目录
[2.1、HTAP 数据库融合](#2.1、HTAP 数据库融合)
[2.2、向量化计算 + 列存](#2.2、向量化计算 + 列存)
前沿
随着业务规模的指数级增长,单库单表早已无法承载海量数据与高并发访问。分库分表(Sharding)作为数据库水平扩展的核心手段,虽有效提升了系统吞吐能力,却也引入了"跨库 JOIN"这一经典难题。
引言:为什么跨库 JOIN 成为"拦路虎"?
如下所示:
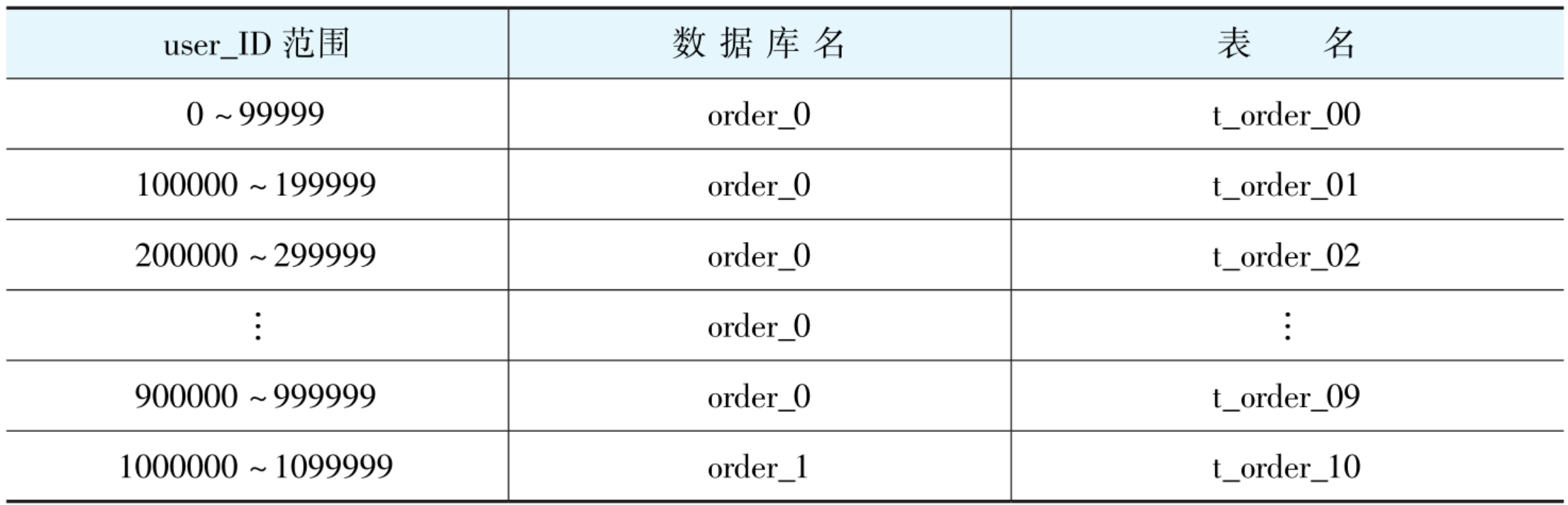
在单体数据库时代,JOIN 是关联查询的基石:
sql
SELECT o.order_no, p.name, o.amount
FROM orders o
JOIN products p ON o.product_id = p.id
WHERE o.user_id = 1001;然而,当 orders 表按 user_id 拆分到 4 个库,products 表因数据量小未分片(或按 category_id 分片),上述 SQL 将面临 物理隔离 ------ 数据库实例之间无通信能力,传统 JOIN 语义失效。
核心矛盾 :逻辑上的关联性 vs 物理上的分散性
本文将为你揭开跨库 JOIN 的面纱,提供可落地的工程化解决方案。
90% 的跨库 JOIN 问题,靠 "冗余字段" + "应用层查两次" 就能解决。
别想"透明 JOIN",那是个坑!
很多开发人员希望:
"有没有一个中间件,让我像单库一样写 JOIN,它自动搞定跨库?"
现实是 :能做到,但性能差、不稳定、大数据量直接 OOM。
❌ 生产环境强烈不推荐!
💡 真正的高手,从设计上避免跨库 JOIN。
1、跨库Join
1.1、单实例跨join
场景:同一个 MySQL 实例,多个数据库(schema)
MySQL 跨库进行 JOIN 操作本质上和单库 JOIN 操作原理类似,只是涉及到不同数据库的表。
在 MySQL 中进行跨库 JOIN 操作,只需要在表名前加上数据库名作为前缀,以明确指定表所在的数据库。
这种写法 **在单机 MySQL 中是合法的!**这不是"分布式",只是"多租户"或"模块隔离"的设计。
语法示例如下:
sql
SELECT column_name(s)
FROM database1.table1
JOIN database2.table2
ON database1.table1.column_name = database2.table2.column_name;这里 database1 和 database2 是不同的数据库名,table1 和 table2 是分别位于两个数据库中的表, column_name 是进行连接操作的关联列。
例如:
若要从 db1 数据库的 students 表和 db2 数据库的 scores 表中根据学生 ID 进行连接查询.
可以使用以下语句:
sql
SELECT s.name, sc.score
FROM db1.students s
JOIN db2.scores sc
ON s.id = sc.student_id;为什么能成功?
- db1 和 db2 虽然是不同数据库(schema),但物理上在同一台 MySQL 服务器上
- MySQL 引擎天然支持跨 schema JOIN
- 所有数据都在同一个进程、同一个磁盘、同一个事务上下文中
注意事项:
1.权限问题:
数据库用户需要对参与 JOIN 操作的所有数据库和表具备足够的权限,包括查询和连接操作所需的权限。如果权限不足,将无法执行跨库 JOIN 操作。
2.数据一致性:
由于数据分布在不同的数据库中,需要确保关联列的数据类型、编码格式等是一致的,否则可能会导致连接结果不准确或者出现错误。比如,一个数据库中的日期格式和另一个数据库中的日期格式不一致,可能会造成连接失败或生成错误的结果。
3.性能问题:
跨库 JOIN 操作通常会比单库 JOIN 操作消耗更多的性能,尤其是涉及到不同服务器上的数据库时。因为数据在不同数据库之间传输需要额外的网络开销。为了提高性能,可以尽量减少返回的数据量,使用合适的索引,以及对关联字段进行优化。
4.数据库版本兼容性:
不同版本的 MySQL 对跨库 JOIN 操作的支持可能存在差异,要确保所使用的数据库版本支持并能正常执行跨库 JOIN 操作。如果版本不兼容,可能会出现一些未知的错误。
1.2、分库分表跨join
如下所示:
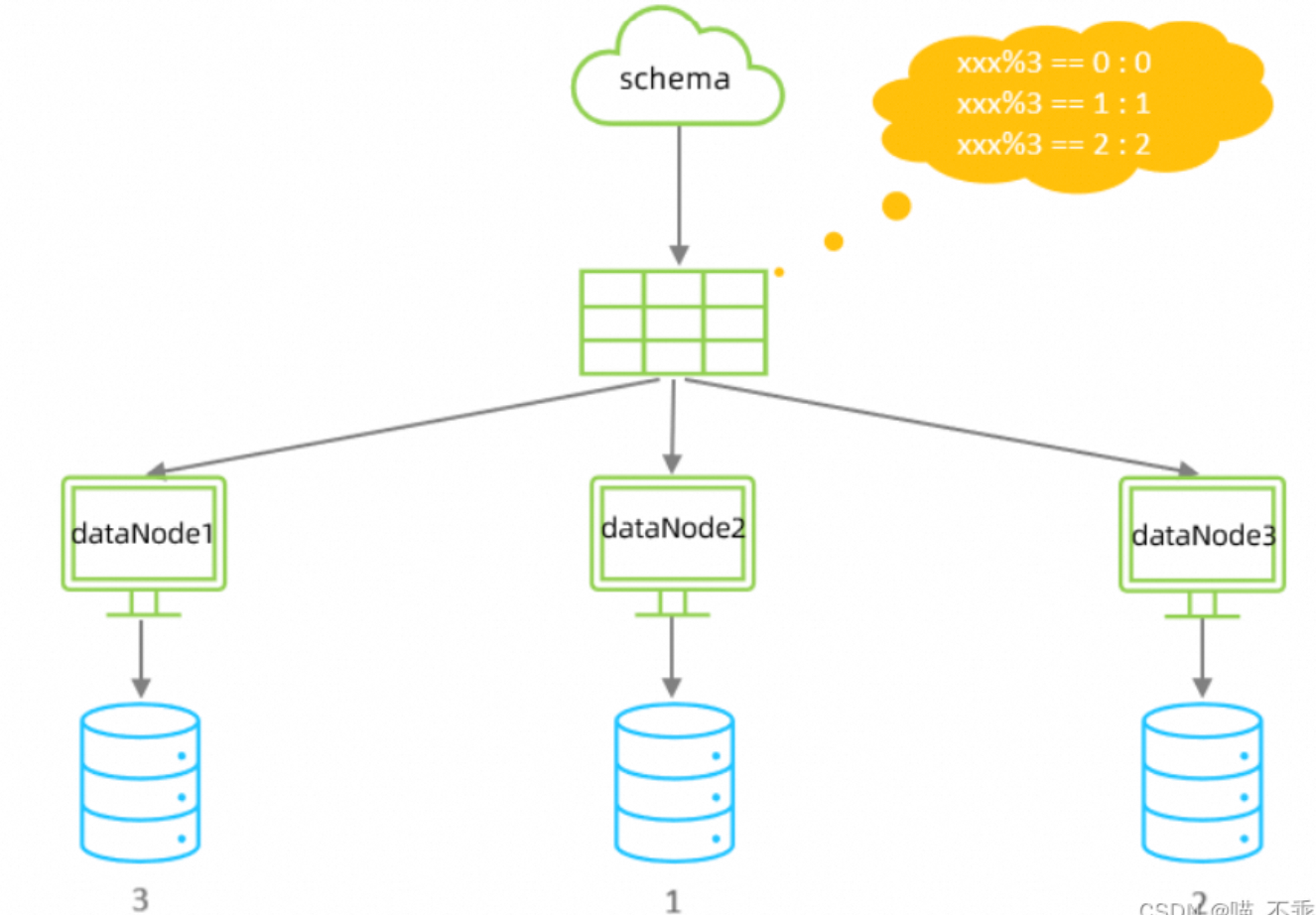
场景:db1 和 db2 是两个独立的 MySQL 实例:
| 表 | 所在位置 |
|---|---|
| orders | MySQL 实例 A(IP: 10.0.0.1) |
| products | MySQL 实例 B(IP: 10.0.0.2) |
此时你执行:
sql
SELECT * FROM db1.orders o JOIN db2.products p ON o.product_id = p.id;为什么会失败?
-
你的应用连接的是哪一个 MySQL?
-
如果连的是实例 A,它根本不知道 db2.products 在哪
-
如果连的是实例 B,它找不到 db1.orders
-
-
MySQL 本身不支持跨实例 JOIN
- 没有内置机制让 10.0.0.1 去访问 10.0.0.2 的数据
-
中间件(如 ShardingSphere)也不会真正执行这种 SQL
- 它会报错:Cannot support cross-database join for ...
🔥 核心区别 :同实例多库(schema)✅ vs 多实例分库 ❌
1.3、特殊数据库
如 TiDB、OceanBase, TiDB 是分布式数据库,天然支持跨节点 JOIN。
sql
-- 在 TiDB 中,即使 orders 和 products 在不同 region,也能 JOIN
SELECT * FROM orders o JOIN products p ON o.pid = p.id;- 但这依赖于 TiDB 的 分布式执行引擎,普通 MySQL 不行
小结:
| 环境 | 是否支持db1.t1 join db2.t2 | 说明 |
|---|---|---|
| 单机 MySQL,多 schema | ✅ 支持 | 同一实例 |
| MySQL 主从 / 读写分离 | ✅ 支持 | 仍是同一实例 |
| ShardingSphere / MyCat 分库 | ❌ 不支持 | 物理库分散 |
| TiDB / OceanBase | ✅ 支持 | 分布式数据库内置能力 |
| 普通分库(多个 MySQL 实例) | ❌ 不支持 | 无跨实例通信 |
2、方案实战指南
2.1、业务层聚合
适用场景:
关联数据量可控(< 1万条)、QPS 中等、延迟容忍度高,不是高频核心链路(比如后台管理、报表)。
原理:
在应用层分别查询多个数据源,通过内存计算完成"伪 JOIN"。
代码示例如下:
java
@Service
public class OrderService {
@Autowired
private OrderMapper orderMapper;
@Autowired
private ProductFeignClient productClient; // 或 ProductMapper
public List<OrderVO> getOrdersWithProducts(Long userId) {
// Step 1: 查询订单(分库分表)
List<Order> orders = orderMapper.selectByUserId(userId);
if (orders.isEmpty()) return Collections.emptyList();
// Step 2: 提取商品ID并去重
Set<Long> productIds = orders.stream()
.map(Order::getProductId)
.collect(Collectors.toSet());
// Step 3: 批量查询商品(可能跨服务/跨库)
Map<Long, Product> productMap = productClient.batchGet(productIds)
.stream()
.collect(Collectors.toMap(Product::getId, p -> p));
// Step 4: 内存组装
return orders.stream().map(order -> {
OrderVO vo = new OrderVO();
vo.setOrderNo(order.getOrderNo());
vo.setAmount(order.getAmount());
vo.setProduct(productMap.get(order.getProductId()));
return vo;
}).collect(Collectors.toList());
}
}⚠️ 关键优化点:
-
异步并行:使用 CompletableFuture 并发查询
-
批量接口:避免 N+1 问题
-
缓存兜底:Redis 缓存热点商品数据
| 问题 | 解决方案 |
|---|---|
| N+1 查询 | 用 IN 批量查(selectByIds) |
| 多次 DB 调用 | 用 CompletableFuture 并行查 |
| 商品服务不可用 | 加 Redis 缓存热点商品 |
代码如下所示:
java
// 并行查询示例
CompletableFuture<List<Order>> orderFuture =
CompletableFuture.supplyAsync(() -> orderMapper.selectByUserId(userId));
CompletableFuture<Map<Long, Product>> productFuture =
CompletableFuture.supplyAsync(() -> {
// 先查缓存
Set<Long> ids = ...;
Map<Long, Product> cache = redis.multiGet(ids);
// 缓存未命中再查 DB
return mergeCacheAndDb(cache, ids);
});
// 等待结果
List<Order> orders = orderFuture.get();
Map<Long, Product> productMap = productFuture.get();局限性
-
大数据量易导致内存溢出(OOM)
-
无法下推复杂过滤条件(如 where p.price > 100)
2.2、冗余字段
适用场景:
维度表(如商品、用户、配置)更新频率低,存储成本可接受,能接受 几秒到几分钟的数据延迟。
原理:
把关联表的关键字段,直接存到主表里,用空间换时间。
举个真实例子:订单系统.
| 原始设计(需要 JOIN) | 改造后(无需 JOIN) |
|---|---|
| orders 表只有 product_id | orders 表多了 product_name, product_price |
表结构设计如下:
sql
-- 改造后的订单表(重点看冗余字段)
CREATE TABLE `orders` (
`id` BIGINT PRIMARY KEY,
`user_id` BIGINT NOT NULL,
`product_id` BIGINT NOT NULL,
-- 👇 冗余字段(关键!)
`product_name` VARCHAR(100) NOT NULL, -- 商品名称
`product_price` DECIMAL(10,2) NOT NULL, -- 商品价格
`amount` INT NOT NULL,
`create_time` DATETIME
);如何保证数据一致?
不要用"双写"!容易丢数据。
推荐做法:监听 Binlog 自动同步。
关于canal的介绍如下: MySQL用Canal服务同步数据->ElasticSearch![]() https://dyclt.blog.csdn.net/article/details/149947508?spm=1011.2415.3001.5331
https://dyclt.blog.csdn.net/article/details/149947508?spm=1011.2415.3001.5331
代码如下所示:
java
// 使用 Canal 监听 product 表变更
@Component
public class ProductChangeListener {
@Autowired
private OrderService orderService;
@EventListener
public void onProductUpdate(CanalEntry.RowData rowData) {
// 解析 Binlog
String productId = rowData.getAfterColumnsList().stream()
.filter(col -> "id".equals(col.getName()))
.findFirst().get().getValue();
String newName = ...; // 新商品名
// 异步更新订单表中的冗余字段
orderService.updateProductName(productId, newName);
}
}
或者// 伪代码:监听 product 表变更,更新订单冗余字段
public void onProductUpdate(Product newProduct) {
// 找出所有引用了该商品的订单
List<Order> orders = orderMapper.selectByProductId(newProduct.getId());
// 批量更新冗余字段
for (Order order : orders) {
order.setProductName(newProduct.getName());
order.setProductPrice(newProduct.getPrice());
}
orderMapper.batchUpdate(orders);
}优势
-
查询性能极致(单表扫描)
-
支持任意 WHERE 条件,SQL 简单,不用改业务逻辑
-
架构简单,无外部依赖
📌 阿里实践:淘宝订单表冗余超 20 个商品/卖家字段,支撑每秒百万级查询。
工具推荐:
- Canal(阿里开源):监听 MySQL Binlog
- RocketMQ:解耦同步任务
- 定时对账:每天凌晨校验一次,兜底
2.3、全局表
适用场景:
小数据量、低频更新的配置类表(< 1万行)。
原理
在所有分片库中复制一份全量数据。
ShardingSphere 配置
java
# application.yml
spring:
shardingsphere:
rules:
sharding:
tables:
orders:
actual-data-nodes: ds$->{0..3}.orders_$->{0..1}
table-strategy:
standard:
sharding-column: user_id
sharding-algorithm-name: user-id-mod
broadcast-tables:
- country_code # 国家码表
- config_dict # 配置字典查询示例如下:
java
-- 可直接 JOIN,中间件自动路由到当前分片
SELECT o.order_no, c.country_name
FROM orders o
JOIN country_code c ON o.country_id = c.id
WHERE o.user_id = 1001;注意事项
- DDL/DML 操作会广播到所有分片
- 不适用于大表或高频更新场景
2.4、绑定表
适用场景:
主子表关系(如订单 & 订单项),且能使用相同分片键。
原理:
确保关联表的数据落在同一物理库,使 JOIN 可下推执行。
ShardingSphere 配置:
java
binding-tables:
- orders, order_items # 绑定 orders 和 order_items查询示例如下:
sql
-- 分片键 user_id 相同,整个 SQL 下推到单库执行
SELECT o.order_no, oi.sku, oi.quantity
FROM orders o
JOIN order_items oi ON o.id = oi.order_id
WHERE o.user_id = 1001;关键要求
-
主子表必须使用完全相同的分片算法
-
分片键需出现在 JOIN 条件或 WHERE 中
这是唯一能实现"真 JOIN"的方案,性能无损!
1.5、异步宽表
适用场景:
报表、BI、分析类查询,可接受分钟级延迟。
架构图如下:
diff
MySQL 分库分表
→ Binlog (Canal)
→ Kafka
→ Flink 实时计算
→ Doris 宽表Flink SQL 示例(构建订单宽表)
sql
-- 创建源表(Kafka)
CREATE TABLE orders_kafka (
order_id BIGINT,
user_id BIGINT,
product_id BIGINT,
...
) WITH (
'connector' = 'kafka',
'topic' = 'orders'
);
-- 创建维表(MySQL)
CREATE TABLE products_mysql (
id BIGINT,
name STRING,
price DECIMAL(10,2),
...
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://...',
'table-name' = 'products'
);
-- 创建结果表(Doris)
CREATE TABLE order_wide_table (
order_id BIGINT,
user_id BIGINT,
product_name STRING,
product_price DECIMAL(10,2),
...
) WITH (
'connector' = 'doris',
'fenodes' = '...'
);
-- 插入宽表
INSERT INTO order_wide_table
SELECT
o.order_id,
o.user_id,
p.name AS product_name,
p.price AS product_price
FROM orders_kafka o
JOIN products_mysql FOR SYSTEM_TIME AS OF o.proc_time p
ON o.product_id = p.id;优势:
- 支持任意复杂 JOIN + 聚合
- 查询性能毫秒级
- 解耦 OLTP 与 OLAP
2、前沿趋势:下一代解决方案
2.1、HTAP 数据库融合
TiDB 、OceanBase 等 HTAP 数据库支持 实时分析,内置分布式 JOIN 引擎。
示例(TiDB):
sql
-- 透明跨节点 JOIN
SELECT /*+ HASH_JOIN(orders, products) */ ...
FROM orders JOIN products ...;2.2、向量化计算 + 列存
Doris 、ClickHouse 通过向量化引擎加速 JOIN,配合列式存储降低 I/O。
2.3、智能查询路由
ShardingSphere 5.x 引入 Federate Query Engine,支持跨数据源联邦查询(实验性)。
3、总结与选型建议
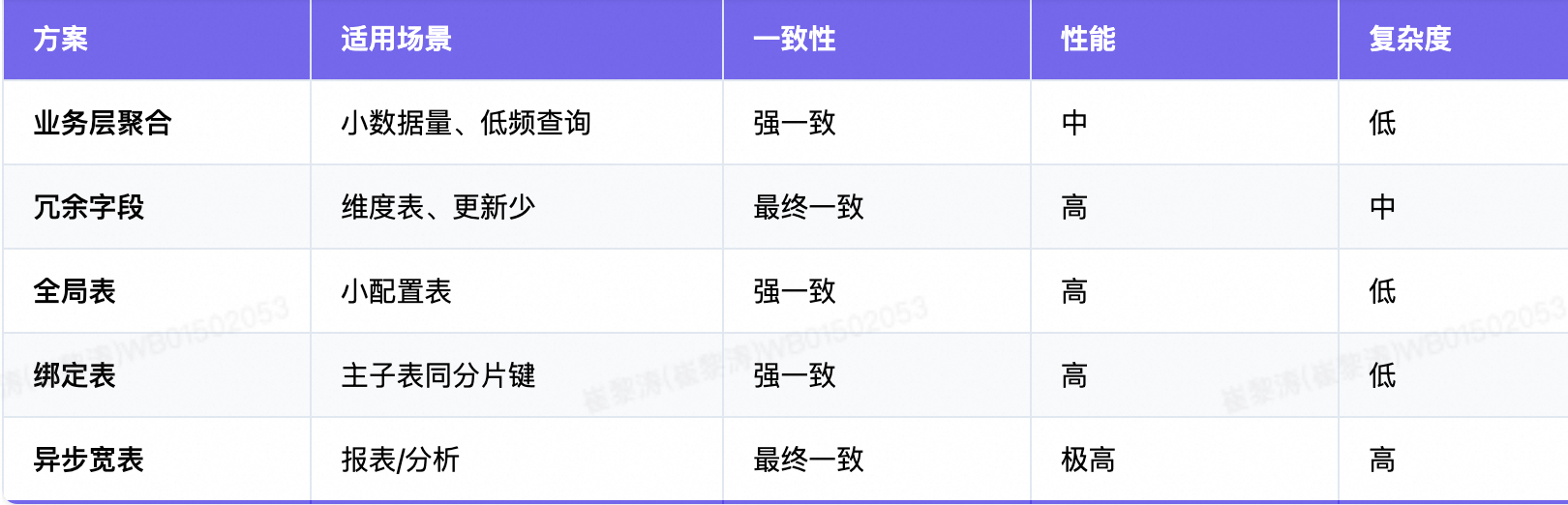
核心原则
- 设计优于补救:分片键选择决定 80% 的查询效率
- 读写分离:OLTP 走分库分表,OLAP 走宽表
- 避免过度工程:优先用冗余字段 + 业务层聚合解决 90% 场景
终极心法 :"分库分表不是技术问题,而是业务建模问题。"
在架构设计初期就规避跨库 JOIN,比事后引入复杂中间件更高效、更稳定。
参考文章: