RAG 是什么?
纯靠对话使用大模型时,我最常遇到的一个问题是:它表达能力很强,但不一定掌握我项目里的"事实" 。比如公司内部的接口命名、鉴权规范、最新的业务规则,它要么不知道,要么只能给出"看起来很对"的通用答案------一旦落到真实项目,就可能踩坑。
RAG(Retrieval-Augmented Generation)就是为了解决这个问题的。
RAG = 检索(Retrieval) + 生成(Generation)
- 检索:先从外部知识(你的文档、代码、规范)里找出与问题最相关的片段(证据)。
- 生成:把"问题 + 证据"交给 LLM,让它基于证据推理、总结并输出答案(最好带引用)。
我更愿意把它理解为:给大模型配了一个"可查询的外部知识库",让它在回答前先翻资料,再开口。
RAG 里的"检索",为什么离不开向量?
说到检索,很多人第一反应是"搜索引擎":关键词匹配、全文搜索、ES......这些当然能用,但它们更偏向"查字面",而 RAG 更常见的诉求是:
我问的是一句人话,但我希望系统能在知识库里找到"讲同一件事"的那几段内容。
这就引出了向量(更准确说:embedding 向量)------它解决的是"按意思找"的问题。
向量是什么?
作为前端开发人员,刚开始接触向量时不太好理解它的概念。后来我干脆不去纠结"高维空间"这些听起来很学术的词,而是换了个更好理解的说法:
向量可以先当成"坐标"。
生活里我们熟悉的坐标是二维、三维:平面一个点、空间一个点。坐标有个天然优势:能算距离。给两个点,在数学中就能算出它们离得远还是近,还能找"离我最近的那个点"。
关键问题来了:
既然点和点能算距离,那能不能让两段文字也像"点"一样能算距离?听上去抽象,但它背后是一个非常实用的需求:按语义去搜东西。
一个例子:我真正想搜的是"意思",不是"关键词"
假设我在做一个 AI 助手,我问它:
"登录过期怎么处理?"
我的知识库里不一定刚好有一段文字就叫"登录过期怎么处理"。它可能写的是:
"token 失效后的跳转策略:清空本地登录态,跳转到 /auth/sign-in,并保留 redirect 参数......"
这两句话字面并不完全重合,但意思非常接近:都是在说"登录失效以后系统应该怎么做"。
如果我用的是纯关键词搜索,它更偏向"有没有出现'登录过期'这几个字"。而我真正想要的是:
把知识库里"讲同一件事"的那段内容搜出来。
那向量到底怎么把"语义"变成"距离"?
我的理解是这样一条链路:
- 先把文字变成一串数字 (这一步靠 Embedding 模型,不是手写规则)
- 这串数字可以看成它的语义指纹(或者说"高维坐标")
- 指纹之间可以计算"像不像"(相似度/距离)
- 越像的,就越应该被检索出来
所以所谓"向量检索",本质就是:
我把"登录过期怎么处理"也转成语义指纹,然后在一堆文档片段的指纹里,找出最像"token 失效后的跳转策略"那几段。
"距离/相似度"怎么算?不用背公式,记住结论就够
常见的计算方式有两类名词:
- 余弦相似度:分数越大越像
- 欧氏距离(L2) :距离越小越像
我不需要记公式,只要记住:它们都是在回答同一个问题------两段内容到底像不像。
到这里,我们就理解了 RAG 里最关键的 Retrieval :我需要先从知识库里召回"能回答这个问题的证据片段",向量检索就是目前最通用的一种实现。
先把误区讲清楚:向量库不产出答案,LLM 才产出答案
很多人第一次听 RAG,会下意识认为流程是(起初我是这么理解的😂):
用户提问 → 向量数据库匹配 → 返回答案
这不准确。更准确的是:
用户提问 → 向量数据库找资料 → LLM 读资料写答案
- 向量数据库返回的是相关原文片段(chunks),它不负责"解释"和"组织语言"。
- LLM 的工作是:基于检索到的证据,输出更贴近人类阅读的答案,并能给出理由/引用。
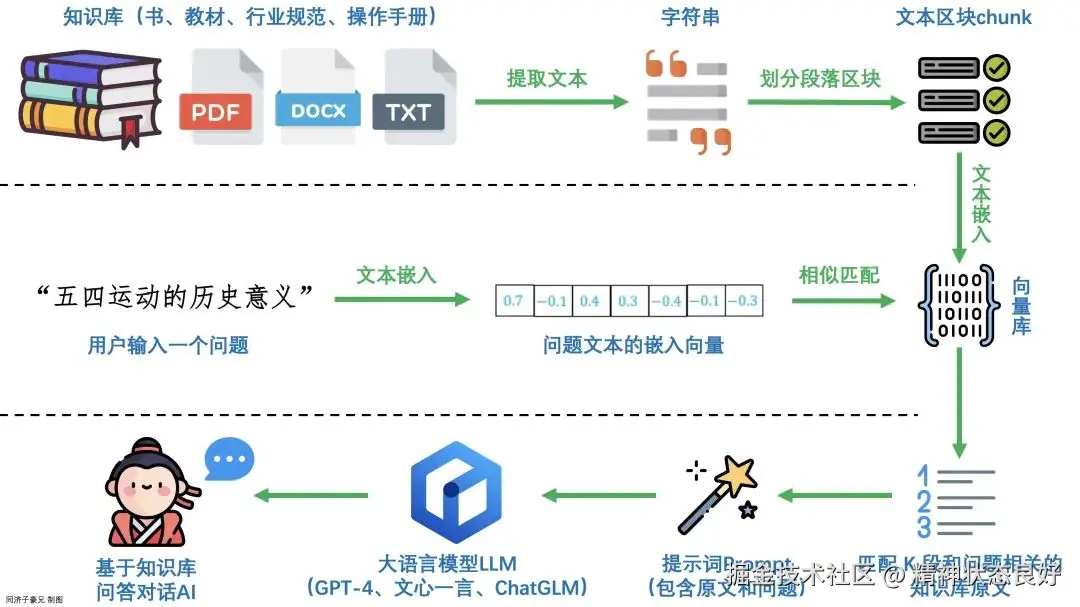
一个最小可落地的 RAG 系统:4 个组件 + 2 条链路
如果我们把 RAG 当成一套工程系统,它最小闭环可以拆成:
四个核心组件
- 知识库(数据源) :文档、Wiki、PRD、代码、FAQ......
- Embedding 模型(语义编码器) :把文本转成向量
- 向量数据库(语义搜索引擎) :存向量并支持相似度检索
- LLM(推理/生成引擎) :基于证据输出答案
常见实现里,向量库不只存"向量",也会存 chunk 原文 + 元数据(来源链接、章节、更新时间、权限等),便于引用和追溯。
同时,RAG 也可以很直观地拆成两条链路:
- Retrieval(检索链路) :Embedding + 向量库
- Generation(生成链路) :Prompt 组织 + LLM
RAG 的核心工作流:离线建库 + 在线问答
阶段一:离线建库(把原始资料变成"可检索索引")
我们要先把资料处理成适合检索的形态:
这里有个关键动作:切分 chunks 。
因为我们检索的通常不是整篇文档,而是"最相关的几段"。切分做得好,检索才会准。
阶段二:在线问答(先找证据,再让 LLM 输出)
用户提问后:
注意这一步的本质变化:
LLM 不再"凭空作答",而是"阅读证据后作答"。
RAG 的价值到底是什么?
最后我让AI帮我总结了一下:
- 让答案可追溯:答案背后有来源(文档/链接/代码位置),便于验证与评审。
- 让知识可更新:文档更新 → 重新入库/增量更新 → 立刻生效,不必重训模型。
- 让模型更少胡编:有证据约束,幻觉显著下降(仍可能发生,但更易发现)。
- 让私有知识可用:把内部资料接入 AI,回答更贴近项目真实情况,而不是"通用建议"。