一个接口入口,便于统一处理日志记录、限流、监控、鉴权,避免为每个数据接口单独配置规则。
(2)动态路径适配多维度数据请求
如果数据接口的路径层级不固定(比如不同业务线的数 - 据路径不同),/**能灵活匹配所有场景,无需为每个路径编写单独的接口方法。
代码示例:
java
@RestController
@RequestMapping("/open/vdata")
public class OpenDataController {
/**
* 匹配所有/open/vdata开头的GET请求
* @param request 获取完整请求路径,解析业务参数
* @return 对应业务数据
*/
@GetMapping("/**")
public ResponseEntity<Object> getOpenData(HttpServletRequest request) {
// 1. 获取完整请求路径(去除前缀后的部分)
String requestUri = request.getRequestURI();
String bizPath = requestUri.replace("/open/vdata/", "");
// 2. 根据bizPath路由到不同业务逻辑
Object data = switch (bizPath.split("/")[0]) {
case "user" -> getUserData(bizPath); // 处理用户数据请求
case "order" -> getOrderData(bizPath); // 处理订单数据请求
default -> throw new IllegalArgumentException("不支持的业务路径:" + bizPath);
};
// 3. 统一返回格式
return ResponseEntity.ok(data);
}
// 模拟用户数据处理
private Object getUserData(String bizPath) {
// 解析路径参数:如/user/1001 → 用户ID=1001
String userId = bizPath.split("/")[1];
return Map.of("userId", userId, "name", "张三", "createTime", "2025-01-01");
}
// 模拟订单数据处理
private Object getOrderData(String bizPath) {
return Map.of("statType", "month", "amount", 10000.0);
}
}(3)版本 / 模块隔离,便于扩展
vdata作为模块标识,后续若需升级接口(如数据格式变更),可新增/open/v2data/**接口,新旧版本并行运行,不影响现有调用方。
1.4 注意事项(避坑指南)
- 权限控制:开放接口必须做轻量鉴权(如 AppKey + 签名),避免直接暴露敏感数据;
- 路径参数校验 :
/**匹配范围广,需严格校验bizPath,防止非法路径攻击; - 性能优化:避免在接口内做复杂逻辑,可通过路由转发到具体业务服务;
- 文档说明 :明确
/**支持的具体路径规则,避免调用方误解。
二、从第三方接口获取数据并写入数据库:方法与最佳实践
2.1 核心流程(通用)
无论用哪种方法,核心流程都是: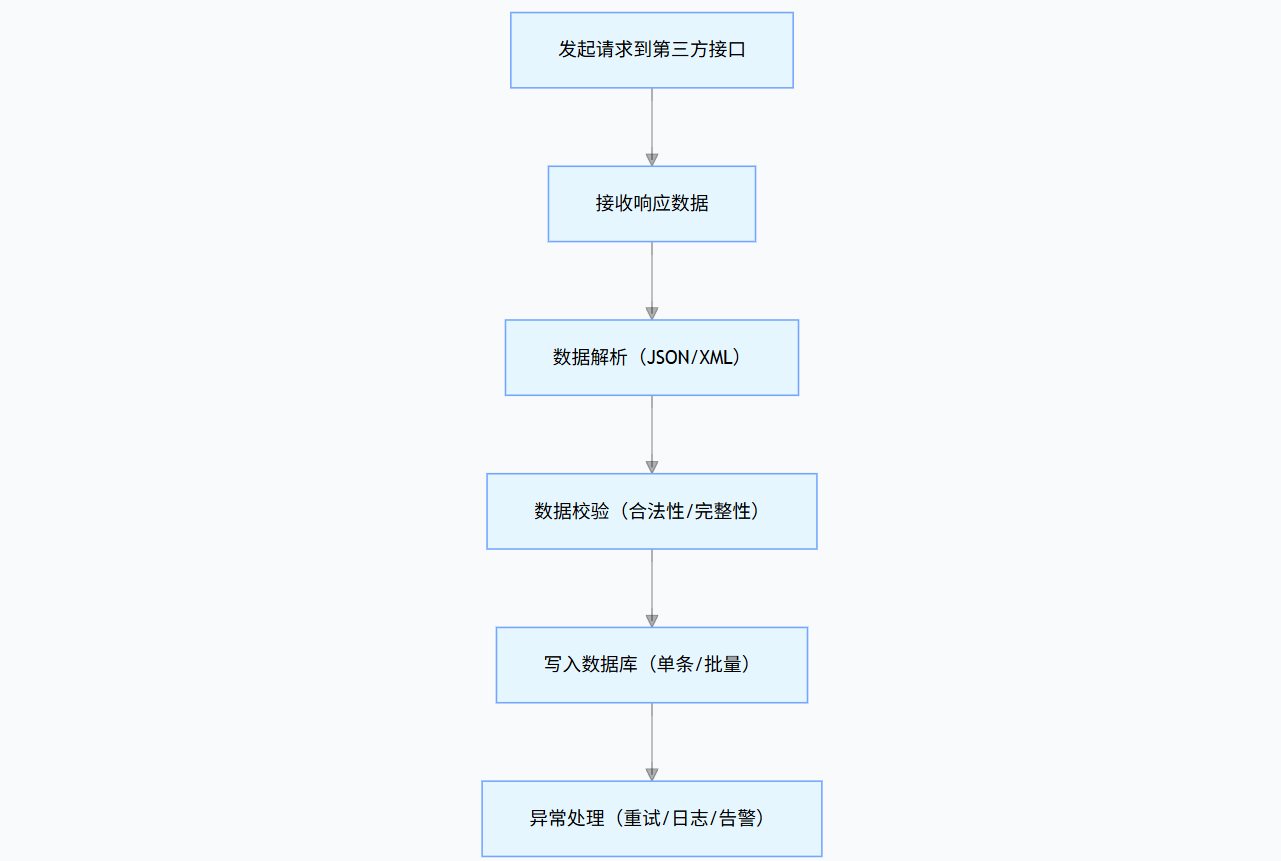
2.2 常用实现方法(附代码示例)
方法 1:原生 HTTP 客户端(HttpURLConnection)
特点 :JDK 内置,无第三方依赖,适合简单场景(不推荐复杂场景)。代码示例:
java
import java.net.HttpURLConnection;
import java.net.URL;
import java.nio.charset.StandardCharsets;
import java.util.Scanner;
// 第三方接口请求工具
public class HttpUrlConnectionUtil {
// 发送GET请求
public static String doGet(String apiUrl) throws Exception {
URL url = new URL(apiUrl);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setRequestMethod("GET");
conn.setConnectTimeout(5000); // 连接超时5s
conn.setReadTimeout(5000); // 读取超时5s
// 读取响应
Scanner scanner = new Scanner(conn.getInputStream(), StandardCharsets.UTF_8);
String response = scanner.useDelimiter("\\A").next();
scanner.close();
conn.disconnect();
return response;
}
}
// 数据同步示例
@Service
public class DataSyncService {
@Autowired
private UserMapper userMapper; // MyBatis Mapper
public void syncThirdPartyData() {
try {
// 1. 调用第三方接口
String apiUrl = "https://third-party.com/api/users";
String response = HttpUrlConnectionUtil.doGet(apiUrl);
// 2. 解析JSON(用FastJSON)
JSONArray userArray = JSON.parseArray(response);
// 3. 数据校验+写入数据库
for (Object obj : userArray) {
JSONObject userJson = (JSONObject) obj;
// 校验必填字段
if (userJson.getString("id") == null || userJson.getString("name") == null) {
log.warn("数据缺失必填字段:{}", userJson);
continue;
}
// 转换为实体类
UserEntity user = new UserEntity();
user.setThirdPartyId(userJson.getString("id"));
user.setName(userJson.getString("name"));
user.setCreateTime(new Date());
// 写入数据库
userMapper.insert(user);
}
} catch (Exception e) {
log.error("同步第三方数据失败", e);
// 可选:重试/告警
}
}
}方法 2:第三方 HTTP 客户端(OkHttp)
特点:性能好、支持异步 / 连接池、API 友好,是生产环境首选。
前置依赖(Maven):
java
<dependency>
<groupId>com.squareup.okhttp3</groupId>
<artifactId>okhttp</artifactId>
<version>4.12.0</version>
</dependency>代码示例:
java
@Service
public class OkHttpDataSyncService {
// 初始化OkHttpClient(单例)
private final OkHttpClient client = new OkHttpClient.Builder()
.connectTimeout(5, TimeUnit.SECONDS)
.readTimeout(5, TimeUnit.SECONDS)
.build();
@Autowired
private UserMapper userMapper;
// 异步请求+批量写入
@Async // 异步执行,避免阻塞主线程
public CompletableFuture<Void> syncDataAsync() {
// 1. 构建请求
Request request = new Request.Builder()
.url("https://third-party.com/api/users")
.addHeader("Authorization", "Bearer " + "第三方接口token")
.build();
// 2. 异步发送请求
client.newCall(request).enqueue(new Callback() {
@Override
public void onFailure(Call call, IOException e) {
log.error("请求第三方接口失败", e);
}
@Override
public void onResponse(Call call, Response response) throws IOException {
if (!response.isSuccessful()) {
log.error("第三方接口返回异常:{}", response.code());
return;
}
// 3. 解析响应
String responseBody = response.body().string();
JSONArray userArray = JSON.parseArray(responseBody);
// 4. 批量转换实体
List<UserEntity> userList = new ArrayList<>();
for (Object obj : userArray) {
JSONObject userJson = (JSONObject) obj;
if (userJson.getString("id") == null) continue;
UserEntity user = new UserEntity();
user.setThirdPartyId(userJson.getString("id"));
user.setName(userJson.getString("name"));
userList.add(user);
}
// 5. 批量写入数据库(提升效率)
if (!userList.isEmpty()) {
userMapper.batchInsert(userList); // MyBatis批量插入
}
}
});
return CompletableFuture.completedFuture(null);
}
}方法 3:Spring 封装工具(RestTemplate/WebClient)
特点 :Spring 生态首选,简化 HTTP 请求,支持自动转换 JSON / 对象。代码示例(RestTemplate):
java
@Configuration
public class RestTemplateConfig {
// 配置RestTemplate Bean
@Bean
public RestTemplate restTemplate() {
SimpleClientHttpRequestFactory factory = new SimpleClientHttpRequestFactory();
factory.setConnectTimeout(5000);
factory.setReadTimeout(5000);
return new RestTemplate(factory);
}
}
@Service
public class RestTemplateSyncService {
@Autowired
private RestTemplate restTemplate;
@Autowired
private UserMapper userMapper;
// 定时拉取数据(常用场景)
@Scheduled(cron = "0 0 1 * * ?") // 每天凌晨1点执行
@Transactional(rollbackFor = Exception.class) // 事务控制
public void syncDataTimed() {
try {
// 1. 调用第三方接口,自动转换为对象
String apiUrl = "https://third-party.com/api/users";
// 设置请求头
HttpHeaders headers = new HttpHeaders();
headers.set("Authorization", "Bearer " + "token");
HttpEntity<Void> requestEntity = new HttpEntity<>(headers);
// 自动解析为List<UserDTO>(第三方数据DTO)
ResponseEntity<List<UserDTO>> response = restTemplate.exchange(
apiUrl,
HttpMethod.GET,
requestEntity,
new ParameterizedTypeReference<List<UserDTO>>() {}
);
// 2. 数据校验+转换
List<UserDTO> userDTOList = response.getBody();
if (userDTOList == null || userDTOList.isEmpty()) {
log.info("第三方接口无数据");
return;
}
List<UserEntity> userList = userDTOList.stream()
.filter(dto -> dto.getId() != null) // 过滤无效数据
.map(dto -> {
UserEntity entity = new UserEntity();
entity.setThirdPartyId(dto.getId());
entity.setName(dto.getName());
entity.setPhone(dto.getPhone());
return entity;
})
.collect(Collectors.toList());
// 3. 批量写入
userMapper.batchInsert(userList);
} catch (Exception e) {
log.error("定时同步数据失败", e);
// 重试机制(Spring Retry)
throw new RuntimeException(e);
}
}
}2.3 关键优化点(生产环境必做)
| 优化点 | 实现方式 |
|---|---|
| 超时控制 | 所有 HTTP 客户端都设置连接 / 读取超时(3-5s),避免线程阻塞 |
| 重试机制 | 使用 Spring Retry 或手动重试(限幂等请求),处理网络波动 |
| 批量写入 | 避免单条插入,用 MyBatis 批量插入、JPA 的saveAll(),提升数据库写入效率 |
| 幂等性处理 | 基于第三方唯一 ID 做 "存在性校验",避免重复写入(如select count(*) where third_party_id = ?) |
| 异常处理 | 记录详细日志(请求参数、响应、异常栈),关键失败触发告警(钉钉 / 邮件) |
| 异步处理 | 用@Async或线程池异步执行,避免阻塞主线程 |
| 数据校验 | 用 Hibernate Validator 校验字段(如@NotBlank),避免脏数据 |
三、九宫格拼图(123456789)算法:BFS 实现最短路径
3.1 问题定义
九宫格拼图(数字华容道)是经典的状态空间搜索问题:
- 初始状态:3x3 网格,包含数字 1-8 和空白格(用 9 表示),数字乱序排列(如
1 3 2 4 5 6 7 8 9); - 目标状态:数字按顺序排列
1 2 3 4 5 6 7 8 9(9 是空白格,位于最后); - 移动规则:空白格(9)只能与上下左右相邻的数字交换位置;
- 求解目标:找到从初始状态到目标状态的最短移动路径。
3.2 核心算法:广度优先搜索(BFS)
BFS 是解决这类 "最短路径" 问题的最优选择,因为 BFS 按 "层级遍历" 状态,首次到达目标状态的路径即为最短路径。
3.2.1 什么是 逆序数?
逆序数是描述 ** 数字序列 "混乱程度"** 的一个概念,核心是统计序列中 "逆序对" 的数量。
1. 基础定义
- 逆序对 :在一个数字序列中,若前面的数 > 后面的数,这两个数就构成一个 "逆序对"。
- 逆序数:整个序列中所有逆序对的总数量。
2. 举个简单例子
比如序列 [3, 1, 2]:
- 检查每一对数:
- 3 在 1 前面,且 3>1 → 构成逆序对
(3,1) - 3 在 2 前面,且 3>2 → 构成逆序对
(3,2) - 1 在 2 前面,且 1<2 → 不构成逆序对
- 3 在 1 前面,且 3>1 → 构成逆序对
- 所以这个序列的逆序数是 2。
3. 结合九宫格拼图的场景
在九宫格拼图(数字华容道)中,逆序数是 **"去掉空白格(比如用 9 表示的空格)后的数字序列" 的逆序数 **,它决定了拼图是否有解:
- 若这个逆序数是 偶数 → 拼图有解;
- 若这个逆序数是 奇数 → 拼图无解。
九宫格实例
比如你之前提到的初始状态 1 3 2 4 5 6 7 8 9(9 是空白格):
- 去掉空白格后,序列是
[1, 3, 2, 4, 5, 6, 7, 8]; - 逆序对只有
(3, 2)→ 逆序数是 1(奇数); - 所以这个初始状态的九宫格拼图无解。
补充:逆序数的其他应用
除了九宫格拼图,逆序数还常用在:
- 排序算法中:表示序列需要 "交换多少次才能排好序"(比如冒泡排序的交换次数等于逆序数);
- 组合数学中:判断排列的奇偶性(逆序数为奇数的排列是 "奇排列",偶数则是 "偶排列")。
3.2.2 什么是 广度优先搜索BFS?
广度优先搜索(Breadth-First Search,简称 BFS)是一种 **"逐层扩散式" 的遍历 / 搜索算法 **,核心思想是 "先访问离起点最近的节点,再依次访问更远层的节点"------ 像往平静的水面扔石头,水波会从中心开始,一层一层向外扩散,直到覆盖所有区域。
一、BFS 的核心逻辑:"逐层遍历"+"队列辅助"
BFS 的实现必须依赖 "队列(Queue)"(先进先出的特性,刚好匹配 "先处理当前层、再处理下一层" 的需求),核心步骤可以总结为:
- 初始化 :将起点节点加入队列,并标记为 "已访问"(避免重复处理);
- 循环处理队列:只要队列不为空,就取出队首节点;
- 访问当前节点:处理当前节点的业务逻辑(比如判断是否是目标节点);
- 扩散下一层 :将当前节点的所有未访问过的相邻节点加入队列,并标记为 "已访问";
- 终止条件:找到目标节点(或遍历完所有节点)时结束。
二、用 "迷宫找最短路径" 理解 BFS
我们用一个简单的迷宫例子(0=通路,1=墙壁,S=起点,T=终点),看 BFS 怎么找最短路径:
TypeScript
迷宫(3行4列):
S 0 0 0
0 1 0 0
0 0 0 T- 起点 S 在
(0,0),终点 T 在(2,3)。
BFS 的遍历过程:
- 第 1 层(起点) :处理
(0,0),将相邻的(0,1)、(1,0)加入队列; - 第 2 层 :处理
(0,1),相邻的(0,2)加入队列;处理(1,0),相邻的(2,0)加入队列; - 第 3 层 :处理
(0,2),相邻的(0,3)、(1,2)加入队列;处理(2,0),相邻的(2,1)加入队列; - 第 4 层 :处理
(0,3),相邻的(1,3)加入队列;处理(1,2),相邻的(2,2)加入队列;处理(2,1),相邻的(2,2)已访问,跳过; - 第 5 层 :处理
(1,3),相邻的(2,3)(终点 T)加入队列 ------ 此时第一次到达终点,路径长度就是 5(这就是最短路径)。
三、BFS 的关键特点
| 特点 | 说明 |
|---|---|
| 最短路径保证 | 因为是 "逐层遍历",首次到达目标节点的路径,一定是起点到目标的最短路径 |
| 空间复杂度较高 | 需要存储 "当前层所有节点",如果节点数量多(比如大迷宫),队列会占用较多内存 |
| 无递归栈溢出问题 | 基于队列实现(迭代方式),不像 DFS(深度优先搜索)可能出现递归栈溢出 |
| 适用于 "层级 / 最短路径" 场景 | 比如二叉树层序遍历、迷宫最短路径、社交网络好友推荐(找最近的好友) |
四、BFS vs 深度优先搜索(DFS)
| 维度 | BFS | DFS |
|---|---|---|
| 遍历方式 | 逐层扩散 | 深度优先(一条路走到黑,再回溯) |
| 数据结构 | 队列(Queue) | 栈(Stack)/ 递归 |
| 最短路径 | 能直接找到最短路径 | 不能(需要遍历所有路径后比较) |
| 空间复杂度 | 取决于当前层节点数 | 取决于最大深度 |
| 适用场景 | 最短路径、层级遍历 | 路径存在性、回溯问题(如全排列) |
五、BFS 在九宫格拼图中的应用
回到之前的九宫格问题:BFS 的 "逐层遍历" 对应 "每一步移动后的状态"------ 每一层是 "移动 n 次后的所有可能状态",首次到达目标状态的层,就是 "最少移动次数"(最短路径),这也是为什么 BFS 是九宫格拼图找最短路径的基础算法。
3.2.3 算法核心步骤:
- 状态表示 :用字符串表示九宫格状态(如
132456789),便于存储和判重; - 移动规则:根据空白格(9)的位置,计算可移动的方向(上 / 下 / 左 / 右);
- 队列存储:队列中保存 "当前状态 + 移动路径",逐层遍历;
- 判重机制 :用
Set存储已访问的状态,避免循环遍历; - 终止条件:找到目标状态,返回移动路径。
3.3 代码实现(Java)
java
import java.util.*;
public class NineGridPuzzle {
// 目标状态
private static final String TARGET = "123456789";
// 方向数组:上、下、左、右(对应索引偏移量)
private static final int[] DX = {-3, 3, -1, 1};
private static final String[] DIR = {"上", "下", "左", "右"};
// BFS求解
public static String solve(String initial) {
// 1. 初始化队列:存储[当前状态, 移动路径]
Queue<String[]> queue = new LinkedList<>();
queue.add(new String[]{initial, ""});
// 2. 已访问状态集合(判重)
Set<String> visited = new HashSet<>();
visited.add(initial);
// 3. BFS遍历
while (!queue.isEmpty()) {
String[] curr = queue.poll();
String currState = curr[0];
String path = curr[1];
// 找到目标状态,返回路径
if (currState.equals(TARGET)) {
return path.isEmpty() ? "初始状态已是目标状态" : path;
}
// 找到空白格(9)的位置
int blankIndex = currState.indexOf('9');
// 遍历所有可移动方向
for (int i = 0; i < 4; i++) {
int newIndex = blankIndex + DX[i];
// 校验移动是否合法(边界判断)
if (isValidMove(blankIndex, newIndex, i)) {
// 交换空白格和相邻数字,生成新状态
char[] newStateArr = currState.toCharArray();
newStateArr[blankIndex] = newStateArr[newIndex];
newStateArr[newIndex] = '9';
String newState = new String(newStateArr);
// 未访问过的状态,加入队列
if (!visited.contains(newState)) {
visited.add(newState);
queue.add(new String[]{newState, path + DIR[i] + " → "});
}
}
}
}
// 无解(注:九宫格拼图有解的条件是逆序数为偶数)
return "该初始状态无解";
}
// 校验移动是否合法
private static boolean isValidMove(int blankIndex, int newIndex, int dir) {
// 索引越界
if (newIndex < 0 || newIndex >= 9) {
return false;
}
// 左移:空白格在第一列(0,3,6),不能左移
if (dir == 2 && blankIndex % 3 == 0) {
return false;
}
// 右移:空白格在第三列(2,5,8),不能右移
if (dir == 3 && blankIndex % 3 == 2) {
return false;
}
return true;
}
// 测试示例
public static void main(String[] args) {
// 初始状态:1 3 2 4 5 6 7 8 9(空白格在最后)
String initial = "132456789";
String result = solve(initial);
System.out.println("最短移动路径:" + result);
// 输出:最短移动路径:左 → (解释:空白格右移?实际是3和2交换,对应空白格左移)
}
}3.4 关键说明
(1)有解性判断
并非所有初始状态都有解:九宫格拼图有解的充要条件是 "逆序数(不包含空白格)为偶数"。
- 逆序数:对于序列
1 3 2 4 5 6 7 8,逆序对是 (3,2),逆序数 = 1(奇数)→ 无解; - 若初始状态是
1 2 3 4 5 9 7 8 6,逆序数 = 2(偶数)→ 有解。
(2)算法优化:A * 算法
BFS 效率较低(遍历所有状态),可优化为 A * 算法(启发式搜索):
- 启发函数:曼哈顿距离(每个数字到目标位置的距离之和);
- 核心逻辑:优先遍历 "曼哈顿距离最小" 的状态,减少无效遍历。
(3)状态可视化
可扩展代码,将字符串状态转换为 3x3 网格输出,便于调试:
java
// 状态可视化
public static void printState(String state) {
for (int i = 0; i < 9; i++) {
System.out.print(state.charAt(i) + " ");
if ((i + 1) % 3 == 0) {
System.out.println();
}
}
}四、核心要点总结
1. 通配符接口
/**是 Ant 风格通配符,匹配多层路径,适合开放数据接口的统一入口;- 核心价值:收敛请求、动态适配、版本隔离,需注意权限和参数校验。
2. 第三方数据同步
- 首选 OkHttp/RestTemplate,结合异步 + 批量写入提升效率;
- 生产环境必做:超时控制、重试、幂等性、事务、异常告警。
3. 九宫格算法
- BFS 是基础解法,保证最短路径;
- 有解性依赖逆序数,A * 算法可优化效率;
- 核心是 "状态表示 + 移动规则 + 判重"。
END
如果觉得这份基础知识点总结清晰,别忘了动动小手点个赞👍,再关注一下呀~ 后续还会分享更多有关面试问题的干货技巧,同时一起解锁更多好用的功能,少踩坑多提效!🥰 你的支持就是我更新的最大动力,咱们下次分享再见呀~🌟