论文信息
论文标题:Structure-aware Propagation Generation with Large Language Models for Fake News Detection
论文翻译:基于大型语言模型的结构感知传播生成用于虚假新闻检
论文作者:陈梦阳、魏灵伟、周伟、胡松林
论文来源:EMNLP 2025
发布时间:2025
论文地址:
论文代码:https://github.com/ICTMCG/GenFEND总结:
研究背景:社交媒体虚假新闻传播威胁公众信任与社会稳定,现有基于传播的检测方法受限于传播数据不完整,而利用大型语言模型(LLMs)生成合成传播数据的最新研究,又常忽略现实讨论中的结构模式。
核心方案:提出结构感知合成传播增强检测(StruSP)框架,可充分捕捉真实传播的结构动态,让 LLMs 生成真实且结构一致的传播数据,从语义和结构两维度将合成传播与现实传播明确对齐。
关键策略:设计双向进化传播(BEP)学习策略,通过结构感知混合采样和掩码传播建模目标,使 LLMs 更好地与现实传播的结构模式对齐。
实验结果:在三个公开数据集上的实验表明,StruSP 在多种实际检测场景中显著提升虚假新闻检测性能;进一步分析显示,BEP 能让 LLMs 在语义和结构上生成更真实、更多样化的传播数据。
1 研究动机&&研究背景
-
研究问题1:基于传播的虚假新闻检测方法在传播数据不完整时性能显著下降,如何缓解该问题?
研究背景:现有虚假新闻检测的传播类方法,通过建模新闻与评论的时间序列、传播树 / 传播图等拓扑结构捕捉传播模式,但受限于社交媒体数据收集的局限性及恶意用户互动等因素,实际场景中常面临传播数据不完整的问题,导致这类方法检测效果大幅受损。
-
研究问题2:现有基于大语言模型(LLM)生成合成传播的方法,因忽略真实传播的结构模式,生成内容与真实传播存在语义 - 结构不匹配,如何提升合成传播的真实性与结构一致性?
研究背景:近年 LLM 被用于通过角色扮演生成合成传播以缓解数据稀缺,但这类方法仅关注语义层面,生成的传播树存在结构过于均匀、缺乏真实传播的不规则分支与层级深度等问题,且内容情感多样性不足、语气趋于通用化,与真实传播的结构动态和语义特征存在显著差异,难以有效支撑下游虚假新闻检测(尤其在早期检测、跨平台泛化场景)。
2 介绍
LLM 生成合成传播的现状与核心缺陷
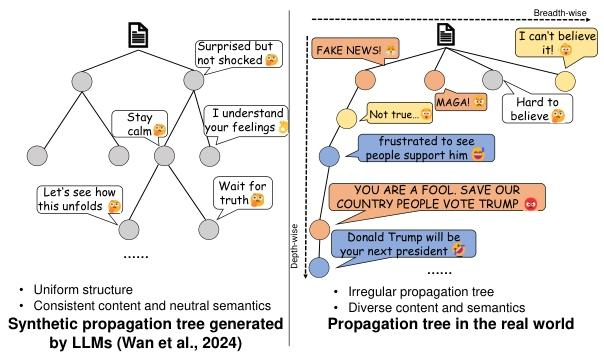
-
左侧:LLM 生成的合成传播树(以 Wan et al., 2024 的方法为例)
-
结构特点:均匀化(分支分布规则、层级简单)
-
内容特点:语义中立、一致性强(评论语气温和,如 "Stay calm""Wait for truth",情感波动小)
-
-
右侧:真实世界的传播树
-
结构特点:不规则(分支分布无规律,存在 "广度扩散""深度递进" 的复杂拓扑)
-
内容特点:语义多样化 、情感强烈(评论包含支持 / 反对、情绪性表达,如 "FAKE NEWS!""YOU ARE A FOOL",语气两极分化)
-
3 方法
3.1 核心概述(Overview)
模块构成
StruSP 框架包含两大核心模块,形成 "学习 - 增强" 的完整流程:
-
-
双向进化传播学习(Bidirectional Evolutionary Propagation, BEP):核心是让 LLM 学习真实传播的结构动态特征
-
结构感知传播增强(Structure-aware Propagation Enhancement, SPE):基于学习到的结构知识,生成合成传播以补充不完整数据
-
整体流程
-
先通过 BEP 模块,从真实传播数据中提取结构模式并训练 LLM;
-
再通过 SPE 模块,利用训练后的 LLM 对不完整传播树进行结构一致的扩展;
-
最终整合真实与合成传播数据,输入检测器完成虚假新闻二分类。
关键符号与输入输出
-
输入:单条新闻的不完整传播图 G_0' = (V', E') ( V' 含新闻节点和少量评论节点, E' 为互动关系)
-
输出:增强后的完整传播树 G_k' 及新闻真实性标签 \\hat{y} \\in \\{0,1\\} (0 为真实新闻,1 为虚假新闻)
框架
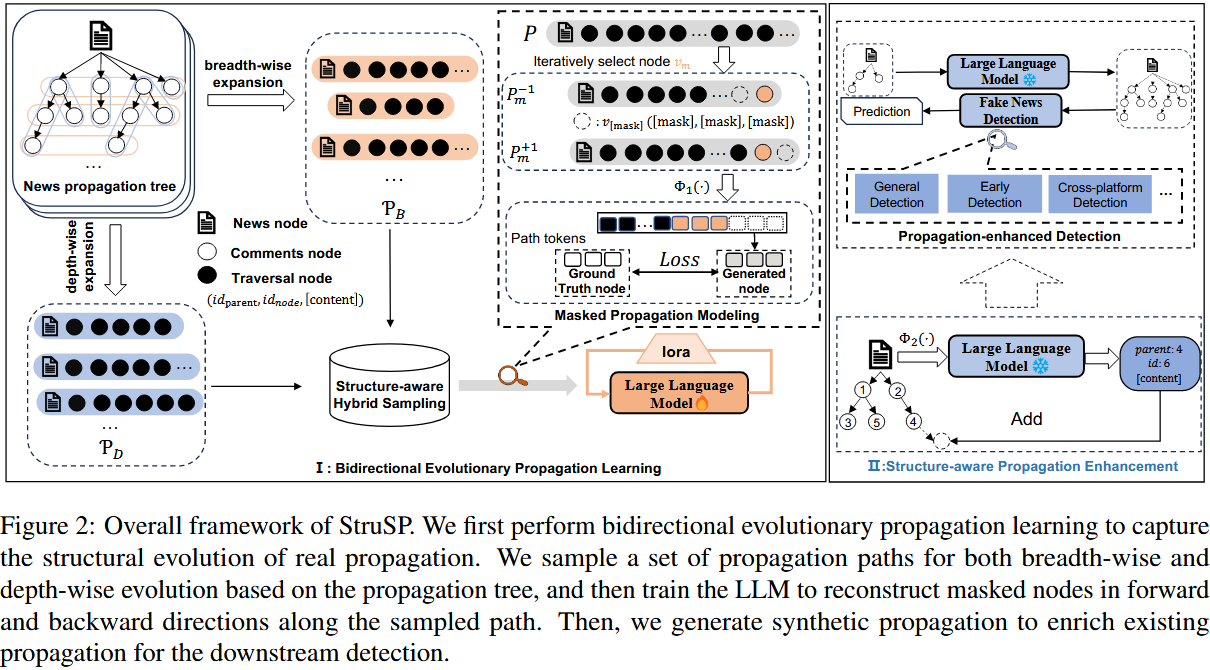
3.2 双向进化传播学习(Bidirectional Evolutionary Propagation Learning)
核心目标
让 LLM 掌握真实传播的 "双向结构动态"(广度扩散 + 深度递进),为生成真实可信的合成传播奠定基础,包含两大核心组件。
3.2.1 结构感知混合采样(Structure-aware Hybrid Sampling)
设计动机
真实新闻传播存在两种关键结构模式,需同时捕捉:
-
-
广度扩展(Breadth-wise Expansion):跨用户群体的广泛传播(如多用户直接评论新闻),形成多分支结构;
-
深度递进(Depth-wise Progression):用户间的分层互动(如多轮评论回复),形成长序列链结构。
-
采样方法
对真实传播图 G=(V, E) 采用两种图遍历策略,生成两类传播路径:
-
-
广度优先搜索(BFS):生成广度扩展路径 P_{\\mathcal{G}}\^B = BFS(\\mathcal{G}) ,捕捉多分支扩散模式;
- 形式:\\mathcal{P}_{\\text{BFS}} = \\{v_0 \\rightarrow v_{1,1} \\rightarrow v_{1,2} \\rightarrow \\dots \\rightarrow v_{1,k}\\}( v_0 为根节点, v_{1,i} 为 v_0 的同级子节点,k 为该层级节点数)
-
深度优先搜索(DFS):生成深度递进路径 P_{\\mathcal{G}}\^D = DFS(\\mathcal{G}) ,捕捉长序列互动模式。
- 形式:\\mathcal{P}_{\\text{DFS}} = \\{v_0 \\rightarrow v_{1,1} \\rightarrow v_{2,1} \\rightarrow \\dots \\rightarrow v_{d,1}\\} (d 为传播树的深度, v_{i,1} 为第i层的子节点)
-
路径表示格式
每条传播路径 P \\in P = P_B \\cup P_D 表示为节点序列:
P = (v_0, v_1, ..., v_{\|P\|})
其中每个节点 v_i 用三元组表示: v_i = \
-
-
id_{parent} :父节点索引(范围 \\{0,1,...,i-1\\} ,新闻节点 v_0 的父节点索引为 None);
-
i:当前节点索引;
-
c_i :节点内容(新闻节点为新闻文本,其他节点为评论文本)。
-
3.2.2 掩码传播建模(Masked Propagation Modeling)
设计动机
借鉴掩码语言模型(MLM)思路,让 LLM 学习传播路径中的结构依赖关系,而非仅依赖语义。
核心操作
-
节点掩码 :对每条采样路径 P,迭代选择节点 v_m ( m \\in \\{1,2,...,\|P\|\\} ),分别对其前序节点 v_{m-1} 和后序节点 v_{m+1} 进行掩码,生成两条子路径:
-
向后预测子路径: P_{m}\^{-1} = (v_0, ..., v_{m-2}, v_{\[mask\]}, v_m) (预测 v_{m-1} );
-
向前预测子路径: P_{m}\^{+1} = (v_0, ..., v_{m-1}, v_m, v_{\[mask\]}) (预测 v_{m+1} )。
-
-
文本化转换 :通过提示模板 \\Phi_1(\\cdot) 将子路径转换为自然语言指令,示例:
-
提示模板:Given the propagation tree: P_{m}\^{z} , please predict the masked comment node ({'parent node index': 'masked', 'node index': 'masked', 'content': 'masked'}) in a JSON format as same as other nodes.
-
传播路径
$P_{m}^{z}$:[(node_index: 0, parent_index: -1, content: "Donald Trump has been disqualified from running for president."), (node_index: 1, parent_index: 0, content: "I can't believe it! 😲"), v_[mask], (node_index: 3, parent_index: 1, content: "Not true...😯")] -
掩码节点 :
{parent node index: 1, node index: 2, content: "Hard to believe🤔"}
-
-
优化目标:最小化掩码节点的预测损失,公式如下:
\\mathcal{L} = \\sum_{P \\in \\mathcal{P}} \\left( \\sum_{m=0}\^{\|P\|-1} -log \\mathbb{P}(v_{m+1} \| \\Phi_1(P_{m}\^{+1})) - \\sum_{m=2}\^{\|P\|} log \\mathbb{P}(v_{m-1} \| \\Phi_1(P_{m}\^{-1})) \\right)
其中,\\mathbb{P}(v \| \\cdot) 表示 LLM 对节点 v 的预测概率。
3.3 结构感知传播增强(Structure-aware Propagation Enhancement)
设计动机
区别于传统 LLM 仅基于新闻内容生成传播的方式,以 "现有不完整传播树" 为引导,确保生成的传播与真实结构一致。
生成流程
-
序列转换 :将给定的不完整传播 G_0' 按时间顺序转换为传播序列 P_{\\mathcal{G}', 0};
-
迭代生成 :训练后的 LLM 基于前序传播序列,通过提示模板 Φ2(⋅) 生成下一个评论节点:
- 公式
v_i' = LLM(\\Phi_2(P_{\\mathcal{G}', i-1}))
P_{\\mathcal{G}', i} = P_{\\mathcal{G}', i-1} \\cup \\{v_i'\\}
-
- 提示模板:Given the propagation tree: {P_{G', i-1}}, please predict the next comment node in a JSON format as same as other nodes, i.e., {parent node index: num, node index: num, content: text}.
-
终止条件:生成节点数量达到预设值 k(实验中设为 30)。【迭代生成】
迭代生成算法
-
第 i 轮生成(\(i = t+1\) ):
-
输入:将当前序列 \(P_{\mathcal{G}', t}\)(即初始不完整序列)通过 \(\Phi_2(\cdot)\) 编码为提示词,示例:
"Given the propagation tree: (node_index: 0, parent_index: None, content: "Donald Trump has been disqualified from running for president."), (node_index: 1, parent_index: 0, content: "I can't believe it! 😲"), (node_index: 2, parent_index: 1, content: "Not true...😯"), please predict the next comment node in a JSON format as same as other nodes, i.e., {parent node index: num, node index: num, content: text}."
-
生成:LLM 输出新节点 \(v_{t+1}'\)(需满足结构一致性,如父节点索引为 0/1/2 中的有效值,自身索引为 \(t+1\),内容与上下文语义连贯);
-
更新:将 \(v_{t+1}'\) 加入序列,得到 \(P_{\mathcal{G}', t+1} = P_{\mathcal{G}', t} \cup \{v_{t+1}'\}\)。
-
-
第 2 轮至第 \(k-t\) 轮生成(\(i = t+2\) 至 \(i = k\)):
重复上述步骤,每次均以 "上一轮更新后的完整序列 \(P_{\mathcal{G}', i-1}\)" 为输入,通过 \(\Phi_2(\cdot)\) 编码后让 LLM 生成下一个节点 \(v_i'\),再更新序列。
-
终止条件:当序列长度达到预设值 k(生成节点总数满足要求),迭代停止。
生成节点的验证过滤
为确保生成节点的有效性,所有 \(v_i'\) 需通过三层自动化验证后,才能加入序列(避免结构异常或语义无效):
-
-
语法过滤:检查 LLM 输出是否为合规 JSON 格式,排除格式错误节点;
-
结构过滤:验证父节点索引是否在当前序列中存在、节点索引是否连续递增、无自环 / 循环等拓扑异常;
-
内容过滤:过滤空内容、重复文本、LLM 拒绝生成的 boilerplate 信息,确保评论内容有效。
-
核心优势
生成的节点同时满足:
-
-
结构一致性:父节点索引符合真实传播的拓扑关系;
-
语义连贯性:内容与现有传播的上下文匹配。
-
3.4 传播增强检测(Propagation-enhanced Detection)
步骤 1:传播树重建
聚合迭代生成后的完整序列 P_{\\mathcal{G}', k} 中所有节点信息,重建增强后的传播树 G_k' 。
步骤 2:虚假新闻分类
将增强后的传播树 G_k' 输入训练好的检测器 f(\\cdot) ,输出新闻真实性预测标签 \\hat{y} ,公式如下:
\\hat{y} = f(\\mathcal{G}_k')
** 关键说明**
-
-
检测器 f(\\cdot) 可采用主流传播基检测模型(如 GCN、Bi-GCN、RAGCL 等);
-
增强后的传播树融合了真实传播的核心特征与合成传播的补充信息,解决了数据不完整问题。
-
4 实验
4.1 数据集(Datasets)
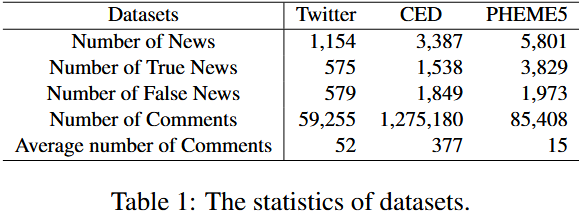
1. 数据集选择与背景
实验采用 3 个公开且具有代表性的虚假新闻数据集,覆盖不同语言(英文、中文)、平台(Twitter/X、Weibo)和场景(普通新闻、紧急事件新闻),确保结果的通用性和鲁棒性。
2. 数据集核心信息
**  **
**
3. 数据划分方式
遵循 Chen 等人(2025)的划分标准,所有数据集按 7:1:2 比例分为训练集、验证集和测试集,确保训练与评估的独立性。
4. 跨平台检测数据处理
针对跨平台检测场景(Twitter→CED),为消除语言差异影响,使用 LLaMa3-8B-Instruct 将 CED 测试集的中文文本翻译为英文。
4.2 Baselines(基准模型)
实验选取两类基准模型,分别用于对比 "虚假新闻检测性能" 和 "合成传播生成质量",确保评估的全面性。
1. 虚假新闻检测基准
| 模型名称 | 模型类型 | 核心原理 |
|---|---|---|
| BERT | 文本内容基模型 | 预训练语言模型,取最后一层输出输入分类器,仅依赖新闻文本特征 |
| dEFEND | 文本 + 评论基模型 | 设计句子 - 评论共注意力子网络,融合新闻内容与评论特征进行检测 |
| GCN | 传播结构基模型 | 对新闻传播图执行图卷积操作,学习结构特征用于分类 |
| Bi-GCN | 传播结构基模型 | 基于传播图建模双向传播关系,捕捉更丰富的结构依赖 |
| EBGCN | 传播结构基模型 | 采用贝叶斯图卷积网络,从不确定传播中学习结构特征 |
| RAGCL | 传播结构基模型 | 通过自适应传播图对比学习,学习鲁棒的谣言表示 |
| LLM-text | LLM 基检测模型 | 仅输入新闻文本,让 LLM 直接进行虚假新闻分类 |
| LLM-comments | LLM 基检测模型 | 输入新闻文本 + 真实评论,让 LLM 进行分类 |
| LLM-propagation | LLM 基检测模型 | 输入完整传播信息(新闻 + 评论 + 传播结构),让 LLM 进行分类 |
2. 合成传播生成基准
| 模型名称 | 核心原理 |
|---|---|
| GenFEND | 定义 30 个特定用户画像(性别、年龄、教育水平),让 LLM 扮演这些用户生成评论 |
| DELL | 通过迭代过程让 LLM 扮演指定用户,可直接评论新闻或回复已有评论,生成传播结构 |
| LLM(未微调) | 直接使用未经过 BEP 训练的 LLaMa3-8B-Instruct,按 SPE 模块流程生成传播 |
4.3 实验内容、结果与结论
1. 实验核心目标
-
验证 StruSP 框架在不同检测场景下的虚假新闻检测性能;
-
评估 StruSP 生成的合成传播在结构和语义上与真实传播的一致性;
-
验证 StruSP 各核心组件(BEP、SPE、SHS、MPM)的有效性;
-
验证 StruSP 对不同 LLM 骨干网络的通用性。
2. 实验 1:一般检测(General Detection)
实验内容
-
场景:使用完整的真实传播数据 + 合成传播数据进行虚假新闻分类;
-
评估指标:Accuracy(准确率)、Macro-F1、Precision(精确率)、Recall(召回率)、AUC;
-
核心对比:StruSP 增强后的检测模型(如 StruSP w/RAGCL)与各类基准检测模型、LLM 生成基准增强模型的性能。
实验结果
** 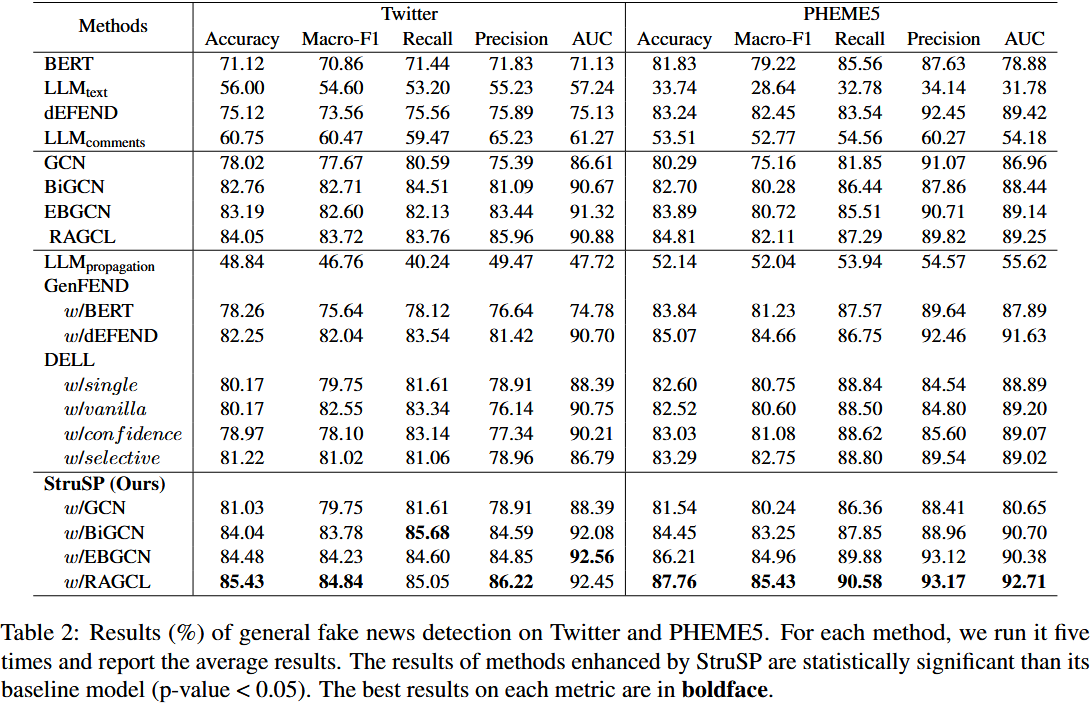 **
**
-
StruSP w/RAGCL 在 Twitter 和 PHEME5 数据集上均取得最优性能,在 PHEME5 上准确率较原始 RAGCL 提升 2.95%;
-
所有传播结构基模型(GCN、Bi-GCN、EBGCN、RAGCL)经 StruSP 增强后,性能均显著提升(p-value < 0.05);
-
StruSP 增强模型的性能优于 GenFEND、DELL 增强模型,且差距明显。
结论
-
StruSP 生成的合成传播数据能有效补充真实传播的特征,显著提升下游检测性能;
-
结构感知的合成传播生成(StruSP)优于仅基于角色扮演的生成方法(GenFEND、DELL),验证了 "结构 + 语义双对齐" 设计的有效性。
3. 实验 2:早期检测(Early Detection)
实验内容
-
场景:模拟早期传播阶段(仅保留少量真实传播数据),用不同方法生成合成传播补充后进行检测;
-
骨干检测模型:选用 RAGCL(自适应传播图对比学习模型)作为核心检测模型,该模型在传播结构特征提取上表现优异,适合评估传播数据补充后的性能变化。
-
四大对比组(确保评估的全面性):
-
Full 组:测试时使用全部真实传播数据(无数据缺失),作为 "理想场景" 的性能上限,用于衡量其他组的性能差距;
-
None 组:测试时仅使用保留的少量真实传播数据(不补充任何合成传播),作为 "无增强场景" 的基准,反映数据稀缺对检测的负面影响;
-
DELL 组:测试时使用 "少量真实传播数据 + DELL 生成的合成传播数据",对比 "角色扮演类生成方法" 与 StruSP 的增强效果;
-
StruSP 组:测试时使用 "少量真实传播数据 + StruSP 生成的合成传播数据",验证本框架的早期检测增强能力。
-
-
评估指标:核心检测指标(Accuracy、Macro-F1)。
实验结果
** 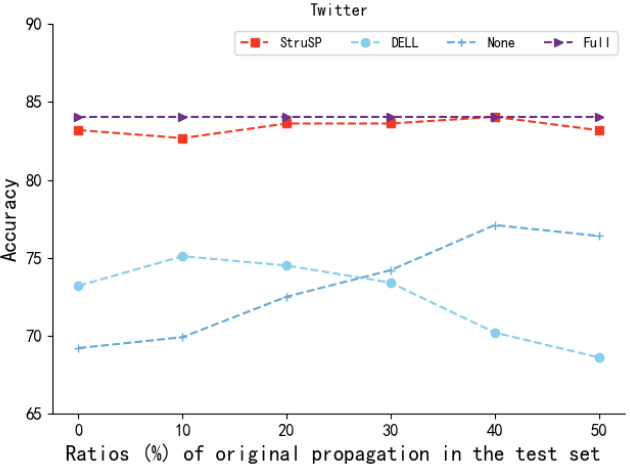 **
**
-
StruSP 增强模型的检测性能接近 Full 组(完整真实数据),显著优于 None 组和 DELL 组;
-
DELL 增强模型的性能甚至低于 None 组,出现负向优化。
结论
-
StruSP 生成的合成传播与真实传播在结构和语义上高度一致,能有效弥补早期传播数据不足的问题;
-
DELL 生成的传播与真实早期传播模式不匹配,导致检测性能下降,进一步验证结构感知生成的必要性。
4. 实验 3:跨平台检测(Cross-platform Detection)
实验内容
-
场景:源平台(Twitter/PHEME5)训练检测模型,目标平台(CED)测试,模拟跨平台传播数据稀缺场景;
-
骨干检测模型:选用 RAGCL(自适应传播图对比学习模型)作为核心检测模型,该模型在传播结构特征提取和鲁棒性上表现优异,适合评估跨平台场景下的特征迁移能力。
-
目标平台数据处理:提取 CED 测试集的少量真实传播数据(模拟目标平台数据稀缺),翻译为英文后构建 "跨平台不完整传播树";
-
三大对比组(聚焦跨平台增强效果对比):
-
原始 RAGCL 组:测试时仅使用目标平台(CED)的少量真实传播数据,不补充任何合成传播,作为 "无增强跨平台检测" 的基准;
-
DELL 增强组:测试时使用 "目标平台少量真实传播数据 + DELL 生成的合成传播数据",对比 "角色扮演类生成方法" 的跨平台增强效果;
-
StruSP 增强组:测试时使用 "目标平台少量真实传播数据 + StruSP 生成的合成传播数据",验证本框架的跨平台增强能力。
-
-
评估指标:Accuracy、Macro-F1。
实验结果
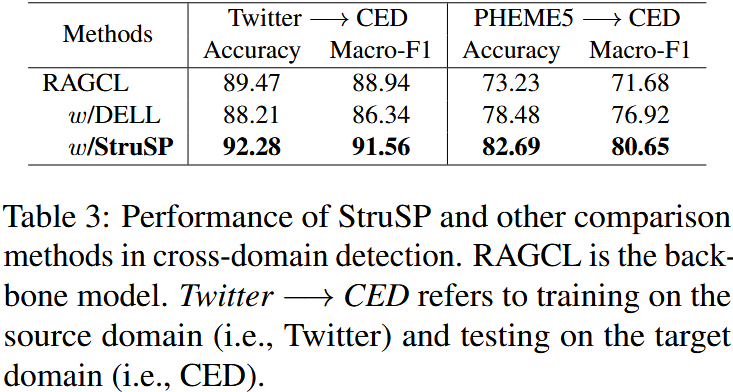
-
RAGCL w/StruSP 取得最优性能(Twitter→CED 准确率 92.28%,Macro-F1 91.56%);
-
原始 RAGCL 和 RAGCL w/DELL 性能较差,跨平台迁移效果不佳。
结论
-
StruSP 能保留源平台的传播动态特征,同时适配目标平台的内容,生成的合成传播具有更强的跨平台通用性;
-
结构感知生成是解决跨平台传播数据稀缺问题的有效手段。
5. 实验 4:消融实验(Ablation Study)
实验内容
-
目的:验证 StruSP 各核心组件的必要性;
-
消融变体:
-
w/o SHS:移除结构感知混合采样模块;
- 移除 BEP 模块中 "BFS+DFS 双向采样" 功能,仅保留单一采样方式或不采样,测试 "双向结构捕捉" 的必要性
-
w/o MPM:移除掩码传播建模模块;
-
移除 BEP 模块中 "双向掩码节点预测" 训练目标,LLM 仅通过原始传播数据初步学习,测试 "结构依赖学习" 的必要性。
- LLM 仅通过原始传播数据初步学习:仅保留采样后的原始传播路径(BFS/DFS 路径),不做任何节点掩码操作。 无显式预测损失,仅通过 "自回归语言建模损失" 让 LLM 学习传播路径的文本序列规律。
-
-
w/o BEP:移除双向进化传播学习策略(同时移除 SHS 和 MPM);
- 完全移除 BEP 模块(同时移除 SHS 和 MPM),LLM 不进行结构感知训练,仅作为通用语言模型生成传播,测试 BEP 模块的核心作用
-
w/o SPE:移除结构感知传播增强模块(仅基于新闻内容生成传播);
- 移除 "基于不完整传播树引导生成" 逻辑,LLM 仅基于新闻文本生成传播(而非以真实不完整传播为引导),测试 "结构引导生成" 的必要性
-
-
基准模型:StruSP w/RAGCL(完整框架);
-
评估指标:Accuracy、Macro-F1(Twitter 和 PHEME5 数据集)。
实验结果
** 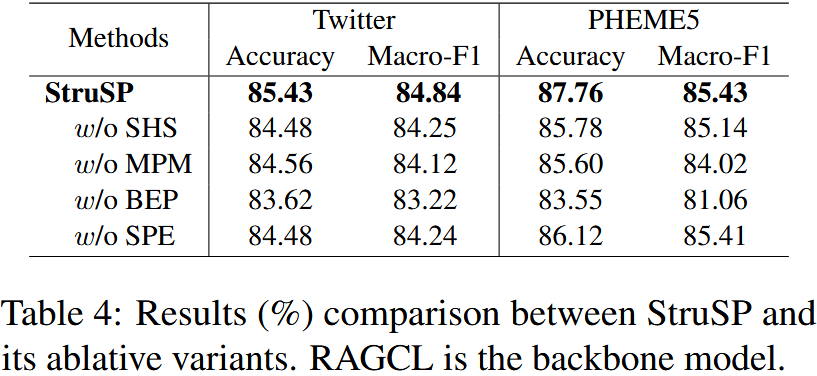 **
**
-
完整 StruSP 框架性能最优;
-
性能下降幅度排序:w/o BEP > w/o MPM ≈ w/o SHS > w/o SPE;
-
w/o BEP 变体性能下降最显著(Twitter 准确率降至 83.62%,Macro-F1 降至 83.22%)。
结论
-
BEP 学习策略(含 SHS 和 MPM)是 StruSP 框架的核心,两者互补,共同保障合成传播的真实性;
-
SHS 模块对捕捉双向传播结构、MPM 模块对学习结构依赖至关重要;
-
SPE 模块(基于不完整传播引导生成)优于仅基于新闻内容的生成,验证了 "结构引导" 的有效性。
6. 实验 5:传播质量评估(Propagation Evaluation)
实验内容
-
目的:评估 StruSP 生成的合成传播与真实传播的一致性;
-
评估维度:
-
结构指标
-
结构熵(Structural Entropy, SE):基于节点度数分布的香农熵,量化传播树节点连接的不确定性,值越接近真实传播,说明结构分布越相似;
-
最大深度(Maximum Depth, MD):单条传播树的最长路径长度,反映传播的深度递进能力;
-
最大广度(Maximum Breadth, MB):传播树中某一层级的最大节点数,反映传播的广度扩散能力。
-
-
语义指标
-
语义一致性(Semantic Consistency, SemC):计算合成传播树与对应真实传播树的平均语义嵌入余弦相似度,值越高说明语义对齐度越强;
-
情感一致性(Sentiment Consistency, SenC):判断合成传播树的 majority 情感(多数节点情感倾向)与真实传播树是否一致,用匹配比例衡量;
-
语义同质性(Semantic Homogeneity, SemH):计算单条合成传播树内所有节点间的语义嵌入余弦相似度平均值,衡量传播内容的内部连贯性。
-
-
-
对比组:
-
GenFEND 生成的合成传播(角色扮演类基线);
-
DELL 生成的合成传播(传播结构生成类基线);
-
未微调 LLM 生成的合成传播(无结构学习的 LLM 基线);
-
StruSP 生成的合成传播(本文方法);
-
实验流程
-
合成传播生成:对 Twitter 和 PHEME5 数据集中的每条新闻,分别用 StruSP、GenFEND、DELL、未微调 LLM 生成合成传播树(每条生成 30 个节点);
-
真实传播提取:提取对应新闻的完整真实传播树,作为评估的 "黄金标准";
-
指标计算:
-
结构指标:对每条合成 - 真实传播树对,计算 SE、MD、MB;
-
语义指标:用 BERT 模型提取所有节点的语义嵌入,计算 SemC 和 SemH;用预训练情感分类器(DistilBERT 微调版)标注每个节点情感,计算 SenC;
-
-
宏观与微观分析:
-
宏观分析:计算所有样本的指标平均值,对比各方法与真实传播的整体差距;
-
微观分析:统计各指标的样本分布情况(如直方图、箱线图),评估合成传播的稳定性与多样性。
-
实验结果
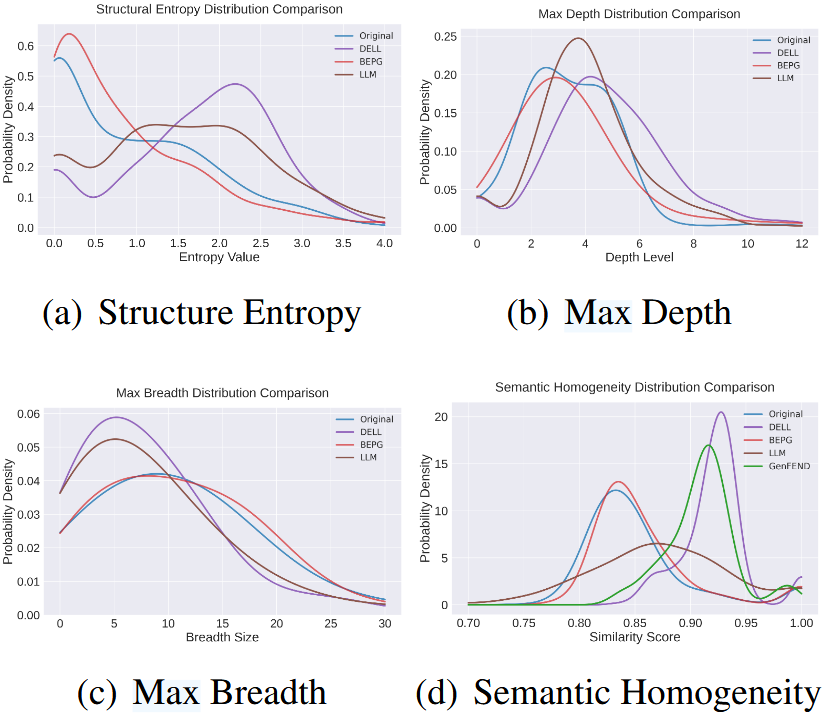
图 4:在合并的 Twitter 和 PHEME5 数据集上进行的微观层面传播分析结果。不同方法生成的传播在结构熵、实例级深度 / 广度以及语义同质性方面的分布情况
结论
-
结构层面:StruSP 生成的传播在 SE、MD、MB 上与真实传播最接近,避免了 GenFEND 的结构单一和 DELL 的结构失真;
-
语义层面:StruSP 的 SemC(0.97)、SenC(0.85)均高于其他基准,说明生成内容与真实传播的语义、情感一致性更强;
-
StruSP 生成的传播兼具 "真实性" 和 "多样性",优于其他生成方法。
7. 实验 6:不同 LLM 骨干网络验证
实验内容
-
目的:验证 StruSP 对不同 LLM 骨干的通用性;
-
变量控制:仅改变 LLM 骨干网络类型,其余训练配置(生成节点数、微调参数、检测模型)完全一致,避免无关变量干扰。
-
LLaMa3-8B-Instruct:Meta 推出的 80 亿参数开源 LLM,指令跟随能力强,是主实验默认骨干网络;
-
Qwen3-4B:阿里推出的 40 亿参数开源 LLM,轻量化且性能优异,适合资源受限场景。
-
-
基准模型:结合 GCN、Bi-GCN、EBGCN、RAGCL 四类检测模型;
-
评估指标:Accuracy、Macro-F1(Twitter 和 PHEME5 数据集)。
实验流程
-
LLM 微调训练:
-
对两款 LLM(LLaMa3-8B-Instruct、Qwen3-4B)分别执行 StruSP 的 BEP 模块训练:使用 Twitter+PHEME5 合并训练集,通过 SHS 采样 + 无掩码文本学习(仅替换骨干,训练逻辑不变);
-
微调配置统一:LoRA 秩 = 8,AdamW 优化器,学习率 5e-5,训练 4 个 epoch,启用 BF16 精度;
-
生成配置统一:所有模型生成的合成节点数均预设为 30。
-
-
检测模型训练与评估:
-
将两款微调后的 LLM 分别接入 SPE 模块,生成合成传播数据,与真实传播数据整合;
-
用整合后的传播数据,分别训练 GCN、Bi-GCN、EBGCN、RAGCL 四类检测模型;
-
在 Twitter 和 PHEME5 测试集上评估所有模型的检测性能,记录核心指标。
-
-
结果对比分析:
-
横向对比:同一 LLM 骨干下,不同检测模型的性能差异;
-
纵向对比:同一检测模型下,两款 LLM 骨干的性能差异;
-
核心观察:两款 LLM 骨干的性能是否接近,是否均能让 StruSP 框架保持优异表现。
-
实验结果
** 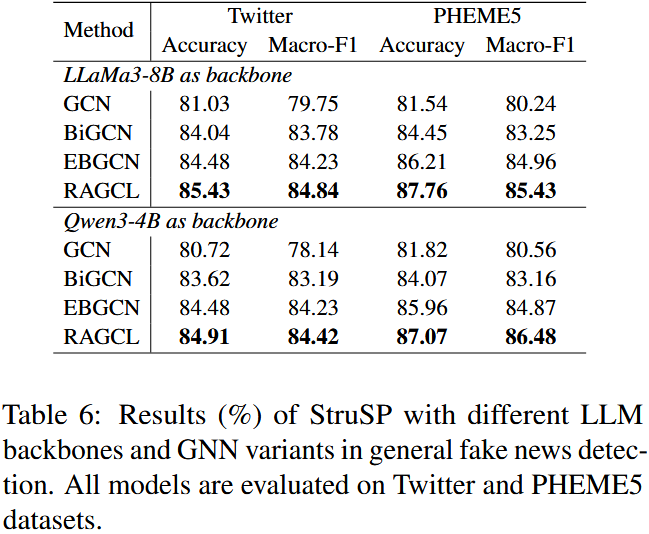 **
**
-
两种 LLM 作为骨干时,StruSP 增强后的检测模型均取得优异性能;
-
LLaMa3-8B-Instruct 和 Qwen3-4B 的性能差异较小(如 StruSP w/RAGCL 在 PHEME5 上的准确率分别为 87.76% 和 87.07%);
-
无论使用哪种 LLM,StruSP 增强后的 RAGCL 均为最优组合。
结论
-
StruSP 框架对 LLM 骨干网络具有良好的鲁棒性,不依赖特定 LLM 模型;
-
框架的核心优势(结构感知生成)不受 LLM 类型影响,具有广泛的适用性。
8. 实验核心总结
-
性能优势:StruSP 在一般检测、早期检测、跨平台检测三大实用场景中均显著优于现有基准,验证了其解决 "传播数据不完整" 问题的有效性;
-
生成质量:StruSP 生成的合成传播在结构和语义上与真实传播高度对齐,且多样性更优;
-
组件必要性:BEP 学习策略(SHS+MPM)是框架核心,SPE 模块的结构引导生成优于纯文本驱动生成;
-
通用性:StruSP 可适配不同 LLM 骨干网络和检测模型,具有较强的落地潜力。
参考
- Let Silence Speak: Enhancing Fake News Detection with Generated Comments from Large Language Models
- DELL: Generating reactions and explanations for LLM-based misinformation detection
- From skepticism to acceptance: Simulating the attitude dynamics toward fake news
- Can llms simulate social media engagement? a study on action-guided response generation
- Evidence-driven retrieval augmented response generation for online misinformation
- Structure-aware Propagation Generation with Large Language Models for Fake News Detection
- Collaboration and Controversy Among Experts: Rumor Early Detection by Tuning a Comment Generator